Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
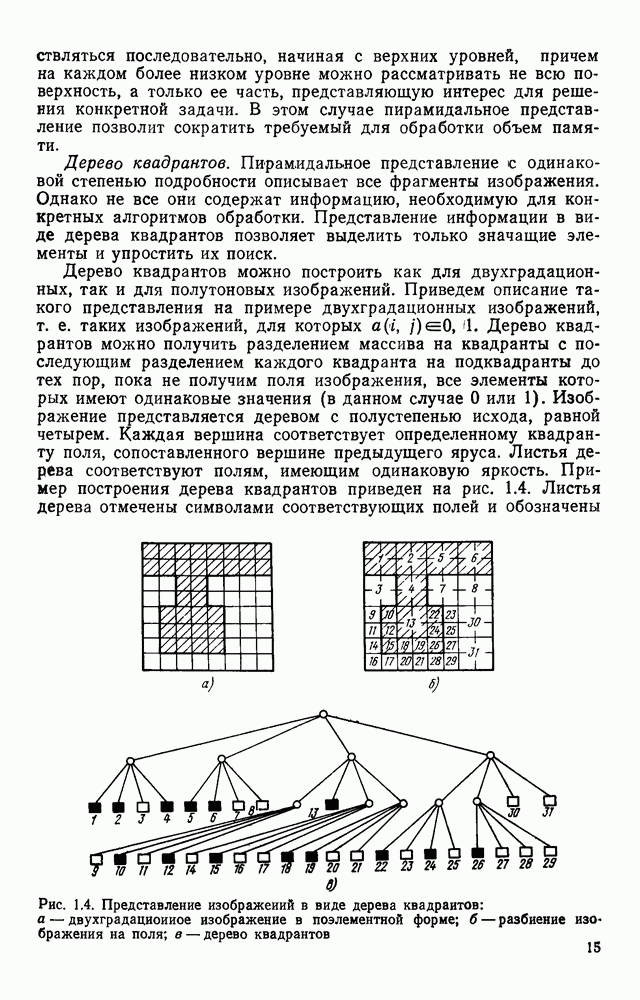
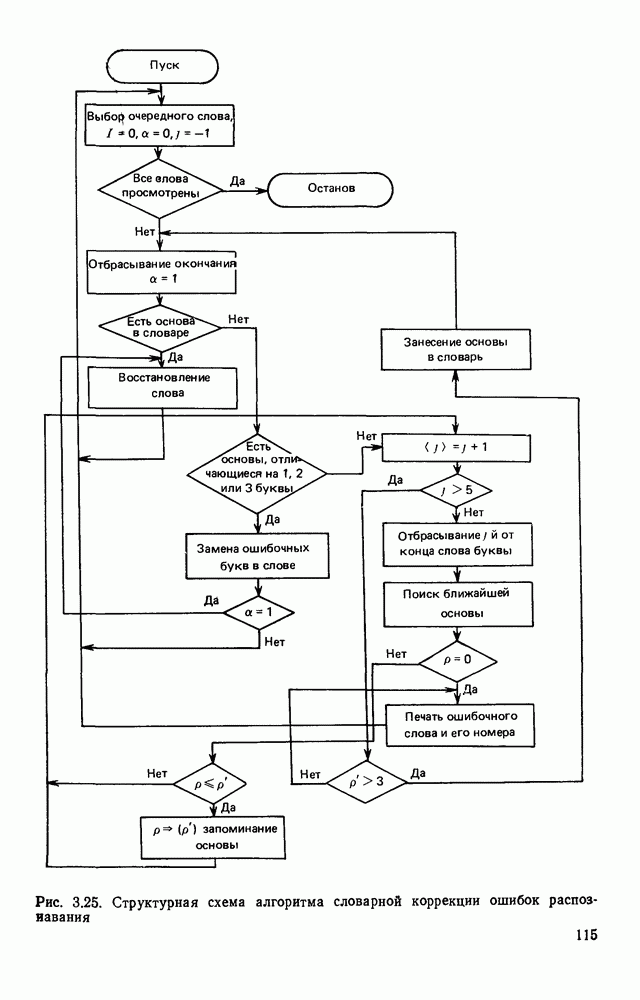
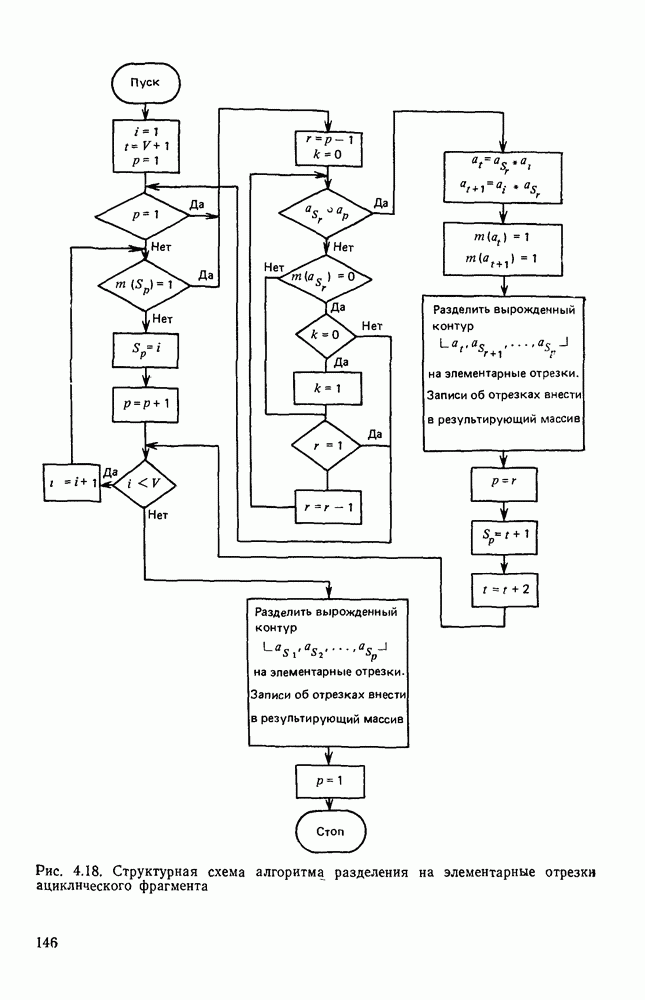
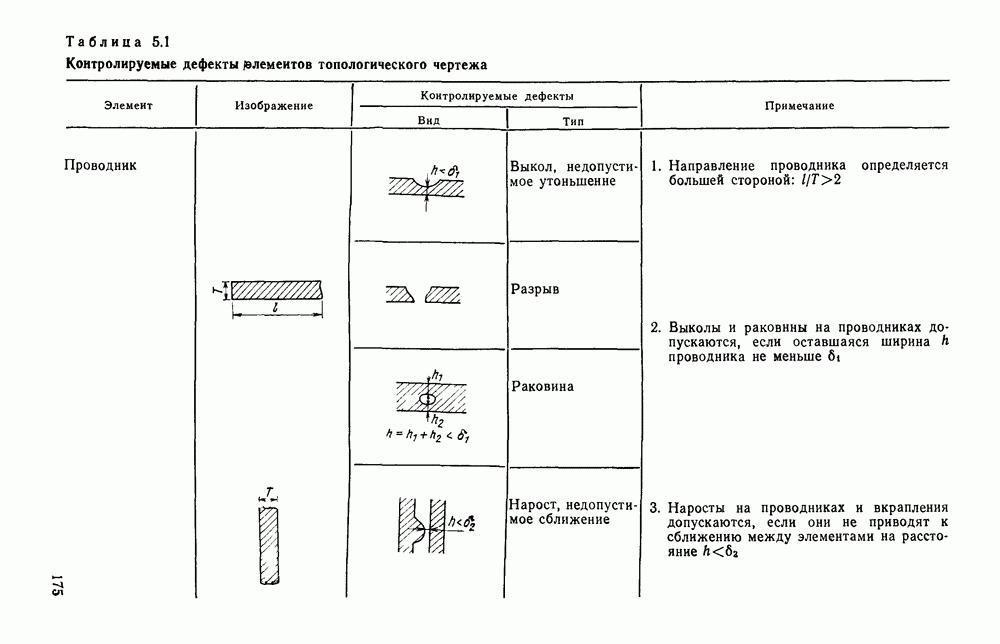
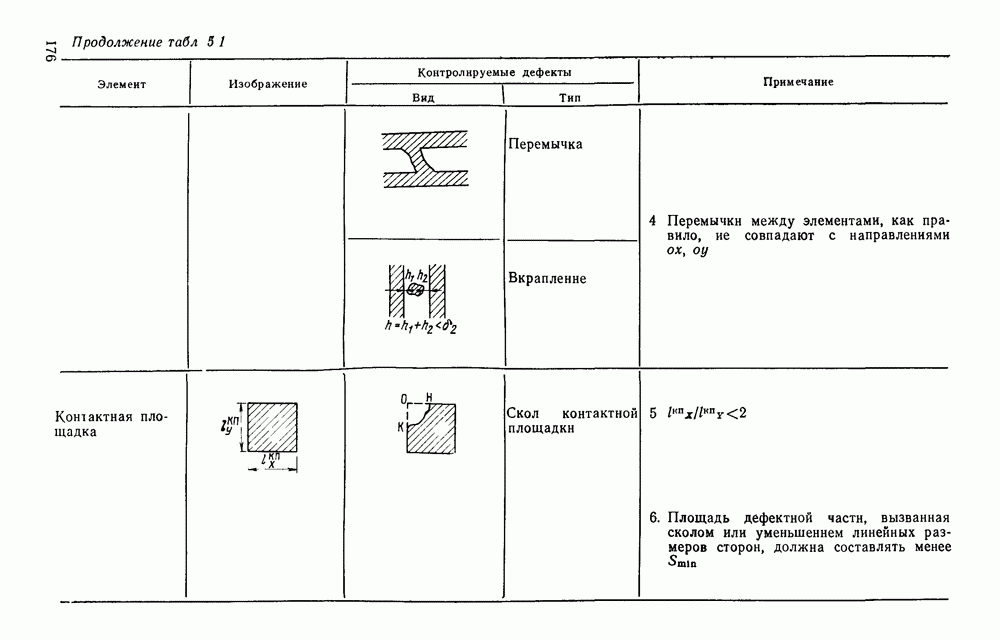
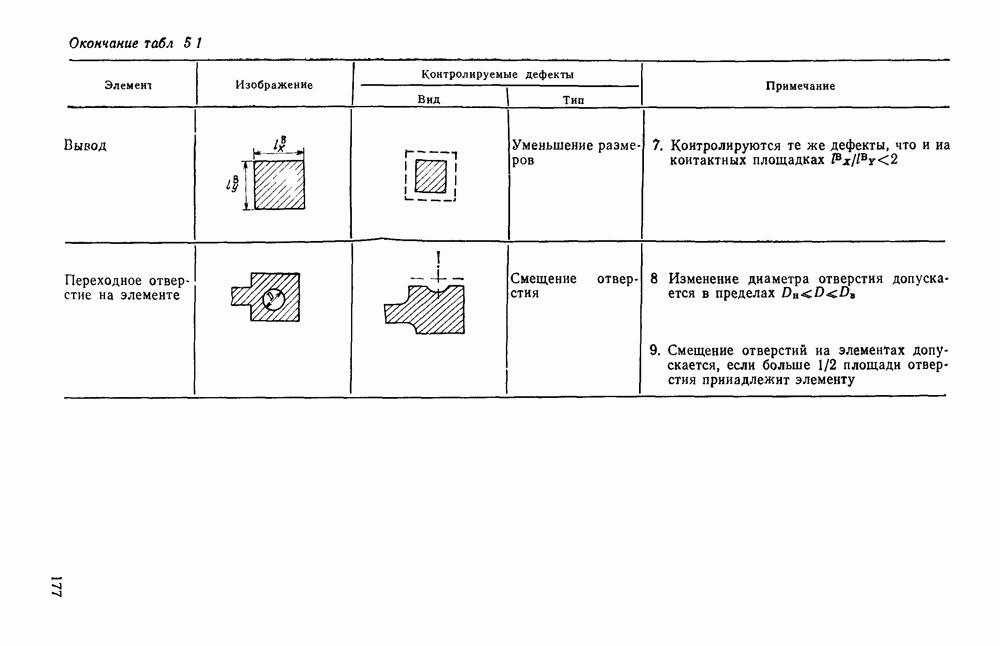
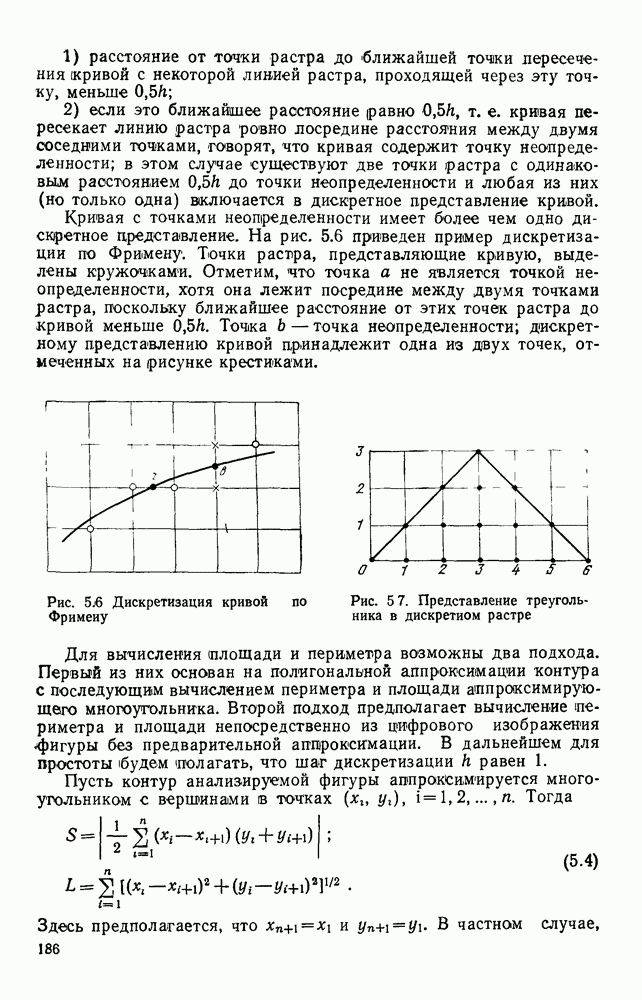
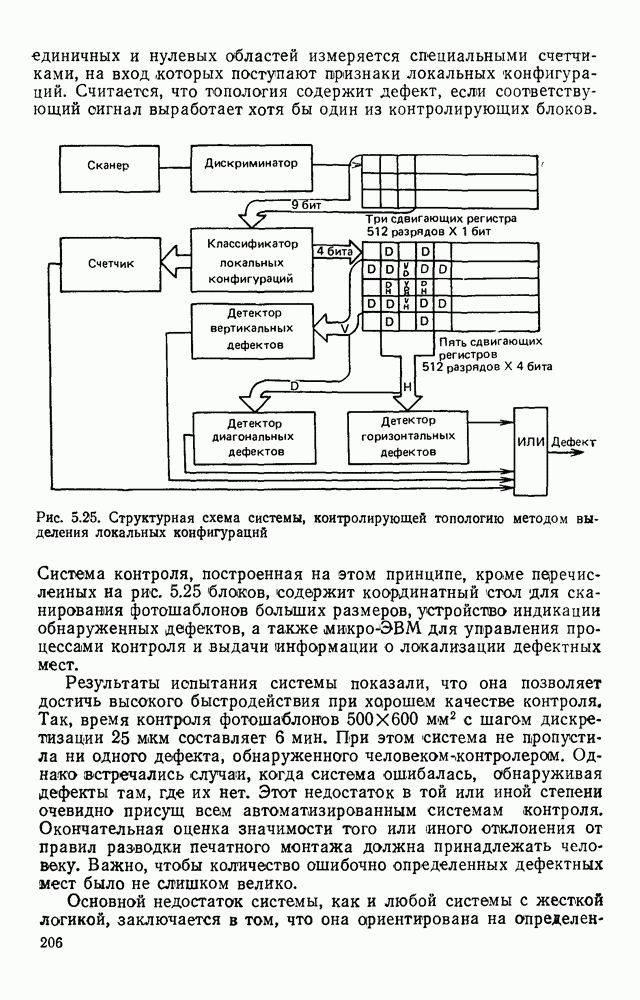
1.4. КОДИРОВАНИЕ ДВУХГРАДАЦИОННЫХ ИЗОБРАЖЕНИЙВ двухградационном (или бинарном) представлении изображений каждый отсчет поля с некоторой пороговой величиной Заслуживает внимания использование двухградационных способов представления изображений и в тех случаях, когда необходимо различать уровни серого, если объект обработки неподвижен и имеется возможность вводить в ЭВМ одну и ту же картину несколько раз, управляя порогом и границами области ввода. В этих случаях для обработки изображений можно использовать иерархическую процедуру последовательного уточнения деталей только тех участков изображения, которые содержат существенную для решения поставленной задачи информацию. Аналогичный подход обсуждался в § 1.3 при описании способов представления изображений в виде пирамиды или дерева квадрантов. Отличие здесь заключается в том, что при переходе от одного уровня иерархического описания изображений к другому изменяется не масштаб представления, а порог Переходя к обсуждению проблемы сжатия, отметим, что все решения, которые используются в случае многоградационных изображений, в принципе пригодны и для двухградационных. Однако специфика бинарных изображений находит свое выражение в некоторой модификации способов сжатия или даже в разработке особых кодов, которые не могут применяться для представления многоградационных изображений. Наиболее часто для представления двухградационных изображений используют методы кодирования длинами серий, блочные коды и векторные коды. Кодирование длинами серий.Кодирование длинами серий базируется на представлении каждой строки растра в виде последовательности длин кодовые слова имеют одинаковую длину, т. е. Для получения оценок коэффициента сжатия примем, что каждая строка изображения представляет собой марковскую цепь первого порядка с переходными вероятностями
где Формула (1.10) выведена в предположении, что для кодирования длин единичных и нулевых серий используются различные коды, учитывающие особенности распределения вероятностей длин серий разного цвета. За счет этого приема удается увеличить коэффициент сжатия информации в среднем на результате статистического анализа изображений, то может оказаться, что Кодирование двухградационных изображений длинами серий достаточно широко изучено и отражено в литературе. Известен код Хаффмена, построенный на основании анализа большого числа изображений и позволяющий закодировать любую длину серии вплоть до максимальной, содержащей 1728 отсчетов. Такой код дает возможность получить близкий к теоретическому пределу коэффициент сжатия, но весьма сложен в реализации. В связи с этим были разработаны более простые модифицированные коды Хаффмена [41], в которых за счет небольшого уменьшения коэффициента сжатия упрощаются процессы кодирования и декодирования. С помощью таких кодов изображение сжимается в среднем в 5—7 раз. Для увеличения коэффициента сжатия за счет учета межстрочной корреляции рассматриваются схемы совместного кодирования нескольких строк растра. Такие методы кодирования получили название двумерных в отличие от одномерных, в которых каждая строка кодируется независимо от остальных. Известны двумерные коды, основанные на предсказании значений элементов изображения, на представлении изображения в виде четырехцветных серий, соответствующих четырем возможным комбинациям белого и черного цветов в соседних строках, на переупорядочении элементов текущей строки в зависимости от значения предыдущей и некоторые другие. В большинстве случаев такие методы на определенном этапе сводятся к кодированию длин серий изображения, преобразованного так, чтобы статистика длин серий позволяла получить большие значения коэффициента сжатия информации. Более подробное описание таких методов кодирования с соответствующим теоретическим анализом можно найти в [38]. Отметим, что неравномерные коды предназначены в основном для передачи информации. При обработке изображений на ЭВМ требуется многократное считывание и преобразование растра в целом или отдельных его фрагментов. Каждое считывание одного элемента изображения, представленного длинами серий, требует декодирования по крайней мере одной строки. Сам процесс декодирования предполагает побитную обработку закодированной строки для выделения кодовых слов и расшифровку их по таблице кодирования. Если учесть, что кодовая таблица даже модифицированного кода Хаффмена содержит около двухсот кодовых слов, длина которых изменяется от одного до тринадцати бит, та сложность обработки представленных таким образом изображений становится очевидной. Поэтому неравномерные коды длин серий для представления изображений в ЭВМ практически не используются. Кодирование длин серий кодовыми словами, имеющими одинаковую длину, позволяет существенно упростить процедуру декодирования. Пусть кодовое слово содержит с двоичных разделов. Если
Для типичных документов Код 1. Один из с двоичных разрядов кодового слова выделяется под представление цвета серии. Оставшиеся Код 2. Все с разрядов кодового слова отводятся под представление длины серии в двоичном позиционном коде. Серии длиной больше Код 3. Кодовое слово имеет формат, аналогичный используемому в коде 1. Информационные поля соседних Блочное кодирование.Суть метода состоит в том, что весь растр разбивается на прямоугольные блоки размером кодом Хаффмана. Однако из-за трудностей кодирования и декодирования на практике этот код не применяют. Вместо него используют субоптимальные коды. Анализ большого числа факсимильных изображений показал, что наиболее вероятной конфигурацией, представленной блоком, является конфигурация, состоящая исключительно из нулевых элементов. Этой конфигурации сопоставляется кодовое слово «0». Кодовые слова других конфигураций образуются из двоичных разрядов, соответствующих блоку, которым предшествует префикс «1». Пример такого кодирования приведен на рис. 1.6. Такой способ кодирования получил название кодирования с пропуском белого [60]. Пусть вероятность того, что блок размером
а коэффициент сжатия определяется формулой
Если
Подставив (1.14) в (1.13), получим в явном виде зависимость коэффициента сжатия от размеров блока. Анализ этой функции показал, что она имеет слабо выраженный максимум в точке
Рис. 1.6. Блочное кодирование: а — двухградационное изображение в поэлементной форме; б — разбиение изображения на блоки; в — блочный код с пропуском белого Для изображений некоторого класса коэффициент сжатия может быть увеличен, если особый код выделить и для представления блоков, состоящих только из единичных элементов. Например, известен код, в котором нулевые блоки кодируются словом «0», единичные — словом «10», а остальные - В блочных кодах и в неравномерных способах кодирования длинами серий возникает задача выделения множества слов, представляющих заданную строку растра. В принципе задача разделения множества кодовых слов на подмножества, описывающие строки, может быть решена на основе использования следующего правила: каждое такое подмножество содержит кодовые слова, в совокупности в точности представляющие Можно предложить другое решение этой проблемы. Для представления изображений используются два массива. Один из них, названный информационным (ИМ), содержит множество кодовых слов, представляющих растр. Этот массив делится на подмассивы, описывающие отдельные строки. Если несколько соседних строк имеют одинаковое значение, то в массиве ИМ они представляются одним подмассивом. Кроме того, из ИМ исключается описание однородных строк, т. е. строк, состоящих только из единичных или только из нулевых элементов. Информационный массив снабжается массивом указателей (УМ). В этом массиве каждой Пример такого кодирования представлен на рис. 1.7. Исходное изображение приведено на рис. 1.6. Указатели нулевых строк на рис. 1.7 обозначены символом «0», а единичных — «1». Строки
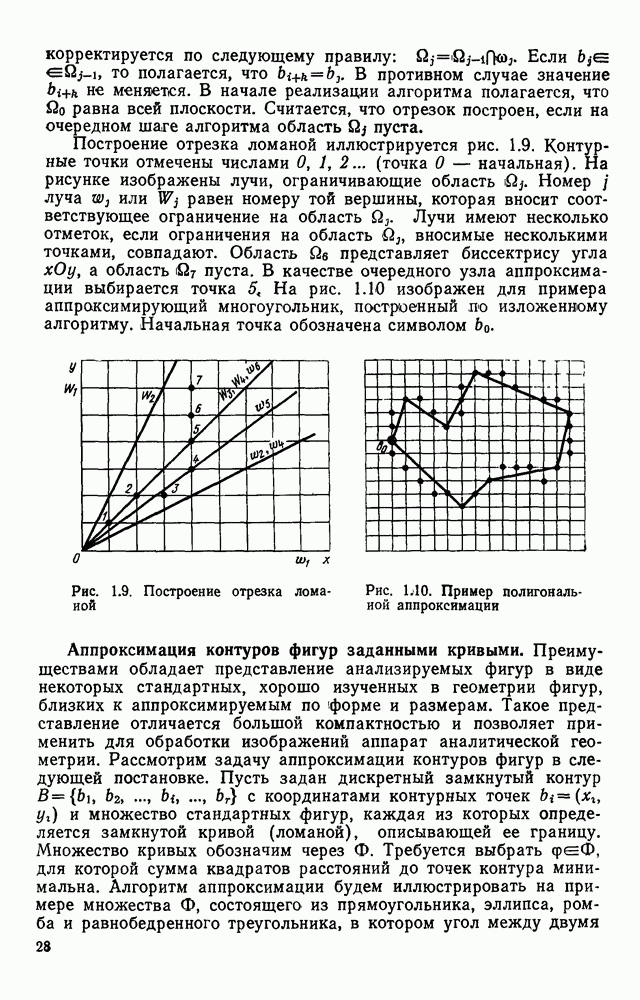
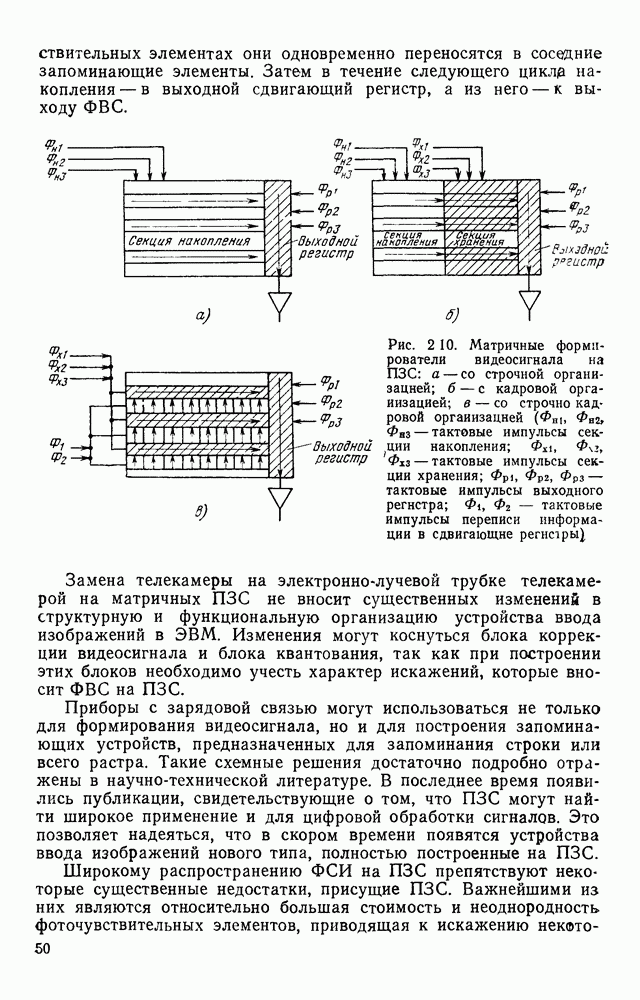
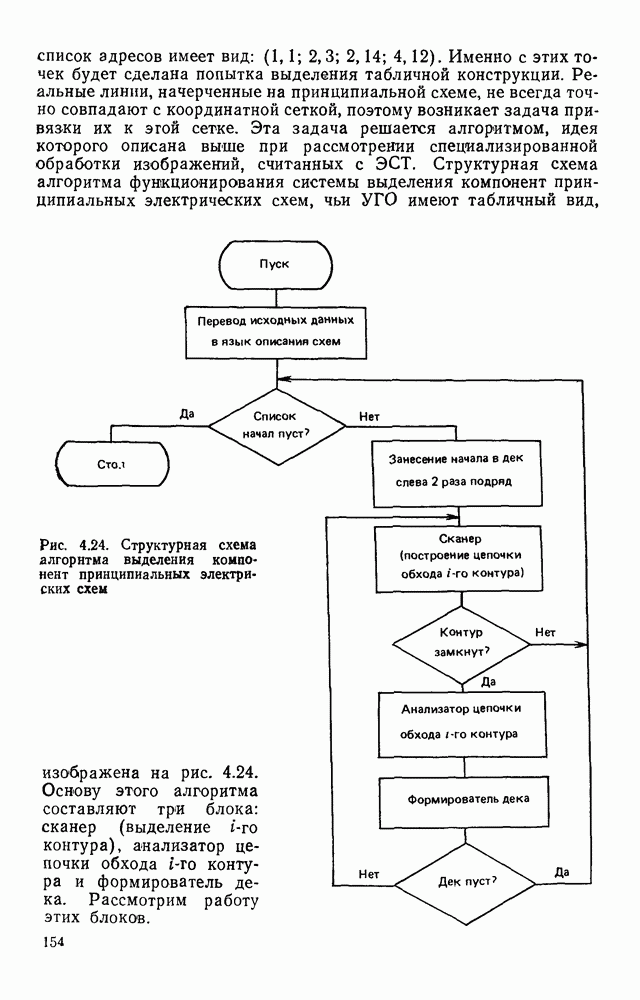
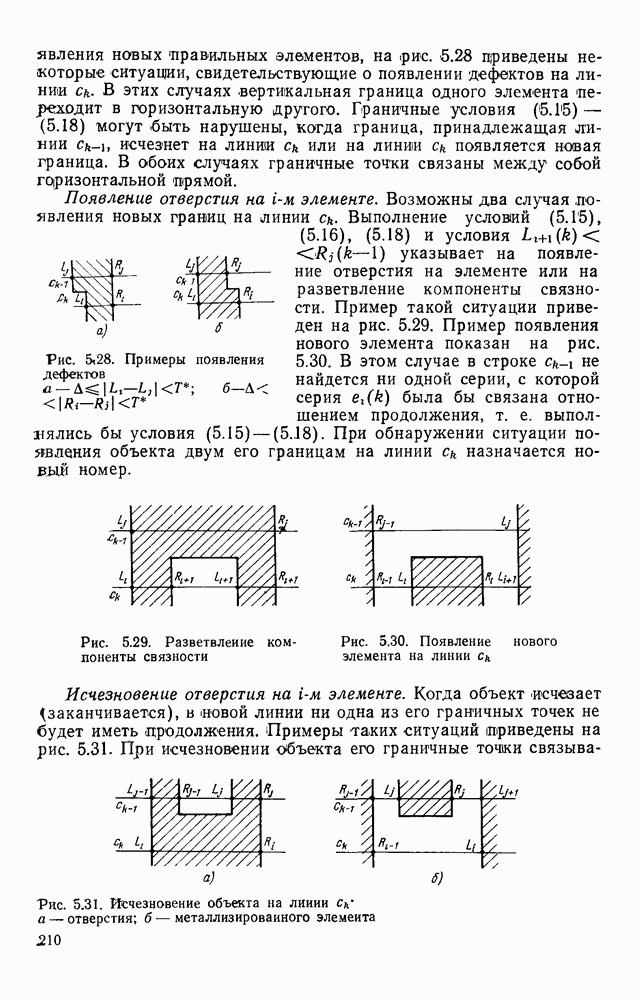
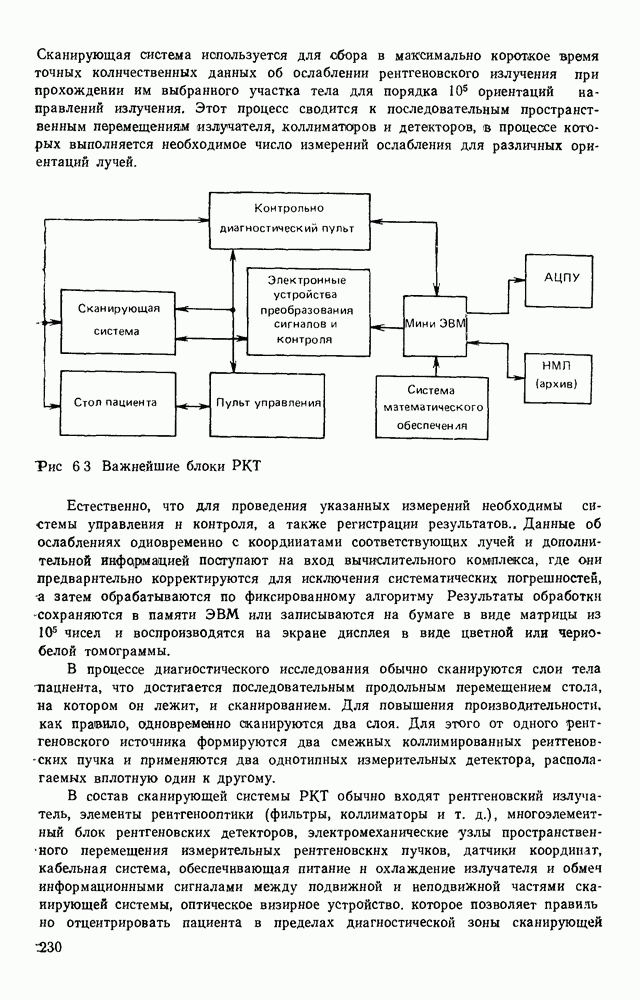
Рис. 1.7. Представление изображения в виде двух массивов представлены в матричной форме, хотя здесь можно применить любой способ кодирования длинами серий или блоками. Представление изображений двумя массивами позволяет легко обращаться к любой строке растра на основе использования косвенной адресации. Кроме того, несмотря на дополнительный массив УМ, суммарный объем памяти, требуемый для представления изображений, уменьшается за счет исключения из ИМ описания некоторых строк. Коэффициент сжатия, получаемый с помощью такого кодирования, достаточно строго не исследован. В предварительных испытаниях на примере представления топологии печатного монтажа применение такого способа кодирования приводило к сокращению требуемого объема памяти приблизительно в 3 раза. Отметим, что можно предложить относительно простые технические решения, в которых массивы УМ и ИМ формируются аппаратно на выходе устройства ввода визуальной информации без дополнительных затрат времени по сравнению с другими способами кодирования. Например, в телевизионных устройствах ввода указатели могут быть сформированы и записаны в память ЭВМ во время обратного хода луча. Именно требованием простоты аппаратной реализации обусловлен тот факт, что в массиве ИМ одним подмножеством представляются не все одинаковые строки растра, а только те, которые следуют непосредственно один за другим. Некоторые схемные решения этого класса обсуждаются в гл. 2. Векторное кодирование.В [39] был предложен метод кодирования двухградационных изображений, ориентированный в основном для представления чертежей. Метод получил название векторного кодирования. Особенность технических чертежей заключается в том, что содержащаяся в них информация может быть удобно представлена в виде набора линий. Метод векторного кодирования предполагает, что каждая такая линия аппроксимируется ломаной. Отрезки аппроксимирующей ломаной получили название векторов. Каждый вектор задается свеими граничными точками и шириной, характеризующей ширину аппроксимируемой линии. Метод выделения вектора рассчитан на его реализацию в процессе растрового сканирования чертежей в реальном масштабе времени без промежуточного хранения данных. В процессе векторного кодирования на чертеже выделяются фигуры (линии). Каждая фигура состоит из нескольких единичных серий на последовательных линиях сканирования. Принадлежность серий одной фигуре определяется сравнением соседних строк растра. Считается, что две серии в соседних строках растра принадлежат одной фигуре, если расстояние между соответствующими (левыми и правыми) границами этих серий не превышает заданное значение (например, три элемента). Принадлежность серии некоторой фигуре отмечается с помощью специальных меток. Разметка каждой строки растра делается на основании разметки предшествующей строки в процессе их сравнения. Когда образуется новый вектор, координаты левой границы серии на начальной линии сканирования считаются координатами начала вектора, а его ширина — равной длине серии. Для каждого вектора ведется счет составляющих его серий. Говорят, что вектор закончен, если число сосчитанных серий достигнет порогового значения (скажем, пяти). В качестве координат конца вектора запоминаются координаты левой границы последней серии. После формирования каждого нового вектора его угол наклона сравнивается с углом наклона предшествующего ему вектора, принадлежащего той же фигуре. Если эти углы отличаются не более чем на заданное значение, то из двух векторов формируется один большей длины. Рисунок 1.8 иллюстрирует процесс векторизации.
Рис. 1.8. Представление изображения в векторной форме: а — представление кривой в виде единичных серий; б — выделение отрезков ломаной; в — результат объединения нескольких отрезков в один Векторное кодирование позволяет сжать изображение приблизительно в 40 раз. Такая форма представления удобна для обработки чертежей, внесения в описание изменений, отображения результатов на дисплее. Однако при таком способе кодирования происходит потеря информации, т. е. после векторного кодирования полностью восстановить исходное матричное представление невозможно. Собственно за счет потери информации и достигается высокий коэффициент сжатия. Применительно к техническим чертежам теряемая в процессе векторизации информация является несущественной. Если объект и цели обработки иные, векторная форма представления изображений может оказаться недостаточно подробной. Обсуждению некоторых более точных методов аппроксимации фигур посвящен следующий параграф.
|
 |
Оглавление
|




































































































































































































 принимает значение 0 или 1. Все множество оттенков серого условно делится на два цвета: черный, которому соответствуют единичные отсчеты, и белый, которому соответствуют нулевые отсчеты. Квантование видеосигнала сводится к сравнению его амплитуды в каждой точке рецепторного
принимает значение 0 или 1. Все множество оттенков серого условно делится на два цвета: черный, которому соответствуют единичные отсчеты, и белый, которому соответствуют нулевые отсчеты. Квантование видеосигнала сводится к сравнению его амплитуды в каждой точке рецепторного
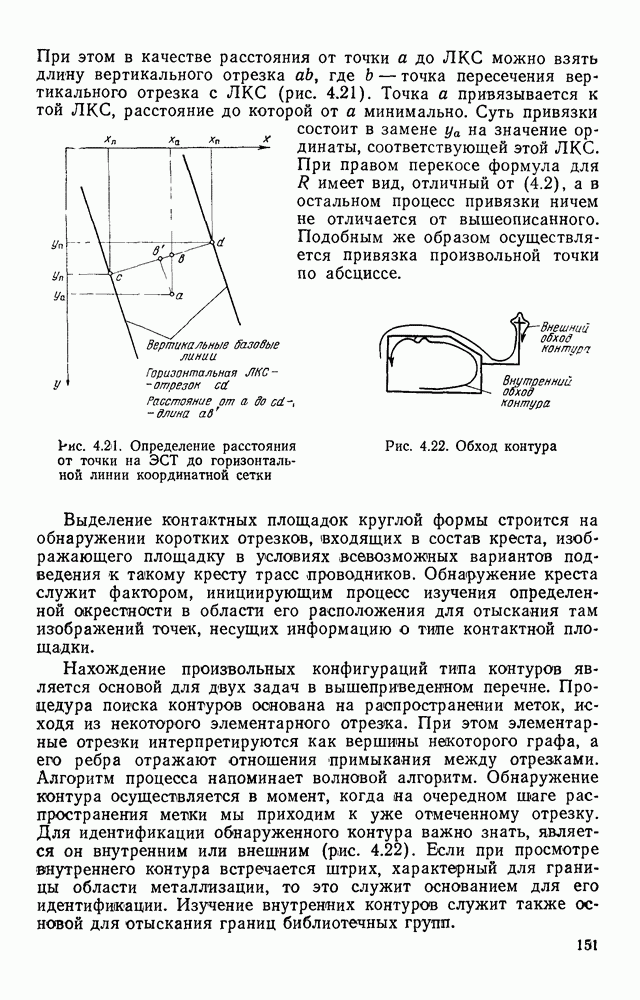
 . При использовании матричного кодирования двухградационные отсчеты плотно упаковываются в слова машинной памяти так, что для представления каждого отсчета отводится один двоичный разряд слова. Совершенно очевидно, что такой способ представления обладает большей компактностью по сравнению с полутоновым. Но он обладает и еще одним существенным преимуществом — возможностью параллельной обработки нескольких отсчетов, записанных в одном машинном слове, с помощью поразрядных логических операций. Эти преимущества обусловили широкое применение двухградационного представления изображений в тех случаях, когда такое представление обеспечивает достаточную степень подробности описания объектов. Например, такое представление используется при обработке документов типа схем, карт, чертежей в робототехнических системах промышленного зрения и в некоторых других применениях.
. При использовании матричного кодирования двухградационные отсчеты плотно упаковываются в слова машинной памяти так, что для представления каждого отсчета отводится один двоичный разряд слова. Совершенно очевидно, что такой способ представления обладает большей компактностью по сравнению с полутоновым. Но он обладает и еще одним существенным преимуществом — возможностью параллельной обработки нескольких отсчетов, записанных в одном машинном слове, с помощью поразрядных логических операций. Эти преимущества обусловили широкое применение двухградационного представления изображений в тех случаях, когда такое представление обеспечивает достаточную степень подробности описания объектов. Например, такое представление используется при обработке документов типа схем, карт, чертежей в робототехнических системах промышленного зрения и в некоторых других применениях.
 с помощью которого оттенки серого цвета разделяются на черные и белые. Впрочем, можно изменять и масштаб представления, управляя частотой дискретизации. Технически управление порогом квантования, частотой дискретизации и границами области ввода осуществляется достаточно просто. Некоторые схемные решения этого класса обсуждаются в гл. 2.
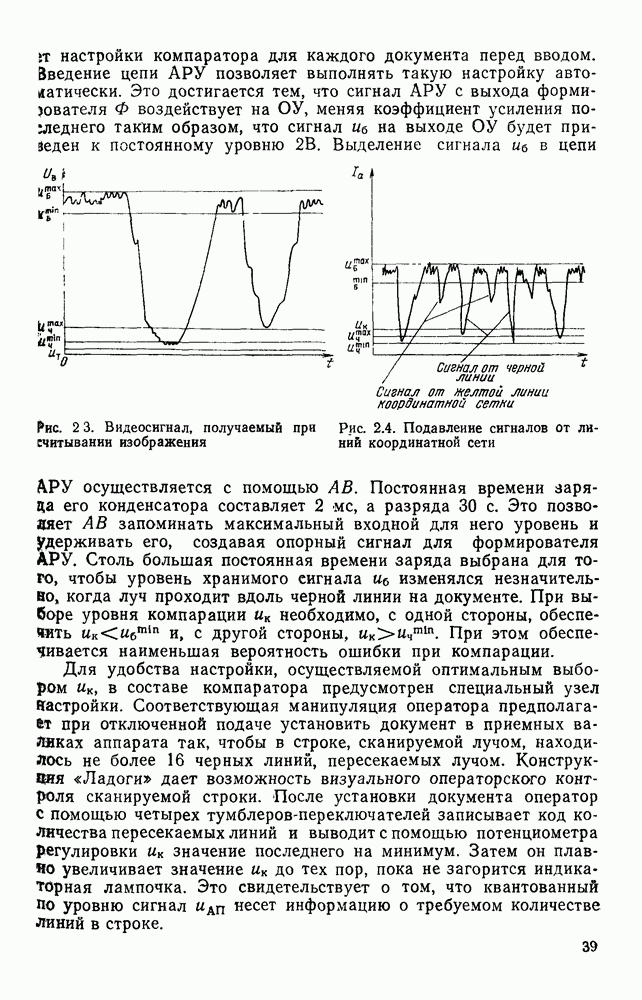
с помощью которого оттенки серого цвета разделяются на черные и белые. Впрочем, можно изменять и масштаб представления, управляя частотой дискретизации. Технически управление порогом квантования, частотой дискретизации и границами области ввода осуществляется достаточно просто. Некоторые схемные решения этого класса обсуждаются в гл. 2.
 составляющих эту строку нулевых и единичных серий. При этом каждое число U представляется определенным кодовым словом, содержащим
составляющих эту строку нулевых и единичных серий. При этом каждое число U представляется определенным кодовым словом, содержащим  двоичных разрядов. Если
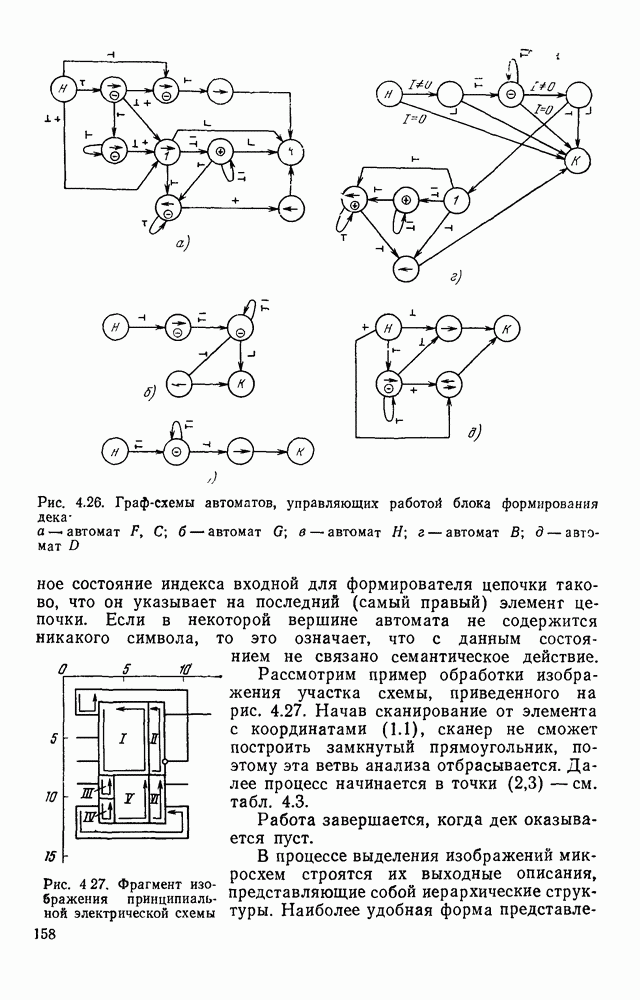
двоичных разрядов. Если
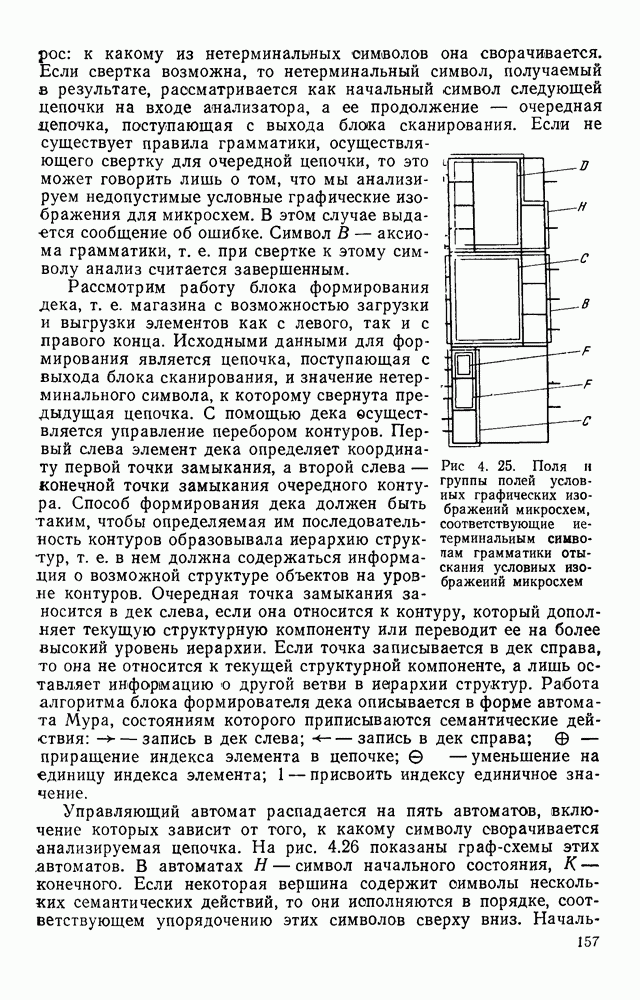
 , то код называется равномерным; в противном случае — неравномерным. Так как в бинарном изображении возможны всего два цвета серий (нулевой и единичный), в кодовом слове цвет серии можно в явном виде не указывать. Наибольшего сжатия информации позволяют достичь неравномерные коды. В частности, для представления длин серий широко используют префиксный код Хаффмена. В префиксных кодах ни одно из кодовых слов не может быть начальной частью (префиксом) другого. Свойство префиксности позволяет определять границы кодовых слов без использования каких-либо граничных меток. Если известно начало
, то код называется равномерным; в противном случае — неравномерным. Так как в бинарном изображении возможны всего два цвета серий (нулевой и единичный), в кодовом слове цвет серии можно в явном виде не указывать. Наибольшего сжатия информации позволяют достичь неравномерные коды. В частности, для представления длин серий широко используют префиксный код Хаффмена. В префиксных кодах ни одно из кодовых слов не может быть начальной частью (префиксом) другого. Свойство префиксности позволяет определять границы кодовых слов без использования каких-либо граничных меток. Если известно начало  кодового слова, то его конец (и, следовательно, начало (i+1)-го кодового слова) определяется на минимальном расстоянии от начала так, чтобы двоичное слово, расположенное между этими двумя границами, содержалось в словаре кодовых слов.
кодового слова, то его конец (и, следовательно, начало (i+1)-го кодового слова) определяется на минимальном расстоянии от начала так, чтобы двоичное слово, расположенное между этими двумя границами, содержалось в словаре кодовых слов.
 Здесь
Здесь  обозначает вероятность того, что некоторый элемент изображения принимает значение i при условии, что предыдущий элемент имеет значение
обозначает вероятность того, что некоторый элемент изображения принимает значение i при условии, что предыдущий элемент имеет значение  Подставив в
Подставив в  получим, что коэффициент сжатия двухградационных изображений равен
получим, что коэффициент сжатия двухградационных изображений равен  где l — среднее количество бит, используемое для представления одного отсчета. Максимальный теоретически достижимый предел а можно получить, положив I равной энтропии
где l — среднее количество бит, используемое для представления одного отсчета. Максимальный теоретически достижимый предел а можно получить, положив I равной энтропии  элемента изображения. Для марковской последовательности первого порядка в соответствии с
элемента изображения. Для марковской последовательности первого порядка в соответствии с  . С другой стороны, при кодировании длинами серий величина I должна удовлетворять неравенству
. С другой стороны, при кодировании длинами серий величина I должна удовлетворять неравенству

 — средние длины единичных и нулевых серий;
— средние длины единичных и нулевых серий;  — энтропии длин единичных и нулевых серий.
— энтропии длин единичных и нулевых серий.
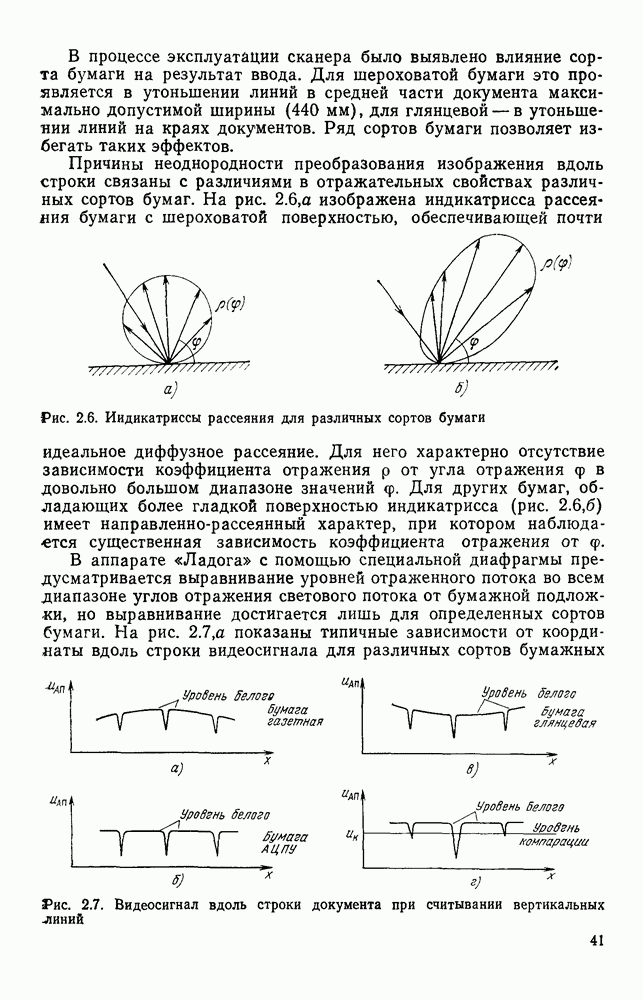
 Распределение вероятностей длин серий может быть получено, исходя из статистической модели, описывающей последовательность отсчетов. В частности, если распределение длин серий соответствует рассматриваемой цепи Маркова, то
Распределение вероятностей длин серий может быть получено, исходя из статистической модели, описывающей последовательность отсчетов. В частности, если распределение длин серий соответствует рассматриваемой цепи Маркова, то  . Другими словами, кодирование длинами серий позволяет в принципе достичь максимально возможного сжатия информации за счет учета статистической зависимости между отсчетами. Естественно, что не всякий способ кодирования длинами серий приводит к такому сжатию информации, U — теоретический предел, который можно достичь на этом пути. Если распределение длин серий получено эмпирически в
. Другими словами, кодирование длинами серий позволяет в принципе достичь максимально возможного сжатия информации за счет учета статистической зависимости между отсчетами. Естественно, что не всякий способ кодирования длинами серий приводит к такому сжатию информации, U — теоретический предел, который можно достичь на этом пути. Если распределение длин серий получено эмпирически в
 . Дополнительное сжатие информации можно получить в случае, когда рассматриваемый класс изображений отличается от модели — цепи Маркова первого порядка.
. Дополнительное сжатие информации можно получить в случае, когда рассматриваемый класс изображений отличается от модели — цепи Маркова первого порядка.
 где n — число отсчетов в строке, то одно кодовое слово позволит закодировать длину любой серии, принадлежащей строке. В этом случае коэффициент сжатия
где n — число отсчетов в строке, то одно кодовое слово позволит закодировать длину любой серии, принадлежащей строке. В этом случае коэффициент сжатия

 с» 10 (данные взяты из [23]). Подставив эти значения в (1.11), получим
с» 10 (данные взяты из [23]). Подставив эти значения в (1.11), получим  , т. е. составляет приблизительно половину теоретически достижимого предела. Коэффициент сжатия можно увеличить за счет оптимального выбора с. Вообще практический интерес представляют такие значения с, при которых
, т. е. составляет приблизительно половину теоретически достижимого предела. Коэффициент сжатия можно увеличить за счет оптимального выбора с. Вообще практический интерес представляют такие значения с, при которых  где s — длина машинного слова,
где s — длина машинного слова,  целое. В этих условиях чаще всего и возникает задача кодирования серий, длина которых превышает
целое. В этих условиях чаще всего и возникает задача кодирования серий, длина которых превышает  . Приведем несколько подходов к решению этой задачи.
. Приведем несколько подходов к решению этой задачи.
 разрядов образуют информационное поле, которое используется для представления длины t серии. Таким образом, одно кодовое слово позволяет закодировать серии длиной от 1 до
разрядов образуют информационное поле, которое используется для представления длины t серии. Таким образом, одно кодовое слово позволяет закодировать серии длиной от 1 до  включительно. Серии, имеющие длину больше
включительно. Серии, имеющие длину больше  искусственно разбиваются на
искусственно разбиваются на  серий с длинами
серий с длинами  каждая из которых представляется отдельным кодовым словом.
каждая из которых представляется отдельным кодовым словом.
 разбиваются на минимальное число
разбиваются на минимальное число  серий, длина каждой из которых не превосходит
серий, длина каждой из которых не превосходит  Для разделения длинных серий на части используют фиктивные серии нулевой длины, которые представляются отдельными кодовыми словами, имеющими нулевые значения.
Для разделения длинных серий на части используют фиктивные серии нулевой длины, которые представляются отдельными кодовыми словами, имеющими нулевые значения.
 кодовых слов с одинаковыми разрядами цвета серии объединяются с помощью операции конкатенации. Составленное таким образом
кодовых слов с одинаковыми разрядами цвета серии объединяются с помощью операции конкатенации. Составленное таким образом  разрядное слово представляет длину серии в двоичном позиционном коде. Код 3 приводит к более компактному по сравнению с кодом 1 представлению информации, но он менее удобен в алгоритмах обработки изображений. Все три кода дают возможность выбрать в зависимости от статистических свойств изображения оптимальное значение с, при котором коэффициент сжатия а достигает максимума. Анализ показал, что для изображений широкого класса с помощью таких способов можно построить достаточно эффективные коды с коэффициентом сжатия, близким к
разрядное слово представляет длину серии в двоичном позиционном коде. Код 3 приводит к более компактному по сравнению с кодом 1 представлению информации, но он менее удобен в алгоритмах обработки изображений. Все три кода дают возможность выбрать в зависимости от статистических свойств изображения оптимальное значение с, при котором коэффициент сжатия а достигает максимума. Анализ показал, что для изображений широкого класса с помощью таких способов можно построить достаточно эффективные коды с коэффициентом сжатия, близким к 
 , где u и v — число элементов соответственно в горизонтальном и вертикальном направлениях. Блоки кодируются в соответствии с вероятностями их появления на изображении. Для достижения наибольшего сжатия целесообразно кодировать блоки неравномерным
, где u и v — число элементов соответственно в горизонтальном и вертикальном направлениях. Блоки кодируются в соответствии с вероятностями их появления на изображении. Для достижения наибольшего сжатия целесообразно кодировать блоки неравномерным
 состоит только из нулевых элементов, равна
состоит только из нулевых элементов, равна  . Тогда средняя длина с кодового слова
. Тогда средняя длина с кодового слова


 т. е. блок принадлежит одной строке, то код называется одномерным, в противном случае — двумерным. Для одномерных кодов, пользуясь моделью марковского процесса, можно записать
т. е. блок принадлежит одной строке, то код называется одномерным, в противном случае — двумерным. Для одномерных кодов, пользуясь моделью марковского процесса, можно записать

 Причем оптимальные размеры блока почти не зависят от статистических характеристик изображения. Коэффициент сжатия при оптимальных размерах блока для одномерных кодов изменяется в пределах от двух до пяти, для двумерных — от четырех до восьми.
Причем оптимальные размеры блока почти не зависят от статистических характеристик изображения. Коэффициент сжатия при оптимальных размерах блока для одномерных кодов изменяется в пределах от двух до пяти, для двумерных — от четырех до восьми.

 -разрядным словом, начинающимся с префикса «11».
-разрядным словом, начинающимся с префикса «11».
 отсчетов. Однако применение этого правила приводит к необходимости всегда начинать процесс декодирования с начала растра, что существенно снижает эффективность многих алгоритмов обработки изображений. В связи с этим часто для разделения строк используются специальные кодовые слова.
отсчетов. Однако применение этого правила приводит к необходимости всегда начинать процесс декодирования с начала растра, что существенно снижает эффективность многих алгоритмов обработки изображений. В связи с этим часто для разделения строк используются специальные кодовые слова.
 строке соответствует указатель
строке соответствует указатель  Этот указатель для однородных строк равен нулю, если строка нулевая, и содержит единицы во всех разрядах, если строка единичная. Если
Этот указатель для однородных строк равен нулю, если строка нулевая, и содержит единицы во всех разрядах, если строка единичная. Если  строка не однородна, то указатель
строка не однородна, то указатель  задает начало подмассива ИМ, сопоставленного этой
задает начало подмассива ИМ, сопоставленного этой  строке.
строке.

