Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
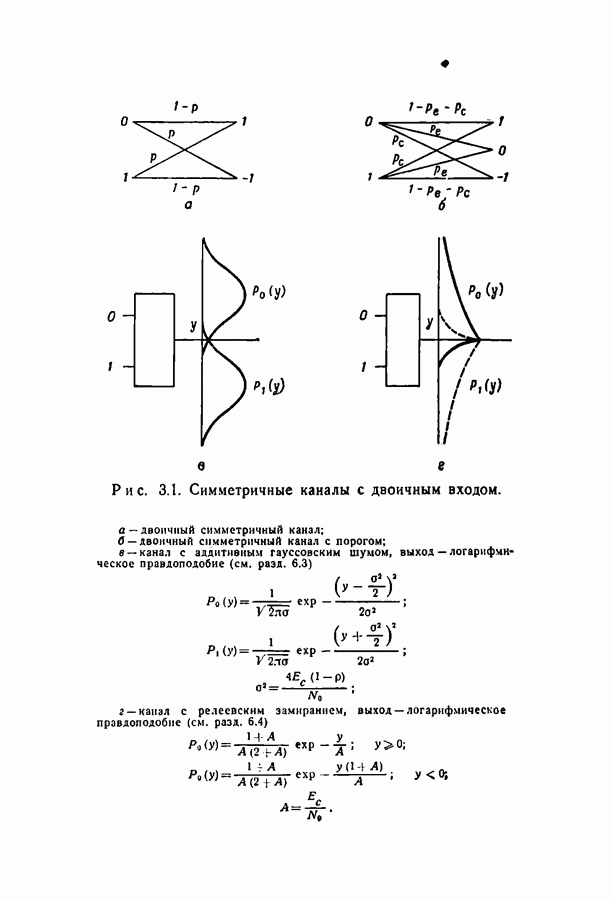
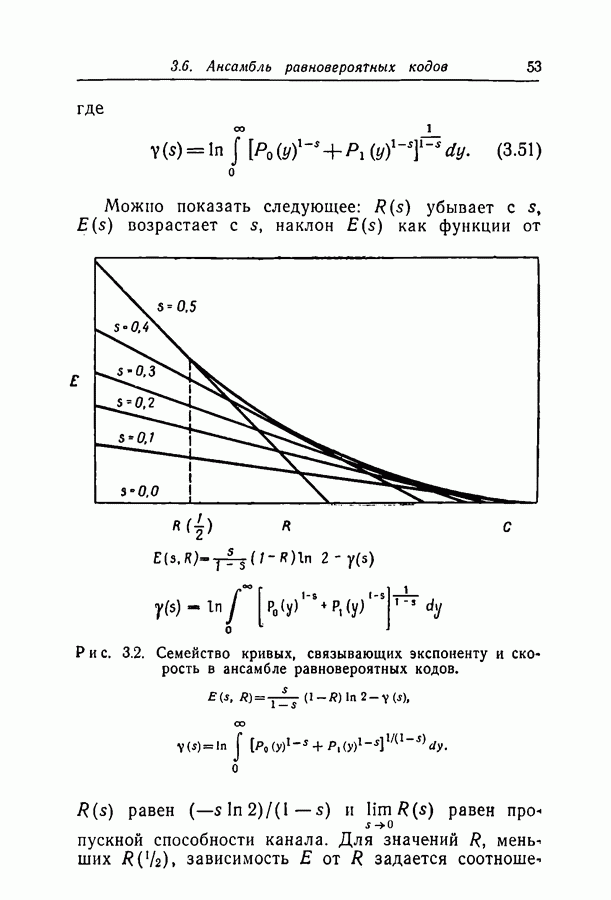
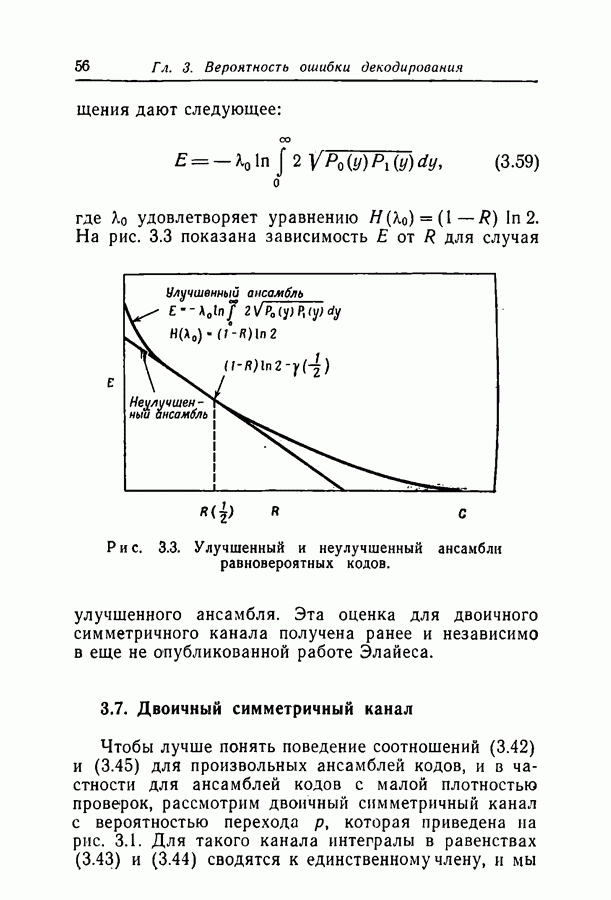
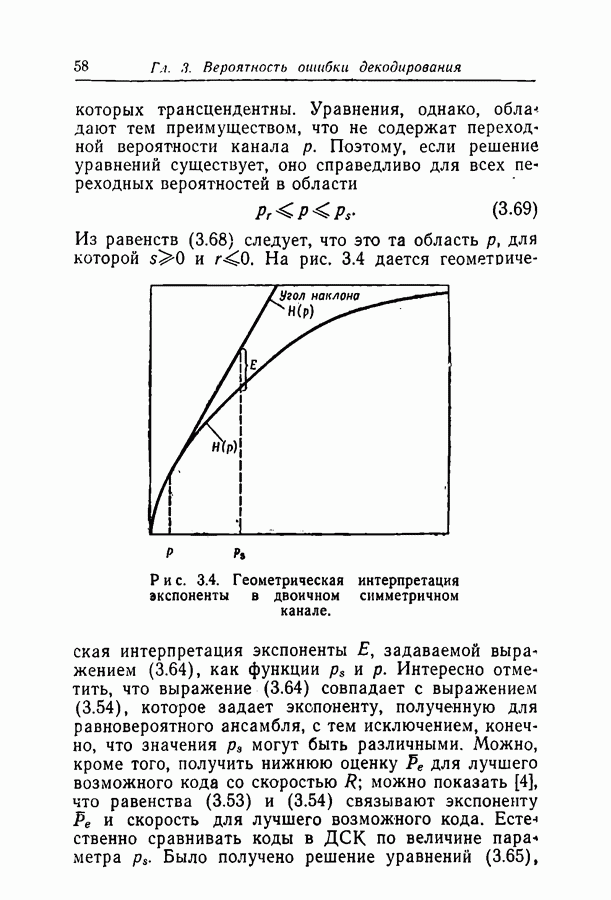
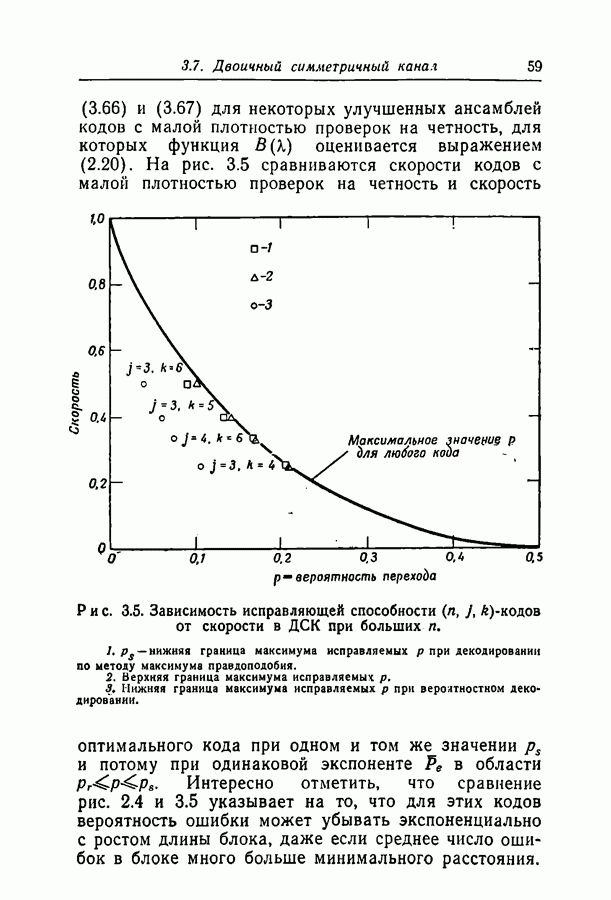
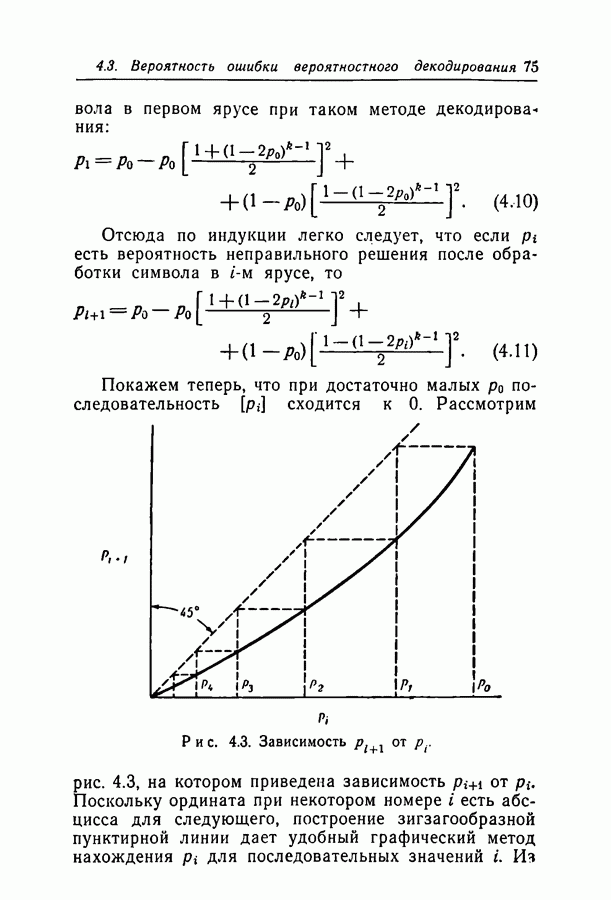
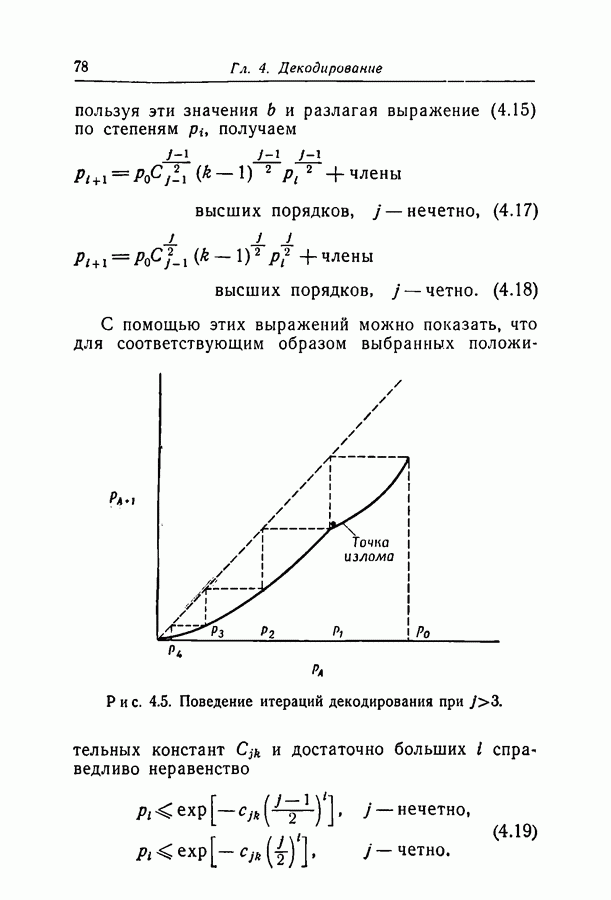
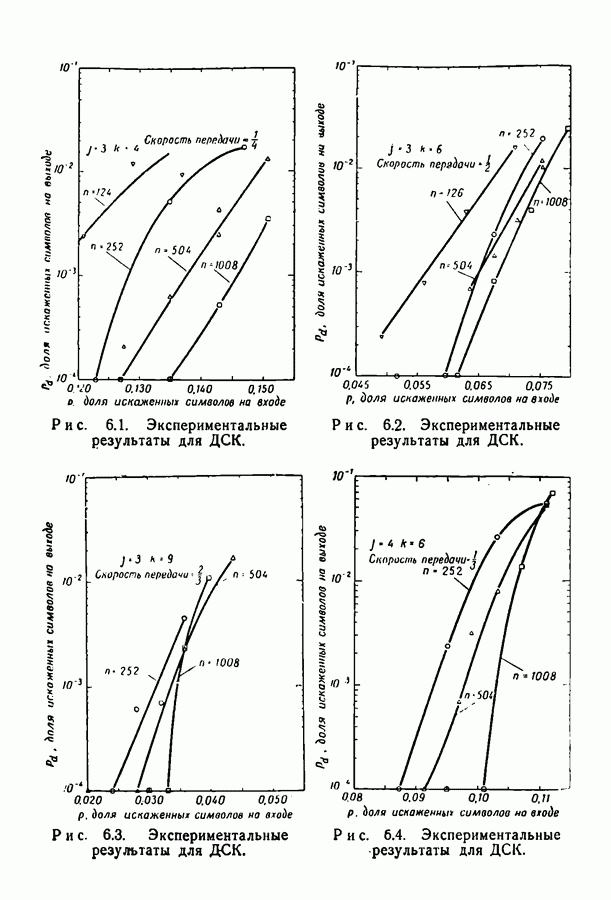
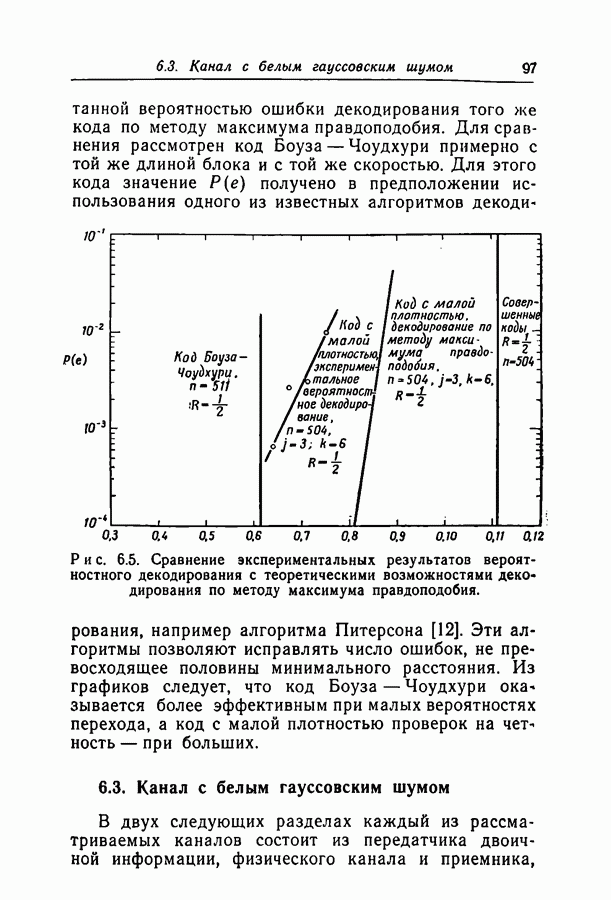
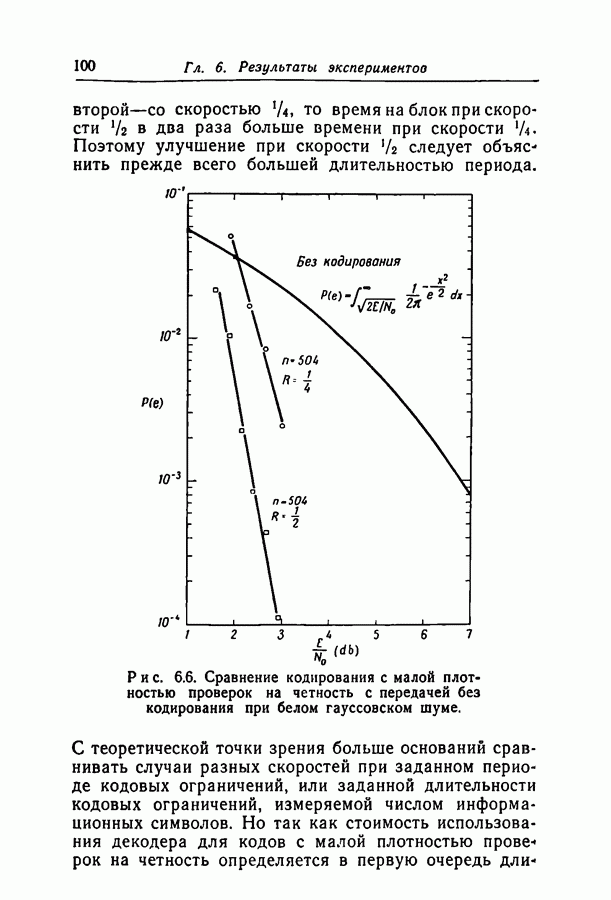
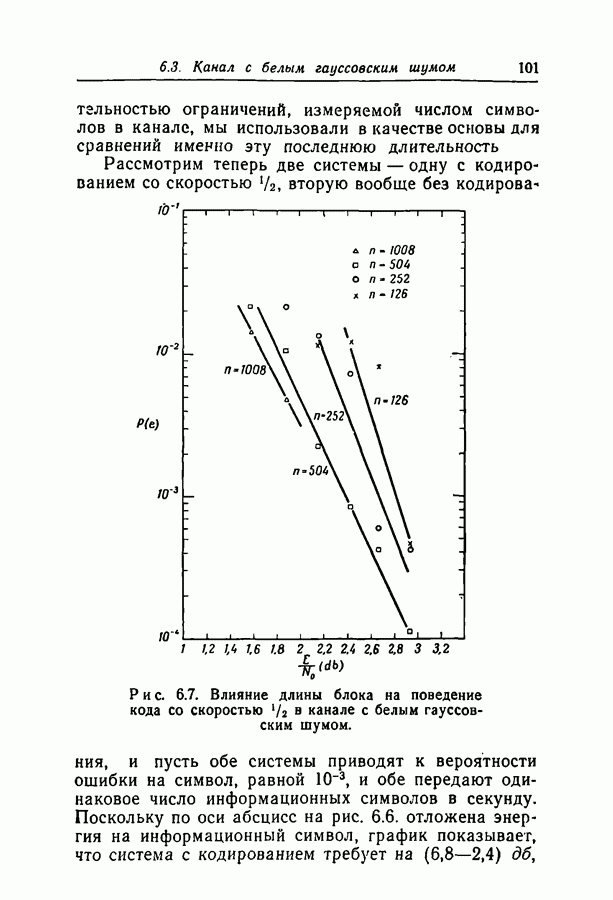
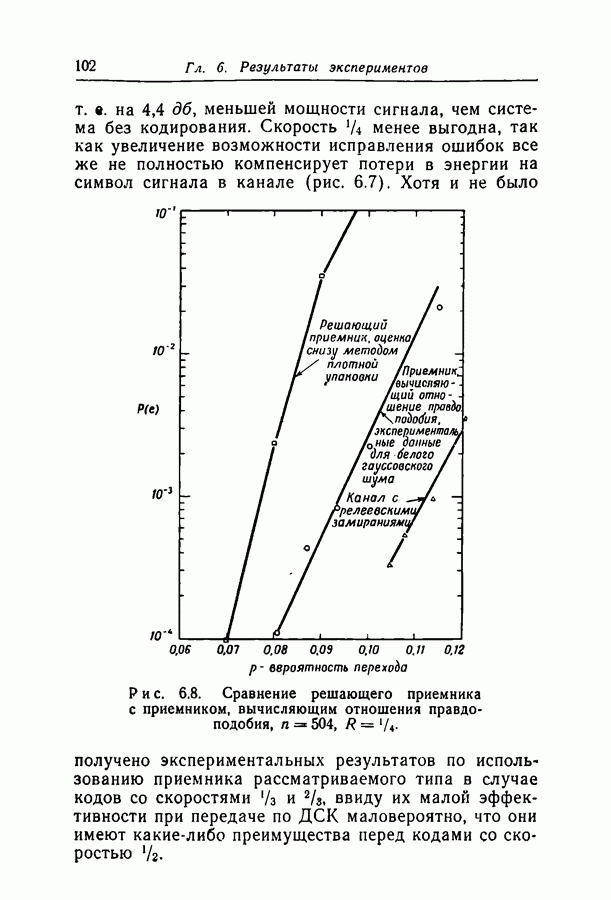
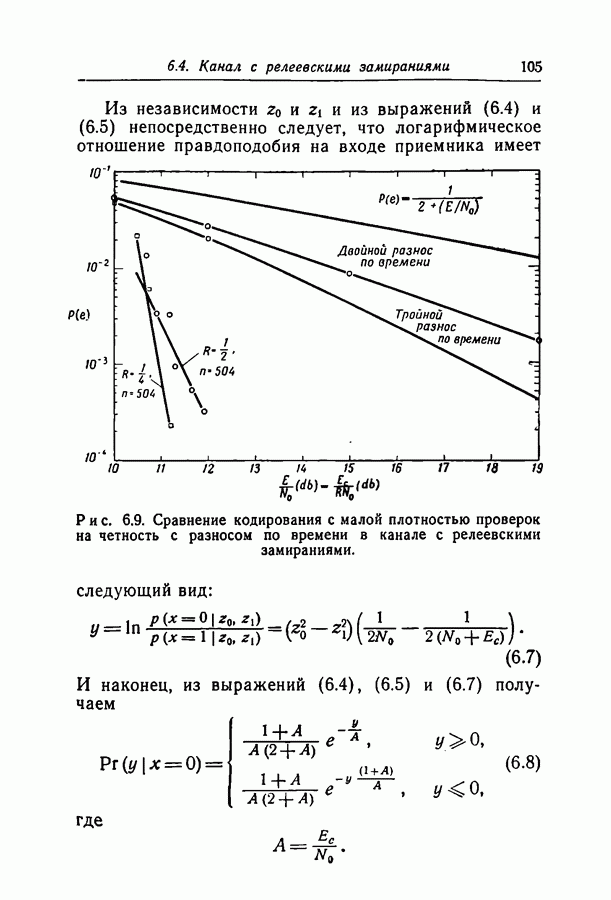
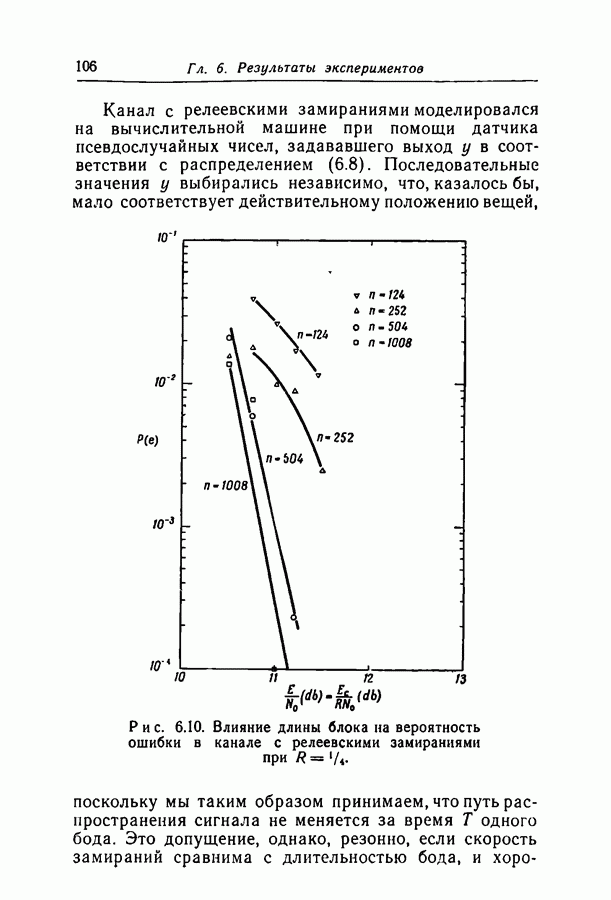
6.2. Двоичный симметричный каналТочное моделирование двоичного симметричного канала (ДСК) состоит в выборе последовательности случайных ошибок, в которой переходы (т. е. ошибки, представляемые перекрещивающимися линиями перехода на рис. 3.1, в) возникают независимо и с фиксированной вероятностью сильно зависят от с — числа переходов, происшедших в процессе моделирования. Поскольку с подчиняется известному (биномиальному) распределению, можно при фиксированном с экспериментально оценить вероятность ошибки декодирования, а затем по этим данным вычислить На рис. 6.1-6.4 приведены результаты, полученные таким способом. По оси абсцисс на каждом из графиков отложено Медиана числа блоков с отказами декодирования для точек, отложенных на графиках рис. На рис. 6.5 сравниваются экспериментальные результаты, полученные при вероятностном декодировании кода с
(кликните для просмотра скана) рассчитанной вероятностью ошибки декодирования того же кода по методу максимума правдоподобия. Для сравнения рассмотрен код Боуза — Чоудхури примерно с той же длиной блока и с той же скоростью. Рис. 6.5. (см. скан) Сравнение экспериментальных результатов вероятностного декодирования с теоретическими возможностями декодирования по методу максимума правдоподобия. Для этого кода значение
|
 |
Оглавление
|























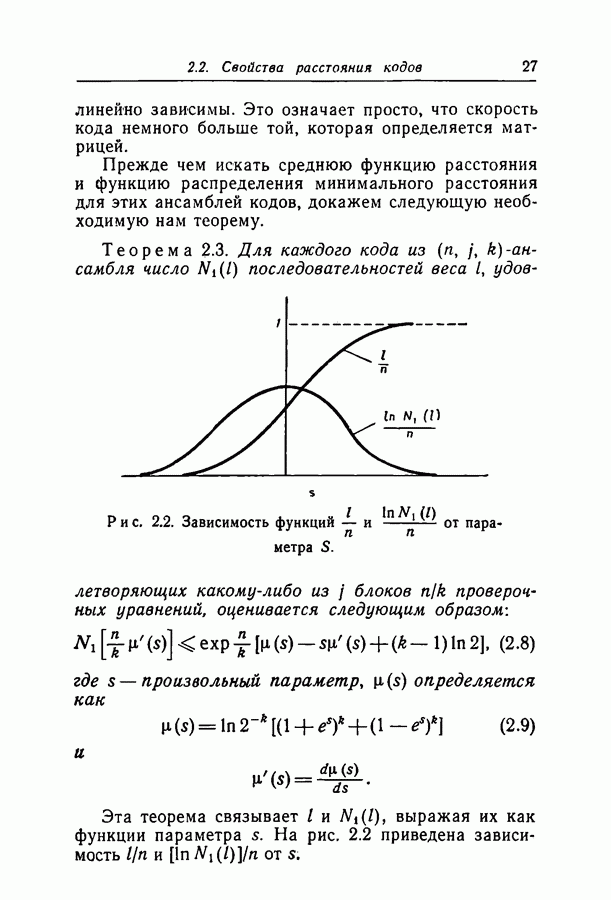

































































































 Возможности декодирования такой последовательности при использовании вероятностного метода с конкретным кодом очень
Возможности декодирования такой последовательности при использовании вероятностного метода с конкретным кодом очень
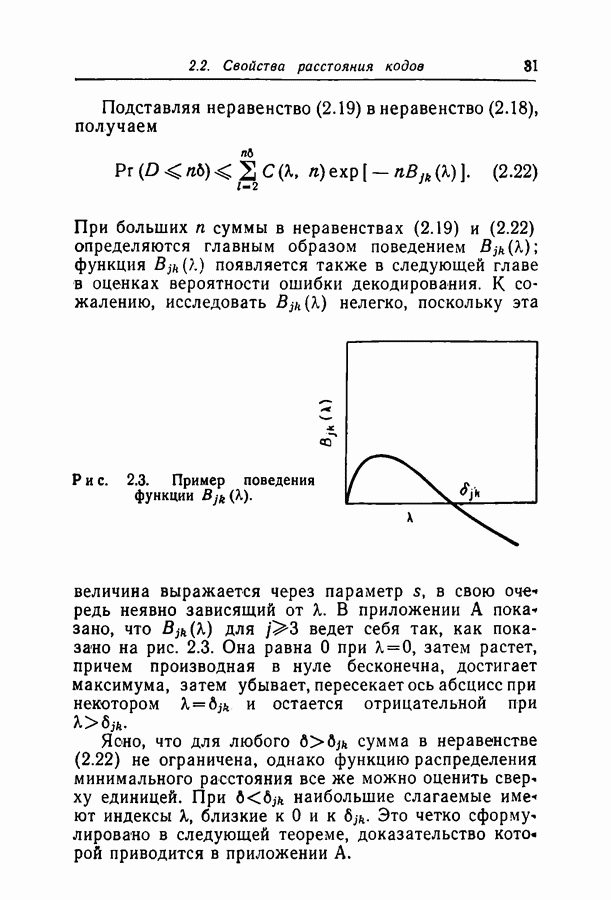
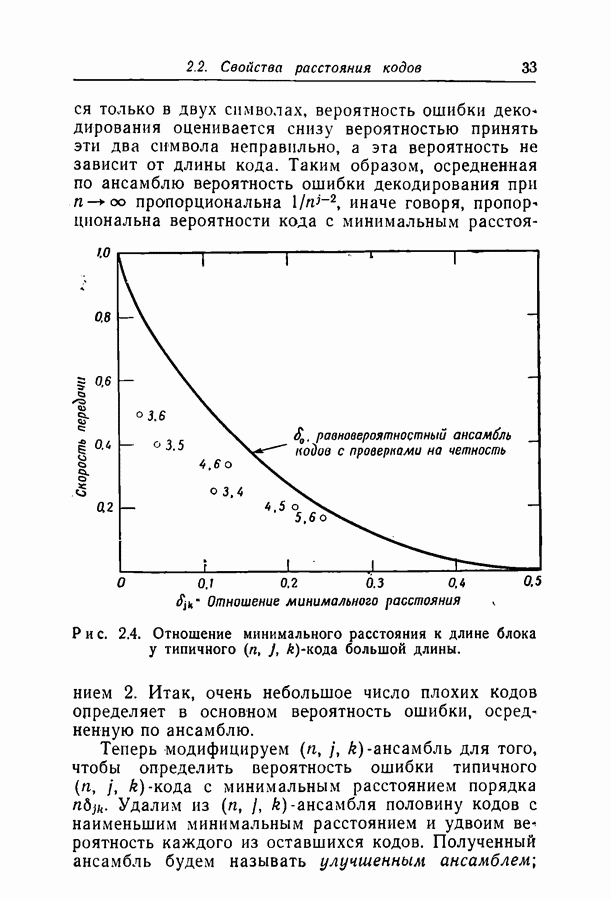
 для ДСК. Преимущества последнего приема заключаются в том, что он позволяет получить дополнительные сведения о эффективности метода декодирования и облегчает сравнение с другими методами, рассчитанными на исправление фиксированного числа ошибок.
для ДСК. Преимущества последнего приема заключаются в том, что он позволяет получить дополнительные сведения о эффективности метода декодирования и облегчает сравнение с другими методами, рассчитанными на исправление фиксированного числа ошибок.
 отношение числа переходов к длине блока, а по оси ординат — вероятность ошибки на символ после декодирования. В экспериментах для всех кодов, за исключением кода со скоростью
отношение числа переходов к длине блока, а по оси ординат — вероятность ошибки на символ после декодирования. В экспериментах для всех кодов, за исключением кода со скоростью  и длиной блока 126, декодер просто отказывал; он не выполнял декодирование даже неправильно. Другими словами, вычисляемая декодером апостериорная вероятность не сходилась ни к 1, ни к 0. А это очень важно в любой системе с каналом обратной связи, поскольку недекодированный блок информационных символов может быть переспрошен. Важно также отметить, что приведенные на рис. 6.1 — 6.4 значения
и длиной блока 126, декодер просто отказывал; он не выполнял декодирование даже неправильно. Другими словами, вычисляемая декодером апостериорная вероятность не сходилась ни к 1, ни к 0. А это очень важно в любой системе с каналом обратной связи, поскольку недекодированный блок информационных символов может быть переспрошен. Важно также отметить, что приведенные на рис. 6.1 — 6.4 значения  суть вероятности ошибки на символ, полученные после того, когда сделаны наилучшие возможные предсказания относительно каждого символа в блоках, которые не удалось декодировать. Вероятность неудачи при декодировании блока, как правило, превышает
суть вероятности ошибки на символ, полученные после того, когда сделаны наилучшие возможные предсказания относительно каждого символа в блоках, которые не удалось декодировать. Вероятность неудачи при декодировании блока, как правило, превышает  в 10 раз.
в 10 раз.
 равна 8, значительное число точек, особенно при малых значениях
равна 8, значительное число точек, особенно при малых значениях  оценивалось при отказе только в одном-двух блоках. Поэтому весьма вероятно, что положение отдельных точек при большем объеме данных заметно изменилось бы.
оценивалось при отказе только в одном-двух блоках. Поэтому весьма вероятно, что положение отдельных точек при большем объеме данных заметно изменилось бы.
 с теоретически
с теоретически

 получено в предположении использования одного из известных алгоритмов декодирования, например алгоритма Питерсона [12]. Эти алгоритмы позволяют исправлять число ошибок, не превосходящее половины минимального расстояния. Из графиков следует, что код Боуза-Чоудхури оказывается более эффективным при малых вероятностях перехода, а код с малой плотностью проверок на четность — при больших.
получено в предположении использования одного из известных алгоритмов декодирования, например алгоритма Питерсона [12]. Эти алгоритмы позволяют исправлять число ошибок, не превосходящее половины минимального расстояния. Из графиков следует, что код Боуза-Чоудхури оказывается более эффективным при малых вероятностях перехода, а код с малой плотностью проверок на четность — при больших.