Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
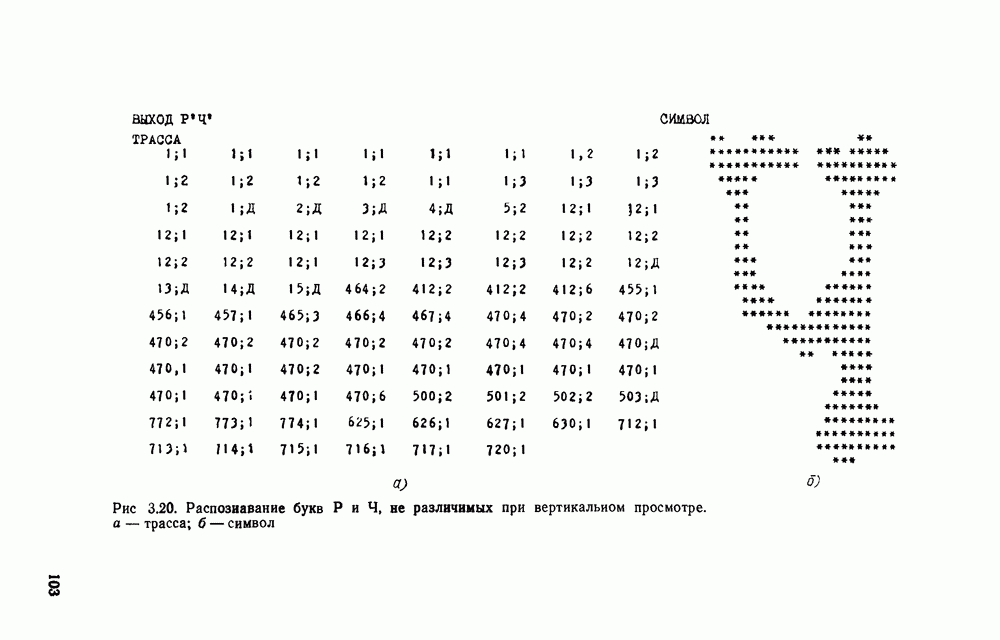
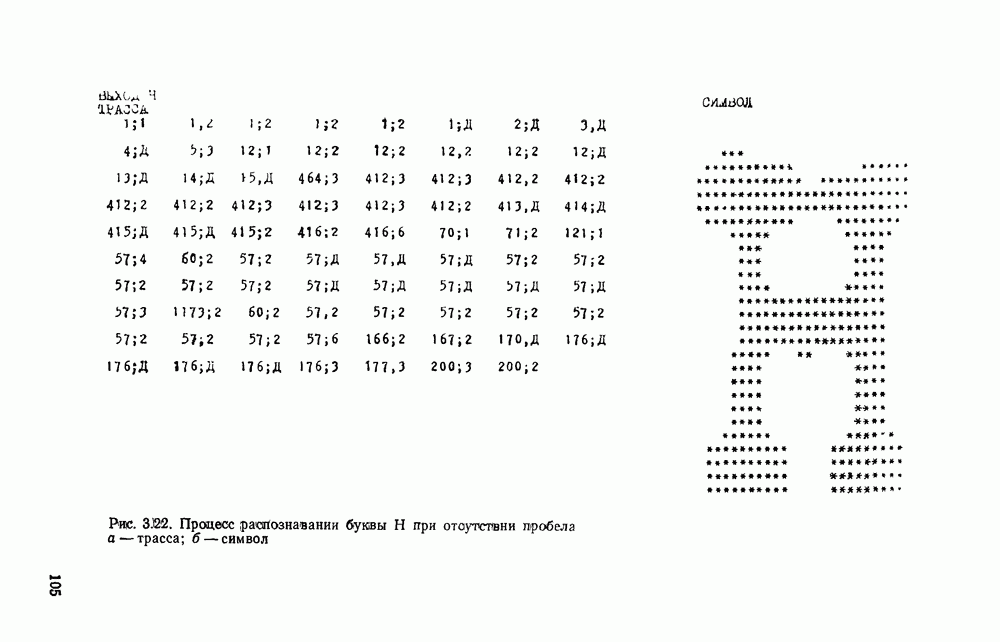
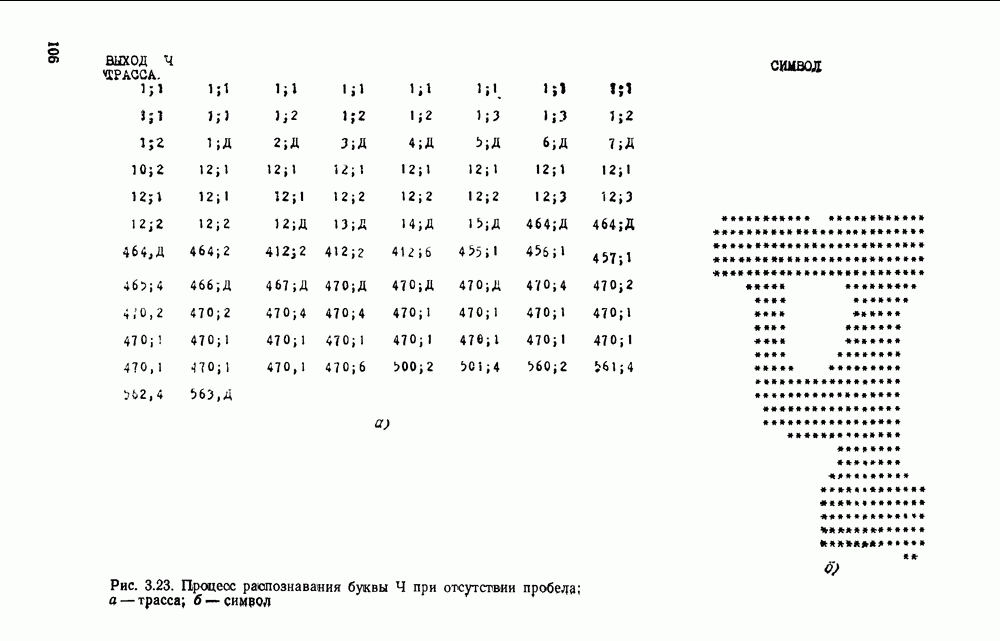
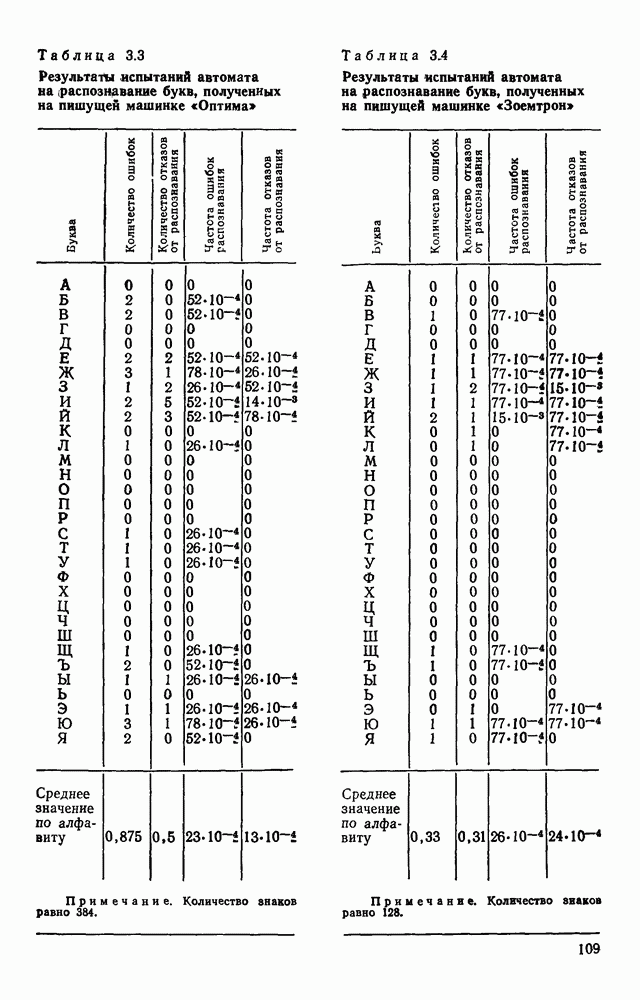
ГЛАВА 3. АВТОМАТИЧЕСКОЕ РАСПОЗНАВАНИЕ ПЕЧАТНЫХ И СТИЛИЗОВАННЫХ РУКОПИСНЫХ ПИСЬМЕННЫХ ЗНАКОВ3.1. МЕСТО РАЗЛИЧНЫХ ВИДОВ СИМВОЛЬНОЙ ИНФОРМАЦИИ В ОБЩЕЙ ЗАДАЧЕ РАСПОЗНАВАНИЯ ОБРАЗОВБольшая часть документации промышленных изделий, снимков, различных карт в том или ином виде содержат тексты, буквенные и цифровые обозначения, специальные символы, которые подлежат вводу наряду с графической и визуальной информацией и, что более важно, составляют неотъемлемую часть всего изображения. Поэтому полная и правильная интерпретация изображения возможна только при правильном «чтении» буквенных текстов, цифр, символов. Тексты и символы могут быть воспроизведены типографским способом, на пишущей машинке, написаны по трафарету или от руки. Но независимо от этого при их «чтении» можно выделить две самостоятельные задачи: отделение символьной информации от графической и визуальной; распознавание № интерпретация каждого символа. В этой главе основное внимание уделяется второй задаче, служащей предметом интенсивных исследований уже почти три десятилетия. Столь большой интерес обусловлен не только ее явно «кибернетической» направленностью, определяемой моделированием человеческих функций, но и непосредственной связью с производственной деятельностью (сортировкой писем, автоматическим набором, робототехническими системами, проектными (САПР) и научными изысканиями, делопроизводством и управлением). Сама эта проблема породила целую серию задач, начиная от считывания и распознавания машинописных цифр до распознавания рукописных знаков (буквы и цифры), символов (например, обозначения месторождений полезных ископаемых на картах), нотных записей и слитно написанных от руки текстов. О сложности распознавания рукописных знаков свидетельствует тот факт, что даже человек, читая их при отсутствии контекста, делает около 4% ошибок [41]. Причины ошибок кроются в бесконечном разнообразии вариаций формы знаков, которое обусловлено наличием ограничений в начертании знаков и символов или их отсутствием, стилем, образованием, опытом, настроением, здоровьем и другими характеристиками пишущего, а также в качестве пишущего инструмента и поверхности, на которой пишут, методах считывания и алгоритмах распознавания. Поэтому для производственных, технических и деловых документов имеет смысл ограничивать возможное многообразие начертаний знаков и символов путем введения стандартов. Например, надписи на чертежах выполняют в соответствии с ЕСКД, цифры почтового кода вписывают в специальные окна-шаблоны. В ряде стран разработаны стандарты рукописного исполнения печатных знаков (стилизованные буквенно-цифровые знаки), что позволяет резко сократить возможные вариации в их написании, получить более высокие показатели правильного распознавания и снизить вероятность ошибок и отказов от распознавания. Регламентируется и способ написания стандартных знаков: они должны быть настолько крупными, насколько это позволяют заданные границы форматного поля, их следует писать в максимально возможном соответствии с заданной моделью, без ненужных разрывов и росчерков. Важное значение имеет пишущий инструмент (карандаши, шариковые ручки, фломастер и т. д.), качество бумаги (отражательная способность, цвет, плотность и пр.). Заметим, что качество бумаги и красящей ленты существенно сказывается и на распознавании машинописных текстов. В этой главе рассмотрен систематический способ построения распознающих устройств, основанный на использовании автоматной грамматики в качестве языка описания изображений. На примере достаточно простого алфавита экспериментально показана высокая эффективность такого подхода, приводящего к достаточно высоким показателям правильного распознавания при сравнительно небольших аппаратурных затратах. Наиболее важным преимуществом методики является эффективная техническая реализация собственно классифицирующего устройства на микропроцессорных наборах. Хотя приводимые экспериментальные результаты относятся в основном к распознаванию машинописных и стилизованных букв» русского алфавита, распространение их на другие алфавиты, а также специальные символы не вызывает серьезных затруднений. Эта не означает, что предложен универсальный способ распознавания чего угодно. Скажем, распознавания рукописных букв по-видимому потребует более изощренного алфавита автоматного языка, а скорее всего иерархию алфавитов [46], построение которых никак не формализовано и в настоящее время почти целиком определяется искусством проектировщика. В то же время ряд важных этапов построения распознающего устройства достаточно формализован и имеются программы для ЭВМ, автоматизирующие этот процесс.
|
 |
Оглавление
|