Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
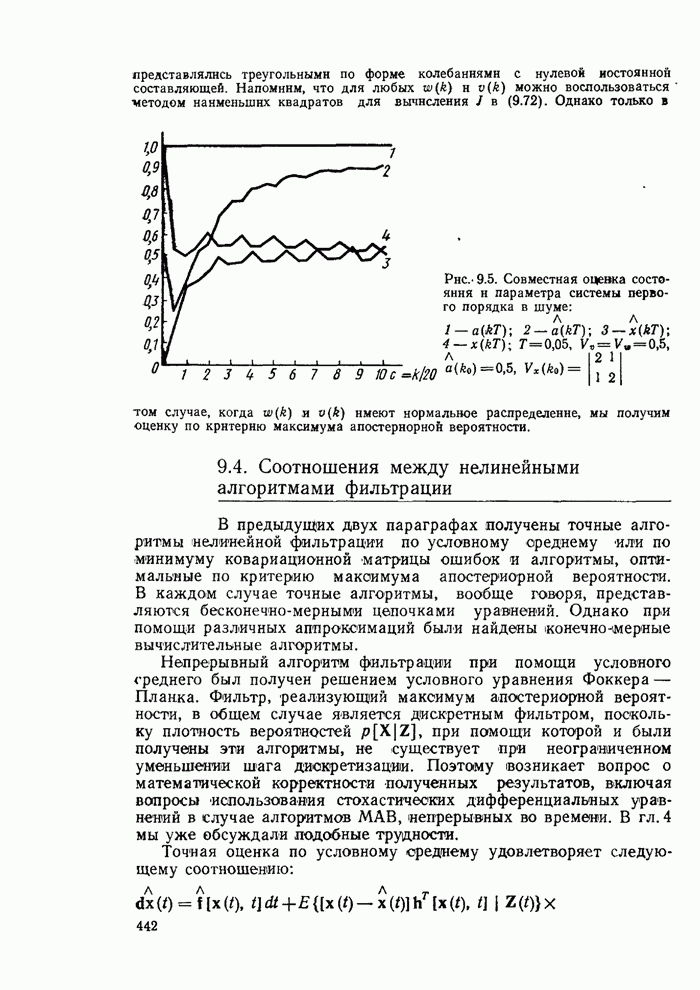
9.4. Соотношения между нелинейными алгоритмами фильтрацииВ предыдущих двух параграфах получены точные алгоритмы нелинейной фильтрации по условному среднему или по минимуму ковариационной матрицы ошибок и алгоритмы, оптимальные по критерию максимума апостериорной вероятности. В каждом случае точные алгоритмы, вообще говоря, представляются бесконечно-мерными цепочками уравнений. Однако при помощи различных аппроксимаций был и найдены конечно-мерные вычислительные алгоритмы.
Непрерывный алгоритм фильтрации
при помощи условного среднего был получен решением условного уравнения Фоккера
— Планка. Фильтр, реализующий максимум апостериорной вероятности, в общем
случае является дискретным фильтром, поскольку плотность вероятностей Точная оценка по условному среднему удовлетворяет следующему соотношению:
которое было получено из уравнения Фоккера-Планка или эквивалентного ему соотношения
где
Эти два соотношения объединяются
теоремой проецирования для» нелинейных непрерывных процессов (
или эквивалентными соотношениями:
где введенный выше оператор условного среднего равен
Линеаризованный фильтр Калмана.
Линеаризованный фильтр Калмана является эвристическим обобщением результатов
ранней работы Калмана и Бьюси [111], рассмотренной в гл. 7, и представляет
собой фильтр с минимумом ковариационной матрицы ошибок, основанный на
линеаризации по заданной траектории. Предположим, что дифференциальное
уравнение заданной траектории
с начальными условиями
Полная оценка состояний равна
где Для удобства сведем алгоритмы линеаризованной фильтрации Калмана в табл. 9.5. Аналогичным образом полученные соответствующие линеаризованные дискретные уравнения фильтрации представлены в табл. 9.6. Таблица 9.5. Линеаризованный фильтр Калмана в непрерывном времени (модели наблюдения и сигнала и априорные данные те же, что и в табл. 9.4)
Таблица 9.6. Дискретный линеаризованный фильтр Калмана (модели сигнала и наблюдения и априорные моменты те же, что и в табл. 9.3)
Расширенный фильтр Калмана. Предполагая,
что оценка по условному среднему известна, можно получить различные алгоритмы
фильтрации в непрерывном времени. Разлагая функции модели сообщения и модели
наблюдения в ряд Тейлора около точки
Сравнивая эти модели сообщения и наблюдения, видим, что в основной модели
Теперь известны входной сигнал и возмущение:
и линеаризованные матричные коэффициенты:
Определение фильтра Калмана тривиально. Используем просто соотношения:
учитывая предыдущее определение
величин Дискретный расширенный фильтр Калмана может быть получен точно так же, как и аналогичный фильтр в непрерывном времени. Он представлен в табл. 9.7. Таблица 9.7. Расширенный дискретный фильтр Калмана (модели сообщения и наблюдения те же, что и в табл. 9.3)
Однако дискретный аналог непрерывного во времени нелинейного фильтра первого порядка получить нельзя. Причиной этого является то обстоятельство, что для дискретных систем не доказана теорема нелинейного проецирования и поэтому нельзя использовать подход с помощью уравнения Фоккера — Планка. Все же при некоторых ограничениях можно получить приближенные конечно-мерные вычислительные алгоритмы, используя уравнение Фоккера — Планка (9.109) или теорему проецирования (9.101). Приближенная дискретная
фильтрация при помощи условного среднего. Используя теоремы об условном
среднем и условной дисперсии, приведенные в гл. 4, можно получить несколько
приближенных алгоритмов фильтрации. Из (4.26) для нормальных случайных величии
Из (9.116) и
находим условное среднее
Учитывая определение моделей сигнала и наблюдения « замечая, что
оценку по условному среднему можно выразить следующим соотношением:
Легко видеть, что член, управляющий процедурой оценивания, представляет «обновляющий» процесс. Однако нужно заметить, что (9.119) есть только приближение в нелинейном случае, так как соотношение (9.116) верно только для нормальных процессов. Используя аналогичную теорему об условной дисперсии [см. (9.117)] и учитывая (9.118), можно получить
Так же как и в предыдущем случае, это выражение верно только для нормальных случайных процессов. В гл. 7 отмечалось, что
поэтому оценка по условному среднему — несмещенная. Кроме того,
откуда следует приближенное соотношение для ковариационной матрицы ошибок фильтрации:
Итак, ур-ния (9.119) и (9.120)
являются приближенными уравнениями дискретной нелинейной фильтрации по
условному среднему и соответствующей ковариационной матрицы ошибок. Для того
чтобы этими алгоритмами можно было пользоваться, необходимо найти выражения
для Приближение первого порядка для
ковариационных матриц может быть получено разложением в ряд Тейлора функций
Теперь используем приближение
первого порядка для
Это дает возможность приближенно вычислить ковариационные матрицы:
Для того чтобы закончить вычисление фильтра первого порядка, необходимо получить выражение для априорной матрицы ошибок, что легко сделать, используя разложение в ряд
В табл. 9.3 приведены алгоритмы фильтрации первого порядка, которые полностью эквивалентны дискретным алгоритмам расширенного фильтра Калмана Интересно, что использование уравнения (9 120) устраняет необходимость применения леммы об обращении матрицы для нахождения эффективной вычислитель I ой формы уравнений для дисперсий. При уменьшении шага дискретизации эти алгоритмы переходят в алгоритмы расширенной фильтрации Калмана в непрерывном времени или в аналогичные алгоритмы фильтрации первого порядка по условному среднему [см табл. 9.1] Заметим также, что эти алгоритмы очень близки к алгоритмам дискретной фильтрации по критерию МАВ (см. табл. 9.3). Аналогичным образам можно
получить приближение второго порядка, удерживая в разложении
Выражения для ковариационных матриц ошибок получаются в предположении, что все третьи моменты равны нулю и, кроме того, используются четвертые моменты нормальной случайной величины. В примере 9.1 рассмотрена процедура вычисления этой величины для непрерывного случая. Однако непосредственное ее использование представляется довольно сложным. Поэтому мы даем в табл. 9.8 лишь результирующие дискретные алгоритмы фильтрации второго порядка по условному среднему. Заметим, что эти уравнения при увеличении частоты дискретизации не переходят в непрерывные алгоритмы табл. 9.2, хотя разница между ними невелика. Таблица 9.8. Дискретные алгоритмы фильтрации второго порядка по условному среднему (модели сообщения и наблюдения и априорные моменты те же, что и в табл. 9.3)
Хотя теорема об условном среднем, примененная к ур-нию (9.119), несправедлива в случае дискретного времени, для нелинейной задачи в непрерывном времени она справедлива. Используем результат одношагового предсказания
и соотношение между дискретной и непрерывной системами [см. (9.63)]:
Тогда при увеличении частоты дискретизации имеем
где символы
где
что легко получить и с помощью теоремы проецирования, вводя эквивалентное определение. Аналогичным образом можно показать, что соотношение для условной ковариационной матрицы в дискретном времени (9.120), по существу, переходит в выражение для ковариационной матрицы из (9.37). Заинтересованный читатель может проделать этот переход в качестве упражнения; действительно, просто показать, что при увеличении частоты дискретизации (9.120) переходит в уравнение
которое аналогично (9.37) Отличие этих двух соотношений содержится в последних членах каждого из них. Можно задать вопрос, почему для
нахождения дискретного расширенного фильтра Калмана мы выбрали метод
линеаризации. Ответ состоит в том, что, разлагая Однако необходимо еще получить
соотношения для нахождения
Легко показать также, что
Подставляя
Теперь желательно получить
выражение для оценки
Вычисленная по этому алгоритму
оценка
которое можно получить
линеаризацией уравнения для модели сообщения около точки Оценка Таблица 9.9. Дискретные итеративные алгоритмы фильтрации по условному среднему
Пример 9.8. Рассмотрим значимость дополнительного управляющего члена уравнения для ковариационной матрицы ошибок и влияние высших порядков малости на фильтр второго порядка с минимальной дисперсией ошибок. Полученные результаты сравним с аналогичными результатами для линеаризованной фильтрации Калмана. Предположим, что модель оценки описывается уравнениями.
где Рассмотрим четыре случая: линеаризованный фильтр Калмана, фильтр второго порядка с минимумом дисперсии, расширенный фильтр Калмана и фильтр, оптимальный по критерию максимума апостериорной вероятности. Соответствующие этим случаям уравнения имеют следующий вид: 1. Фильтр по критерию МАВ, основанный на методе инвариантного погружения:
2. Расширенный фильтр Калмана или фильтр первого порядка с минимумом дисперсии:
3. Фильтр второго порядка по минимуму дисперсии:
4. Линеаризованный фильтр Калмана:
Если алгоритмы фильтрации в непрерывном времени реализовываются на ЭВМ, то должна быть проведена дискретная аппроксимация. Не оставляя в стороне стохастическую интерпретацию, которая должна быть дана приближенным уравнением фильтрации, можно показать, что вполне приемлемой является ступенчатая аппроксимация непрерывных функций. Если в рассматриваемом примере применить этот способ, то получаются следующие дискретные алгоритмы фильтрации: 1. Фильтр инвариантного погружения по критерию МАВ:
2. Расширенный фильтр Калмана или фильтр первого порядка с минимумом дисперсии:
3.Фильтр второго порядка с минимумом дисперсии:
4. Линеаризированный фильтр Калмана:
В качестве первого шага
предположим, что распределение шумов полностью известно, а исходные параметры
равны:
Рис. 9.6. Фильтрация с известными априорными данными: 1 – нелинейные фильтры; 2 – линеаризованный фильтр Калмана
Рис. 9 7. Дисперсия ошибки фильтрации с известными априорными данными (получена решением приближенных уравнений для ковариационной матрицы ошибок)
Рис 9 8. Фильтрация при неполных априорных данных: 1 — расширенный фильтр Калмана; 2 — линеаризованный фильтр Калмана; 3 — метод инвариантного погружения и фильтр второго порядка по минимуму дисперсии. Графики приближенной дисперсии ошибок приведены на рис. 9.7. Заметим, что для всех трех фильтров они идентичны. На втором этапе предположим, что
истинные значения
Рис. 9.9. Дисперсии ошибок при неполных априорных данных: 1 — фильтр МАВ и фильтр второго порядка; 2 — расширенный фильтр Калмана. Снова видно, что нелинейные оценки существенно лучше оценок, даваемых линеаризованным фильтром Калмана. Более того, в случае априорной неопределенности поучителен тот факт, что добавочный управляющий член в фильтре инвариантного погружения по критерию МАВ и использование членов высших порядков малости в уравнениях фильтрации по минимуму дисперсии обеспечивают лучшую чувствительность в слежении за траекторией на отрезке быстрого изменения переменной состояния. Приближенные дисперсии ошибок представлены на рис. 9.9. Таблица 9.10. Алгоритмы первого порядка вычисления отношения правдоподобия (используются все алгоритмы табл. 9.7 и даваемые ниже)
Пример 9.9. Для того чтобы показать, как дискретные алгоритмы фильтрации по условному среднему можно применить для построения последовательных алгоритмов отношения правдоподобия, необходимо вернуться к некоторым выводам § 5.7. Если объединить дискретные алгоритмы из табл. 9.7 с ур-ниями (5.180) и (5.181), то получим алгоритмы, приведенные в табл. 9.10, для приближенного (первого порядка) отношения правдоподобия. Конечно, в случае необходимости можно использовать алгоритмы второго порядка или алгоритмы одношаговой итерационной фильтрации для получения отношения правдоподобия [209]. Рассмотрим задачу обнаружения случайного фазомодулированного сигнала на фоне аддитивного нормального шума. Приемник выбирает одну из гипотез
где
Рис 9 10
Последовательное обнаружение Верна Используя алгоритмы первого порядка из табл. 9.6, получим (все соотношения даны в форме, пригодной для цифровых методов реализации):
Для того чтобы осуществить
последовательную процедуру обнаружения, логарифм отношения правдоподобия
Если Приведенные алгоритмы проще всего
реализовывать на ЭВМ, при этом как последовательное обнаружение, так и обнаружение
при фиксированном объеме выборки могут быть проведены для различных наборов
параметров. Результаты для некоторых случаев приведены на рис. 9.10-9.13. Здесь
Рис 9 11.
Последовательное обнаружение. Отношение сигнал/шум равно 6 дБ. Девиация частоты
30%. В табл. 9.11 представлены различные варианты значений параметров, при которых решалась задача обнаружения, а на рисунках представлены выборочные значения логарифма отношения правдоподобия для различных случаев. Таблица 9.11 содержит также значения отношений правдоподобия для проверки гипотез при фиксированном объеме выборки, равном 25. Номера на кривых совпадают с номерами в соответствующей колонке таблицы. Из приведенных данных видно, что во всех случаях, когда последовательное обнаружение происходит неверно, обнаружение при фиксированном объеме выборки происходит безошибочно: значения отношения правдоподобия «перекрыты». Из рис 9.11 видно также, что для опыта № 3 ошибка была допущена при фиксированной выборке, в то время как последовательная процедура прошла безошибочно.
Рис. 9.12.
Последовательное обнаружение. Отношение сигнал/шум равно 0 дБ. Девиация частоты
60%.
Рис. 9.13
Последовательное обнаружение. Отношение сигнал/шум равно 6 дБ. Девиация частоты
60%. Таблица 9.11. Логарифм отношения правдоподобия при фиксированной
выборке. Гипотеза
|
 |
Оглавление
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||










































































































































































































































































































































































































































































































 ;
;  . (9.106)
. (9.106)












 (9.108)
(9.108)
 (9.109)
(9.109)
 (9.
112)
(9.
112)
 (9.113)
(9.113)







 (9.121)
(9.121)
 (9.122)
(9.122)
 (9.123)
(9.123)
 (9 124)
(9 124)
 (9.125)
(9.125)
 (9.126)
(9.126)
 (9.127)
(9.127)
 (9.128)
(9.128)
 (9.129)
(9.129)









 (9.132)
(9.132)
 (9
133)
(9
133)
 (9.135)
(9.135)















 .
.
 ;
;




