Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
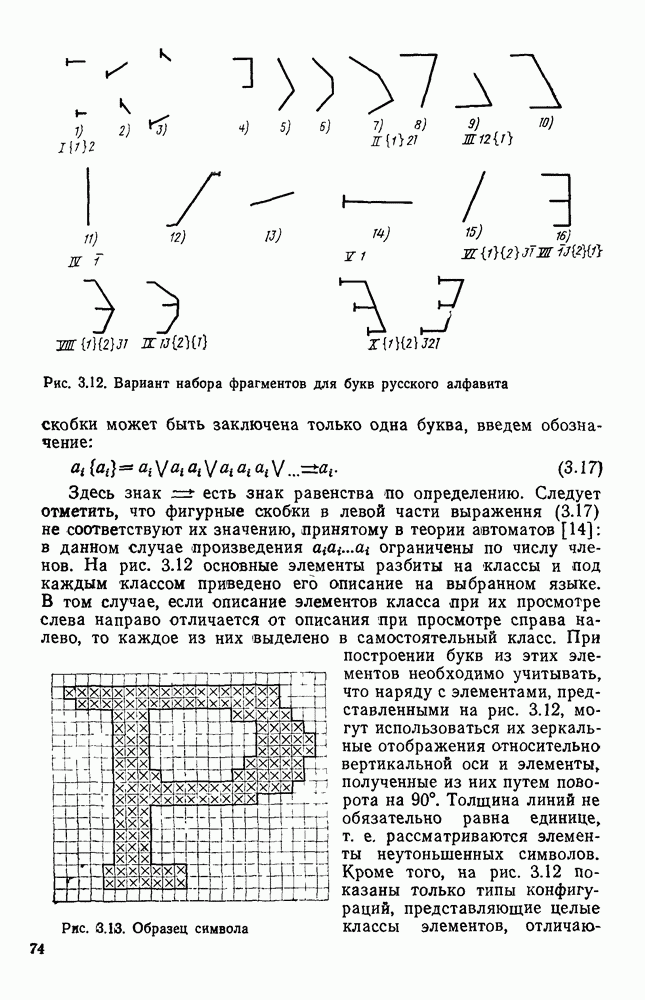
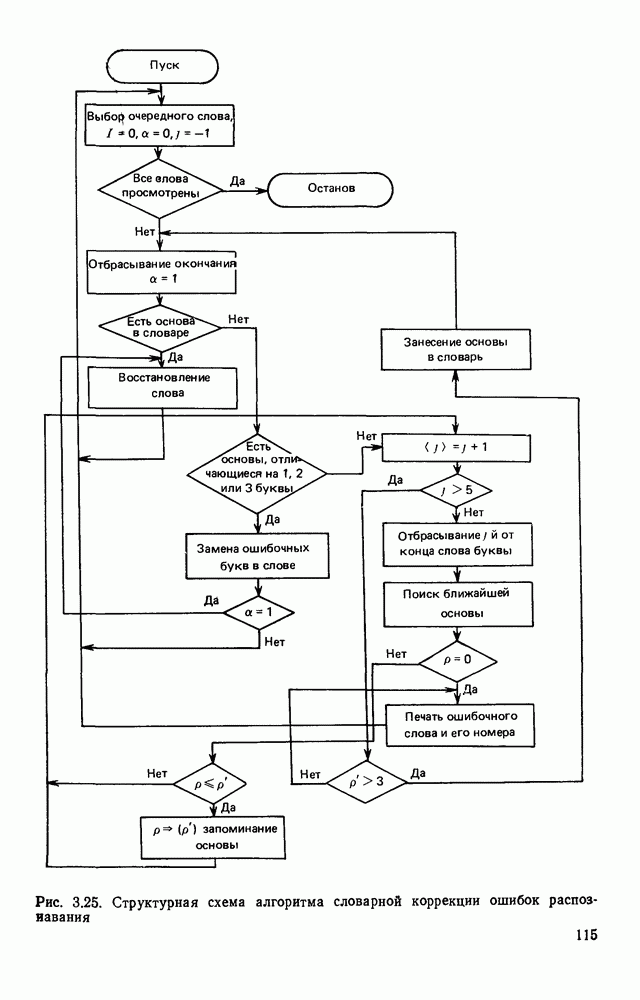
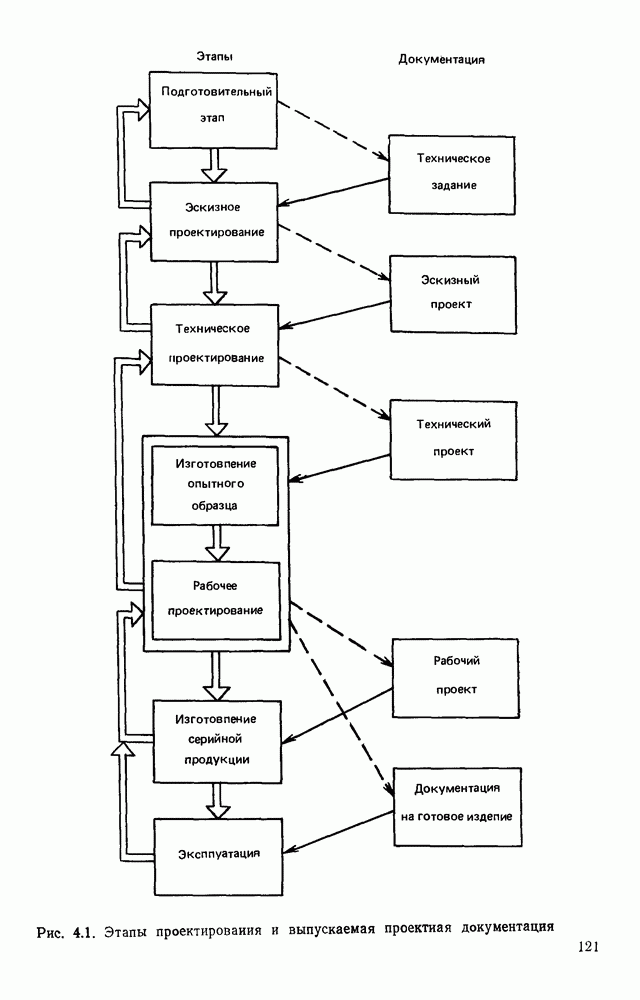
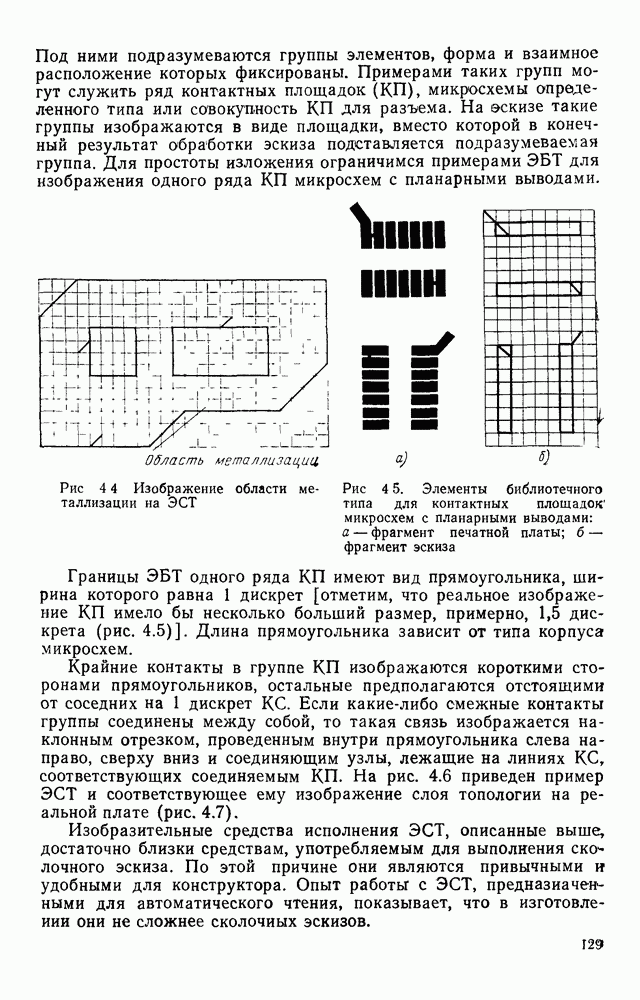
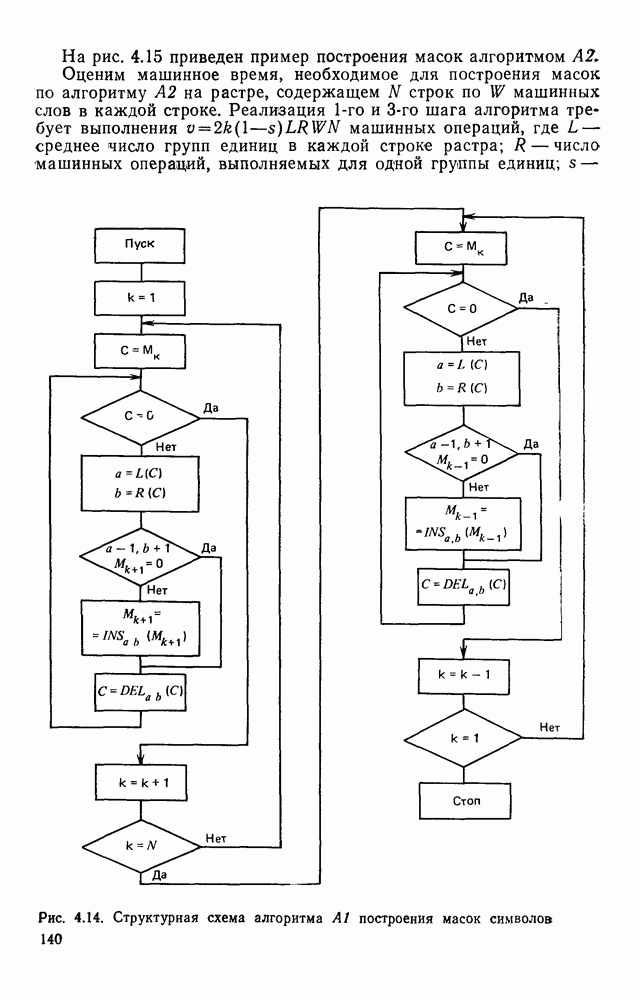
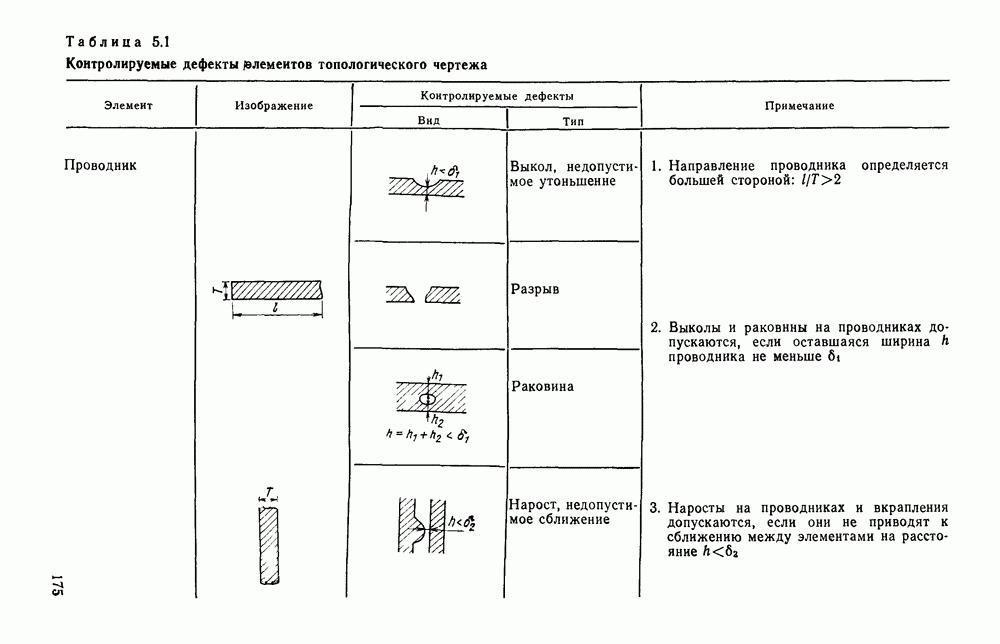
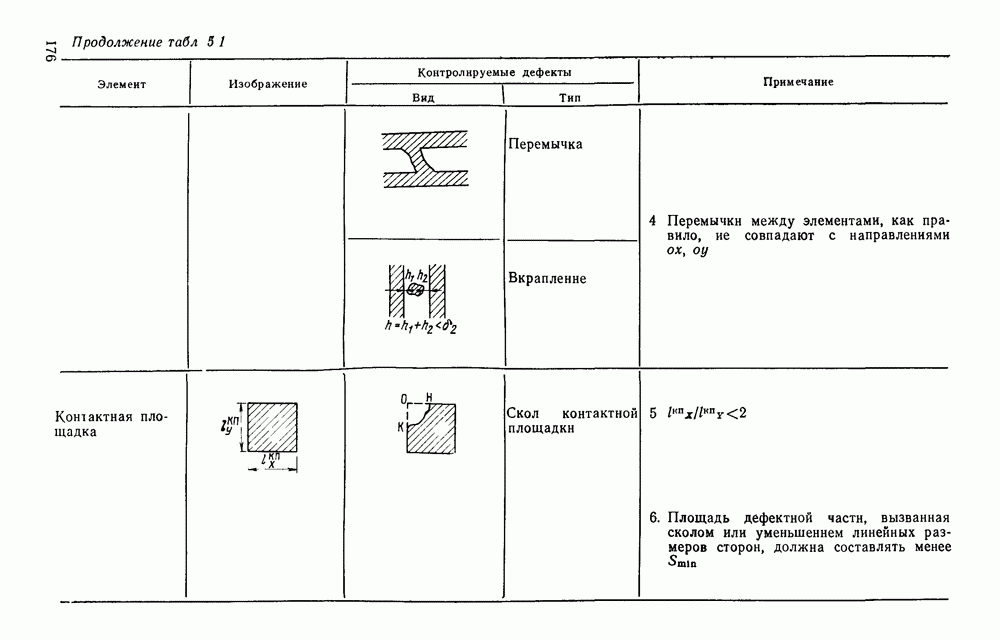
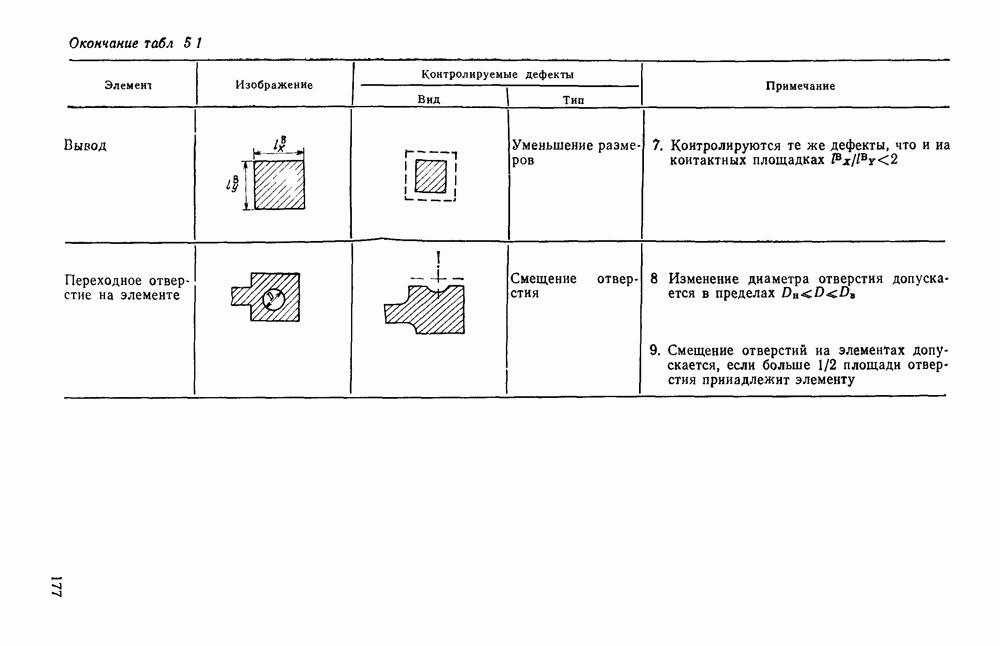
3.2. СТРУКТУРНО-ЛИНГВИСТИЧЕСКИЙ ПОДХОД К ОБРАБОТКЕ ИЗОБРАЖЕНИЙТипичная задача автоматического распознавание образов формулируется примерно так: все множество подлежащих обработке изображений некоторым способом разбивается на конечное число классов, называемых образами. Автоматическому устройству, например ЭВМ, снабженной механизмом восприятия изображений, предъявляется изображение. Устройство должно решить, к какому из классов оно относится. Представлялось вполне естественным, что поскольку необходимо устройств, принимающее решение, то алгоритмы его работьа должны опираться на статистическую теорию решений. Объектьк каждого класса (образы) характеризовались некоторой совокупностью признаков, каждый из которых мог принимать одно из определенного множества значений. Возникала задача: с помощью» семейства поверхностей разбить пространство признаков на непересекающиеся области и сопоставить каждую область одному из образов. Если это сделано, то процесс распознавания представляется достаточно простым: для прдъявленного изображения нужно вычислить значения всех признаков, иными словами, определить некоторую точку в пространстве признаков; затем выявить, в какую из выделенных областей попадает эта точка. Изображение относится к тому образу, которому соответствует найденная область. В этом описании автоматического распознавания образов мы сознательно не использовали ни одного математического обозначения, чтобы показать, сколь проста по своей сути эта задача а ее исходной постановке Тот факт, что сейчас трудно назвать область математики, которая не привлекалась бы к решению этой и близких к ней задач, и что созданные на сегодняшний день автоматические устройства для распознавания образов уступают человеку, говорит о чрезвычайной сложности этой задачи. Описанная процедура распознавания рассматривает каждый образ и каждое конкретное изображение как изолированный объект, пусть довольно сложный, но существующий цельно и независимо от выбранной методики решения задачи. Выбор самих признаков и определение их значений осуществляется, исходя, главным образом, из стремления оптимизировать как разбивку пространства признаков на области, так и процедуру принятия решения при статистическом минимуме ошибки распознавания. Типичной задачей, на которой опробо вались те или иные процедуры распознавания, было распознавание букв некоторого алфавита. Оказалось, что даже в этом «простом» приложении описанный общий подход не всегда обеспечивает надежность распознавания. Он хорошо работает в том случае, когда изображения, представляемые на растре, близки к «идеальным» представителям класса (образа), что на практике случается крайне редко. Учитывая большое число слабо контролируемых факторов качество бумаги, качество пишущего или печатающего инструмента, характеристики фотооптического преобразователя, разнообразие почерков и шрифтов и т. д. — «оказывается чрезвычайно трудно выделить систему устойчивых признаков Многие задачи обработки изображений вообще выходят за рамки упрощенно описанного выше метода классификации по совокупности признаков, который солидаризуясь с переводчиками монографии К. Фу [46], назовем дискриминантным. К числу таких задач относится обработка изображений, не являющихся неделимыми с общечеловеческой точки зрения (например, буква или цифра), но представляющих собой некоторым образом организованную «сцену», состоящую из структурно связанных объектов, которые своим присутствием и конкретным характером межобъектных связей определяют индивидуальные особенности сцены. Анализ фотографий с искусственных спутников Земли земной поверхности с целью выявления природных ресурсов, облачного покрова для предсказания погоды, анализ фотографий пузырьковой камеры для обнаружения определенного физического явления, идентификация личности по отпечаткам пальцев, анализ принципиальной схемы электронного устройства при разработке фотошаблонов для плат печатного монтажа, визуальная проверка плат печатного монтажа для выявления дефектов производства и другие подобные задачи, являясь по сути задачами распознавания, не могут быть сведены к трем простейшим ответам «да», «нет», «не знаю», а требуют глубокого проникновения в структуру изображения — сцены. Задачи такого типа определяются как «анализ сцен». При решении таких задач часто требуется дать ответ на вопрос: находится ли определенный объект в изображении — сцене, находятся ли выделенные объекты сцены в заданном положении, например один выше другого, слева от него, за другим и т. д.? Может потребоваться и описание сцены. Для решения такого рода задач необходимо иметь развитый аппарат описания сцены, ориентированный на иерархическую структуру ее объектов, опирающийся на систему непроизводных (простейших) элементов и отношений между ними. Развитие такого аппарата основывается на аналогии между структурой изображения и структурой фразы в естественном или искуственном языке. Подобно тому, как опираясь на правила грамматики, мы строим фразы из слов, а слова из букв, можно строить изображение (сцену) из объектов, опираясь на отношения между объектами, а объекты составлять из соединяемых по определенным правилам легко выделяемых простейших фрагментов — непроизводных элементов. Если удается найти такую грамматику изображений, то возникает возможность анализировать изображения, пользуясь синтаксическими правилами этой грамматики как при синтаксическом разборе предложений естественного языка. В этом случае говорят о лингвистическом подходе к распознаванию, иногда его называют структурным, а соответствующие формальные средства — языком описаний изображений. Существенно, что эти формальные средства могут быть использованы не только для описания предъявленного изображения, но и для порождения всего класса изображений определяемого выбранными языковыми средствами, подобно тому, как по правилам грамматики естественного языка можно сгенерировать все синтаксически правильные предложения. Поэтому имеет смысл говорить о порождающей грамматике класса изображений. Изоб ражения, относящиеся к некоторому классу, соответствуют предложению (фразе) порождающего языка. Описанная в начале параграфа задача распознавания образов решается попутно в процессе синтаксического анализа. В самом деле, в ходе такого анализа устанавливается, что на заданном изображении группа из таких-то и таких-то непроизводных элементов, соединенных между собой по таким-то и таким-то грамматическим правилам, образует объект на сцене, соответствующий такой-то синтаксической категории. Это и есть решение задачи распознавания, сформулированное лишь на другом языке. Не следует понимать, что лингвистический аппарат описания изображений необходимо применять только для сцен или изображений со сложной иерархической структурой. При соответствующем подборе грамматики он может применяться и для анализа и распознавания таких «простых» образов, как, скажем, буквы и цифры. Подход с позиции теории решений (дискиминантный подход) и лингвистический подход отличаются тем, что в первом для описания и моделирования пользуются статистическими характеристиками образов, а во втором — грамматическими правилами. Эффективность того или иного подхода в значительной мере зависит от особенностей задачи и искусства разработчика. Довольно часто при решении практической задачи приходится прибегать к сочетанию того и другого подхода. Формальные грамматики и языки.Основой для построения языковых моделей сцен и объектов служат аппарат математической лиигвнстикн [13], важнейшие понятия которой рассмотрены ниже. Алфавитом V будем называть любое непустое конечное множество символов. В лингвистике алфавит обычно называют словарем. Цепочка длины Формальный язык Конечное множество правил, определяющих способ образования цепочек языка, называется грамматикой. Порождающей грамматикой называется упорядоченная четверка 1) 2) Р есть конечное множество упорядоченных пар вида 3) Элементы Поскольку не всегда у непосредственно порождается Последовательность цепочек Пусть порождаемый ею язык есть множество Пример. Пусть задана порождающая грамматика Порождающая грамматика Язык Дальнейшие ограничения на правила подстановки дают более узкую грамматику, чем контекстно-свободная, но представляющую большой интерес для теории конечных автоматов. Порождающая грамматика Язык
|
 |
Оглавление
|

























































































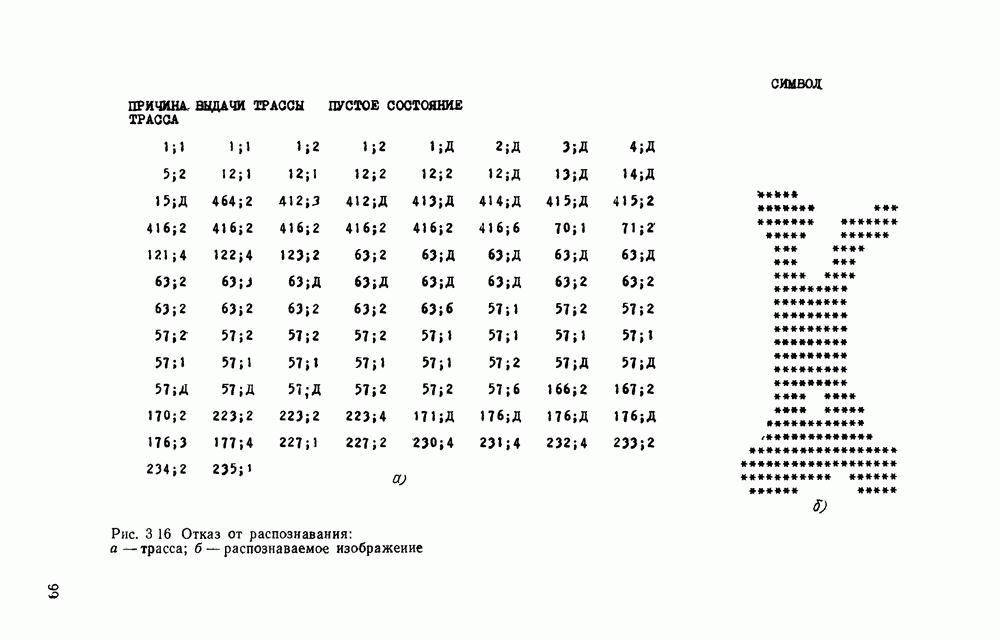
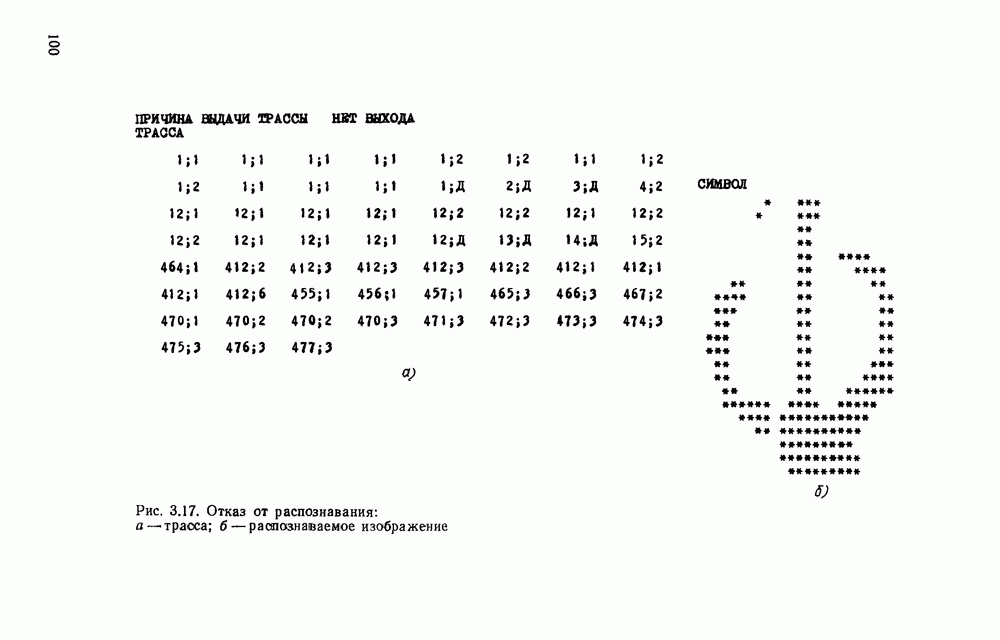
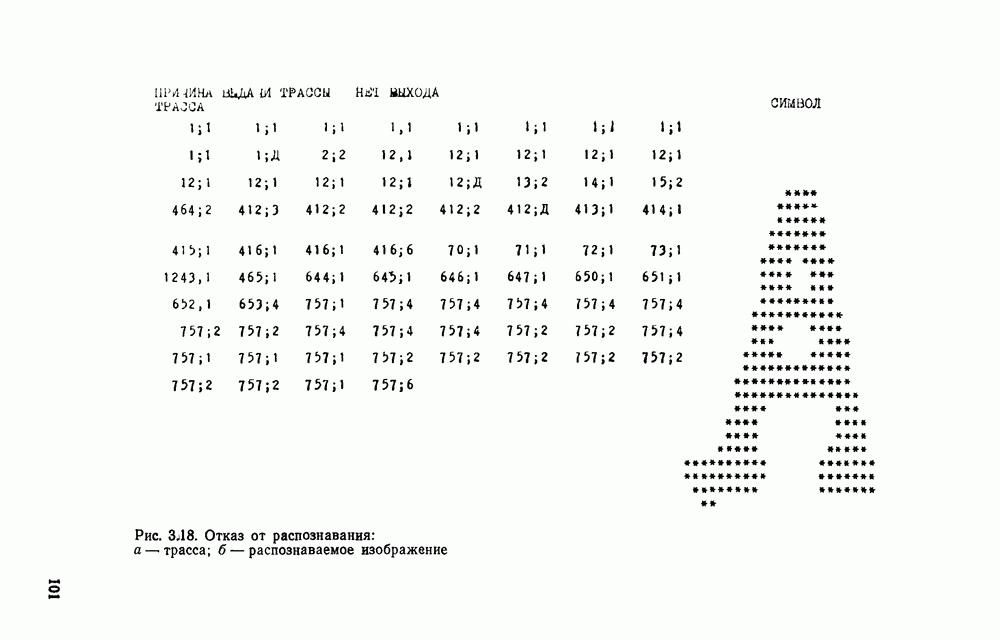
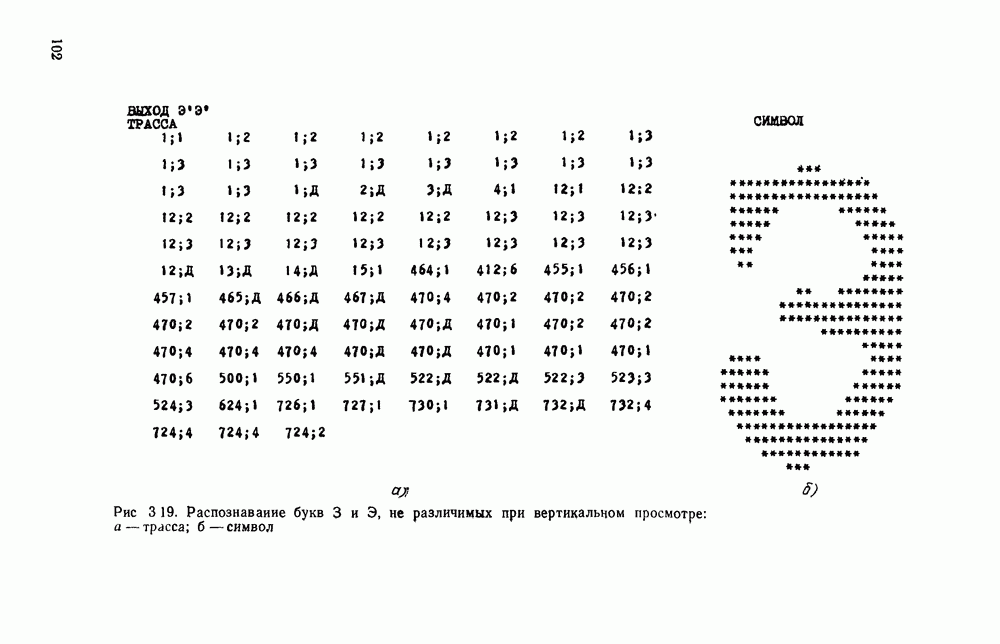











































































































 в алфавите V есть конечная последовательность
в алфавите V есть конечная последовательность  элементов V. Цепочку, как правило, записывают без запятых, т. е. в виде
элементов V. Цепочку, как правило, записывают без запятых, т. е. в виде  Цепочка длины нуль называется пустой и обозначается через
Цепочка длины нуль называется пустой и обозначается через  , цепочка длины — непустой Отметим, что в алгебре и теории автоматов цепочки называются словами, а в применении к естественным языкам — предложениями. Цепочка
, цепочка длины — непустой Отметим, что в алгебре и теории автоматов цепочки называются словами, а в применении к естественным языкам — предложениями. Цепочка  а называется
а называется  -цепочкой, если
-цепочкой, если  каждое
каждое  принадлежит V. К-цепочки
принадлежит V. К-цепочки  равны (обозначение
равны (обозначение  ), если
), если  для всех
для всех  Конкатенацией или произведением
Конкатенацией или произведением  (обозначение
(обозначение  ) называется цепочка
) называется цепочка  Множество всех цепочек, включая пустую цепочку
Множество всех цепочек, включая пустую цепочку  в алфавите V, обозначается через V. Пусть
в алфавите V, обозначается через V. Пусть  — некоторые цепочки
— некоторые цепочки  . Цепочка
. Цепочка  является подцепочкой цепочки
является подцепочкой цепочки  если
если  для подходящих цепочек
для подходящих цепочек  из V. Цепочка
из V. Цепочка  есть начало цепочки
есть начало цепочки  если
если  для подходящей цепочки
для подходящей цепочки  . Цепочка
. Цепочка  служит концом цепочки
служит концом цепочки  если
если  для подходящей
для подходящей  почки и из V.
почки и из V.
 есть множество цепочек в алфавите V (т. е.
есть множество цепочек в алфавите V (т. е.  выделенных с помощью некоторого конечного множества правил. Язык называется конечным, если
выделенных с помощью некоторого конечного множества правил. Язык называется конечным, если  — конечное множество. Таким образом, проблема определения того или ииого формального языка сводится к проблеме определения соответствующих правил и указания способа выделения цепочек с помощью этих правил.
— конечное множество. Таким образом, проблема определения того или ииого формального языка сводится к проблеме определения соответствующих правил и указания способа выделения цепочек с помощью этих правил.
 , в которой:
, в которой:
 есть множество вспомогательных символов (
есть множество вспомогательных символов ( -вспомогательный алфавит,
-вспомогательный алфавит,  множество основных символов (
множество основных символов ( - основной алфавит (
- основной алфавит ( - общий алфавит порождающей грамматики
- общий алфавит порождающей грамматики 
 где
где  — цепочки в алфавите У и в цепочку
— цепочки в алфавите У и в цепочку  входит по крайней мере один символ из
входит по крайней мере один символ из  ;
;
 - специальный символ, называемый начальным или аксиомой.
- специальный символ, называемый начальным или аксиомой.
 множества Р называются правилами подстановки. Эти правила используются следующим образом. Пусть
множества Р называются правилами подстановки. Эти правила используются следующим образом. Пусть  элемент Р. Тогда для цепочки
элемент Р. Тогда для цепочки  правило подстановки означает, что можно заменить цепочку
правило подстановки означает, что можно заменить цепочку  на цепочку
на цепочку  где
где  или
или  (или обе сразу) могут быть пустыми. Эта подстановка обозначается
(или обе сразу) могут быть пустыми. Эта подстановка обозначается  и говорит, что
и говорит, что  непосредственно порождает
непосредственно порождает 
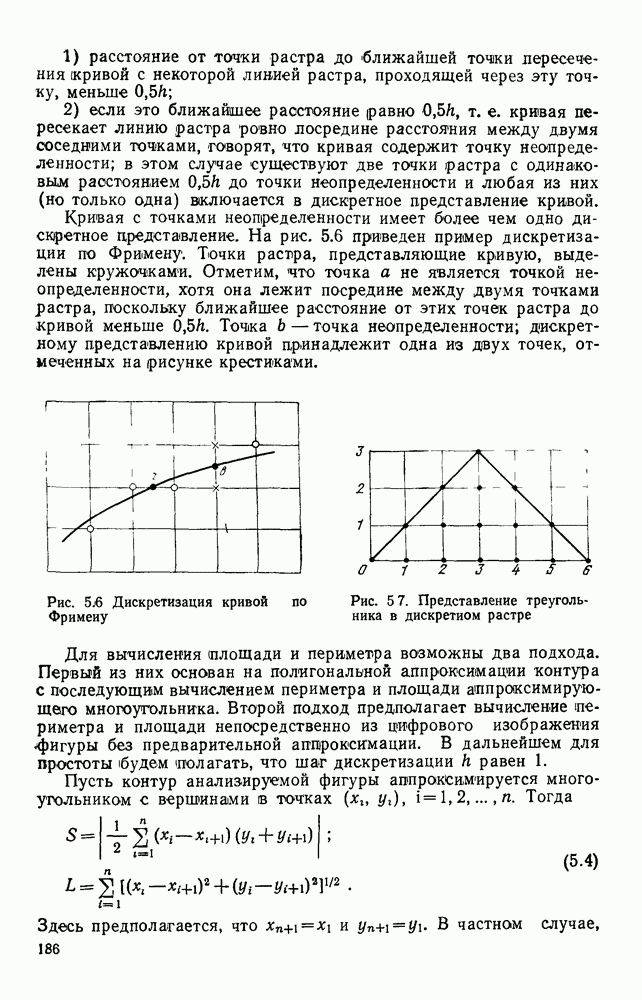
 то в общем случае необходима серия промежуточных подстановок, прежде чем получим у. Поэтому если существует последовательность цепочек
то в общем случае необходима серия промежуточных подстановок, прежде чем получим у. Поэтому если существует последовательность цепочек  такая, что
такая, что  то считают, что
то считают, что  порождает у и пишут
порождает у и пишут 
 называется выводом длины
называется выводом длины  . Используя введенные понятия, можно указать способ, при помощи которого грамматика выделяет цепочки, составляющие язык.
. Используя введенные понятия, можно указать способ, при помощи которого грамматика выделяет цепочки, составляющие язык.

 -порождающая грамматика. Множество
-порождающая грамматика. Множество  называется языком, порождаемым грамматикой (иначе — грамматика 3 порождает язык
называется языком, порождаемым грамматикой (иначе — грамматика 3 порождает язык  ). Каждая цепочка языка
). Каждая цепочка языка  является выводимой из а. Таким образом, для каждой порождающей грамматики 2?
является выводимой из а. Таким образом, для каждой порождающей грамматики 2?
 , где
, где  наименьшее множество, которое содержит а в цепочку
наименьшее множество, которое содержит а в цепочку  всякий раз, когда
всякий раз, когда  и Иначе говоря, порождающая грамматика выделяет только те цепочки из
и Иначе говоря, порождающая грамматика выделяет только те цепочки из  которые являются выводимыми из а.
которые являются выводимыми из а.
 . Положим
. Положим  Получим одну из цепочек, порождаемых этой грамматикой;
Получим одну из цепочек, порождаемых этой грамматикой;  . Аналогичным образом можно получить другие цепочки языка, порождаемого выбранной грамматикой. Весь язык можно представить следующим образом:
. Аналогичным образом можно получить другие цепочки языка, порождаемого выбранной грамматикой. Весь язык можно представить следующим образом: 
 называется контекстно-свободней грамматикой, если ее правила подстановки имеют вид
называется контекстно-свободней грамматикой, если ее правила подстановки имеют вид  , где и
, где и  или
или  .
.
 порождаемый контекстно-свободной грамматикой, называется контекстно-свободным. Ограничения, наложенные на правила подстановки, сводятся к тому, что вспомогательный символ может заменяться в соответствии с правилами подстановки независимо от контекста, в котором этот символ встречается.
порождаемый контекстно-свободной грамматикой, называется контекстно-свободным. Ограничения, наложенные на правила подстановки, сводятся к тому, что вспомогательный символ может заменяться в соответствии с правилами подстановки независимо от контекста, в котором этот символ встречается.
 называется грамматикой с конечным числом состояний, если каждое ее правило подстановки имеет вид
называется грамматикой с конечным числом состояний, если каждое ее правило подстановки имеет вид  или
или  где
где 
 порождаемый грамматикой с конечным числом состояний, называется языком с конечным числом состояний. Структура правил подстановки в этой грамматике такова, что цепочки символов строятся слева направо. Как мы убедимся позже, существует тесная связь между языками с конечным числом состояний и конечными автоматами.
порождаемый грамматикой с конечным числом состояний, называется языком с конечным числом состояний. Структура правил подстановки в этой грамматике такова, что цепочки символов строятся слева направо. Как мы убедимся позже, существует тесная связь между языками с конечным числом состояний и конечными автоматами.