Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
1.4. Сравнение с другими методамиПеречислим другие методы кодирования и декодирования, которые представляются весьма перспективными с точки зрения получения малой вероятности ошибки и большой скорости передачи информации без особо больших затрат: первый — сверточные коды [3] с последовательным декодированием, развитым Возенкрафтом [17], Фано [5] и Рейффеном [14], второй — сверточные коды с пороговым декодированием Месси [10] и третий — коды Боуза — Чоудхури с декодированием по методу Питерсона [12] и Цирлера и Горенстейна [18]. Фано показал [5], что последовательное декодирование позволяет в любом дискретном канале без памяти декодировать с вероятностью ошибки, ограниченной сверху функцией вида В Линкольновской лаборатории (Лексингтон, Массачусетс) [11] построен экспериментальный декодер. Применение его в системе с обратной связью и с соответствующими модулятором и демодулятором позволило получить экспериментально надежную связь по телефонной линии со скоростью около 7500 бит/сек, в то время как без кодирования возможно достичь скорости всего в 1200 или 2400 бит/сек. Последовательному декодированию присущи два основных недостатка: первый — число операций на символ есть случайная величина, это создает проблему очереди в декодере; второй — если декодер совершает ошибку, возможно появление большого числа ошибок, прежде чем декодер вернется на правильный путь. Эти проблемы не вызывают серьезных затруднений при наличии обратной связи, однако случай, когда линия обратной связи отсутствует, требует дальнейшего исследования. Пороговое декодирование — наиболее просто реализуемый из рассматриваемых здесь методов — требует наличия только регистров сдвига, некоторого числа двоичных сумматоров и порогового устройства. Оно наиболее эффективно при сравнительно небольших длинах кодовых ограничений, однако дает несколько большую вероятность ошибки и менее гибко, чем метод последовательного декодирования. Число операций на символ при декодировании кодов Боуза — Чоудхури в двоичных симметричных каналах растет, грубо говоря, как куб длины блока, и слабо флуктуирует. Метод декодирования гарантирует исправление всех комбинаций с числом ошибок вплоть до некоторой величины и не позволяет исправлять никаких других комбинаций. Уже при блоках умеренной длины это ограничение вызывает большой рост Число операций на символ при декодировании кодов с малой плотностью проверок на четность, по-видимому, растет самое большее логарифмически с длиной блока и слабо флуктуирует. Вероятность ошибки декодирования неизвестна, однако есть основание считать, что она убывает экспоненциально с ростом длины блока. Возможность декодировать параллельно все символы позволяет получить скорости передачи информации большие, чем при использовании других методов. Для многих каналов с памятью можно запоминать апостериорные вероятности на выходе канала, и это практически исключает необходимость принимать во внимание память канала каким-либо иным способом. В канале с замираниями, например когда замирания охватывают несколько бодов подряд, апостериорные вероятности укажут на присутствие замирания. Если же этот канал используется как двоичный симметричный, при декодировании нужно учитывать тот факт, что пакеты ошибок более вероятны, чем изолированные ошибки. Таким образом, использование апостериорных вероятностей приводит к тому, что декодирование кодов с малой плотностью и последовательное декодирование оказываются более гибкими при работе в каналах с зависимыми шумами. С другой стороны, существует особенно простой метод декодирования кодов Боуза — Чоудхури [12] для того случая, когда действие шумов ограничивается появлением коротких, но плотных пакетов ошибок. Когда передача по каналу происходит с длительными замираниями или подвергается действию длинных пакетов ошибок, часто практически не имеет смысла исправлять ошибки в эти периоды. В таких случаях использование сочетания исправления и обнаружения ошибок при обратной связи и переспросе имеет определенные преимущества. Все рассматриваемые здесь методы кодирования и декодирования естественным образом укладываются в эту схему, однако в тех случаях, когда исправление не осуществляется или исправляется небольшое число ошибок, коды с малой плотностью оказываются малоэффективными. В заключение скажем, что все перечисленные методы имеют свои достоинства и недостатки и ясно, что ни один из них не может оказаться оптимальным во всех случаях. Сейчас, по-видимому, существует достаточное число вариантов методов кодирования и декодирования, чтобы можно было всерьез рассматривать вопрос об их использовании в конкретных каналах.
|
 |
Оглавление
|























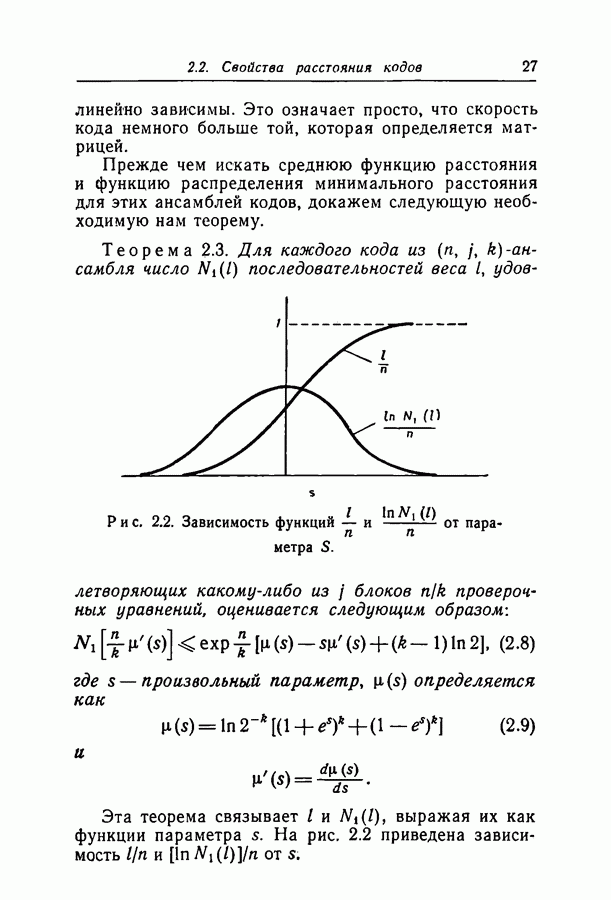



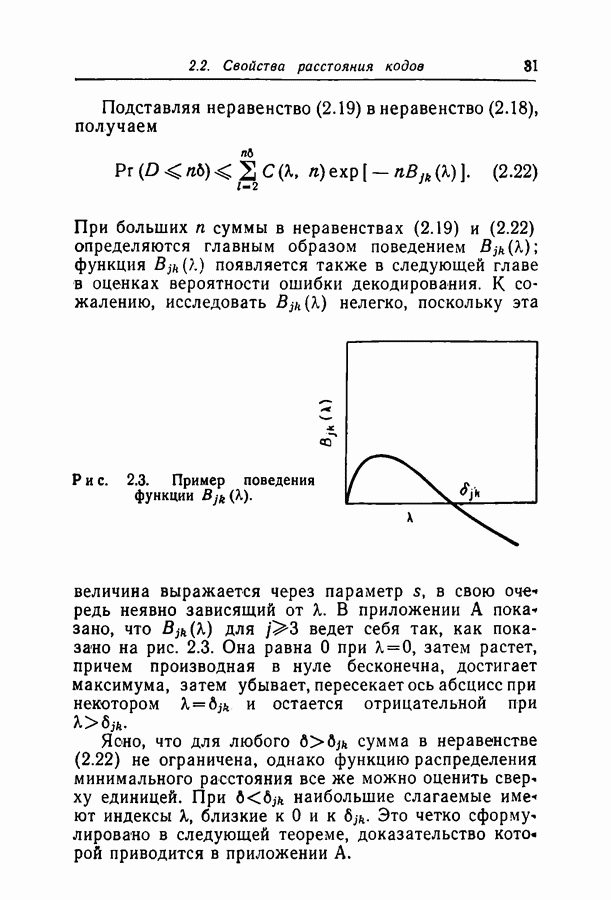

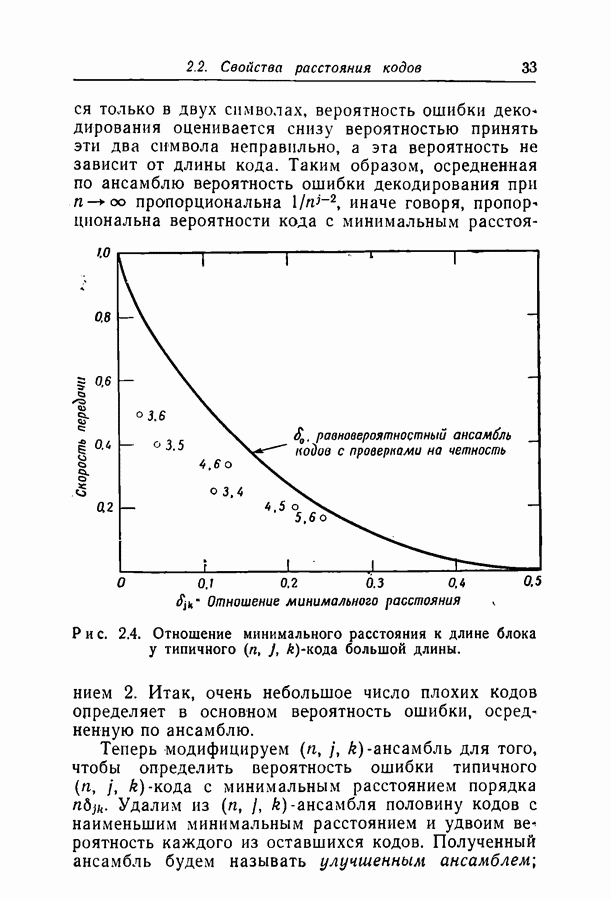





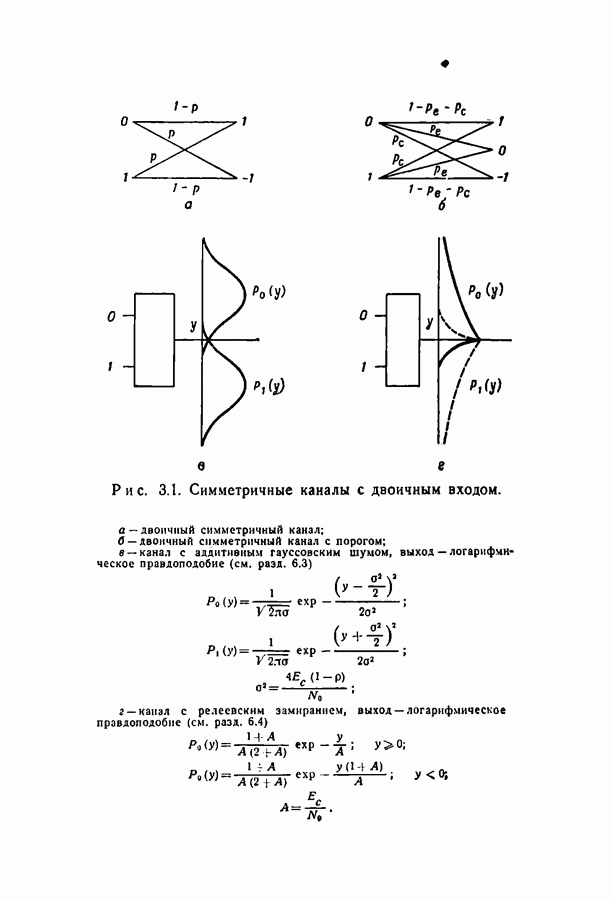













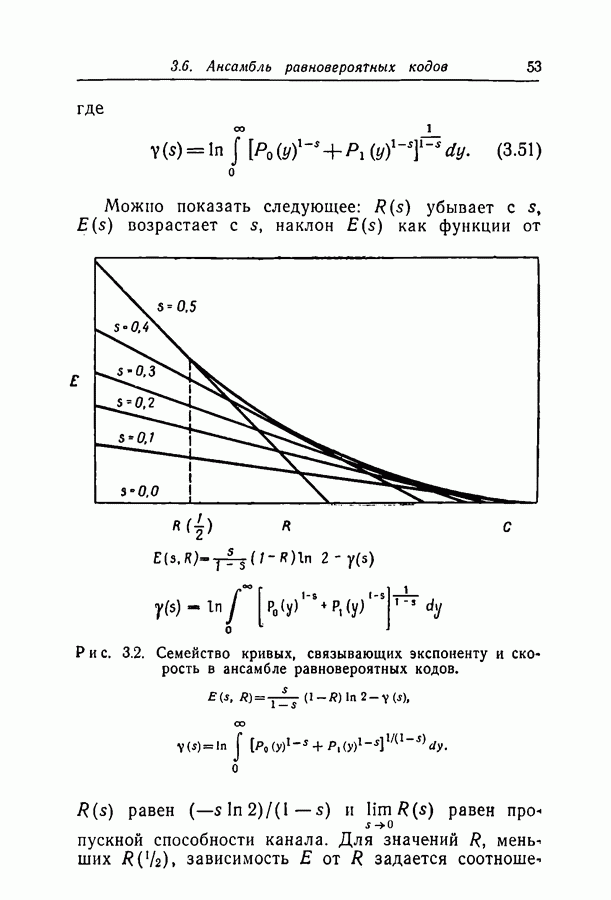


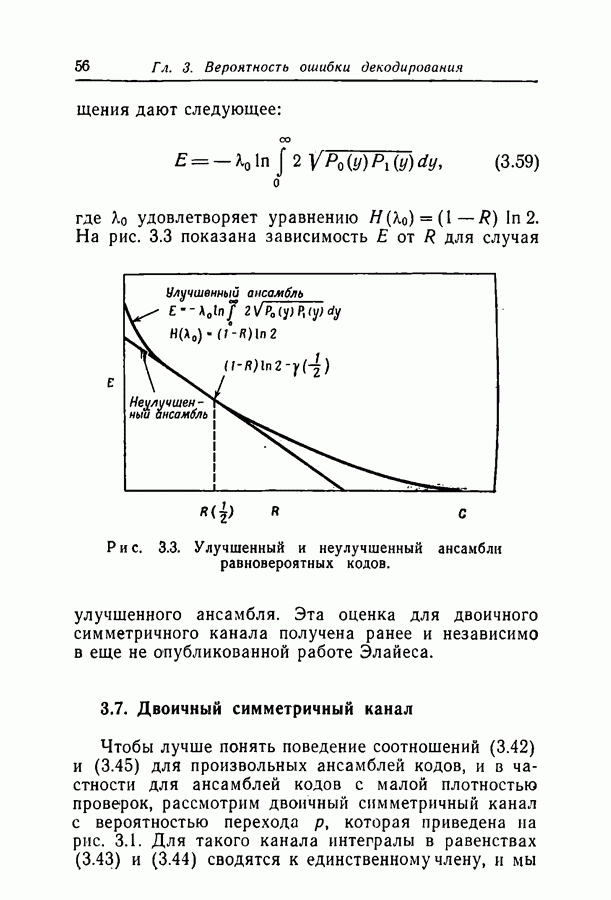

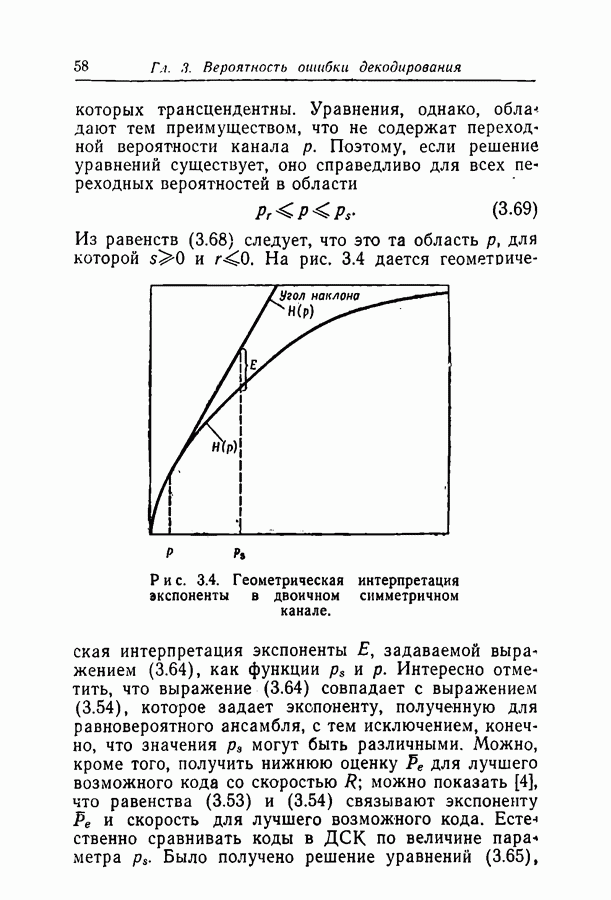
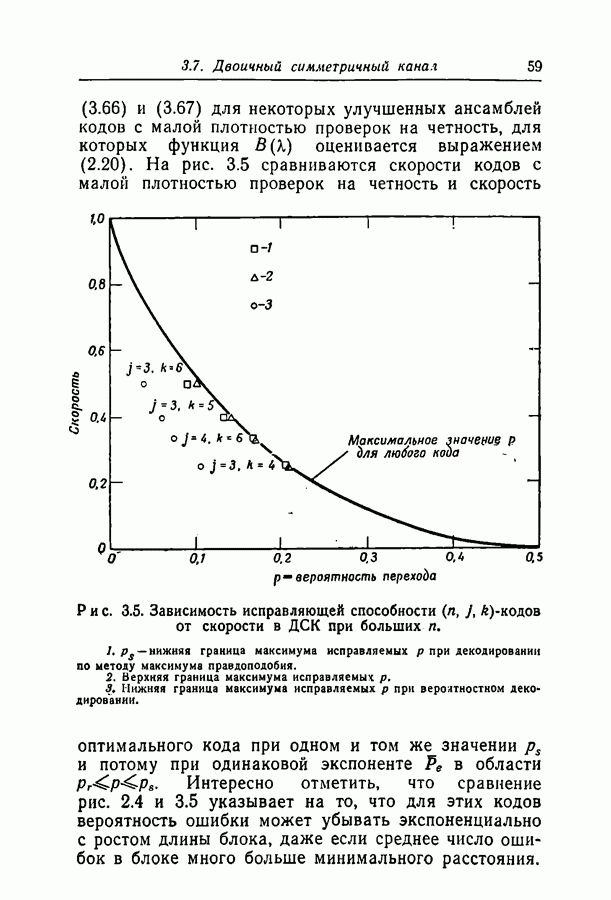















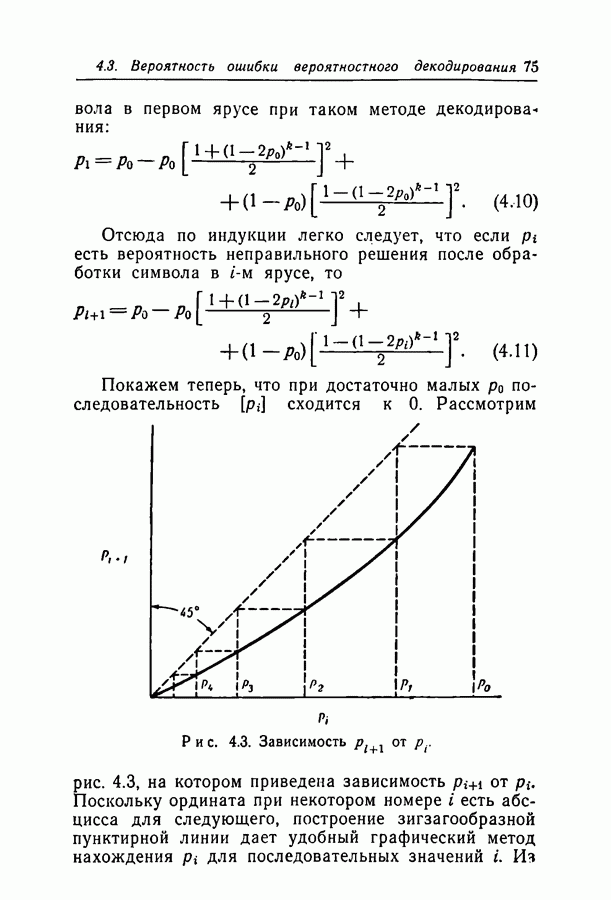


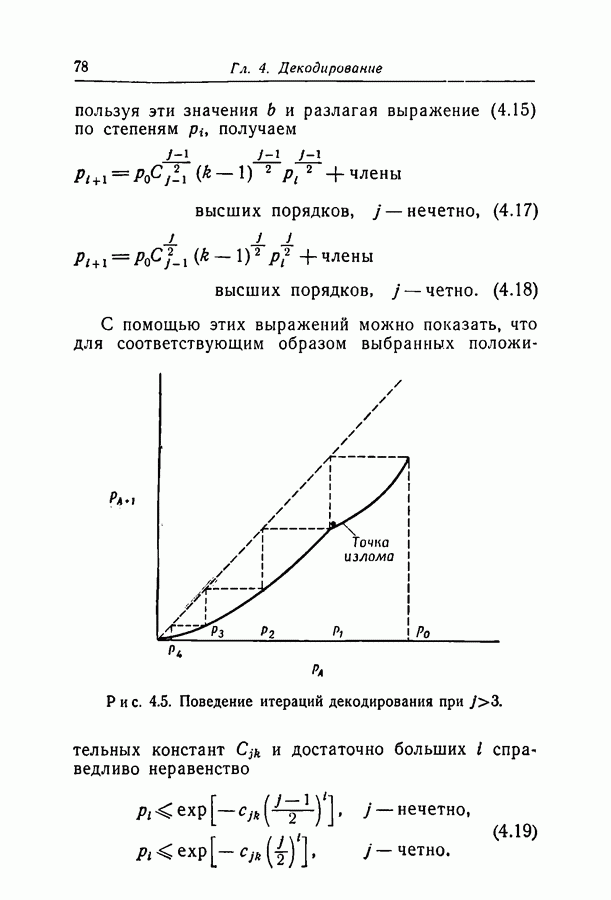

















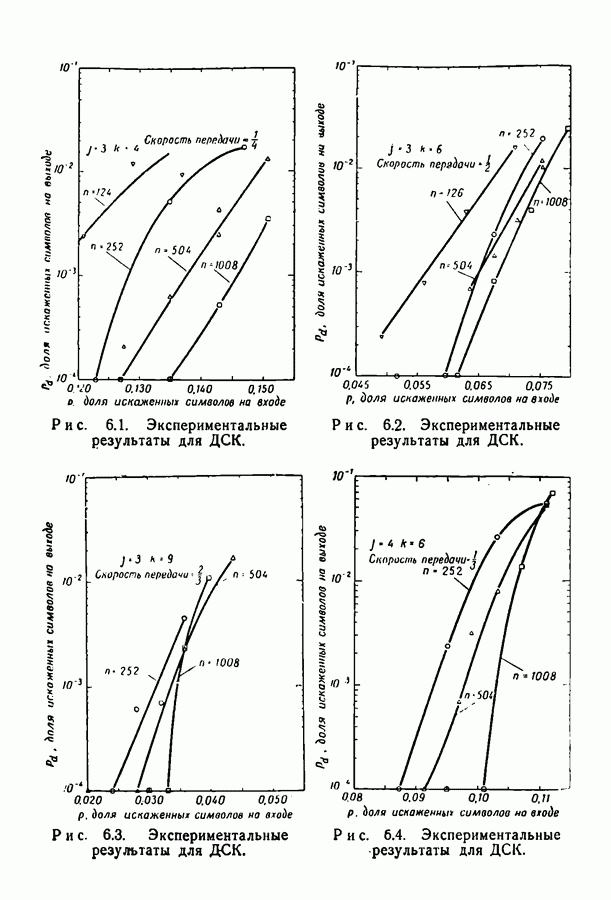
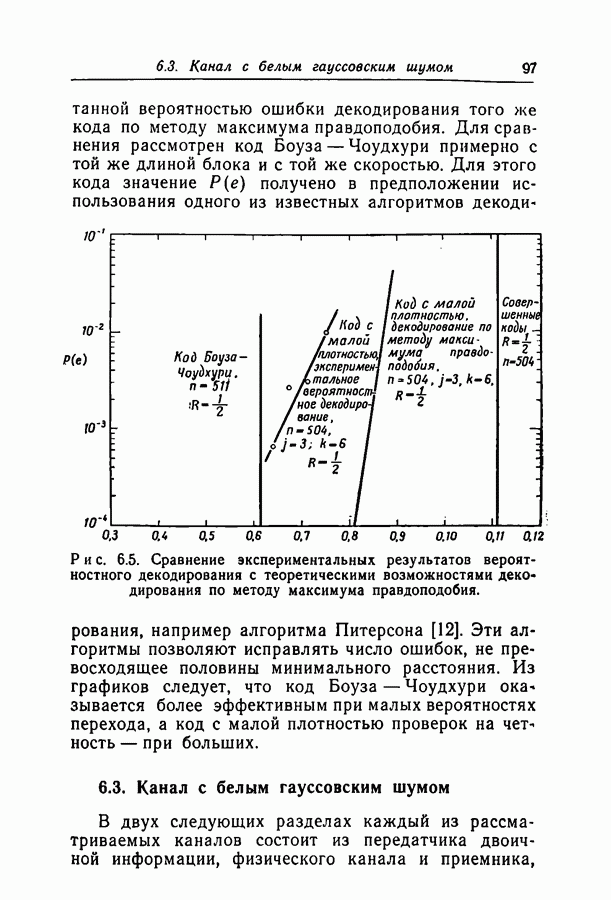


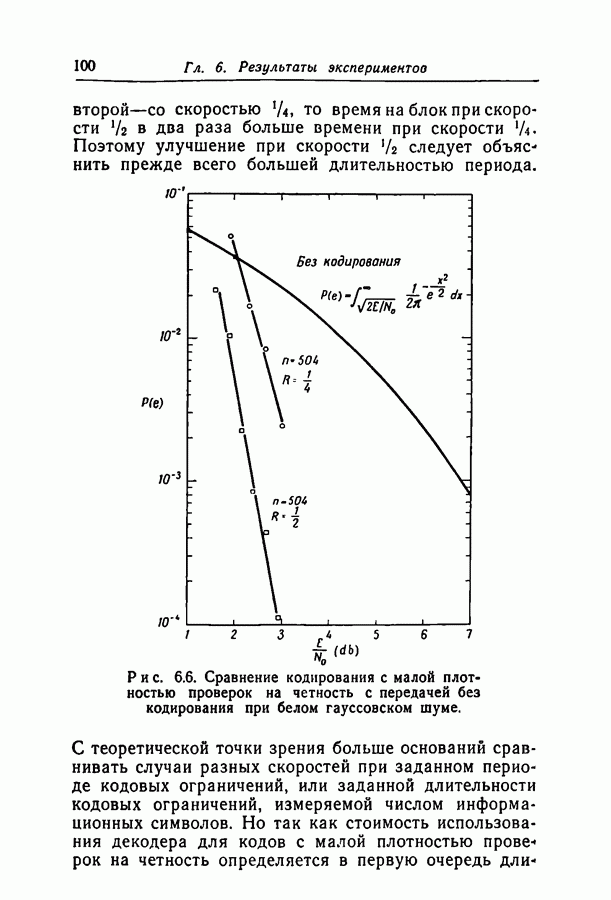
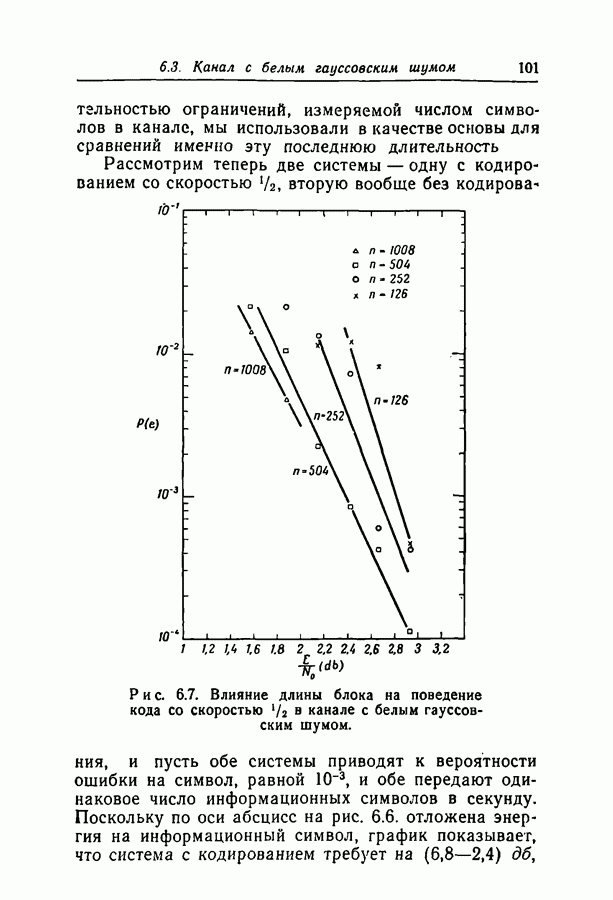
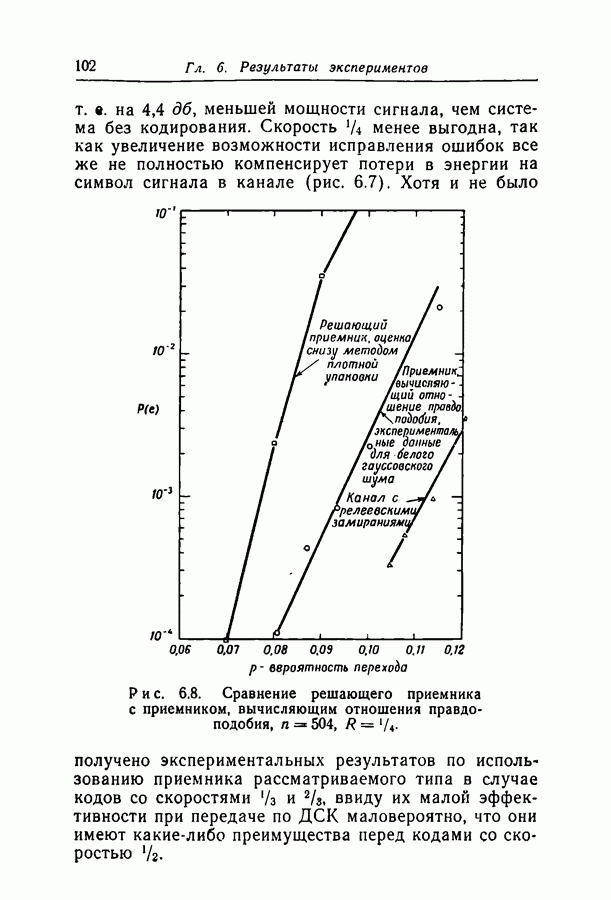


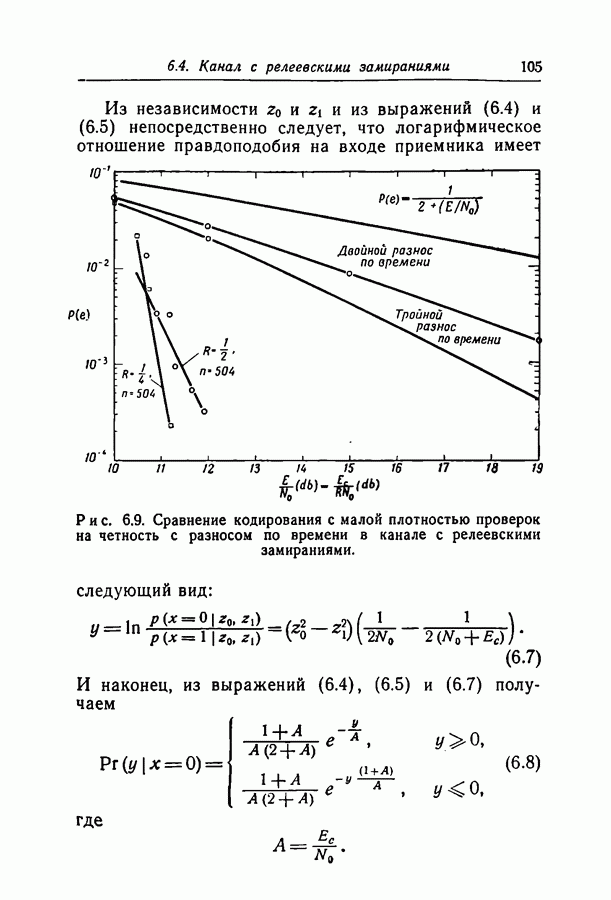


































 Здесь
Здесь  — длина кодовых ограничений,
— длина кодовых ограничений,  функция как канала, так и кода, причем а положительна для скоростей, меньших пропускной способности С. Фано показал также, что при скоростях, меньших некоторой величины Ясотр, где
функция как канала, так и кода, причем а положительна для скоростей, меньших пропускной способности С. Фано показал также, что при скоростях, меньших некоторой величины Ясотр, где  среднее число операций при декодировании символа ограничено величиной, не зависящей от длины кодовых ограничений.
среднее число операций при декодировании символа ограничено величиной, не зависящей от длины кодовых ограничений.
 Неизвестно, каким образом можно использовать апостериорные вероятности на выходе более общих каналов с двоичным входом. По-видимому, то, что алгебраические методы декодирования не позволяют использовать апостериорные вероятности, есть их характерное отличие от вероятностных методов.
Неизвестно, каким образом можно использовать апостериорные вероятности на выходе более общих каналов с двоичным входом. По-видимому, то, что алгебраические методы декодирования не позволяют использовать апостериорные вероятности, есть их характерное отличие от вероятностных методов.