Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Глава I. ВВЕДЕНИЕ1.1. Кодирование при передаче цифровой информацииЗа последние годы резко возросла потребность в эффективных и надежных системах передачи информации. Это вызвано целым рядом причин и среди них растущим применением аппаратуры автоматической обработки информации и увеличивающейся потребностью в связи на большие расстояния. Попытки создать информационные системы с использованием обычных методов модуляции и телефонной техники приводили, как правило, к системам со сравнительно низкими скоростями передачи информации и высокой вероятностью ошибки.
Рис. 1.1. Блок-схема системы связи. Более глубокий подход к проблеме эффективности и надежности систем связи содержится в теореме кодирования для канала с шумами, доказанной К. только одного блока. Символы на выходе кодера передаются по каналу и изменяются под действием каких-либо случайных возмущений или шума. Декодер обрабатывает символы на выходе канала и воссоздает с задержкой некоторый вариант символов, созданных источником. Теорема кодирования утверждает: для широкого класса моделей каналов существуют такие кодер и декодер, для которых вероятность
Функции На такую теорему реакция инженера очевидна: «Великолепно, но как построить такие кодеры и декодеры, если Проблема простого, но эффективного декодирования, к сожалению, оказывается при больших гораздо более трудной, чем проблема кодирования. Было предложено достаточно большое число подходов к этой проблеме, для того чтобы доказать инженерам ценность теоремы кодирования. Эти подходы, однако, не были разработаны настолько, чтобы создание эффективной и надежной системы передачи информации стало вопросом повседневной техники. Данная монография содержит детальное исследование одного из трех или четырех наиболее перспективных подходов к проблеме простого декодирования кодов с большой длиной кодовых ограничений. Цель опубликования этой работы состоит прежде всего в том, чтобы показать, как и где можно использовать такой метод кодирования и декодирования, найденный в результате этого подхода. Я надеюсь, кроме того, что она будет способствовать дальнейшему развертыванию исследований в этой области. Дальнейшие математические исследования, вероятно, не будут плодотворными, однако существует целый ряд интересных модификаций метода, которые можно было бы развить; нужно также провести большую экспериментальную работу. Для того чтобы математически доказать некоторые факты, мы примем, что эти коды с малой плотностью проверок на четность будут использоваться в несколько ограниченном и идеализированном классе каналов. Ясно, что результаты, полученные для таких моделей, можно применять только к каналам, которые хорошо описываются этими моделями. Однако, изучая вероятность ошибки, мы интересуемся прежде всего весьма нетипичными событиями, вызывающими ошибки. Нелегко найти модель, хорошо описывающую как типичные, так и нетипичные события. Следовательно, анализ кодов в идеализированных каналах может дать только ограниченные сведения о поведении их в реальных каналах, и к результатам такого анализа следует подходить весьма осторожно. Рассматриваемые здесь модели каналов называют симметричными каналами с двоичным входом. Мы имеем в виду канал с дискретным временем, входом которого служит последовательность двоичных символов 0 и 1, а выходом — соответствующая последовательность букв дискретного или непрерывного алфавита. Канал не обладает памятью, иначе говоря, при заданном в некоторый момент времени символе на входе соответствующий символ на выходе канала статистически не зависит от символов на входе и выходе канала в другие моменты времени. Требования симметрии будут точно определены в гл. 3, но, грубо говоря, они означают следующее: символы на выходе канала можно объединить в пары так, что вероятность одного выходного символа при заданном входном совпадает с вероятностью второго выходного символа при другом входном. Двоичный симметричный канал, сокращенно ДСК, принадлежит этому классу каналов; он имеет два символа на выходе, каждый из которых соответствует некоторому символу на входе. ДСК можно полностью охарактеризовать с помощью вероятности перехода одного входного символа в символ на выходе, соответствующий другому входному символу. Если нужно использовать симметричный канал с двоичным входом без кодирования, передают последовательность двоичных символов и приемник восстанавливает символы на основе принятых, по одному в каждый момент времени. Если же для передачи по каналу используется кодирование, кодер должен сначала преобразовать последовательности двоичных символов, несущих информацию, в более длинные, содержащие избыточность последовательности, называемые кодовыми словами. Мы определим для таких кодов скорость На приемном конце декодер по хранящимся в нем последовательностям, являющимся кодовыми словами, может отделить переданную последовательность длины
Рис. 1.2. Пример проверочной матрицы. Описанный ниже метод декодирования позволяет избежать промежуточного решения и оперирует непосредственно с апостериорными вероятностями входных символов, условными по отношению к соответствующим выходным символам. Коды, рассматриваемые в данной работе, являются специальными случаями кодов с проверками на четность. Кодовые слова в коде с проверками на четность образуются комбинированием блоков двоичных информационных символов с блоками проверочных символов. Каждый проверочный символ есть сумма по модулю 2 некоторой наперед указанной совокупности информационных символов. Правила построения таких проверочных символов удобно представить в виде проверочной матрицы, такой, как приведенная на рис. 1.2. Такая матрица представляет собой систему линейных однородных уравнений по модулю 2, называемых проверочными уравнениями, а множество кодовых слов есть множество решений этих уравнений. Совокупность символов, входящих в проверочное уравнение, мы назовем проверочным множеством. Например, первое проверочное множество на рис. 1.2 есть множество символов с индексами (1, 2, 3, 5). Применение кодов с проверками на четность делает кодирование (в отличие от декодирования) сравнительно простым для реализации. Кроме того, как показал Элайес [3], если в ДСК используется типичный код с проверками на четность с большой длиной блока и если скорость кода лежит между критической скоростью и пропускной способностью канала, то вероятность ошибки декодирования почти совпадает с вероятностью ошибки для лучшего из возможных кодов с той же скоростью передачи и длиной блока. К сожалению, для кодов с проверками на четность не проста реализация декодирования, поэтому мы вынуждены искать специальные классы таких кодов с проверками на четность, для которых существует приемлемый метод декодирования, например, класс кодов, описываемый в разд. 1.2.
|
 |
Оглавление
|
































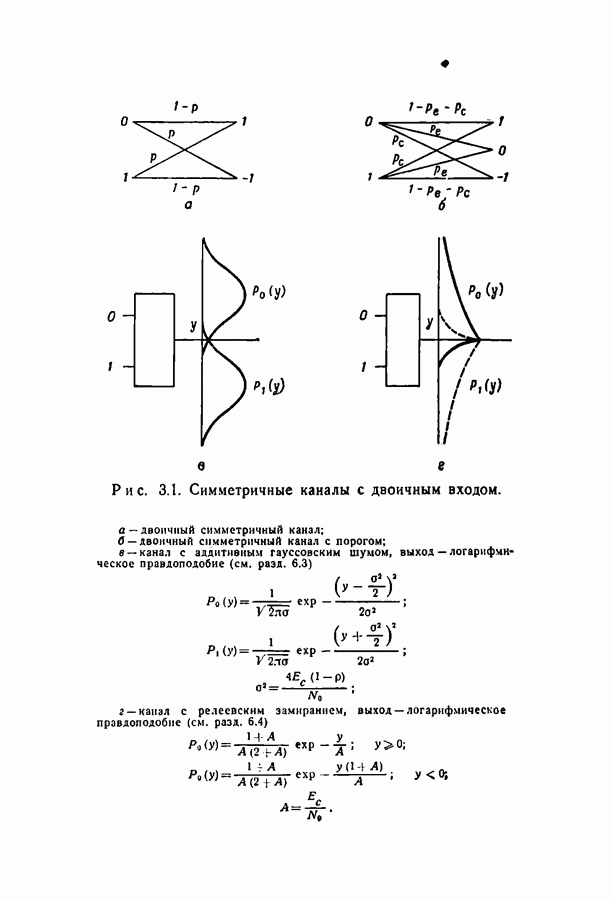































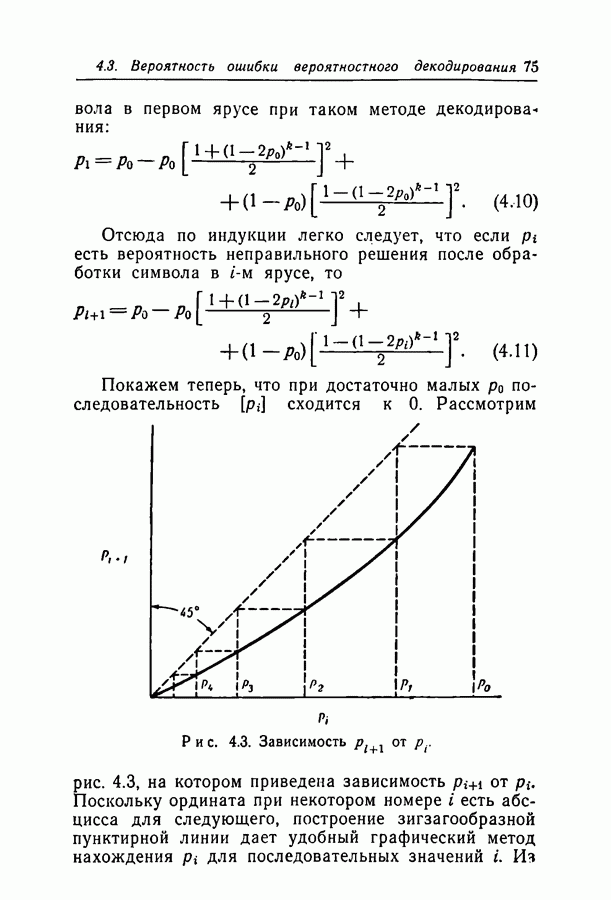


























































 Шенноном в 1948 г. [4, 15]. Для того чтобы лучше понять смысл этой теоремы, рассмотрим рис. 1.1. Источник создает двоичные символы с некоторой фиксированной скоростью
Шенноном в 1948 г. [4, 15]. Для того чтобы лучше понять смысл этой теоремы, рассмотрим рис. 1.1. Источник создает двоичные символы с некоторой фиксированной скоростью  Кодер — устройство, обрабатывающее поступающую информацию, осуществляющее модуляцию и вообще делающее все необходимое для подготовки информации к передаче по каналу. Предположим, что кодер разбивает последовательность символов, создаваемых источником, на блоки по
Кодер — устройство, обрабатывающее поступающую информацию, осуществляющее модуляцию и вообще делающее все необходимое для подготовки информации к передаче по каналу. Предположим, что кодер разбивает последовательность символов, создаваемых источником, на блоки по  символов и обрабатывает одновременно символы
символов и обрабатывает одновременно символы
 того, что декодер воспроизводит символ источника ошибочно, оценивается следующим образом:
того, что декодер воспроизводит символ источника ошибочно, оценивается следующим образом:

 зависят от канала, но не зависят от
зависят от канала, но не зависят от  они положительны при
они положительны при  убывают с ростом
убывают с ростом  и обращаются в нуль при некоторой скорости
и обращаются в нуль при некоторой скорости  называемой пропускной способностью канала. Нам нет необходимости рассматривать здесь точный вид этих функций и класс каналов, для которых справедлива теорема. Важно то, что длина кодовых ограничений
называемой пропускной способностью канала. Нам нет необходимости рассматривать здесь точный вид этих функций и класс каналов, для которых справедлива теорема. Важно то, что длина кодовых ограничений  это основной параметр системы связи. Если мы хотим использовать канал эффективно, т. е. со скоростью
это основной параметр системы связи. Если мы хотим использовать канал эффективно, т. е. со скоростью  близкой к пропускной способности
близкой к пропускной способности  и получить при этом удовлетворительную вероятность ошибки, значение
и получить при этом удовлетворительную вероятность ошибки, значение  следует выбрать достаточно большим.
следует выбрать достаточно большим.
 велико?» Соображения, показывающие, что требуемый для их построения объем памяти пропорционален
велико?» Соображения, показывающие, что требуемый для их построения объем памяти пропорционален  в том случае, когда кодер содержит в памяти сигнал, или кодовое слово, для каждого из возможных блоков по
в том случае, когда кодер содержит в памяти сигнал, или кодовое слово, для каждого из возможных блоков по  символов, действуют в достаточной мере отрезвляюще. К счастью, Элайес [3] и Рейффен [14] показали, что для широкого класса моделей каналов результаты, даваемые теоремой кодирования для канала с шумами, могут быть достигнуты при небольшой сложности кодера с помощью кодов с проверками на четность. Ниже мы подробнее рассмотрим этот факт.
символов, действуют в достаточной мере отрезвляюще. К счастью, Элайес [3] и Рейффен [14] показали, что для широкого класса моделей каналов результаты, даваемые теоремой кодирования для канала с шумами, могут быть достигнуты при небольшой сложности кодера с помощью кодов с проверками на четность. Ниже мы подробнее рассмотрим этот факт.

 как отношение длин информационной последовательности и кодового слова. Если кодовые слова имеют длину
как отношение длин информационной последовательности и кодового слова. Если кодовые слова имеют длину  то существует
то существует  возможных последовательностей на выходе источника, которые необходимо преобразовать в кодовые слова. Тогда в качестве кодовых слов можно использовать только
возможных последовательностей на выходе источника, которые необходимо преобразовать в кодовые слова. Тогда в качестве кодовых слов можно использовать только  долю из
долю из  различных последовательностей длины
различных последовательностей длины 
 от шума в канале. Так, кодовое слово отображается обратно на совокупность
от шума в канале. Так, кодовое слово отображается обратно на совокупность  информационных символов. Во многих методах декодирования находят переданное слово, принимая сначала решение относительно каждого отдельного символа, а затем исправляют ошибки, пользуясь списком кодовых слов. Однако, как подробно показано для нескольких типов каналов в работе [1], при таком промежуточном решении теряется значительная доля информации о переданном сообщении.
информационных символов. Во многих методах декодирования находят переданное слово, принимая сначала решение относительно каждого отдельного символа, а затем исправляют ошибки, пользуясь списком кодовых слов. Однако, как подробно показано для нескольких типов каналов в работе [1], при таком промежуточном решении теряется значительная доля информации о переданном сообщении.
