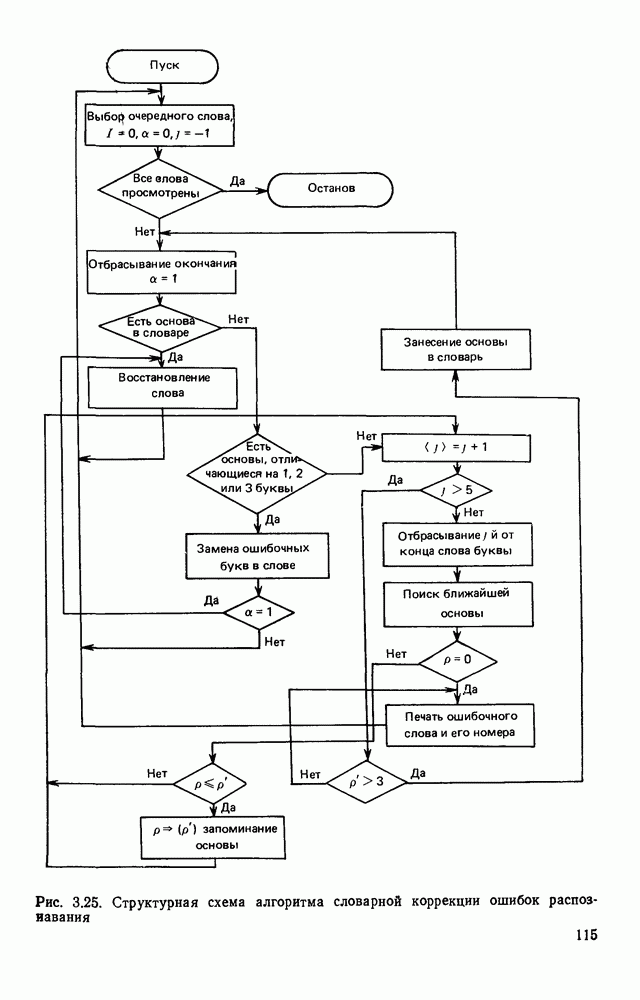
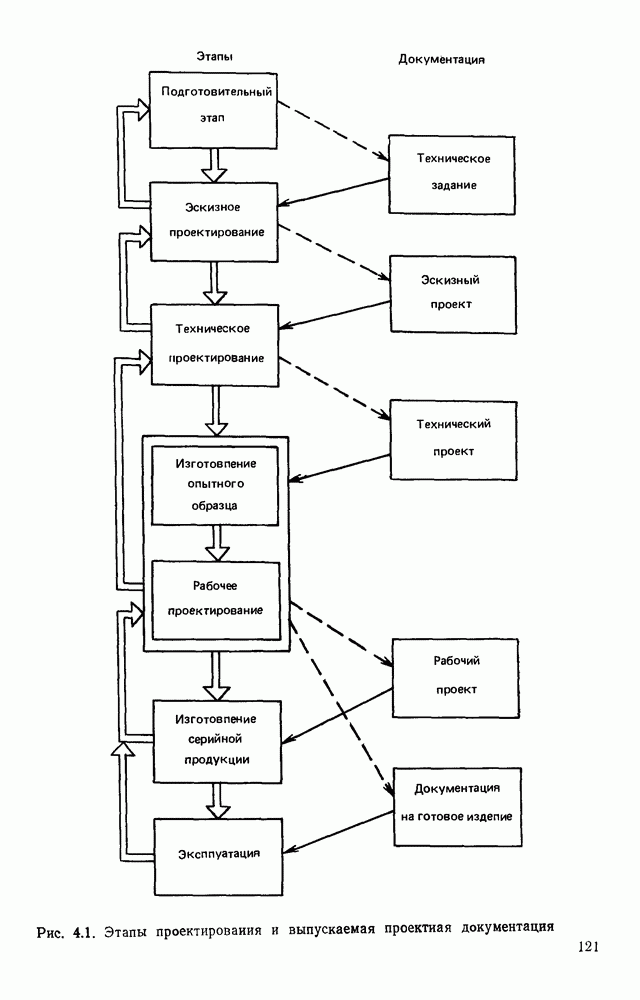
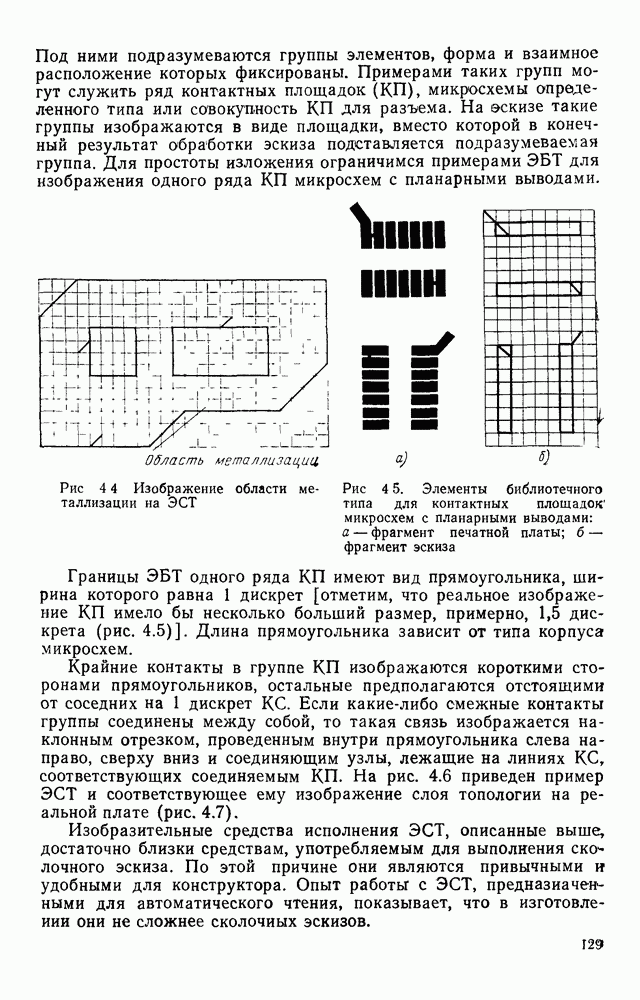
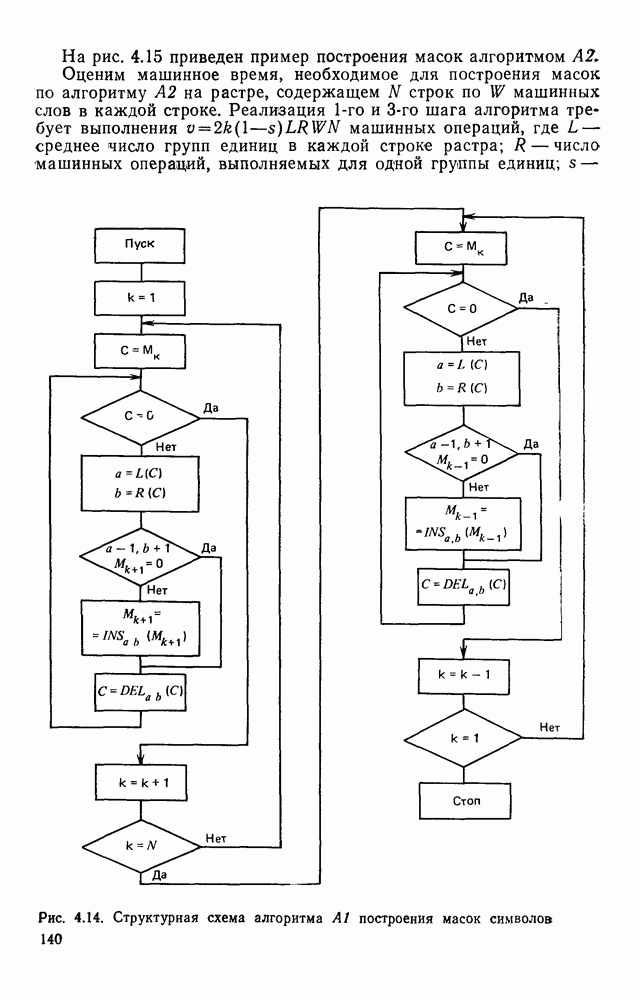
Пред.
След.
Макеты страниц
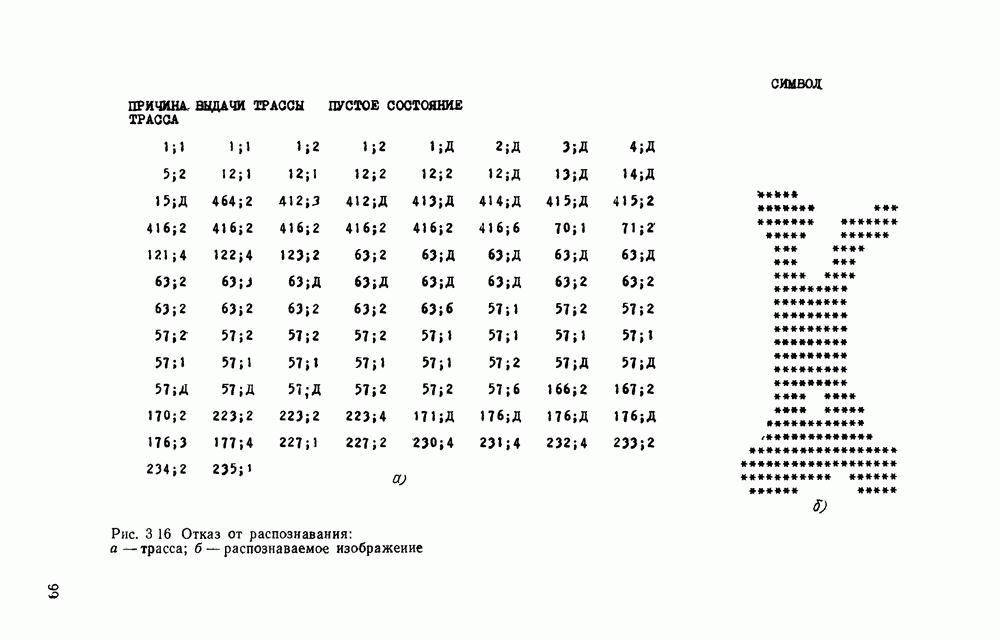
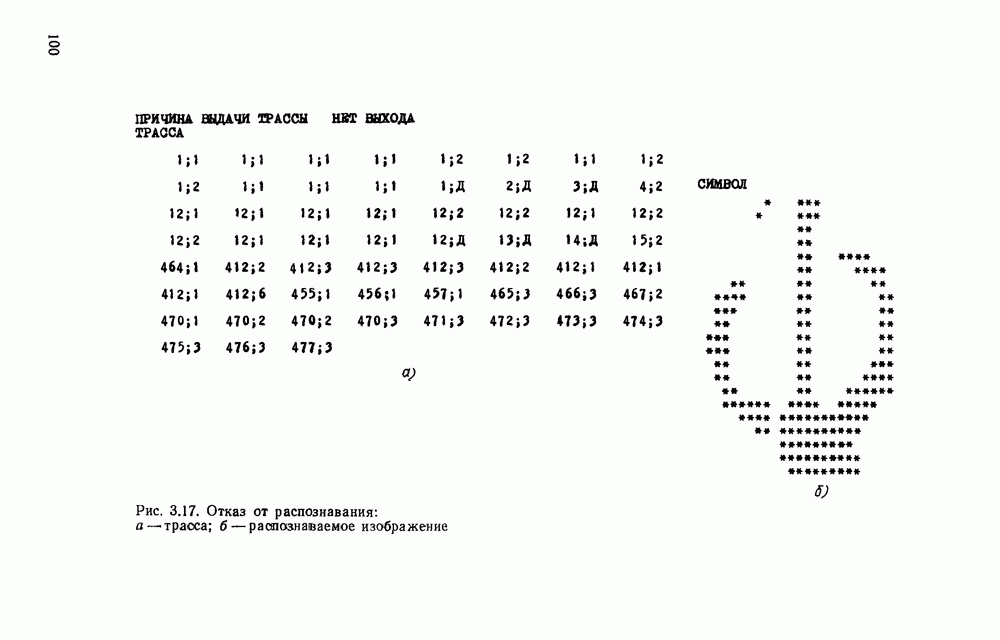
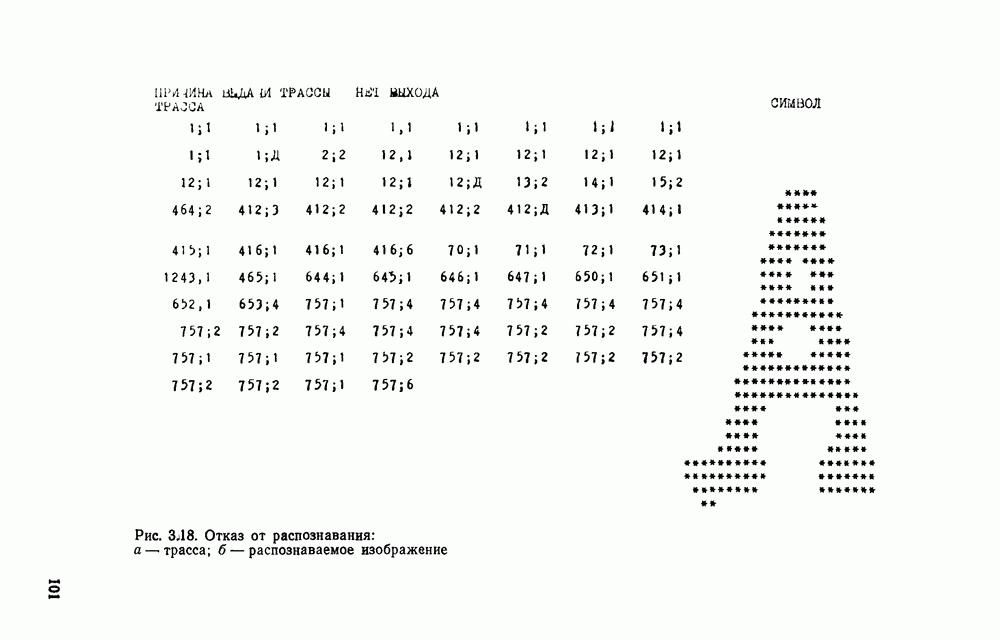
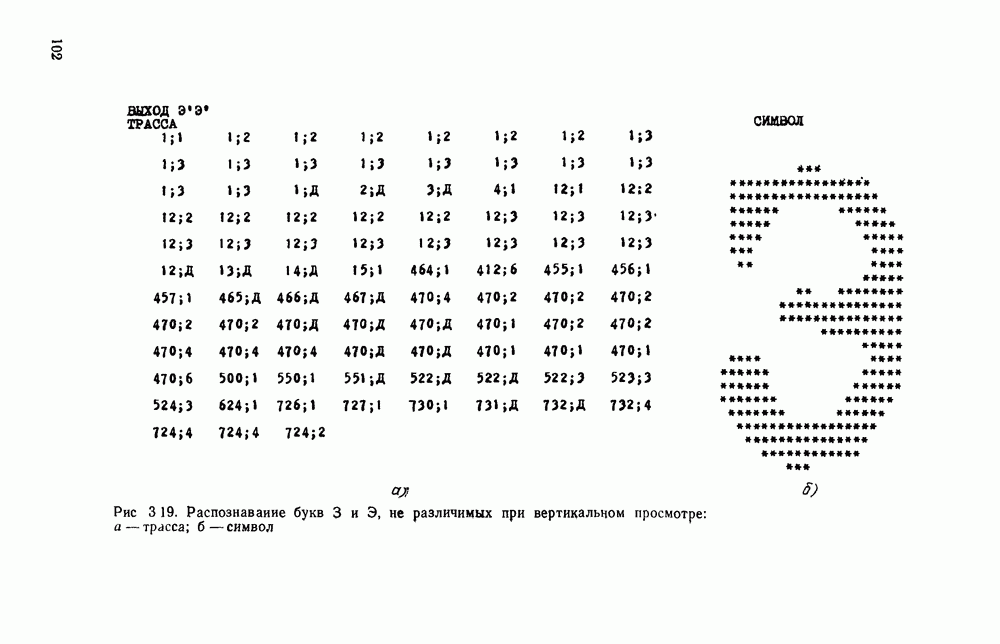
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
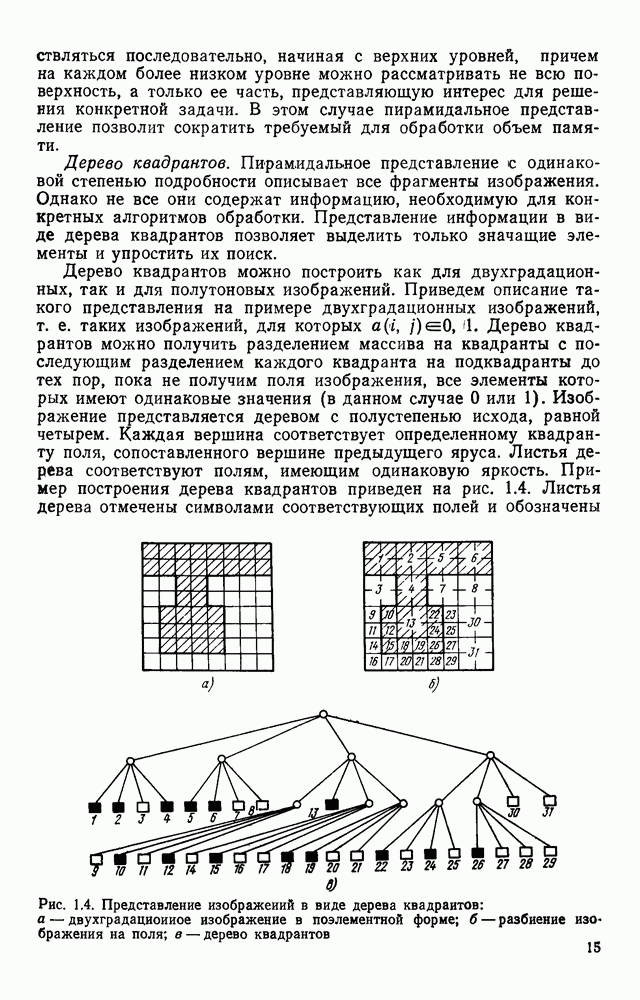
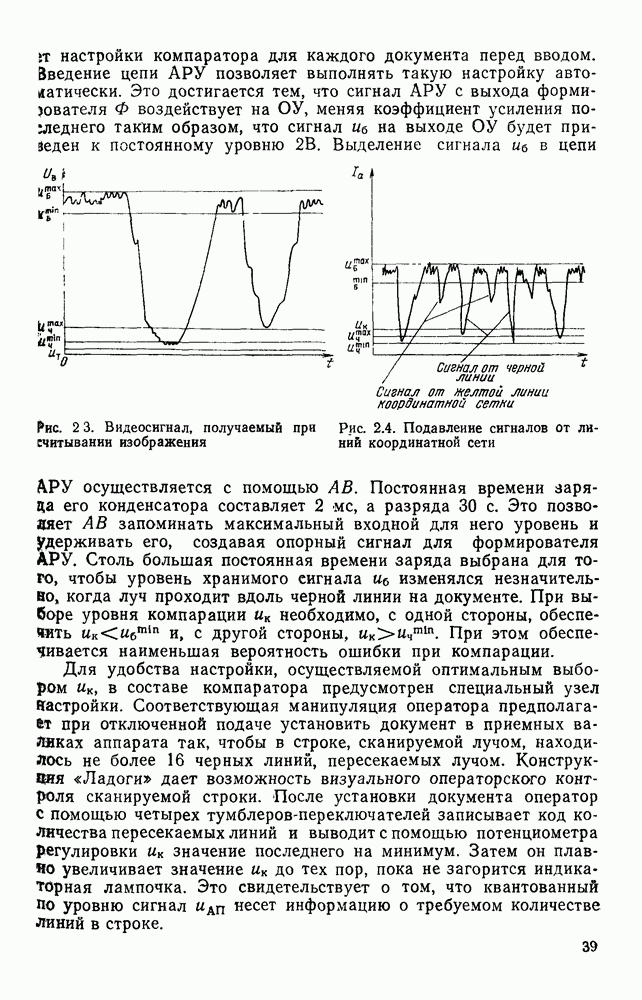
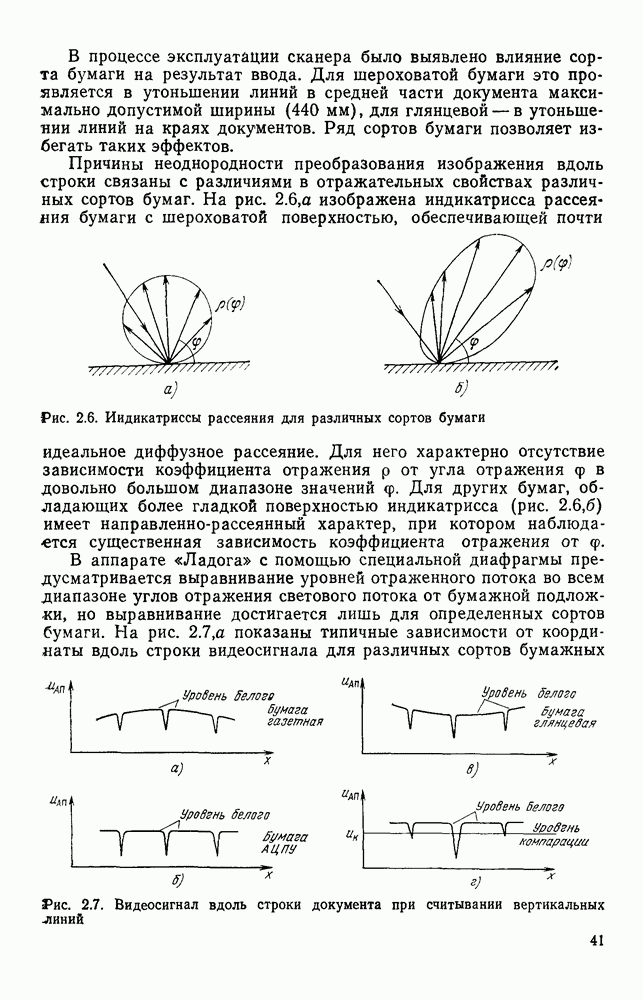
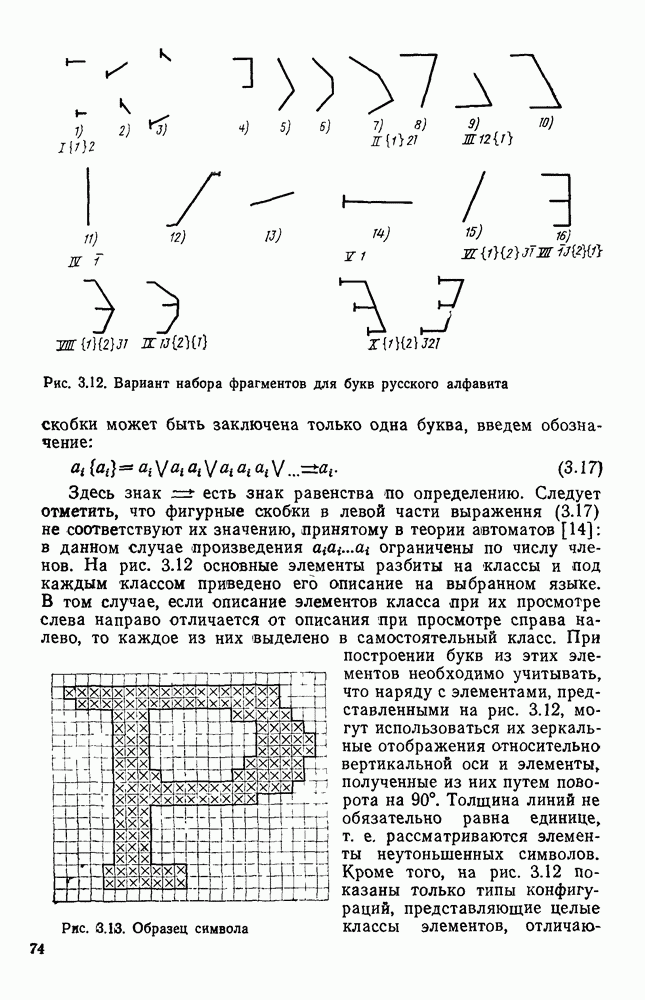
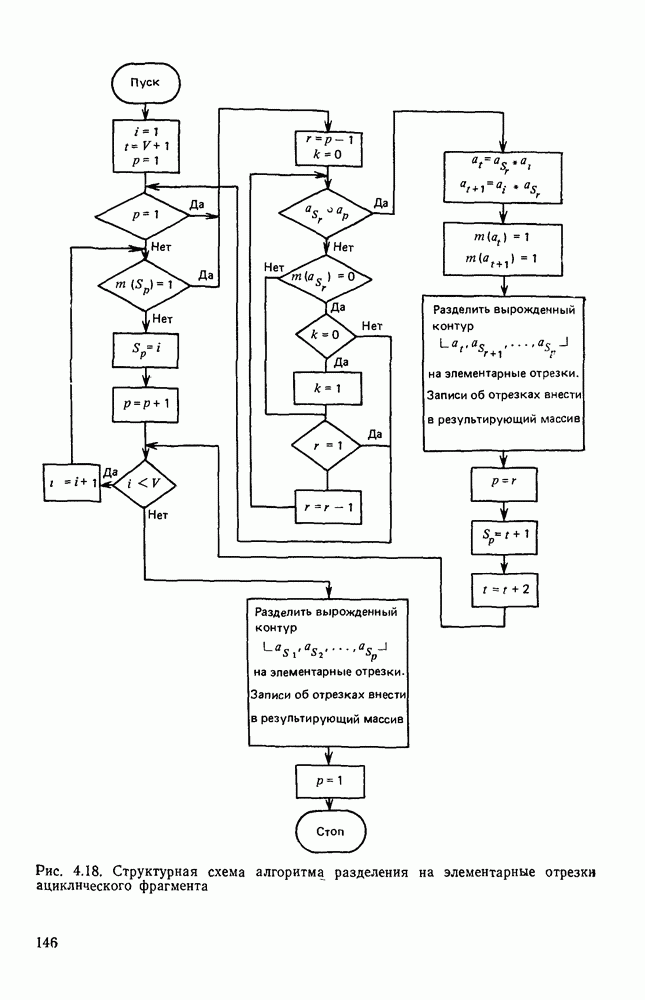
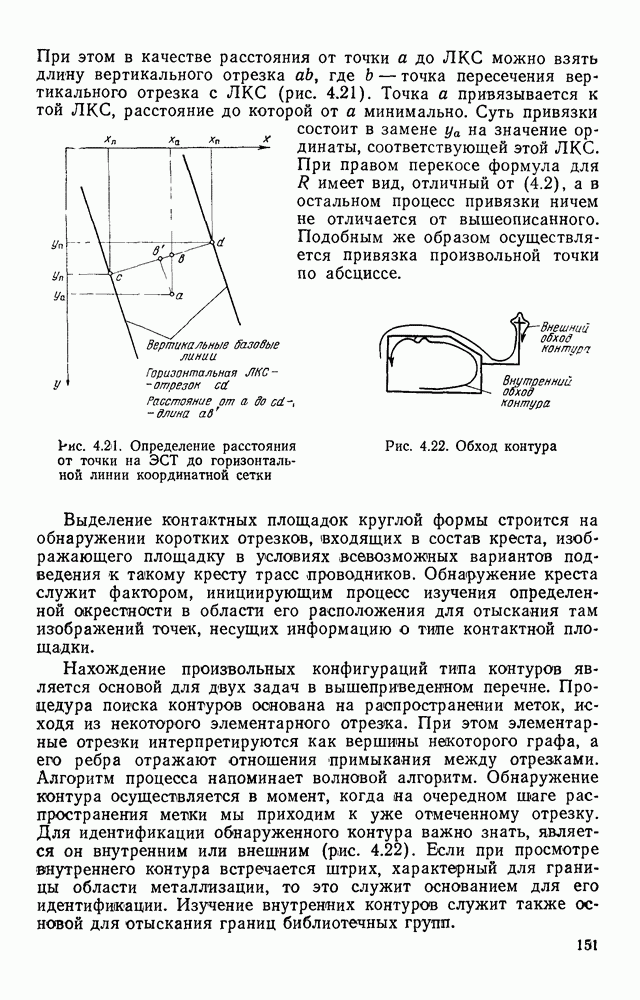
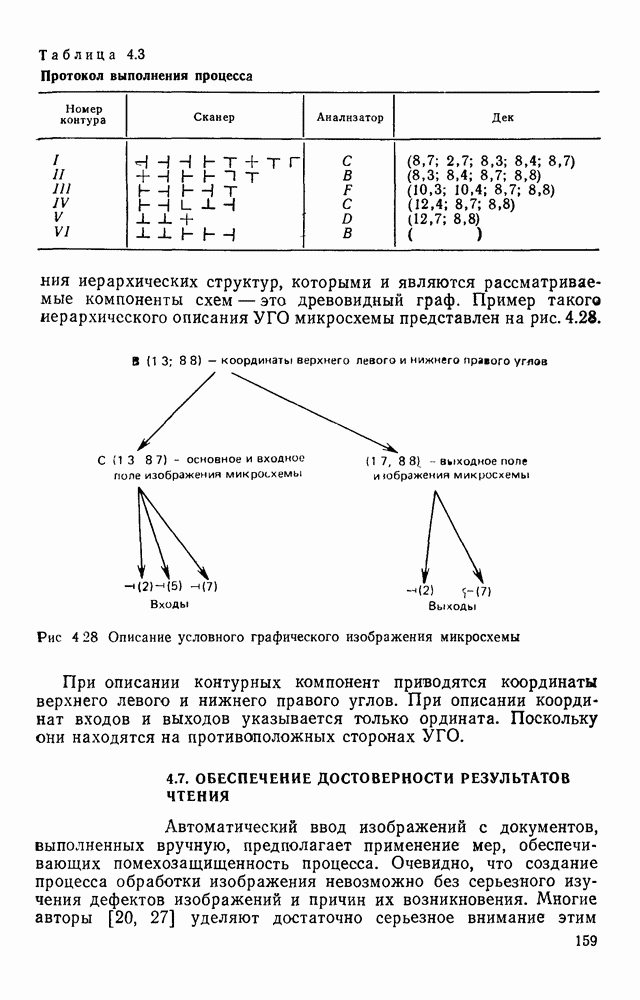
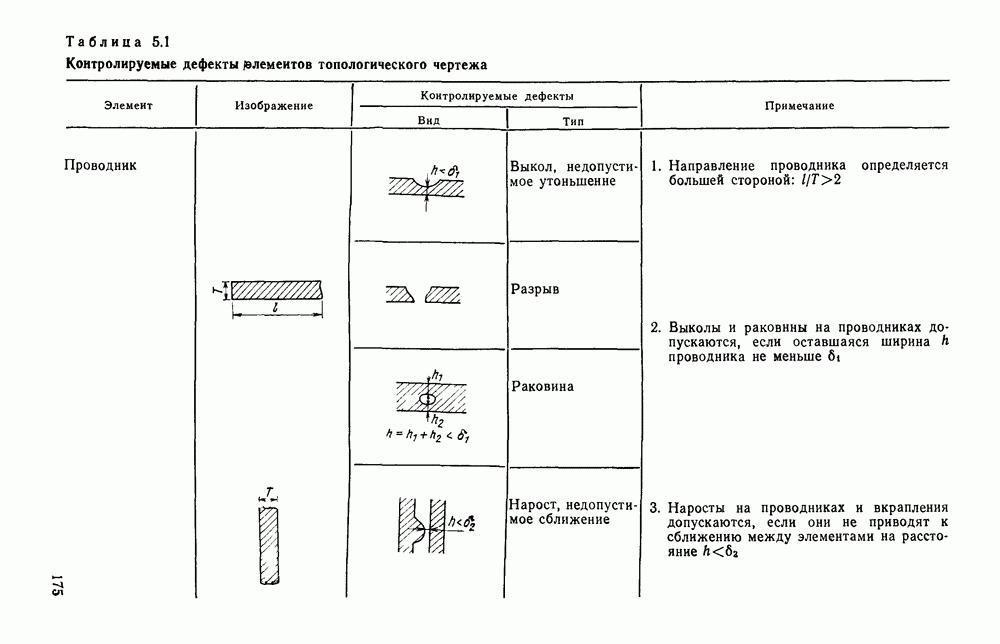
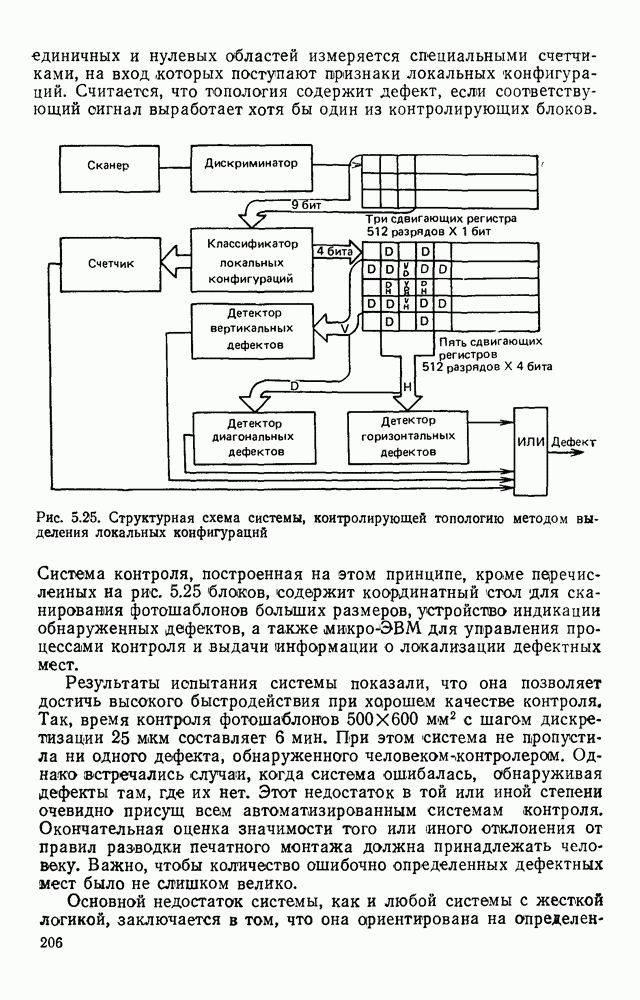
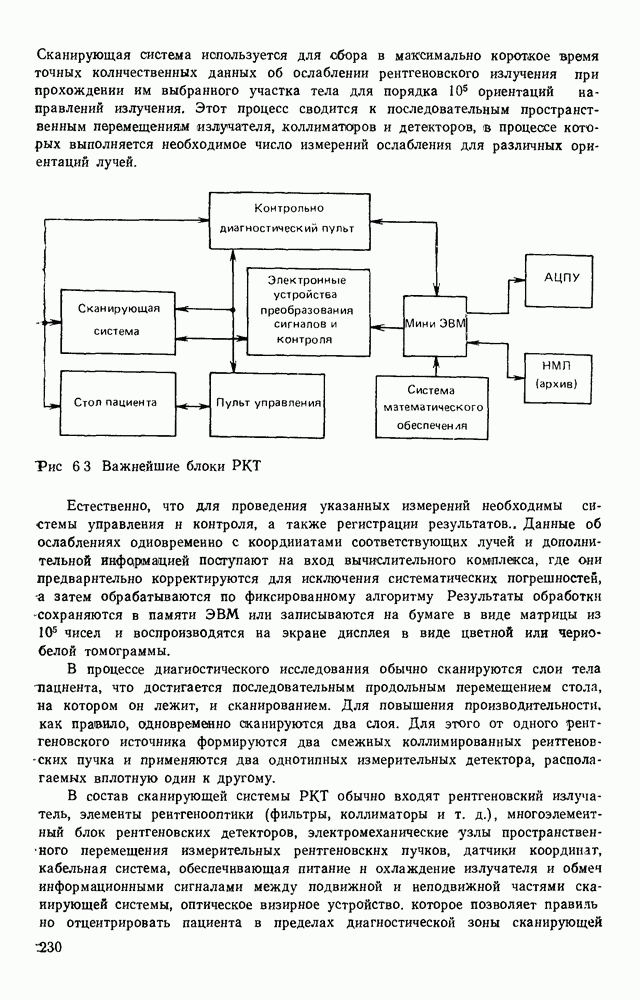
4.6. СПЕЦИАЛИЗИРОВАННАЯ ОБРАБОТКА ИЗОБРАЖЕНИИ ДЛЯ ПРИНЦИПИАЛЬНЫХ ЭЛЕКТРИЧЕСКИХ СХЕМСпециализированная обработка изображений принципиальных электрических схем (ПЭС) является более сложной задачей по сравнению с ранее рассмотренной. Дело в том, что в изображении ПЭС гораздо больше объектов, подлежащих распознаванию. Достаточно указать на чрезвычайное разнообразие УГО для микросхем, которые содержатся во многих ПЭС. Их распознавание представляет собой серьезную проблему. Метод распознавания предполагает, что изображения микросхем представлены соответствующими таблицами. Этим методом можно выделять также УГО для групп выводов, изображаемых в табличном виде, что достаточно часто встречается в ПЭС. Другие типичные элементы изображения ПЭС (резисторы, транзисторы, диоды, конденсаторы и т. п.) при обработке легко выявляются специализированными алгоритмами, подобными тем, которые применялись при специализированной обработке ЭСТ. Рассмотрим метод отыскания объектов изображения, имеющих табличную структуру. Для того чтобы представить иерархическую структурную информацию, содержащуюся в каждом образе, т. е. описывать образ при помощи более простых лодобразов, а каждый подобраз еще более простыми подобразами и так далее, был предложен синтаксический, или структурный подход. Этот подход основан на аналогии между структурой образов и синтаксисом языков. Анализу графических изображений структурными методами посвящено значительное число публикаций. Тем не менее разработчик системы распознавания обнаруживает, что прямое применение известных языков описаний графических объектов затруднительно либо из-за специфики рассматриваемых образов [46], либо, в случае универсальных языков, из-за отсутствия эффективных методов разбора и сложности приведения исходного описания к системе образующих данного языка. В связи с этим была разработана специализированная система, грамматика которой ориентирована на анализ принципиальных схем цифровой автоматики и электронных вычислительных устройств, построенных, в основном, на двоичных логических элементах. Анализ принципиальной схемы проводится в два этапа. На первом — выделяются компоненты принципиальной схемы: условные графические обозначения микросхем, шин, спецификаций, разъемов. На втором этапе проводится описание соединений между компонентами, выделенными на первом этапе. Синтаксический подход к распознаванию компонент электронных схем предполагает решение следующих задач. 1. Выбор языка описания элементов схем и грамматики описания объектов в этом языке. 2. Выбор способа приведения описания двумерных объектов к цепочке элементов, по которой распознавание ведется стандартными методами разбора, разработанными для построения трансляторов языков программирования. 3. Определение структуры выходного описания. Известны языки описания двумерных образов (плекс-грамматики, графовые грамматики [46]), для которых не надо решать задачу 2, но зато возрастает сложность приведения данных к исходному описанию, а также становятся неприменимыми хорошо разработанные методы раэбора. Начнем с языка исходного описания. Согласно ГОСТу чертеж, принципиальной схемы выполняется таким образом, что все вертикальные и горизонтальные линии ложатся на четырехмиллиметровую координатную сетку, и эквивалентное описание можно получить, закодировав все возможные ситуации в узлах сетки и представив изображение в виде двумерной матрицы. Элементами этой матрицы будут коды ситуаций в узлах сетки, а индексы элементов — координаты узла сетки, на которую ложится элемент. Разбор описания объектов принципиальных схем производится путем отслеживания контуров, из которых они состоят. Рассматриваемые объекты представляют собой табличные конструкции, образующиеся путем разбиения прямоугольника на ряд более мелких, называемых полями. Выделить все поля табличной конструкции можно отслеживанием контура линии, ограничивающей это поле. Контуры выделяют с левого верхнего, который начинается с элемента «г» (левый верхний угол). Адреса веек элементов «г», встречающихся на принципиальной схеме, сводятся в специальный список. В примере на рис. 4.23
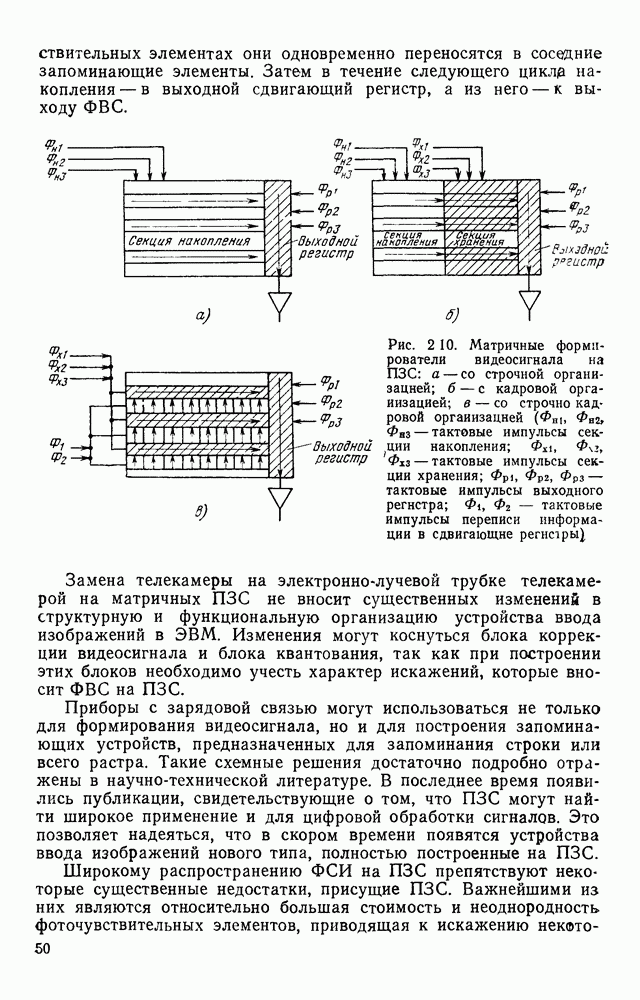
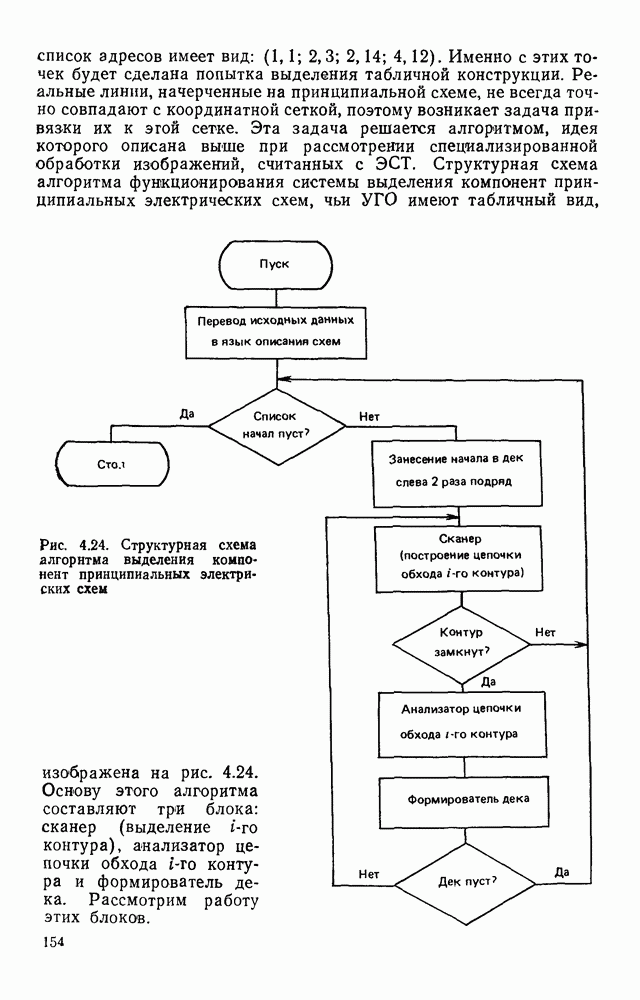
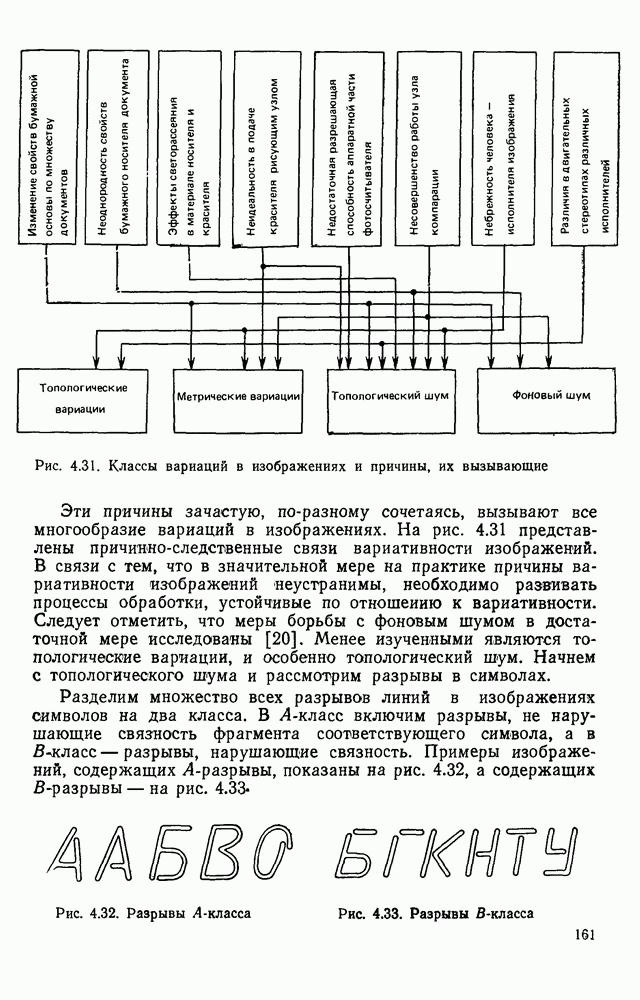
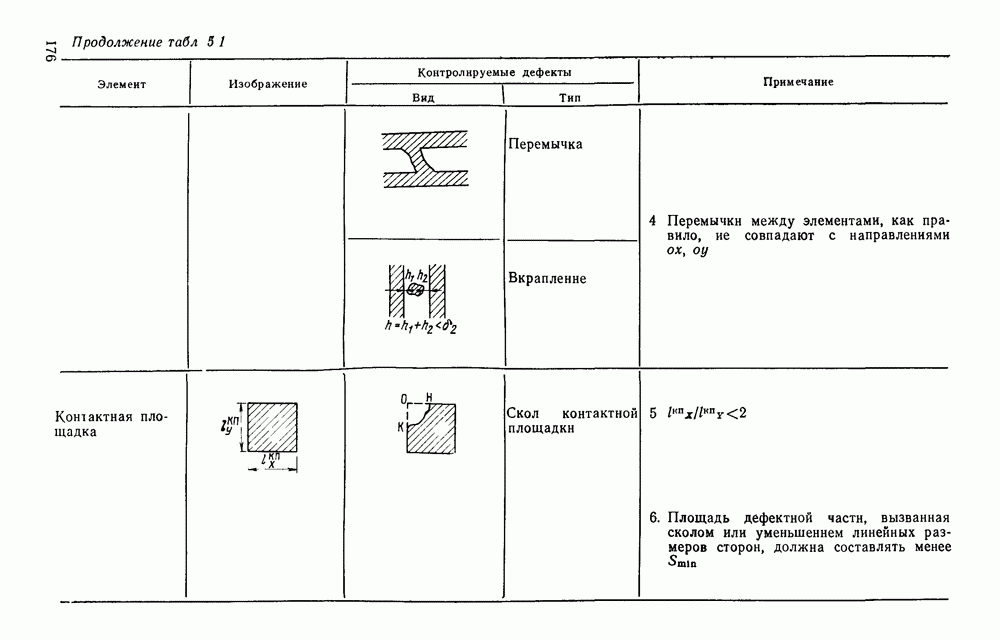
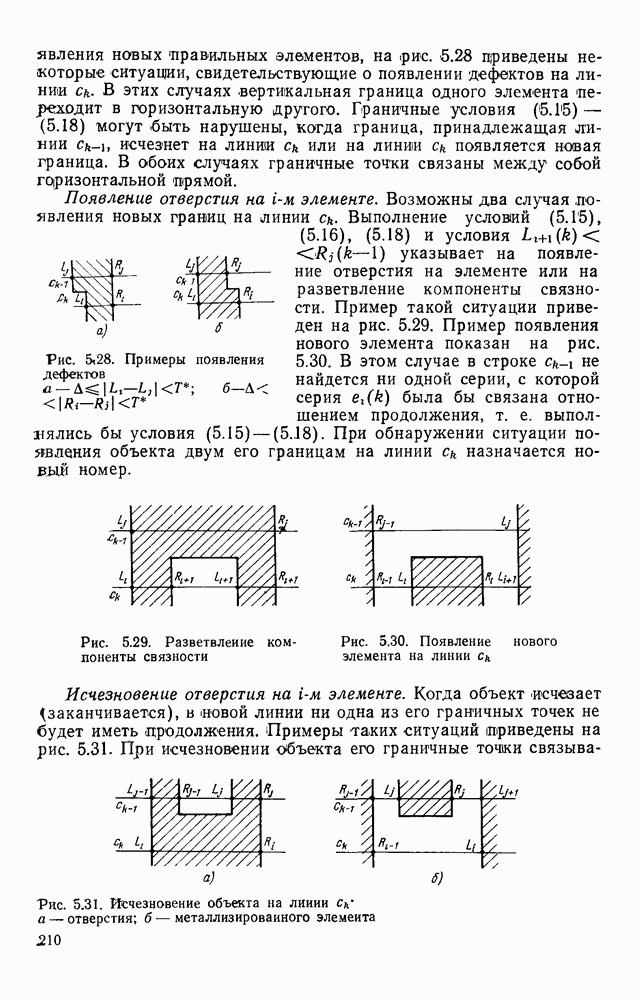
Рис. 4 23 Фрагмент принципиальной электрической схемы, выполненный в соответствии с требованиями входного описания список адресов имеет вид: (1,1; 2,3; 2,14; 4,12). Именно с этих точек будет сделана попытка выделения табличной конструкции. Реальные линии, начерченные на принципиальной схеме, не всегда точно совпадают с координатной сеткой, поэтому возникает задача привязки их к этой сетке. Эта задача решается алгоритмом, идея которого описана выше при рассмотрении специализированной обработки изображений, считанных с ЭСТ. Структурная схема алгоритма функционирования системы выделения компонент принципиальных электрических схем, чьи УГО имеют табличный вид, изображена на рис. 4.24. (см. скан) Рис. 4.24. Структурная схема алгоритма выделения компонент принципиальных электрических схем Основу этого алгоритма составляют три блока: сканер (выделение i-го контура), анализатор цепочки обхода i-го контура и формирователь дека. Рассмотрим работу этих блоков. Процедура сканирования объектов — процесс приведения исходного двумерного описания к последовательности элементов — одномерной структуре. Отслеживание контура строится таким образом, что он должен начинаться и заканчиваться в точках с заранее известными координатами. Эти точки — точки замыкания контура. Реально отслеженная цепочка элементов может и не образовывать контур, но если она начинается и заканчивается в точках замыкания, то это значит, что недостающая часть контура входит в состав контура, отслеженного на предыдущем шаге сканирования. Исходные данные для блока сканирования — принципиальная схема в описанном выше языке. Кроме того, известны координаты двух точек двумерной матрицы исходного описания. Необходимо выделить контур, начинающийся в первой точке и заканчивающийся во второй при движении против часовой стрелки. Отслеживание любого контура производится против часовой стрелки и начинается с угла, включенного в цепочку обхода ранее развернутого контура. При сканировании отбрасываются элементы, несущественные для последующего анализа, т. е. такие, которые не являются точками поворота линии либо ее ветвления. Процесс перебора элементов исходной двумерной матрицы строится так, что индексы очередного элемента отличаются от предыдущего не более, чем на единицу. При сканировании в выходную цепочку заносятся существенные для последующего анализа элементы. Элемент выходной цепочки — это триада (код, координаты х и у). Если появляется элемент, у которого изгиб линии против часовой стрелки составляет угол 90°, то происходит смена индекса, меняющего свое значение при переборе элементов исходной матрицы. Если элемент указывает на перегиб линии под другим углом (или по часовой стрелке), то сканирование завершается с сообщением о неудаче. Перейдем к описанию анализатора, в основу работы которого положен синтаксический анализ на основе предложенной нами грамматики. Алфавит грамматики включает все символы, которые могут встретиться в цепочках, поступающих с выхода сканера, и которые рассматриваются как терминальные, а также нетерминальные символы В, С, D, F, G, Н. Для удобства группу терминальных символов типа входов в табличные УГО обозначим через
Список правил грамматики имеет вид:
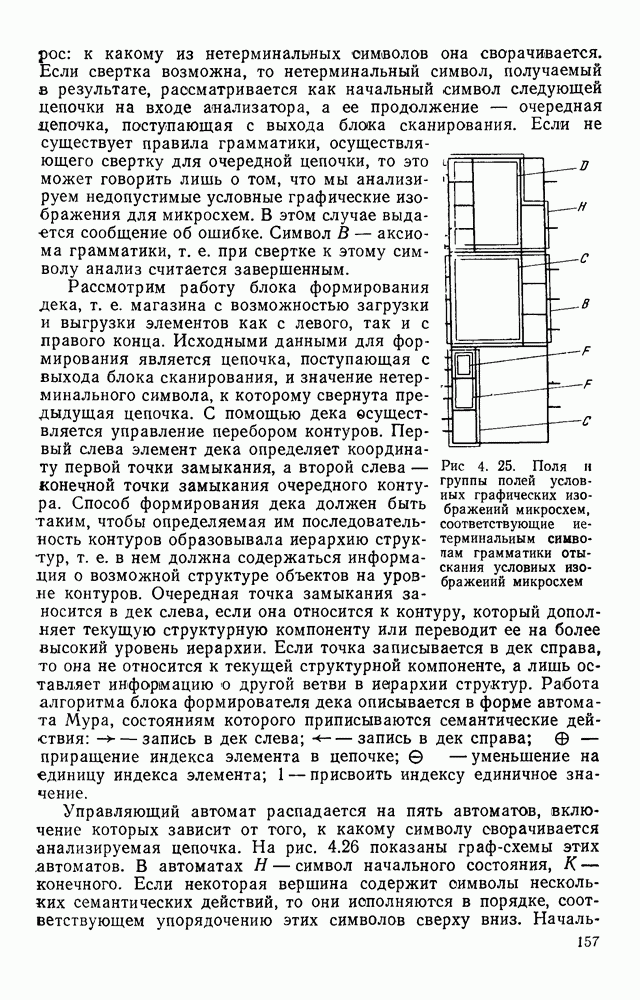
где n — максимальное количество входов; m — максимальное количество выходов; Нетерминальные символы грамматики имеют следующий смысл: F — незавершенная группа следующих подряд входных полей, включающая верхнее; С — вся группа входных полей либо основное поле при отсутствии группы входных полей; D — основное поле вместе Легко заметить при изучении правил грамматики, приведенных выше, что мы имеем дело с автоматной грамматикой. Анализ цепочки символов, поступающей с выхода блока сканирования, осуществляется в блоке анализатора и сводится к ответу на вопрос к какому из нетерминальных символов она сворачивается. Если свертка возможна, то нетерминальный символ, получаемый в результате, рассматривается как начальный символ следующей цепочки на входе анализатора, а ее продолжение — очередная депочка, поступающая с выхода блока сканирования. Если не существует правила грамматики, осуществляющего свертку для очередной цепочки, то это может говорить лишь о том, что мы анализируем недопустимые условные графические изображения для микросхем. В этом случае выдается сообщение об ошибке. Символ В — аксиома грамматики, т. е. при свертке к этому символу анализ считается завершенным.
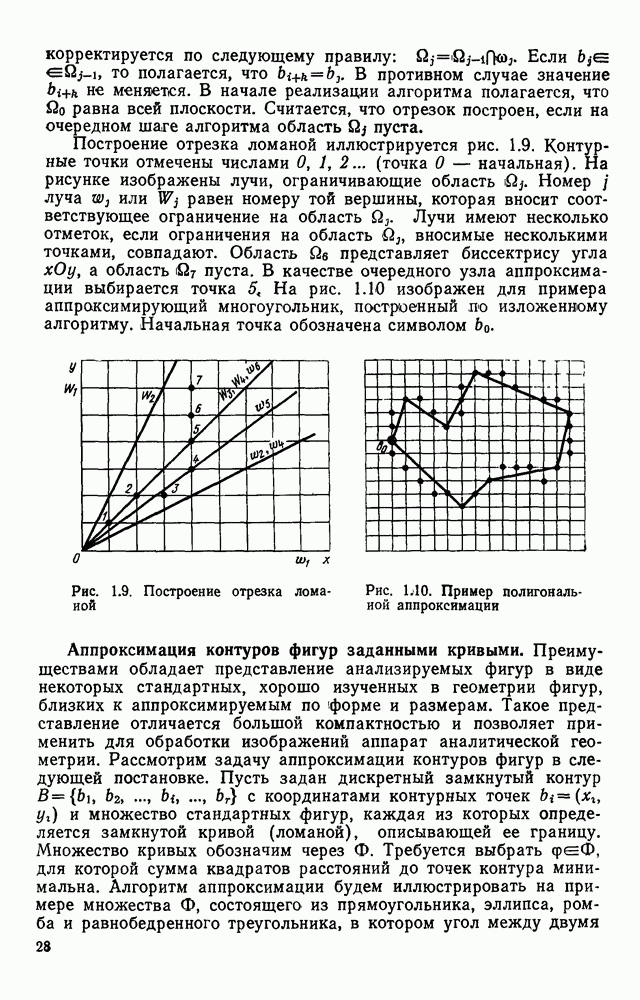
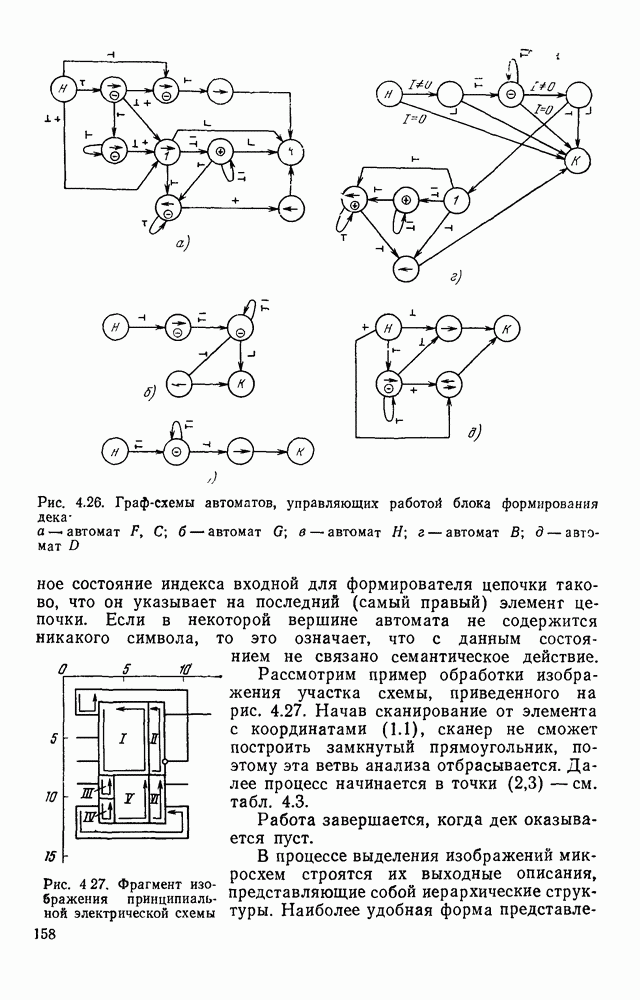
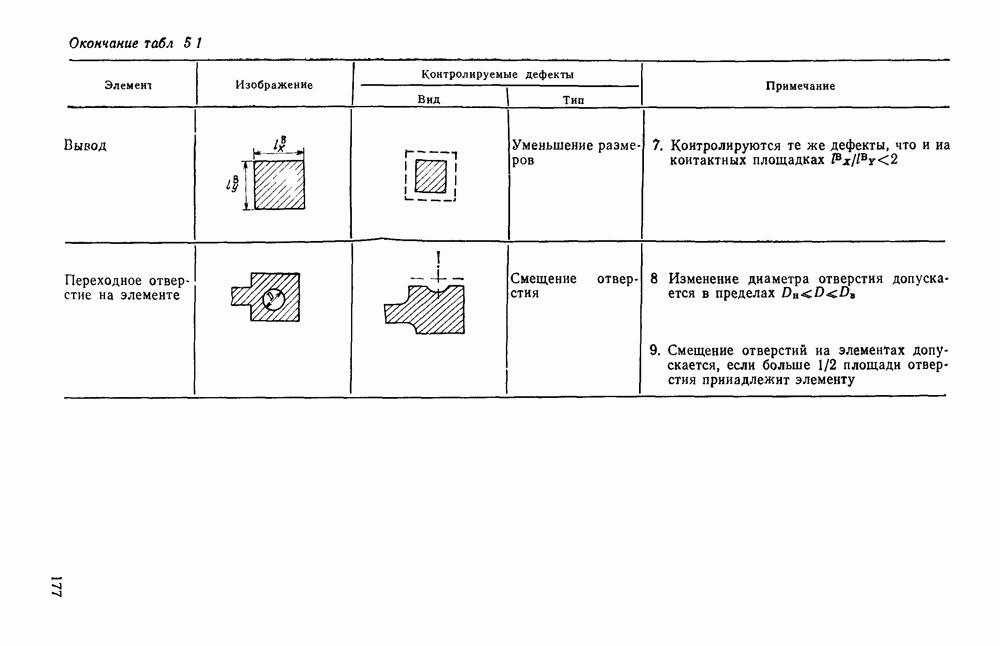
Рис. 4. 25. Поля и группы полей условных графических изображений микросхем, соответствующие нетерминальным символам грамматики отыскания условных изображений микросхем Рассмотрим работу блока формирования дека, т. е. магазина с возможностью загрузки и выгрузки элементов как с левого, так и с правого конца. Исходными данными для формирования является цепочка, поступающая с выхода блока сканирования, и значение нетерминального символа, к которому свернута предыдущая цепочка. С помощью дека осуществляется управление перебором контуров. Первый слева элемент дека определяет координату первой точки замыкания, а второй слева — конечной точки замыкания очередного контура. Способ формирования дека должен быть таким, чтобы определяемая им последовательность контуров образовывала иерархию структур, т. е. в нем должна содержаться информация о возможной структуре объектов на уровне контуров. Очередная точка замыкания заносится в Управляющий автомат распадается на пять автоматов, включение которых зависит от того, к какому символу сворачивается анализируемая цепочка. На рис. 4.26 показаны граф-схемы этих автоматов. В автоматах Н — символ начального состояния, К — конечного. Если некоторая вершина содержит символы нескольких семантических действий, то они исполняются в порядке, соответствующем упорядочению этих символов сверху вниз. Начальное
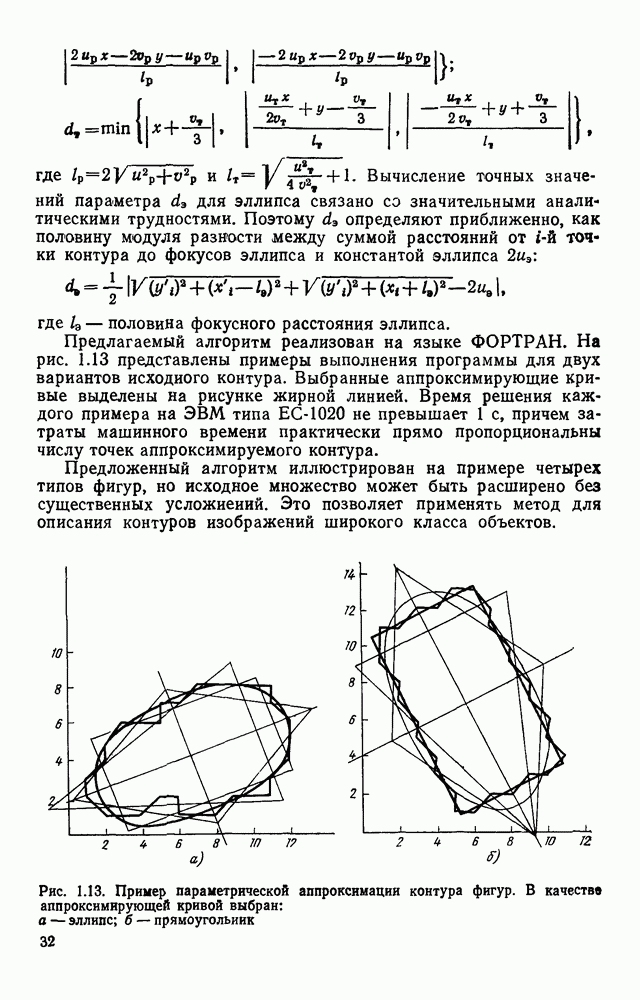
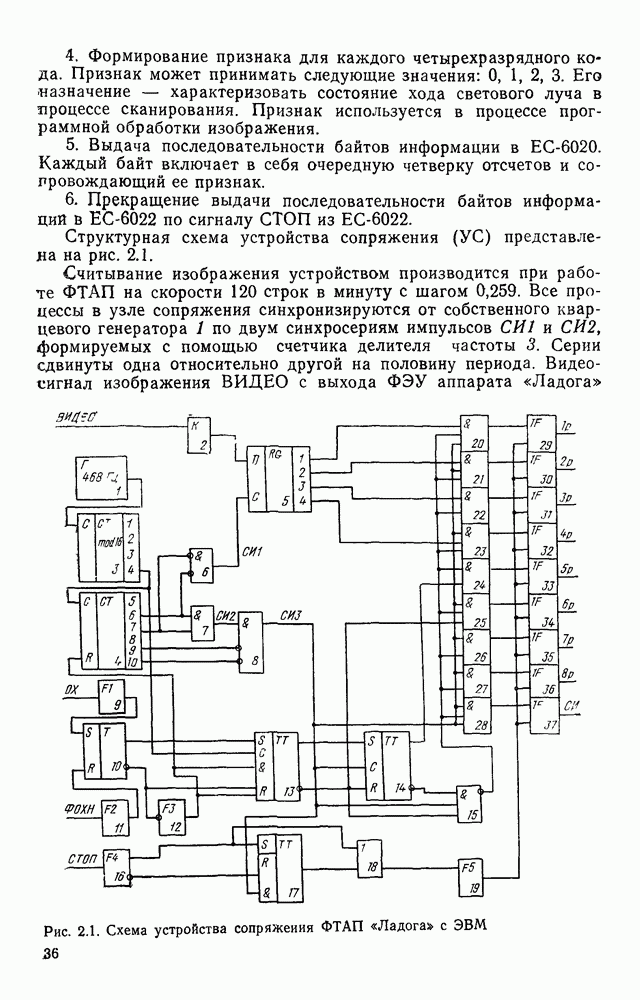
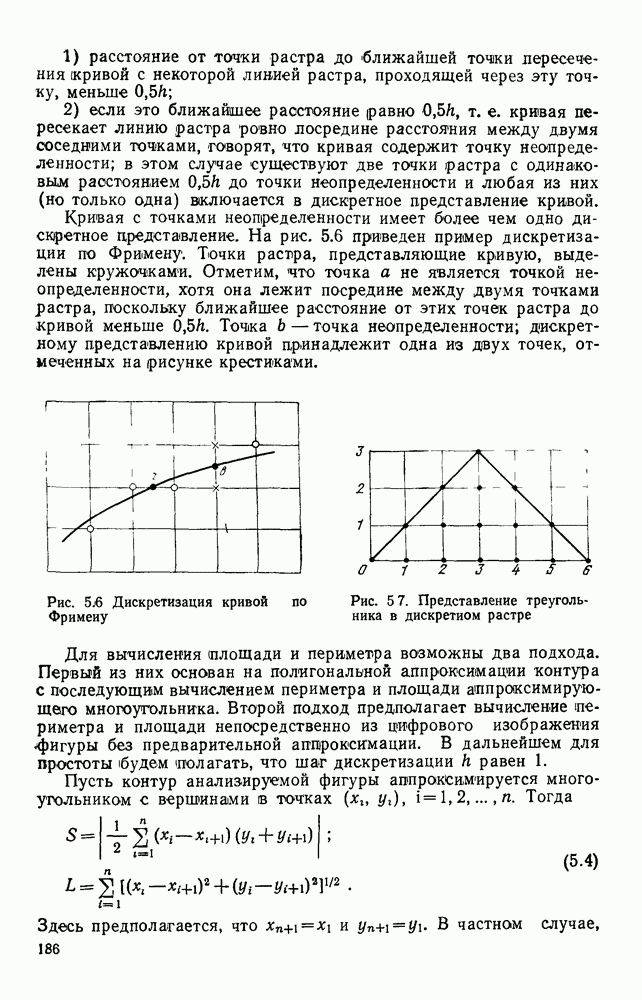
Рис. 4.26. Граф-схемы автоматов, управляющих работой блока формирования дека а — автомат F, С; б — автомат G; в — автомат состояние индекса входной для формирователя цепочки таково, что он указывает на последний (самый правый) элеменг цепочки. Если в некоторой вершине автомата не содержится никакого символа, то это означает, что с данным состоянием не связано семантическое действие. Рассмотрим пример обработки изображения участка схемы, приведенного на рис. 4.27. Начав сканирование от элемента с координатами (1.1), сканер не сможет построить замкнутый прямоугольник, поэтому эта ветвь анализа отбрасывается. Далее процесс начинается в точки (2,3) — см. табл. 4.3. Работа завершается, когда В процессе выделения изображений микросхем строятся их выходные описания, представляющие собой иерархические структуры. Наиболее удобная форма представления
Рис. 4 27. Фрагмент изображения принципиальной электрической схемы Таблица 4.3. Протокол выполнения процесса
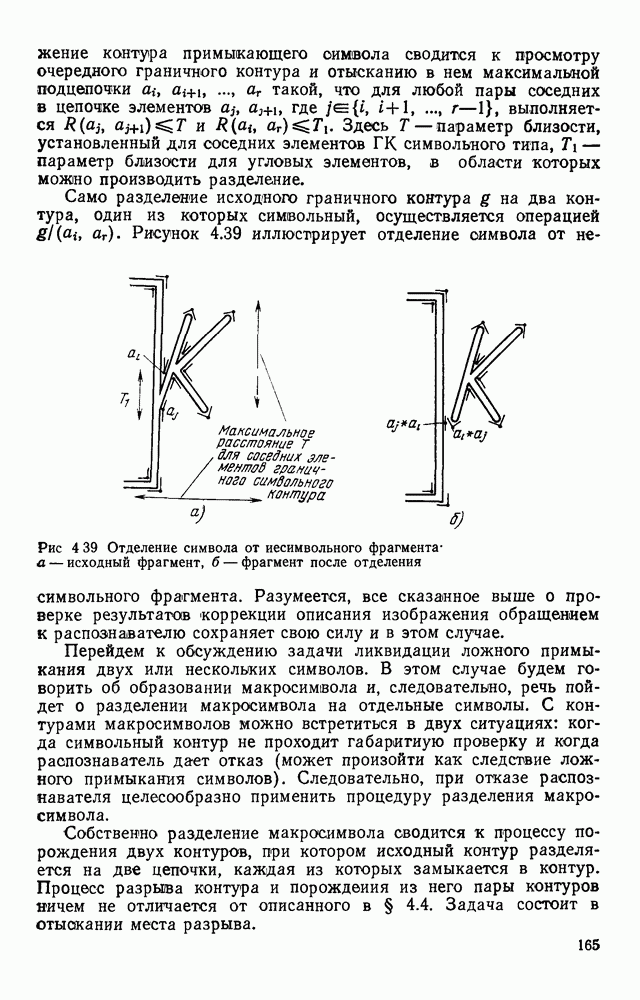
иерархических структур, которыми и являются рассматриваемые компоненты схем — это древовидный граф. Пример такого иерархического описания УГО микросхемы представлен на рис. 4.28.
Рис. 4.28. Описание условного графического изображения микросхемы При описании контурных компонент приводятся координаты верхнего левого и нижнего правого углов. При описании координат входов и выходов указывается только ордината. Поскольку они находятся на противоположных сторонах УГО.
|
 |
Оглавление
|





































































































































































































 , а группу выходов через
, а группу выходов через 


 — количество подполей выходного поля без единицы; (а) — элемент а либо опущен
— количество подполей выходного поля без единицы; (а) — элемент а либо опущен  , либо повторяется i раз
, либо повторяется i раз  -знак «или», означающий возможности выбора;
-знак «или», означающий возможности выбора;  — скобки, заключающие цепочки, разделенные символом
— скобки, заключающие цепочки, разделенные символом 
 всей группой входных полей при условии, что такая группа существует;
всей группой входных полей при условии, что такая группа существует;  — нижнее выходное поле в группе выходных полей вместе со всей совокупностью полей, левых по отношению к группе выходных; G — незавершенная группа следующих подряд выходных полей, включая нижнее, вместе со всей совокупностью полей, левых по отношению к группе выходных; В — вся группа выходных полей вместе со всей совокупностью полей, левых по отношению к группе выходных полей. На рис. 4.25 приведено изображение микросхем с разметкой, иллюстрирующей смысл нетерминальных символов.
— нижнее выходное поле в группе выходных полей вместе со всей совокупностью полей, левых по отношению к группе выходных; G — незавершенная группа следующих подряд выходных полей, включая нижнее, вместе со всей совокупностью полей, левых по отношению к группе выходных; В — вся группа выходных полей вместе со всей совокупностью полей, левых по отношению к группе выходных полей. На рис. 4.25 приведено изображение микросхем с разметкой, иллюстрирующей смысл нетерминальных символов.

 слева, если она относится к контуру, который дополняет текущую структурную компоненту или переводит ее на более высокий уровень иерархии. Если точка записывается в
слева, если она относится к контуру, который дополняет текущую структурную компоненту или переводит ее на более высокий уровень иерархии. Если точка записывается в  справа, то она не относится к текущей структурной компоненте, а лишь оставляет информацию о другой ветви в иерархии структур. Работа алгоритма блока формирователя дека описывается в форме автомата Мура, состояниям которого приписываются семантические действия:
справа, то она не относится к текущей структурной компоненте, а лишь оставляет информацию о другой ветви в иерархии структур. Работа алгоритма блока формирователя дека описывается в форме автомата Мура, состояниям которого приписываются семантические действия:  - запись в дек слева;
- запись в дек слева;  - запись в дек справа;
- запись в дек справа;  приращение индекса элемента в цепочке;
приращение индекса элемента в цепочке;  — уменьшение на единицу индекса элемента; 1 — присвоить индексу единичное значение.
— уменьшение на единицу индекса элемента; 1 — присвоить индексу единичное значение.

 ; г — автомат В; д — автомат
; г — автомат В; д — автомат 
 оказывается пуст.
оказывается пуст.


