Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
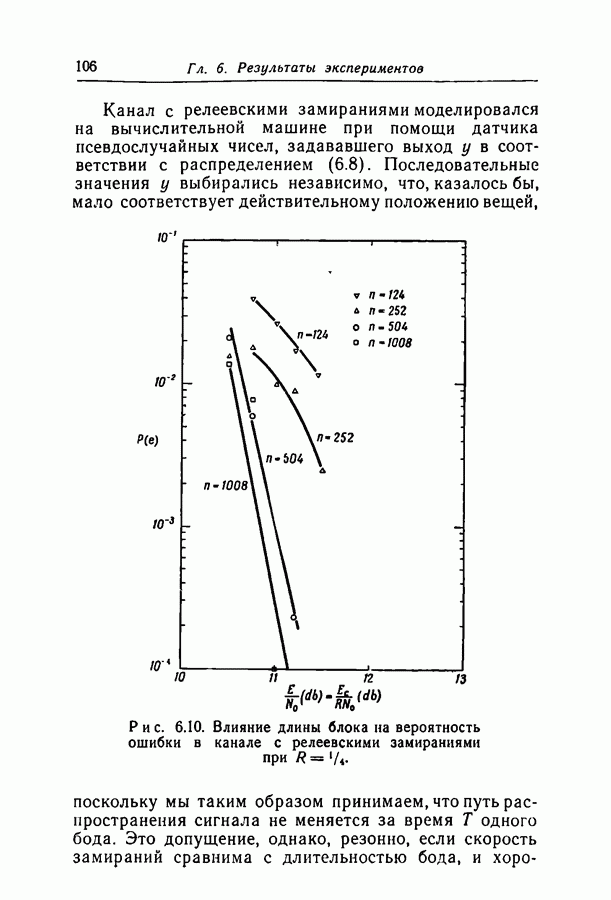
Глава 6. РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТОВВероятность ошибки декодирования Ввиду ограниченности машинного времени все приведенные здесь результаты относятся к случаям больших 6.1. Моделирование кодаВсе результаты этой главы получены для кодов с малой плотностью проверок на четность, моделированных на вычислительной машине ИБМ-7090 псевдослучайным методом. Говоря более конкретно, проверочные матрицы выбирались так же, как строился в гл. 2 ансамбль матриц с малой плотностью проверок. Первая подматрица из Коды, построенные таким способом, запоминались вычислительной машиной и использовались при декодировании шумовых последовательностей, имитирующих двоичный симметричный канал, канал с белым гауссовским шумом и канал с релеевскими замираниями. Для сокращения времени вычислений было принято, что передается кодовое слово, целиком состоящее из нулей. Это допустимо, поскольку в гл. 3 было показано, что вероятность ошибки декодирования при передаче по симметричному каналу с двоичным входом не зависит от передаваемого слова. Такое упрощение, конечно, требует особенно тщательной проверки полной симметрии положительных и отрицательных выходов при моделировании декодирования.
|
 |
Оглавление
|























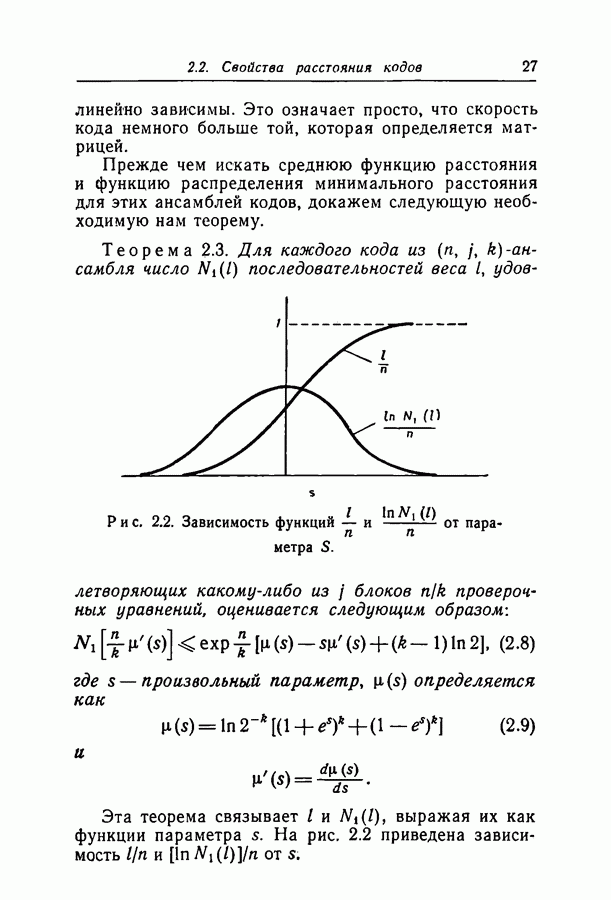



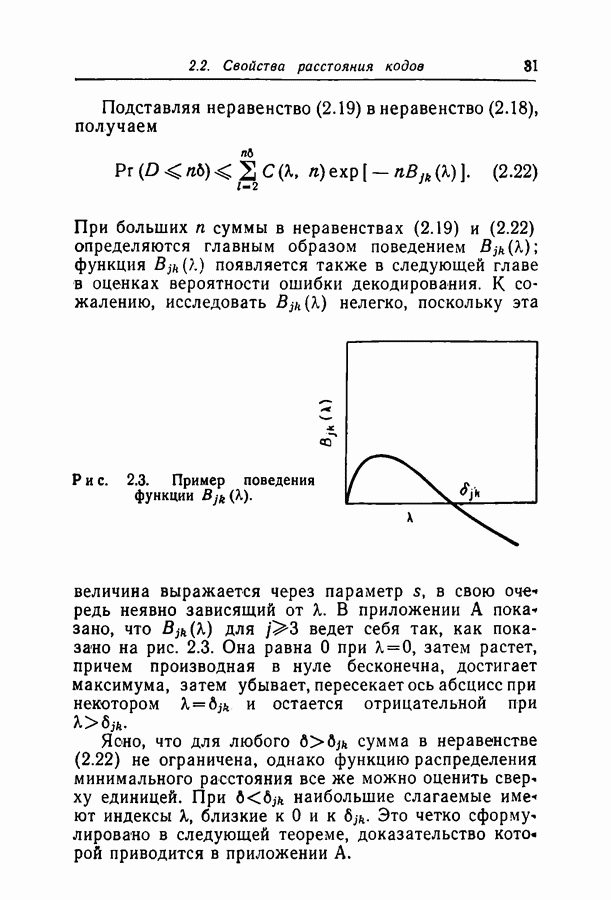

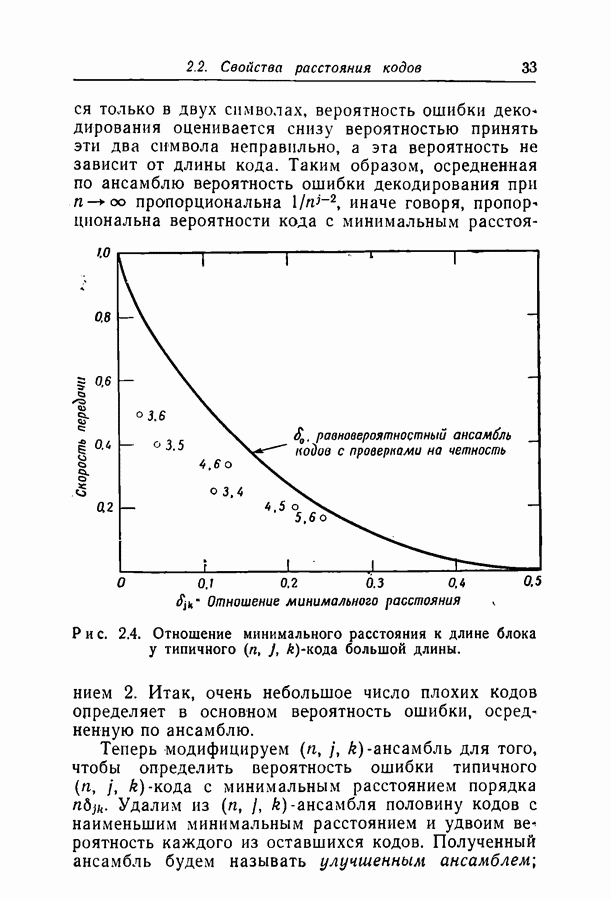





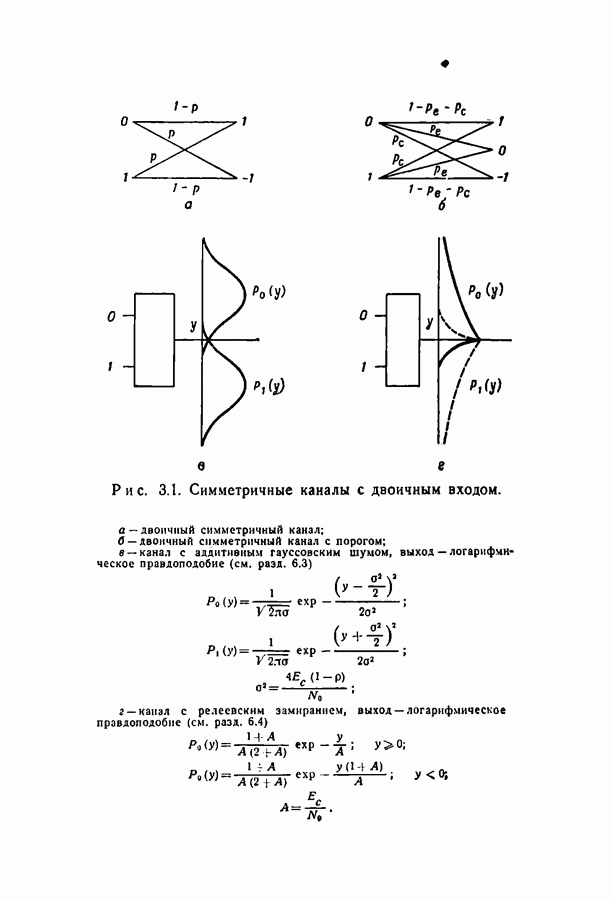













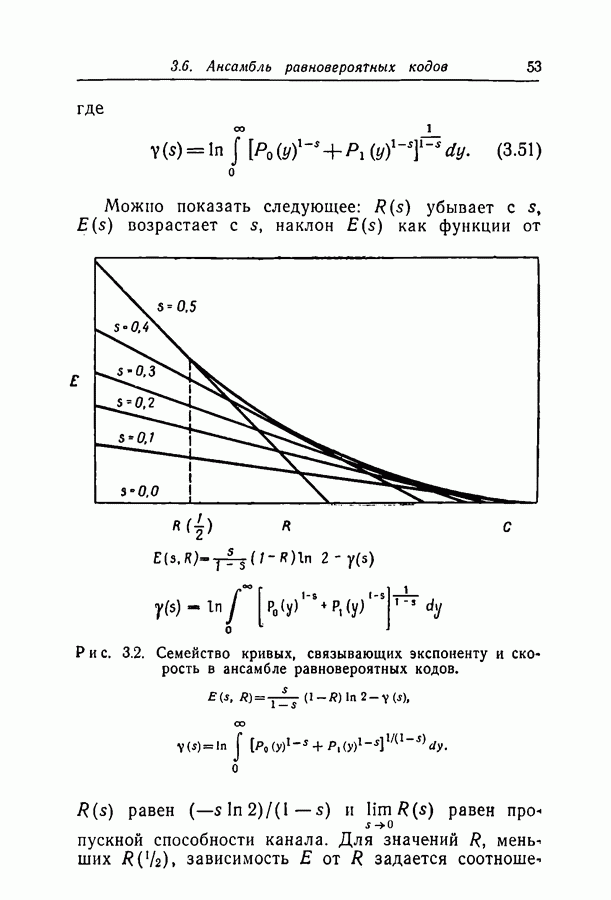


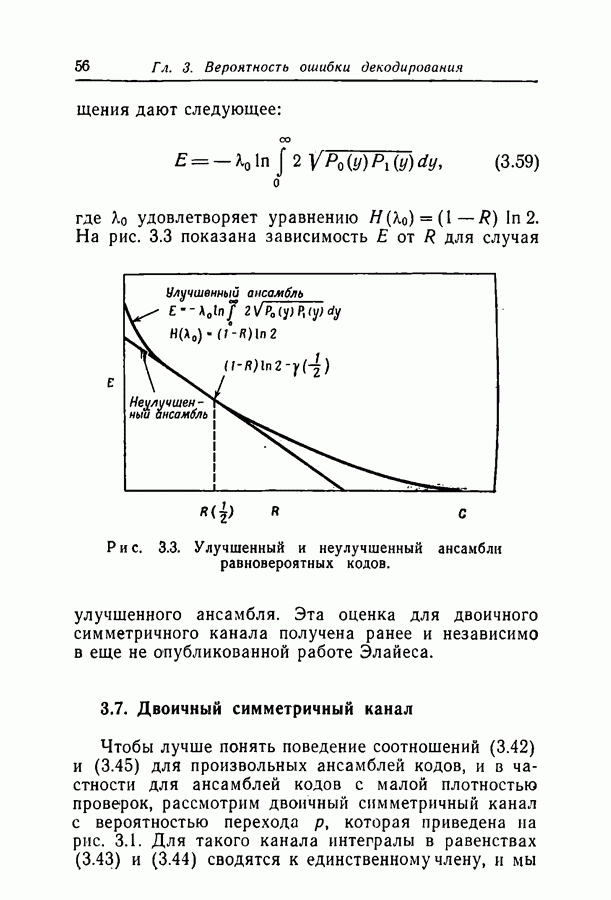

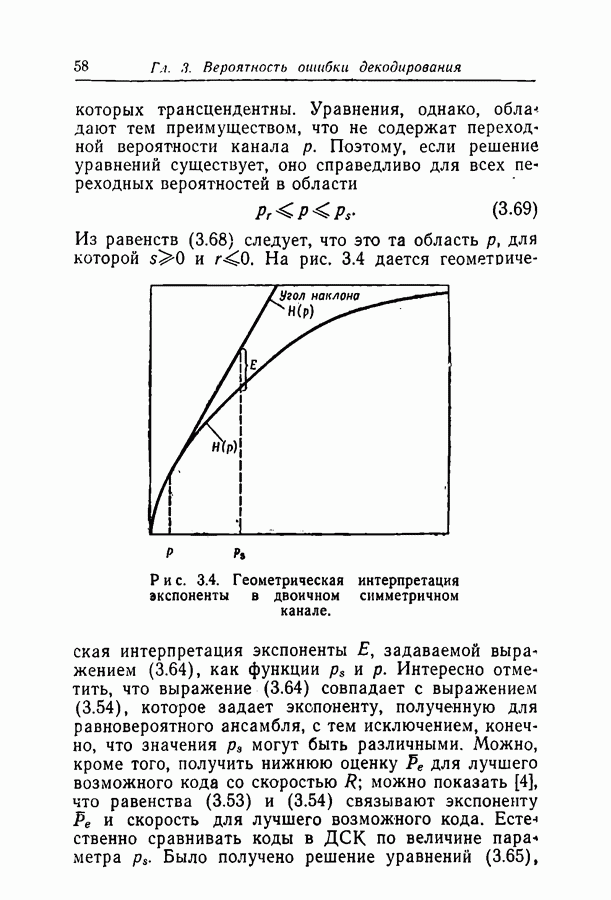
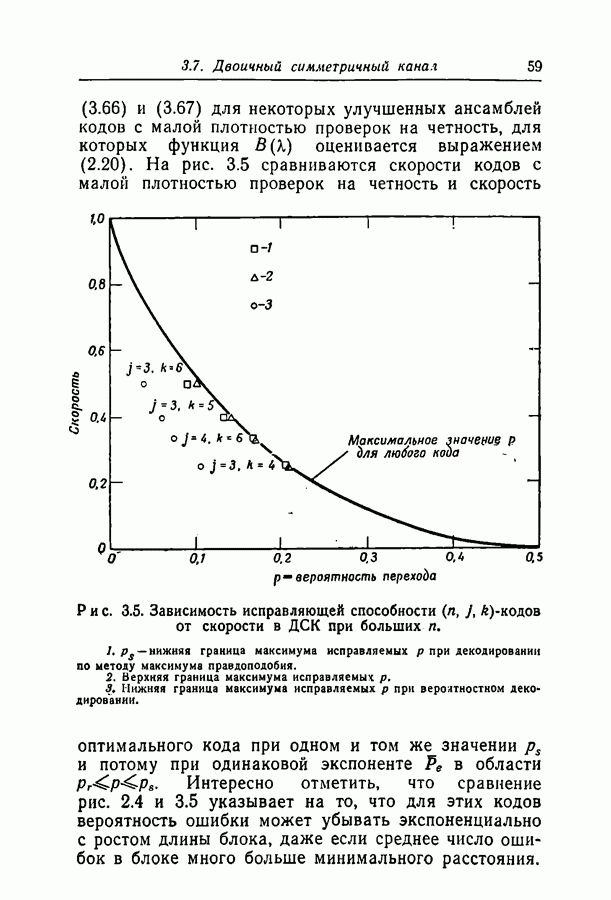















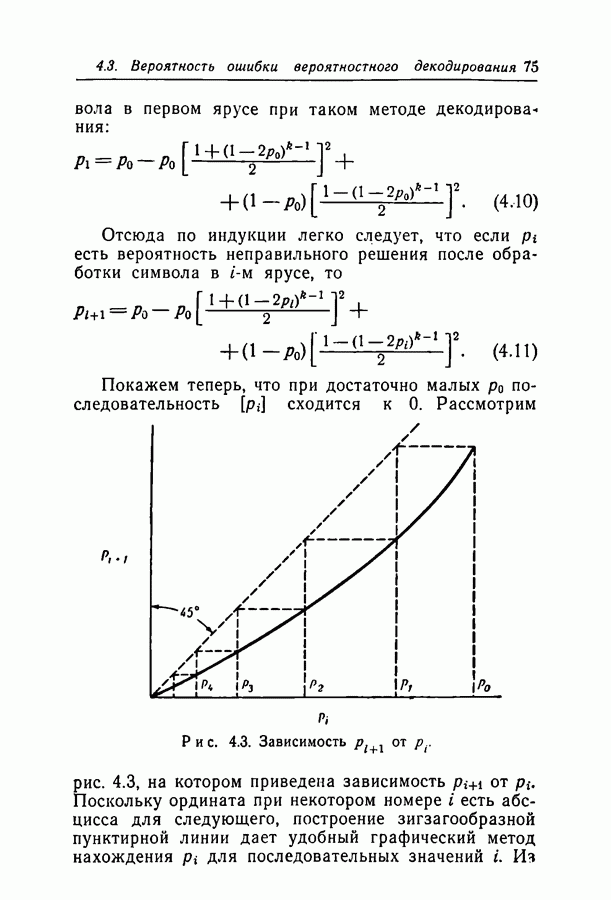



















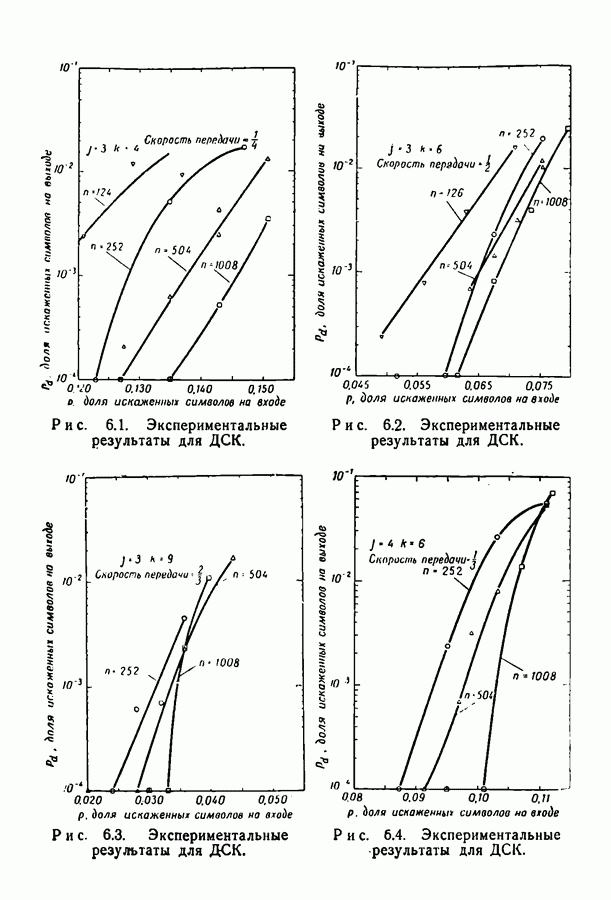
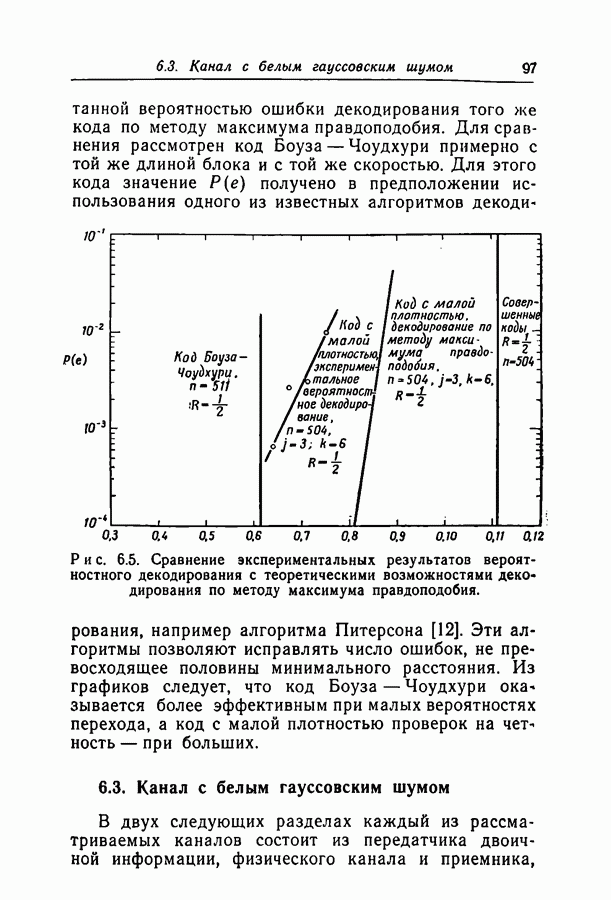


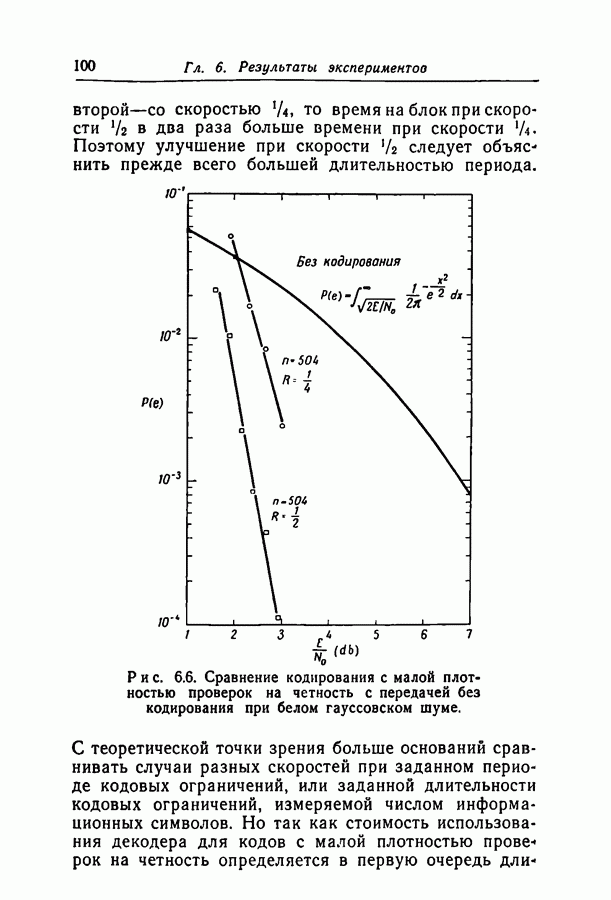
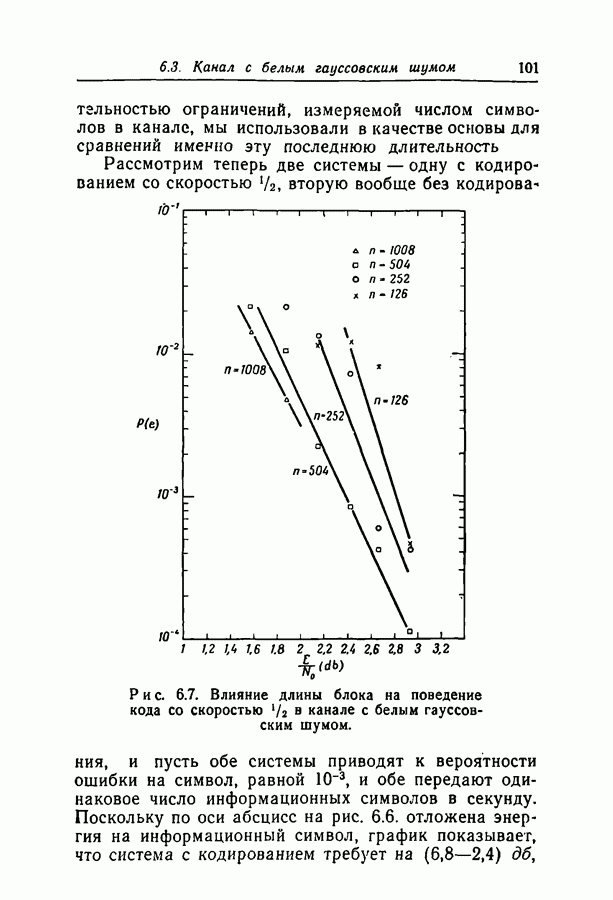
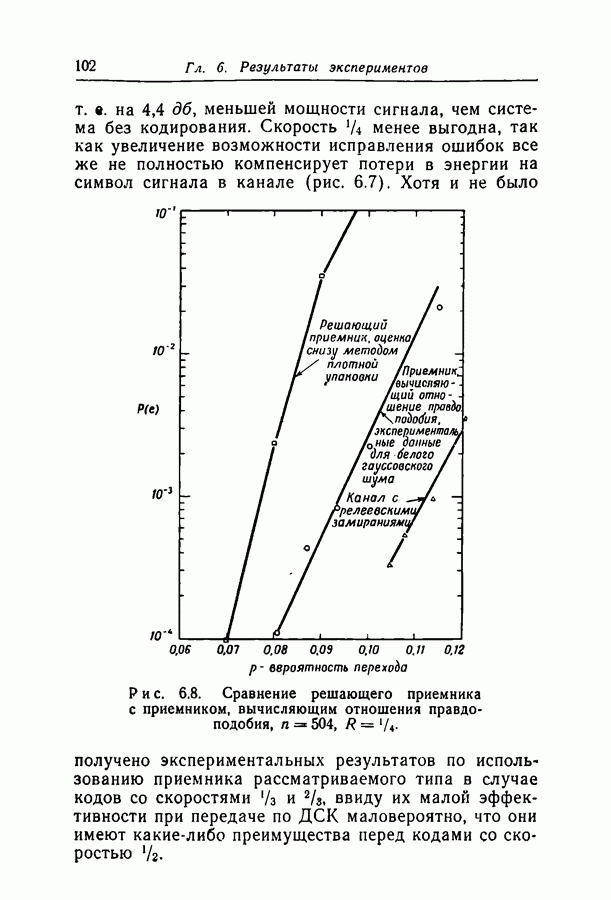


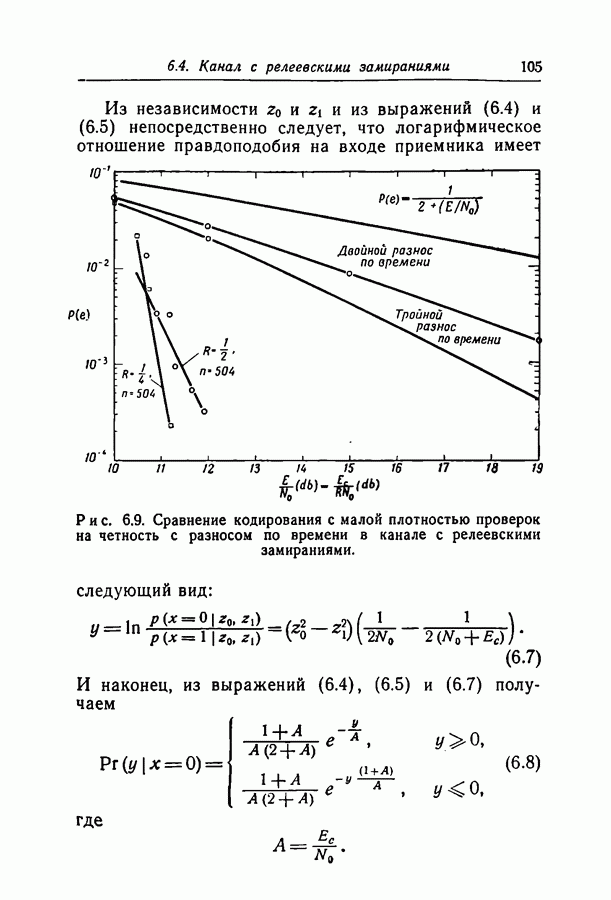


































 при некотором методе кодирования и декодирования можно измерить непосредственно, моделируя рассматриваемые канал и схему на вычислительной машине. К сожалению, для более или менее точной оценки значения
при некотором методе кодирования и декодирования можно измерить непосредственно, моделируя рассматриваемые канал и схему на вычислительной машине. К сожалению, для более или менее точной оценки значения  необходимо получить довольно большое число случаев неправильного декодирования, поэтому число повторений эксперимента должно быть много больше
необходимо получить довольно большое число случаев неправильного декодирования, поэтому число повторений эксперимента должно быть много больше  При длине блока около 500 вычислительная машина ИБМ-7090 затрачивает примерно 0,1 сек на итерацию при декодировании блока согласно вероятностной схеме декодирования. Следовательно, для оценки вероятности
При длине блока около 500 вычислительная машина ИБМ-7090 затрачивает примерно 0,1 сек на итерацию при декодировании блока согласно вероятностной схеме декодирования. Следовательно, для оценки вероятности  даже имеющей порядок 10-4, потребуются многие часы машинного времени.
даже имеющей порядок 10-4, потребуются многие часы машинного времени.
 Безусловно, интереснее оказались бы результаты для малых значений
Безусловно, интереснее оказались бы результаты для малых значений  Однако приведенные ниже данные можно, по-видимому, с некоторой долей уверенности экстраполировать на случаи, когда
Однако приведенные ниже данные можно, по-видимому, с некоторой долей уверенности экстраполировать на случаи, когда  имеет порядок
имеет порядок  или
или  Кроме того, даже приведенные здесь весьма ограниченные результаты дают некоторую информацию о поведении
Кроме того, даже приведенные здесь весьма ограниченные результаты дают некоторую информацию о поведении  при изменении таких параметров, как длина блока, скорость кода и тип канала.
при изменении таких параметров, как длина блока, скорость кода и тип канала.
 проверочных множеств содержала по
проверочных множеств содержала по  символов, расположенных в ступенчатом порядке, и каждая из последующих подматриц строилась случайной перестановкой столбцов первой. Случайные перестановки выполнялись обычным получением псевдослучайных чисел, результаты затем изменялись так, чтобы никакие два проверочных множества не содержали больше одного общего символа. Такая модификация случайного выбора гарантирует выполнение введенных выше предположений для первой итерации, а также исключает маловероятную возможность выбрать код с минимальным расстоянием 2.
символов, расположенных в ступенчатом порядке, и каждая из последующих подматриц строилась случайной перестановкой столбцов первой. Случайные перестановки выполнялись обычным получением псевдослучайных чисел, результаты затем изменялись так, чтобы никакие два проверочных множества не содержали больше одного общего символа. Такая модификация случайного выбора гарантирует выполнение введенных выше предположений для первой итерации, а также исключает маловероятную возможность выбрать код с минимальным расстоянием 2.