Пред.
След.
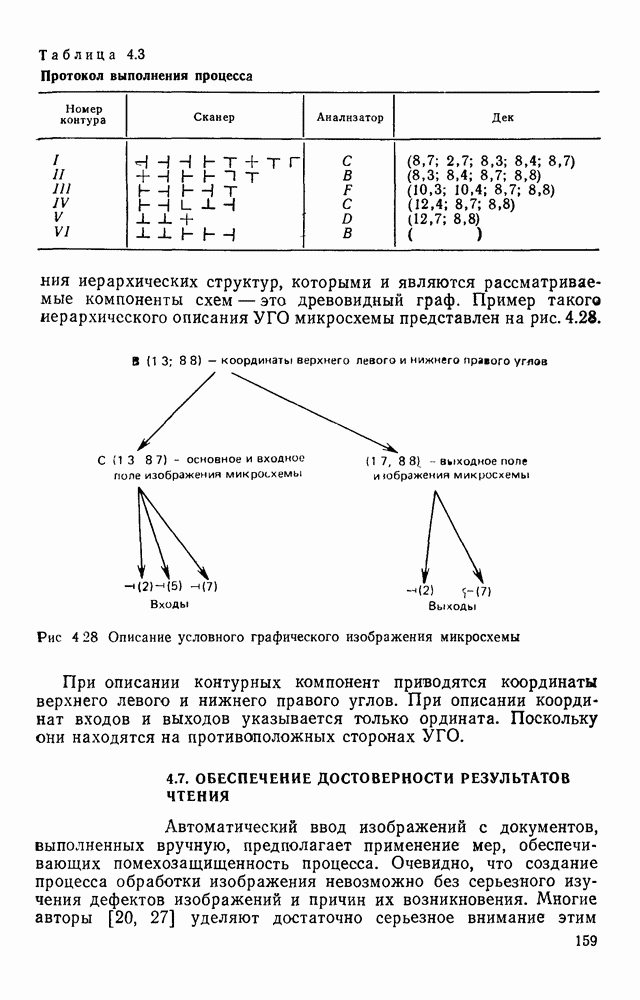
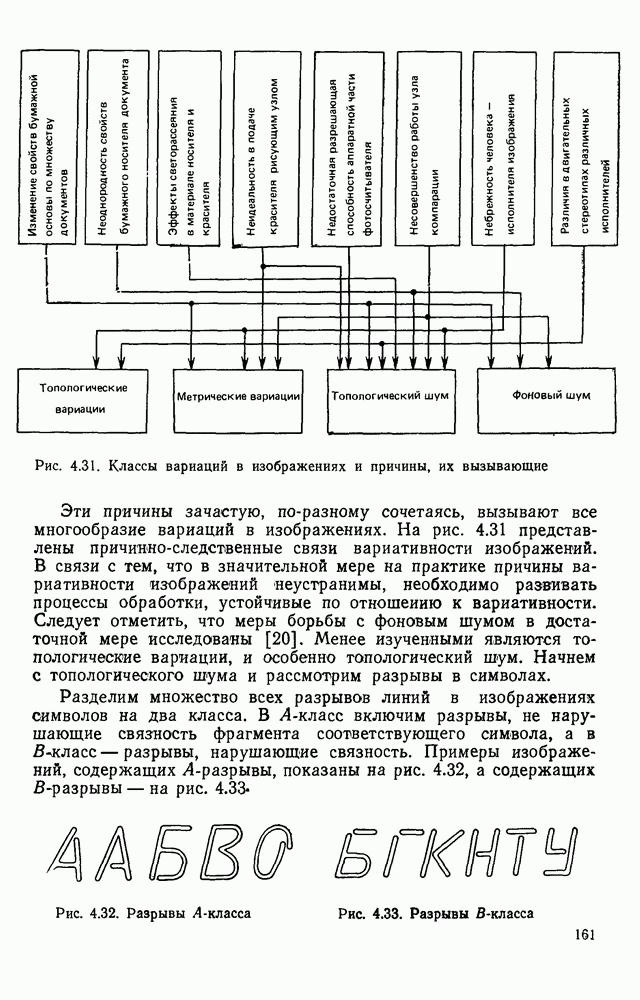
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
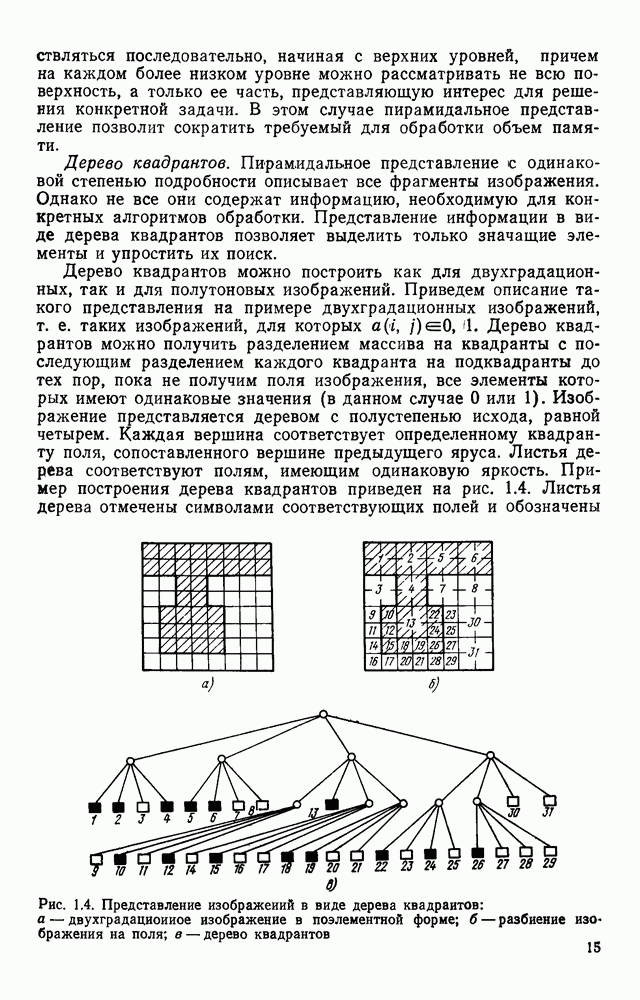
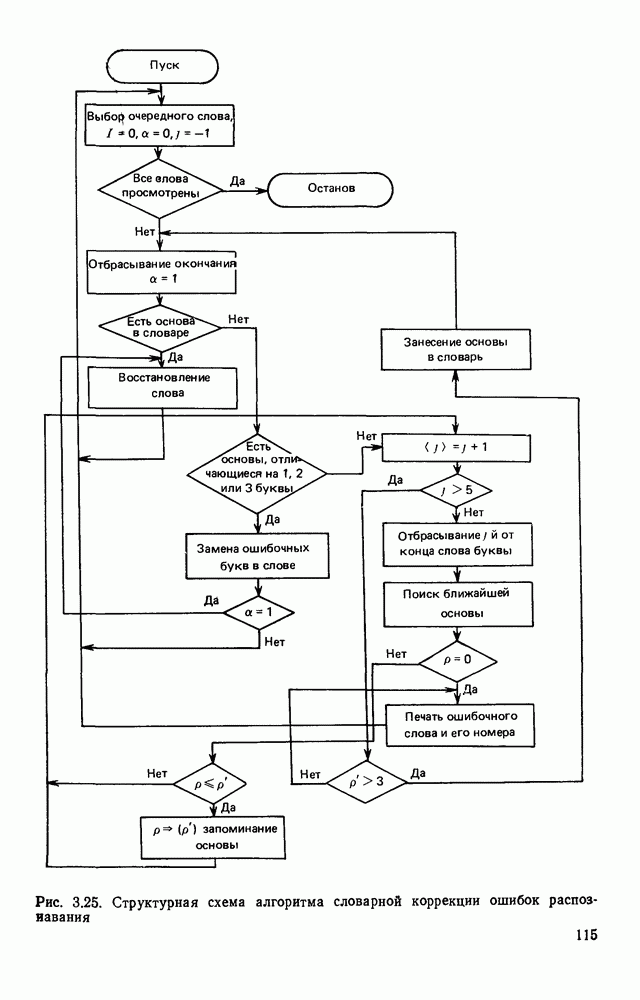
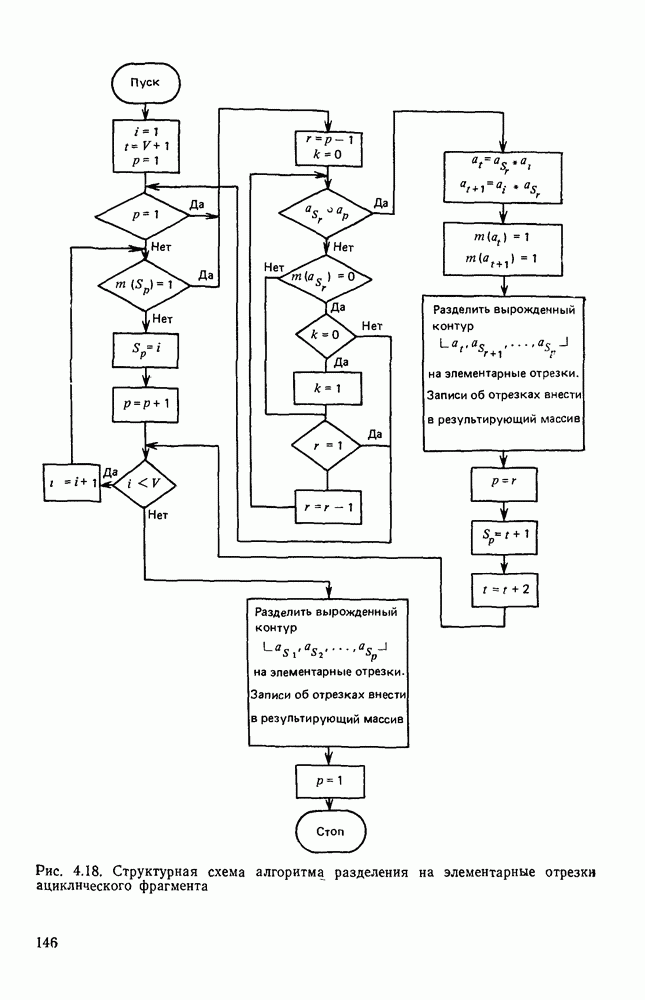
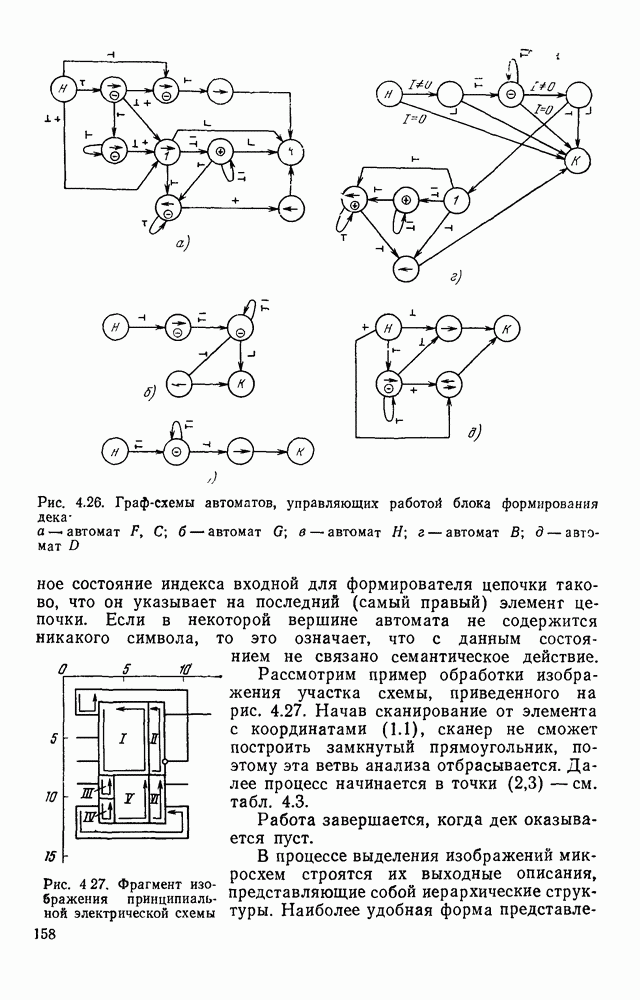
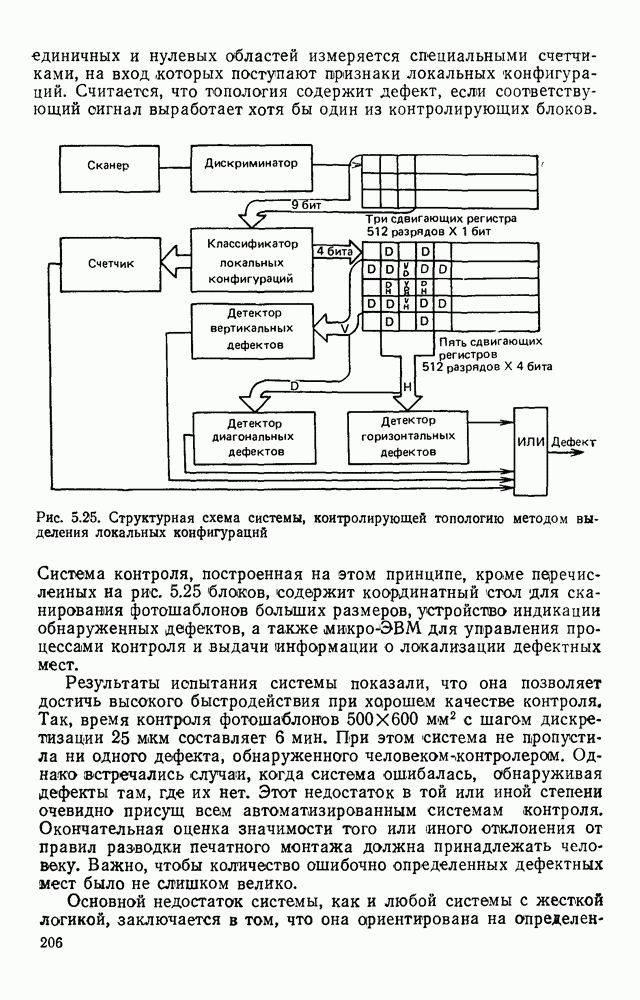
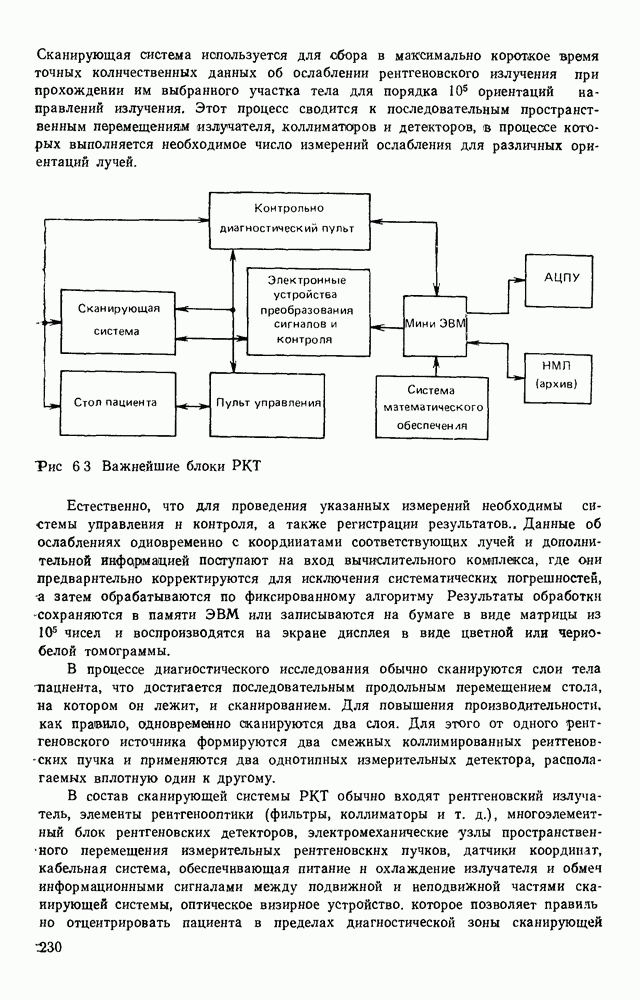
3.5. ЯЗЫК ОПИСАНИЯ ИЗОБРАЖЕНИЙПроблема построения эффективной языковой системы для описания изображений может решаться двумя путями. Один из них состоит в том, что алфавит (словарь признаков) и грамматика выбираются человеком. Другой путь предполагает автоматическое формирование языка. В этом случае считается, что машина, наблюдая изображения некоторого класса, сама должна сформировать соответствующий алфавит и набор травил описания изображений в этом алфавите. Несмотря на очевидную перспективность методов автоматического формирования языков, в настоящее время нет достаточно эффективных методов и алгоритмов выполнения такой процедуры. Сделаны только первые шаги, которые далеки от того, чтобы дать практически приемлемый результат. С другой стороны, опыт и интуиция человека, его представление о характере распознаваемых изображений позволяет неформальным путем построить определенную совокупность признаков: и правил описания изображений в терминах, в достаточной степени удовлетворяющих запросам практики. Кроме того, если бы даже и существовала возможность автоматического формирования языка описания изображений, остается открытым вопрос, насколько удобен полученный таким образом язык для построения специализированного устройства, решающего задачу распознавания. Проектировщик же при выборе системы признаков и грамматики всегда может учитывать их реализуемость доступными техническими средствами, простоту аппаратурного воплощения языка. Исходя из изложенных соображений, в основу языка описания символов положим язык последовательностей, достаточно хорошо изученный в теории цифровых автоматов. Как мы уже отмечали, существует тесная связь между языками с конечным числом состояний и конечными автоматами. Любой язык с конечным числом состояний может быть представлен в виде регулярного выражения, а каждое регулярное выражение определяет язык с конечным числом состояний [46]. Чтобы убедиться в том, что любой язык с конечным числом состояний может быть описан регулярным выражением, рассмотрим грамматику с конечным числом состояний В качестве примера построения графа рассмотрим грамматику регулярное выражение, описывающее все последовательности, переводящие соответствующий автомат из состояния а в состояние Т, т. е. все цепочки языка Таким образом, множество цепочек языка с конечным числом состояний может рассматриваться как некоторое регулярное событие, и, следовательно, всегда можно построить конечный автомат, представляющий это событие.
Рис. 3.9. Граф подстановок для грамматики В § 3.2 было показано, что, выбрав соответствующим образом основной и вспомогательный алфавиты, можно построить порождающую грамматику с конечным числом состояний таким образом, что каждому изображению на растре будет соответствовать цепочка в языке
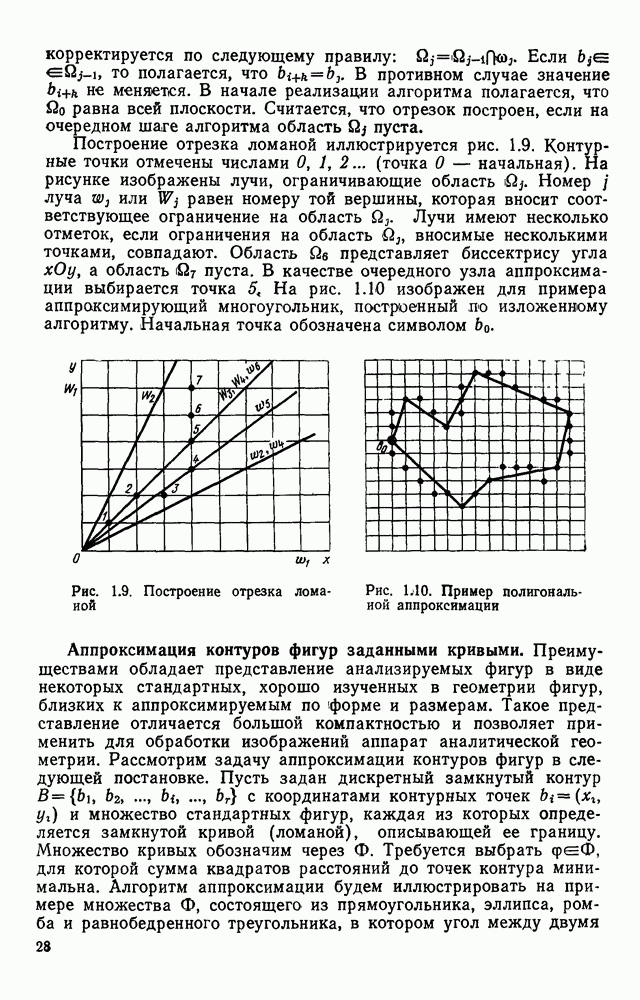
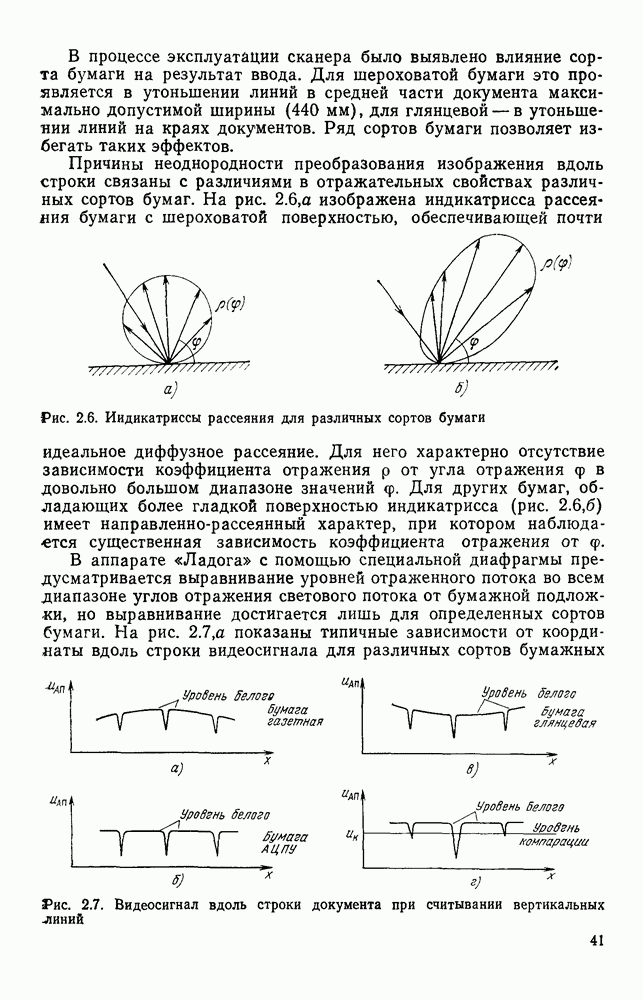
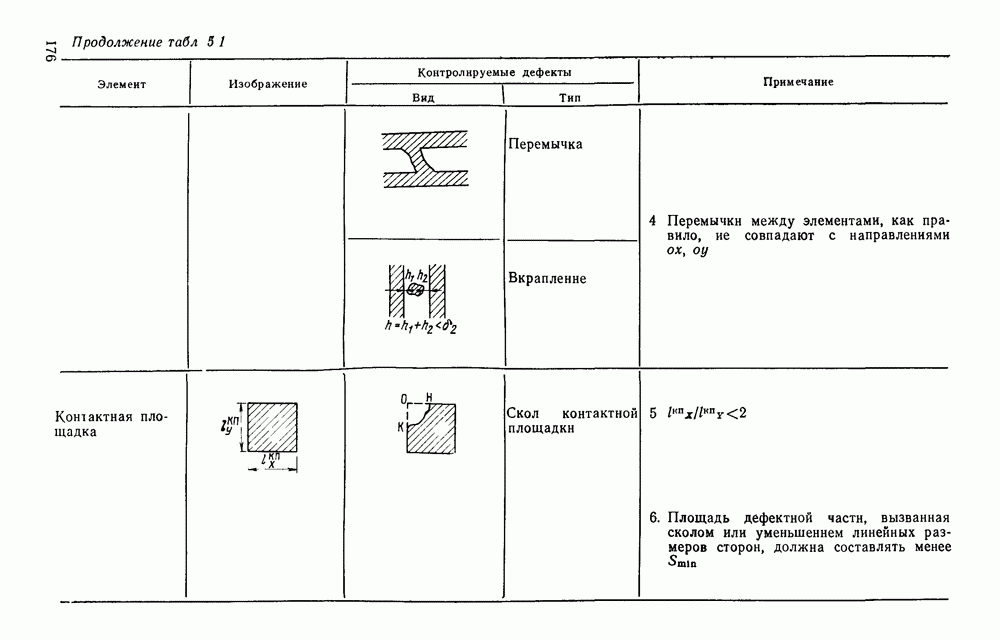
Здесь Условие непересечения подмножеств цепочек является, очевидно, необходимым, для того, чтобы автомат действительно распознавал. Выполнение этого условия обеспечивается соответствующим выборам алфавита А. Доказательством того, что такой алфавит существует, является алфавит из двух букв — 1 и 0, соответствующих зачерненным и незачерненным элементам растра. В этом случае каждый символ характеризуется цепочкой длиной для его сокращения необходимо использовать априорную информацию о распознаваемых символах. Из нескольких вариантов алфавита, представляющихся эффективными конструктору, лучший будет отобран по результатам моделирования работы устройства на ЭВМ. В основу алфавита языка описания изображений положим число пересечений данного символа с i-й строкой (столбцом). Иными словами, пусть символы алфавита определяются числом групп единиц, которые изображение создает в I. Признаки, основанные на подсчете числа пересечений, дали неплохой результат в экспериментах целого ряда исследований.
Рис. 3.10. Подсчет групп единиц в строках и столбцах II. Сведение алфавита к подсчету числа пересечений символа со строкой (столбцом) создает хорошее сжатие информации, так как III. Подсчет числа пересечений эффективно реализуется в любом процессоре. Обозначим через поразрядный двоичный вектор, соответствующий
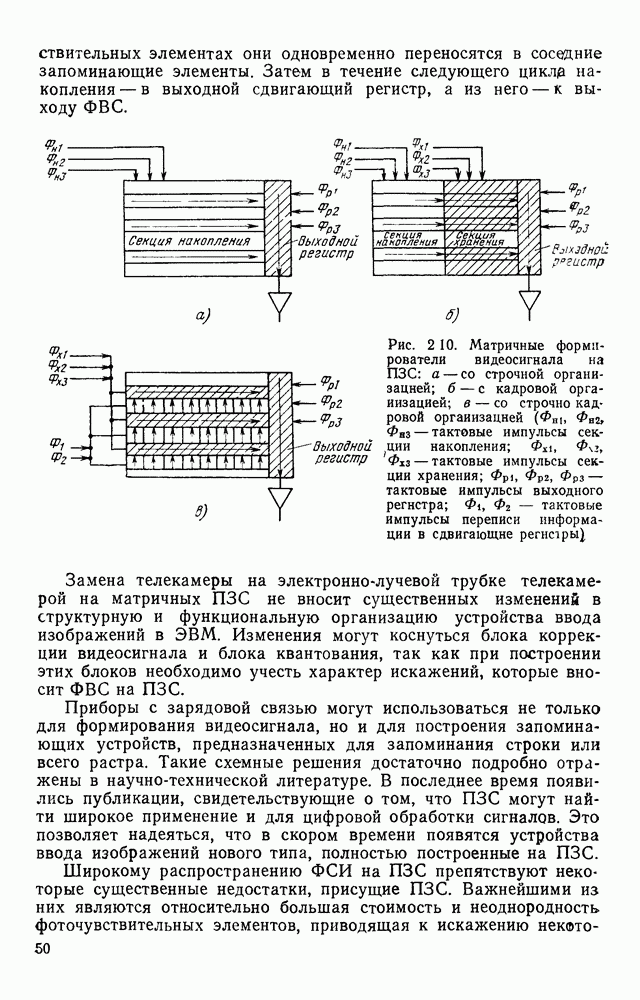
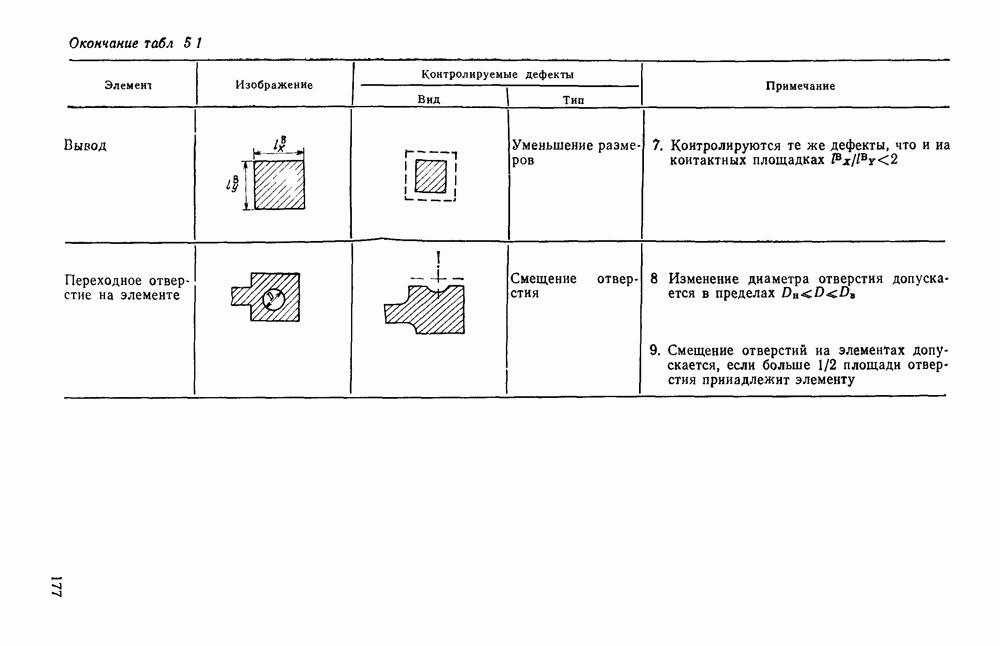
где Определим алфавит А. В качестве его букв возьмем числа вида
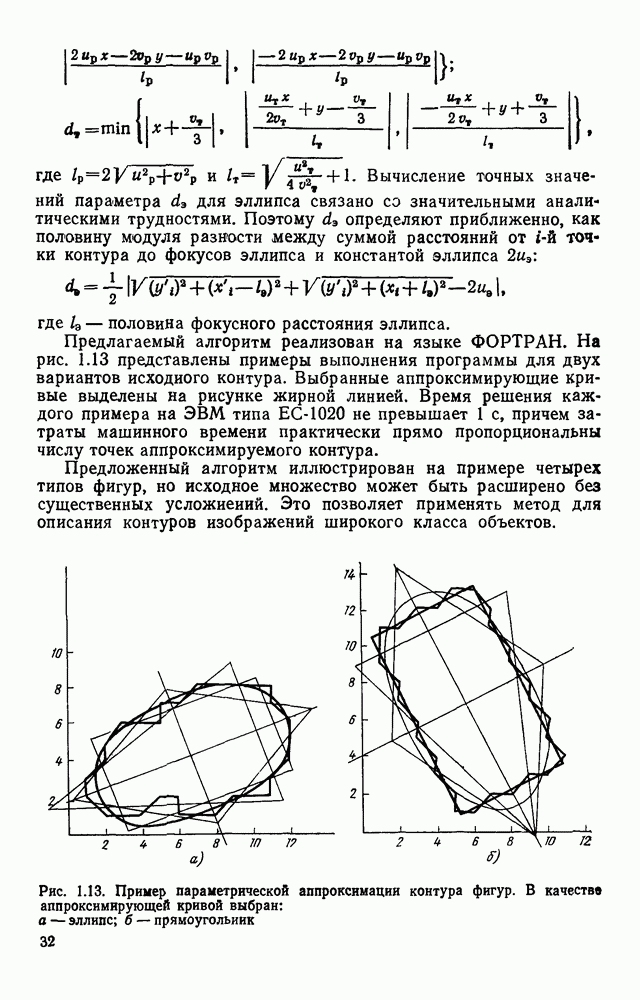
Здесь Наряду с А — алфавитом первого уровня, включим в полный алфавит ряд символов, образующих алфавит второго уровня
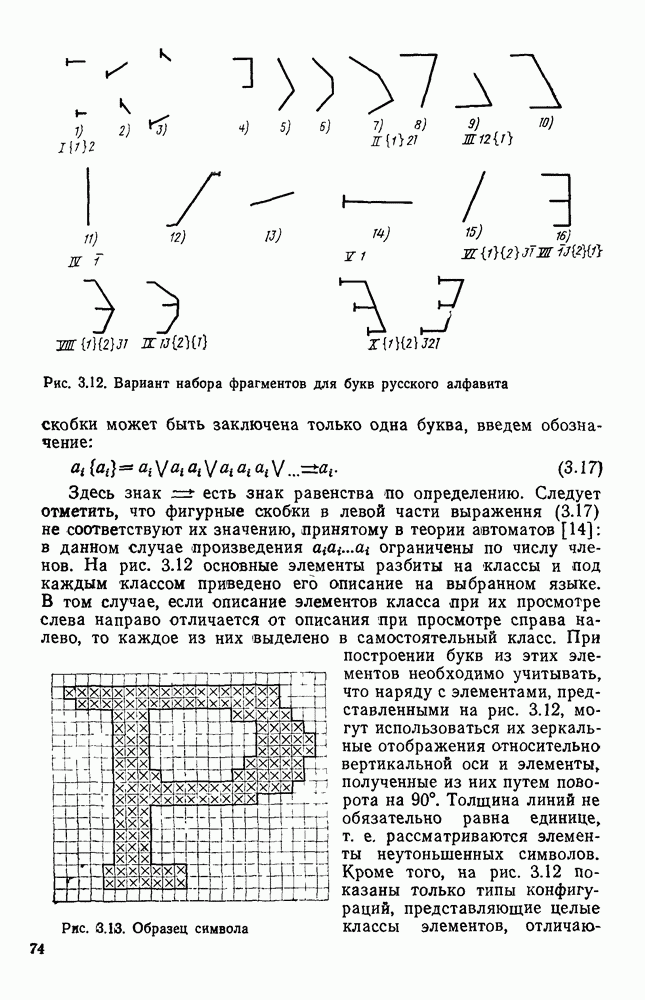
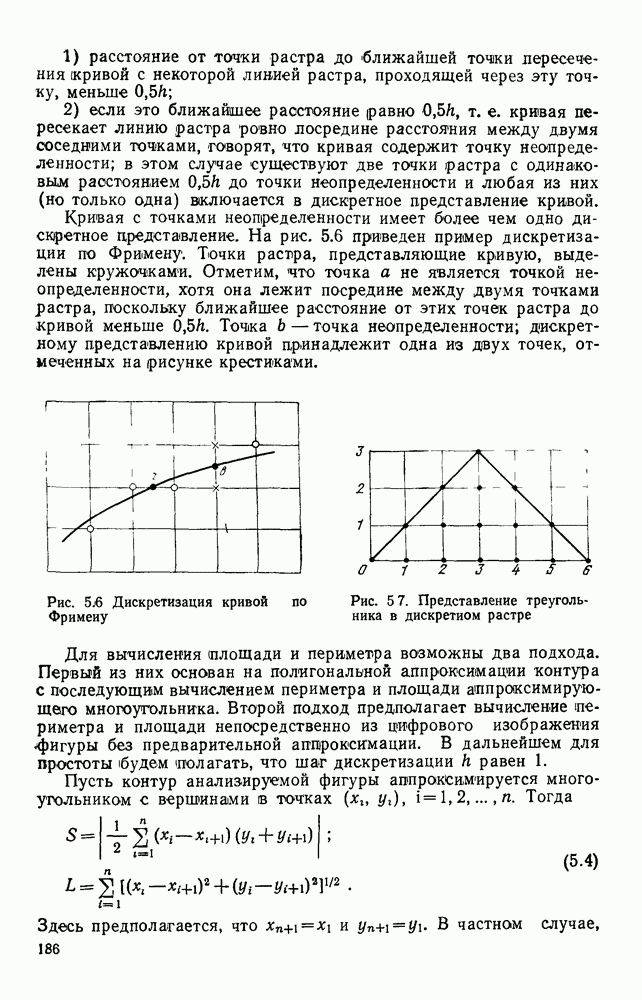
Рис. 3.11. Формирование букв алфавита А Сопоставляя парам строк растра буквы алфавита (3.16), получим цепочку Событие может быть задано различными способами. Наиболее простой из них состоит в непосредственном перечислении сопоставляемых ему цепочек. Поскольку все множество возможных изображений на растре конечно, то события, соответствующие распознаваемым символам, тоже конечны. Но любое конечное событие регулярно. Следовательно, множество цепочек, представляющих различные изображения на растре, может быть описано регулярным выражением. Однако нас интересуют не все возможные изображения, а только те из них, которые соответствуют распознаваемым символам. Для получения описаний символов рассмотрим основные элементы, из которых при определенной степени идеализации могут быть построены, например, все буквы русского алфавита. Элементы представлены на рис. 3.12. Учитывая, что при описании этих элементов букв никогда не возникает выражение вида
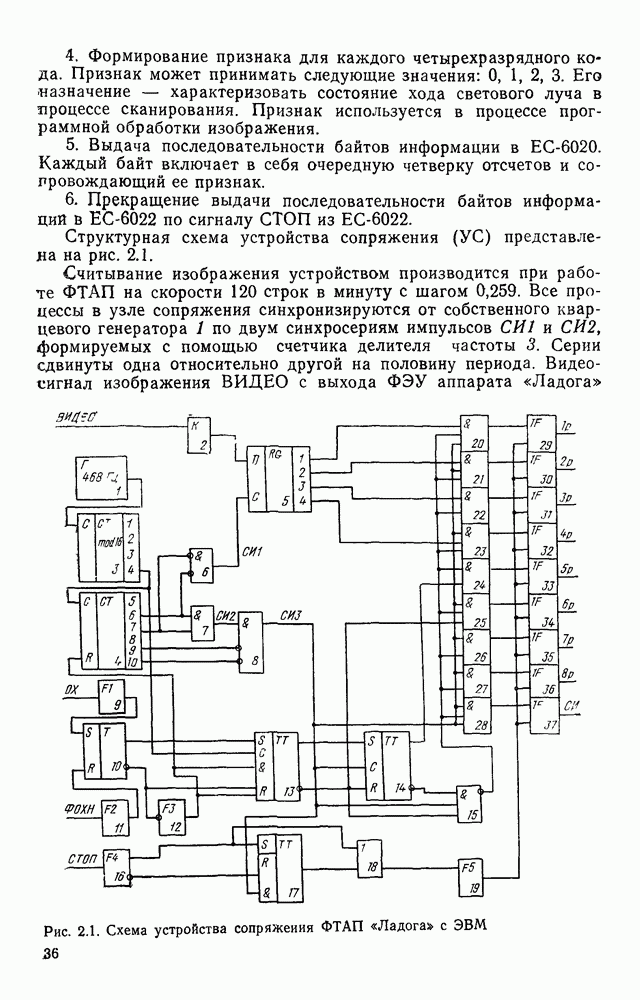
Рис. 3.12. Вариант набора фрагментов для букв русского алфавита скобки может быть заключена только одна буква, введем обозначение:
Здесь знак
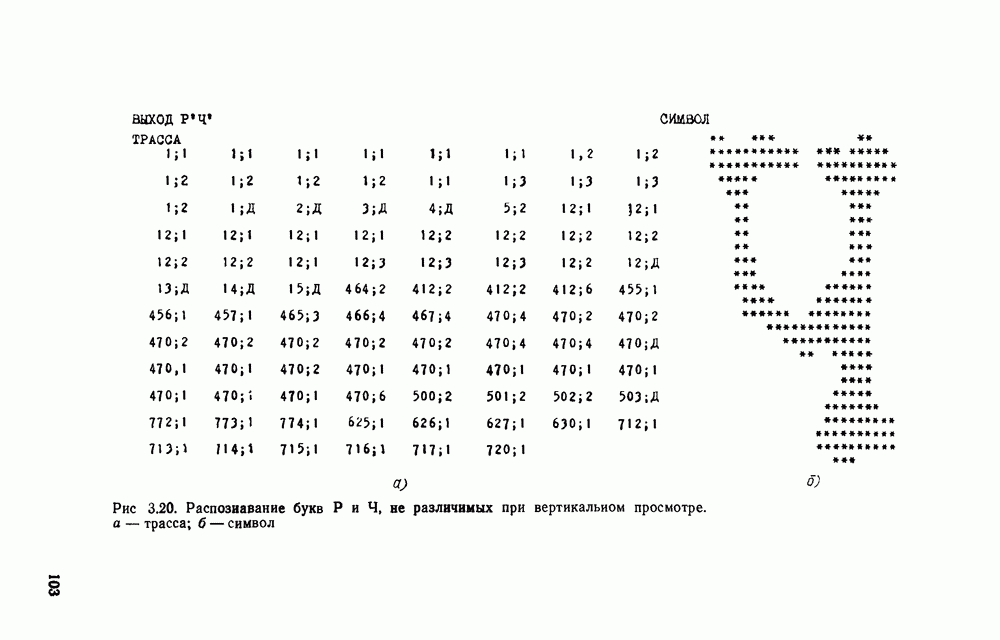
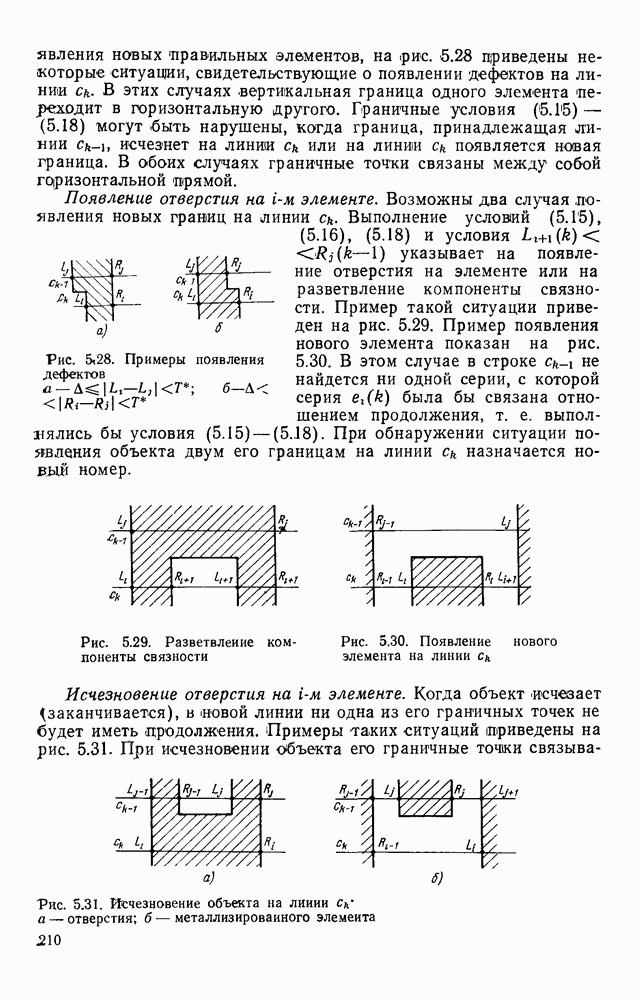
Рис. 3.13. Образец символа степенью наклона отдельных прямых, относительной и абсолютной длиной и т. д. Для иллюстрации того, каким образом изображение может быть разложено на элементы, рассмотрим изображение, представленное на рис. 3.13. Оно получено с помощью оптического преобразователя с отпечатка заглавной буквы «Р» пишущей машинки «Украина». Предположим, что просматриваем растр слева направо. Тогда нетрудно видеть, что сначала идет элемент 1 (см. рис. 3.12), затем (справа от него) зеркальное отражение относительно вертикальной оси элемента 16 (16 — «крыша» сверху означает зеркальное отражение относительно вертикальной оси) и, наконец, 4. Теперь можно словесно описать букву Р «Самым левым является элемент 1, к нему непосредственно примыкает зеркальное отображение относительно вертикальной оси 16, последний переходит в 4». Кратко описание можно представить следующим образом
Элементы, получаемые при просмотре в направлении снизу вверх, отделены точкой с запятой от элементов, полученных при просмотре слева направо. В выражении (3.18) каждый номер элемента заменим на номер типа регулярного выражения, которым описывается данный элемент
Выражение (3.19) является лингвистическим описанием буквы Р. Получив аналогичные описания для всех букв алфавита В, можно следующим образом организовать процесс распознавания. 1. Просматриваем растр с неизвестной буквой в горизонтальном направлении и в соответствии с (3.16) записываем цепочку, порождаемую растром в принятых обозначениях. 2. Разбиваем полученную цепочку на части таким образом, чтобы каждая из этих частей была описанием одного из представленных на рис. 3.12 элементов. 3. Выписываем номера типов элементов. 4. Повторяем процесс, просматривая растр в вертикальном направлении. 5. Сравниваем полученные описания символа в терминах типов регулярных выражений с имеющимися описаниями символов алфавита В. Пример 1 Просматривая представленный на рис 3 13 растр слева направо, получаем цепочку
Учитывая введенное обозначение (3 17), находим
2 Выражение (3 21) может быть однозначным образом разбито на следующие три «фразы» (0 не учитывается, поскольку он не относится к символам) 3 Таким образом, после просмотра в горизонтальном направлении имеем Повторяем п. 1—3, просматривая растр в вертикальном направлении 1 Просматривая растр снизу вверх, находим 2. 1 V тип; 1 IV тип; 2 I тип; 1 IV тип. 3 Окончательно получаем Изложенный способ описания изображений более совершенен» чем принятое в структурных методах описание в терминах признаков. Основные его преимущества состоят в следующем. 1. В нем учитывается взаимное расположение элементов, что значительно повышает выразительные возможности языка. 2. Сами элементы задаются через свои описания (микроструктурно), поэтому отдельные искажения и отклонения легко могут быть отфильтрованы. 3. «Словарь признаков» довольно гибок и имеется возможность автоматического «выбора признаков», точнее говоря, автоматического формирования описаний изображений. Следует отметить, что при построении распознающего устройства построение описания изображения в терминах типов элементов не является обязательным. Вопросы технической реализации изложенного метода будут рассмотрены ниже.
|
 |
Оглавление
|

































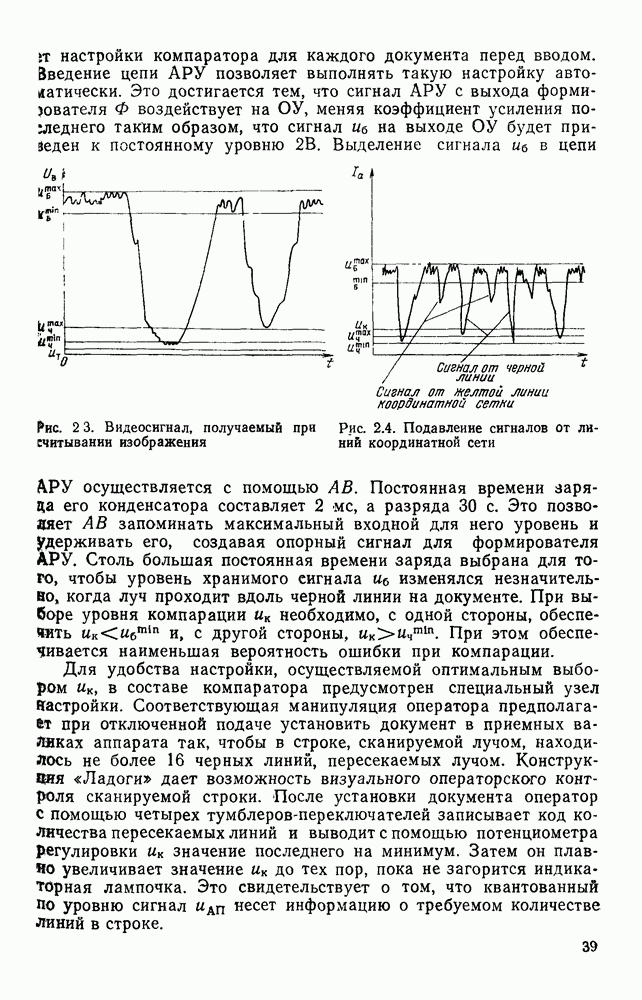
















































































































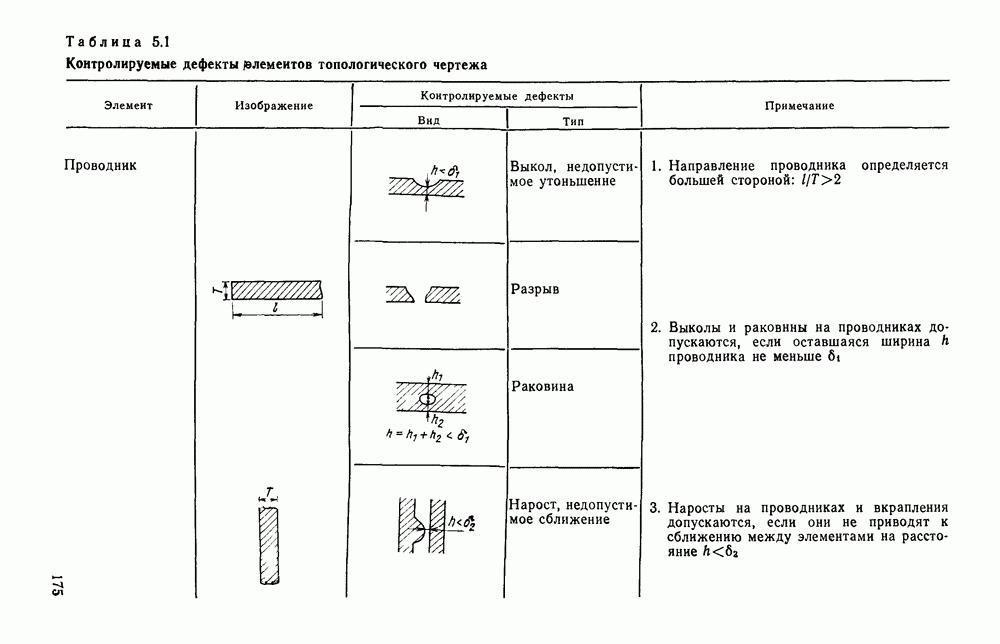



















































 Сопоставим этой грамматике ориентированный взвешенный граф Г, вершины которого соответствуют символам вспомогательного алфавита
Сопоставим этой грамматике ориентированный взвешенный граф Г, вершины которого соответствуют символам вспомогательного алфавита  и, кроме того, существует одна специальная вершина, обозначаемая Т. Вершины
и, кроме того, существует одна специальная вершина, обозначаемая Т. Вершины  соединяются дугой
соединяются дугой  если во множестве Р есть правило подстановки
если во множестве Р есть правило подстановки  где
где  Эта дуга взвешивается символом а. Кроме того, вершина соединяется дугой с вершиной Т, если среди элементов множества Р имеется правило подстановки вида
Эта дуга взвешивается символом а. Кроме того, вершина соединяется дугой с вершиной Т, если среди элементов множества Р имеется правило подстановки вида  Эта дуга направлена от к Т и взвешена символом а.
Эта дуга направлена от к Т и взвешена символом а.
 в которой
в которой  Соответствующий граф представлен на рис. 3.9. Множество всех цепочек языка
Соответствующий граф представлен на рис. 3.9. Множество всех цепочек языка  порождаемого грамматикой
порождаемого грамматикой  соответствует множеству всех путей между вершинами а и Т. Рассматривая граф Г как диаграмму переходов некоторого автомата и применяя теорию автоматов, можем найти
соответствует множеству всех путей между вершинами а и Т. Рассматривая граф Г как диаграмму переходов некоторого автомата и применяя теорию автоматов, можем найти
 . В нашем примере грамматики и графа Г регулярное выражение, описывающее все цепочки языка
. В нашем примере грамматики и графа Г регулярное выражение, описывающее все цепочки языка  имеет вид
имеет вид 


 Поскольку нас интересует задача распознавания изображений на растре, то мы должны найти способ разбиения всего множества цепочек языка
Поскольку нас интересует задача распознавания изображений на растре, то мы должны найти способ разбиения всего множества цепочек языка  на подмножества таким образом, чтобы каждому распознаваемому образу сопоставить свое подмножество цепочек, т. е., если проектируемое распознающее устройство должно различать q символов, то множество
на подмножества таким образом, чтобы каждому распознаваемому образу сопоставить свое подмножество цепочек, т. е., если проектируемое распознающее устройство должно различать q символов, то множество  должно быть представлено в следующем виде:
должно быть представлено в следующем виде:

 множество цепочек, не соответствующих ни одному из распознаваемых символов. Условимся обозначать совокупность распознаваемых символов через В.
множество цепочек, не соответствующих ни одному из распознаваемых символов. Условимся обозначать совокупность распознаваемых символов через В.
 Ясно, что все множество таких цепочек может быть разбито на классы, соответствующие распознаваемым образам и всем остальным изображениям. Этап выбора подходящего алфавита является чрезвычайно важным при проектировании распознающего устройства, так как, с одной стороны, выбор алфавита определяет качество распознавания, с другой — алфавит определяет сложность распознающего устройства (программы) и скорость распознавания. Выбор алфавита тесно связан со способом обработки информации. Если, например, символы алфавита А сопоставлять строкам растра размерами
Ясно, что все множество таких цепочек может быть разбито на классы, соответствующие распознаваемым образам и всем остальным изображениям. Этап выбора подходящего алфавита является чрезвычайно важным при проектировании распознающего устройства, так как, с одной стороны, выбор алфавита определяет качество распознавания, с другой — алфавит определяет сложность распознающего устройства (программы) и скорость распознавания. Выбор алфавита тесно связан со способом обработки информации. Если, например, символы алфавита А сопоставлять строкам растра размерами  то алфавит будет содержать в общем случае
то алфавит будет содержать в общем случае  букв. Поскольку такой алфавит громоздок, то
букв. Поскольку такой алфавит громоздок, то
 строке
строке  столбце) растра. Обоснуем такой выбор.
столбце) растра. Обоснуем такой выбор.

 комбинаций нулей и единиц сводятся лишь к
комбинаций нулей и единиц сводятся лишь к  комбинациям, где
комбинациям, где  — наименьшее целое число, большее или равное
— наименьшее целое число, большее или равное 
 строке растра. Обозначим через
строке растра. Обозначим через  — число групп единиц в векторе
— число групп единиц в векторе  . На рис. 3.10 показан пример символа и числа
. На рис. 3.10 показан пример символа и числа  . Обозначим через
. Обозначим через  число единиц в векторе
число единиц в векторе  . Пересечение символа с i-й строкой
. Пересечение символа с i-й строкой  столбцом) будем называть длинным, если
столбцом) будем называть длинным, если

 — некоторое фиксированное число,
— некоторое фиксированное число,  — параметр, определяющий размер символа в направлении просмотра. При просмотре в вертикальном направлении — это ширина буквы, при просмотре в горизонтальном направлении — высота. В противном случае пересечение будем называть коротким.
— параметр, определяющий размер символа в направлении просмотра. При просмотре в вертикальном направлении — это ширина буквы, при просмотре в горизонтальном направлении — высота. В противном случае пересечение будем называть коротким.

 — двоичный вектор, компоненты которого являются дизъюнкцией соответствующих компонент векторов и
— двоичный вектор, компоненты которого являются дизъюнкцией соответствующих компонент векторов и  Если вектор
Если вектор  удовлетворяет уровню (3.15), то будем писать
удовлетворяет уровню (3.15), то будем писать  и говорить, что вектор
и говорить, что вектор  имеет длинное пересечение. На рис. 3.11 показаны примеры пар векторов и соответствующие им буквы алфавита А.
имеет длинное пересечение. На рис. 3.11 показаны примеры пар векторов и соответствующие им буквы алфавита А.
 Символы этого алфавита также соответствуют числу пересечений, но не во всей строке (столбце) растра, а в определенной части символа — нижней, верхней, левой, правой половине. Дальнейшее изложение будем вести, исходя из алфавита А. Детальное описание символов алфавита второго уровня будет приведено ниже.
Символы этого алфавита также соответствуют числу пересечений, но не во всей строке (столбце) растра, а в определенной части символа — нижней, верхней, левой, правой половине. Дальнейшее изложение будем вести, исходя из алфавита А. Детальное описание символов алфавита второго уровня будет приведено ниже.

 из
из  букв, описывающую изображение при его просмотре сверху вниз (снизу вверх). Аналогичным образом создается цепочка
букв, описывающую изображение при его просмотре сверху вниз (снизу вверх). Аналогичным образом создается цепочка  описывающая изображение при просмотре в горизонтальном направлении. Полное описание изображения дает, очевидно, конкатенация цепочек
описывающая изображение при просмотре в горизонтальном направлении. Полное описание изображения дает, очевидно, конкатенация цепочек  Из-за неидеальности печати, написания и помех при преобразовании оптического сигнала в электрический, изображения различных экземпляров даже одного и того же распознаваемого символа будут отличаться. Тем более будут отличаться изображения различных начертаний некоторого символа. Каждому изображению на растре, вообще говоря, соответствует своя цепочка
Из-за неидеальности печати, написания и помех при преобразовании оптического сигнала в электрический, изображения различных экземпляров даже одного и того же распознаваемого символа будут отличаться. Тем более будут отличаться изображения различных начертаний некоторого символа. Каждому изображению на растре, вообще говоря, соответствует своя цепочка  из
из  символов (3.16). Множеству цепочек
символов (3.16). Множеству цепочек  сопоставляемых одному и тому же распознаваемому символу
сопоставляемых одному и тому же распознаваемому символу  , соответствует событие.
, соответствует событие.
 т. е. в итерационные
т. е. в итерационные


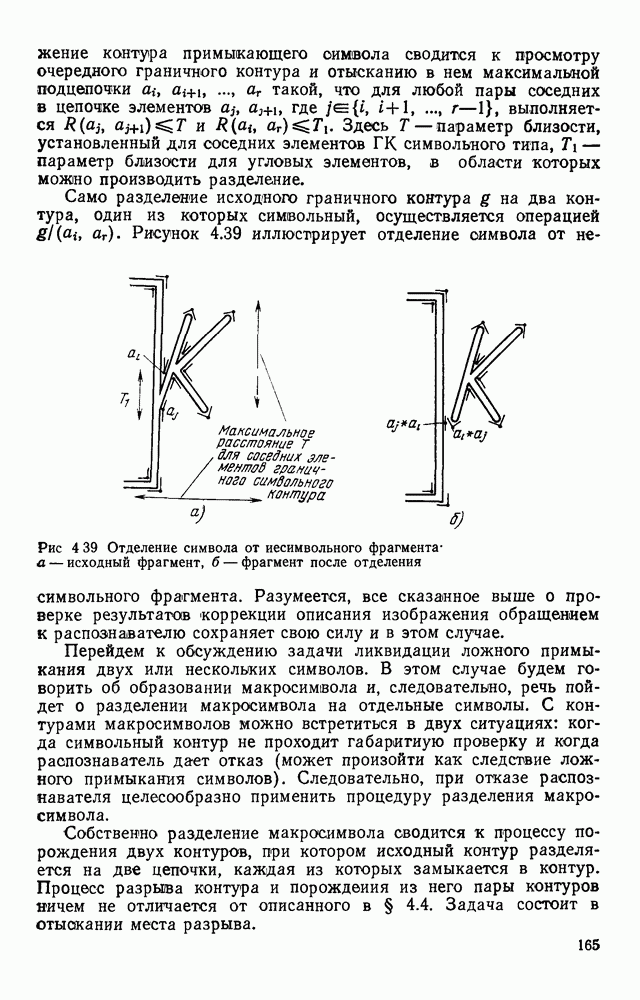
 есть знак равенства по определению. Следует отметить, что фигурные скобки в левой части выражения (3.17) не соответствуют их значению, принятому в теории автоматов [14]: в данном случае произведения ограничены по числу членов. На рис. 3.12 основные элементы разбиты на классы и под каждым классом приведено его описание на выбранном языке. В том случае, если описание элементов класса при их просмотре слева направо отличается от описания при просмотре справа налево, то каждое из них выделено в самостоятельный класс. При построении букв из этих элементов необходимо учитывать, что наряду с элементами, представленными на рис. 3.12, могут использоваться их зеркальные отображения относительно вертикальной оси и элементы, полученные из них путем поворота на 90°. Толщина линий не обязательно равна единице, т. е. рассматриваются элементы неутоныиенных символов. Кроме того, на рис. 3.12 показаны только типы конфигураций, представляющие целые классы элементов, отличающихся
есть знак равенства по определению. Следует отметить, что фигурные скобки в левой части выражения (3.17) не соответствуют их значению, принятому в теории автоматов [14]: в данном случае произведения ограничены по числу членов. На рис. 3.12 основные элементы разбиты на классы и под каждым классом приведено его описание на выбранном языке. В том случае, если описание элементов класса при их просмотре слева направо отличается от описания при просмотре справа налево, то каждое из них выделено в самостоятельный класс. При построении букв из этих элементов необходимо учитывать, что наряду с элементами, представленными на рис. 3.12, могут использоваться их зеркальные отображения относительно вертикальной оси и элементы, полученные из них путем поворота на 90°. Толщина линий не обязательно равна единице, т. е. рассматриваются элементы неутоныиенных символов. Кроме того, на рис. 3.12 показаны только типы конфигураций, представляющие целые классы элементов, отличающихся

 . Однако оно недостаточно полна, в частности, не позволяет отличить Р от Б, так как остается неясным, какая из двух пар горизонтальных линий в 16 переходит в 4. Для получения этой информации необходимо просмотреть растр снизу вверх. При этом находим, что самым нижним является элемент 14, переходящий в 22, затем идут 1 и 11. Таким образом, описание буквы Р может быть выполнено так:
. Однако оно недостаточно полна, в частности, не позволяет отличить Р от Б, так как остается неясным, какая из двух пар горизонтальных линий в 16 переходит в 4. Для получения этой информации необходимо просмотреть растр снизу вверх. При этом находим, что самым нижним является элемент 14, переходящий в 22, затем идут 1 и 11. Таким образом, описание буквы Р может быть выполнено так:

 (3.19)
(3.19)


 тип,
тип,  тип
тип


 . Это описание Совпадает с описанием буквы
. Это описание Совпадает с описанием буквы  т. е.
т. е. 