Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
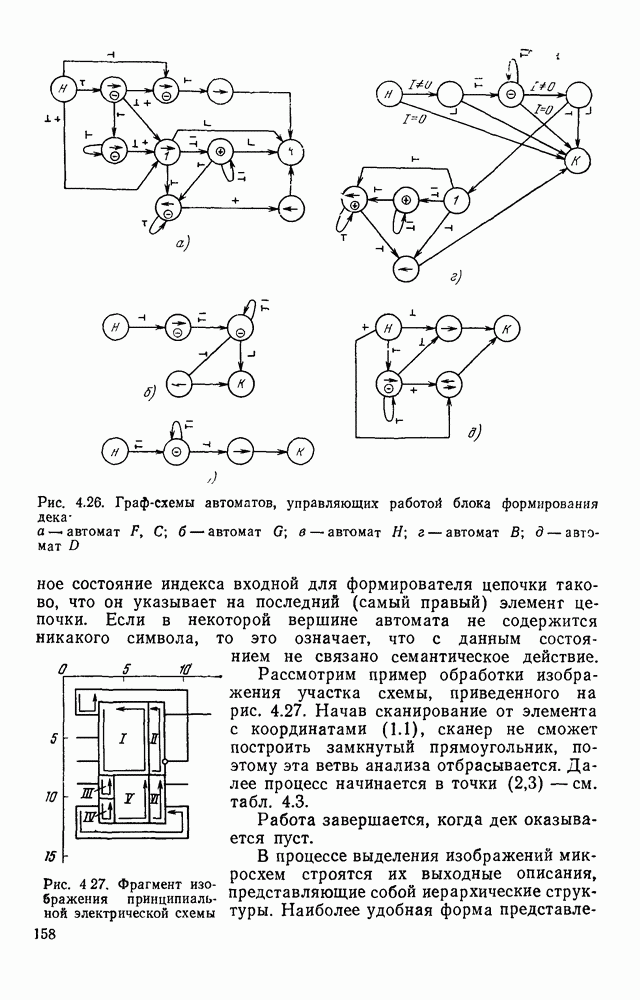
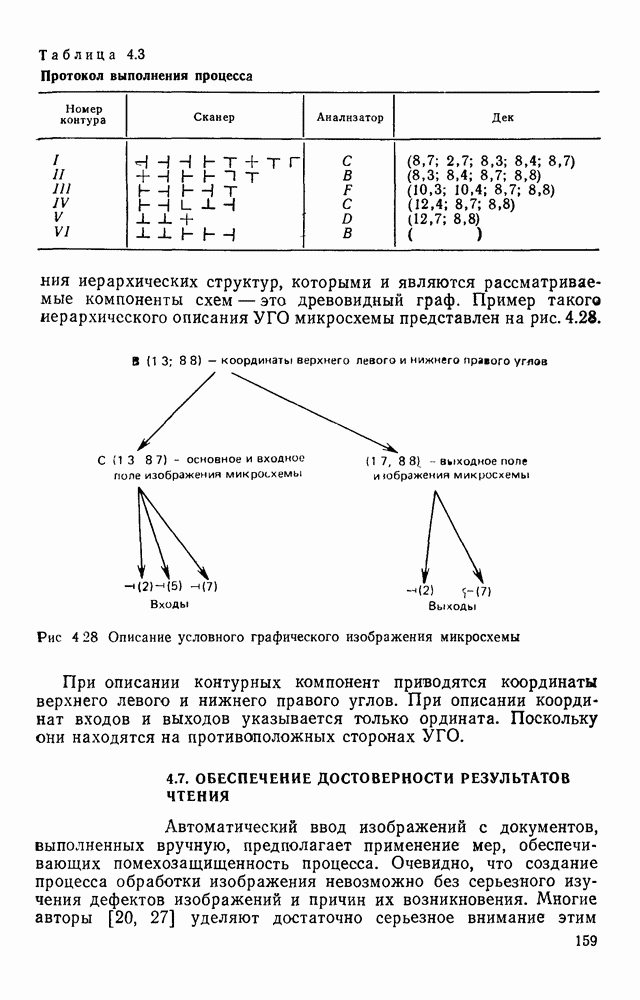
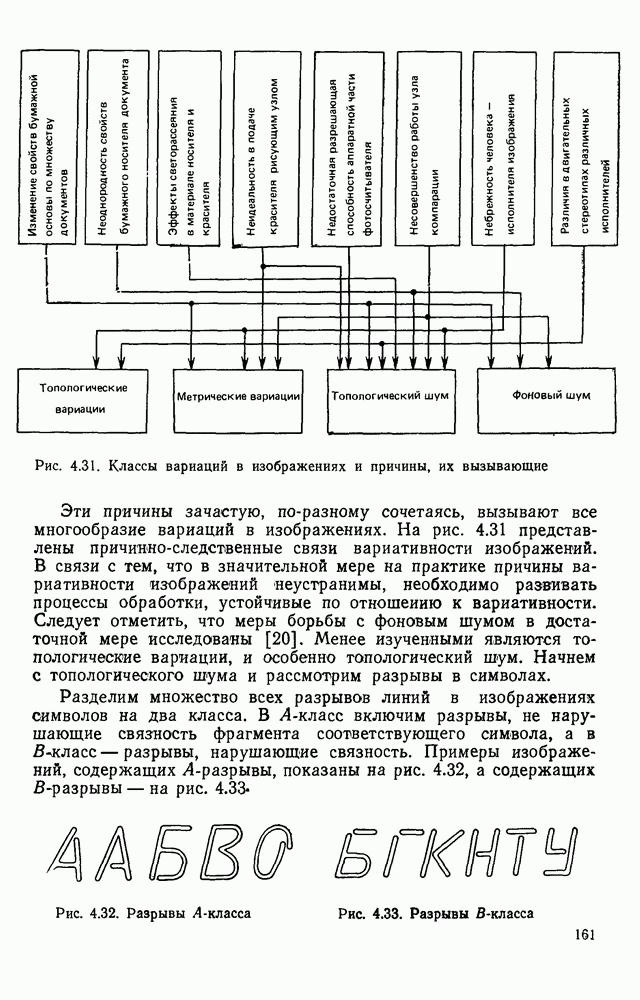
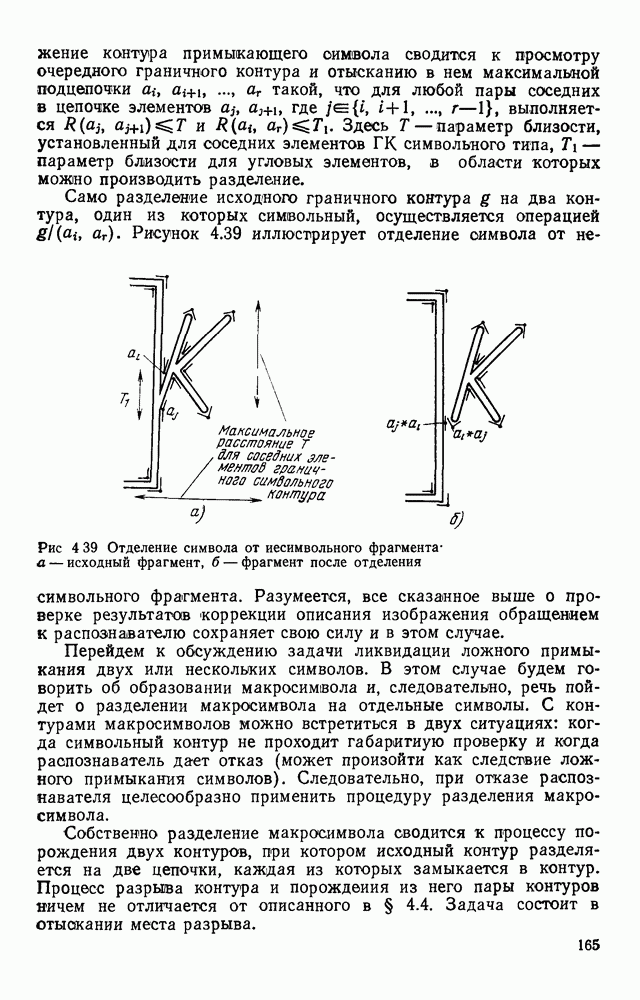
ZADANIA.TO
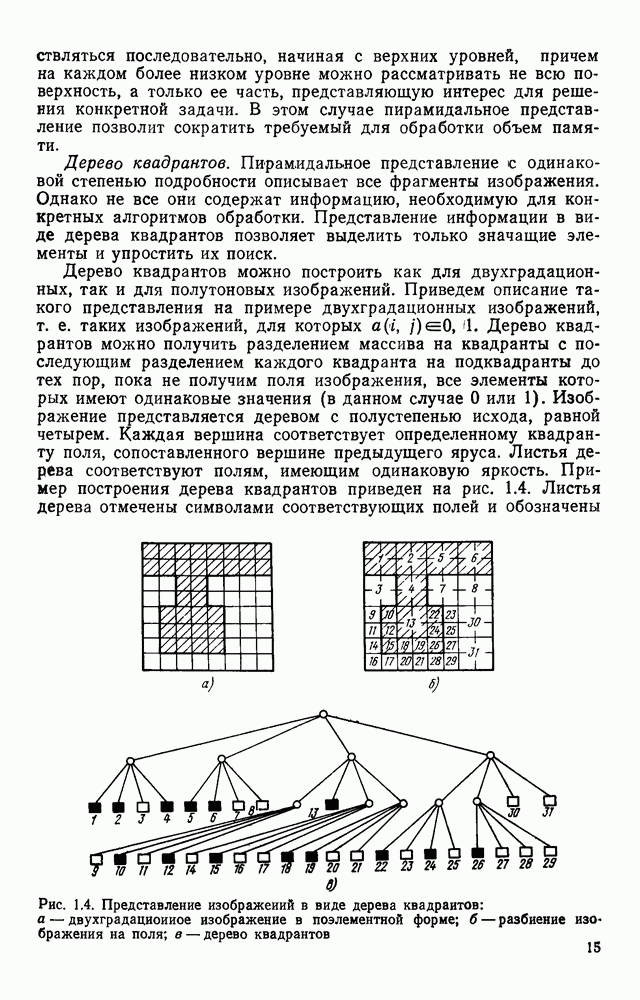
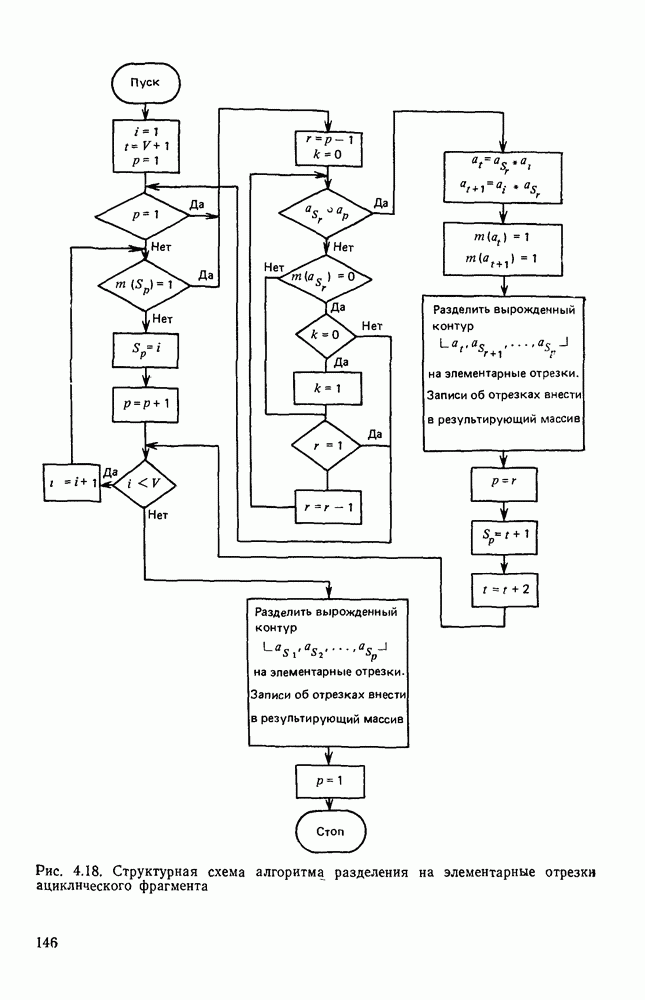
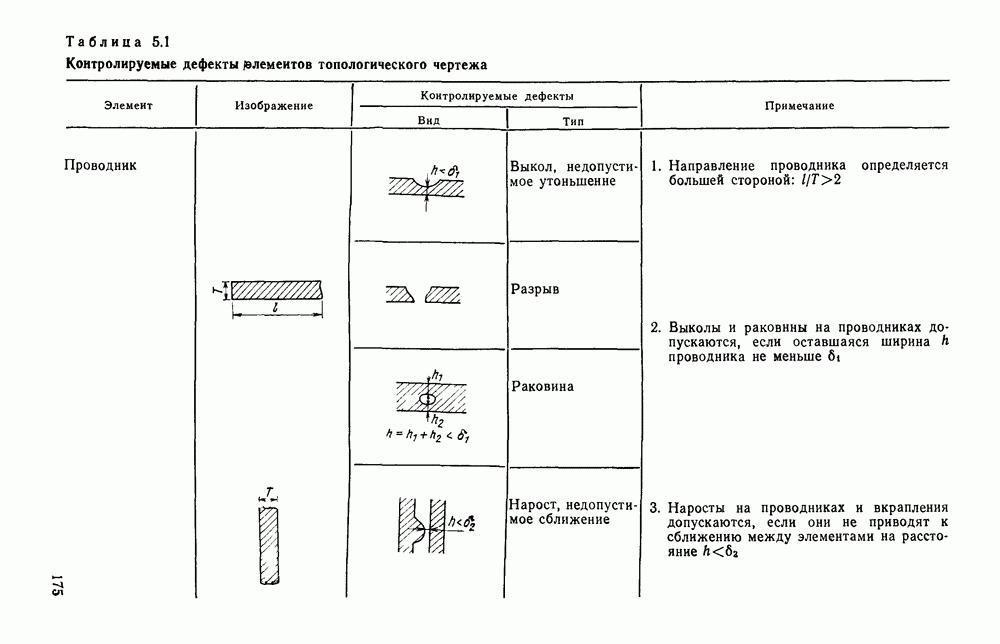
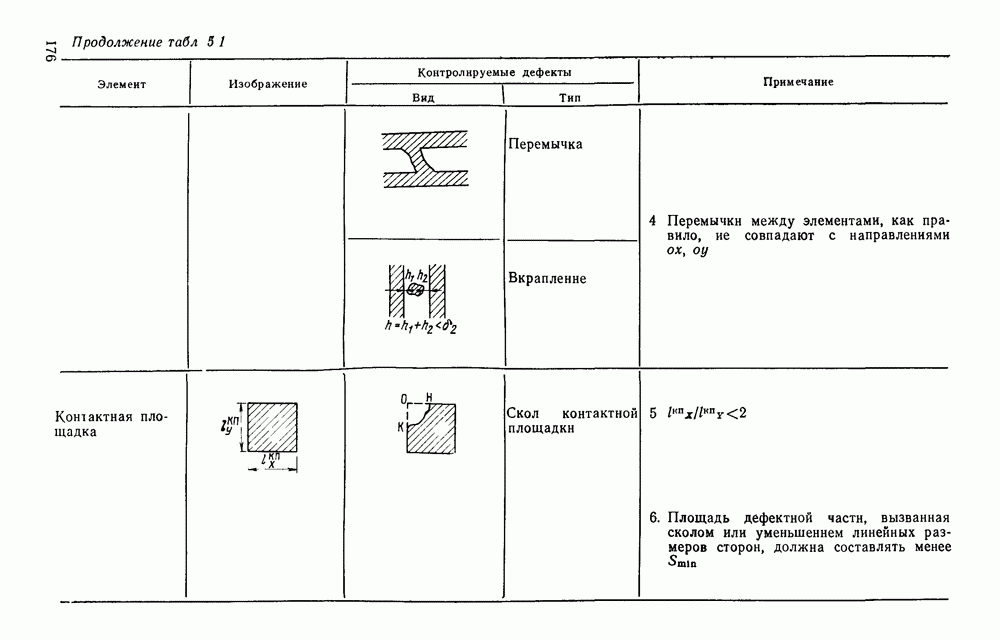
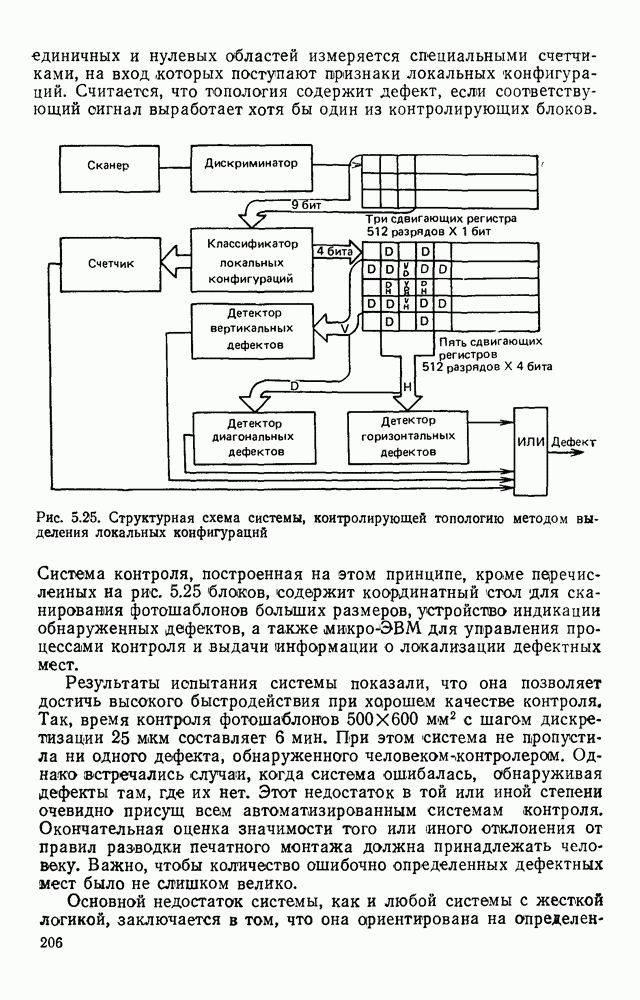
ГЛАВА 1. МЕТОДЫ КОДИРОВАНИЯ И СЖАТИЯ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ1.1. ЗАДАЧИ КОДИРОВАНИЯ ВИЗУАЛЬНОЙ ИНФОРМАЦИИВизуальная информация, подлежащая обработке на ЭВМ, может вводиться в запоминающее устройство со специального датчика (устройства ввода) или представлять собой результат некоторых вычислений. В том и другом случае такая информация сопоставляется с некоторой картиной, зрительно воспринимаемой человеком. Это сопоставление по сути и является принципиальным отличием визуальной информации от числовой, логической, символьной или какой-либо другой, которая может быть представлена в памяти ЭВМ. Очевидно, что визуальная информация должна с определенной степенью точности отражать состояние яркости или прозрачности каждой точки зрительно воспринимаемой картины. Для простоты в дальнейшем будем рассматривать только плоские картины. Чтобы представить визуальную информацию в цифровой форме, необходимо дискретизировать пространство (плоскость) и проквантовать значение яркости в каждой дискретной точке. Наиболее просто и естественно дискретизация достигается с помощью координатной сетки, образованной линиями, параллельными осям х и у декартовой системы координат. В каждом узле такой решетки делается отсчет яркости или прозрачности носителя зрительно воспринимаемой информации, которая затем квантуется и представляется в памяти ЭВМ. Рисунок 1.1 иллюстрирует процесс кодирования на примере изображения с четырьмя градациями
Рис. 1.1. Кодирование визуальной информации: а — исходное изображение; б — его рецепторное представление яркости. Результат представлен на рис. 1.1,б в виде матрицы, элементами Такое представление визуальной информации называется рецепторным [43], естественным (11], поэлементным или матричным
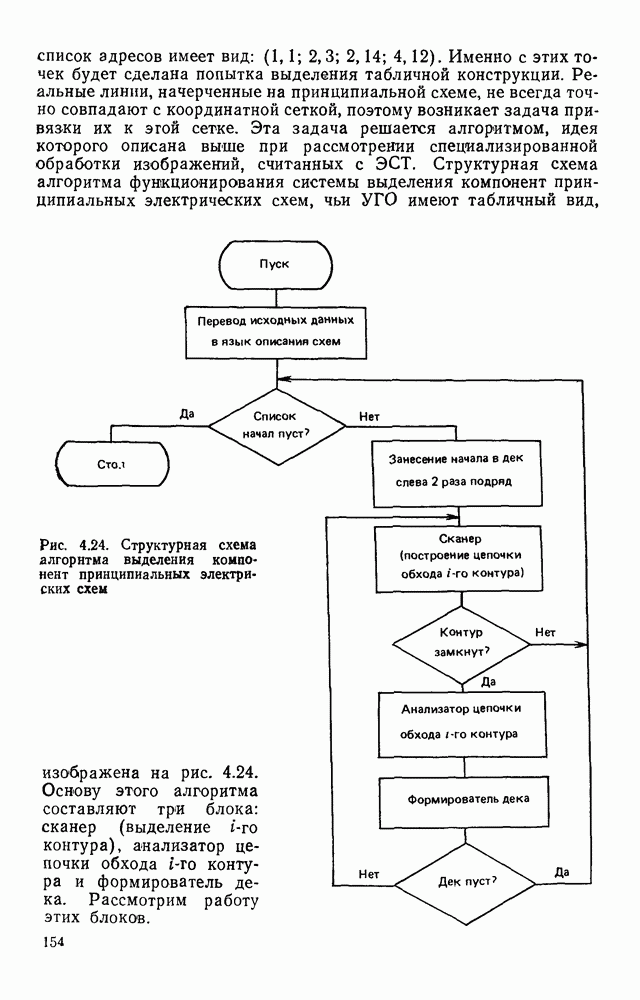
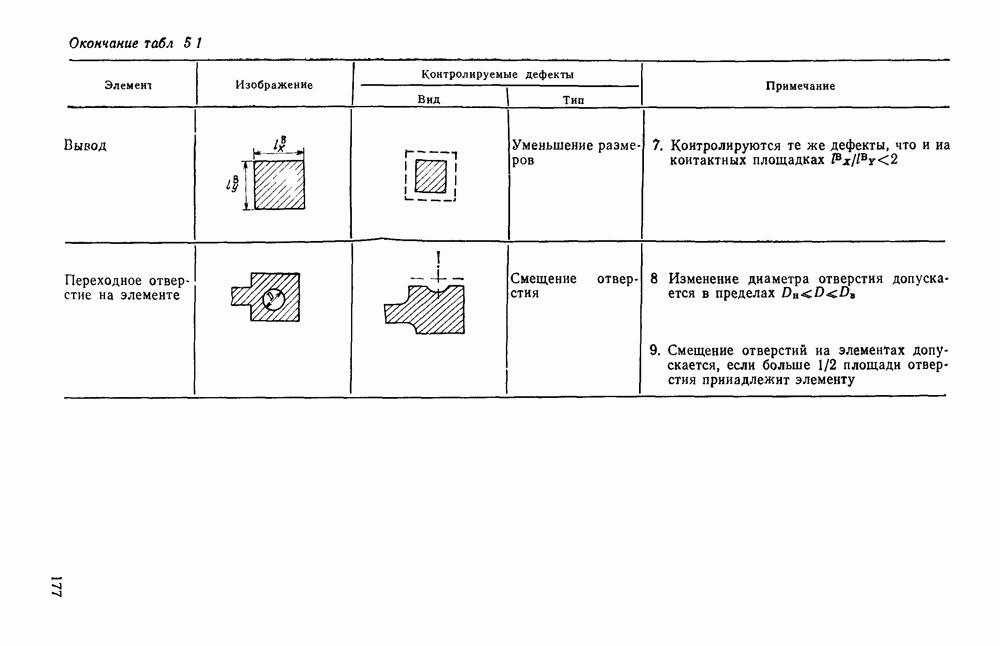
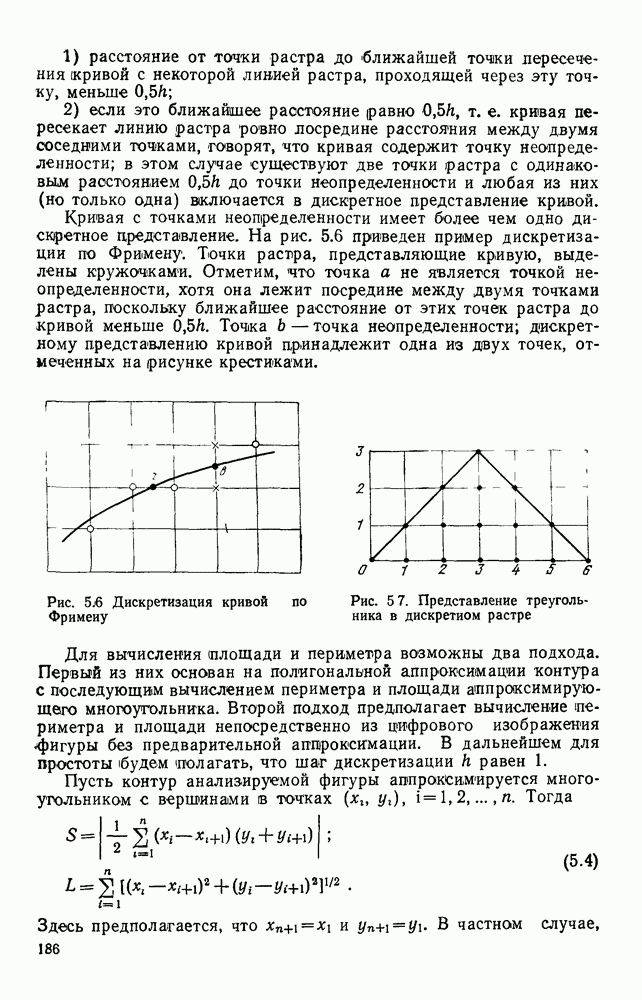
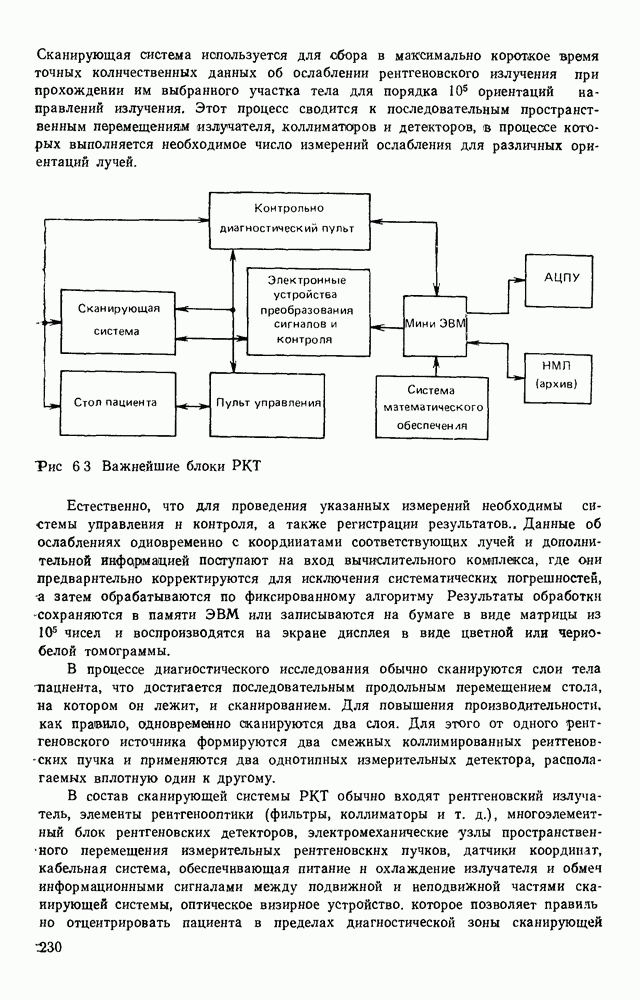
где При использовании других датчиков (например, твердотельных) отсчеты могут выдаваться в иной последовательности. Во всех случаях поэлементный способ представления изображений находит применение в качестве промежуточного при считывании визуальной информации. Этот способ удобно использовать и при отображении информации на видеоконтрольных устройствах. В связи с этим задачу кодирования визуальной информации будем рассматривать как задачу преобразования естественной формы представления в форму, удобную для хранения и обработки в ЭВМ. Учитывая, что любая обработка информации может рассматриваться как ее перекодирование, будем отличать первичные, или абсолютные, кодовые описания от вторичных, или относительных [11]. Не давая строгих определений, укажем лишь на два существенных отличия таких кодовых описаний. Во-первых, первичные способы представления в отличие от вторичных должны быть универсальными, т. е. допускать возможность восстановления соответствующего изображения с точностью, определяемой параметрами рецепторной решетки и числом К уровней квантования, и не учитывать специфику вводимых изображений или дальнейших алгоритмов их обработки. Во-вторых, первичное представление можно достаточно просто получить из естественного так, чтобы перекодирование осуществлялось относительно простыми устройствами в процессе ввода информации в ЭВМ. Примером первичного описания визуальной информации служит ее поэлементное кодирование. Вторичные способы представления информации могут существенно отличаться от первичных (или естественного) и получаться в результате достаточно сложных алгоритмов обработки визуальной информации. Например, можно предложить весьма компактные способы представления принципиальных электрических схем, основанные на перечислении элементов, встречающихся в схеме, с указанием мест расположения на чертеже самих элементов и соединяющих их линий. В качестве примера вторичного описания можно привести описание изображения в некотором пространстве признаков, используемых в дальнейшем для распознавания образов. Для того чтобы далее формализовать задачу кодирования, удобно более четко выделить структурные единицы визуальной информации. Назовем всю подлежащую записи в ЭВМ визуальную информацию картиной или сценой. Будем предполагать, что она представлена в естественной форме. На размеры картины никаких ограничений не накладывается. В частном случае ее размеры могут превышать размеры рецепторного поля оптического датчика, используемого для ввода информации в ЭВМ. В этом случае картина разбивается на прямоугольные области, называемые растрами или кадрами (рис. 1.2).
Рис. 1.2. Структурные единицы машинного представления визуальной информации Каждый растр по размерам соответствует рецепторному полю датчика и содержит растра обычно изменяется в пределах от 256 до 512, а число различимых уровней серого не превышает В общем случае для поэлементной записи кадра требуется память, содержащая
бит информации. Если оценить W, то можно убедиться в том, что для поэлементного представления кадра требуется значительный объем памяти. Например, пусть В первом из них для представления визуальной информации используют все разряды всех слов выделенного массива. В этом случае достигается наибольшая компактность представления и требуется меньший объем памяти. Его оценка при поэлементном кодировании дается формулой (1.2). Однако такое размещение неудобно для обработки информации, так как некоторые отсчеты оказываются размещенными в нескольких словах. При другом подходе каждый отсчет целиком представляется некоторым машинным словом. Но при этом в общем случае используются не все разряды машинных слов, что приводит к увеличению требуемого объема памяти. Например, если принять подход, при котором каждый отсчет размещается в отдельном слове, то для представления одного кадра потребуется Естественно сформулировать задачу кодирования как задачу получения такого представления визуальной информации, которое занимает минимальный объем памяти ЭВМ и в то же время удобно для обработки. Практическая значимость минимизации объема памяти становится более очевидной, если учесть, что во многих случаях требуется анализировать картины значительных размеров, содержащие сотни, а может быть тысячи растров. Чтобы получить какие-то численные оценки, рассмотрим реальный пример, в котором размеры обрабатываемой картины составляют 200X300 мм и каждый отсчет представляется словом, содержащим восемь двоичных разрядов. Если при этом шаг рецепторной сетки равен 0,1 мм, то потребуется память порядка 6 Мбайт. Оценим качество или эффективность кода средним количеством бит, приходящихся на один отсчет:
где Если не учитывать возможные потери, обусловленные словарной организацией памяти, для поэлементного способа кодирования в соответствии с
характеризующий сокращение объема памяти по сравнению с поэлементным кодированием.
|
 |
Оглавление
|





































































































































































































 которой служат отсчеты в узлах решетки.
которой служат отсчеты в узлах решетки.
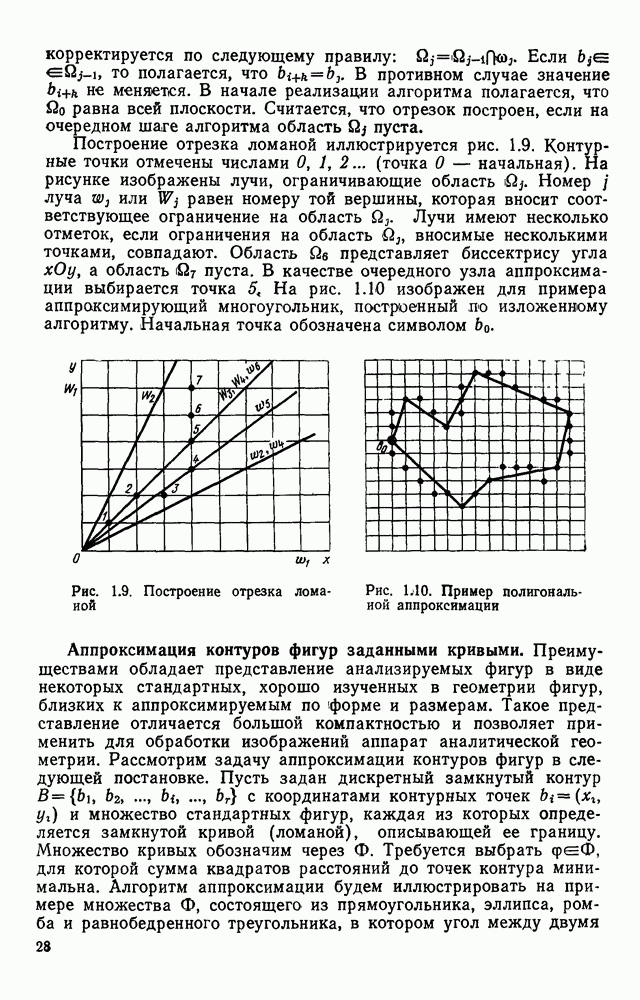
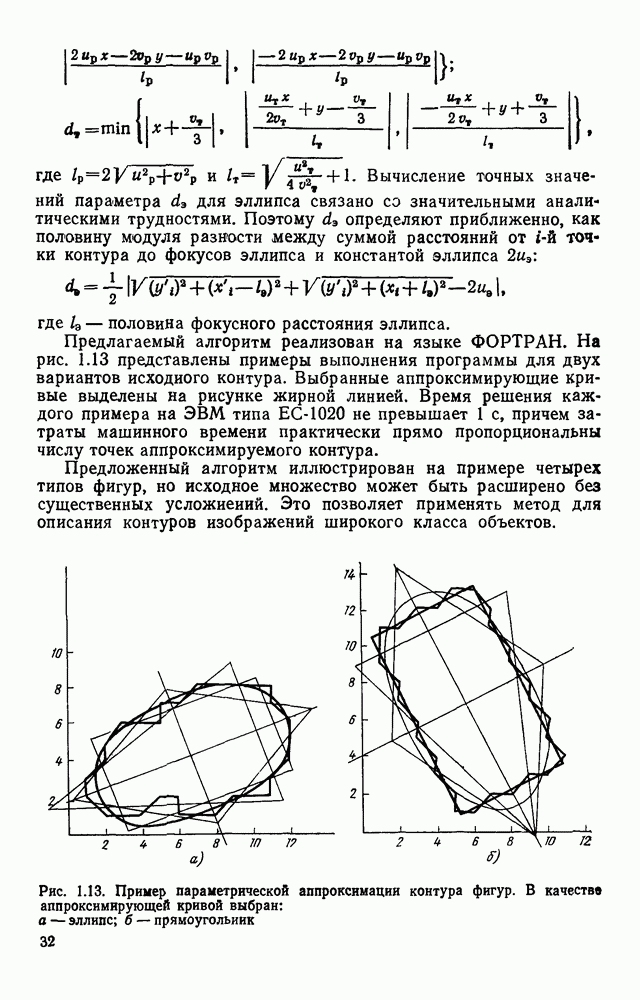
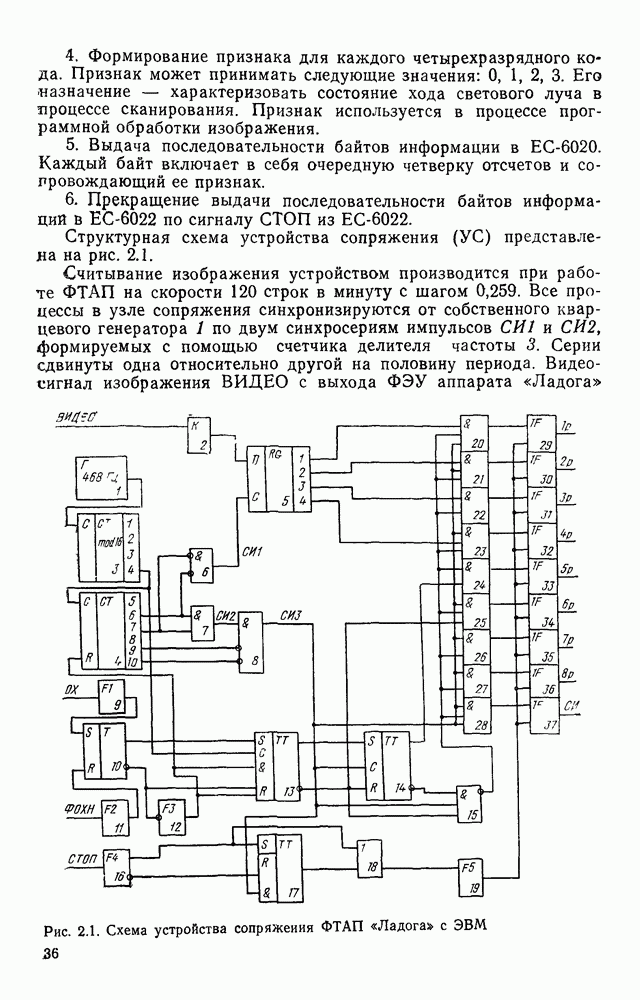
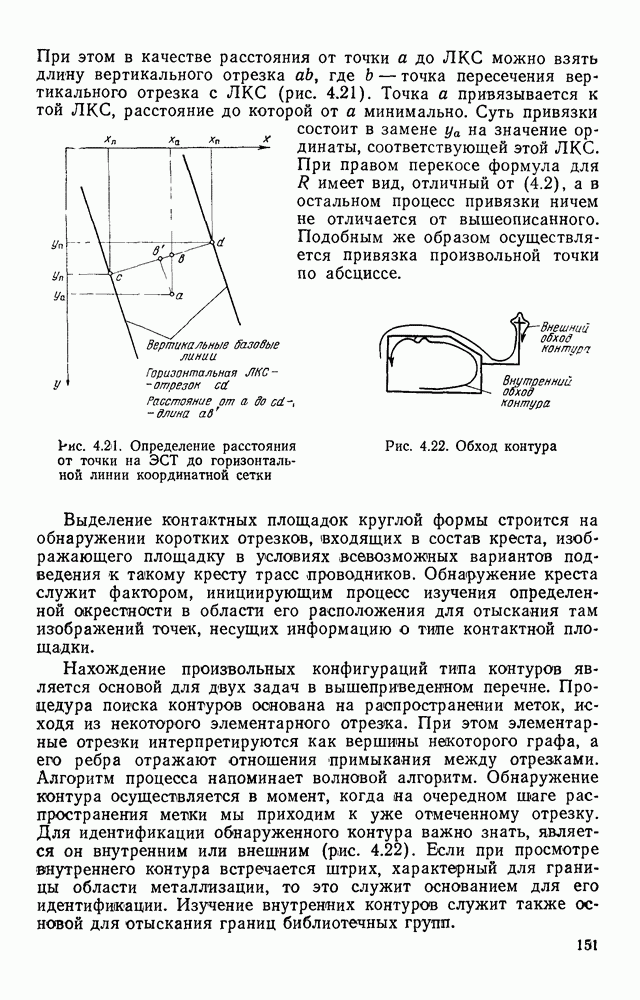
 Оно заслуживает внимания хотя бы потому, что наиболее удобно описывает процессы ввода и вывода изображений и позволяет легко установить однозначное соответствие между картиной и ее представлением в памяти ЭВМ. Широкий класс датчиков, используемых для ввода оптической информации в ЭВМ, представляет собой набор светочувствительных элементов (рецепторов), преобразующих световой сигнал в электрический. В процессе ввода рецепторы, расположенные в узлах рецепторной сетки, опрашиваются в определенной последовательности и снимаемые с них сигналы преобразуются в цифровую форму. Таким образом получается последовательность отсчетов в узлах координатной сетки. Например, при использовании телевизионных датчиков, информация, содержащаяся в телевизионном кадре, считывается построчно, т. е. отсчеты во времени образуют следующую последовательность:
Оно заслуживает внимания хотя бы потому, что наиболее удобно описывает процессы ввода и вывода изображений и позволяет легко установить однозначное соответствие между картиной и ее представлением в памяти ЭВМ. Широкий класс датчиков, используемых для ввода оптической информации в ЭВМ, представляет собой набор светочувствительных элементов (рецепторов), преобразующих световой сигнал в электрический. В процессе ввода рецепторы, расположенные в узлах рецепторной сетки, опрашиваются в определенной последовательности и снимаемые с них сигналы преобразуются в цифровую форму. Таким образом получается последовательность отсчетов в узлах координатной сетки. Например, при использовании телевизионных датчиков, информация, содержащаяся в телевизионном кадре, считывается построчно, т. е. отсчеты во времени образуют следующую последовательность:

 — элемент матрицы отсчетов, расположенный на пересечении i-й строки и
— элемент матрицы отсчетов, расположенный на пересечении i-й строки и  столбца;
столбца;  — число строк матрицы, соответствующее числу строк в кадре;
— число строк матрицы, соответствующее числу строк в кадре;  — число столбцов матрицы, соответствующее числу элементов в строке.
— число столбцов матрицы, соответствующее числу элементов в строке.

 отсчетов, образующих прямоугольную матрицу, состоящую из
отсчетов, образующих прямоугольную матрицу, состоящую из  строк и
строк и  столбцов. Каждый отсчет характеризуется числом К уровней квантования видеосигнала. Обычно полагают
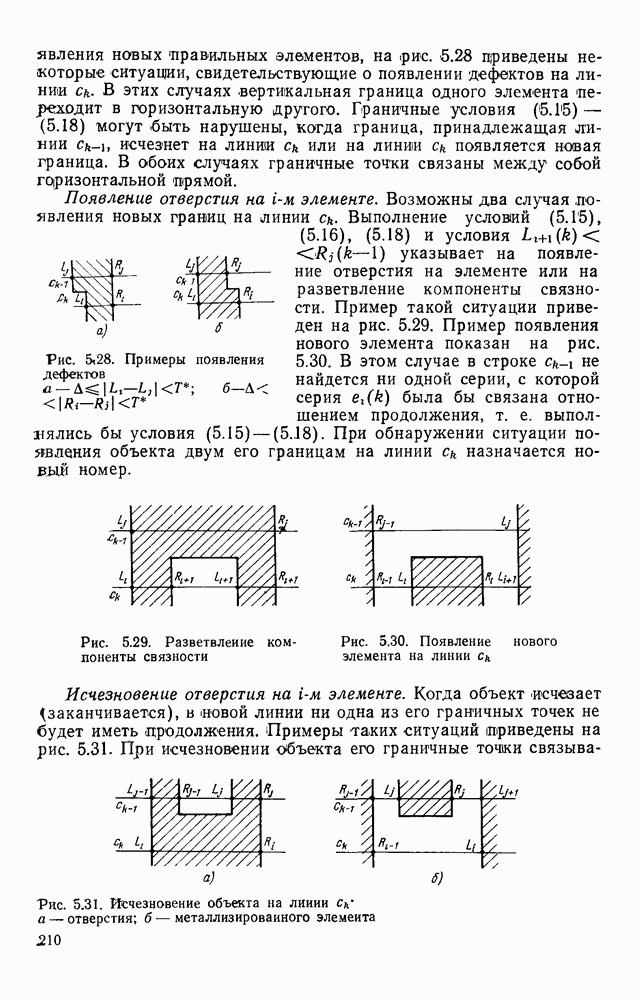
столбцов. Каждый отсчет характеризуется числом К уровней квантования видеосигнала. Обычно полагают  где k — целое. Иногда выделяют еще одну структурную единицу информации — поле. Поле — это часть кадра, образованная несколькими соседними отсчетами. Параметры
где k — целое. Иногда выделяют еще одну структурную единицу информации — поле. Поле — это часть кадра, образованная несколькими соседними отсчетами. Параметры  выбирают в зависимости от требуемой точности представления информации с учетом возможностей оптического датчика. Например, если в качестве такого датчика используют телекамеру, работающую в стандартном режиме, число строк и столбцов
выбирают в зависимости от требуемой точности представления информации с учетом возможностей оптического датчика. Например, если в качестве такого датчика используют телекамеру, работающую в стандартном режиме, число строк и столбцов


 В этом случае
В этом случае  бит. При определении способа размещения информации в памяти ЭВМ необходимо учитывать тот факт, что память ЭВМ имеет словарную структуру, т. е. существует минимальное адресуемое слово фиксированной длины s. В общем случае s не равно и не кратно k. Здесь можно предложить два подхода к решению задачи размещения отсчетов в словах памяти ЭВМ.
бит. При определении способа размещения информации в памяти ЭВМ необходимо учитывать тот факт, что память ЭВМ имеет словарную структуру, т. е. существует минимальное адресуемое слово фиксированной длины s. В общем случае s не равно и не кратно k. Здесь можно предложить два подхода к решению задачи размещения отсчетов в словах памяти ЭВМ.
 машинных слов.
машинных слов.

 — объем памяти, требуемый для представления одного кадра размером
— объем памяти, требуемый для представления одного кадра размером 
 Предполагая, что требуемый при поэлементном кодировании объем памяти удается сократить, положим
Предполагая, что требуемый при поэлементном кодировании объем памяти удается сократить, положим  Введем в рассмотрение коэффициент сокращения
Введем в рассмотрение коэффициент сокращения
