Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
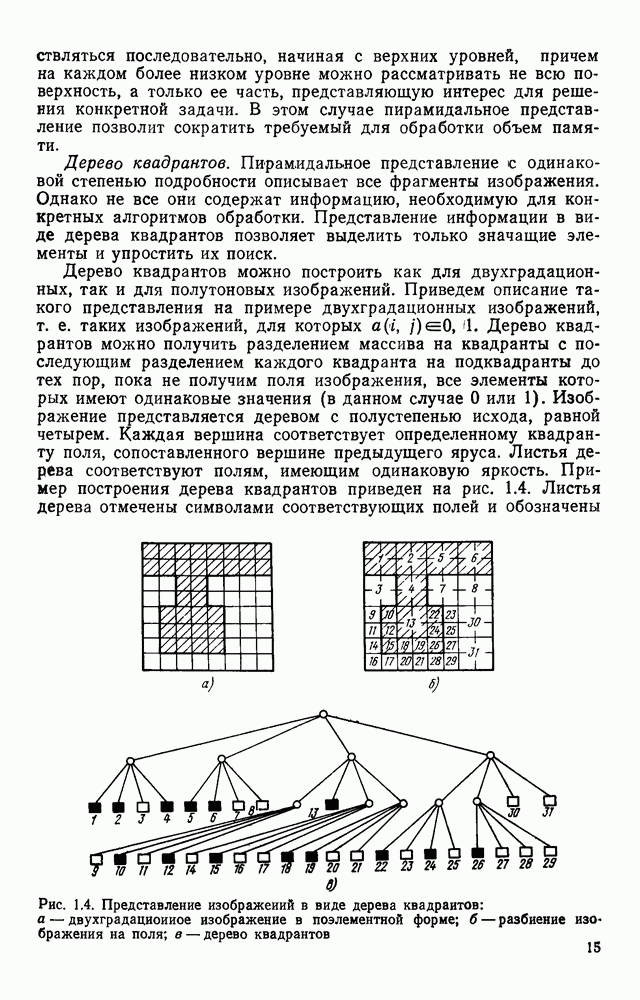
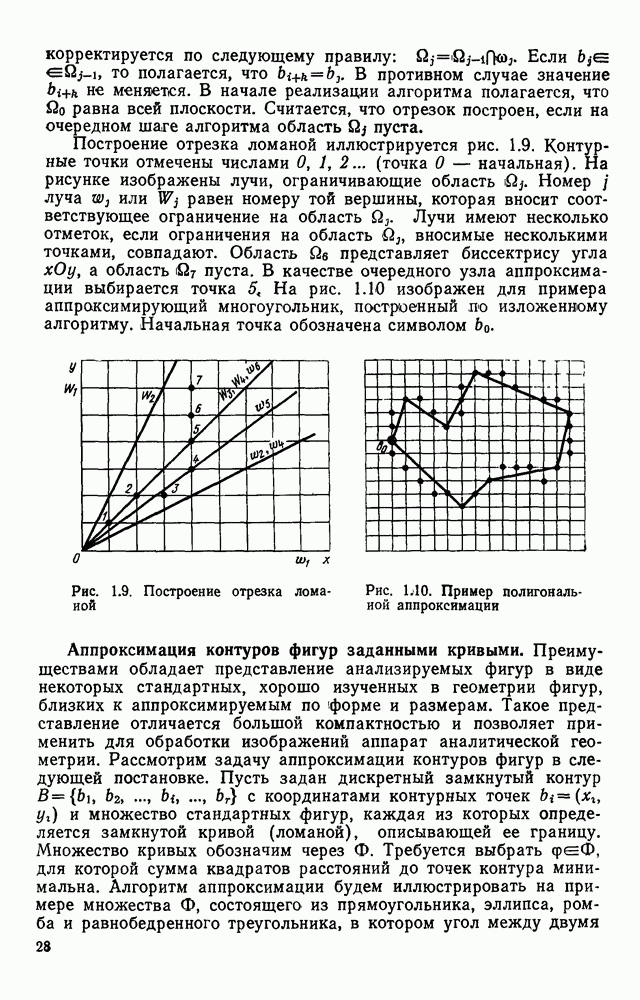
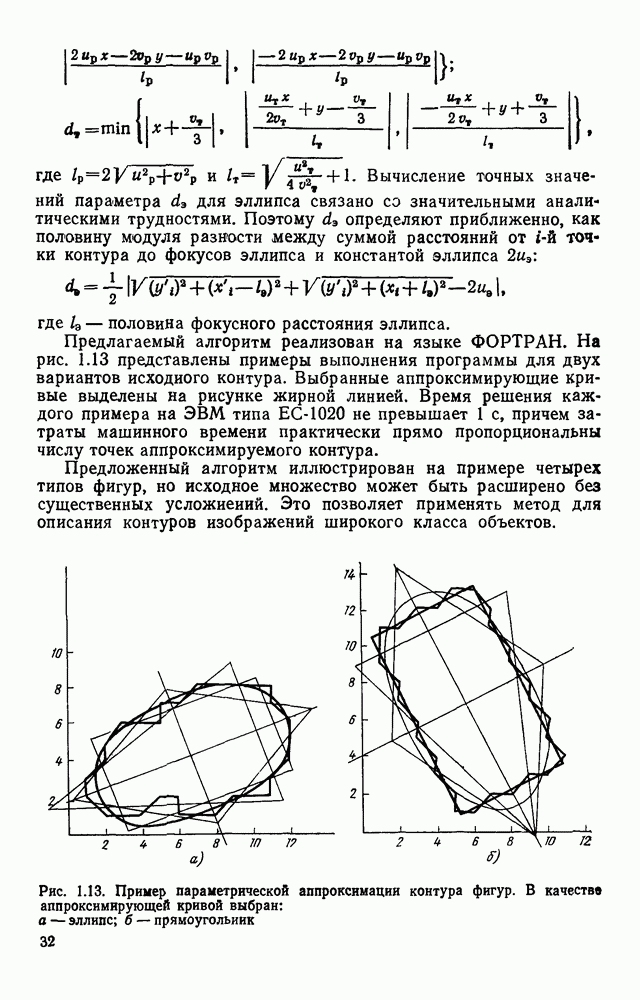
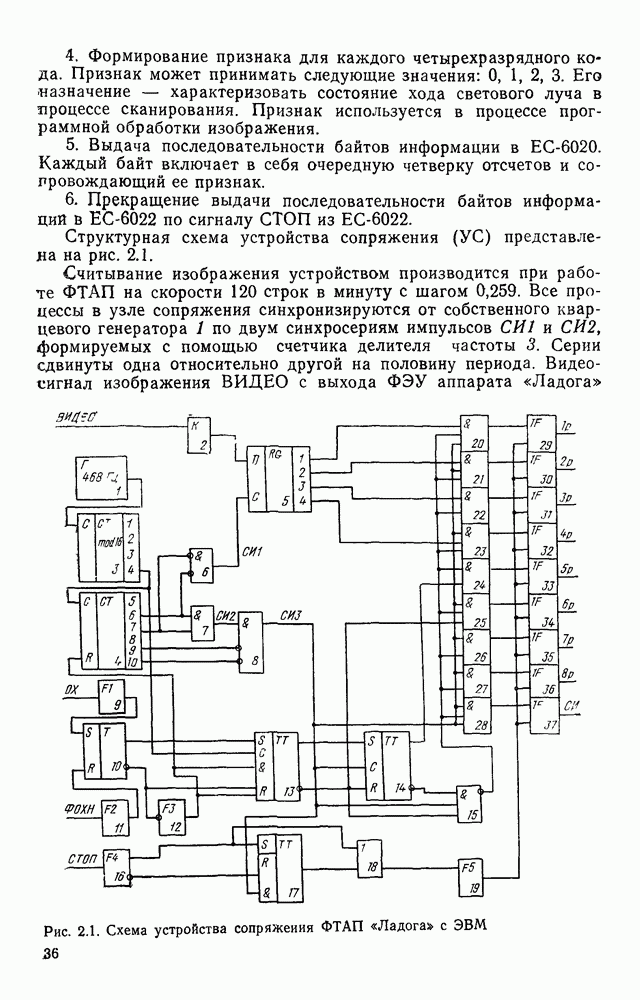
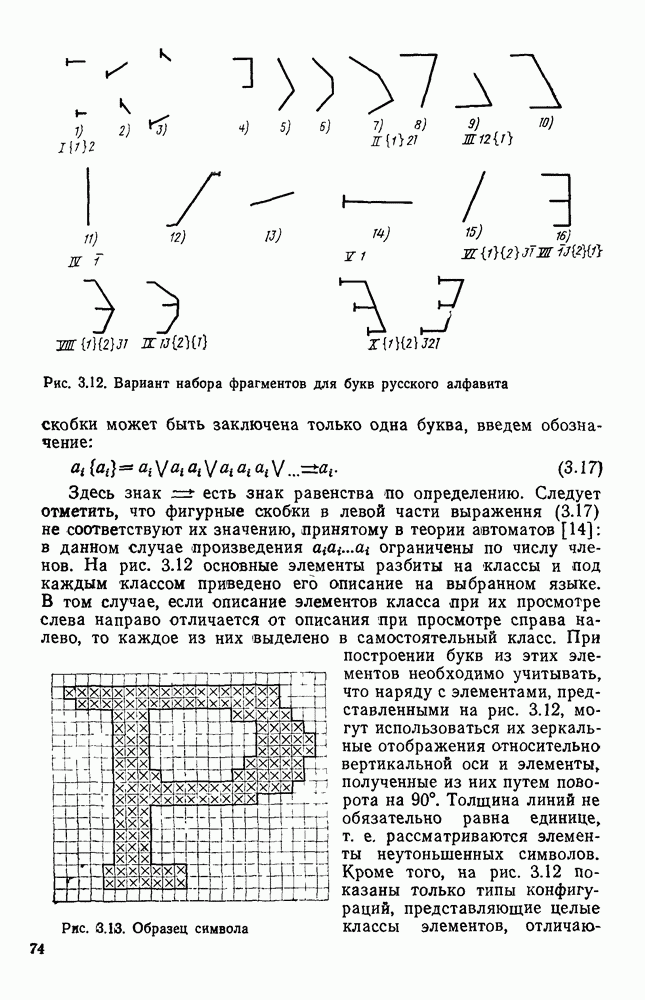
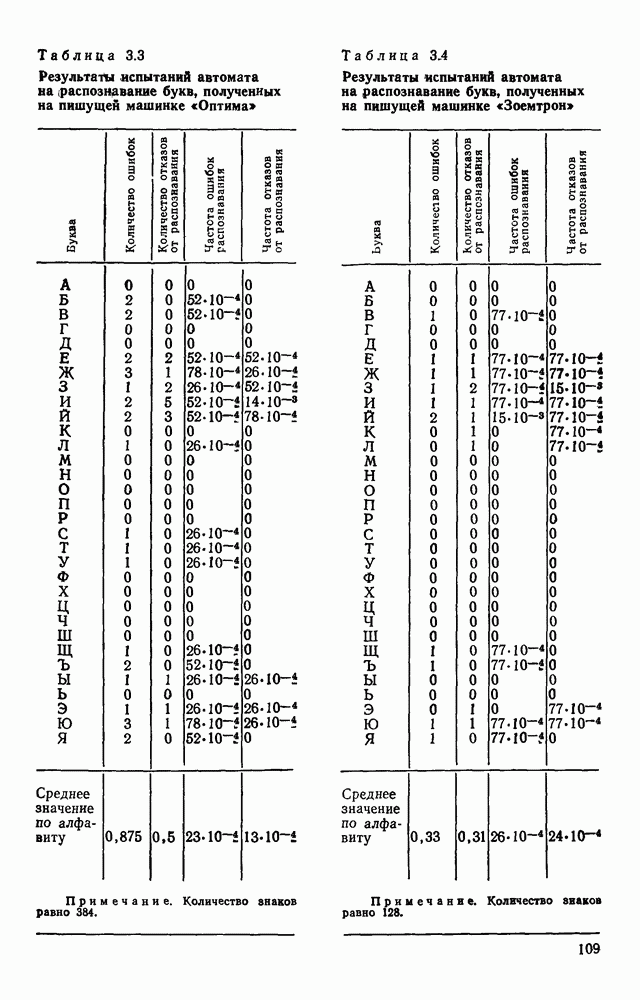
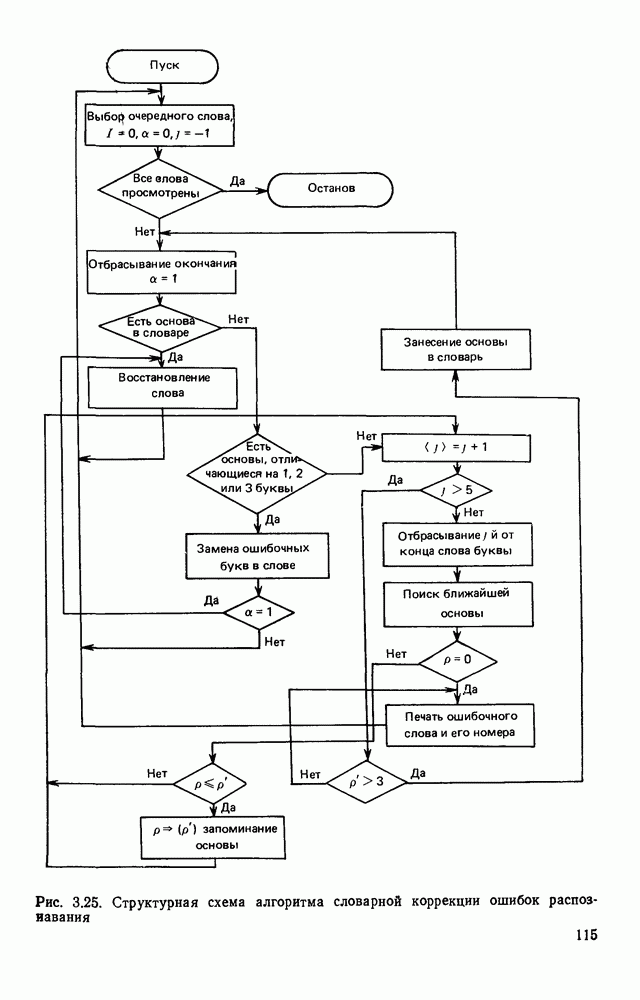
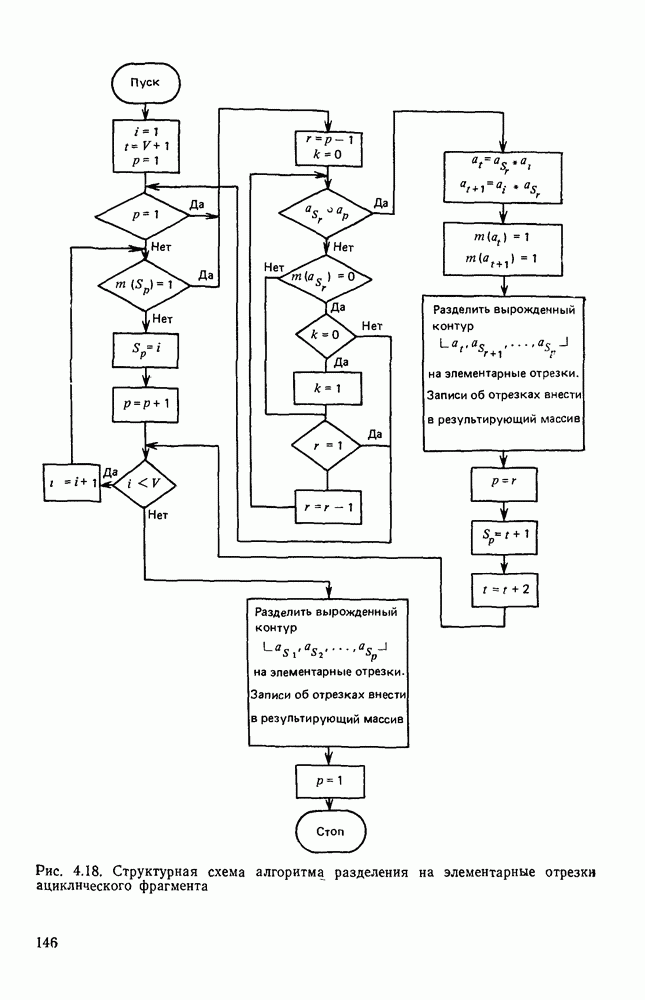
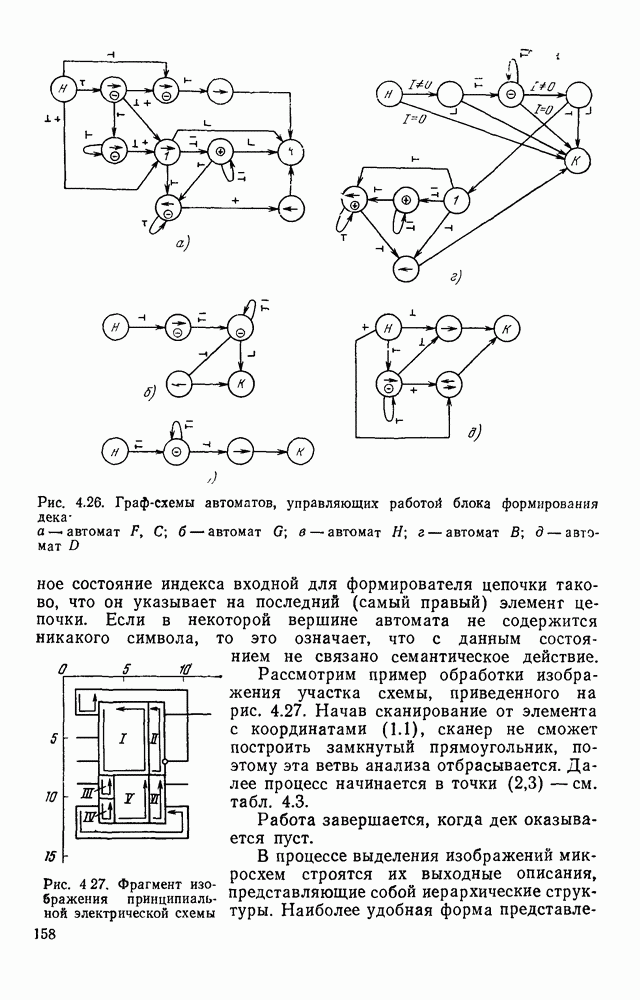
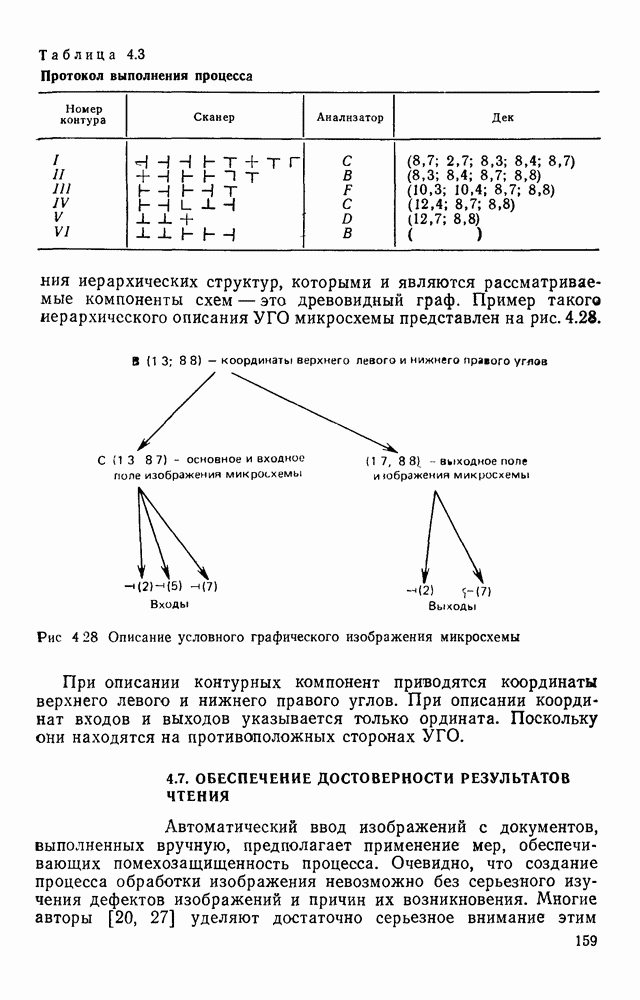
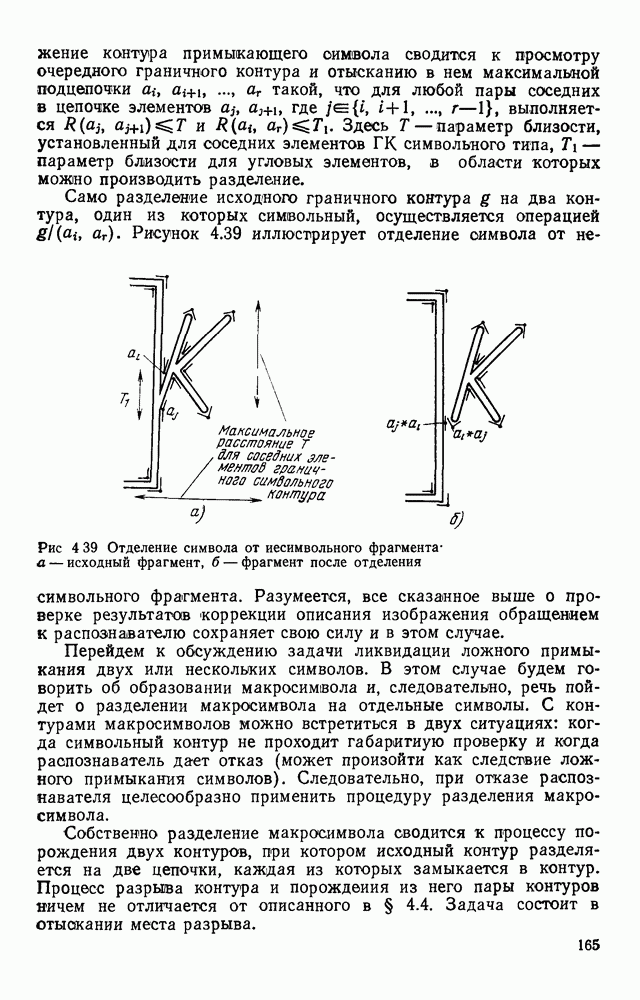
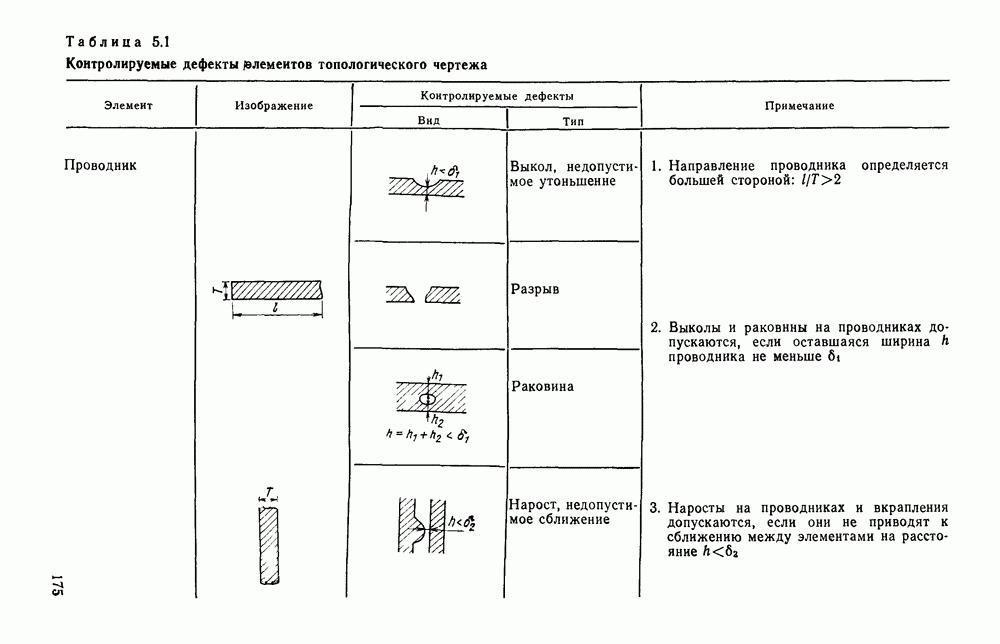
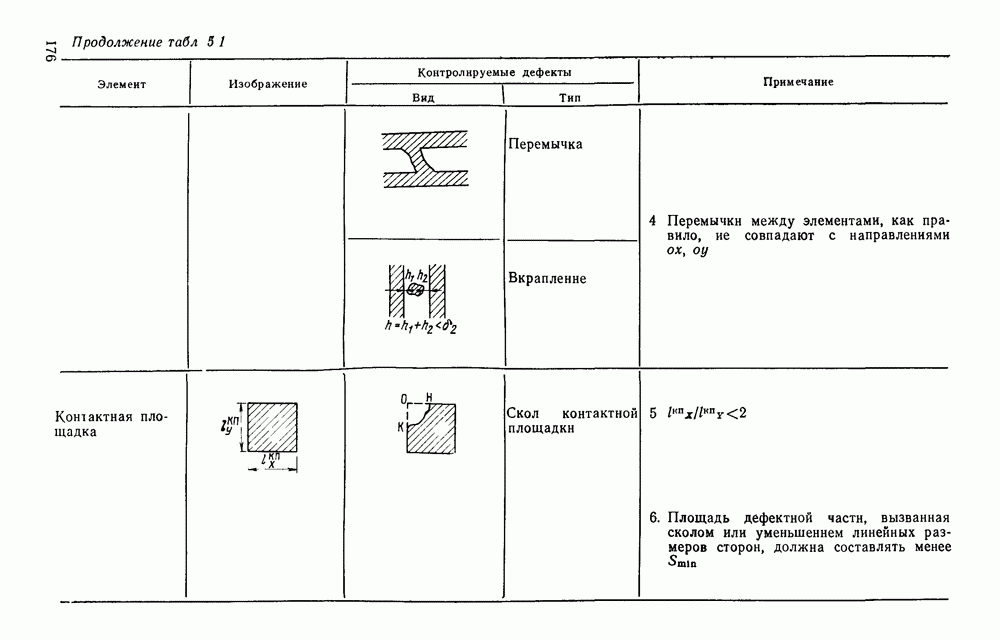
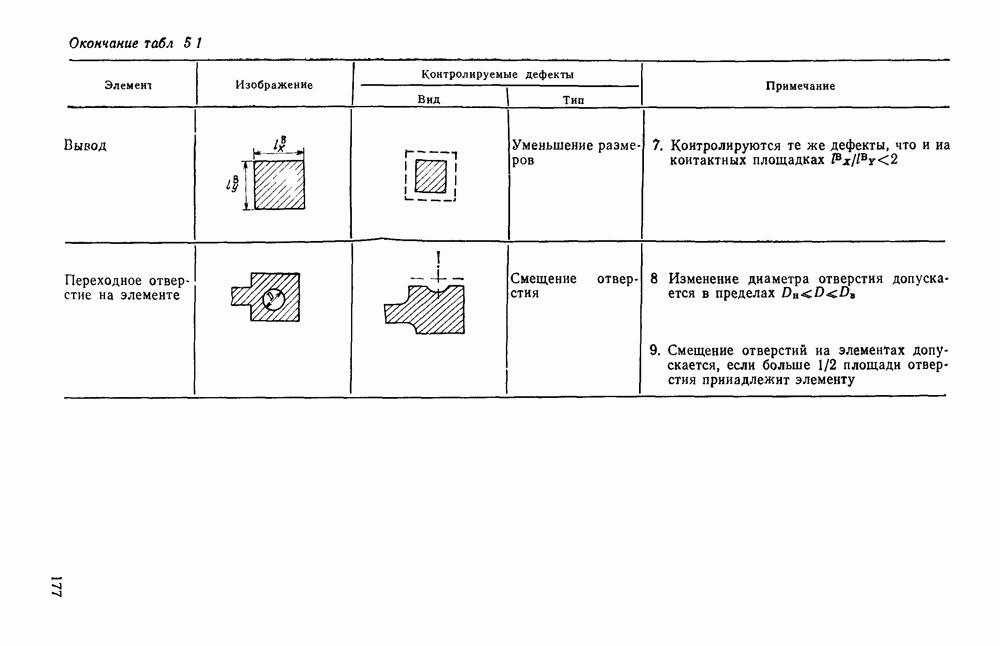
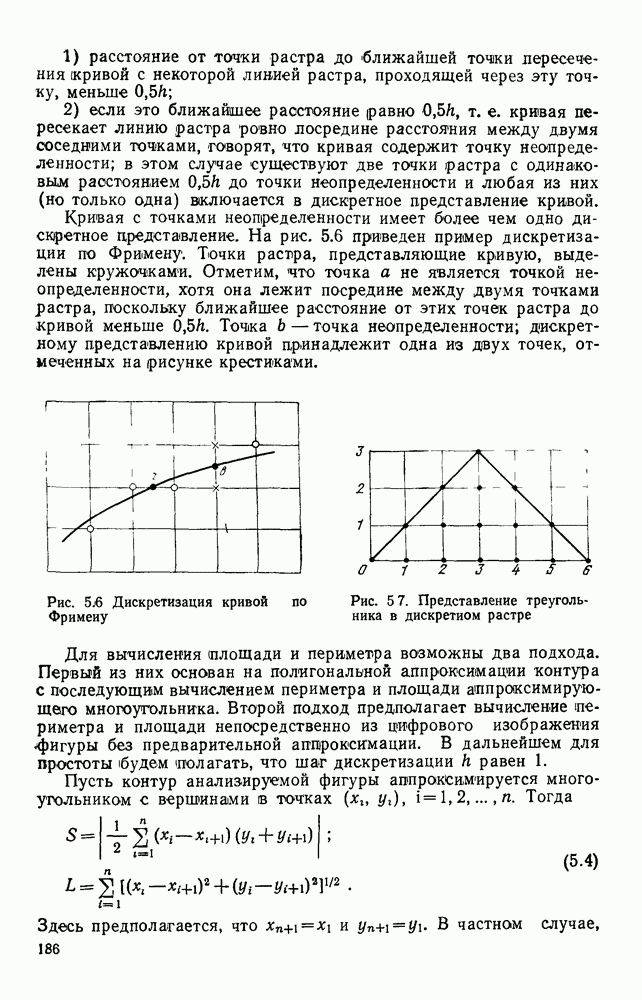
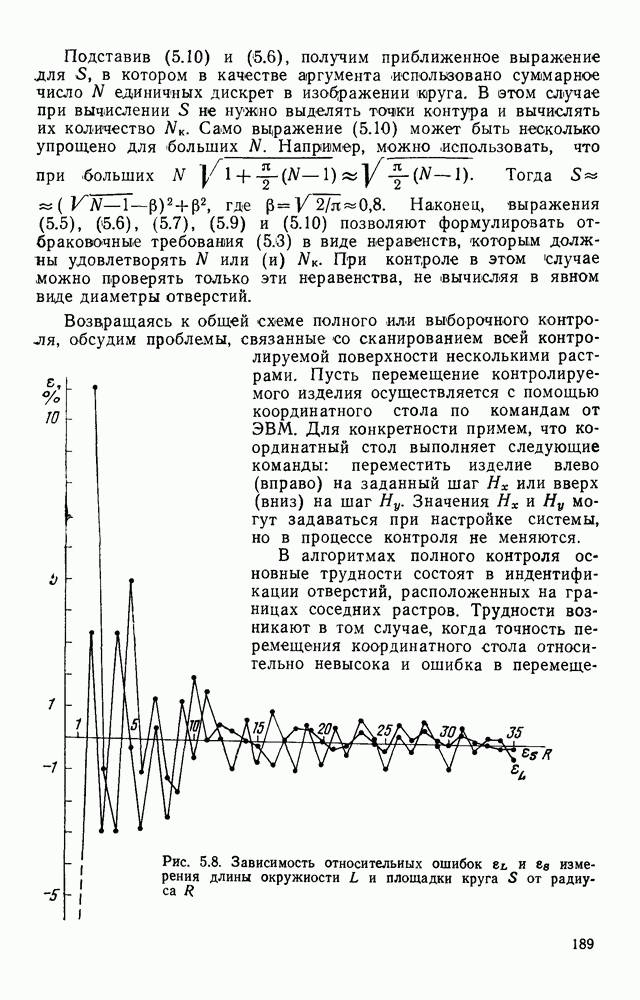
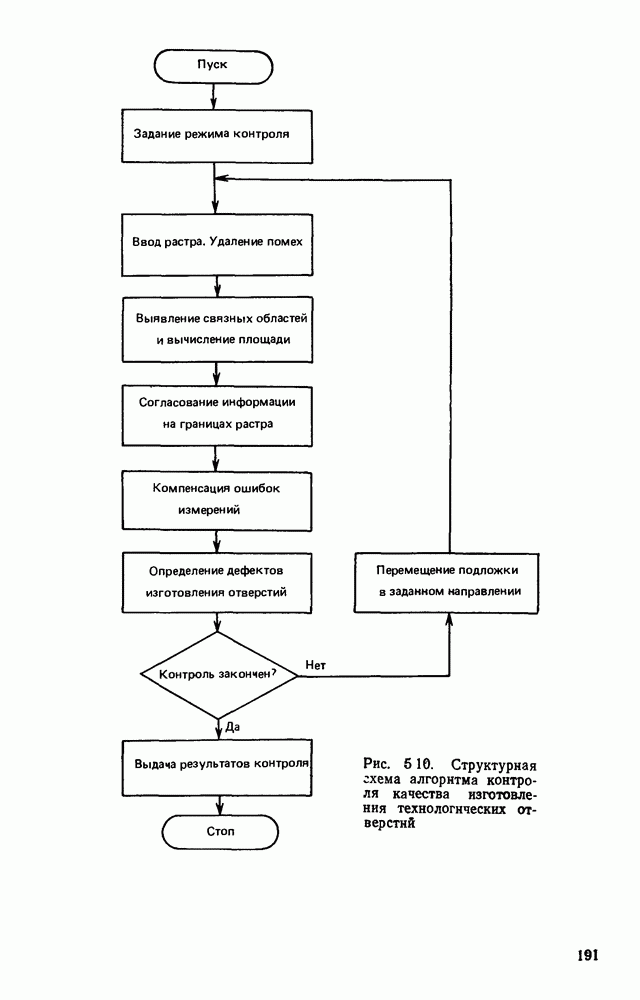
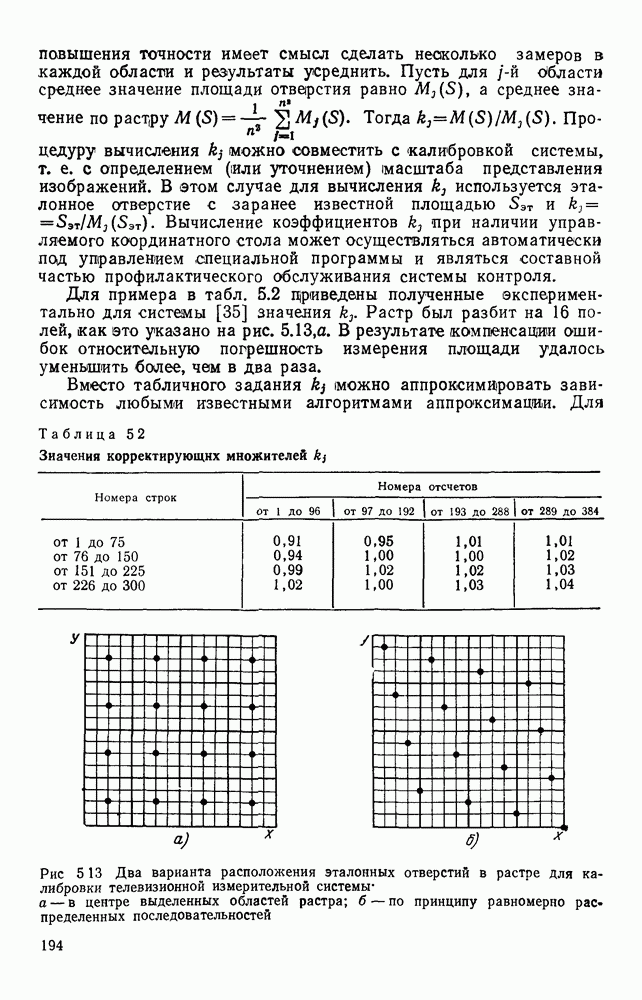
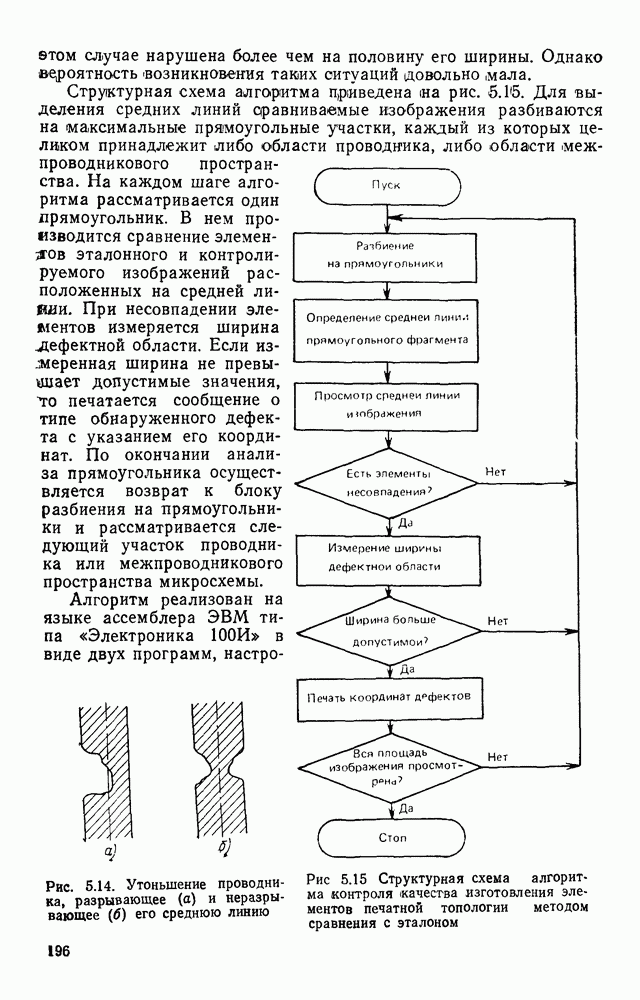
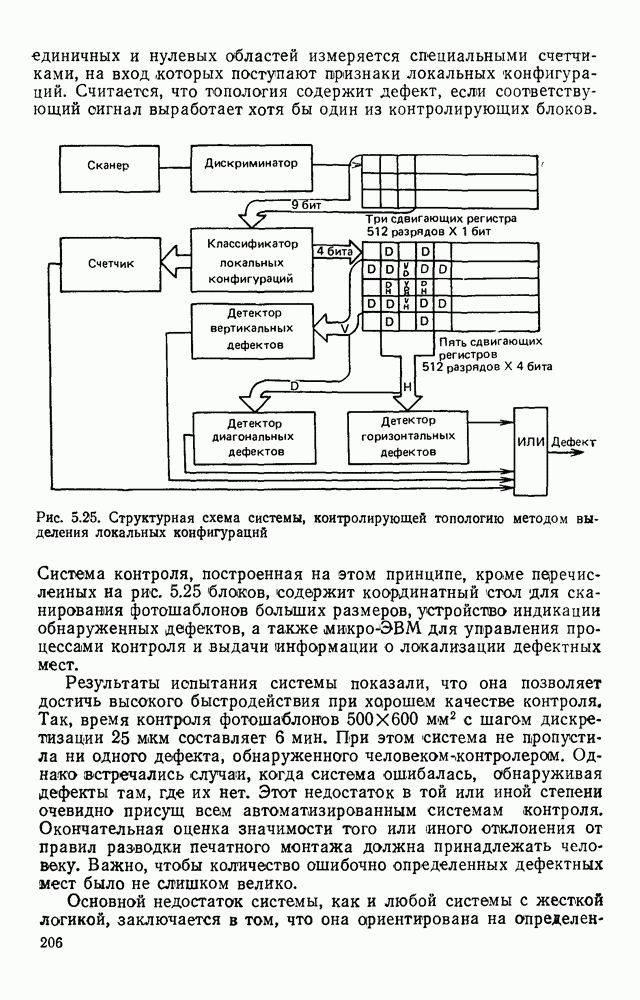
3.3. ОБЩАЯ СТРУКТУРА И ОРГАНИЗАЦИЯ СИСТЕМЫ РАСПОЗНАВАНИЯПопытки применить методы математической лингвистики к задаче анализа изображений приводят к необходимости решить ряд проблем, связанных с отображением двумерной структуры изображения на одномерные цепочки формального языка. В монографии [46] приводится несколько конкретных примеров разрешения этой проблемы. Имея ввиду конкретную задачу — распознавание машинописных и рукописных букв, проанализируем примеры в [46], относящиеся к этой задаче. 1. В качестве непроизводных элементов выбирают сложные элементы, например штрихи (отрезки прямых) — горизонтальные, вертикальные, наклонные, крючки, кривые и т. д. Выявление этих примитивов может оказаться непростой задачей поскольку довольно часто нет четкой границы между, скажем, вертикальной и наклонной линией (например, в рукописных символах). Еще сложнее отличить кривые линии от наклонных и т. д., особенно учитывая ограниченные размеры растра. Использование в качестве непроизводных элементов определенных областей символа равносильно решению задачи его цейтровки на растре, а сделать это не просто. 2. Непроизводные элементы воспринимаются со значениями их признаков, например для отрезков рассматривается признак «толщина», или «ширина». Вряд ли стоит напоминать, что толщина линий, даже относительная, существенно зависит от условий написания. 3. При выборе как примитивов, так и отношений между ними (правил композиции) совершенно не учитывают вопросы технической реализации соответствующей распознающей системы. На первый взгляд может показаться, что эти вопросы не имеют существенного значения, поскольку методы ориентированы на использование универсальной ЭВМ. Однако необходимо помнить, что практические системы распознавания букв и цифр, называемые читающими машинами (автоматами), предназначены для скоростного ввода информации в ЭВМ, и время распознавания одного символа является для них чрезвычайно существенным техникоэкономическим показателем. Практические системы обработки изображений на ЭВМ с традиционной архитектурой должны учитывать, что информация, представленная на двумерном растре, обрабатывается в машине пословно, т. е. в лучшем случае, когда длина машинного слова это позволяет, возможно выполнение операций над отдельными строками или столбцами растра. Этот факт, по-видимому, нельзя не учитывать при выборе непроизводных элементов, если стоит задача разработки быстродействующего устройства или программы. Примеры, рассмотренные в [46], носят экспериментальный характер, поэтому вопросы эффективной технической реализации соответствующих моделей там не рассмотрены. Если говорить о конкретной задаче распознавания букв, то до недавнего времени создавались специализированные устройства, называемые читающими машинами, предназначенные для оптического считывания, распознавания и ввода в ЭВМ буквенно-цифровой информации. Широкое распространение микро-ЭВМ привело к тому, что для решения указанной задачи стало более целесообразно использовать программируемую (микропрограммируемую) ЭВМ, снабженную устройством ввода изображений. Поэтому рассматривая структуру системы для обработки изображений, использующую лингвистический подход (рис. 3.1), мы лишь по традиции выделяем функциональные блоки, как это принято при рассмотрении технических устройств. На самом деле, каждый из указанных блоков является программным (микропрограммным) комплексом (модулем), реализующим соответствующие функции. Блок предварительной обработки осуществляет операции по улучшению изображения путем фильтрации помех в виде мелких изолированных пятнышек, ликвидации так называемой бахромы, мелких пробелов (пустот) внутри линий-раковин и, если необходимо, операции утоньшения линий. Более подробно вопросы предобработки рассматриваются в следующем параграфе.
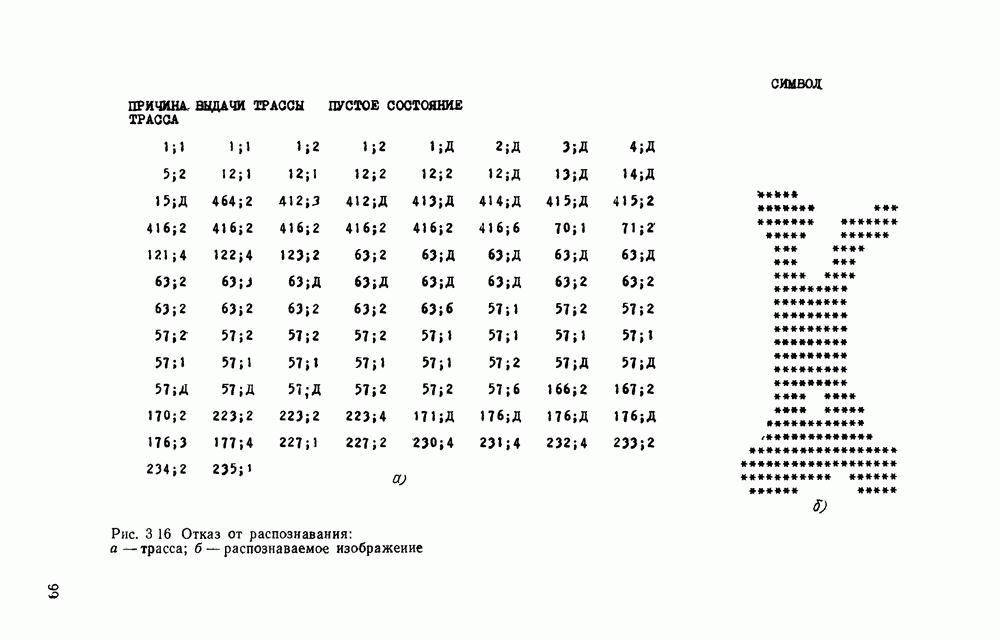
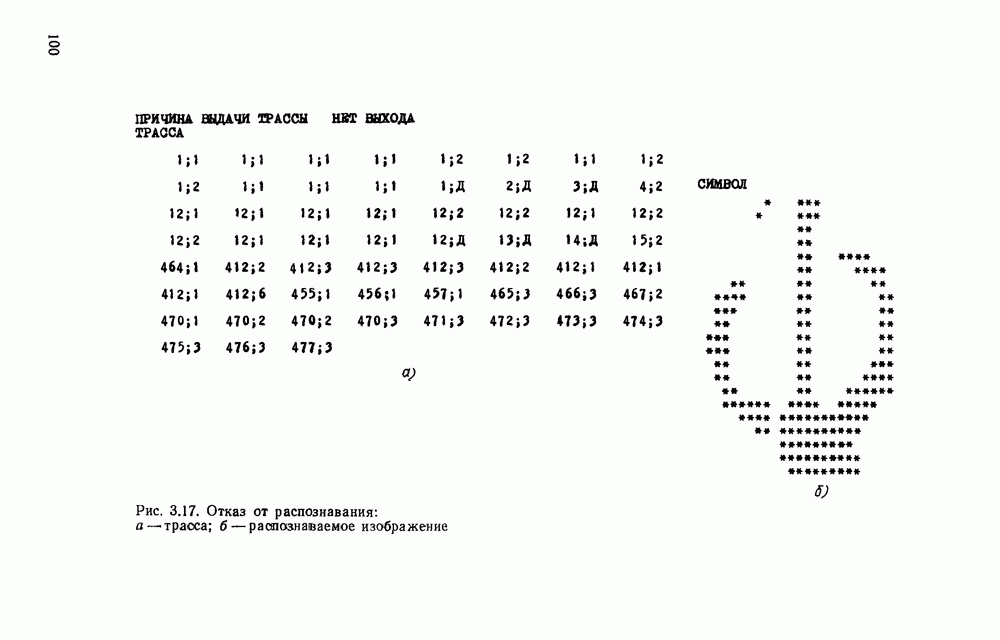
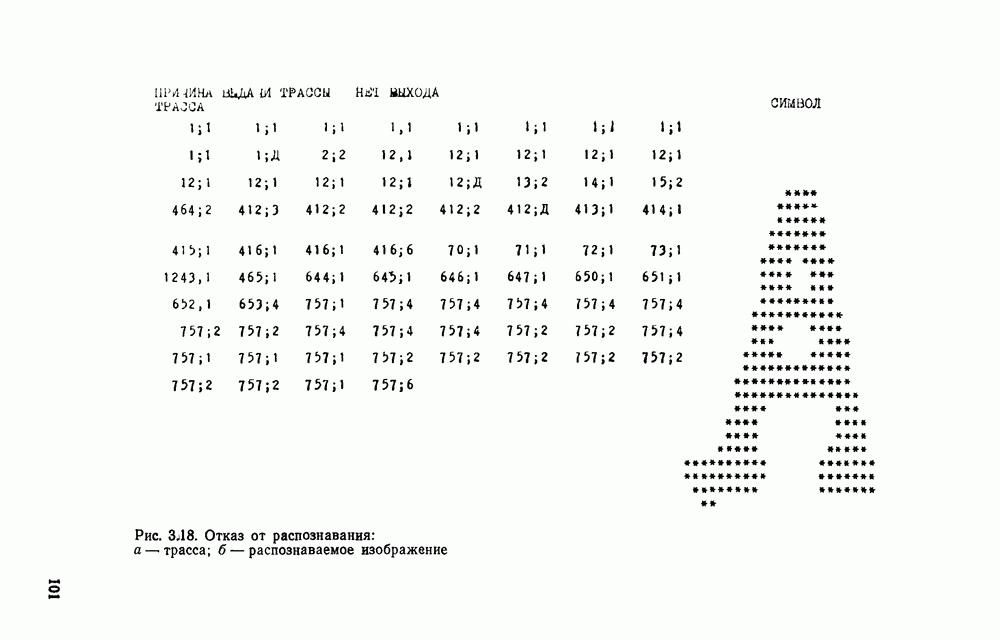
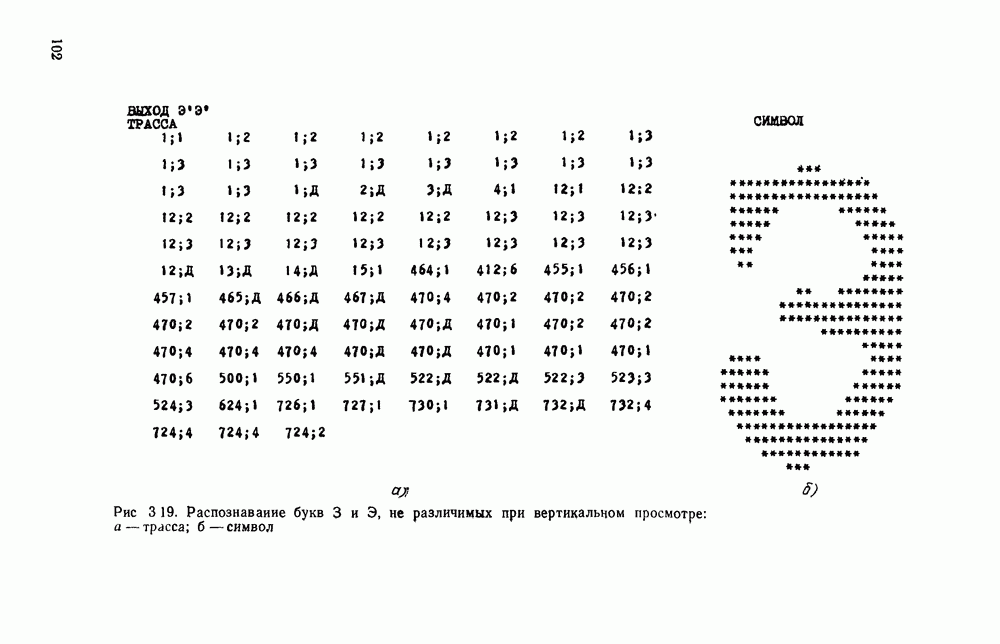
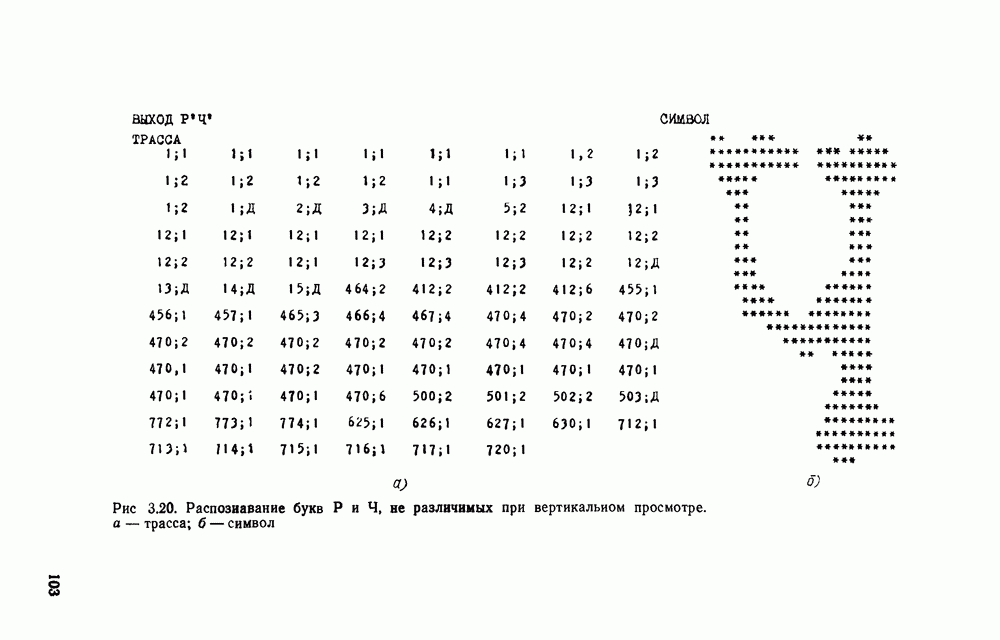
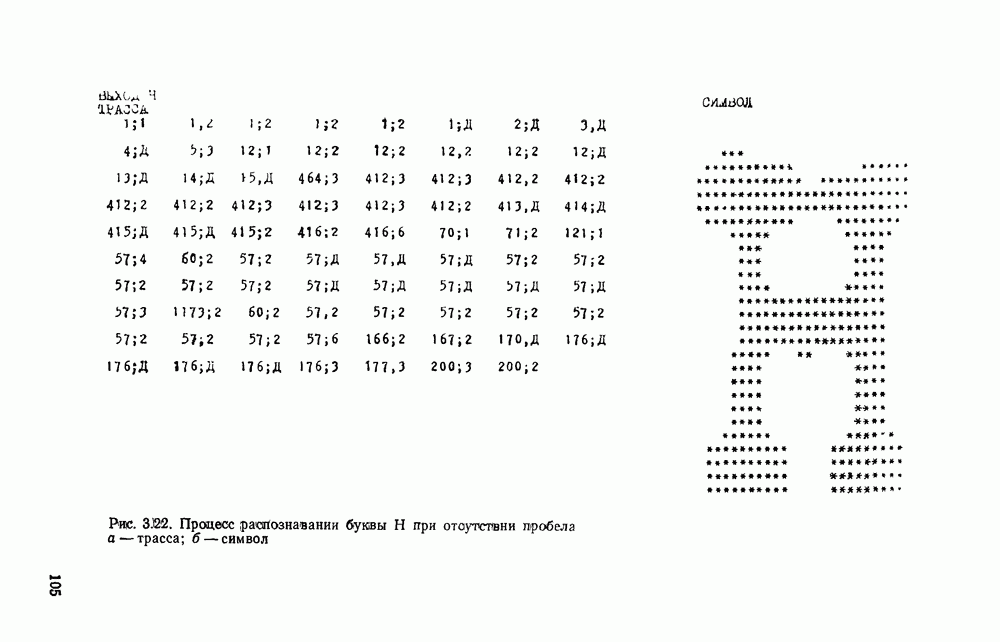
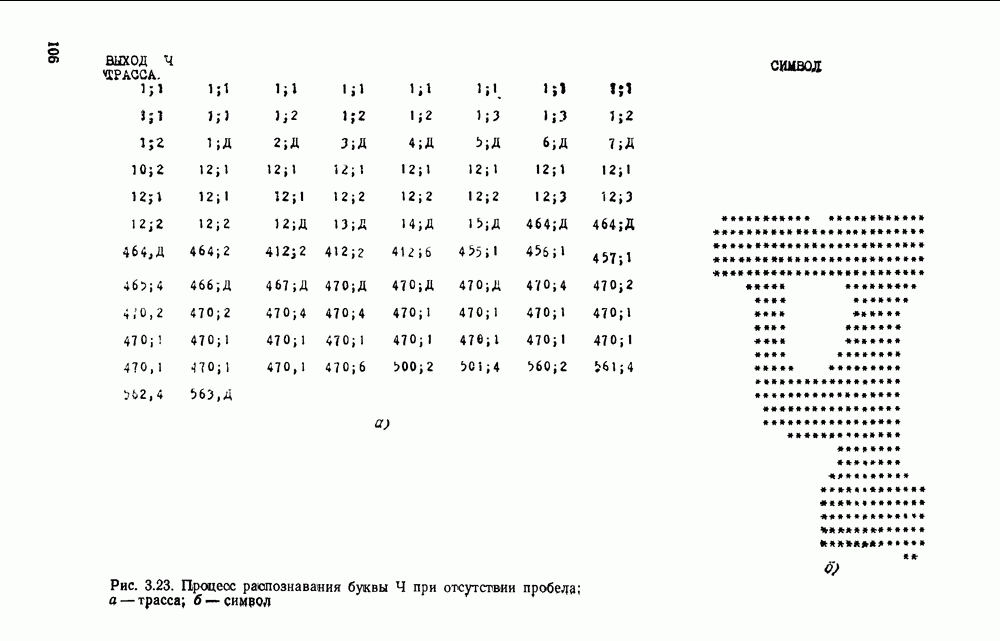
Рис. 3.1 Структурная схема распознающего устройства Каждый подвергнутый предобработке объект должен затем быть представлен в виде структуры языкового типа, например цепочки. Этот процесс состоит, во-первых, из сегментации и, во-вторых, из выделения непроизводных элементов. Другими словами, объект разделяется на части и каждая выделенная часть, в свою очередь, идентифицируется относительно заданного множества непроизводных элементов и определенных синтаксических операций. Например, если задана операция конкатенации, то каждый объект представляется цепочкой примыкающих непроизводных элементов. Выполнение этой функции возлагается на специальный блок, называемый дискриминатором. Он выдает решение о том, является ли представление объекта синтаксически правильным, т. е. принадлежит ли он одному из образов, на распознавание которых система настроена, принимается ли блоком, который мы называли координатором. Основной задачей координатора естественно является задача классификации, однако в зависимости от конкретной предметной области на него могут возлагаться и более широкие функции, например указание, к какому из образов ближе всего распознаваемый объект. Наиболее простой формой распознавания служит сравнение с эталоном. Цепочка непроизводных элементов, представляющая распознаваемый объект, сравнивается с цепочками непроизводных элементов, представляющих каждый эталонный образ [4]. Решение принимается в пользу того образа, для которого будет достигнуто наилучшее в некотором смысле согласование одной из эталонных цепочек с цепочкой, выданной дискриминатором. Процесс получения множества эталонных цепочек для каждого образа осуществляется блоком вывода грамматики, позволяющим восстановить их по заданному множеству изображений, называемому обучающей последовательностью. Этот процесс аналогичен процессу обучения в традиционных схемах распознавания. В приложении к задаче распознавания машинописных и стилизованных буквенноцифровых символов в целях экономии оборудования более предпочтительной оказывается построчная или постолбцовая обработка, при которой в каждый момент производится преобразование информации в одной или нескольких (но не во всех!) строках (столбцах) растра. Такой подход в какой-то мере аналогичен последовательному выполнению операций в вычислительных машинах. Если изображение считать разбитым на строки и столбцы, то представляется естественным сопоставление каждой строке (столбцу) некоторого символа (буквы алфавита А), характеризующего некоторым образом информацию этой строки (столбца) и возможно нескольких соседних с ней строк (столбцов). Тогда весь растр размерами 1. В качестве основного алфавита 2. Произвольному изображению 3. Изображение, получающееся из изображения 4. Правила подстановки определим следующим образом:
Как легко убедиться, определенная таким образом грамматика является грамматикой с конечным числом состояний. Каждому изображению на растре, а значит, и «аждому распознаваемому символу она сопоставляет цепочку в алфавите А. Множество таких цепочек образует язык с конечным числом состояний. Проведенное построение соответствует случаю, когда буквы алфавита А сопоставляются строкам и столбцам растра. Ясно, что аналогичным образом может быть построена порождающая грамматика, при которой буквы алфавита А сопоставляются другим частям того же растра, например паре строк, «окну» размерами
|
 |
Оглавление
|





































































































































































































 (удобнее брать именно квадратные растры) может быть отображен в слово длиной
(удобнее брать именно квадратные растры) может быть отображен в слово длиной  в алфавите А. Сделаем это следующим образом.
в алфавите А. Сделаем это следующим образом.
 возьмем алфавит
возьмем алфавит 
 на растре сопоставим символ а.
на растре сопоставим символ а.
 путем отбрасывания первых I строк и t столбцов растра, назовем
путем отбрасывания первых I строк и t столбцов растра, назовем  изображением. Каждому из
изображением. Каждому из  -изображений сопоставим символы
-изображений сопоставим символы  и каждому из
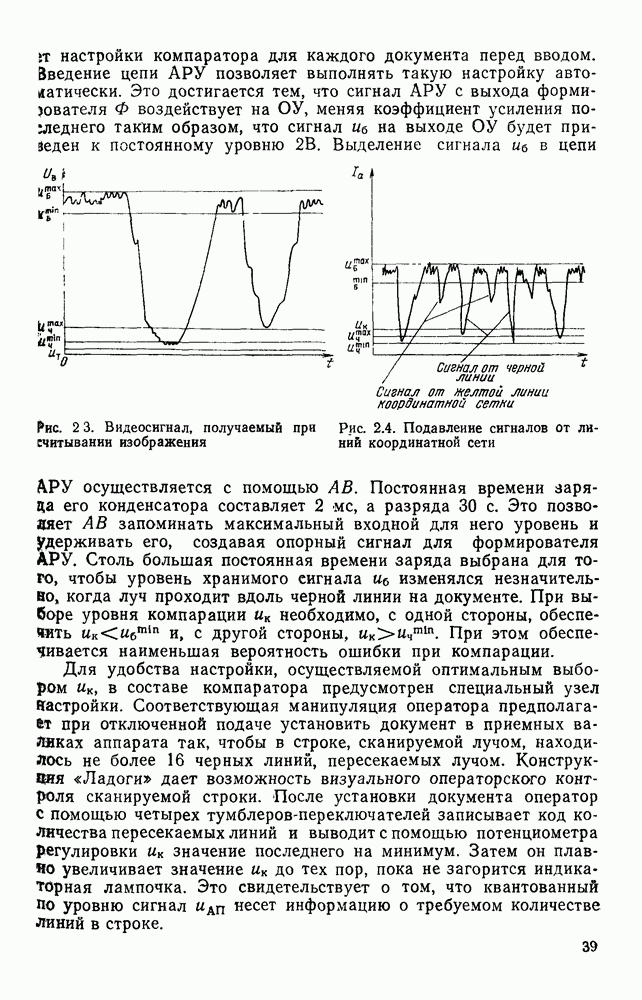
и каждому из  изображений сопоставим символы
изображений сопоставим символы  Символы
Символы  включим в алфавит VV Таким образом,
включим в алфавит VV Таким образом, 

 или
или  элемента и т. д.
элемента и т. д.