Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
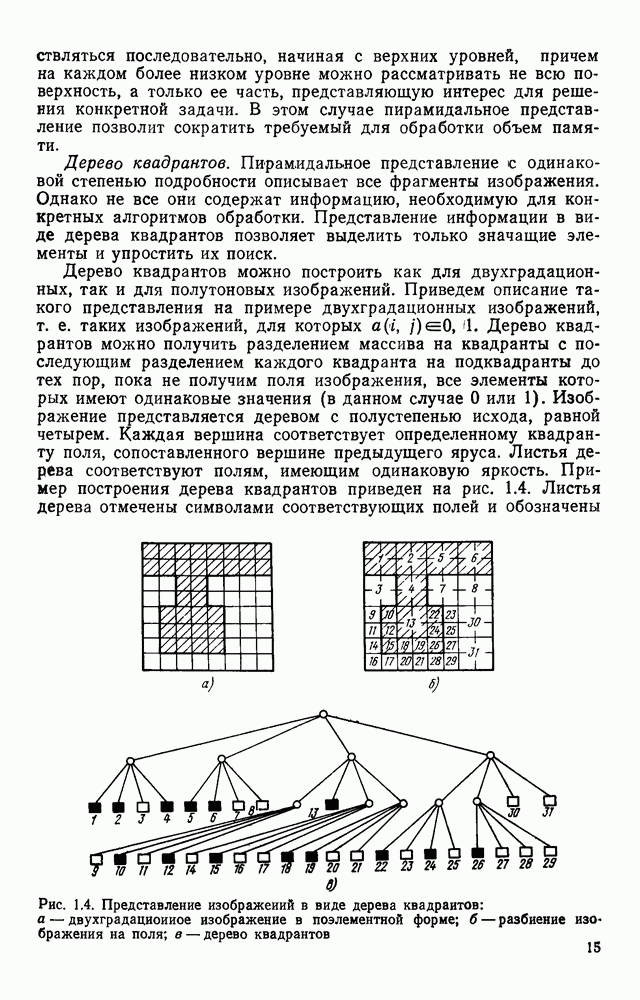
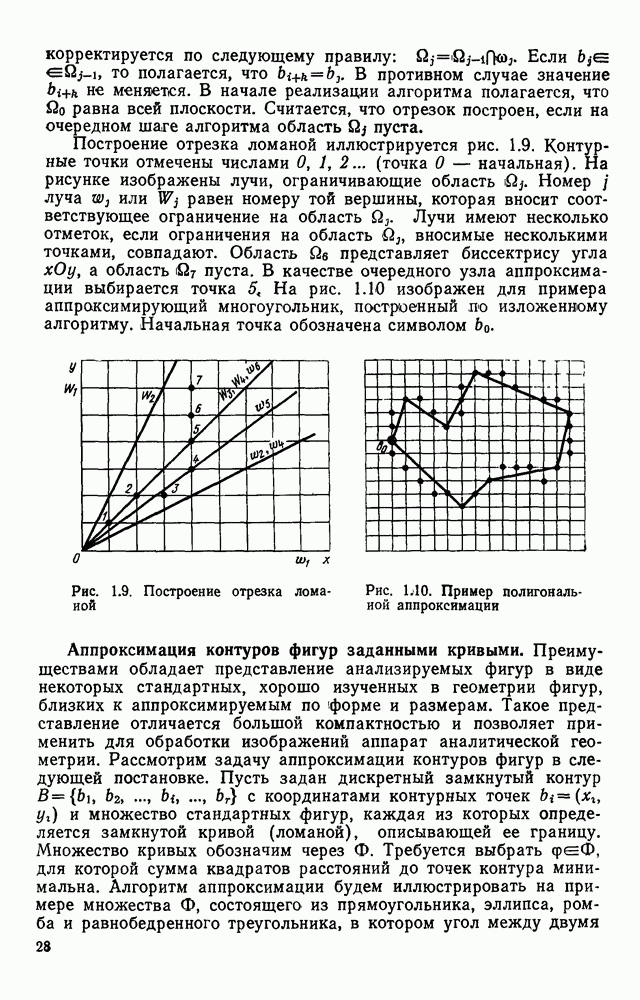
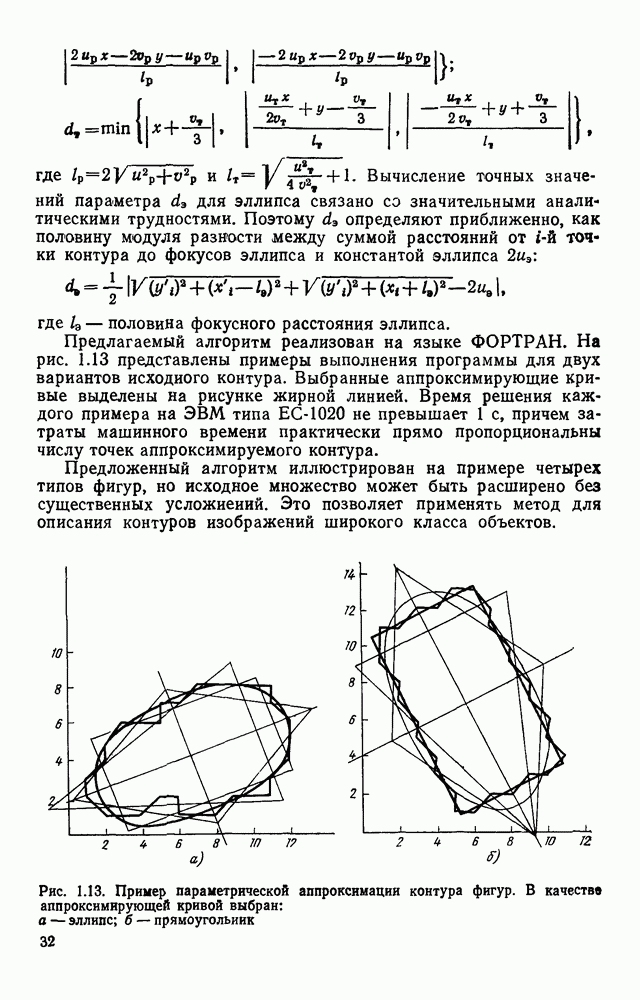
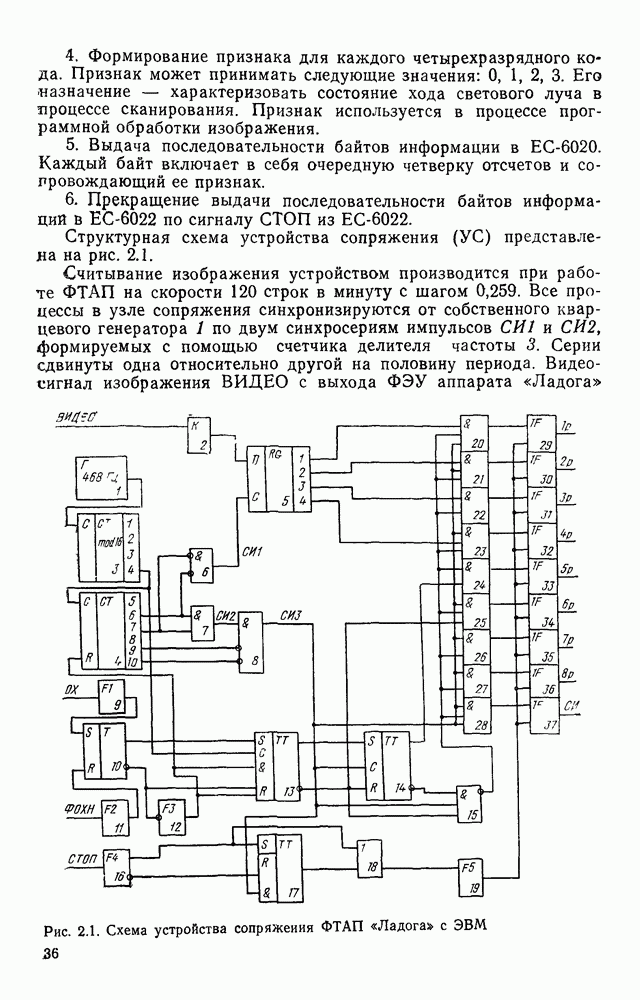
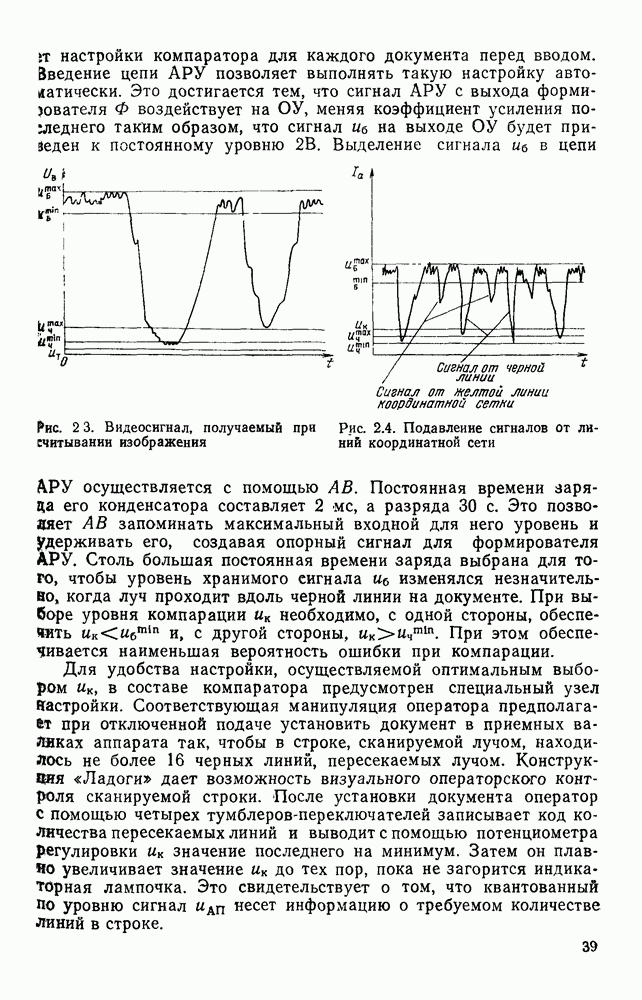
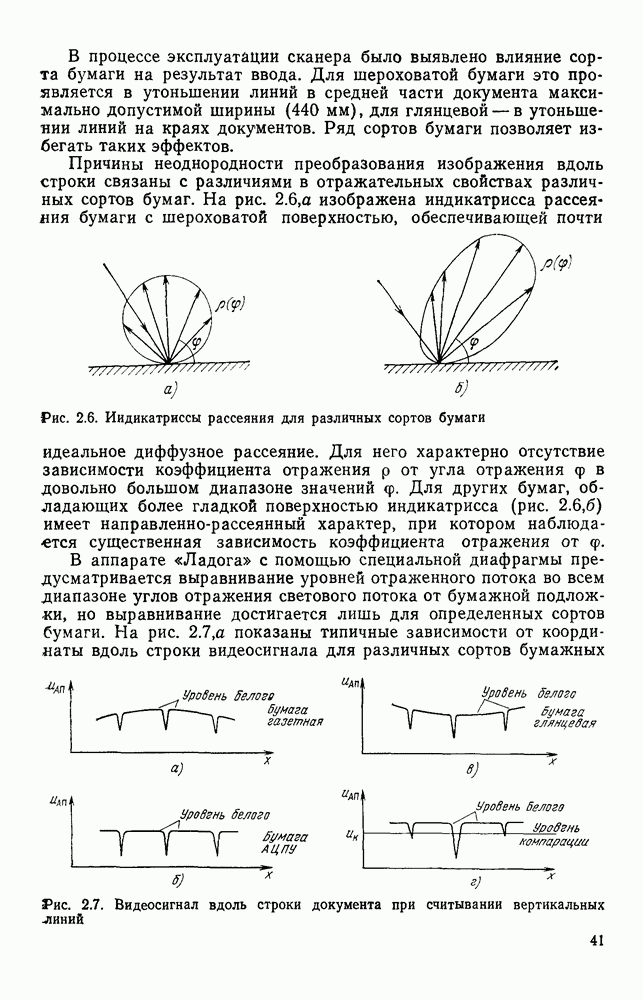
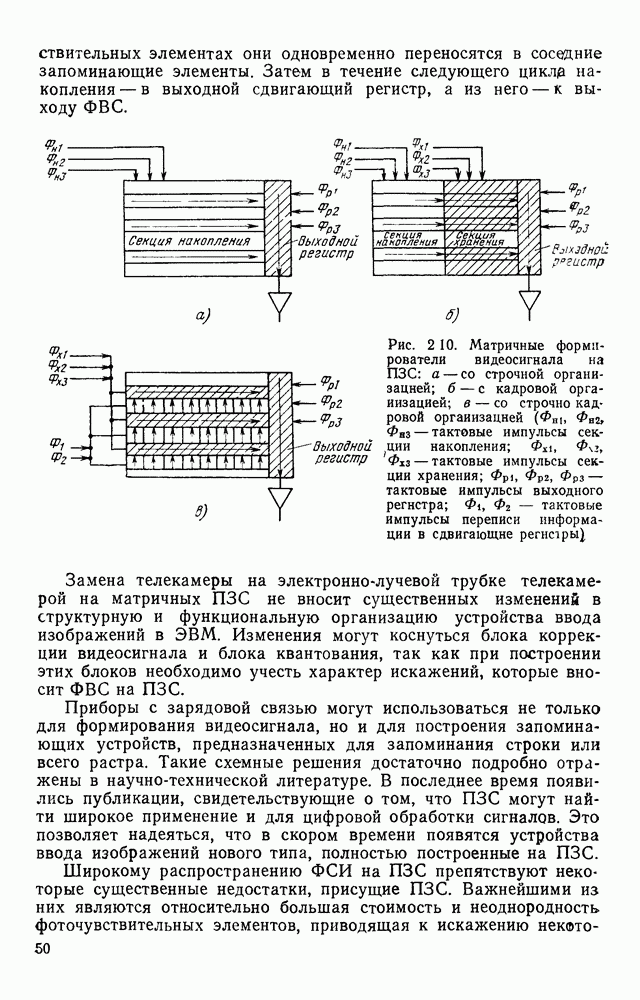
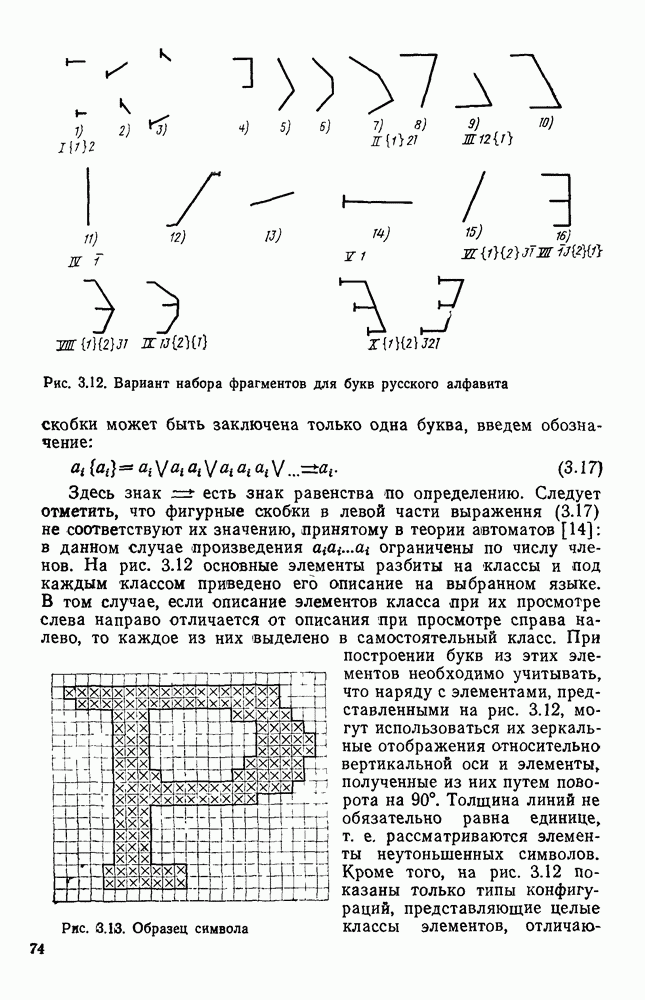
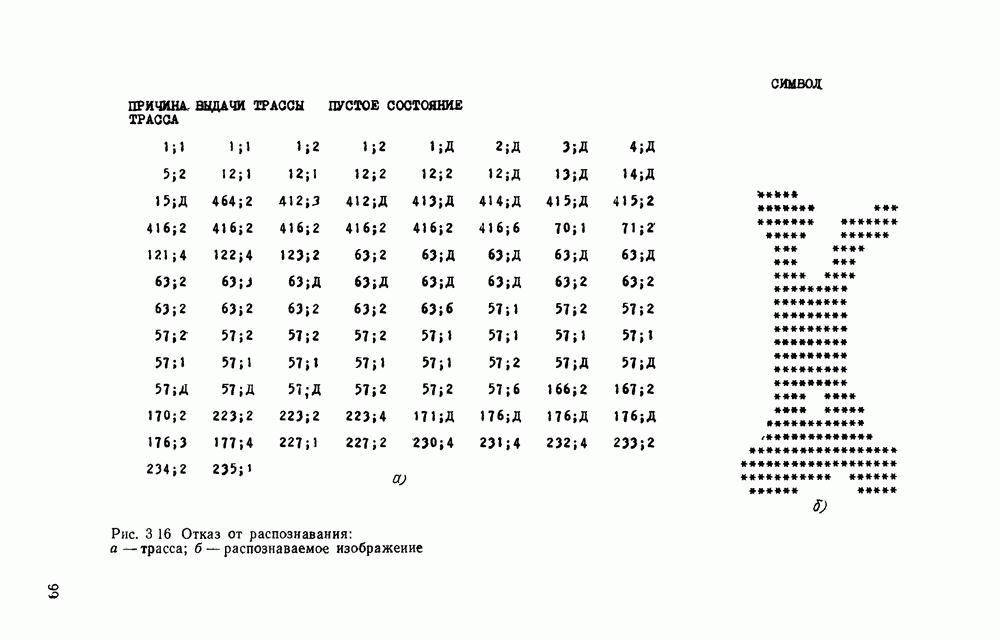
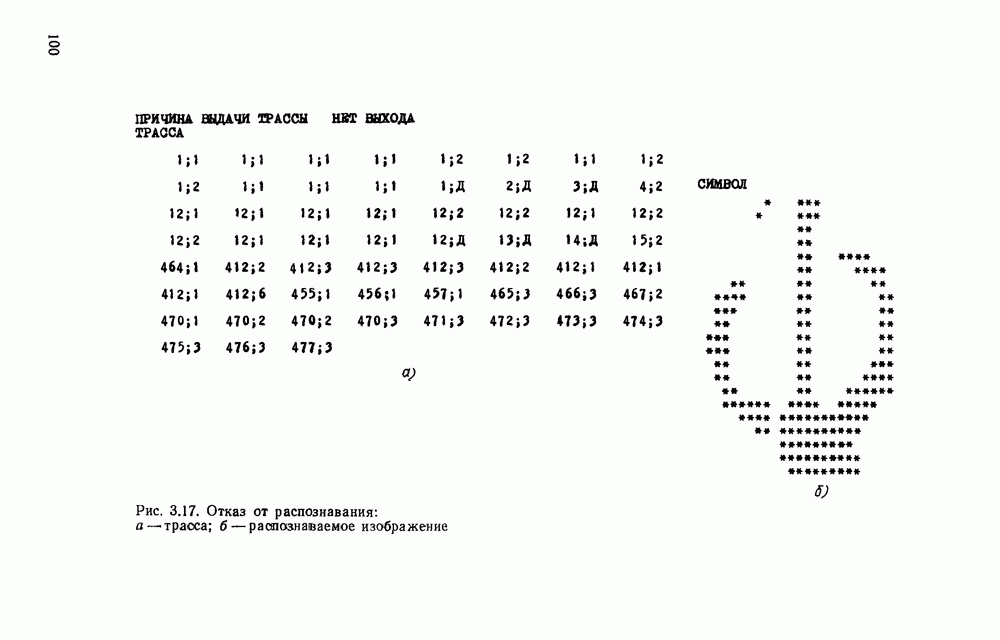
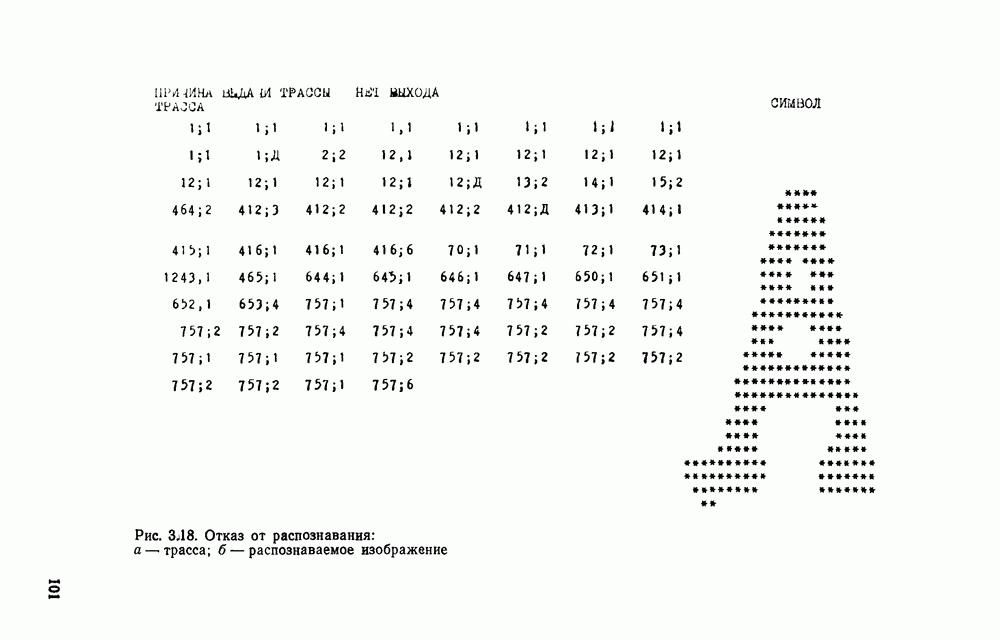
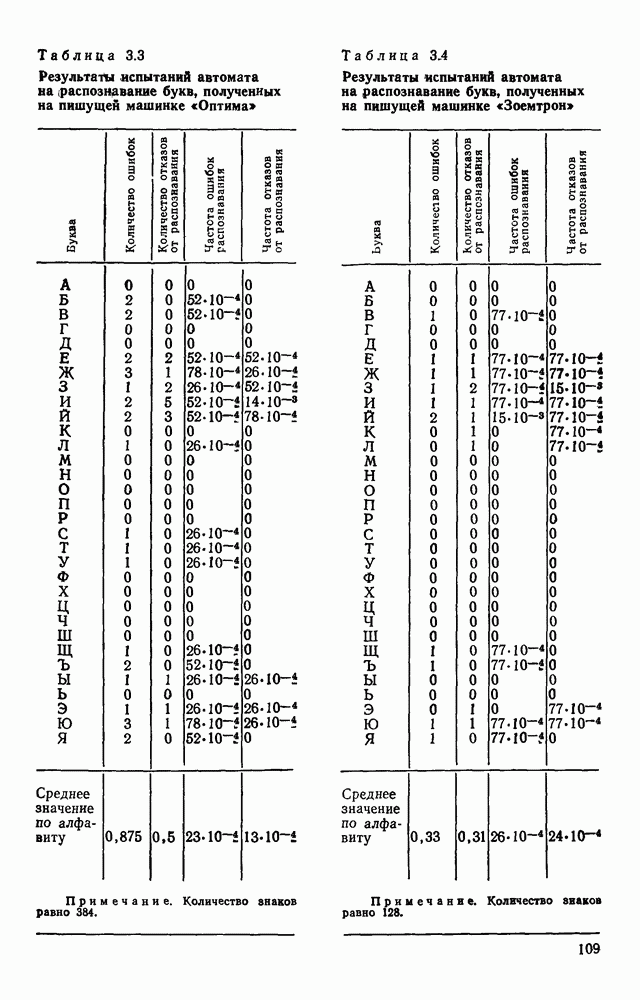
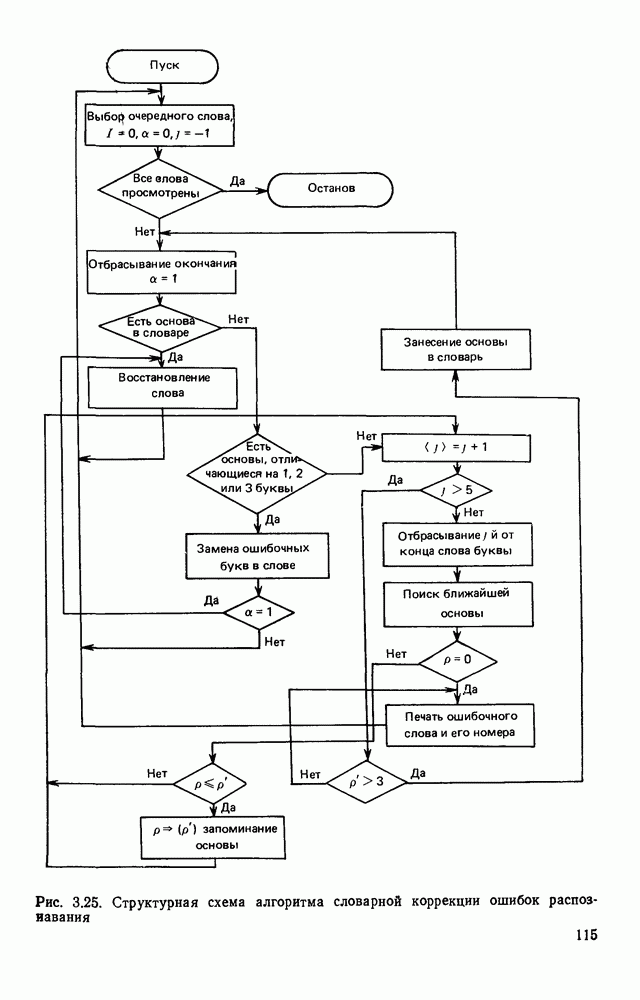
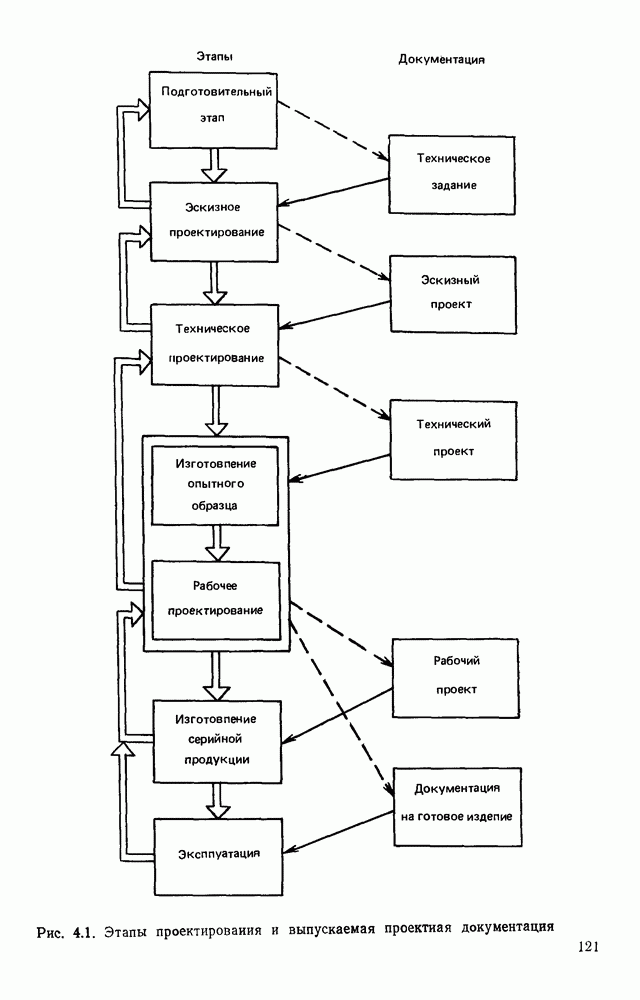
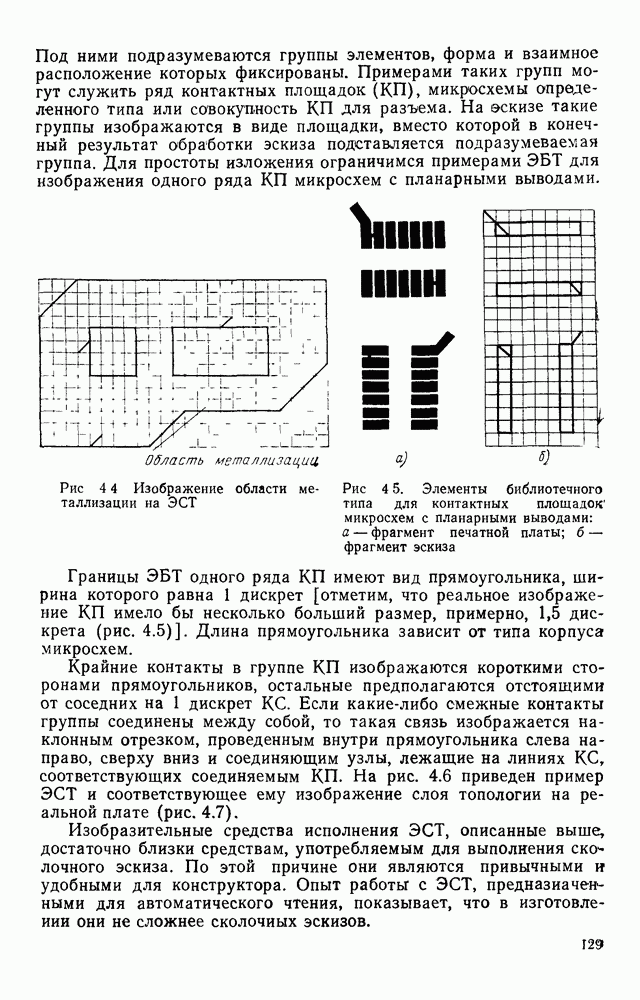
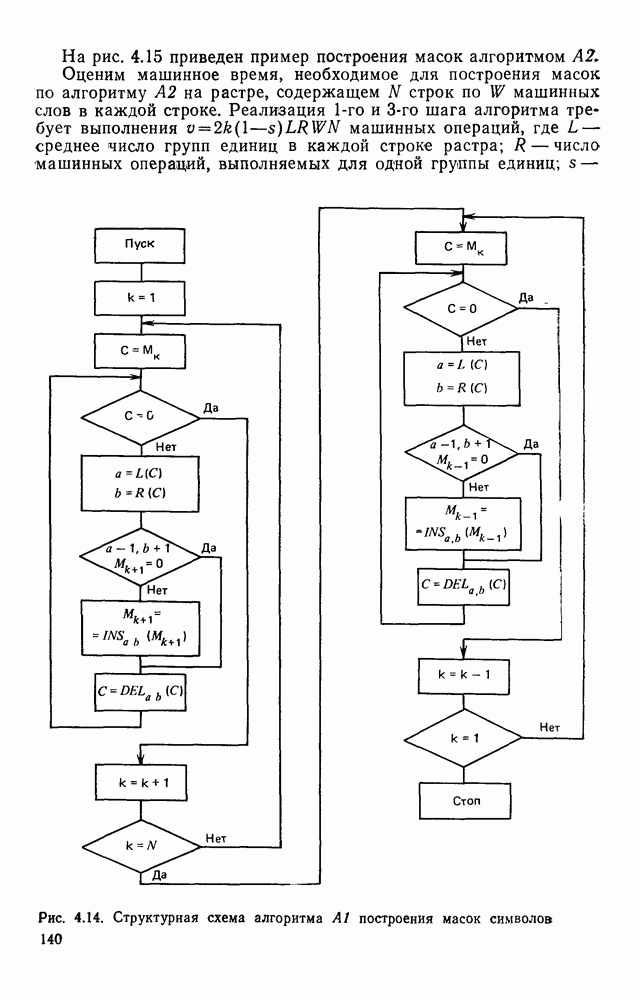
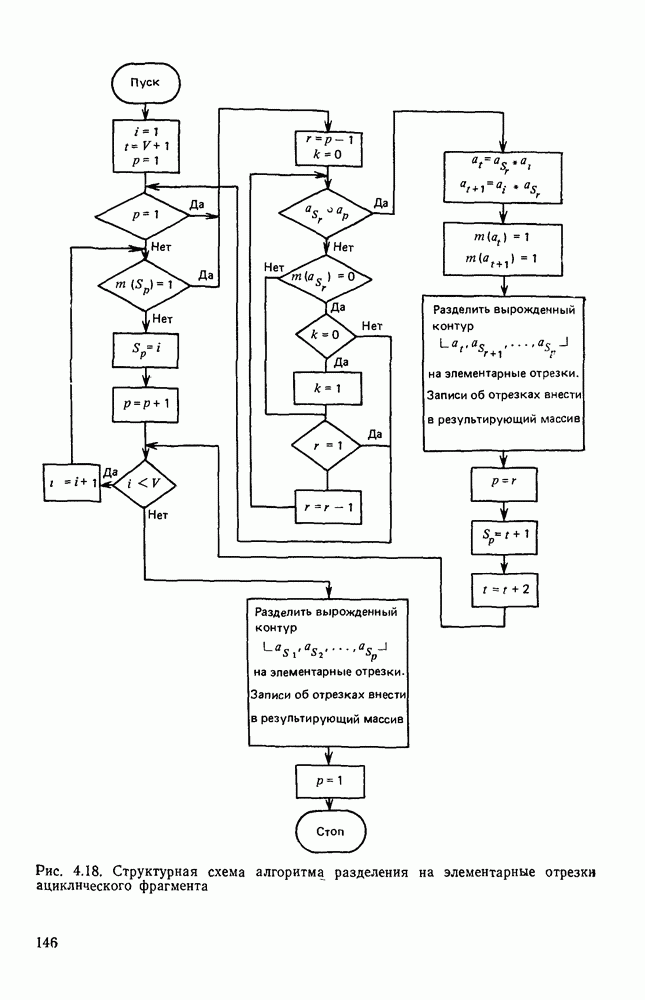
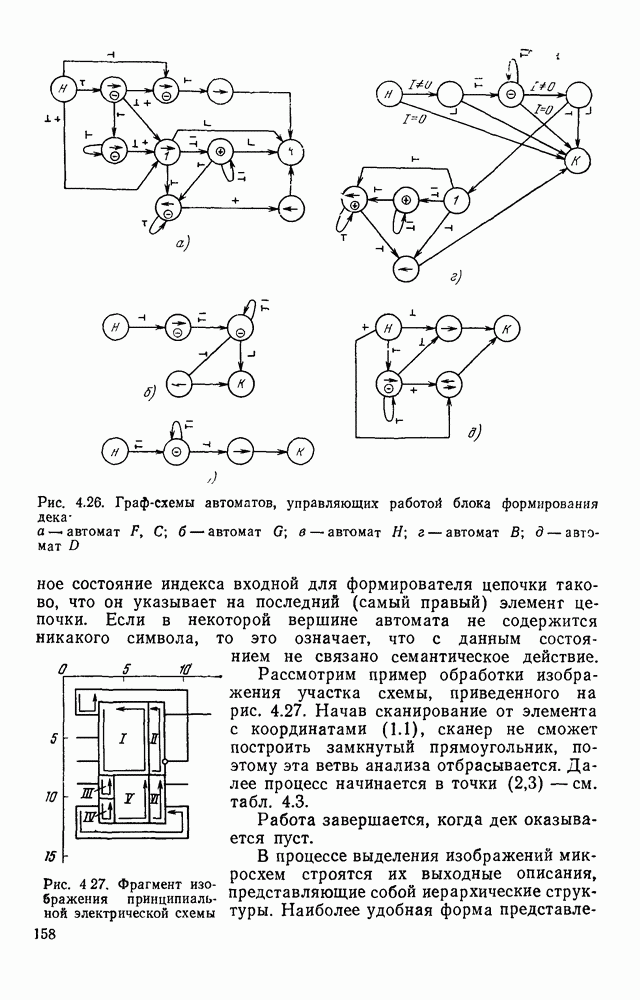
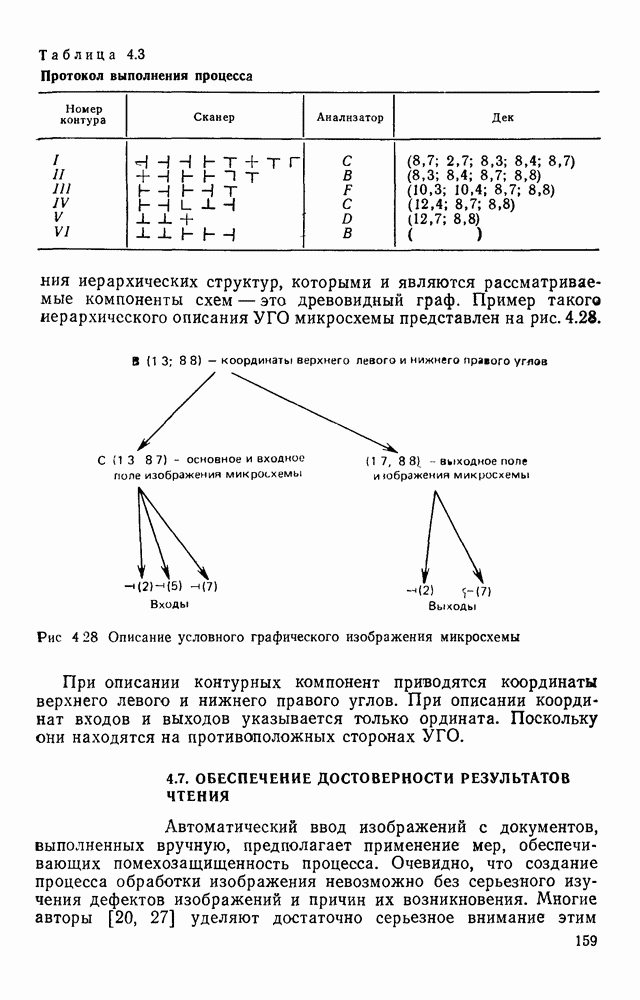
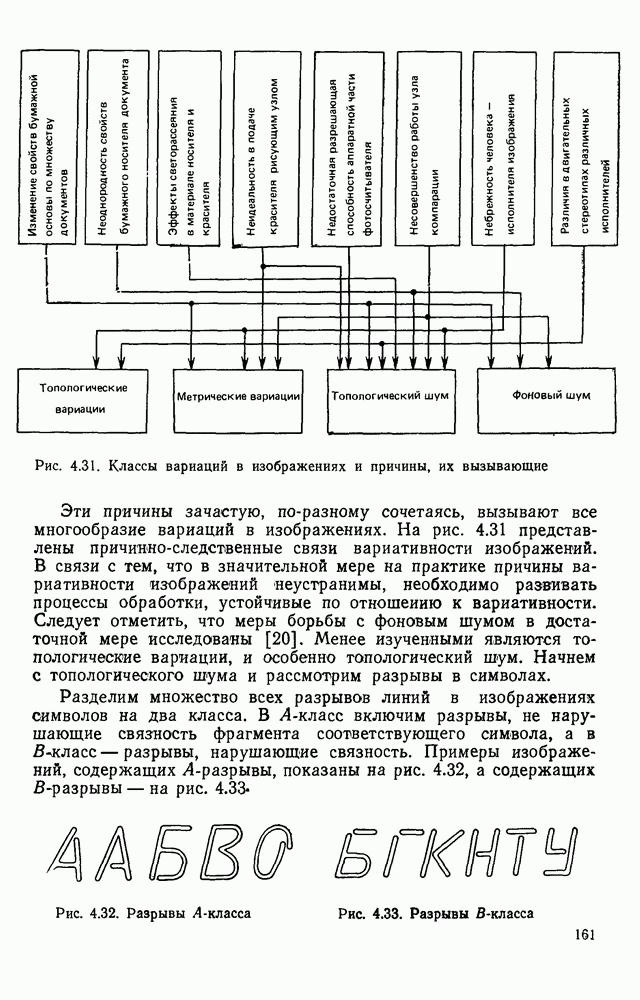
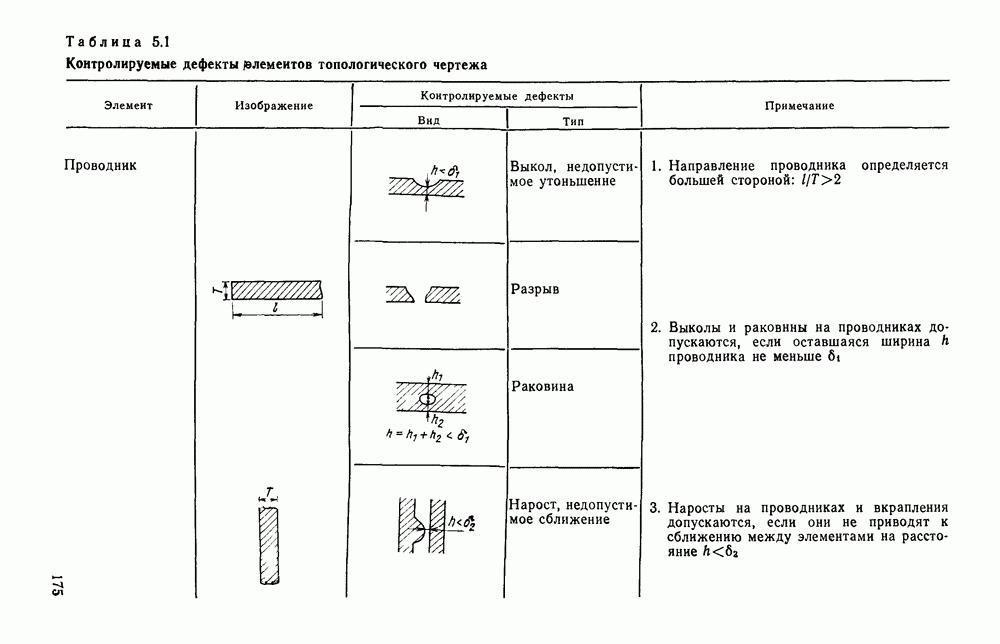
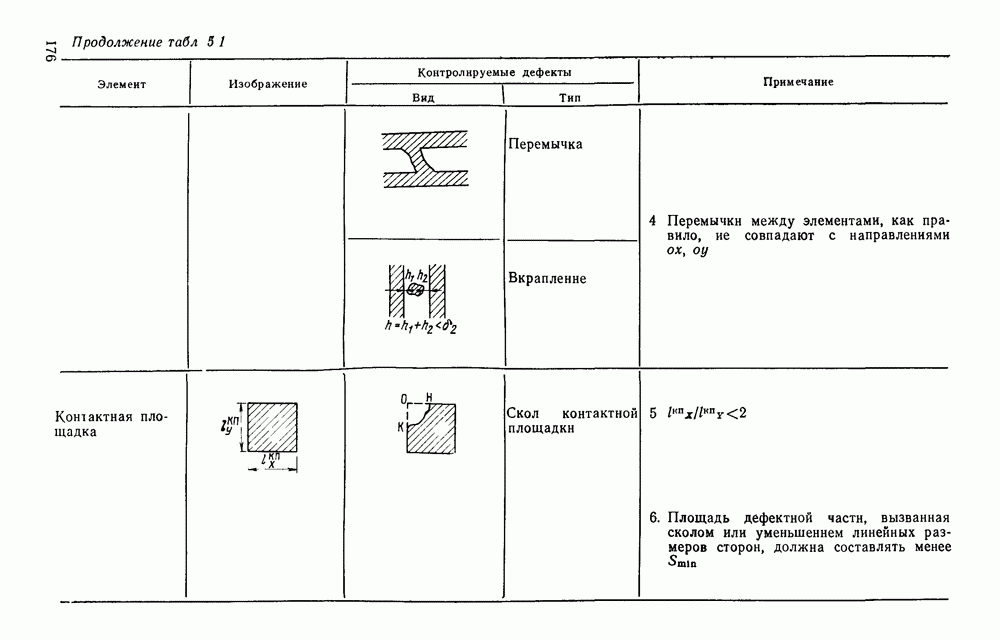
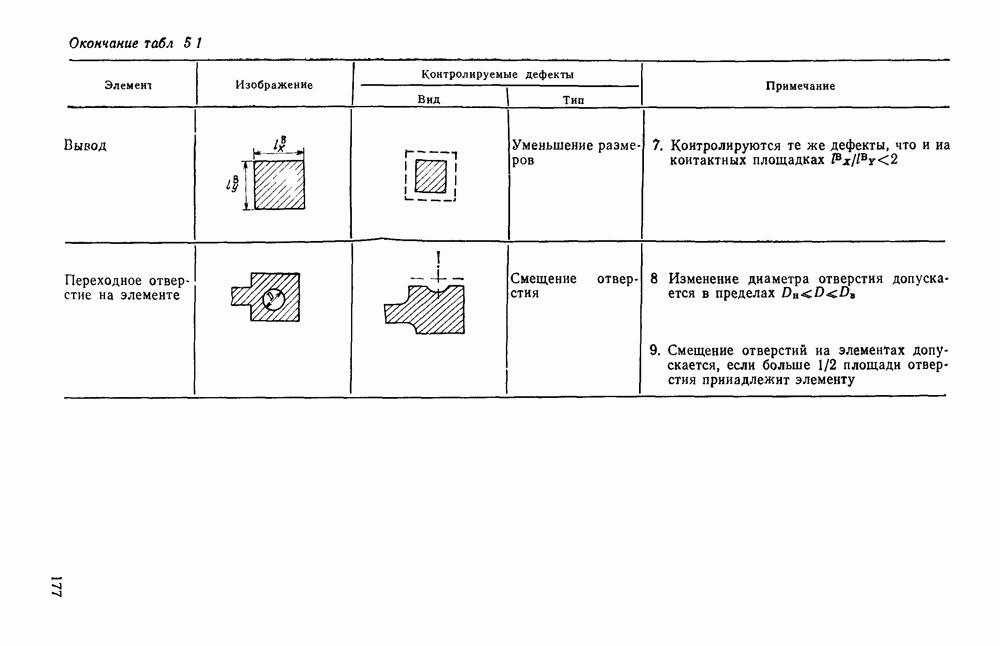
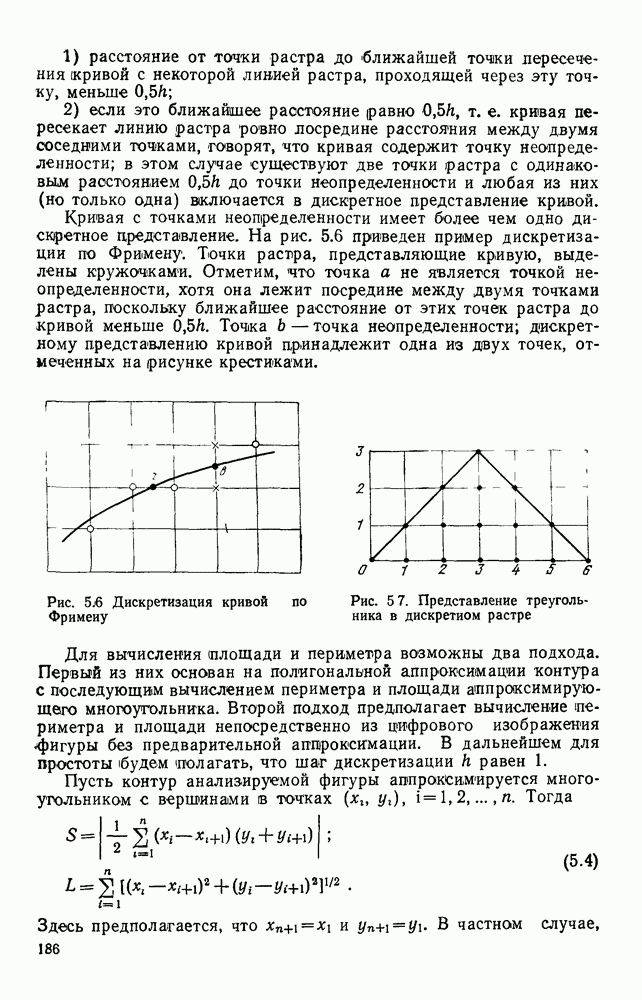
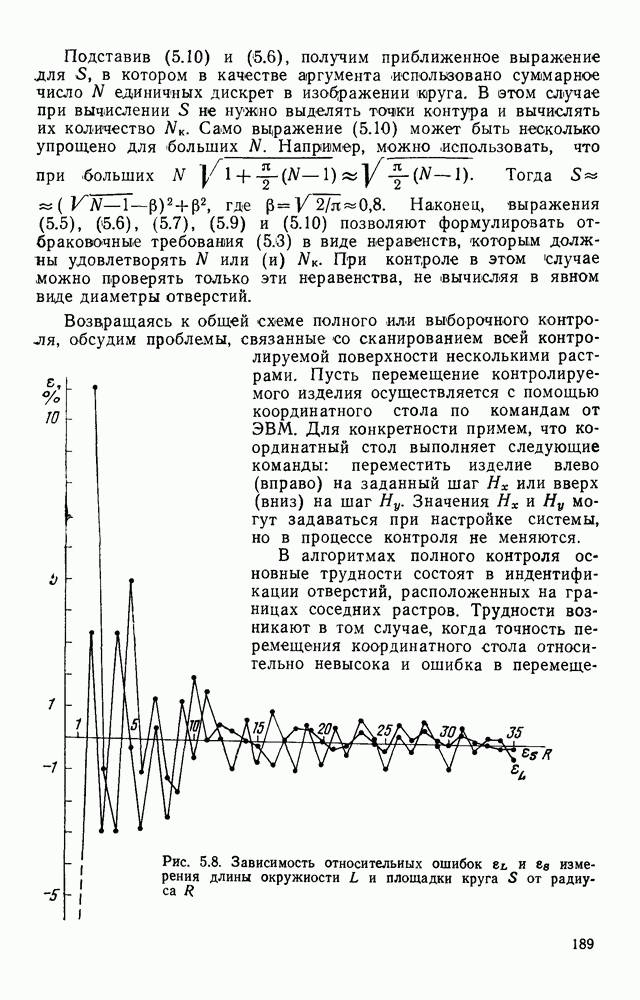
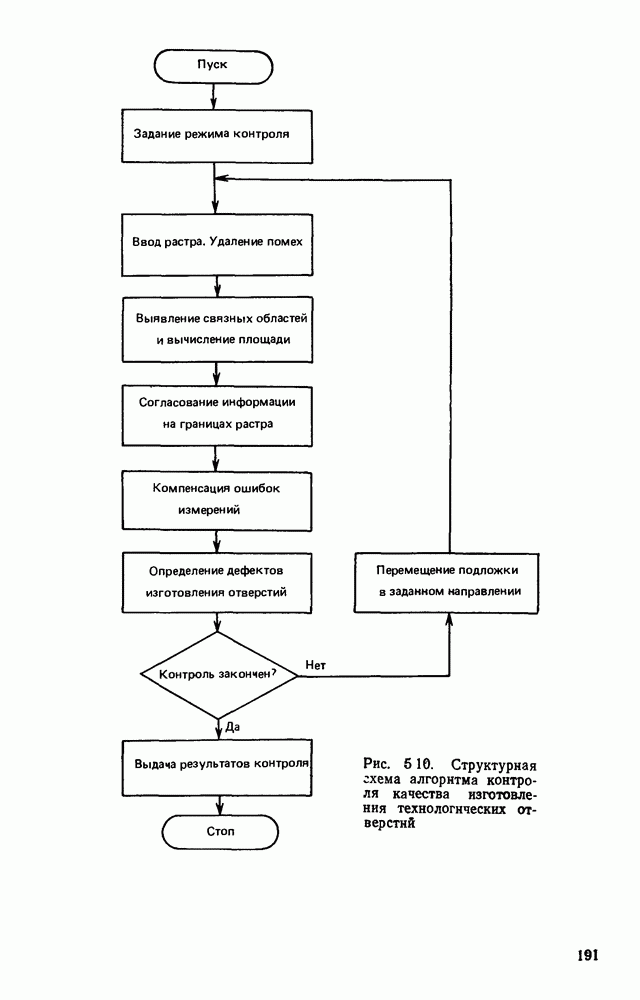
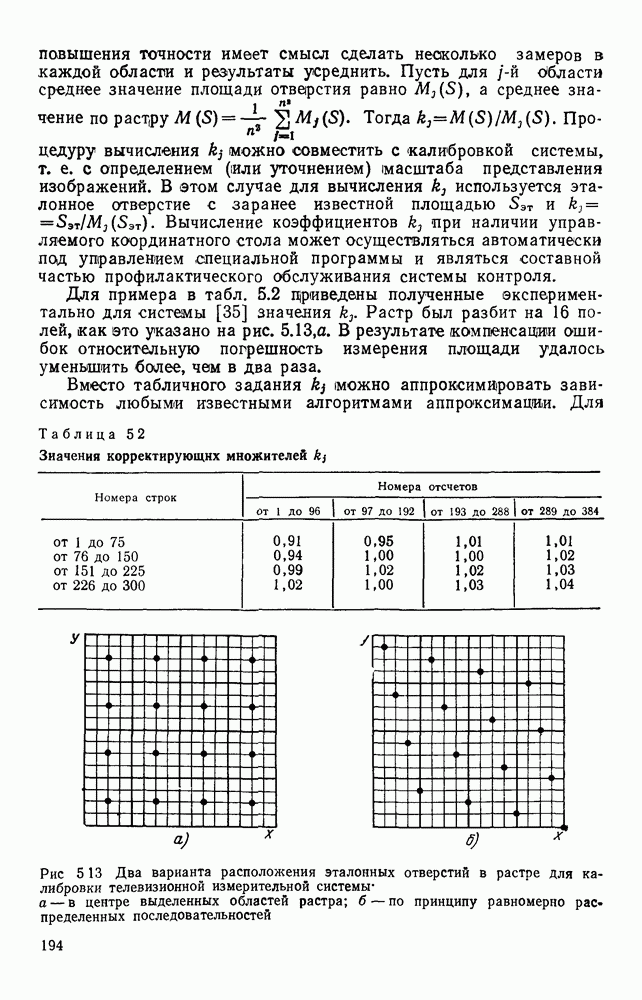
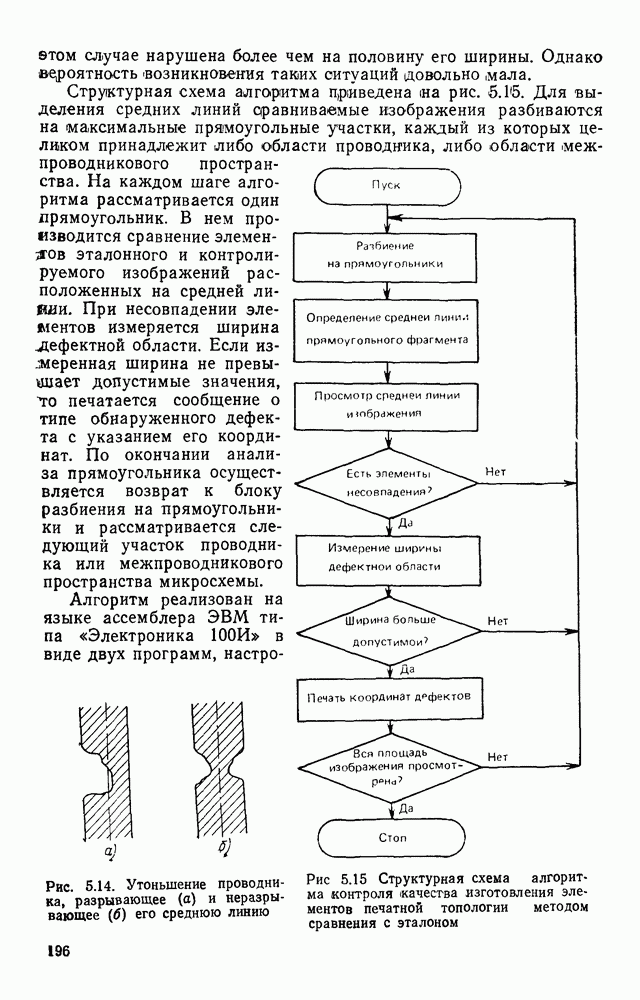
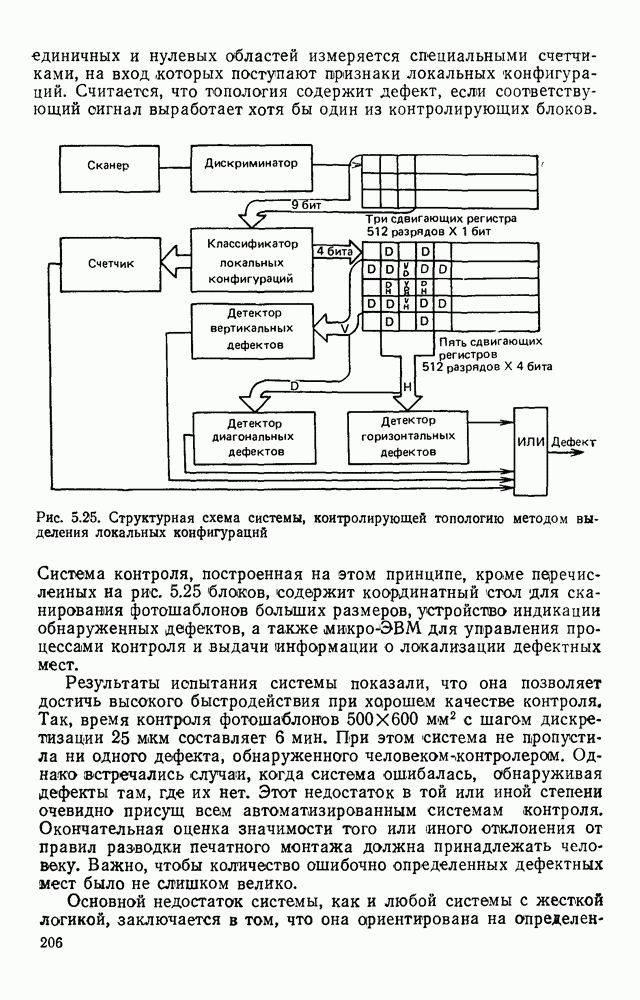
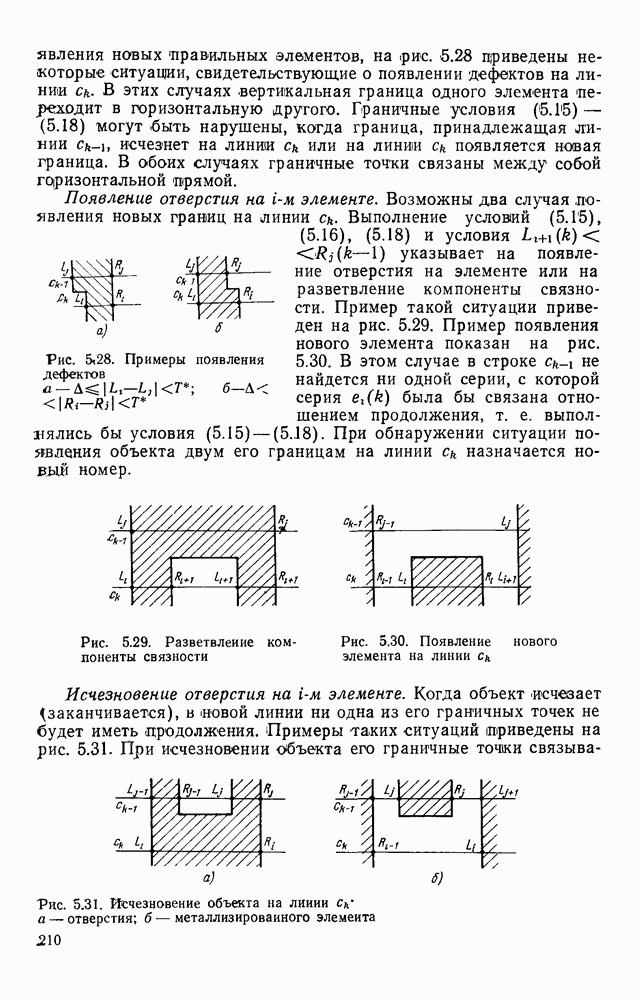
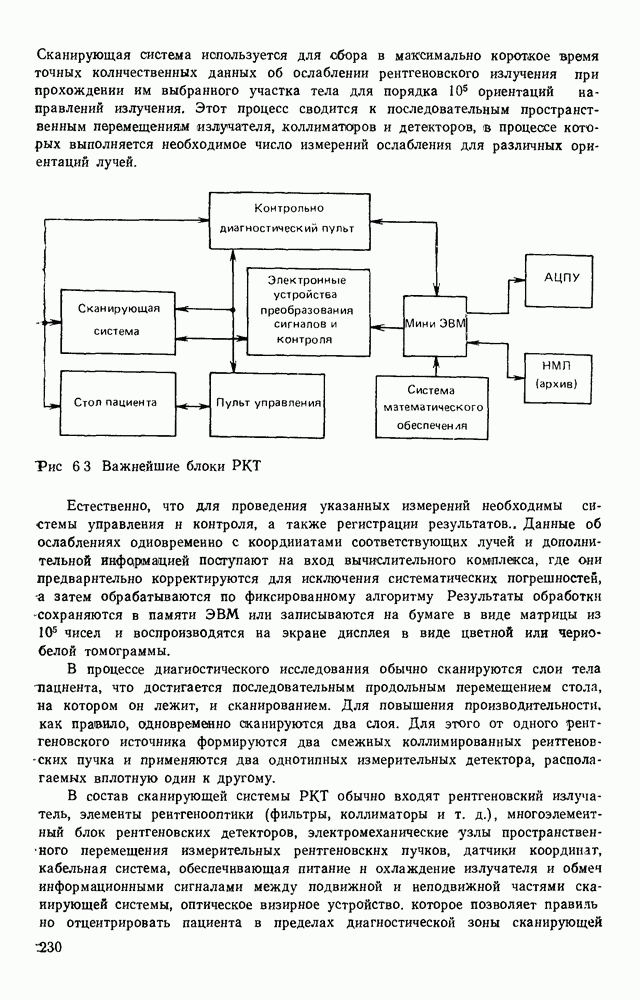
3.6. АЛГОРИТМИЗАЦИЯ АБСТРАКТНОГО СИНТЕЗА РАСПОЗНАЮЩЕГО АВТОМАТАПосле того как выбран алфавит и язык описания изображений можно приступить к синтезу дискриминатора. Подчеркнем только, что наилучших результатов удается достичь, решая комплексно задачу выбора алфавита и синтеза координатора, и дискриминатора. Обеспечить выполнение условия (3.14) нетрудно, если предположить, что изображения на растре являются «идеальными», т. е. что символы отображаются на растр в некоторой стандартной форме без каких-либо шумов и искажений. Однако эта ситуация практически недостижима по следующим причинам. 1. Даже в качественном печатном документе неизбежны отклонения От стандартного написания букв, часто незаметные визуально, проявляющиеся при фотоэлектрическом отображении символа на растр. Еще более значительны отклонения в стандартизированных рукописных знаках. 2. В самом процессе считывания документа неизбежны флуктуации и шумы, приводящие к искажениям отдельных деталей распознаваемого символа. Указанные причины приводят к тому, что при заданном основном алфавите А для некоторых изображении условие (3.14) не будет соблюдаться. Условимся характеризовать достоверность - распознавания с отношением числа правильно распознанных символов к общему числу распознаваемых символов. Требования к достоверности распознавания зависят от назначения устройства. Если для устройств, осуществляющих ввод данных в ЭВМ со стандартных документов, необходимо, чтобы При фиксированном алфавите А и выбранном способе описания распознаваемых символов процесс синтеза дискриминатора и координатора сводится к написанию соответствующих микропрограмм и программ для микропроцессора или мини-ЭВМ. Один из путей реализации координатора будет рассмотрен ниже на примере машинописных символов. Поскольку отклонения при печати документов и преобразовании визуальных символов в электрические сигналы носят случайный характер и предусмотреть все их заранее невозможно, то для построения координатора, обеспечивающего высокую достоверность распознавания, необходим процесс обучения. Этот процесс целесообразно организовать следующим образом. Задавшись исходными условиями на качество документов (оптические свойства бумаги, допустимый уровень «фона», тип красящей ленты, сила удара и т. д.), подготовить обучающую выборку всех букв распознаваемого алфавита В. Объем обучающей выборки имеет большое значение, так как от него в значительной степени зависит достоверность распознавания. Обучающая выборка с помощью фотосчитывающего устройства преобразуется в последовательность растров того же объема и вводится в ЭВМ, где записывается на магнитную ленту в виде серии файлов, а часть обучающей выборки, содержащая растры одной буквы, занимает один файл. Обработка изображений, образующих обучающую выборку, начинается с работы программы, моделирующей блок предварительной обработки. Результатом является файл с препарированными символами. Дальше идет процесс формирования эталонных описаний. Просматривая хранящиеся в памяти ЭВМ изображения с помощью дисплея или используя распечатки изображения на АЦПУ, проектировщик задает машине описание каждого из распознаваемых классов в терминах алфавита А. При этом нет необходимости давать описание каждого изображения, хранящегося в памяти. Достаточно, чтобы проектировщик уловил основные (тенденции в отклонениях изображений от идеальных символов. После ввода описаний, составленных проектировщиком, по специальной программе, автоматически формирующей описания изображений, осуществляется проверка, все ли изображения, хранящиеся в памяти ЭВМ, представлены данным проектировщиком описанием. Если найдется изображение, не описанное проектировщиком, то оно выдается на АЦПУ или дисплей вместе с соответствующей цепочкой После того как все изображения, хранящиеся в памяти машины, проверены на их соответствие описаниям и откорректированы сами описания на основе полученных при анализе данных, переходим к построению автомата по этим эталонным описаниям. Отметим, что задание проектировщиком описаний, учитывающих различные отклонения, не является обязательным в данном методе. Достаточно, если проектировщик укажет лишь стандартное описание каждого класса, т. е. описание изображения, в котором присутствуют без искажений все элементы. Например, для класса Н при просмотре слева направо стандартное описание в алфавите А имеет вид Легко убедиться, что это описание включает цепочки, соответствующие На основе подобных описаний строятся таблицы переходов и выходов синхронного автомата Мили по множеству входных последовательностей в основном алфавите А. Учет специфики — знание класса выражений, описывающих последовательности, возможностей дискриминатора и т. д., с одной стороны, позволяют получить более простые структуры, с другой — приводят к необходимости разработки специальных методов и программ, осуществляющих этот процесс. Затем следует этап минимизации числа состояний автомата, который является весьма важным при любом способе технической реализации автомата, поскольку позволяет сократить число элементов или ячеек памяти. В зависимости от результатов, достигнутых при применении описаний в языке А, процесс построения эталонных описаний и таблиц переходов-выходов будет повторяться для отдельных групп символов, но теперь уже в другом алфавите, расширенном за счет включения символов алфавита второго уровня. Более детально этот вопрос будет рассмотрен ниже. Здесь мы только отметим, что разделение алфавита на два уровня позволяет, во-первых, упростить координатор, поскольку число входных сигналов в нем остается постоянным (меняется лишь их состав), во-вторых, облегчает процесс выбора алфавита описаний, так как внимание проектировщика концентрируется на конкретной группе символов, которые не распознаются в терминах алфавита первого уровня, и он может более тщательно проанализировать изображения этой группы символов, прежде чем ввести тот или иной новый символ в алфавит. Ясно, что этот процесс необходим лишь в том случае, когда ведется выбор подходящего алфавита. Если же алфавит известен заранее и на сложность автомата нет ограничений, то процесс проектирования координатора может вестись без вмешательства человека. Задачу построения достаточно сложного дискретного устройства естественно разделить на ряд самостоятельных этапов. В настоящее время в теории автоматов принято выделять три этапа. На первом, называемом этапом блочного синтеза, структура проектируемого устройства представляется в виде совокупности взаимодействующих крупных узлов — блоков. При этом на каждый блок возлагается реализация того или иного процесса в общем алгоритме функционирования автомата в целом. На втором этапе производится описание задачи, решаемой синтезируемым автоматом, в терминах того или иного языка. При этом определяются входной и выходной алфавиты (пока на абстрактном уровне) для перерабатываемой автоматом информации и устанавливается закон отображения слов входного алфавита в слова выходного алфавита. Этот этап называют этапом формальной постановки и уточнением задачи. Третий этап — этап абстрактного синтеза автомата. В классической теории автоматов [14] предполагается, что на втором этапе полностью задано соответствие между последовательностями на входе автомата и выходными сигналами. Наиболее простой способ задания соответствия между входными и выходными последовательностями сигналов автоматов — простое перечисление всех входных последовательностей и соответствующих им выходных. Ясно, что этот способ применим лишь в том случае, когда число входных последовательностей не слишком велико. Сложнее обстоит дело, если число заданных последовательностей неограничено. В этом случае возникает необходимость в некотором языке, позволяющем описывать отображения бесконечных множеств входных и выходных последовательностей. Одним из таких языков является язык регулярных выражений [14]. Далее предполагается, что на втором же этапе решена задача проверки реализуемости заданного отображения конечным автоматом. Если соответствие представлено на языке регулярных выражений, то множество событий, заданных в этом языке, должно удовлетворять условиям автоматности [14]. В случае же перечисления всех входных и соответствующих им выходных последовательностей это задание должно удовлетворять условию непротиворечивости [14]. Рассмотрим специфические особенности решаемой задачи. 1. Хотя множество входных последовательностей и конечно, оно все же слишком велико, чтобы можно было определить функционирование автомата путем перечисления всех входных последовательностей и соответствующих им выходных сигналов. Поэтому необходим специальный язык описания изображений, в (большей степени учитывающий специфику задачи. 2. В случае, если выяснится, что в выбранном нами алфавите А одинаковые входные последовательности не соответствуют одному и тому же выходному символу, мы всегда можем расширить алфавит шервого уровня путем добавления новых входных сигналов и удлинить каждую из совпадающих последовательностей до такой степени, чтобы устранить имеющееся противоречие. Следствием первой особенности является то, что множество входных последовательностей лишь частично определяется на втором этапе как множество стандартных описаний в языке А, задаваемых человеком. Определение же полного описания событий, представимых в автомате символами распознаваемого алфавита, осуществляется на этапе абстрактного синтеза. Ввиду серьезных затруднений в нахождении компактного алфавита языка описаний, который бы обеспечивал непротиворечивость задания отображений, а также для упрощения системы автоматизации проектирования, задача обеспечения условия непротиворечивости задания отображений (первого условия автоматности) решается одновременно с задачей построения таблиц переходов— выходов автомата. С этой целью построение таблиц переходов—выходов ведется на двух уровнях. Сначала, исходя из описаний в алфавите первого уровня А, осуществляется разбиение всего распознаваемого алфавита на подмножества сходных изображений, т. е. таких изображений, которые имеют одинаковые цепочки со в алфавите А. Следует отметить, что значительная доля изображений при этом распознается совершенно однозначно, т. е. большинство подмножеств сходных изображений состоит из одного элемента. Однако из-за влияния различного рода помех изображения различных символов распознаваемого алфавита могут иметь одинаковые описания в терминах алфавита А. В этом случае образуются группы сходных изображений. Различение сходных изображений осуществляется путем изменения алфавита А за счет включения в него букв алфавита второго уровня. Эта задача решается в режиме взаимодействия проектировщика с ЭВМ, которая выдает в виде распечатки на АЦПУ или на дисплей сходные изображения, а проектировщик решает вопросы о конкретном символе алфавита второго уровня (дополнительного алфавита) и направлении просмотра растра, обеспечивающем разделение сходных изображений. Поскольку число состояний в подлежащих минимизации таблицах переходов — выходов измеряется сотнями, то развитые в рамках теории автоматов методы, дающие точное решение задачи, здесь не могут быть применены, так как требуют непомерно большого времени для нахождения решения даже с привлечением современных ЭВМ. Исходя из этого, был разработан приближенны» метод минимизации числа состояний, позволяющий минимизировать число состояний в автоматах, размеры которых определяются, в основном, размерами оперативной памяти ЭВМ. Описанные в § 3.5 элементы изображений носят главным образом иллюстративный характер, их основной целью является раскрытие сущности используемого нами подхода. На самом деле вовсе не обязательно выделять в чистом виде те или иные элементы изображения, тем более, что наличие шумов может существенно искажать отдельные детали, так что выделение описаний элементов (декомпозиция цепочки) может существенно усложняться. Более гибким оказывается другой подход, к рассмотрению которого мы переходим. Пусть даны совокупности цепочек в алфавите Условия автоматности множества событий формулируются следующим образом. I. Автоматное множество событий должно состоять из конечного числа событий в одном и том же конечном алфавите, называемом входным. События попарно не пересекаются и не содержат пустого слова. II. Если некоторое слово принадлежит какому-либо событию из автоматного множества событий, то все начальные отрезки этого слова, за исключением пустого слова, принадлежат каким-либо событиям из того же множества. Поскольку любое слово входного алфавита обязательно входит Процесс формирования описаний состоит в следующем. Множество символов «обучающей» выборки, преобразованных в растры с помощью фотосчитывающего устройства, вводится в ЭВМ и записывается на магнитную ленту таким образом, что все символы С этой целью процесс получения описаний делится на два этапа. На первом — для каждого изображения списка строится описание, аналогичное (3.20). Эти описания свертываются в более удобную для дальнейшей обработки форму по следующим правилам: символ 0 исключается из цепочки; подцепочка из 5 одинаковых символов Пример. Описание (3.20) в свернутом виде выглядит следующим образом:
На втором этапе описания списка сравниваются со стандартным описанием символа. Под стандартным понимается описание, не учитывающее помех и искажений. Стандартное списание либо формируется из указанных конструктором символов списка, либо задается аналитически. При сравнении описаний списка со стандартным выполняются следующие операции. 1. Для каждой подцепочки, входящей в стандартное описание, определяется диапазон значений метки. 2. Подцепочки (необязательно из одинаковых букв), возникающие между подцепочками, входящими в стандартное описание, вьписываются в виде списка помех. 3. Буква 4. Если диапазон значений метки буквы 5. Элементы из списка помех, возникающих между любыми двумя подцепочками, объединяются знаком дизъюнкции и заключаются в круглые скобки. Пример. Проиллюстрируем процесс получения эталонного описания на небольшом списке из семи изображений буквы Б Для простоты рассмотрим только цепочки I Описания изображений списка имеют вид, представленный на рис. 3 14. Свернем эти описания.
2. Стандартное описание буквы Б при просмотре сверху вниз имеет вид Выполняя перечисленные выше операции, получаем
Рис. 3.14. Исходное описание семи вариантов символа Б На следующем этапе осуществляется проверка условия автоматности. Для упрощения структуры координатора сначала проверяют, выполняется ли условие автоматности, если не учитывать метки. В тех случаях, когда эталонные цепочки Пример. Буквы Рассмотрим диапазоны подцепочек:
Из этих описаний следует, что диапазон меток буквы 2 в При значительных искажениях изображений символов может случиться, что описания различных символов в алфавите А совпадают даже с учетом диапазона. В этом случае для символов, у которых не выполняется условие автоматности, отыскиваются описания в некотором расширенном алфавите, включающем частично или полностью символы алфавита
|
 |
Оглавление
|




































































































































































































 то для автомата, преобразовывающего буквы в шрифт Брайля (одного из вариантов машины, позволяющий слепым людям читать обычные тексты), по-видимому, будет достаточным
то для автомата, преобразовывающего буквы в шрифт Брайля (одного из вариантов машины, позволяющий слепым людям читать обычные тексты), по-видимому, будет достаточным 
 и проектировщик должен либо дать машине указание скорректировать описание класса таким образом, чтобы оно включало описание и этого символа, либо принять решение, что символ настолько искажен при отображении на растр, что существенно отличается от остальных изображений класса и правильно распознан быть не может. Примером такой ситуации может служить буква
и проектировщик должен либо дать машине указание скорректировать описание класса таким образом, чтобы оно включало описание и этого символа, либо принять решение, что символ настолько искажен при отображении на растр, что существенно отличается от остальных изображений класса и правильно распознан быть не может. Примером такой ситуации может служить буква  у которой из-за недостаточной силы удара или дефекта красящей ленты пропала нижняя засечка. Очевидно, что это единственный элемент, позволяющий различать буквы
у которой из-за недостаточной силы удара или дефекта красящей ленты пропала нижняя засечка. Очевидно, что это единственный элемент, позволяющий различать буквы  Ясно, что внесение описания такой искаженной буквы в описание класса
Ясно, что внесение описания такой искаженной буквы в описание класса  повлечет за собой ошибки при распознавании буквы
повлечет за собой ошибки при распознавании буквы  она будет классифицироваться как
она будет классифицироваться как 
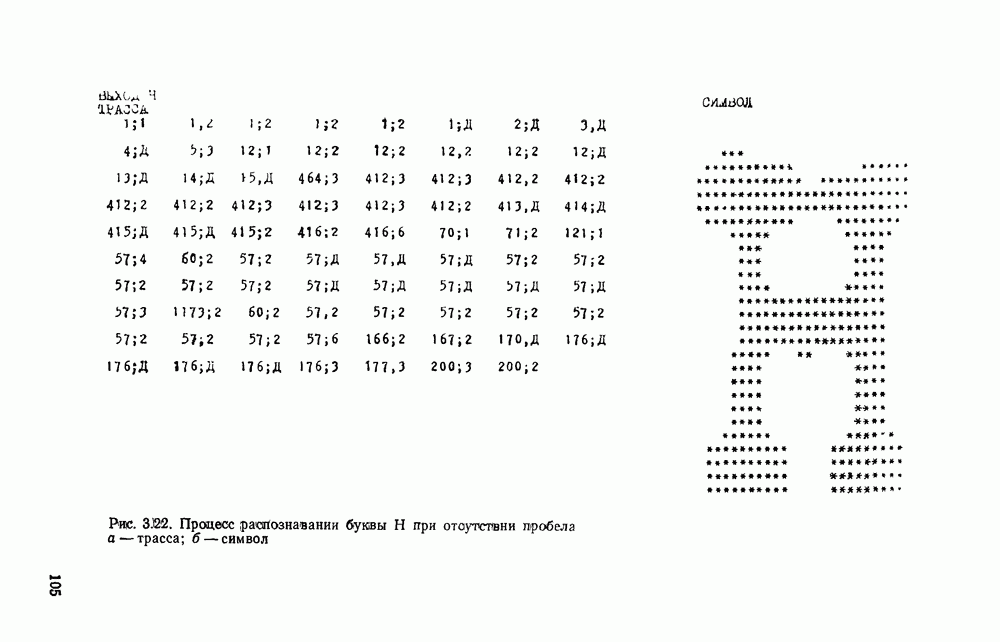
 Ниже будет приведен алгоритм, который на основе стандартного описания позволяет полностью автоматически сформировать эталонное описание класса путем анализа изображений обучающей выборки. Однако при этом значительно возрастает объем обучающей выборки, необходимой для качественного распознавания. Действительно, одно из (простейших отклонений в изображении, например, буквы Н состоит в том, что одна из засечек будет отсутствовать. Поскольку Н имеет восемь засечек, то для того, чтобы эталонное описание отражало все возможные исчезновения (уменьшения длины) засечек, необходимо, чтобы в обучающей выборке было 28 изображений с разными комбинациями засечек. В то же время проектировщик легко обнаруживает, что у Н могут пропадать засечки уже при просмотре одного-двух десятков изображений. Поэтому он может сразу записать эталонное описание при просмотре слева, учитывающее все возможные исчезновения засечек (считаем для простоты, что перекладина сохраняется)
Ниже будет приведен алгоритм, который на основе стандартного описания позволяет полностью автоматически сформировать эталонное описание класса путем анализа изображений обучающей выборки. Однако при этом значительно возрастает объем обучающей выборки, необходимой для качественного распознавания. Действительно, одно из (простейших отклонений в изображении, например, буквы Н состоит в том, что одна из засечек будет отсутствовать. Поскольку Н имеет восемь засечек, то для того, чтобы эталонное описание отражало все возможные исчезновения (уменьшения длины) засечек, необходимо, чтобы в обучающей выборке было 28 изображений с разными комбинациями засечек. В то же время проектировщик легко обнаруживает, что у Н могут пропадать засечки уже при просмотре одного-двух десятков изображений. Поэтому он может сразу записать эталонное описание при просмотре слева, учитывающее все возможные исчезновения засечек (считаем для простоты, что перекладина сохраняется) 
 изображениям буквы Н с различными комбинациями засечек.
изображениям буквы Н с различными комбинациями засечек.
 сопоставляемых соответственно распознаваемым символам
сопоставляемых соответственно распознаваемым символам  . Каждая из этих совокупностей может рассматриваться как событие. Нетрудно видеть, что если нам удастся построить конечный автомат, в котором каждое из событий
. Каждая из этих совокупностей может рассматриваться как событие. Нетрудно видеть, что если нам удастся построить конечный автомат, в котором каждое из событий  будет представлено соответственно выходным сигналом
будет представлено соответственно выходным сигналом  то такой автомат полностью реализует функции координатора. Для построения такого автомата необходимо, чтобы множество событий
то такой автомат полностью реализует функции координатора. Для построения такого автомата необходимо, чтобы множество событий  было автоматным.
было автоматным.
 одно из событий, то условие II в нашем случае выполняется. Остается позаботиться о выполнении условия I; его в наших терминах можно сформулировать следующим образом: никакие два различных символа распознаваемого алфавита не должны описываться одинаковыми цепочками. Вопрос о построении автоматного множества событий будет рассмотрен в следующем параграфе вместе с алгоритмом построения таблиц переходов — выходов.
одно из событий, то условие II в нашем случае выполняется. Остается позаботиться о выполнении условия I; его в наших терминах можно сформулировать следующим образом: никакие два различных символа распознаваемого алфавита не должны описываться одинаковыми цепочками. Вопрос о построении автоматного множества событий будет рассмотрен в следующем параграфе вместе с алгоритмом построения таблиц переходов — выходов.
 занимают первый файл
занимают первый файл  символы
символы  — файл
— файл  и т. д., наконец, символ
и т. д., наконец, символ  — файл
— файл  Совокупность растров из одного файла (изображения одного и того же распознаваемого символа) будем называть списком. Далее путем моделирования в ЭВМ блока предварительной обработки производится фильтрация шумов и устранение мелких флуктуаций в изображении. При данном способе распознавания нет необходимости в утоньшении. По препарированному таким образом изображению путем моделирования работы дискриминатора находятся цепочки
Совокупность растров из одного файла (изображения одного и того же распознаваемого символа) будем называть списком. Далее путем моделирования в ЭВМ блока предварительной обработки производится фильтрация шумов и устранение мелких флуктуаций в изображении. При данном способе распознавания нет необходимости в утоньшении. По препарированному таким образом изображению путем моделирования работы дискриминатора находятся цепочки  Исследования показали, что наиболее рациональным является следующий порядок просмотра растра: слева направо по горизонтали и сверху вниз по вертикали. Несмотря на принятые меры по сглаживанию, препарированные изображения одного и того же символа отличаются между собой. Эти различия резче всего проявляются на «стыках» представленных на рис. 3.11 элементов. Поскольку мелкие различия и детали не являются характерными элементами символа, то их следует исключить из описания.
Исследования показали, что наиболее рациональным является следующий порядок просмотра растра: слева направо по горизонтали и сверху вниз по вертикали. Несмотря на принятые меры по сглаживанию, препарированные изображения одного и того же символа отличаются между собой. Эти различия резче всего проявляются на «стыках» представленных на рис. 3.11 элементов. Поскольку мелкие различия и детали не являются характерными элементами символа, то их следует исключить из описания.
 заменяется на один символ и метку — натуральное число, обозначающее число повторений символа
заменяется на один символ и метку — натуральное число, обозначающее число повторений символа  Для удобства записи условимся метки писать а виде индекса над символом, как это принято в алгебре для показателей степени.
Для удобства записи условимся метки писать а виде индекса над символом, как это принято в алгебре для показателей степени.

 записывается в эталонное описание с меткой, определяющей диапазон изменения метки этой буквы во всех описаниях списка. Если какое-либо описание не содержит подцепочки, входящей в стандартное описание (метка некоторой буквы равна 0), то в эталонном описании эта буква вместе с ее списком помех заключается в фигурные скобки.
записывается в эталонное описание с меткой, определяющей диапазон изменения метки этой буквы во всех описаниях списка. Если какое-либо описание не содержит подцепочки, входящей в стандартное описание (метка некоторой буквы равна 0), то в эталонном описании эта буква вместе с ее списком помех заключается в фигурные скобки.
 входящей в список помех, равен или превосходит диапазон значений метки, стоящей на том же месте буквы а, одного из эталонных описаний любого из распознаваемых символов, то буква
входящей в список помех, равен или превосходит диапазон значений метки, стоящей на том же месте буквы а, одного из эталонных описаний любого из распознаваемых символов, то буква  записывается на соответствующем месте эталонного описания со значением индекса, равным нижней границе этих двух диапазонов.
записывается на соответствующем месте эталонного описания со значением индекса, равным нижней границе этих двух диапазонов.





 с отброшенными метками совпадают, рассматриваются диапазоны хотя бы одной буквы, входящей в
с отброшенными метками совпадают, рассматриваются диапазоны хотя бы одной буквы, входящей в  не пересекаются или верхняя граница диапазона какой-либо буквы в со, строго меньше верхней границы той же буквы в со, (или наоборот), цепочки со, и
не пересекаются или верхняя граница диапазона какой-либо буквы в со, строго меньше верхней границы той же буквы в со, (или наоборот), цепочки со, и  считаются различными, но при синтезе координатора учитываются диапазоны этой буквы.
считаются различными, но при синтезе координатора учитываются диапазоны этой буквы.
 (последняя при наличии разрыва в верхней горизонтальной линии) при просмотре сверху вниз имеют одинаковые описания если не учитывать диапазоны
(последняя при наличии разрыва в верхней горизонтальной линии) при просмотре сверху вниз имеют одинаковые описания если не учитывать диапазоны  .
.

 не пересекается с диапазонами той же буквы в
не пересекается с диапазонами той же буквы в  Этого достаточно для различения буквы
Этого достаточно для различения буквы  от
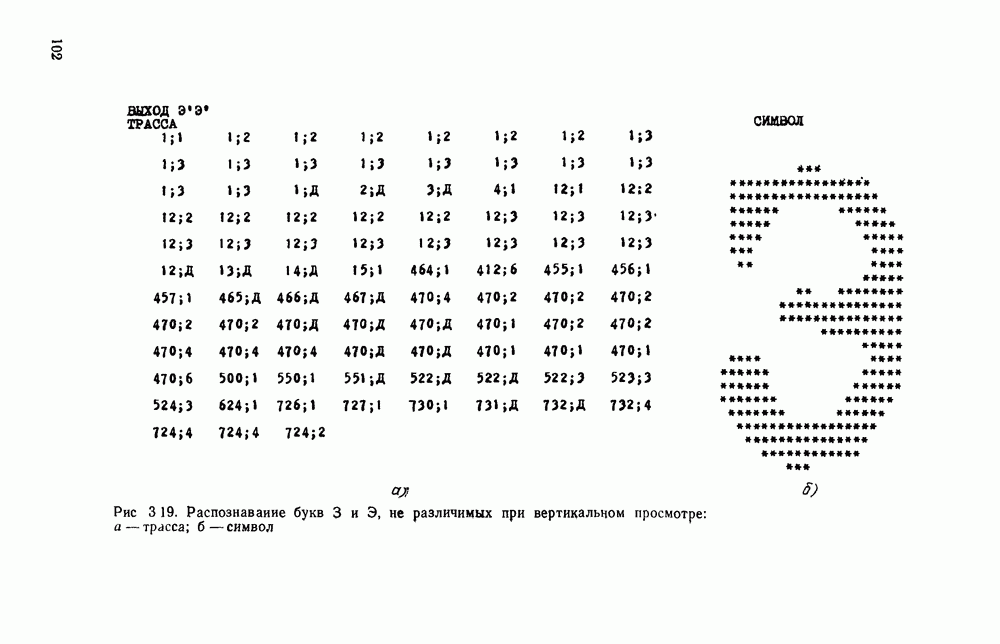
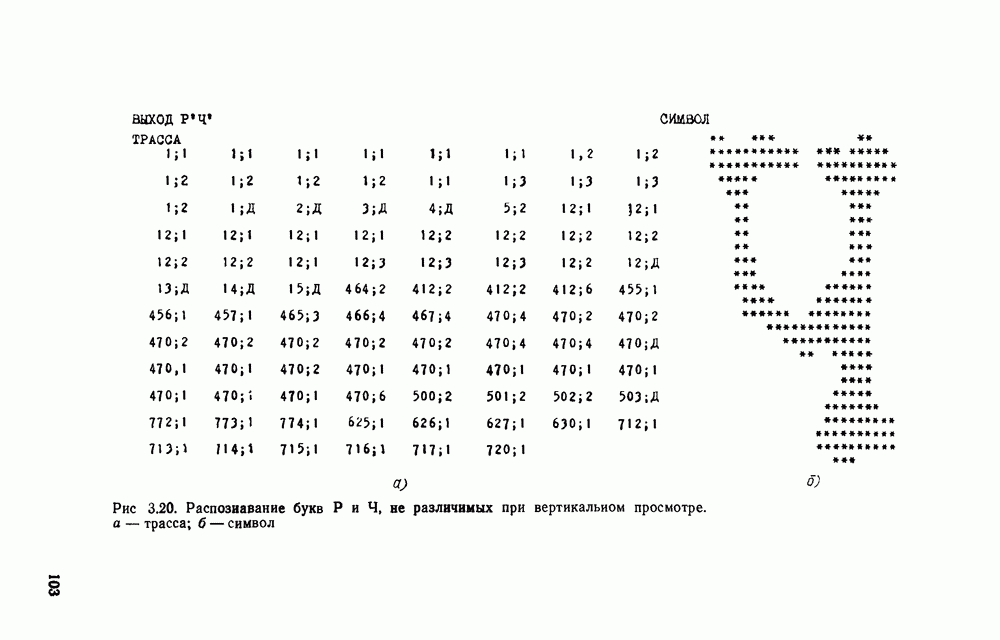
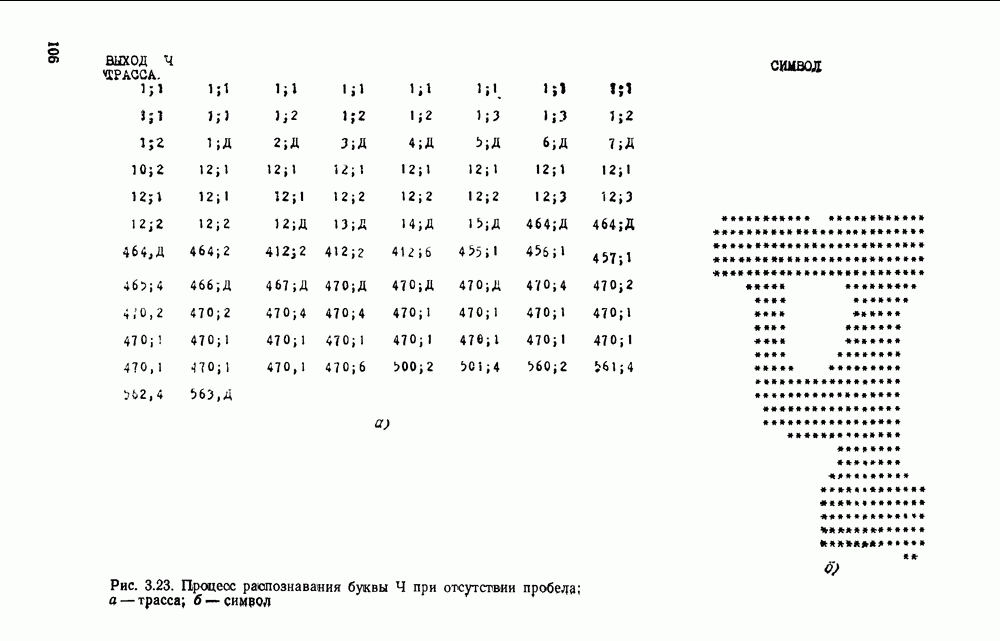
от  . Что касается различения Ч и Р (с учетом искажения), то при просмотре по вертикали при выбранном алфавите их различить невозможно. Это легко сделать при просмотре по горизонтали.
. Что касается различения Ч и Р (с учетом искажения), то при просмотре по вертикали при выбранном алфавите их различить невозможно. Это легко сделать при просмотре по горизонтали.
 Вопрос о том, какие именно символы алфавита
Вопрос о том, какие именно символы алфавита  следует вести в описание, решается конструктором исходя из анализа изображений.
следует вести в описание, решается конструктором исходя из анализа изображений.