Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
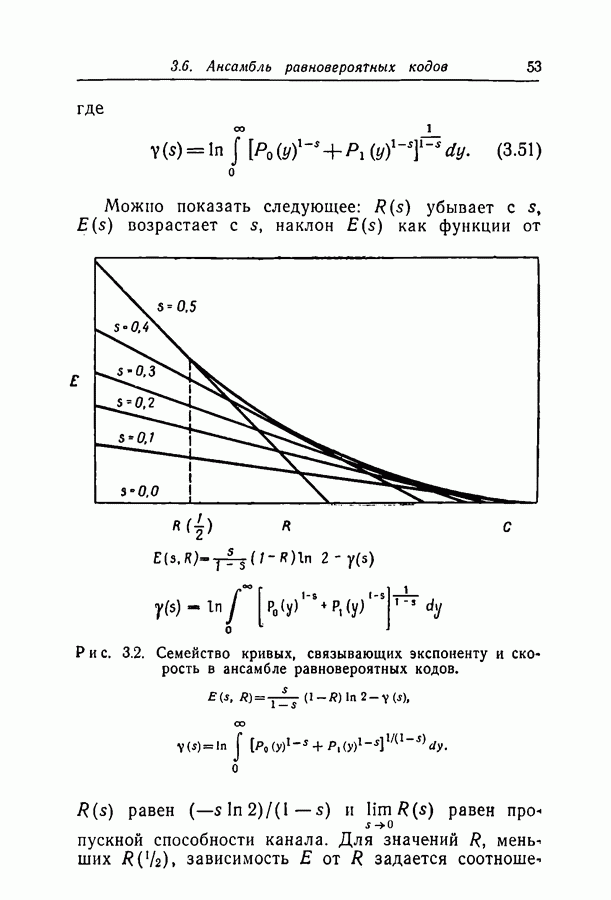
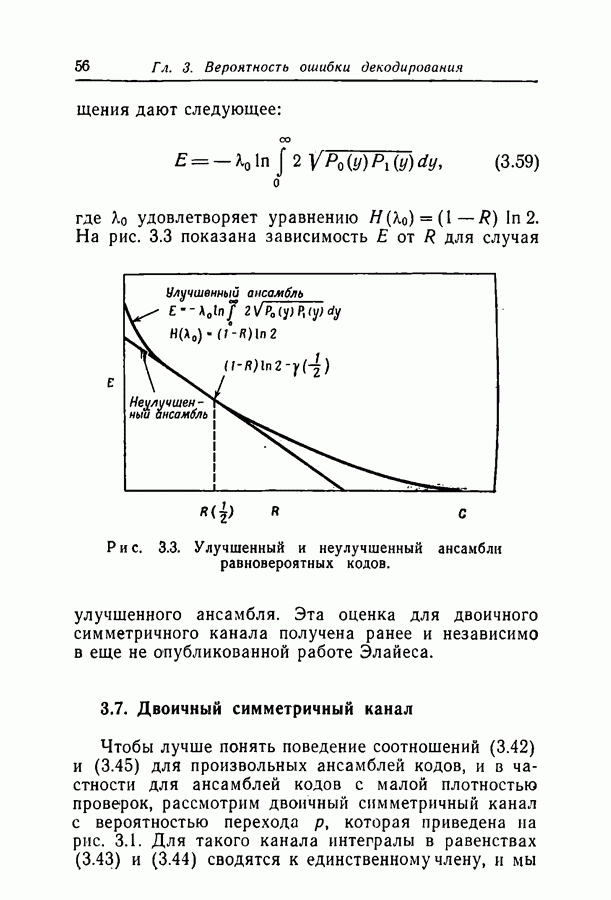
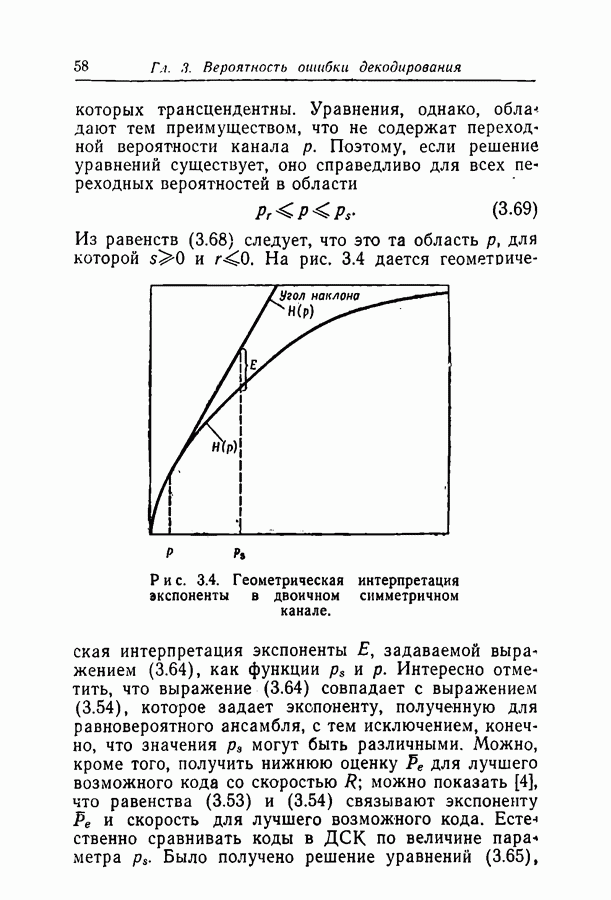
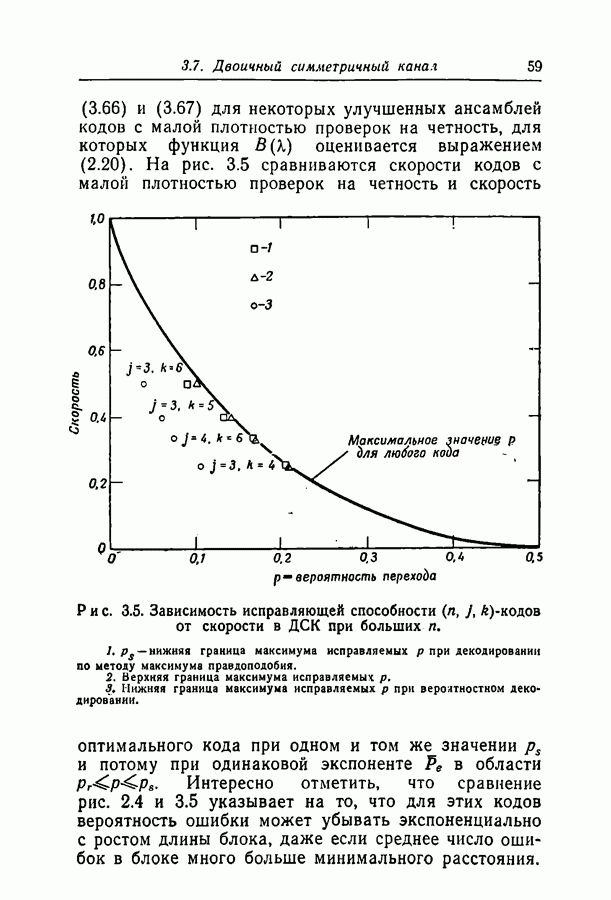
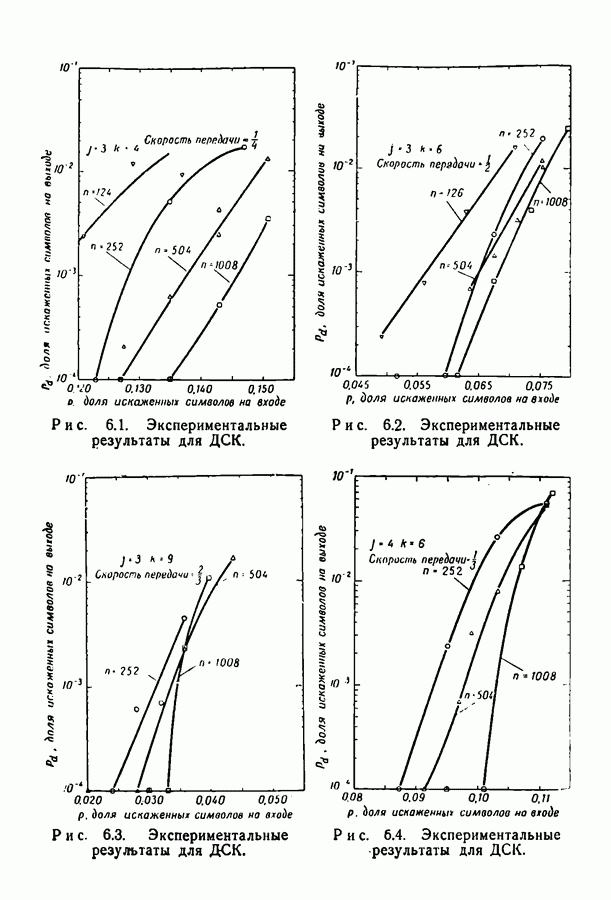
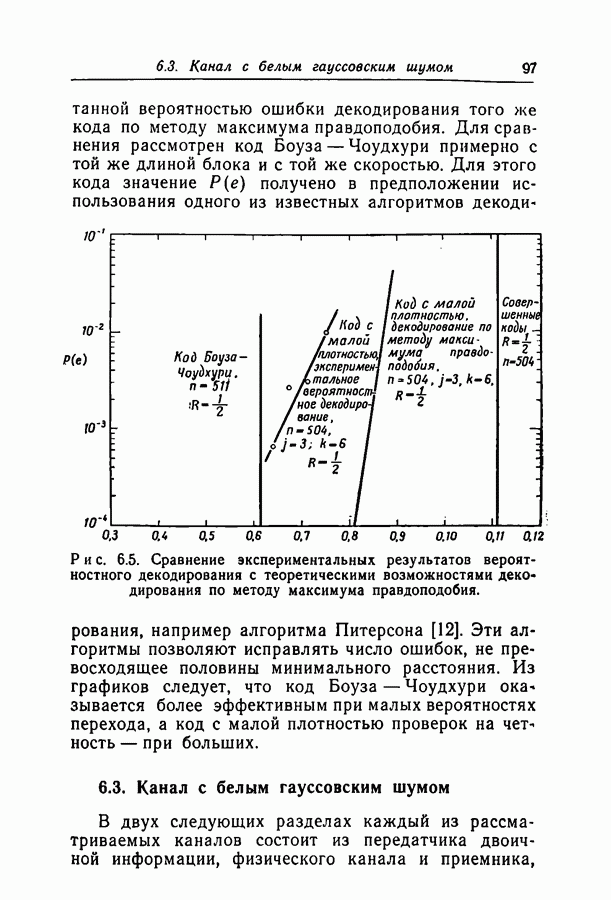
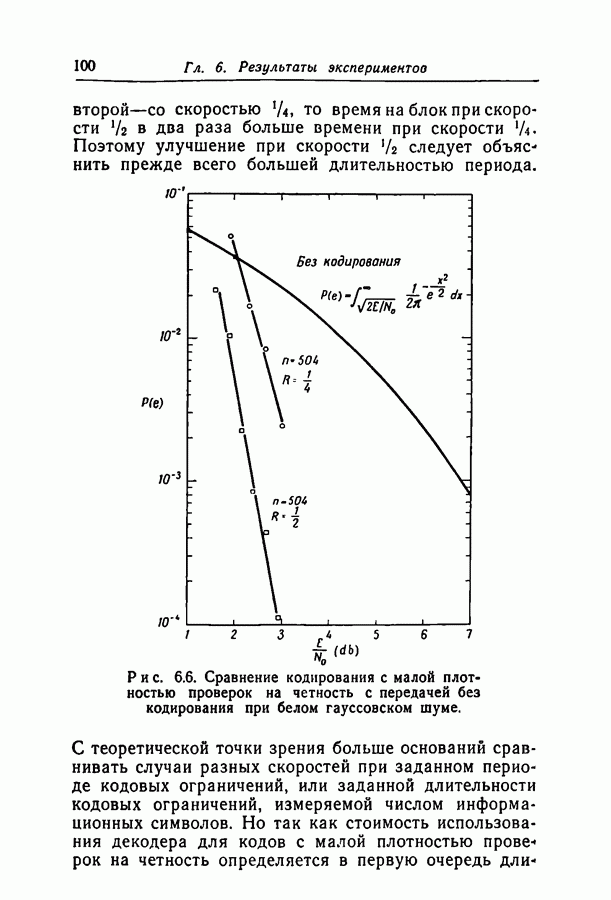
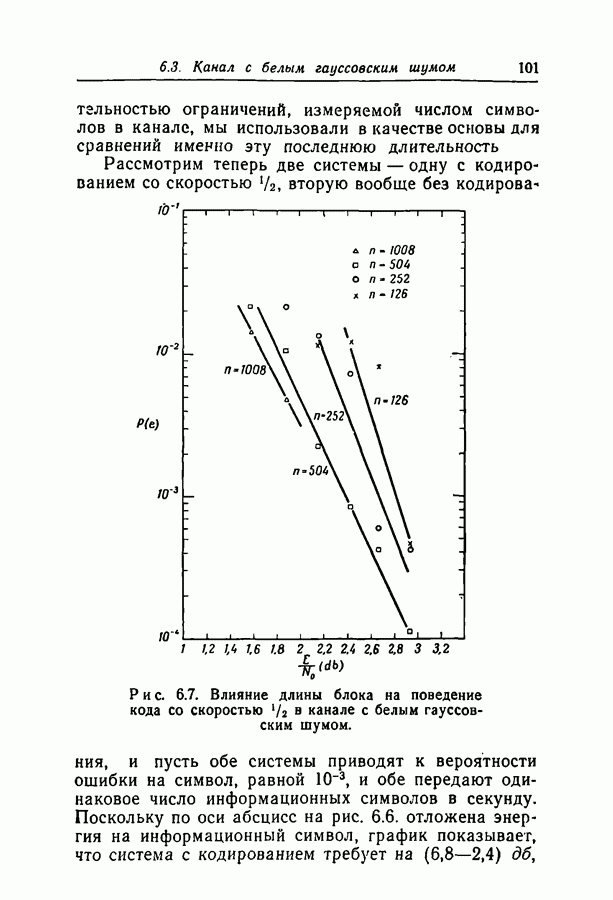
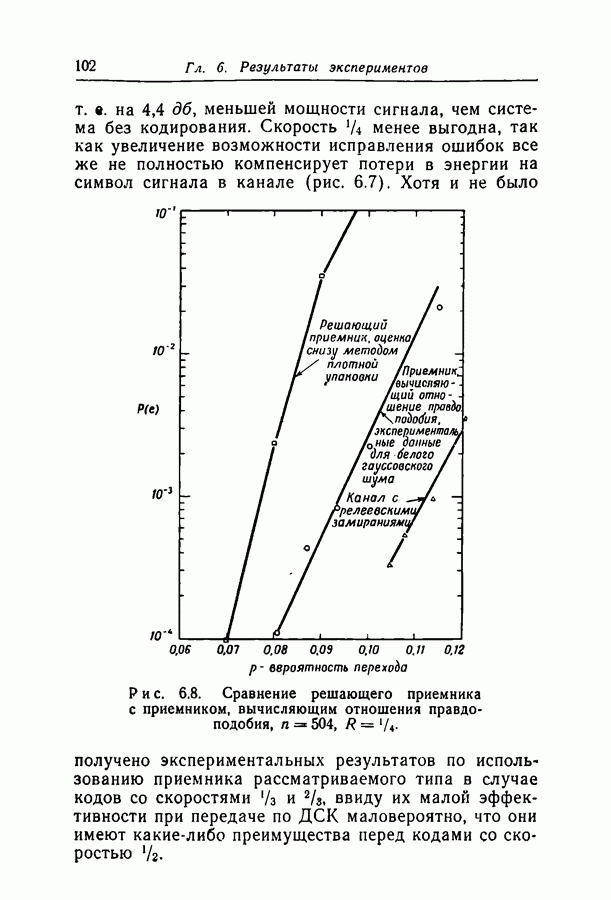
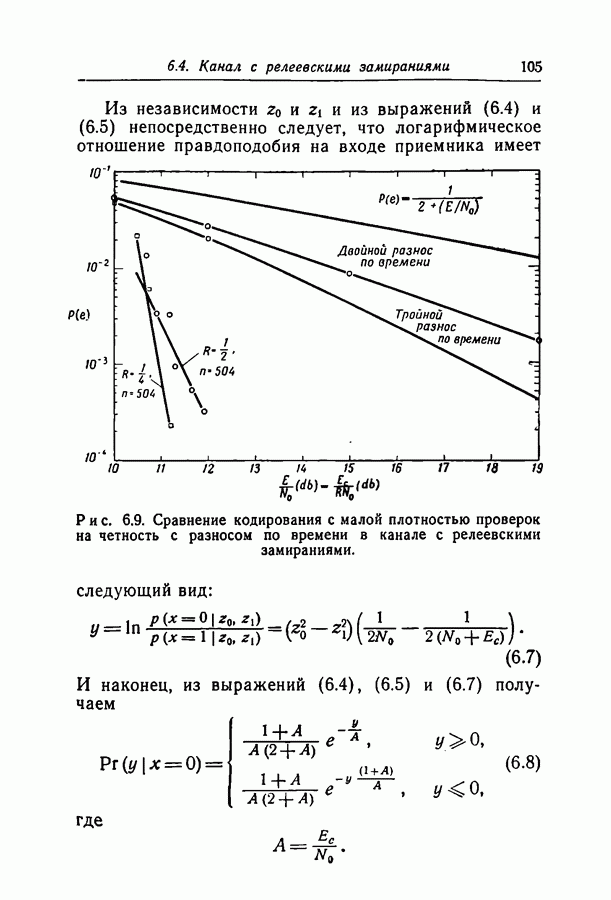
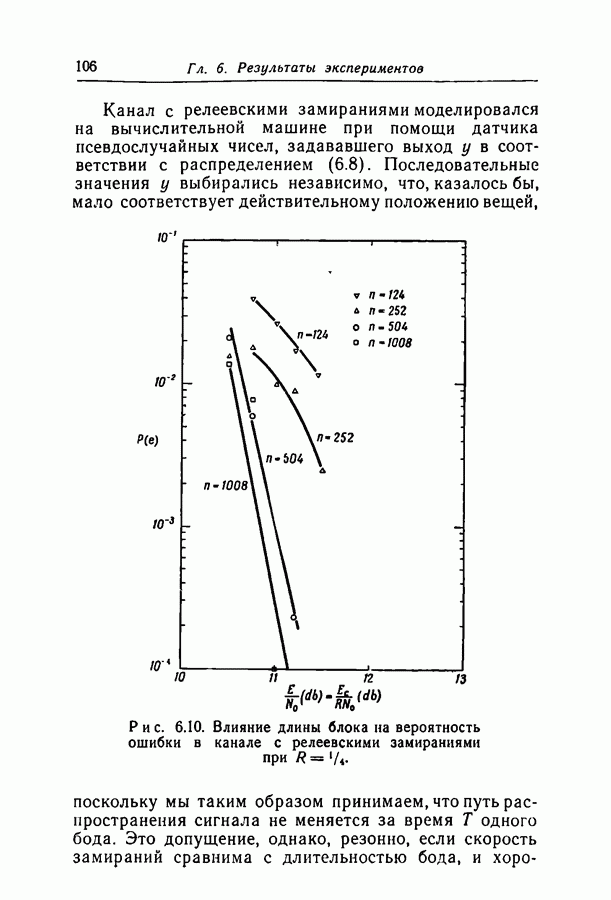
1.3. Сводка результатовВ гл. 2 будет построен ансамбль В гл. 3 найдена некоторая общая верхняя граница для вероятности ошибки декодирования в симметричном канале с двоичным входом при декодировании по максимуму правдоподобия как для кодов, так и для произвольных ансамблей кодов. Граница связана с кодом только через свойства расстояний. Допущение о декодировании по максимуму правдоподобия введено отчасти из-за вносимого им упрощения вычислений, частично же для того, чтобы было можно оценивать коды независимо от алгоритма декодирования. Любой практически реализуемый алгоритм декодирования, такой, как описанный в гл. 4, приводит к необходимости выбора между малостью вероятности ошибки и простотой; декодирование по максимуму правдоподобия минимизирует вероятность ошибки, но абсолютно неприменимо, если длина блока велика. В гл. 3 показано, что если расстояния кодовых слов связаны линейно с длиной блока и если скорость кода достаточно мала, граница Особенно простая оценка найдена, в частности, для двоичного симметричного канала. С ее помощью показано, что при всех вероятностях перехода в канале для типичного кода с малой плотностью поведение вероятностей ошибки такое же, как и для оптимального кода с немного большей скоростью. Рис. 3.5 иллюстрирует проигрыш в скорости, связанный с использованием кодов с малой плотностью проверок на четность. В гл. 4 описаны два метода декодирования. В соответствии с первым, особенно простым методом декодер вначале принимает решение о каждом символе, а затем вычисляет проверки на четность и изменяет на обратные все символы, содержащиеся больше чем в некотором фиксированном числе неудовлетворившихся проверочных соотношений. Процесс повторяется до тех пор, пока последовательность не будет декодирована, причем каждый раз используются измененные символы. Второй метод декодирования основан на вычислении условных вероятностей того, что символ на входе равен 1. Эти вероятности вычисляются при условии, что известны все принятые символы, входящие в любое проверочное уравнение, содержащее рассматриваемый символ. И опять процесс повторяется до тех пор, пока последовательность не будет декодирована. Число операций на символ при каждом повторении в обоих методах не зависит от длины кода. Второй, вероятностный метод требует несколько большего числа операций, однако позволяет декодировать с меньшей вероятностью ошибки. Математический анализ вероятности появления ошибки при вероятностном методе декодирования труден из-за статистических зависимостей. Однако для ДСК с достаточно малой вероятностью перехода и для кодов с Все основные результаты гл. 2, 3 и 4 распространяются в гл. 5 на недвоичные коды с малой плотностью проверок на четность. Хотя такое обобщение вполне естественно, выражения для минимального расстояния, вероятности ошибки и вероятности ошибки при вероятностном декодировании очень сложны, и поэтому очень мало можно сказать о преимуществах и недостатках недвоичных кодов по сравнению с двоичными. По-видимому, для оценки качества этих кодов окажется полезной дальнейшая экспериментальная работа. Некоторые экспериментальные результаты о двоичных кодах с малой плотностью приведены в гл. 6. Для моделирования вероятностного декодирования и шумов, возникающих в каналах нескольких разных типов, использовалась вычислительная машина ИБМ-7090. Ввиду ограниченности машинного времени исследовался только случай каналов со значительным уровнем шумов, таких, что вероятность ошибки декодирования превышала 10-4. На рис. 6.8 приведены наиболее поучительные результаты экспериментов. они особенно подчеркивают преимущества метода декодирования с использованием приемника, вычисляющего отношение правдоподобия, по сравнению с решающим приемником.
|
 |
Оглавление
|























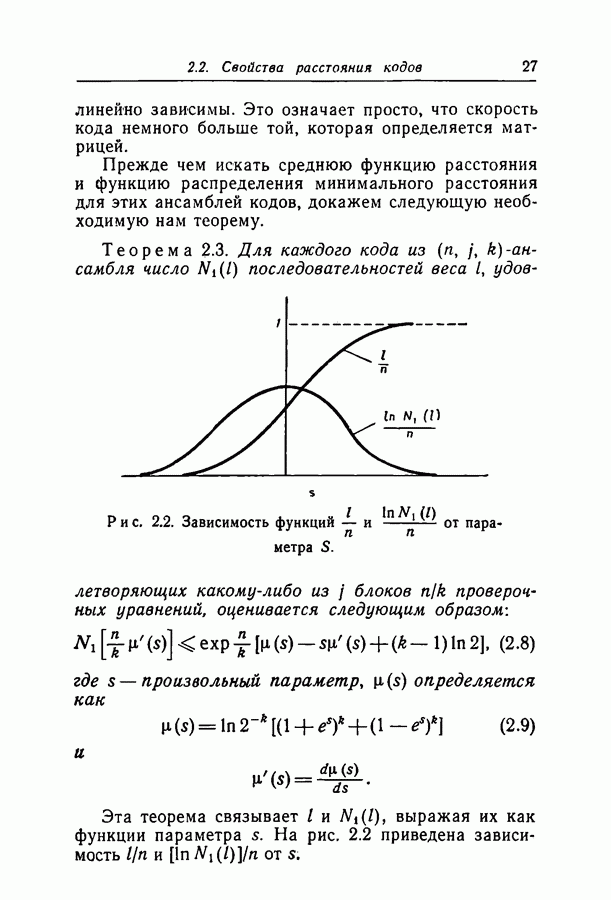

































































































 -кодов, мы используем его для анализа свойств расстояний этих кодов. Расстояние между двумя кодовыми словами есть просто число символов, в которых они различаются. Ясно, что совокупность расстояний между некоторым словом и всеми остальными кодовыми словами есть важный параметр кода. Можно показать [12], что в коде с проверками на четность все кодовые слова имеют одинаковые наборы расстояний до других кодовых слов. Поэтому свойства расстояния в ансамбле можно описать, используя типичные числа кодовых слов, находящихся на разных расстояниях от слова, состоящего целиком из нулей. Найдено, что для типичного
-кодов, мы используем его для анализа свойств расстояний этих кодов. Расстояние между двумя кодовыми словами есть просто число символов, в которых они различаются. Ясно, что совокупность расстояний между некоторым словом и всеми остальными кодовыми словами есть важный параметр кода. Можно показать [12], что в коде с проверками на четность все кодовые слова имеют одинаковые наборы расстояний до других кодовых слов. Поэтому свойства расстояния в ансамбле можно описать, используя типичные числа кодовых слов, находящихся на разных расстояниях от слова, состоящего целиком из нулей. Найдено, что для типичного  -кода с
-кода с  минимальное расстояние линейно возрастает с длиной блока при постоянных
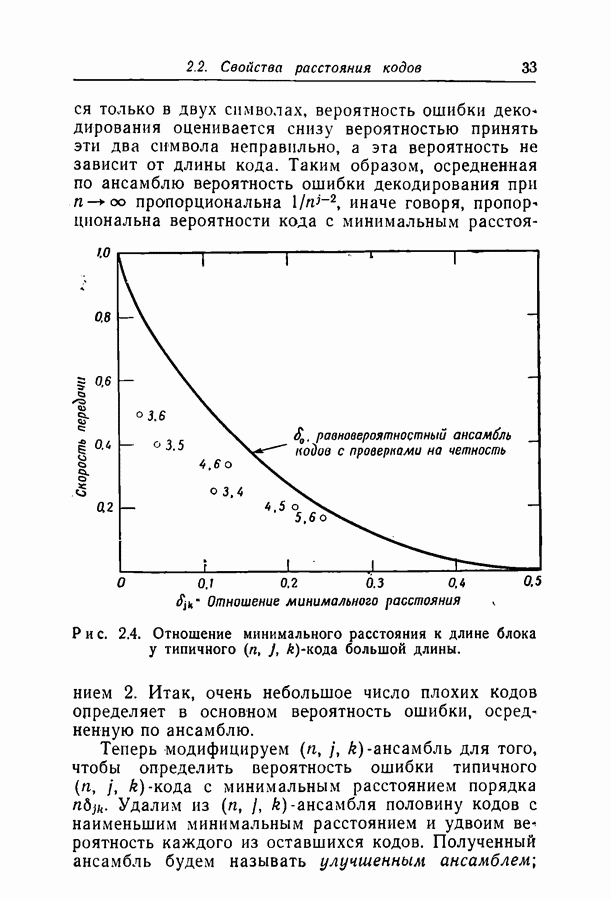
минимальное расстояние линейно возрастает с длиной блока при постоянных  На рис. 2.4 приведено отношение минимального расстояния к длине блока при нескольких значениях
На рис. 2.4 приведено отношение минимального расстояния к длине блока при нескольких значениях  оно сравнивается с соответствующим отношением для обычных кодов с проверками на четность;
оно сравнивается с соответствующим отношением для обычных кодов с проверками на четность;  -код при
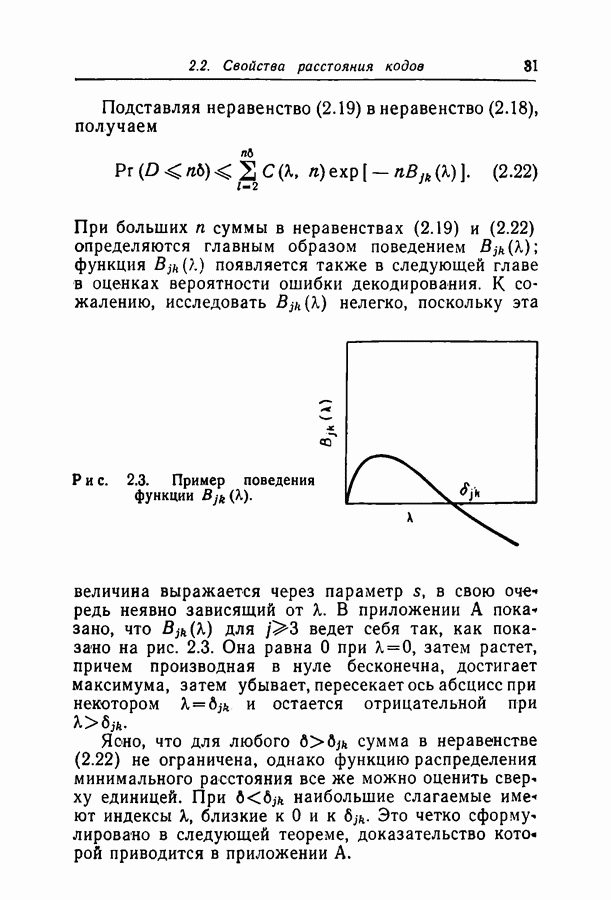
-код при  ведет себя совсем по-другому; показано, что минимальное расстояние
ведет себя совсем по-другому; показано, что минимальное расстояние  -кода может расти самое большее логарифмически с длиной блока.
-кода может расти самое большее логарифмически с длиной блока.
 оказывается экспоненциально убывающей функцией длины блока. Для выбранных подходящим образом ансамблей кодов эти оценки сводятся к обычным оценкам случайного кодирования [3, 4].
оказывается экспоненциально убывающей функцией длины блока. Для выбранных подходящим образом ансамблей кодов эти оценки сводятся к обычным оценкам случайного кодирования [3, 4].
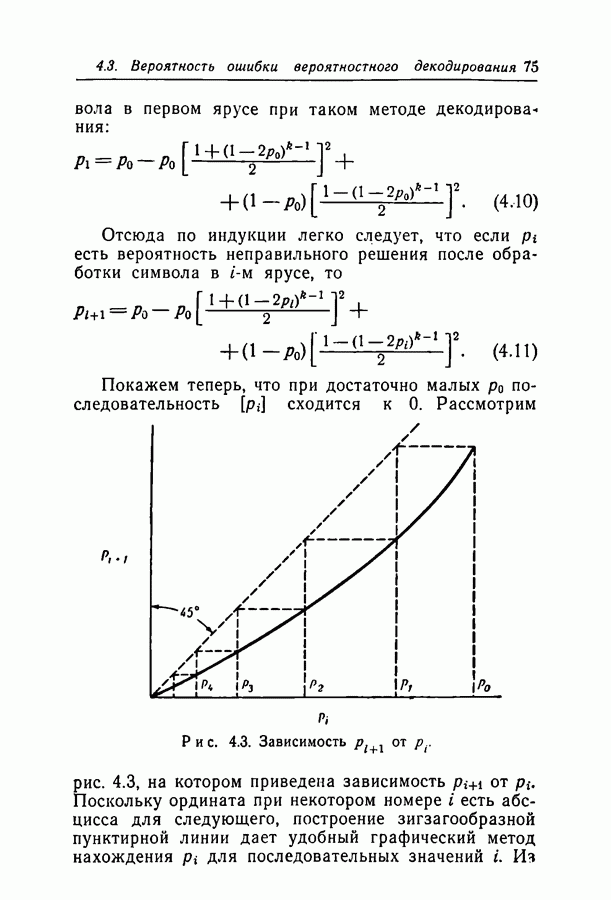
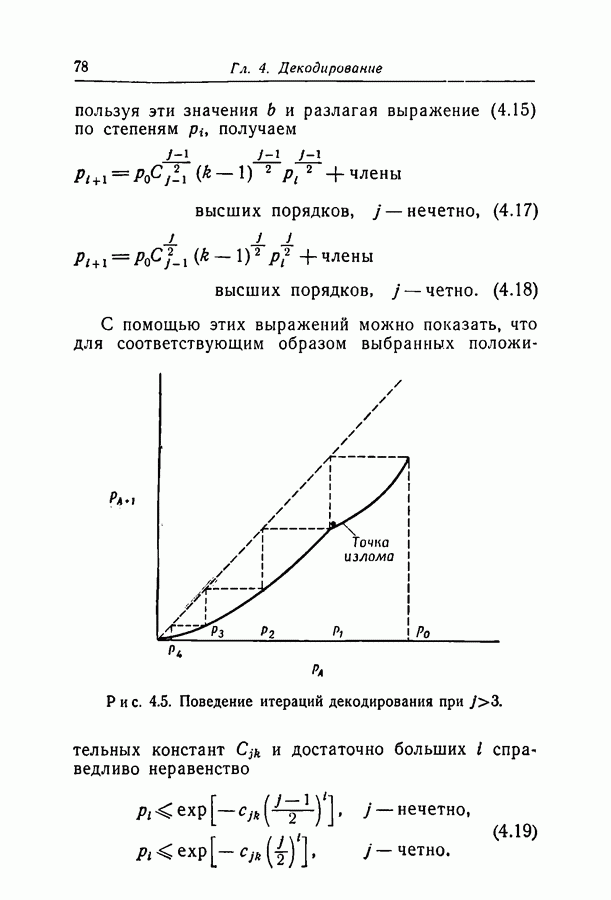
 удалось получить очень слабую оценку сверху вероятности ошибки; она убывает экспоненциально с убыванием корня из длины блока. На рис. 3.5 отложены вероятности перехода, для которых вероятность ошибки декодирования во всяком случае стремится к 0 с возрастанием длины кода. Высказывается гипотеза о том, что в действительности вероятность ошибки декодирования убывает экспоненциально с возрастанием длины блока, а число итераций, необходимых для декодирования, растет логарифмически.
удалось получить очень слабую оценку сверху вероятности ошибки; она убывает экспоненциально с убыванием корня из длины блока. На рис. 3.5 отложены вероятности перехода, для которых вероятность ошибки декодирования во всяком случае стремится к 0 с возрастанием длины кода. Высказывается гипотеза о том, что в действительности вероятность ошибки декодирования убывает экспоненциально с возрастанием длины блока, а число итераций, необходимых для декодирования, растет логарифмически.