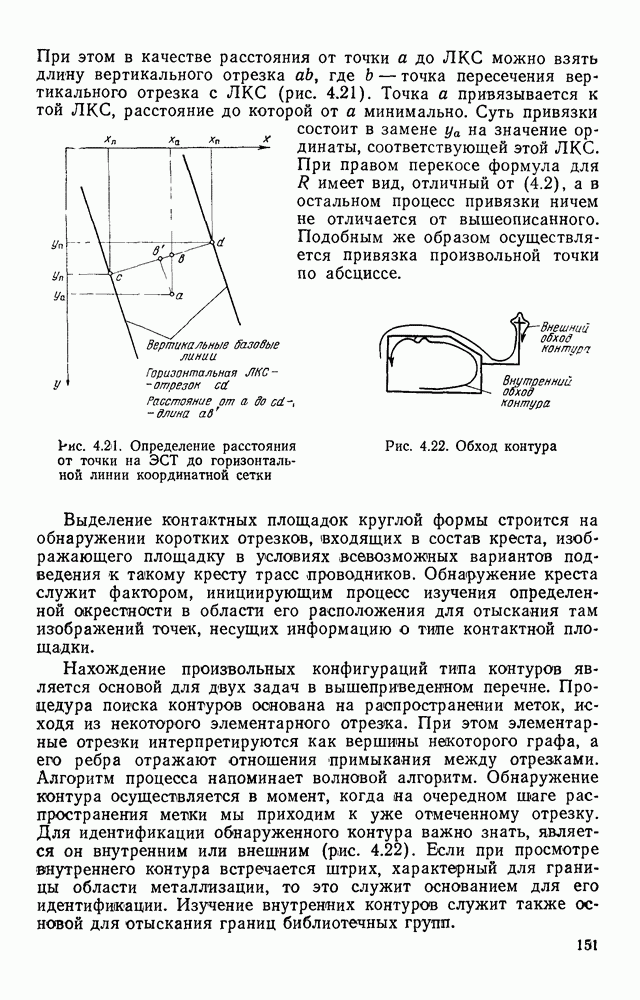
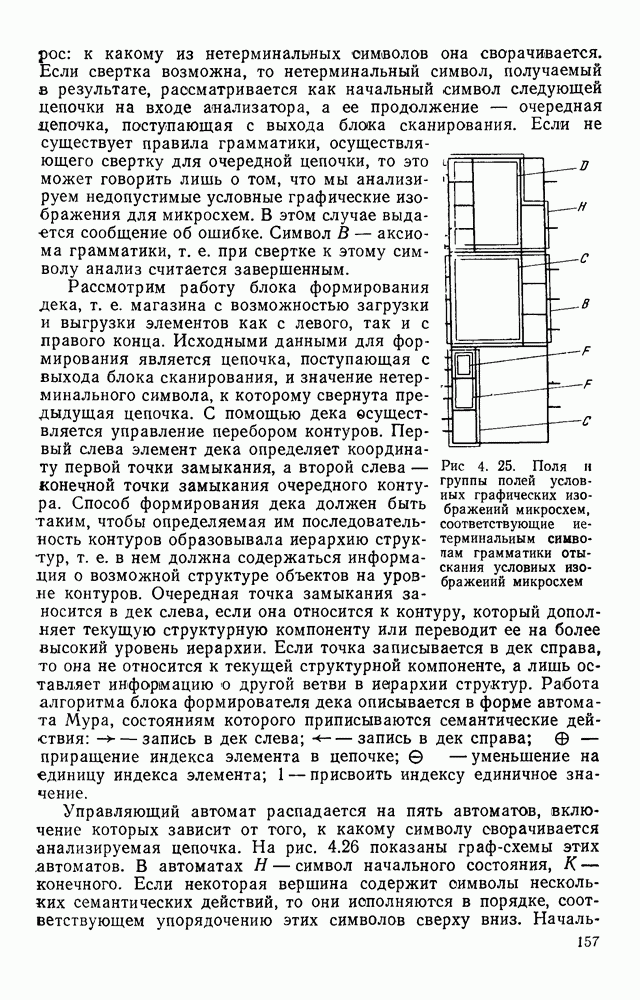
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
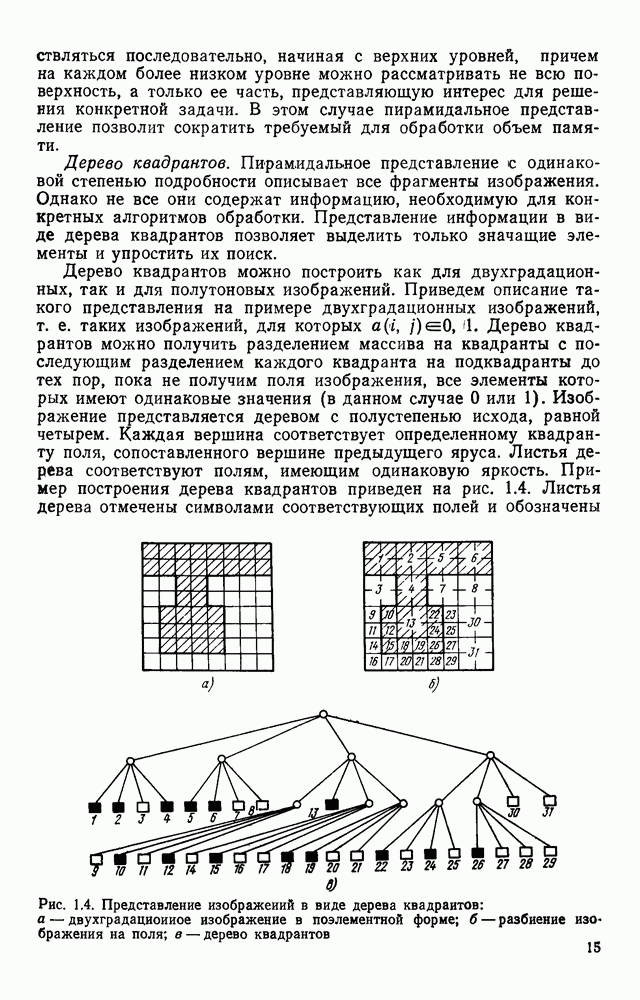
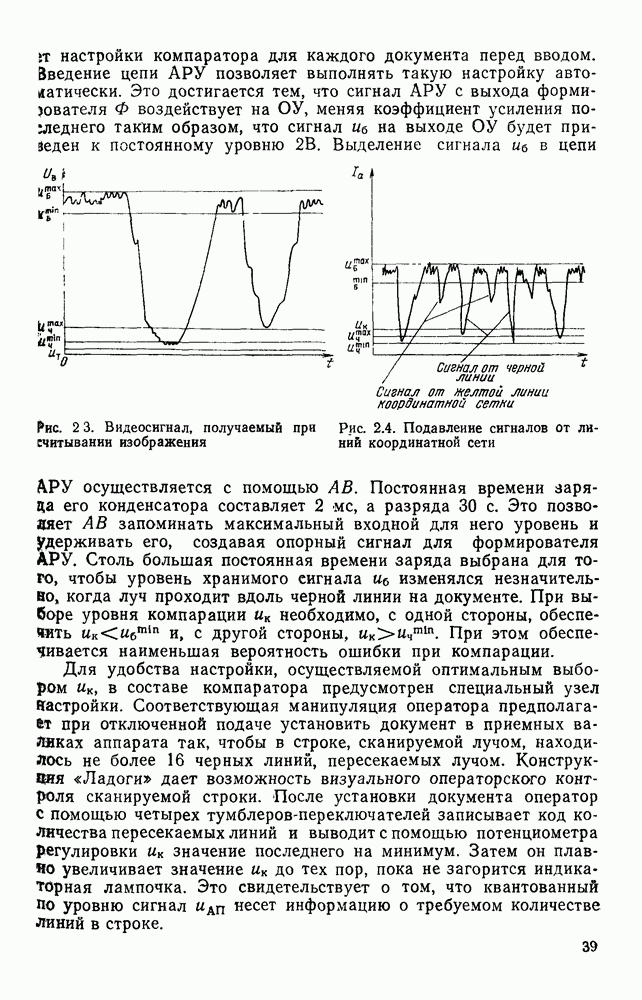
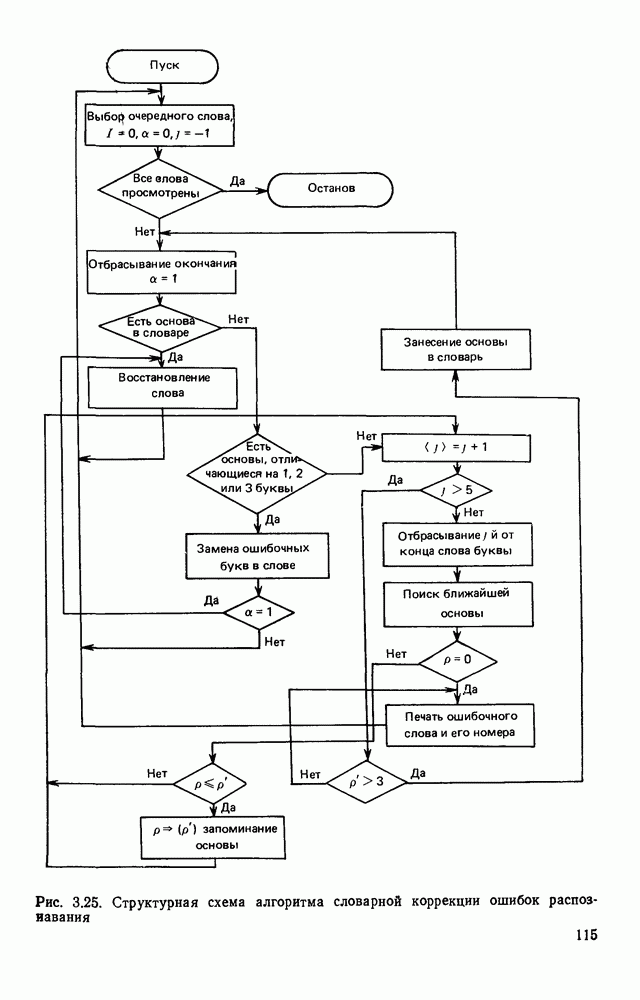
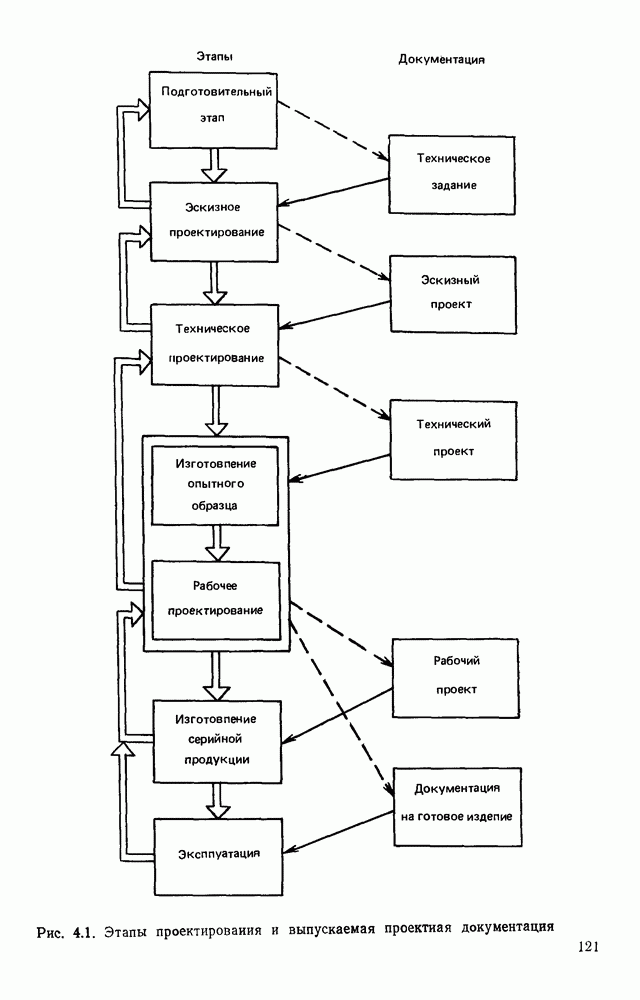
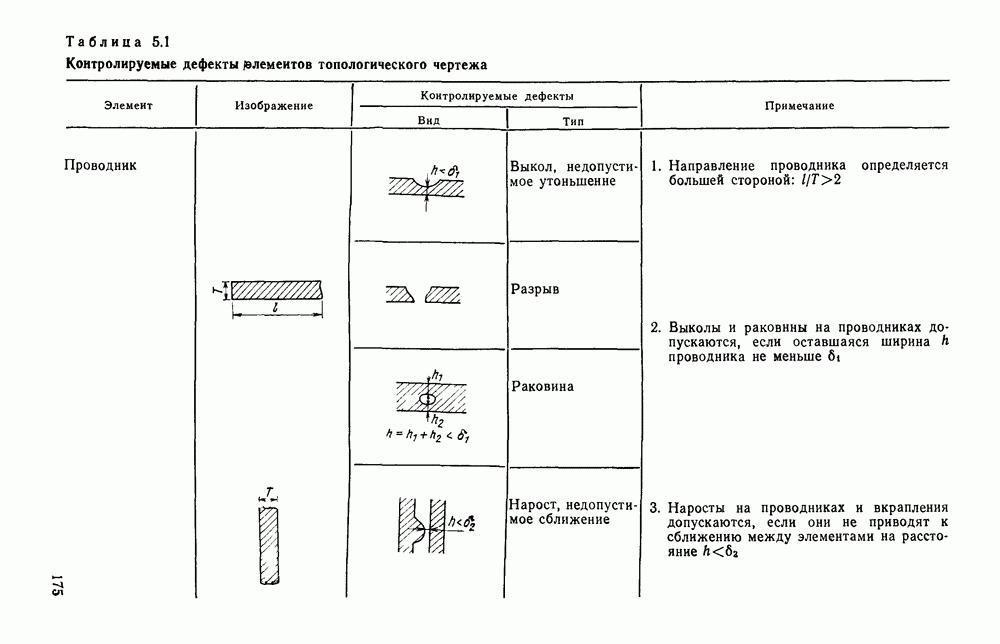
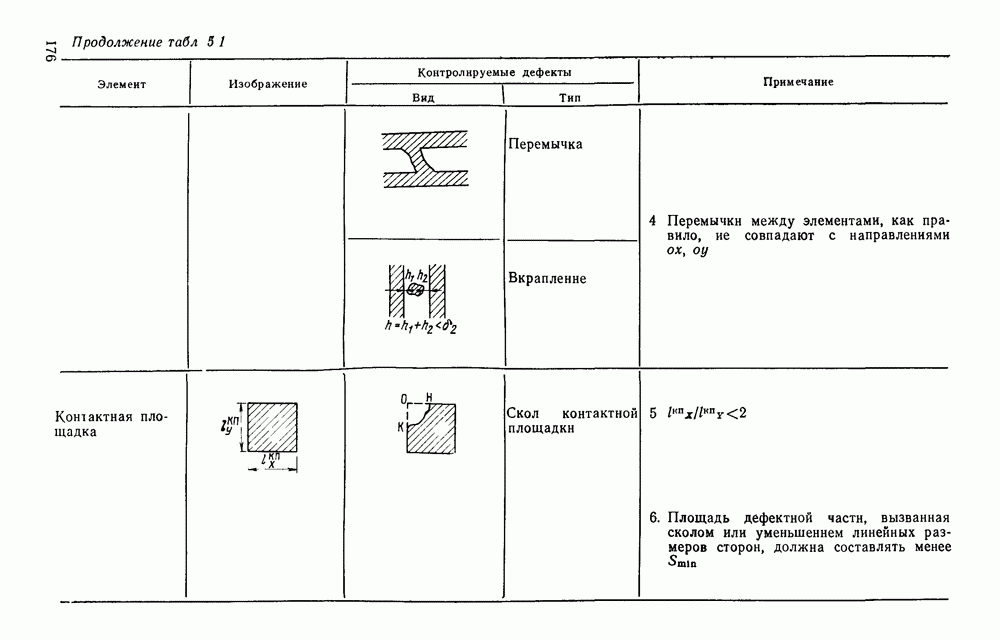
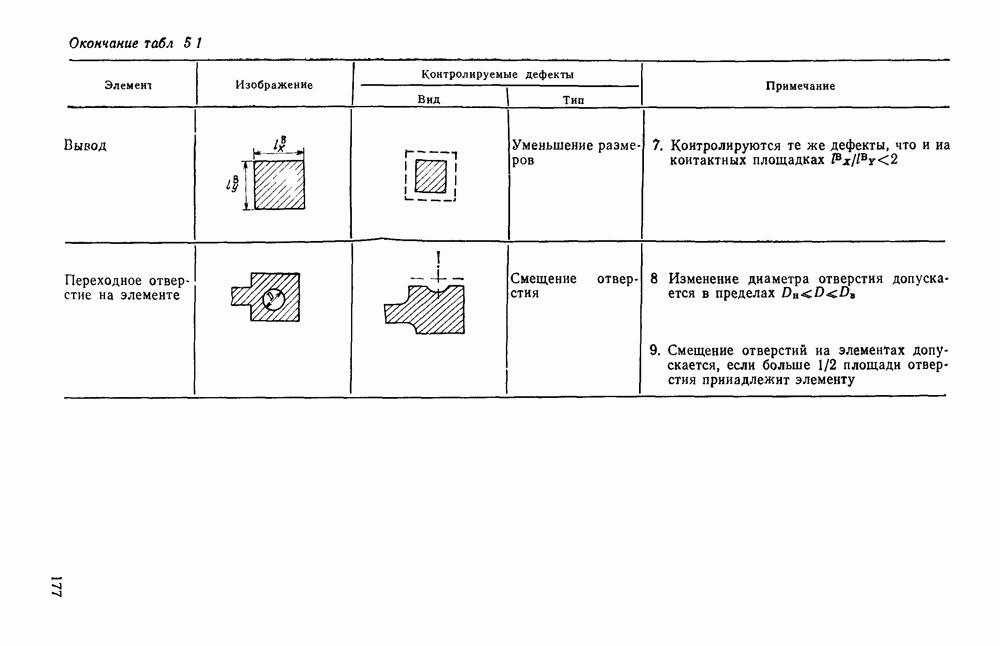
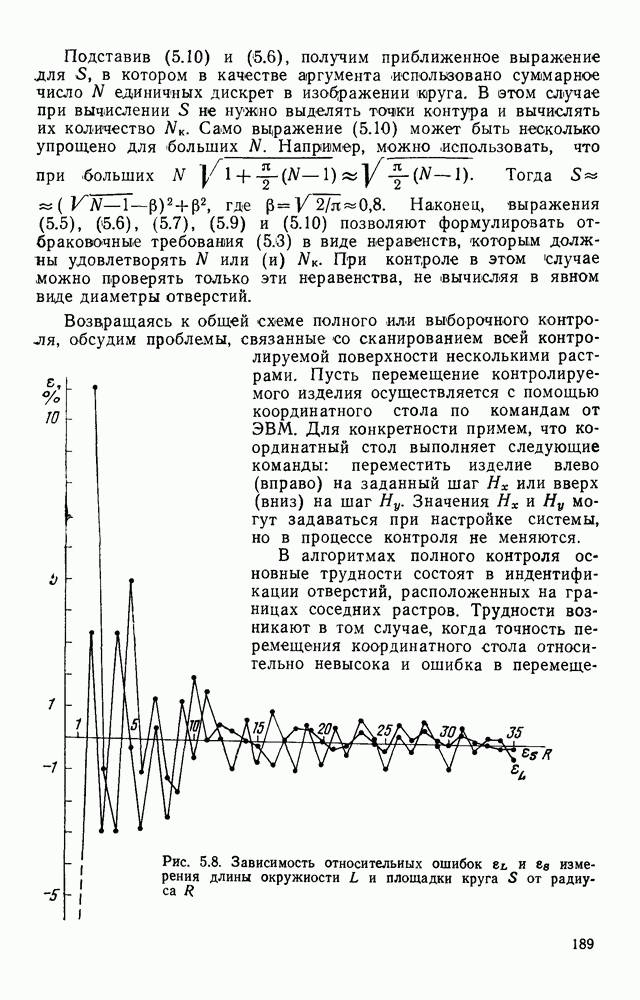
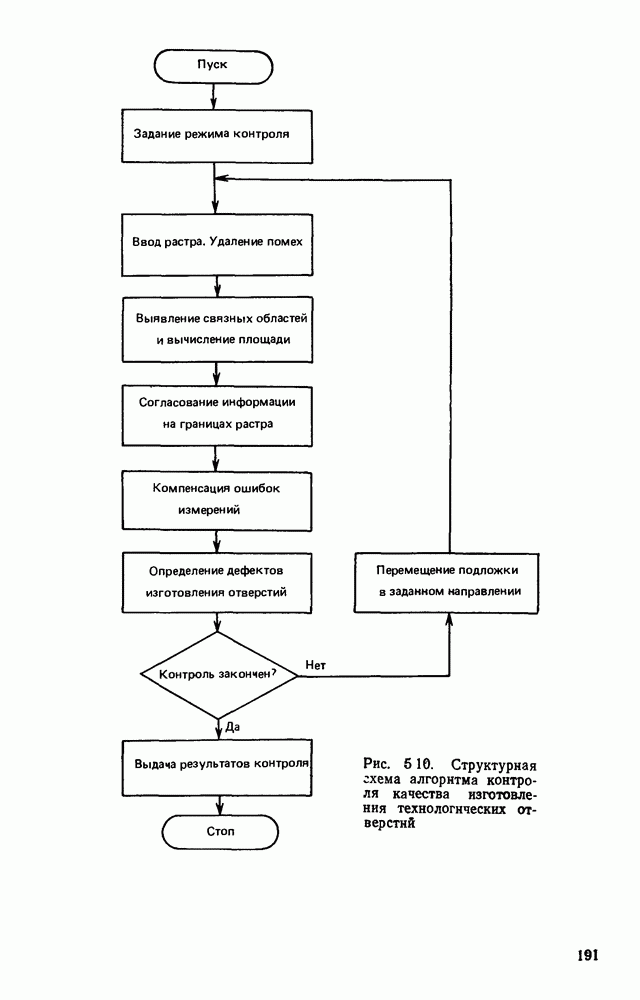
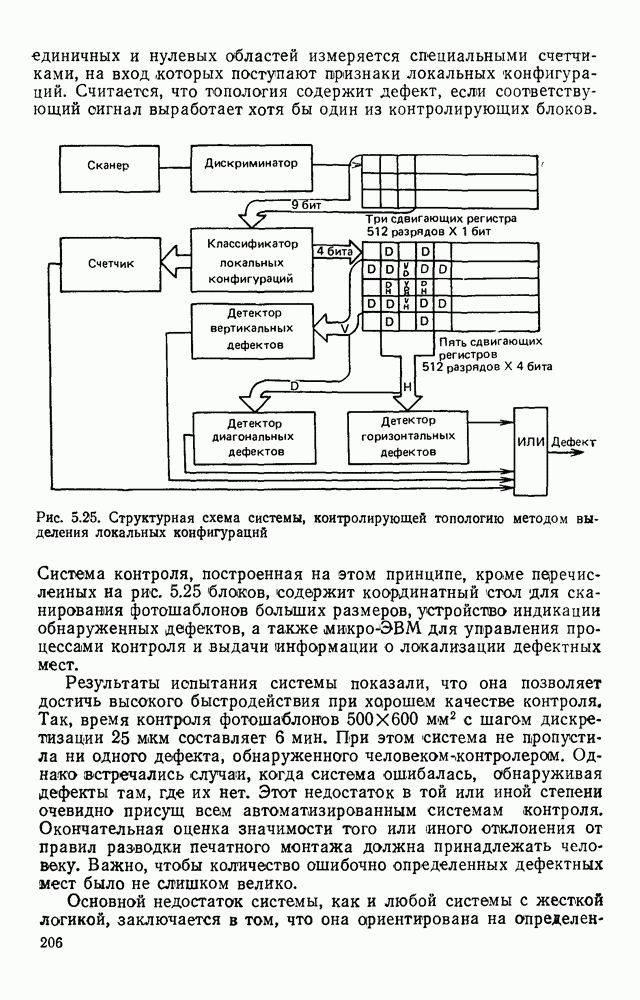
4.4. УНИВЕРСАЛЬНЫЙ ЭТАП ОБРАБОТКИ ИЗОБРАЖЕНИИ, АВТОМАТИЧЕСКИ СЧИТАННЫХ С КОНСТРУКТОРСКИХ ДОКУМЕНТОВОбработка изображений представляет собой многоэтапный процесс информационного преобразования, в ходе которого осуществляется последовательный переход от одной формы описания к другой. В качестве дискретной первичной формы (ДПФ) будем рассматривать черно-белую мозаику, получаемую в памяти ЭВМ с помощью аппаратных средств, например, таких, как описано в § 2.1. Поскольку большая часть изображений производственных черно-белых документов строится с помощью одних и тех же изобразительных средств (линий, символов), то имеет смысл специально выделить этап обработки, целью которого является получение описания отрезков линий, задаваемых координатами его концов, и кодов символов с указанием координат их расположения на поле изображения. Такой этап необходимо реализовать для всех документов и поэтому его можно назвать универсальным в отличие от последующих этапов, узкоспециализированных для каждого типа документа. Результирующая форма для универсального этапа обработки, которую мы назовем дискретной вторичной (ДВФ), состоит из списка отрезков и списка символов. Запись первого списка состоит из полей, предназначенных для задания координат концов отрезков, а поля записи второго списка служат для координатной привязки символа к полю документа и указания кода символа. С учетом размеров документов (форматы от 11 до 24 включительно) и при разрешающей способности сканера, обеспечивающего не более 10 отсчетов на миллиметр, длина записи первого типа составляет 8 байт, второго — 6 байт. Таким образом, универсальный этап должен обеспечить распознавание символов и разделение несимвольной части изображения на отдельные элементарные отрезки. Названные две задачи столь разнородны, что целесообразно перед их решением разложить изображение на символьную и несимвольную части, чтобы каждую из них подвернуть своей специфической обработке. Появление в перечне основных задач универсального этапа задачи отделения символов заставляет исследовать пригодность ДПФ как исходной формы для решения, в первую очередь, задачи отделения. Отделение символов в ДПФ.Задача отделения символов из «сходной матрицы I, описывающей изображение в ДПФ, сводится к нахождению в исходной матрице фрагментов документа, которые содержат символы. Каждый такой фрагмент затем переписывается До сих пор все рассуждения опирались на интуитивное понятие символа, которое существует в сознании каждого человека. Прежде чем отделить какой-либо символ человек решает задачу распознавания. Мы не можем пойти по пути моделирования этого процесса, так как не знаем его сути. Для построения алгоритма отделения необходимо такое определение символа, которое позволило бы эффективно решить поставленную задачу. Назовем группой единиц множество единиц в одной строке матрицы, не разделенных нулями. Две группы единиц, лежащие в соседних строках изображения, с координатами концов по оси абсцисс а, b и с, d называются связными, если справедливо хотя бы одно из соотношений:
На рис. 4.12, а приведены примеры связных групп единиц, а на рис. 4.12,б — несвязных. Под символом будем понимать множество связных групп единиц, минимальный охватывающий прямоугольник которых имеет размеры, принадлежащие интервалам размеров символов по высоте и ширине (рис. 4.13). Использование такого определения символа создает риск отделения части несимвольной информации При анализе таких фрагментов изображения блок распознавания с большой вероятностью примет решение, что связная конфигурация, записанная в матрице, не является символом Вероятность ошибки такого типа на этапе отделения символов невелика Воспользуемся приведенным выше определением символов для построения алгоритма отделения. Для решения поставленной задачи необходим однократный просмотр матрицы I с целью выявления связности между группами единиц и получения информации о том, что связные конфигурации по размерам не превышают размеры символов. Проверка связности, осуществляемая на основании соотношений (4.1), достаточно проста.
Рис. 4.12. Отношение связности групп единиц: а — связные группы, б — несвязные группы Для фиксации результатов такого просмотра используются маски, каждая из которых представляет собой область прямоугольной формы, состоящую из единиц, на поле масок М. Поле масок представляет собой двоичную матрицу, совпадающую по размерам с исходным полем изображения I. При совмещении поля изображения с полем масок каждая маска покрывает фрагмент поля I, содержащий связную конфигурацию единиц. Каждая маска для выделяемой с
Рис. 4.13. Символ как фрагмент связных групп единиц ее помощью конфигурации имеет минимальные размеры, т. е. играет роль минимального охватывающего прямоугольника. Проверка метрических ограничений, накладываемых на связные конфигурации, которые трактуются как символы, осуществляется довольно просто, когда в нашем распоряжении имеется соответствующая маска. Рассмотрим алгоритм Структурная схема алгоритма При достаточно больших размерах строки М каждая строка упаковывается в группу машинных слов (обычно 16 или 32 двоичных разряда). Алгоритм Здесь операция связывания двух соседних слов
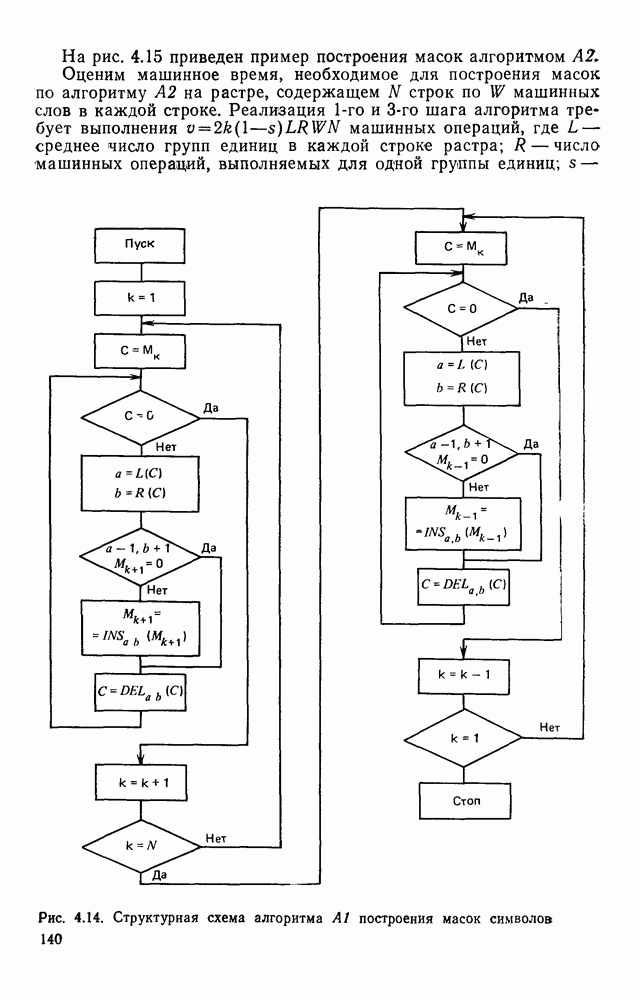
На рис. 4.15 приведен пример построения масок алгоритмом Оценим машинное время, необходимое для построения масок по алгоритму (см. скан) Рис. 4.14. Структурная схема алгоритма (см. скан) Рис. 4.15. Построение масок алгоритмом Для выполнения
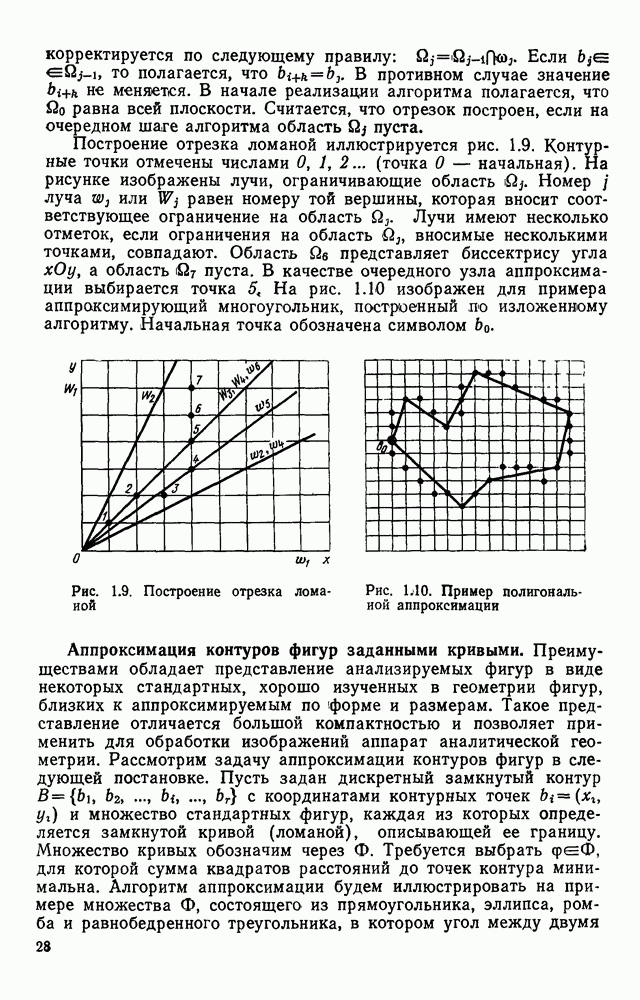
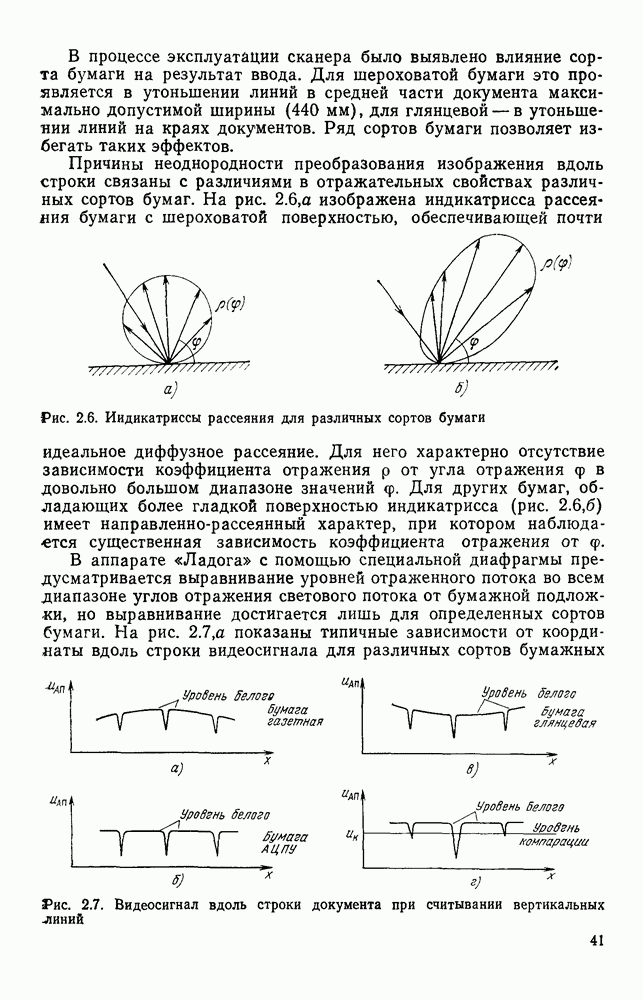
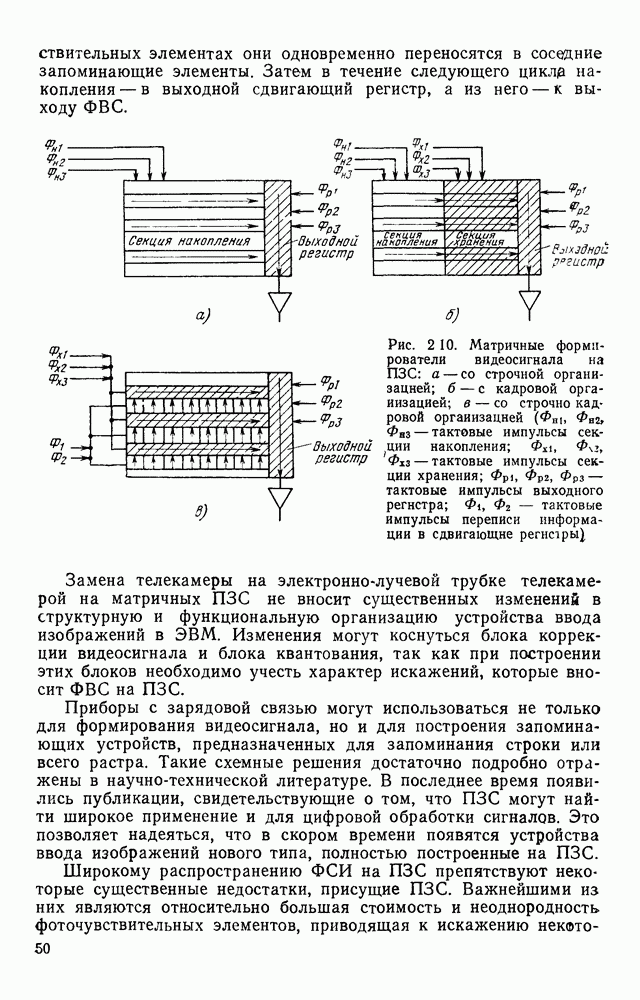
Оценки быстродействия процесса разделения информации на символьную и несимвольную при использовании в качестве исходных данных ДПФ показывают, что временные затраты при этом получаются достаточно существенные. Кроме того, в ряде случаев взаимного расположения соседних символов, характерного для ручного исполнения документа, задача вышеописанным методом не решается. Попытка обобщить метод разделения на случай документов, на поле которых присутствуют фрагменты несимвольной информации, приводит к алгоритму с еще более низким быстродействием. Более подходящей для решения задания разделения изображения на символьную и несимвольную части является полигональная форма (ПФ) описания изображения. Полигональная форма.Эта форма представляет собой совокупность граничных контуров (ГК), которые в дальнейшем будем обозначать В ГК углы упорядочены правым обходом черно-белой границы, т. е. таким, при котором черная область всегда расположена справа по отношению к направлению обхода. Нумерация лучей угла также определяется этим обходом. На рис. 4.16 представлен фрагмент ДПФ, в котором черные элементы отмечены крестами. Явно показаны углы
Рис. 4 16. Дискретная первичная форма: а — фрагмент формы; б — таблица значений параметров элементов граничного контура Достоинством полигональной формы является то, что она, по сравнению с широко применяемым скелетным описанием [24], не привносит искажений, которые могут затруднить дальнейшую обработку и привести к ошибкам или отказам, например на этапе распознавания символов. Форма ПФ является универсальной. Она очень легко позволяет выделить наиболее информативные признаки изображения типа резких изгибов границ черной и белой областей. Кроме того, ПФ существенно более экономна с точки зрения затрат памяти по сравнению с ДПФ. Для подтверждения сказанного можно привести следующие оценки, полученные нами при экспериментальном обследовании реальных производственных документов. Соотношение объема памяти, используемой для представления документов в полигональной форме, по отношению к аналогичному показателю для случая ДПФ составляет для документа типа: эскиза слоя топологии платы печатного монтажа — 0,03; принципиальной электрической схемы — 0,05; машиностроительного эскиза — 0,08; текстового — 0,13. Не затрагивая в этом параграфе вопросов построения ПФ, исходя из ДПФ, перейдем к описанию процессов решения задачи отделения символов и разложения несимвольной части изображения на элементарные отрезки. В литературе отсутствуют публикации по этой тематике для случая, когда исходная форма полигональная. Задача распознавания символов, исходя из ПФ, решена в [54] и поэтому в настоящей работе не рассматривается. Отделение символов.Проблема отделения символов формулируется как задача отбора из ПФ тех К символьным Очевидно, что проверка любого Разделение несимвольного фрагмента на элементарные отрезки.Начнем с ациклических фрагментов, т. е. таких, разрыв линии которых в любом месте нарушает его связность. Очевидно, что черно-белая граница такого фрагмента описывается одним Если рассмотреть пример любого ациклического фрагмента, например, изображенного на рис. 4.17, а, то легко заметить, что в областях рассечения фрагмента на элементарные отрезки (рис. 4.17,б) расположены пары близко размещенных элементов из ГК. В рассматриваемом случае эти пары
Рис. 4.17. Рассечение на элементарные отрезки ациклического фрагмента изображения, описанного в полигональной форме Введем ряд понятий, отношений и операций, полезных для более четкого изложения. Скобки вида
Операция разделения граничного контура g парой
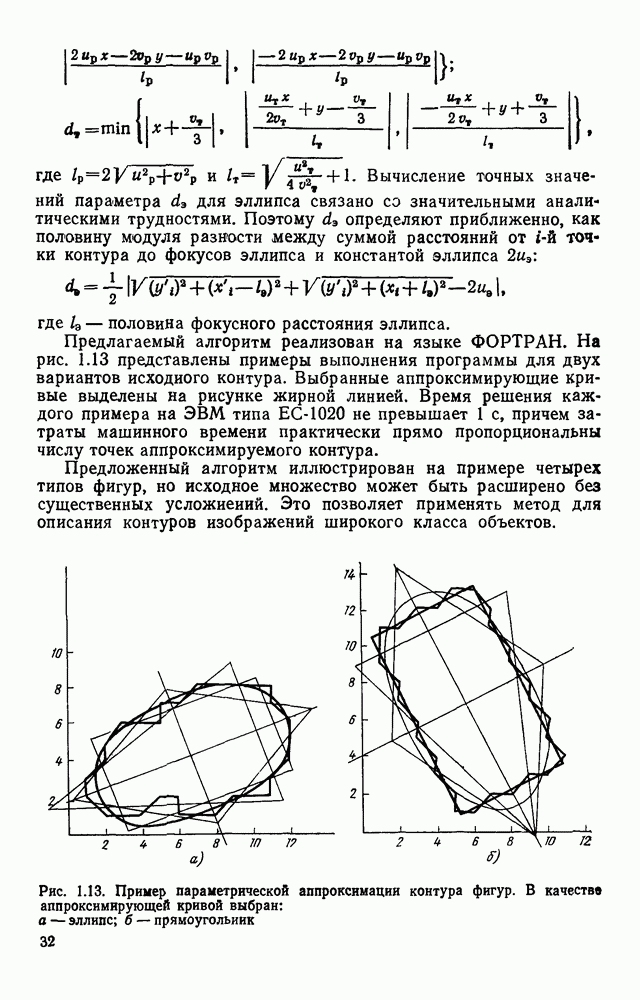
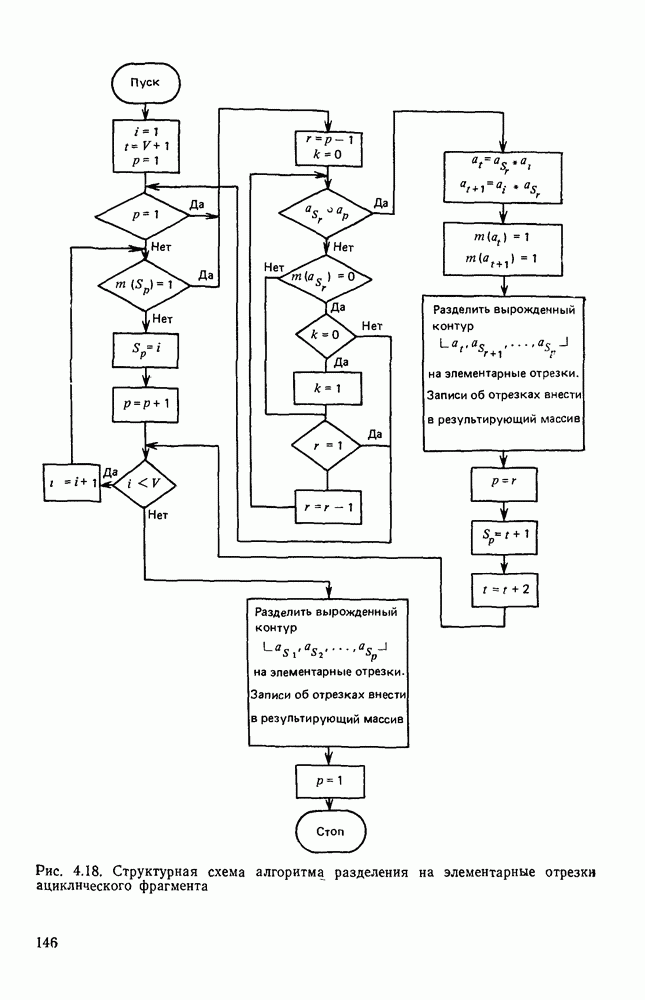
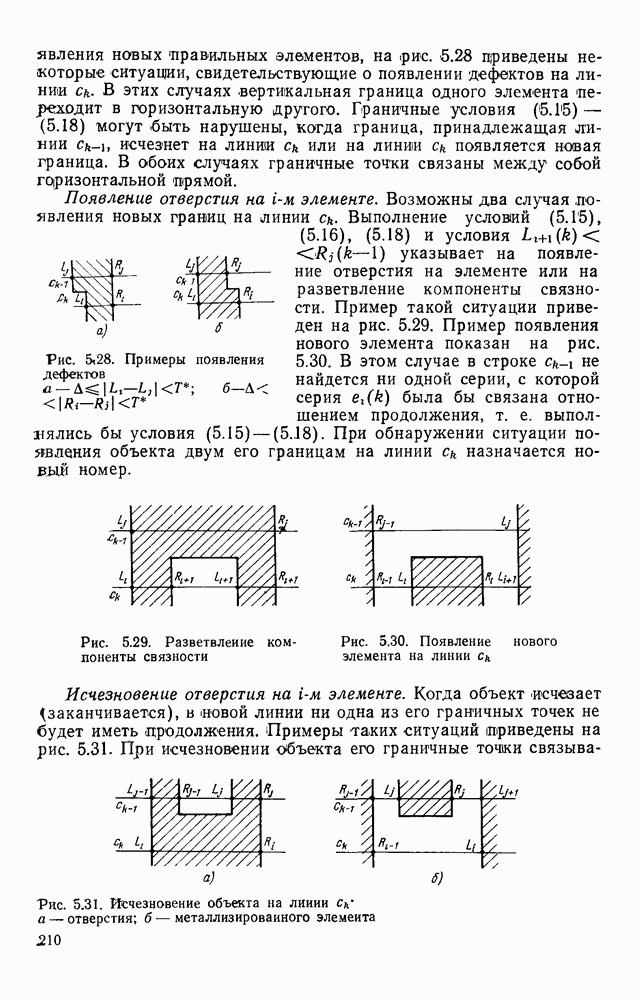
Введем в рассмотрение функцию метки полигональной формы, а областью значений 0 и 1. Значением 1 отмечаются номера тех элементов, которые были синтезированы в процессе разделения фрагмента на элементарные отрезки, а значением 0 снабжаются номера элементов, заданных к началу процесса разделения. Назовем g вырожденным, если в нем отсутствует пара элементов, для которой Для организации процесса разделения на элементарные отрезки используется стек S с указателем верхушки Обработка осуществляется таким образом, что при любом шаге разделения текущего ГК второй остаток представляет собой вырожденный ГК. Его элементы удаляются из стека и подвергаются особой процедуре разложения на элементарные отрезки. Первый остаток разделения рассматривается теперь как текущий ГК. Его просмотренная часть находится в стеке, а непросмотренная совпадает с частью исходного для всего процесса разложения ГК, начиная с Для того чтобы минимизировать перебор, поиск близких пар для Структурная схема алгоритма разбора фрагмента, реализующего метод последовательного отсечения прямолинейных отрезков, описанный выше, представлена на рис. 4.18. Разбор вырожденного ГК осуществляется достаточно просто и начинается с отыскания концевого элемента Приведенный выше алгоритм решает задачу разложения ациклического фрагмента на элементарные отрезки при следующих условиях: в исходной ГК отсутствует элемент а, не являющийся концевым, для которого не существует в ГК близкого, отличного (см. скан) Рис. 4.18. Структурная схема алгоритма разделения на элементарные отрезки ациклического фрагмента от него самого элемента; элементы любой пары элементов из ГК, принадлежащих к одному и тому же узлу, находятся в отношении близости. Нарушение первого из этих условий в принципе возможно для случаев, когда угол близок к 180°. Это может быть следствием ошибки измерения угла, равного 180°, либо влиянием малых краевых помех на границе черного и белого (бахромы). Незначительное видоизменение алгоритма, придающее ему фильтрующие свойства, позволяет исключить неприятный эффект воздействия подобного рода помех. Выбор слишком большого Т создает риск ошибочного отнесения двух угловых элементов контура к одному и тому же узлу. Анализ нормативных правил исполнения документов дает возможность выявить максимальное пороговое значение Т близости для угловых элементов контуров. Два угловых элемента, расстояние между которыми не превышает Т, относят к одному узлу; в противном случае относиться к одному узлу они не могут. Выбор Т в соответствии с такими принципами гарантирует выполнение второго условия. Рассмотрим ситуацию циклического фрагмента. В этом случае, в отличие от ациклического описания, требуется более, чем один ГК. Сведем задачу разложения на элементарные отрезки циклического фрагмента. Для этого достаточно ввести в каждый цикл фрагмента искусственный разрез, что позволяет объединить пару граничных контуров На рис. 4.19, а представлен фрагмент, описание которого состоит из двух ГК:
На рис. Подходящим типом искусственного разреза будет такой, который выполняется в области размещения двух элементов
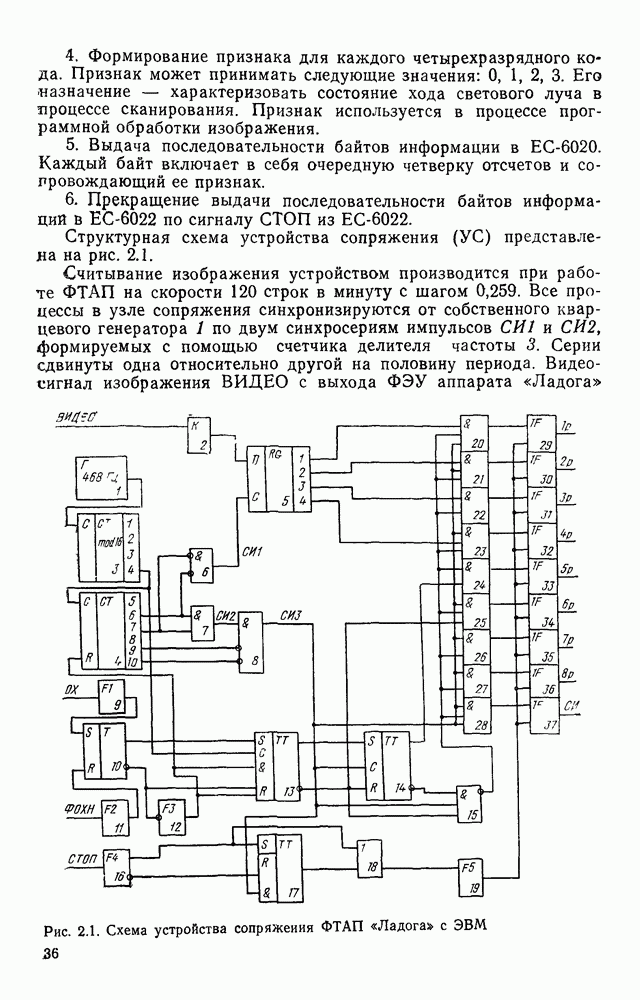
Для фрагмента на рис. 4.19, в введение искусственного разреза в области Оценка быстродействия предложенных алгоритмов.Вначале определим количество машинных операций, необходимых для выполнения основных процедур: синтез угла — 24 операции; проверка близости углов — 12 операций; засылка в стек — 4 операции; обработка тривиального второго остатка — 20 операций. Затем в тех же единицах определим объем вычислений при обработке таких объектов, как изгиб линии (100 операций); узел, из которого выходят три линии (200 операций); узел, из которого выходят четыре линии (300 операций), и т. д.
Рис. 4.19. Введение разреза в циклический фрагмент изображения Например, для изгиба линии оценка получена на том основании, что при обработке такого элемента изображения приходится синтезировать два угла, осуществлять две засылки в стек, выполнять обработку второго остатка (с большой вероятностью тривиального, как показывает опыт изучения реальных документов) и т. д. Будем называть порядком узла число линий, исходящих из него. Располагая оценками для объемов вычислений, выполняемых при обработке узлов различных порядков в несимвольной части изображения (изгиб будем раесматривать Для фрагмента реальной электрической принципиальной схемы, изображенной на рис. 4.20 Реальная принципиальная схема (формат листа 12), реализуемая в виде одного типового элемента замены (ТЭЗ), может содержать десяток подобных фрагментов и некоторые фрагменты изображения, описывающие входные и выходные сигналы (рис. 4.20, б). Предположим, что трудоемкость описаний входных и выходных сигналов не превышает трудоемкости остальной части.
Рис. 4.20. Фрагменты изображений на принципиальной электрической схеме Тогда с учетом оказанного общий объем вычислений оценивается примерно 140 тыс. машинных операций. Если ориентироваться на быстродействие процессоров современных мини- и микро-ЭВМ, то время обработки составляет около 1 с либо десятых секунды. Время реализации программы отделения символов и разделения несимвольной части изображения на элементарные отрезки, которая построена на основе вышеописанных алгоритмов, соответствует приведенным оценкам.
|
 |
Оглавление
|

























































































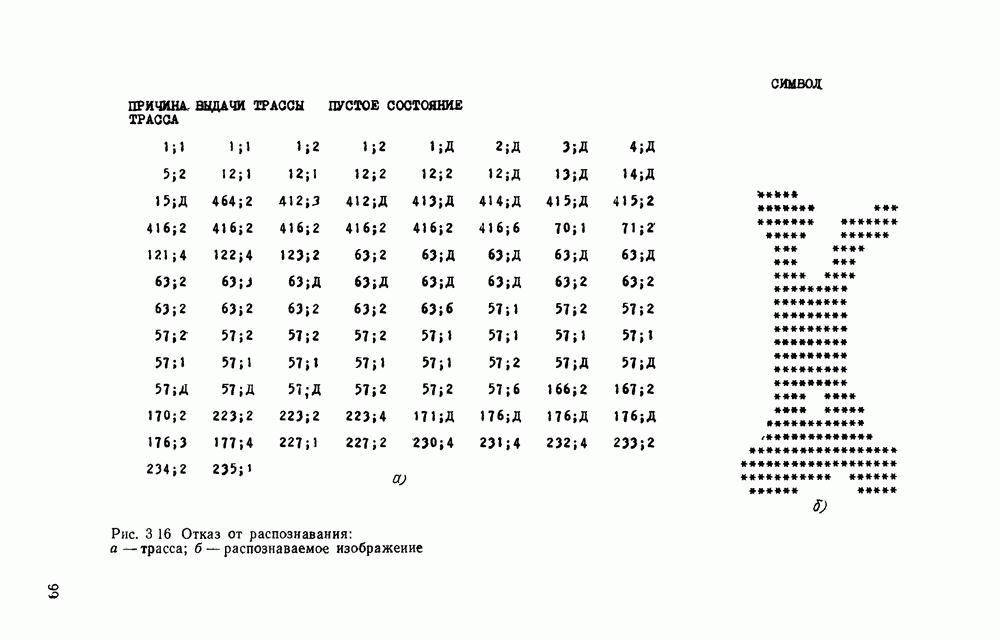
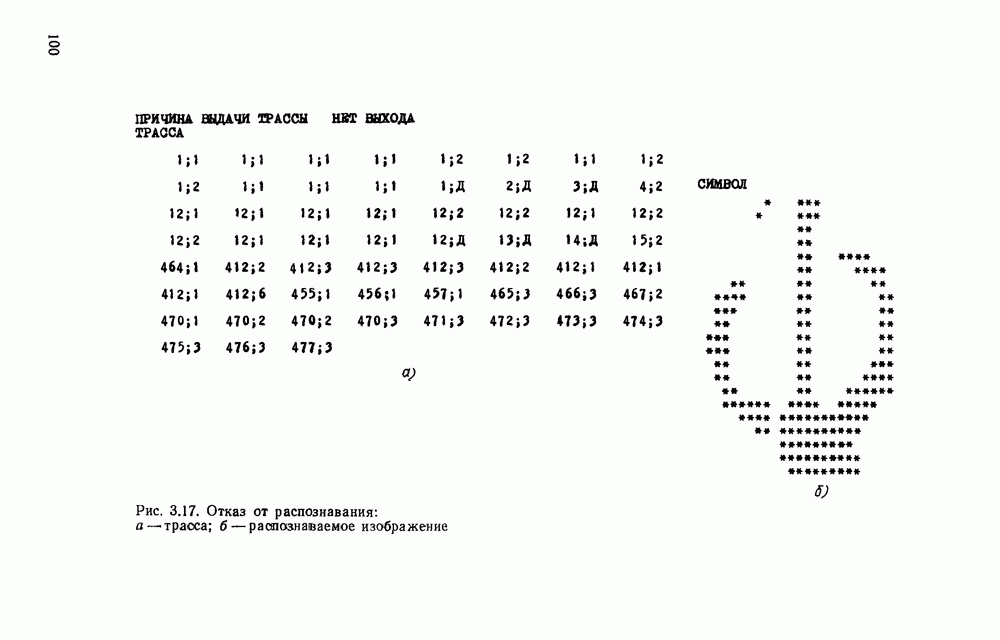
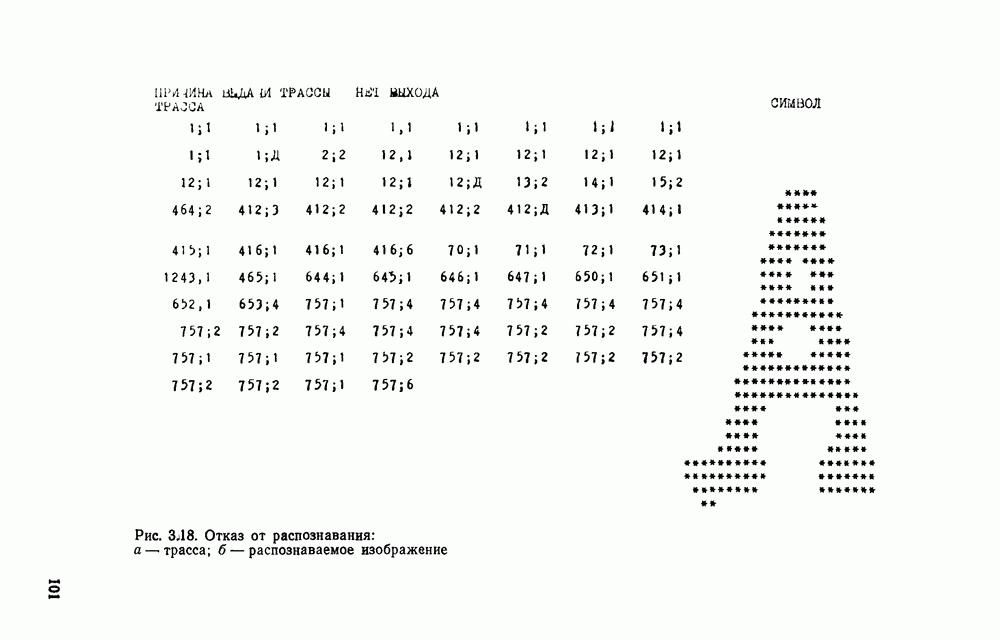
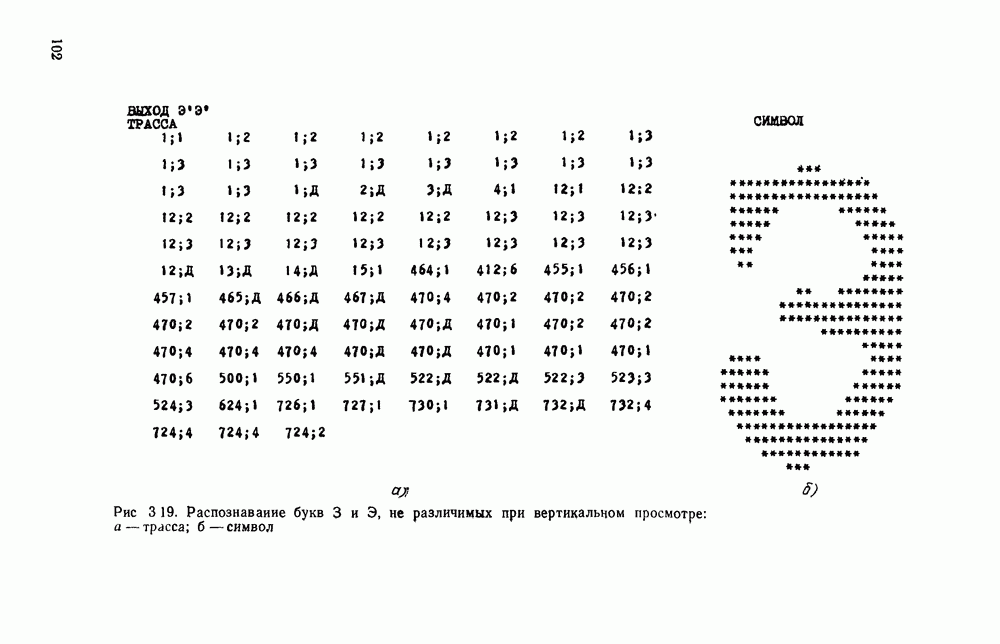
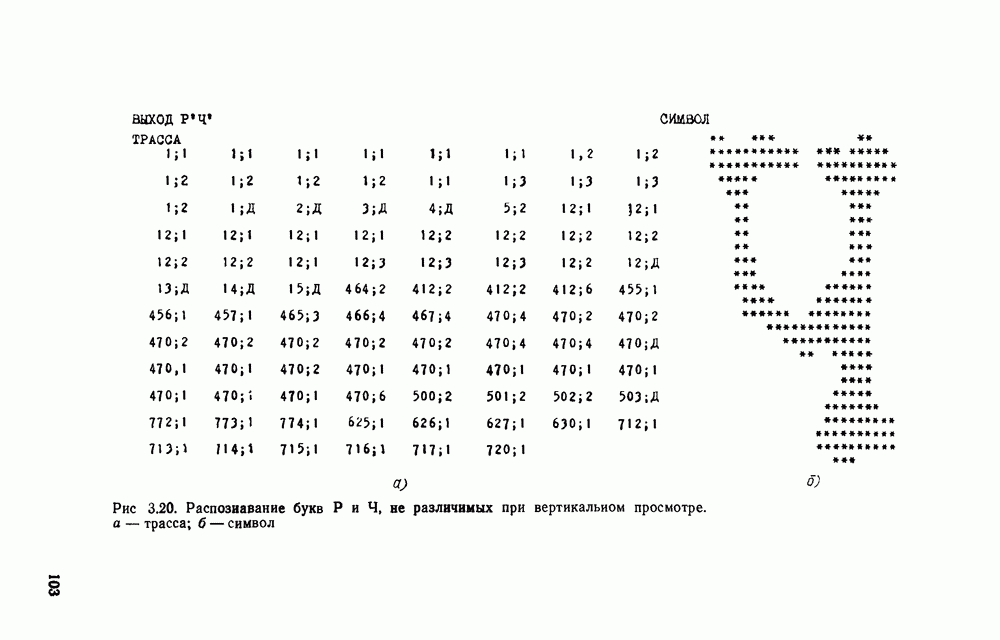

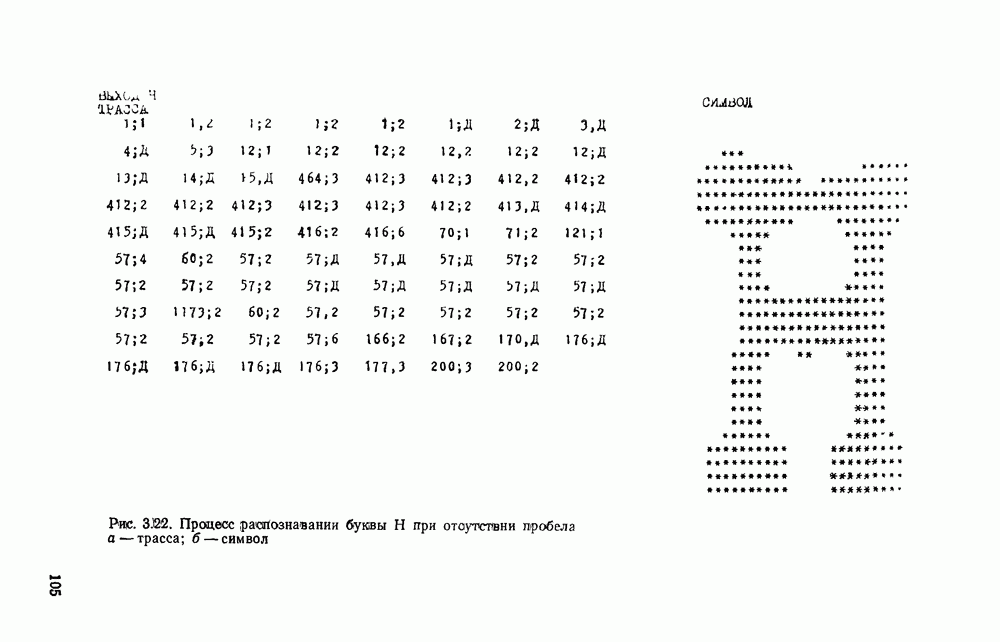
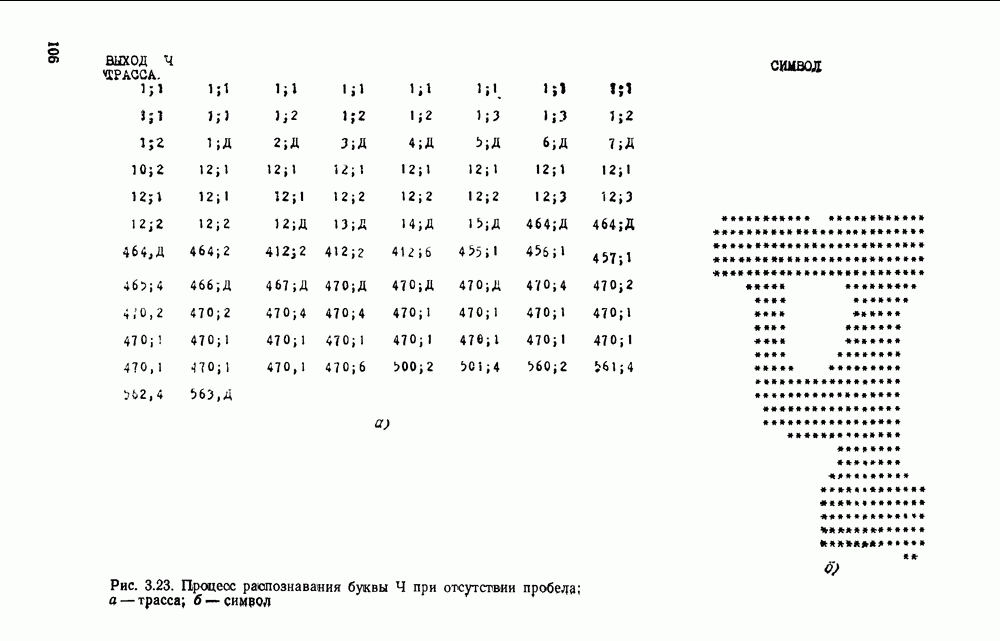


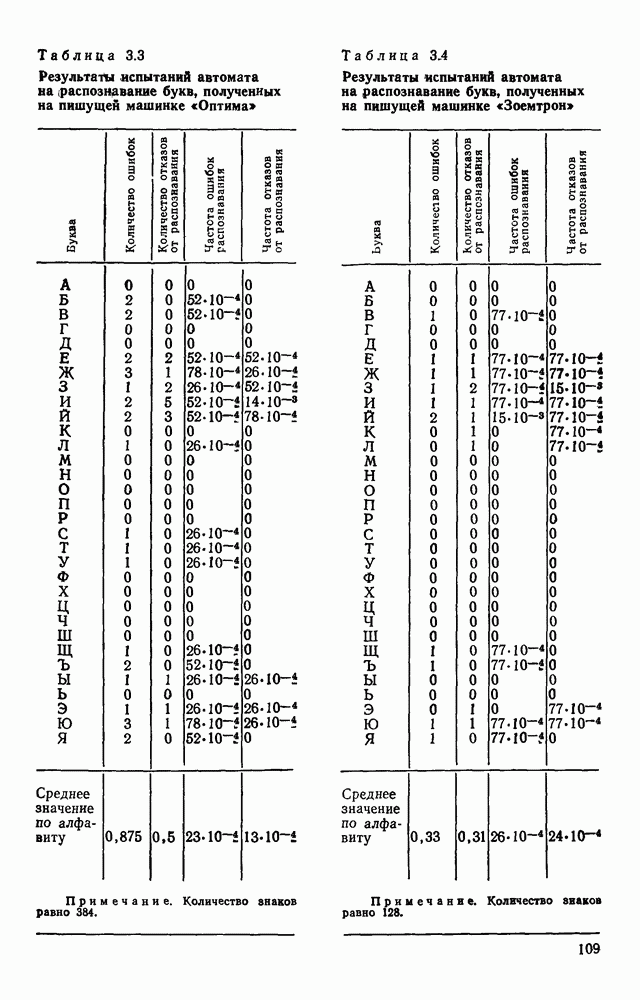

















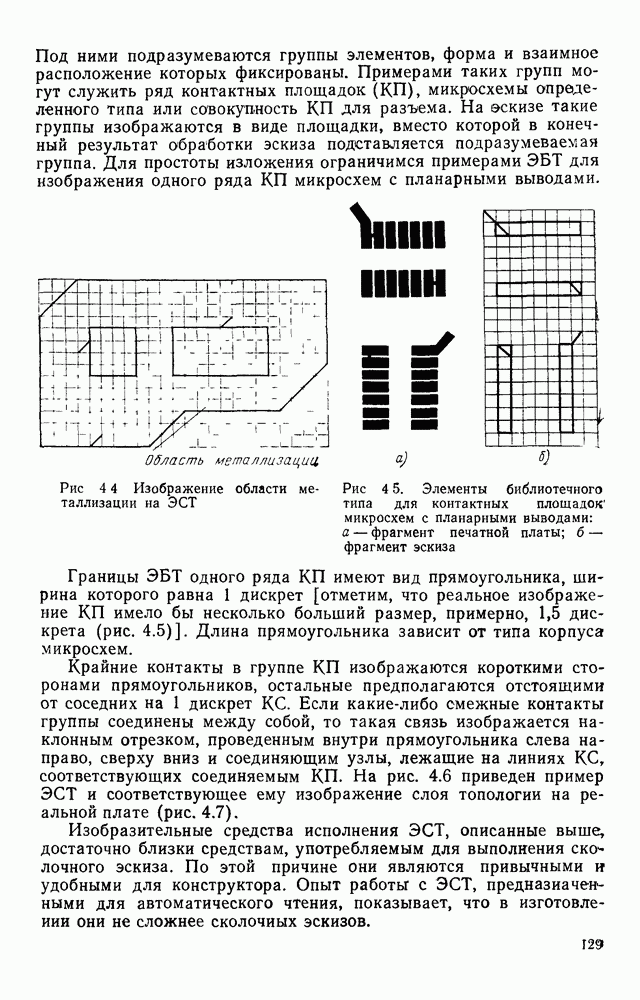























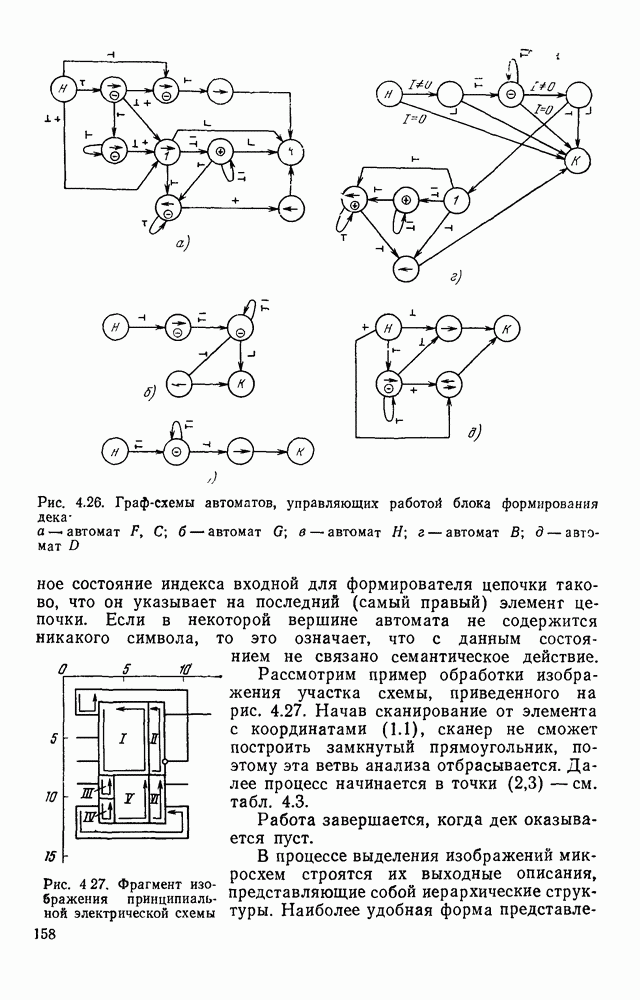
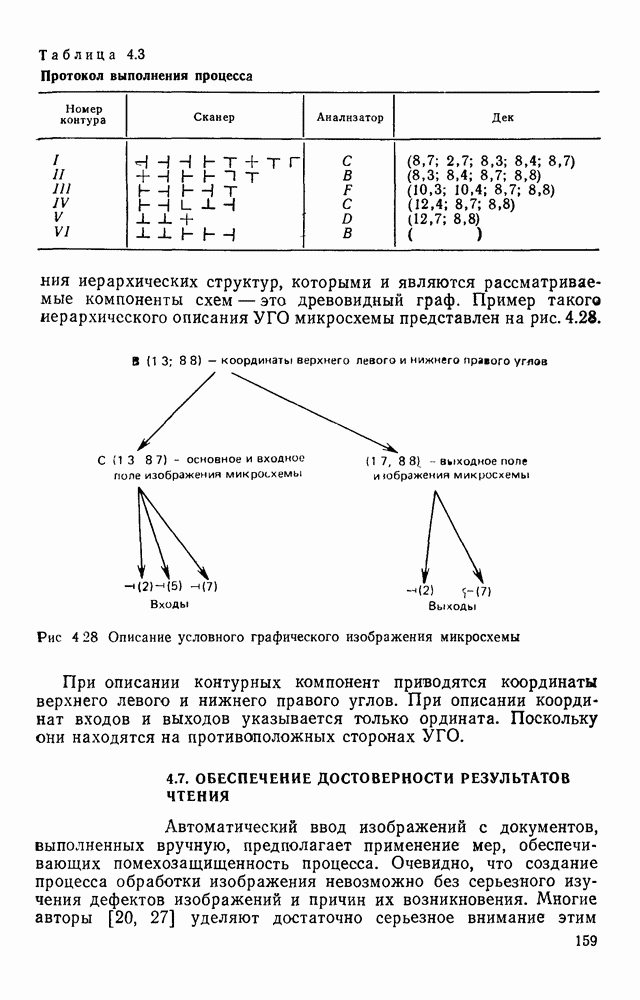

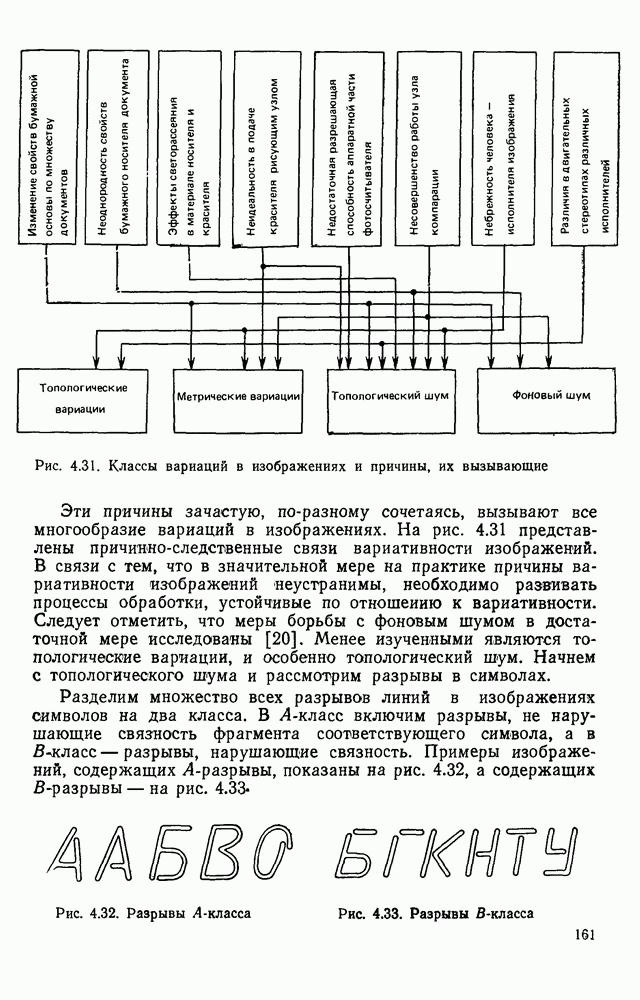



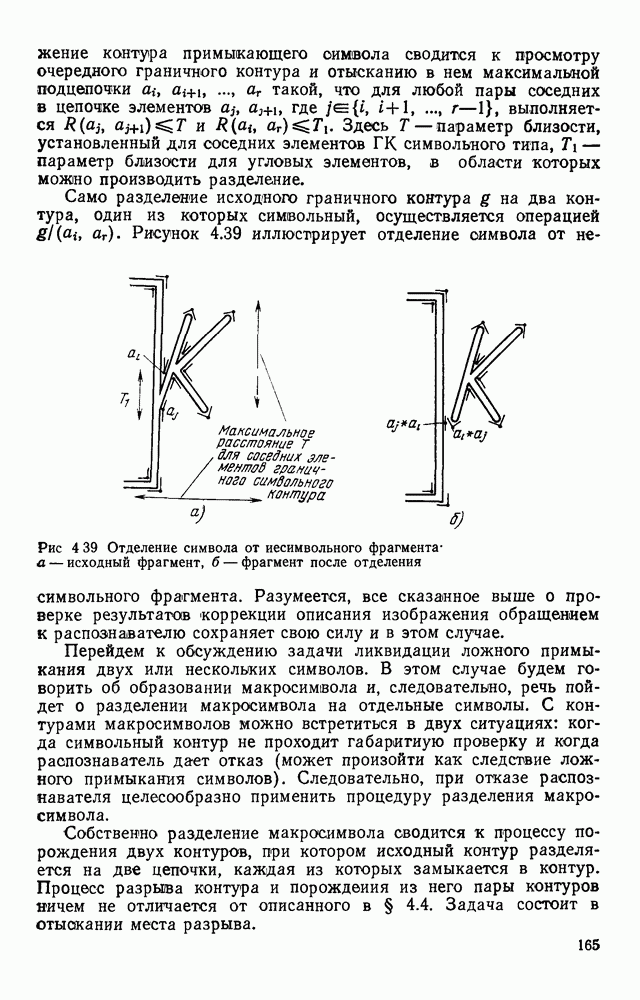




























































 отдельный кадр, представляющий собой двоичную матрицу, размеры которой должны быть не меньше максимальных размеров символов. Далее содержимое этих матриц будет анализироваться блоком распознавания.
отдельный кадр, представляющий собой двоичную матрицу, размеры которой должны быть не меньше максимальных размеров символов. Далее содержимое этих матриц будет анализироваться блоком распознавания.



 построения масок для случая документа, содержащего лишь строки символов. Введем следующие обозначения: k — содержимое счетчика строк матрицы М; N — число строк матрицы М;
построения масок для случая документа, содержащего лишь строки символов. Введем следующие обозначения: k — содержимое счетчика строк матрицы М; N — число строк матрицы М;  строка матрицы М;
строка матрицы М;  — номер левой крайней единицы двоичного вектора С;
— номер левой крайней единицы двоичного вектора С;  -номер правой крайней единицы в левой группе единиц двоичного вектора С;
-номер правой крайней единицы в левой группе единиц двоичного вектора С;  - операция инверсии значений компонент С двоичного вектора С, для которых
- операция инверсии значений компонент С двоичного вектора С, для которых  — операция замены значений компонент
— операция замены значений компонент  двоичного вектора С на единичные, где
двоичного вектора С на единичные, где  — отношение, заключающееся в равенстве нулю каждой компоненты двоичного вектора С;
— отношение, заключающееся в равенстве нулю каждой компоненты двоичного вектора С;  — отношение
— отношение  Здесь а, b — целые положительные числа, для которых
Здесь а, b — целые положительные числа, для которых 
 изображена на рис. 4.14. Операторы DEL, INS, операторы нахождения значений
изображена на рис. 4.14. Операторы DEL, INS, операторы нахождения значений  к проверки отношений
к проверки отношений  достаточно просто реализуются, когда строка матрицы М (вектор С) упаковывается в одно машинное слово памяти. Будем считать, что эти операторы реализованы именно для такого случая. Тогда алгоритм
достаточно просто реализуются, когда строка матрицы М (вектор С) упаковывается в одно машинное слово памяти. Будем считать, что эти операторы реализованы именно для такого случая. Тогда алгоритм  решает задачу построения масок, когда строка матрицы М упаковывается в одно машинное слово.
решает задачу построения масок, когда строка матрицы М упаковывается в одно машинное слово.
 для такой матрицы строит маски в пределах вертикальных полос шириной в одно слово. Для того чтобы строились маски в матрице М целиком, необходимо модифицировать алгоритм
для такой матрицы строит маски в пределах вертикальных полос шириной в одно слово. Для того чтобы строились маски в матрице М целиком, необходимо модифицировать алгоритм  дополнив его действиями по установлению связи между словами соседних полос. В результате получаем алгоритм
дополнив его действиями по установлению связи между словами соседних полос. В результате получаем алгоритм  состоящий из следующей последовательности операций: реализовать алгоритм
состоящий из следующей последовательности операций: реализовать алгоритм  связать соседние слова в каждой строке матрицы М, реализовать алгоритм
связать соседние слова в каждой строке матрицы М, реализовать алгоритм  конец.
конец.
 принадлежащих одной строке
принадлежащих одной строке  матрицы М заключается в изменении значений старшей компоненты
матрицы М заключается в изменении значений старшей компоненты  слова
слова  и младшей компоненты
и младшей компоненты  слова
слова  по следующему правилу:
по следующему правилу:


 на растре, содержащем N строк по W машинных слов в каждой строке. Реализация 1-го и 3-го шага алгоритма требует выполнения
на растре, содержащем N строк по W машинных слов в каждой строке. Реализация 1-го и 3-го шага алгоритма требует выполнения  машинных операций, где L — среднее число групп единиц в каждой строке растра; R — число машинных операций, выполняемых для одной группы единиц; s —
машинных операций, где L — среднее число групп единиц в каждой строке растра; R — число машинных операций, выполняемых для одной группы единиц; s —
 построения масок символов
построения масок символов
 для изображения на рис. 4.13; матрица М получена после: а — первого, б — второго, в — третьего шага алгоритма
для изображения на рис. 4.13; матрица М получена после: а — первого, б — второго, в — третьего шага алгоритма
 шага алгоритма требуется затратить
шага алгоритма требуется затратить  машинных операций, где z — количество машинных операций, выполняемых при связывании пары соседних слов. Таким образом, общий объем выполняемых машинных операций по алгоритму
машинных операций, где z — количество машинных операций, выполняемых при связывании пары соседних слов. Таким образом, общий объем выполняемых машинных операций по алгоритму  составляет
составляет  Зная быстродействие ЭВМ, можно определить затраты процессорного времени на реализацию алгоритма. Например, при среднем быстродействии 20 000 операций в секунду затраты времени составят
Зная быстродействие ЭВМ, можно определить затраты процессорного времени на реализацию алгоритма. Например, при среднем быстродействии 20 000 операций в секунду затраты времени составят  . Для обработки
. Для обработки  документа потребуется
документа потребуется
 машинного времени, где F — площадь обрабатываемого поля документа. При
машинного времени, где F — площадь обрабатываемого поля документа. При  ; при
; при  ; при
; при  .
.
 . Каждый ГК — это циклическая последовательность углов поворота хода границы между черной и белой областями. В ГК включаются лишь углы, отличные от 180°. Договоримся обозначать углы граничного контура через
. Каждый ГК — это циклическая последовательность углов поворота хода границы между черной и белой областями. В ГК включаются лишь углы, отличные от 180°. Договоримся обозначать углы граничного контура через  Угол
Угол  характеризуется следующим набором параметров: координаты центра угла
характеризуется следующим набором параметров: координаты центра угла  направление
направление  соответственно первого и второго луча; угол
соответственно первого и второго луча; угол 
 привязанные к местам границы между черным и белым, где эта граница меняет свое направление.
привязанные к местам границы между черным и белым, где эта граница меняет свое направление.

 которые описывают ход границы фрагмента изображения символа. Изучение реальных документов показывает, что фрагменты изображения символов гораздо значительнее насыщены неоднородностями хода границы черно-белого, чем фрагменты изображений несимвольной (иногда будем называть ее линейной) части. Этот факт дает возможность предложить достаточно простой критерий для сортировки
которые описывают ход границы фрагмента изображения символа. Изучение реальных документов показывает, что фрагменты изображения символов гораздо значительнее насыщены неоднородностями хода границы черно-белого, чем фрагменты изображений несимвольной (иногда будем называть ее линейной) части. Этот факт дает возможность предложить достаточно простой критерий для сортировки  входящих в ПФ, на символьные и несимвольные.
входящих в ПФ, на символьные и несимвольные.
 будем относить такой граничный контур, для любых двух соседних элементов
будем относить такой граничный контур, для любых двух соседних элементов  которого выполняется
которого выполняется  где
где  — расстояние между центрами углов
— расстояние между центрами углов  — некоторая константа, определяемая максимальным линейным размером символа, допускаемым на документе.
— некоторая константа, определяемая максимальным линейным размером символа, допускаемым на документе.
 на принадлежность его множеству символьных ГК осуществляется одним проходом по циклически упорядоченной совокупности его элементов и не создает никаких трудностей при построении соответствующего алгоритма. Высокое быстродействие такой проверки также не вызывает никаких сомнений.
на принадлежность его множеству символьных ГК осуществляется одним проходом по циклически упорядоченной совокупности его элементов и не создает никаких трудностей при построении соответствующего алгоритма. Высокое быстродействие такой проверки также не вызывает никаких сомнений.
 .
.
 Отметим, что по крайней мере двум элементарным отрезкам, на которые разлагается фрагмент, в его полигональном описании соответствуют последовательности из
Отметим, что по крайней мере двум элементарным отрезкам, на которые разлагается фрагмент, в его полигональном описании соответствуют последовательности из  начало и конец которых составляют элементы отмеченных выше пар. Это
начало и конец которых составляют элементы отмеченных выше пар. Это  Выявив такие последовательности и отделив от фрагмента соответствующие им отрезки, получим изображение, показанное на рис. 4.17, в. Точками отмечены места отрыва ранее отделенных отрезков, которым соответствуют пары
Выявив такие последовательности и отделив от фрагмента соответствующие им отрезки, получим изображение, показанное на рис. 4.17, в. Точками отмечены места отрыва ранее отделенных отрезков, которым соответствуют пары  Информация о месте отрыва ранее отделенных отрезков используется для разделения оставшейся части фрагмента на элементарные отрезки.
Информация о месте отрыва ранее отделенных отрезков используется для разделения оставшейся части фрагмента на элементарные отрезки.

 заключающие некоторый перечень элементов
заключающие некоторый перечень элементов  означают, что заключенная в них последовательность трактуется как циклическая, т. е. в ней после
означают, что заключенная в них последовательность трактуется как циклическая, т. е. в ней после  следует
следует  Два угловых элемента
Два угловых элемента  из ГК назовем близкими и обозначим это отношение
из ГК назовем близкими и обозначим это отношение  если
если  где Т — некоторая константа, являющаяся параметром процесса разделения на элементарные отрезки. Операция
где Т — некоторая константа, являющаяся параметром процесса разделения на элементарные отрезки. Операция  над элементами
над элементами  порождает новый угловой элемент
порождает новый угловой элемент  с параметрами:
с параметрами:

 элементов из g порождает два граничных контура:
элементов из g порождает два граничных контура:  — первый и второй остаток соответственно:
— первый и второй остаток соответственно:

 областью определения которой является множество R номеров угловых элементов
областью определения которой является множество R номеров угловых элементов
 Если вырожденный контур g содержит всего два элемента, то такой контур назовем тривиальным. Узлом называется совокупность элементов из ГК, примыкающих к точке изгиба или разветвления линии фрагмента.
Если вырожденный контур g содержит всего два элемента, то такой контур назовем тривиальным. Узлом называется совокупность элементов из ГК, примыкающих к точке изгиба или разветвления линии фрагмента.
 . С этой целью перебираются
. С этой целью перебираются  . В стек помещаются номера тех
. В стек помещаются номера тех  для которых среди
для которых среди  не нашлось близких. По мере обнаружения близких пар осуществляются операции разделения текущего ГК такими парами. Каждое разделение порождает пару новых углов и пару новых ГК.
не нашлось близких. По мере обнаружения близких пар осуществляются операции разделения текущего ГК такими парами. Каждое разделение порождает пару новых углов и пару новых ГК.
 .
.
 осуществляют лишь в области испытания S, т. е. совокупности элементов стека, имеющих номера
осуществляют лишь в области испытания S, т. е. совокупности элементов стека, имеющих номера  для которых
для которых  а среди
а среди  (где имеется не более одного элемента SV, для которого
(где имеется не более одного элемента SV, для которого  ). Для остальных
). Для остальных  выполняется
выполняется 
 который рассматривается как инициирующий. Далее из предшествующего и последующего элементов для инициирующего отыскания
который рассматривается как инициирующий. Далее из предшествующего и последующего элементов для инициирующего отыскания  наиболее близко к нему расположенный. Пара
наиболее близко к нему расположенный. Пара  рассматривается как отсекающая элементарный отрезок, т. е. координаты концов отрезка совпадают с координатами элементов
рассматривается как отсекающая элементарный отрезок, т. е. координаты концов отрезка совпадают с координатами элементов  После того, как запись об очередном отрезке занесена в соответствующий список, инициирующий элемент удаляется из ГД, в качестве нового инициирующего элемента рассматривается
После того, как запись об очередном отрезке занесена в соответствующий список, инициирующий элемент удаляется из ГД, в качестве нового инициирующего элемента рассматривается  и шаг отсечения повторяется, пока в ГК не останется лишь один элемент.
и шаг отсечения повторяется, пока в ГК не останется лишь один элемент.
 входящих в описание.
входящих в описание.

 показаны варианты сечений, позволяющих объединить
показаны варианты сечений, позволяющих объединить  . Сечение
. Сечение  предпочтительнее, чем
предпочтительнее, чем  так как в случае
так как в случае  реализовав вышеописанный алгоритм, мы получим требуемое разложение, а в случае
реализовав вышеописанный алгоритм, мы получим требуемое разложение, а в случае  нет.
нет.
 где
где  Введение искусственного разреза в области
Введение искусственного разреза в области  объединяющего
объединяющего  реализуется операцией
реализуется операцией  :
:

 порождает ациклический фрагмент, имеющий следующее описание в полигональной форме:
порождает ациклический фрагмент, имеющий следующее описание в полигональной форме:  апаг,
апаг, 

 узел второго порядка), для любого реального документа можно подсчитать количество узлов любого типа и получить интересующую нас оценку для разделения линейной части изображения на элементарные отрезки
узел второго порядка), для любого реального документа можно подсчитать количество узлов любого типа и получить интересующую нас оценку для разделения линейной части изображения на элементарные отрезки  сцки где
сцки где  — объем вычислений при обработке узла
— объем вычислений при обработке узла  порядка; кг — количество узлов i-го порядка;
порядка; кг — количество узлов i-го порядка;  — верхнее значение для
— верхнее значение для  порядка узла. Для оценки объема вычислений отделения символьной части изображения будем исходить из того, что описание символа в полигональной форме содержит не более 12 угловых элементов. Этот вывод является результатом экспериментов с символами, считанными с реальных документов, для которых строилось описание ПФ. В соответствии со сказанным выше относительно процесса отделения символов, число машинных операций на символ не превышает стоимости проверки близости углов, умноженной на 12. Таким образом, оценка объема вычислений для символьной части изображения документа имеет вид
порядка узла. Для оценки объема вычислений отделения символьной части изображения будем исходить из того, что описание символа в полигональной форме содержит не более 12 угловых элементов. Этот вывод является результатом экспериментов с символами, считанными с реальных документов, для которых строилось описание ПФ. В соответствии со сказанным выше относительно процесса отделения символов, число машинных операций на символ не превышает стоимости проверки близости углов, умноженной на 12. Таким образом, оценка объема вычислений для символьной части изображения документа имеет вид  , где
, где  — общее число символов на документе.
— общее число символов на документе.
 Общее количество машинных операций, затрачиваемых на разделение линейной части изображения и отделения символов, равно
Общее количество машинных операций, затрачиваемых на разделение линейной части изображения и отделения символов, равно  тыс. операций.
тыс. операций.
