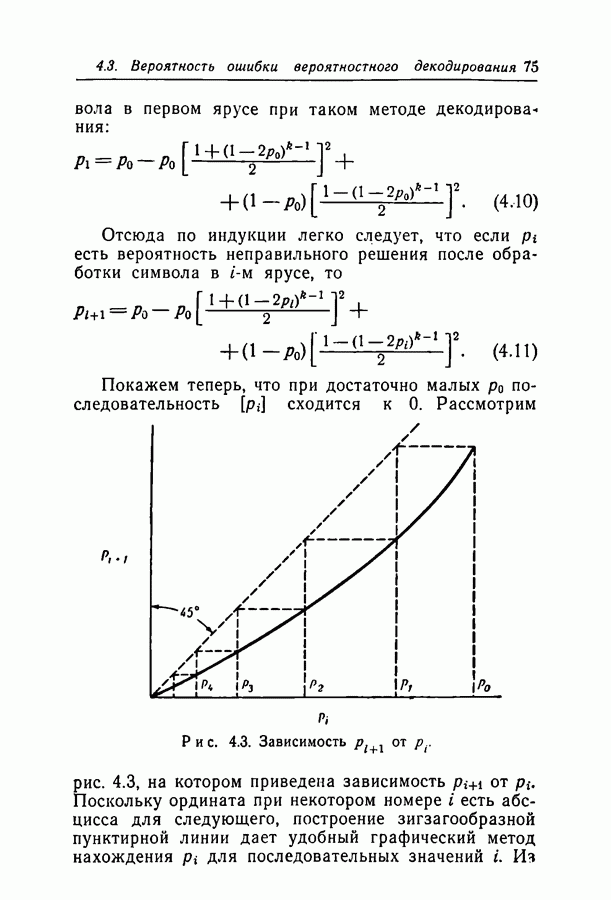
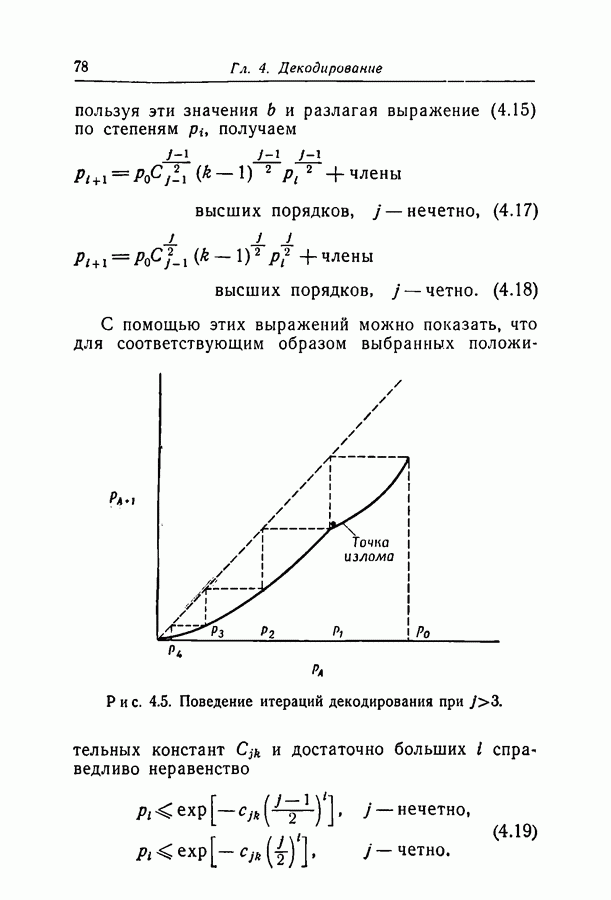
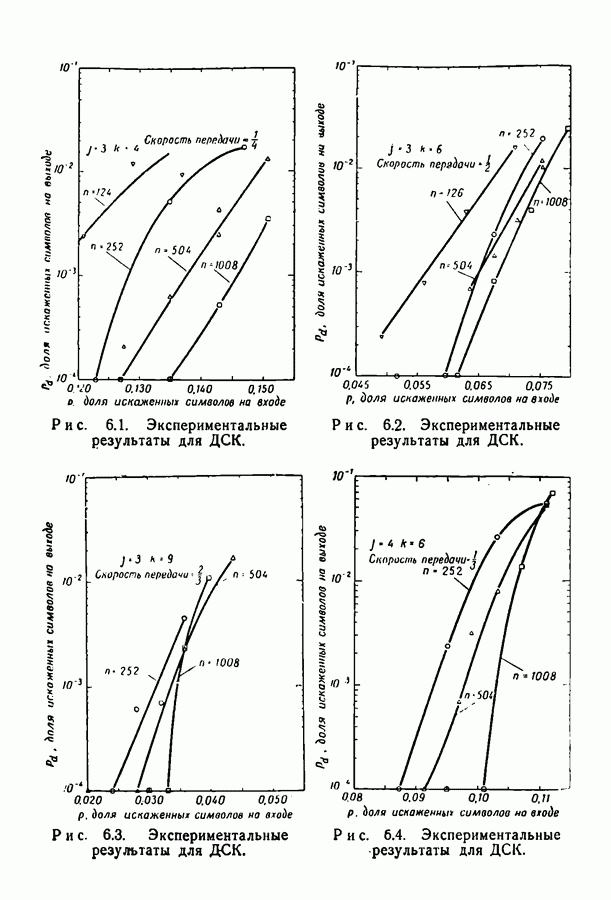
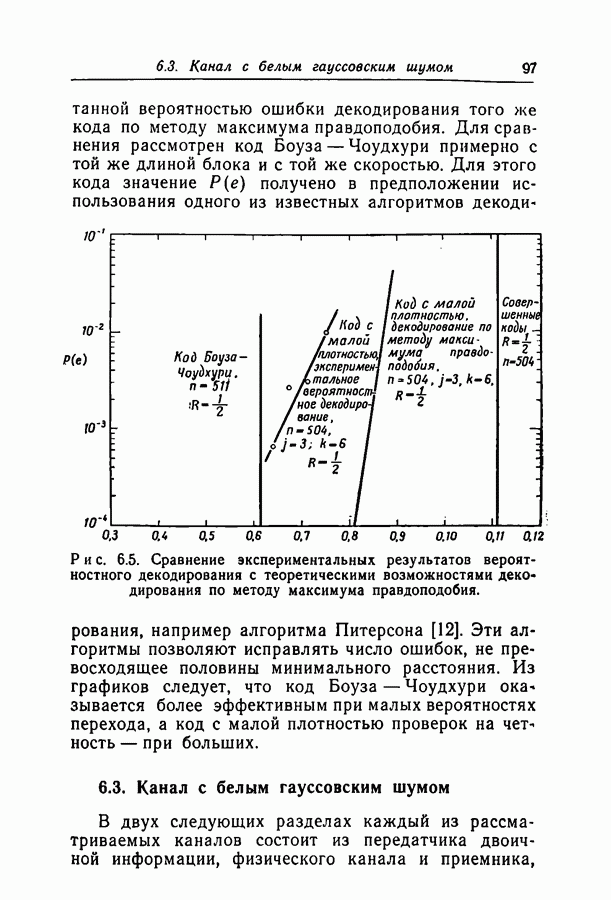
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
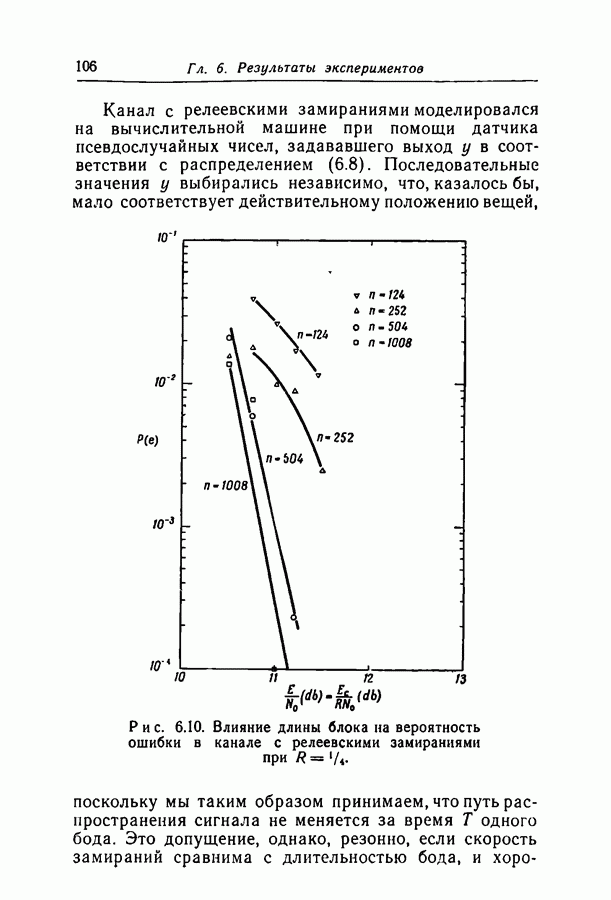
2.2. Свойства расстояния кодов с малой плотностью проверокВ этом разделе мы определим ансамбль кодов с малой плотностью проверок на четность и докажем теоремы, аналогичные теоремам 2.1 и 2.2. Затем мы построим новый ансамбль, отбрасывая коды с малым минимальным расстоянием. Такой улучшенный ансамбль будет использован в следующей главе при выводе оценок вероятности ошибки декодирования для различных каналов. Определим Эта матрица разбита на
Рис. 2.1. Пример матрицы кода с малой плотностью проверок на четность; Остальные подматрицы суть просто перестановки столбцов первой. Определим ансамбль линейно зависимы. Это означает просто, что скорость кода немного больше той, которая определяется матрицей. Прежде чем искать среднюю функцию расстояния и функцию распределения минимального расстояния для этих ансамблей кодов, докажем следующую необходимую нам теорему.
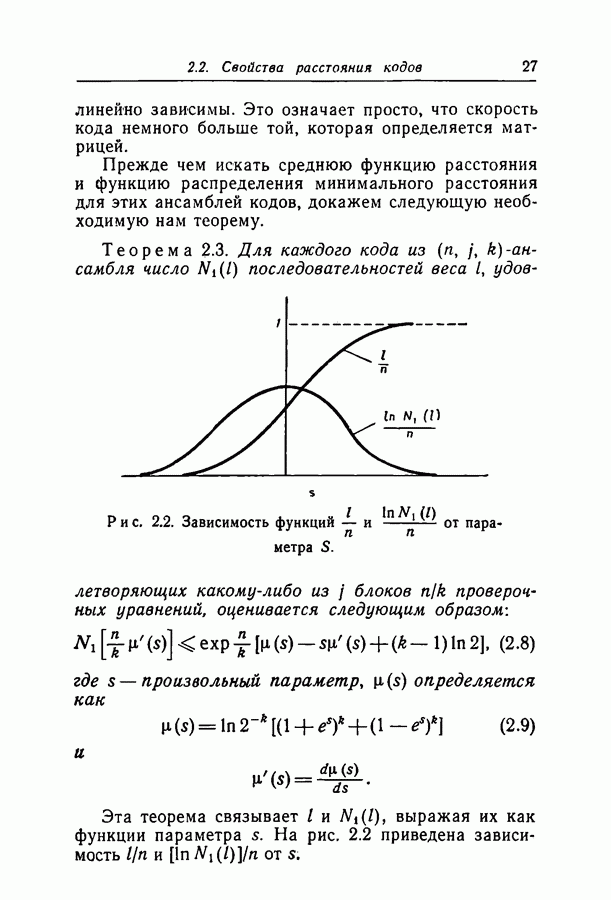
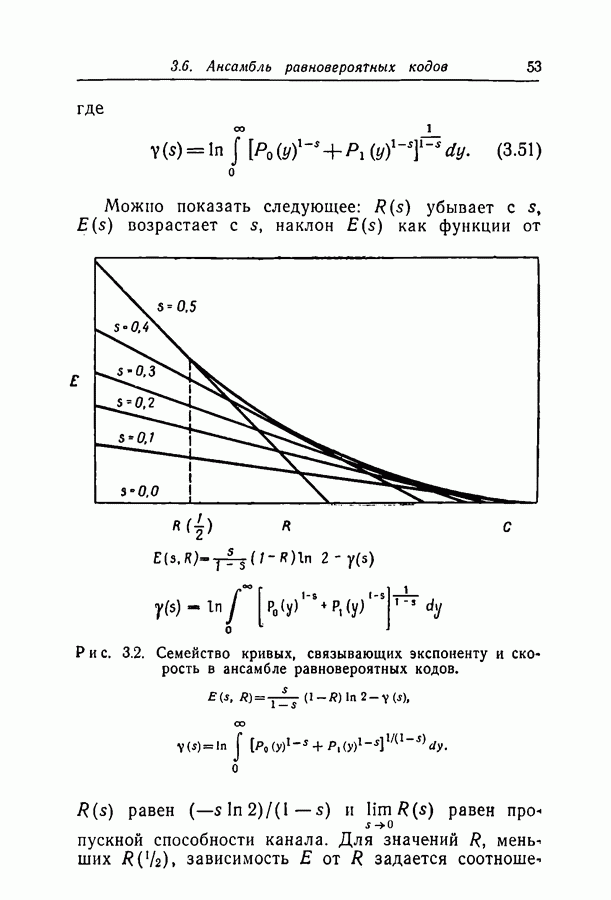
Рис. 2.2. Зависимость функций Теорема 2.3. Для каждого кода из
где
Эта теорема связывает Доказательство. Для любого кода в ансамбле и любого из у блоков по
или
Для того чтобы показать, что правые части равенств (2.10) и (2.11) эквивалентны, нужно разложить правую часть равенства (2.11) по формуле бинома и заметить, что нечетные члены уничтожаются. Для каждого из вероятности
для любых Из равенств (2.9) и (2.11) следует, что
И наконец,
Положим производную экспоненты в неравенстве (2.14) равной 0 и подставим полученное значение Как показано в [4], положив
Мы можем теперь воспользоваться теоремой 2.3 для того, чтобы найти вероятность кодов, для которых некоторая фиксированная после довательность веса I есть кодовое слово. Ясно, что, поскольку все перестановки кода равновероятны, Если последовательность веса I выбрана случайным образом, то для любого кода из ансамбля вероятность того, что эта последовательность удовлетворит любому фиксированному блоку из
Теперь мы можем выразить через
Заметим, что в ансамбле кодов с малой плотностью кодовыми словами могут быть только последовательности четного веса. Используя неравенства (2.4) и (2.14), получаем
где
Подставляя неравенство (2.19) в неравенство (2.18), получаем
При больших
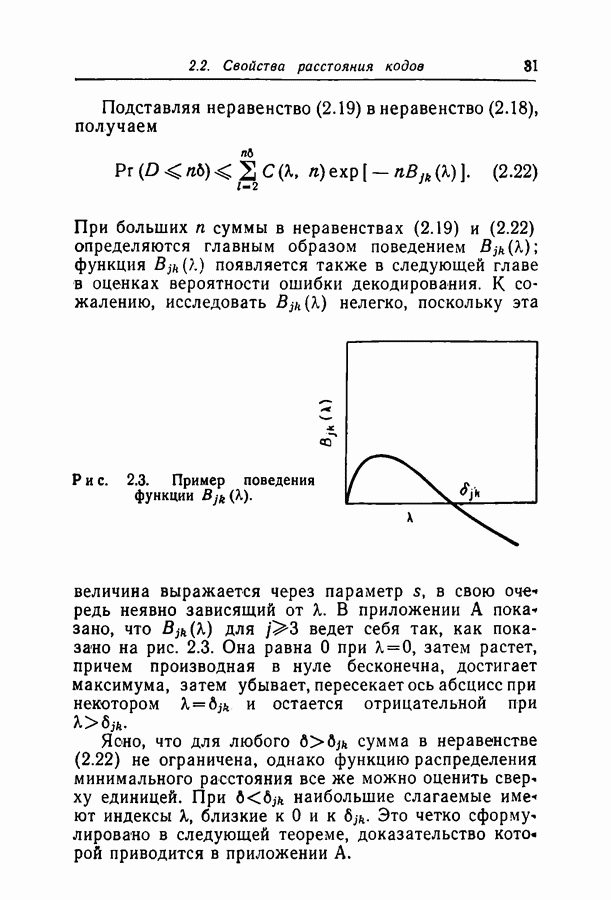
Рис. 2.3. Пример поведения функции К сожалению, исследовать Ясно, что для любого Теорема 2.4. В
и
где Первое слагаемое в неравенстве (2.23) соответствует кодовым словам веса 2, следующее слагаемое соответствует словам с малыми весами, большими 2, а последнее соответствует словам с большим весом. При возрастании Будем называть выражение 6 типичным коэффициентом минимального расстояния в Здесь же мы видим, зачем функция распределения минимального расстояния была получена раньше каких-либо результатов о вероятности ошибки декодирования. Если два слова в групповом коде отличаются только в двух символах, вероятность ошибки деко дирования оценивается снизу вероятностью принять эти два символа неправильно, а эта вероятность не зависит от длины кода. Таким образом, осредненная по ансамблю вероятность ошибки декодирования при
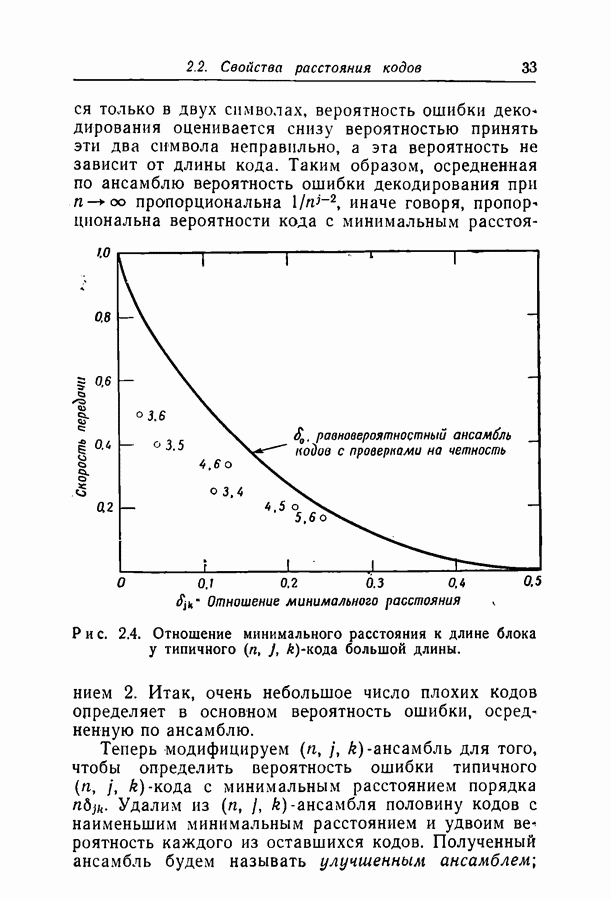
Рис. 2.4. Отношение минимального расстояния к длине блока у типичного Итак, очень небольшое число плохих кодов определяет в основном вероятность ошибки, осредненную по ансамблю. Теперь модифицируем он используется в гл. 3 при выводе оценок вероятности ошибки декодирования Пусть
Проведя аналогичным образом улучшение ансамбля случайных кодов с проверками на четность, получаем из соотношений (2.1) и (2.5)
где
Прежде чем использовать этот модифицированный ансамбль для вывода оценок вероятности ошибки декодирования, рассмотрим частный случай Теорема 2.5. Пусть в коде с проверками на четность длина блока равна минимальное расстояние кода
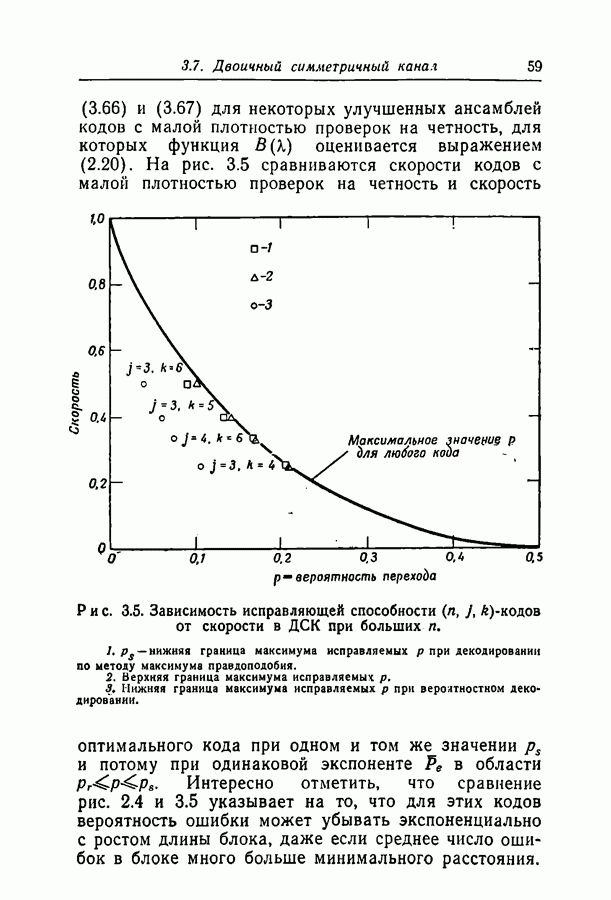
Доказательство. Докажем теорему, представив код в виде дерева — так, как это сделано на рис. 2.5. Пусть первый символ в коде представлен корнем дерева.
Рис. 2.5. Проверочное дерево. Этот символ входит в два проверочных множества, обозначенных двумя ветвями, выходящими из корня. Остальные символы этих двух проверочных множеств представлены узлами первого яруса дерева. Точно так же каждый символ первого яруса содержится в некотором другом проверочном множестве, представляемом ветвью, выходящей из этого символа. Подобным образом можно строить ярусы дерева до тех пор, пока при некотором целом Теперь оценим второй
Для фиксированной петли в дереве рассмотрим совокупность узлов на сочленениях ветвей петли. На рис. 2.5 эти узлы отмечены звездочками. Каждая ветвь петли должна содержать ровно два таких узла, и никакая из других ветвей дерева их не содержит. Поэтому последовательность длины
поскольку петля образована одним путем, идущим вверх по дереву, и одним путем, идущим вниз по де реву. Объединяя неравенства (2.27) и (2.28), получаем неравенство (2.26), Ч.Т.Д.
|
 |
Оглавление
|
























































































































 -проверочную матрицу как матрицу с
-проверочную матрицу как матрицу с  столбцами,
столбцами,  единицами в каждом столбце,
единицами в каждом столбце,  единицами в каждой строке и с нулями во всех остальных позициях. Из определения следует, что
единицами в каждой строке и с нулями во всех остальных позициях. Из определения следует, что  -проверочная матрица имеет
-проверочная матрица имеет  строк и поэтому скорость
строк и поэтому скорость  Для того чтобы построить ансамбль
Для того чтобы построить ансамбль  -матриц, рассмотрим сначала
-матриц, рассмотрим сначала  -матрицу, приведенную на рис. 2.1, для которой
-матрицу, приведенную на рис. 2.1, для которой 
 подматриц, и в каждом столбце каждой подматрицы содержится только одна единица. В первой подматрице все единицы расположены в ступенчатом порядке,
подматриц, и в каждом столбце каждой подматрицы содержится только одна единица. В первой подматрице все единицы расположены в ступенчатом порядке,  строка содержит единицы в столбцах с
строка содержит единицы в столбцах с  по
по 


 -кодов как ансамбль, получающийся при случайных перестановках столбцов каждой из
-кодов как ансамбль, получающийся при случайных перестановках столбцов каждой из  нижних подматриц матрицы типа приведенной на рис. 2.1, причем всем перестановкам приписываются равные вероятности. Это определение несколько произвольно и введено для удобства математического анализа. На самом деле такой ансамбль не включает все только что определенные
нижних подматриц матрицы типа приведенной на рис. 2.1, причем всем перестановкам приписываются равные вероятности. Это определение несколько произвольно и введено для удобства математического анализа. На самом деле такой ансамбль не включает все только что определенные  -коды. К тому же по крайней мере
-коды. К тому же по крайней мере  строк каждой матрицы ансамбля
строк каждой матрицы ансамбля

 от параметра
от параметра 
 -ансамбля число
-ансамбля число  последовательностей веса
последовательностей веса  удовлетворяющих какому-либо из
удовлетворяющих какому-либо из  блоков
блоков  проверочных уравнений, оценивается следующим образом:
проверочных уравнений, оценивается следующим образом:

 — произвольный параметр,
— произвольный параметр,  определяется как
определяется как

 выражая их как функции параметра
выражая их как функции параметра  На рис. 2.2 приведена зависимость
На рис. 2.2 приведена зависимость  от
от 
 проверочных соотношений
проверочных соотношений  проверочных множеств
проверочных множеств  не пересекаются и исчерпывают все позиции блока. Рассмотрим совокупность всех двоичных последовательностей длины
не пересекаются и исчерпывают все позиции блока. Рассмотрим совокупность всех двоичных последовательностей длины  содержащих четное число единиц, и построим из них ансамбль, приписывая всем им равные вероятности. Общее число последовательностей в ансамбле равно
содержащих четное число единиц, и построим из них ансамбль, приписывая всем им равные вероятности. Общее число последовательностей в ансамбле равно  а вероятность того, что последовательность содержит
а вероятность того, что последовательность содержит  единиц
единиц  четно), равна
четно), равна  Отсюда выражение для производящей функции моментов числа единиц в последовательности будет
Отсюда выражение для производящей функции моментов числа единиц в последовательности будет


 проверочных множеств выберем независимо последовательность из построенного выше ансамбля и используем ее в качестве двоичных единиц в позициях этого проверочного множителя. Таким образом определим ансамбль равновероятных событий, в котором каждое событие есть последовательность длины
проверочных множеств выберем независимо последовательность из построенного выше ансамбля и используем ее в качестве двоичных единиц в позициях этого проверочного множителя. Таким образом определим ансамбль равновероятных событий, в котором каждое событие есть последовательность длины  удовлетворяющая
удовлетворяющая  проверочным соотношениям. Число единиц в каждой последовательности длины
проверочным соотношениям. Число единиц в каждой последовательности длины  есть сумма чисел единиц, входящих в каждое проверочное множество, и, таким образом, есть сумма
есть сумма чисел единиц, входящих в каждое проверочное множество, и, таким образом, есть сумма  независимых случайных величин, причем производящая функция моментов каждой из них определяется равенством (2.11). Следовательно, производящая функция моментов числа единиц в последовательности длины
независимых случайных величин, причем производящая функция моментов каждой из них определяется равенством (2.11). Следовательно, производящая функция моментов числа единиц в последовательности длины  есть
есть  Используем теперь это обстоятельство для оценки
Используем теперь это обстоятельство для оценки
 того, что последовательность из ансамбля содержит
того, что последовательность из ансамбля содержит  единиц. По определению,
единиц. По определению,

 и
и 
 и
и

 рвно произведению
рвно произведению  на число последовательностей в ансамбле. Поскольку в ансамбле последовательностей длины
на число последовательностей в ансамбле. Поскольку в ансамбле последовательностей длины  всего
всего  элементов, имеется
элементов, имеется  элементов в ансамбле последовательностей длины
элементов в ансамбле последовательностей длины  отсюда
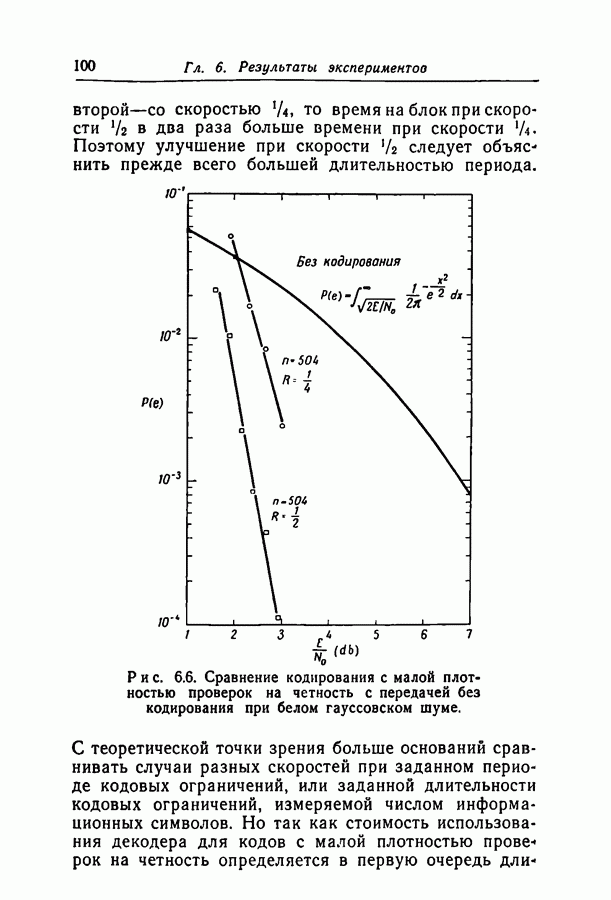
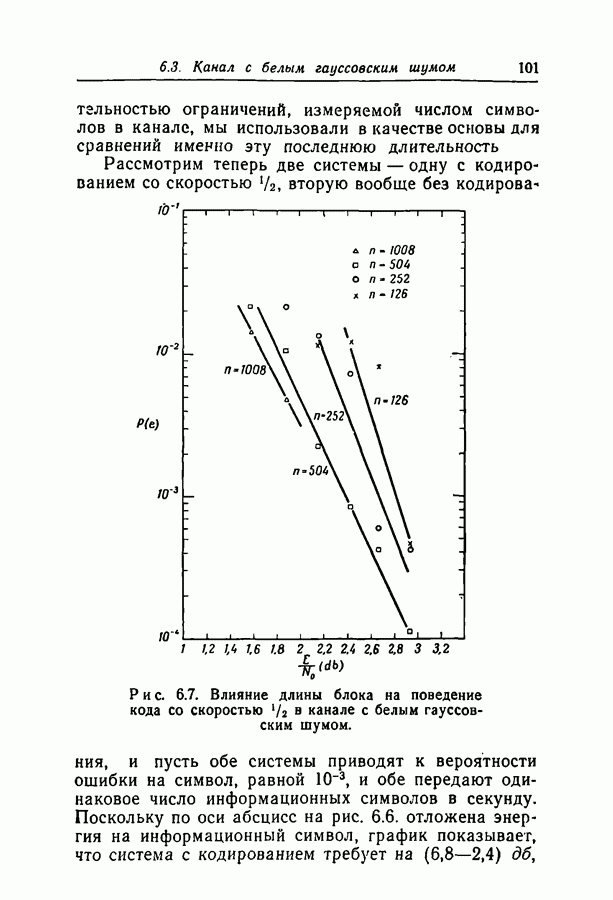
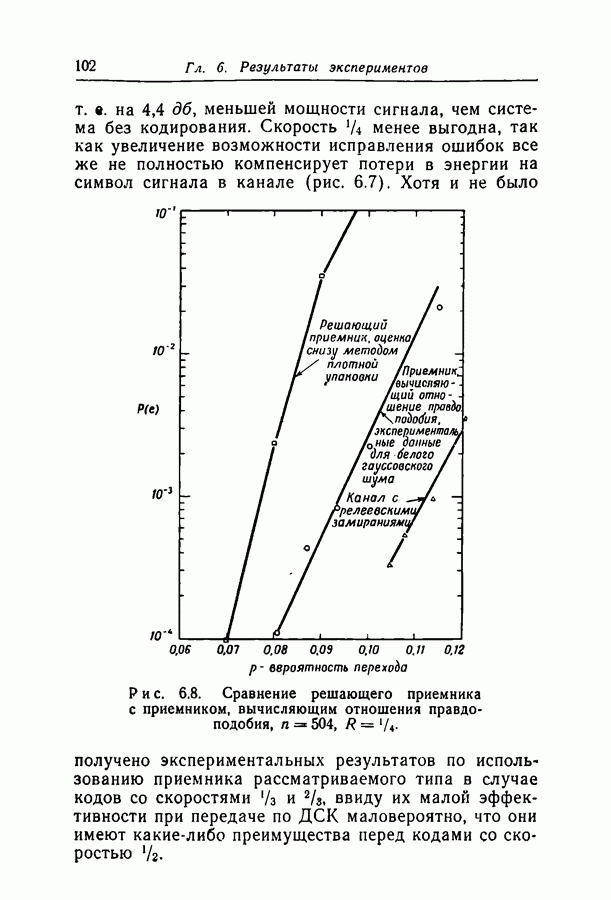
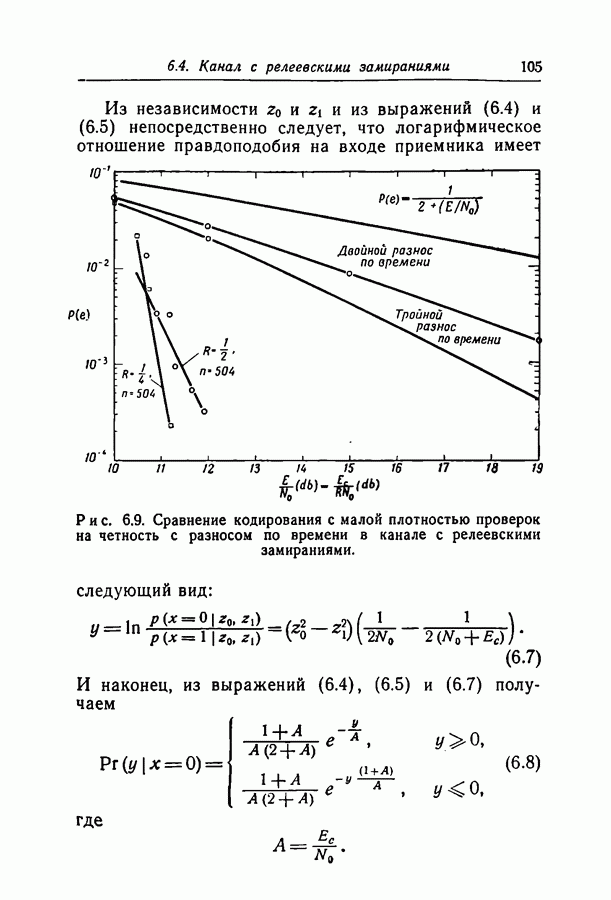
отсюда

 в неравенство (2.14). Это даст нам неравенство (2.8), доказывающее теорему. Ч.Т.Д.
в неравенство (2.14). Это даст нам неравенство (2.8), доказывающее теорему. Ч.Т.Д.
 мы действительно минимизируем экспоненту, получая таким образом оптимальную оценку; теорема, однако, верна безотносительно к минимальности экспоненты. Можно показать (хотя в этом нет необходимости при нашем доказательстве), используя «перекошенные» распределения [4] и центральную предельную теорему [7], что при больших
мы действительно минимизируем экспоненту, получая таким образом оптимальную оценку; теорема, однако, верна безотносительно к минимальности экспоненты. Можно показать (хотя в этом нет необходимости при нашем доказательстве), используя «перекошенные» распределения [4] и центральную предельную теорему [7], что при больших  справедливо асимптотическое равенство
справедливо асимптотическое равенство

 множества
множества
 не зависит от конкретного вида такой последовательности.
не зависит от конкретного вида такой последовательности.
 проверочных соотношений, равна
проверочных соотношений, равна  Поскольку все
Поскольку все  блоков проверочных соотношений выбраны независимо, то
блоков проверочных соотношений выбраны независимо, то

 свойства расстояния и функцию распределения минимального расстояния, так же как это было сделано для ансамбля всех кодов с проверками на четность в соотношениях (2.1) и (2.5):
свойства расстояния и функцию распределения минимального расстояния, так же как это было сделано для ансамбля всех кодов с проверками на четность в соотношениях (2.1) и (2.5):




 суммы в неравенствах (2.19) и (2.22) определяются главным образом поведением
суммы в неравенствах (2.19) и (2.22) определяются главным образом поведением  функция появляется также в следующей главе в оценках вероятности ошибки декодирования.
функция появляется также в следующей главе в оценках вероятности ошибки декодирования.


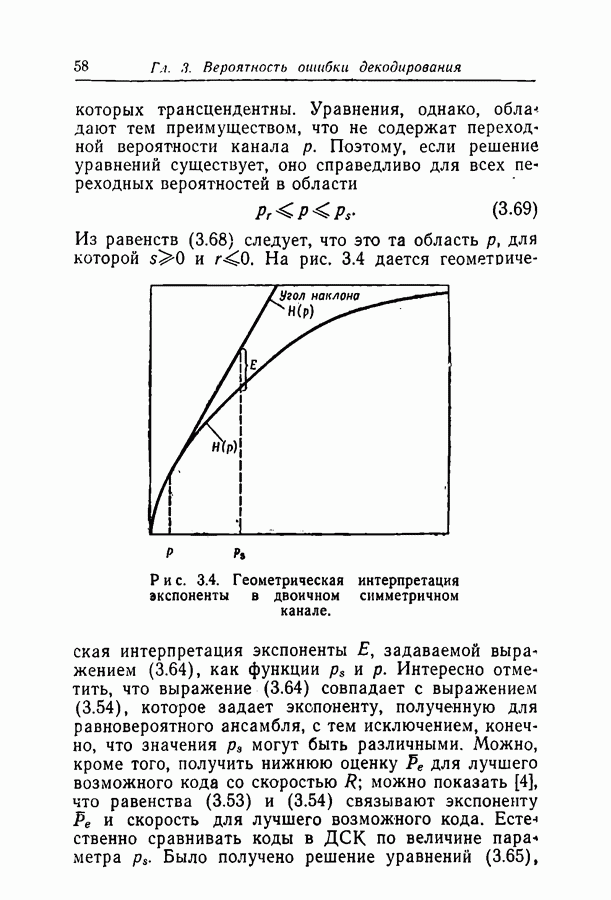
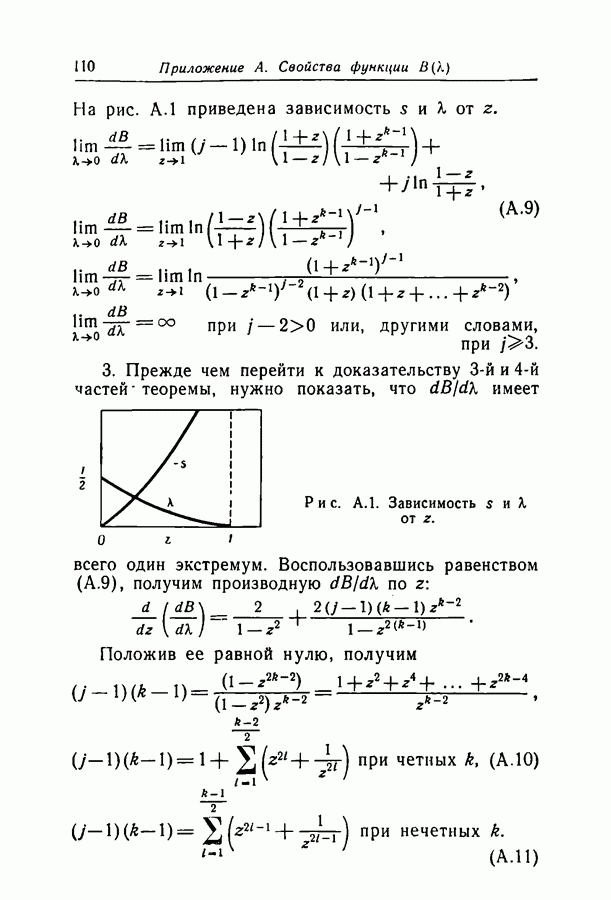
 нелегко, поскольку эта величина выражается через параметр
нелегко, поскольку эта величина выражается через параметр  в свою оче редь неявно зависящий от
в свою оче редь неявно зависящий от  . В приложении А показано, что
. В приложении А показано, что  для 3 ведет себя так, как показано на рис. 2.3. Она равна 0 при
для 3 ведет себя так, как показано на рис. 2.3. Она равна 0 при  затем растет, причем производная в нуле бесконечна, достигает максимума, затем убывает, пересекает ось абсцисс при некотором
затем растет, причем производная в нуле бесконечна, достигает максимума, затем убывает, пересекает ось абсцисс при некотором  и остается отрицательной при
и остается отрицательной при 
 сумма в неравенстве (2.22) не ограничена, однако функцию распределения минимального расстояния все же можно оценить сверху единицей. При
сумма в неравенстве (2.22) не ограничена, однако функцию распределения минимального расстояния все же можно оценить сверху единицей. При  наибольшие слагаемые имеют индексы к, близкие к 0 и к
наибольшие слагаемые имеют индексы к, близкие к 0 и к  четко сформулировано в следующей теореме, доказательство кото» рой приводится в приложении А.
четко сформулировано в следующей теореме, доказательство кото» рой приводится в приложении А.
 -ансамбле кодов функция распределения минимального расстояния оценивается следующими двумя неравенствами:
-ансамбле кодов функция распределения минимального расстояния оценивается следующими двумя неравенствами:


 определяются равенствами (2.20) и (2.21),
определяются равенствами (2.20) и (2.21),  -функция, убывающая с ростом
-функция, убывающая с ростом  быстрее, чем
быстрее, чем 
 такая оценка функции распределения минимального расстояния сходится к ступенчатой функции с небольшим скачком при
такая оценка функции распределения минимального расстояния сходится к ступенчатой функции с небольшим скачком при  и большим скачком при
и большим скачком при  причем величина меньшего скачка убывает как
причем величина меньшего скачка убывает как 
 -ансамбле. При больших
-ансамбле. При больших  подавляющая часть кодов в ансамбле имеет минимальное расстояние, либо близкое к
подавляющая часть кодов в ансамбле имеет минимальное расстояние, либо близкое к  либо большее; поскольку
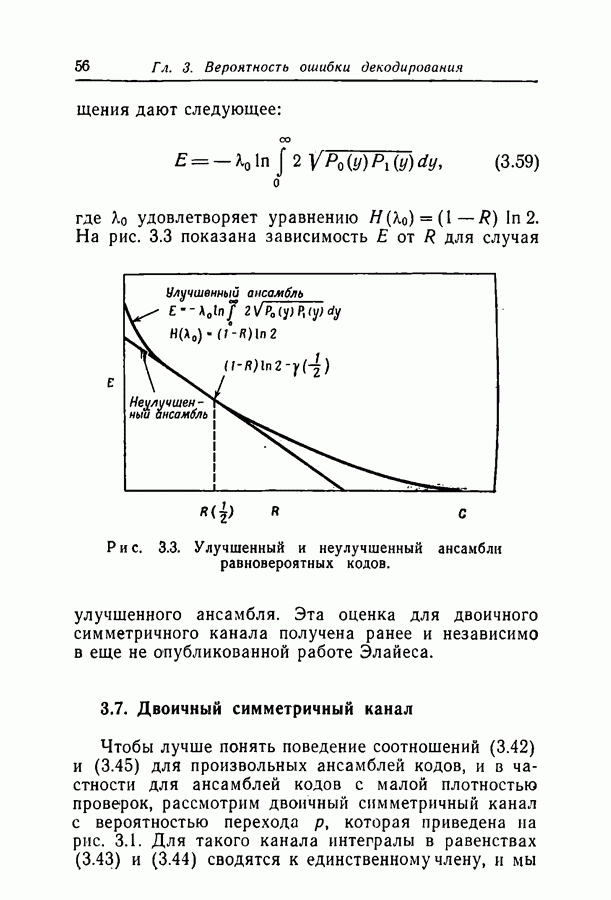
либо большее; поскольку  не зависит от длины блока, минимальное расстояние, характерное для большинства кодов ансамбля, растет линейно с ростом длины блока. На рис. 2.4 приведена зависимость
не зависит от длины блока, минимальное расстояние, характерное для большинства кодов ансамбля, растет линейно с ростом длины блока. На рис. 2.4 приведена зависимость  от скорости для некоторых значений
от скорости для некоторых значений  и эта величина сравнивается с коэффициентом минимального расстояния для ансамбля равновероятных кодов. Можно заметить, что с ростом
и эта величина сравнивается с коэффициентом минимального расстояния для ансамбля равновероятных кодов. Можно заметить, что с ростом  для
для  -кодов
-кодов  быстро приближается к
быстро приближается к  ансамбля равновероятных кодов. Это доказывается в теореме
ансамбля равновероятных кодов. Это доказывается в теореме  приложения А.
приложения А.
 пропорциональна
пропорциональна  иначе говоря, пропорциональна вероятности кода с минимальным расстоянием 2.
иначе говоря, пропорциональна вероятности кода с минимальным расстоянием 2.

 -кода большой длины.
-кода большой длины.
 -ансамбль для того, чтобы определить вероятность ошибки типичного
-ансамбль для того, чтобы определить вероятность ошибки типичного  -кода с минимальным расстоянием порядка
-кода с минимальным расстоянием порядка  Удалим из
Удалим из  -ансамбля половину кодов с наименьшим минимальным расстоянием и удвоим вероятность каждого из оставшихся кодов. Полученный ансамбль будем называть улучшенным ансамблем;
-ансамбля половину кодов с наименьшим минимальным расстоянием и удвоим вероятность каждого из оставшихся кодов. Полученный ансамбль будем называть улучшенным ансамблем;

 есть минимальное расстояние в улучшенном ансамбле. Тогда
есть минимальное расстояние в улучшенном ансамбле. Тогда  оценивается снизу тем значением 6, при котором правая часть неравенства (2.23) равна половине. С ростом
оценивается снизу тем значением 6, при котором правая часть неравенства (2.23) равна половине. С ростом  оценка, даваемая неравенством (2.23), сходится к функции со скачком при
оценка, даваемая неравенством (2.23), сходится к функции со скачком при  таким образом,
таким образом,  асимптотически оценивается с помощью
асимптотически оценивается с помощью  Мы имеем поэтому для улучшенного ансамбля кодов с малой плотностью следующую оценку:
Мы имеем поэтому для улучшенного ансамбля кодов с малой плотностью следующую оценку:


 удовлетворяет уравнению
удовлетворяет уравнению  достаточно велико, так что выполняется неравенство
достаточно велико, так что выполняется неравенство

 соответствующий ансамблям, в которых каждый символ входит в точности в два проверочных множества.
соответствующий ансамблям, в которых каждый символ входит в точности в два проверочных множества.
 каждый символ входит в точности в два проверочных множества и каждое проверочное множество содержит
каждый символ входит в точности в два проверочных множества и каждое проверочное множество содержит  символов. Тогда
символов. Тогда
 оценивается следующим образом:,
оценивается следующим образом:,


 ветвями, выходящими из
ветвями, выходящими из  яруса, не будет образована петля. Такая петля может появиться либо тогда, когда два проверочных множества, выходящих из
яруса, не будет образована петля. Такая петля может появиться либо тогда, когда два проверочных множества, выходящих из  яруса, содержат общий символ в
яруса, содержат общий символ в  ярусе, как это показано на рис. 2.5, либо когда одно проверочное множество, выходящее из
ярусе, как это показано на рис. 2.5, либо когда одно проверочное множество, выходящее из  яруса, содержит более одного символа в
яруса, содержит более одного символа в  ярусе.
ярусе.
 в зависимости от длины блока
в зависимости от длины блока  Первый ярус дерева содержит
Первый ярус дерева содержит  узлов,
узлов,
 узлов, аналогичным образом
узлов, аналогичным образом  ярус содержит
ярус содержит  узлов, так как по предположению ветви ниже
узлов, так как по предположению ветви ниже  яруса не образовывали петель. Поскольку каждому узлу соответствует свой символ,
яруса не образовывали петель. Поскольку каждому узлу соответствует свой символ,

 содержащая единицы в позициях, соответствующих узлам нашего множества, и нули во всех других позициях, должна быть кодовым словом, так как все проверочные множества содержат четное число единиц. И наконец, вес кодового слова
содержащая единицы в позициях, соответствующих узлам нашего множества, и нули во всех других позициях, должна быть кодовым словом, так как все проверочные множества содержат четное число единиц. И наконец, вес кодового слова  соответствующего первой из ветре" тившихся петель, всегда оценивается следующим образом:
соответствующего первой из ветре" тившихся петель, всегда оценивается следующим образом:
