Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
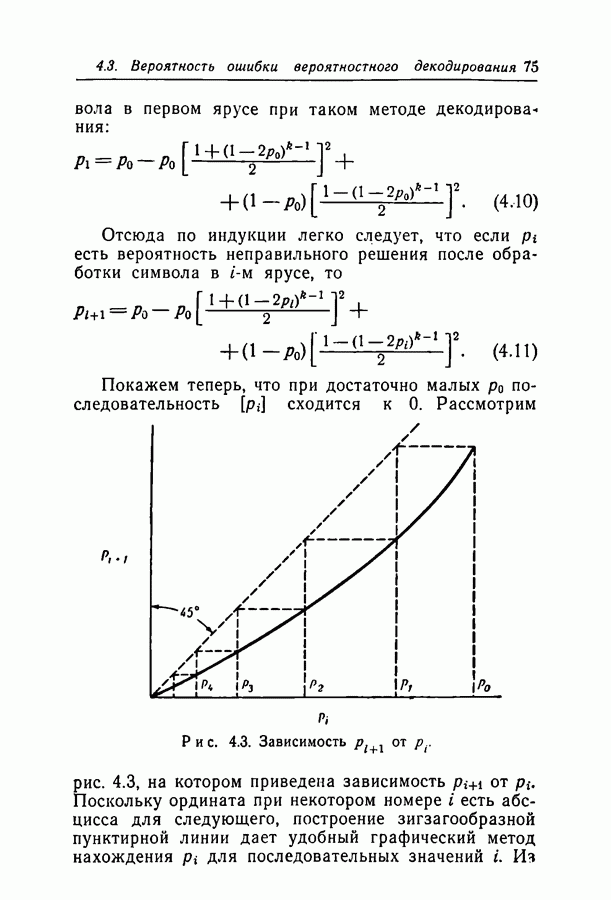
5.4. Вероятность ошибки при вероятностном декодировании
Рассмотрим канал с А входами и выходами, перенумерованными от 0 до  Переходные вероятности канала задаются следующим образом:
Переходные вероятности канала задаются следующим образом:

Рассмотрим дерево проверочных множеств, такое, как приведенное на рис. 4.1, с  независимыми ярусами и
независимыми ярусами и  Модифицируем метод декодирования следующим образом. Если оба проверочных соотношения, содержащие некоторый символ, не удовлетворены и принимают равные значения, изменим символ так, чтобы оба проверочных соотношения удовлетворились; во всех остальных случаях символ изменять не будем. Вероятность ошибки при таком методе служит оценкой сверху для вероятности ошибки при вероятностном декодировании. Вероятность того, что символ первого яруса принят искаженным, а затем исправлен, равна
Модифицируем метод декодирования следующим образом. Если оба проверочных соотношения, содержащие некоторый символ, не удовлетворены и принимают равные значения, изменим символ так, чтобы оба проверочных соотношения удовлетворились; во всех остальных случаях символ изменять не будем. Вероятность ошибки при таком методе служит оценкой сверху для вероятности ошибки при вероятностном декодировании. Вероятность того, что символ первого яруса принят искаженным, а затем исправлен, равна  где
где  есть вероятность того, что в одном из множеств по
есть вероятность того, что в одном из множеств по  символов нет искаженных символов, или сумма искаженных символов по модулю А равна 0. Определим ошибку в символе как
символов нет искаженных символов, или сумма искаженных символов по модулю А равна 0. Определим ошибку в символе как  Покажем теперь, что
Покажем теперь, что

Заметим, что  -преобразование обычной суммы ошибок в
-преобразование обычной суммы ошибок в  символах имеет следующий вид:
символах имеет следующий вид:

Рассмотрим теперь величину

Все степени  этого выражения, не кратные А, взаимно уничтожаются ввиду их равномерного распределения по единичному кругу в комплексной плоскости, коэффициенты при степенях, кратных А, складываются, что и дает выражение для
этого выражения, не кратные А, взаимно уничтожаются ввиду их равномерного распределения по единичному кругу в комплексной плоскости, коэффициенты при степенях, кратных А, складываются, что и дает выражение для 

Теперь, используя равенство (5.33), получаем

И наконец, объединяя равенства (5.36) и (5.34), получаем (5.31). Таким образом, вероятность того, что символ первого яруса принят неправильно, а затем исправлен, равна

Вероятность того, что символ первого яруса принят правильно, но изменен из-за двух одинаково искаженных проверок, равна

В равенстве (5.38) множитель  есть вероятность того, что искаженные символы одного из
есть вероятность того, что искаженные символы одного из
множеств  символов не удовлетворяют уравнению, а множитель
символов не удовлетворяют уравнению, а множитель  равен вероятности того, что сумма символов второго множества принимает значение, сравнимое по модулю А с суммой первого множества.
равен вероятности того, что сумма символов второго множества принимает значение, сравнимое по модулю А с суммой первого множества.
Объединяя соотношения (5.37), (5.38) и (5.31), получаем вероятность ошибки решения о символе в первом ярусе после первой итерации процесса декодирования:

Аналогичным образом для последовательных ярусов получаем

Скорость, с которой  стремится к нулю, можно определить из равенства (5.40). При малых
стремится к нулю, можно определить из равенства (5.40). При малых 

Интересно отметить, что выражение (5.41) совпадает с выражением (4.14), но, конечно, максимальное значение  при котором последовательность
при котором последовательность  сходится к нулю, здесь другое. С ростом А эта величина растет до
сходится к нулю, здесь другое. С ростом А эта величина растет до 
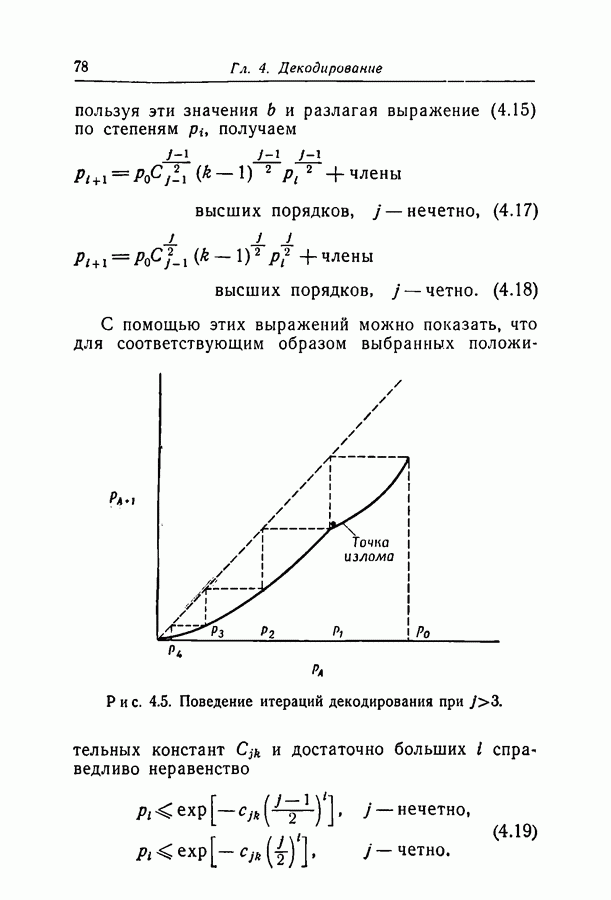
Значительно труднее получить оценку вероятности ошибки декодирования для случаев  Декодируемый символ должен изменяться всякий раз, когда
Декодируемый символ должен изменяться всякий раз, когда  будет определено позже) или большее число проверочных отношений, содержащих этот символ, все принимают одно значение. Символ следует изменить таким образом, чтобы были удовлетворены все
будет определено позже) или большее число проверочных отношений, содержащих этот символ, все принимают одно значение. Символ следует изменить таким образом, чтобы были удовлетворены все 
проверочных соотношений. При  можно таким же способом, как это было сделано в разд. 4.3, показать, что
можно таким же способом, как это было сделано в разд. 4.3, показать, что

где

Теперь можно выбрать целое  так, чтобы минимизировать
так, чтобы минимизировать  причем на
причем на  накладывается ограничение
накладывается ограничение  Решением задачи будет минимальное целое
Решением задачи будет минимальное целое  такое, что
такое, что

При  стремящемся к нулю,
стремящемся к нулю,  для четных
для четных  для нечетных
для нечетных  Раскладывая выражение (5.42) по степеням
Раскладывая выражение (5.42) по степеням  получаем
получаем

Заметим, что выражение (5.45) совпадает с (4.17), а  с точностью до коэффициентов.
с точностью до коэффициентов.
При выводе вероятности ошибки из равенства (4.18) в гл. 4 мы не использовали ограничения, связанные с тем, что алфавит двоичный, поэтому оценка вероятности ошибки, задаваемая неравенством (4.21), справедлива для кодов с произвольным объемом алфавита. Однако коэффициенты  используемые в выражении (4.21), зависят от объема алфавита А.
используемые в выражении (4.21), зависят от объема алфавита А.