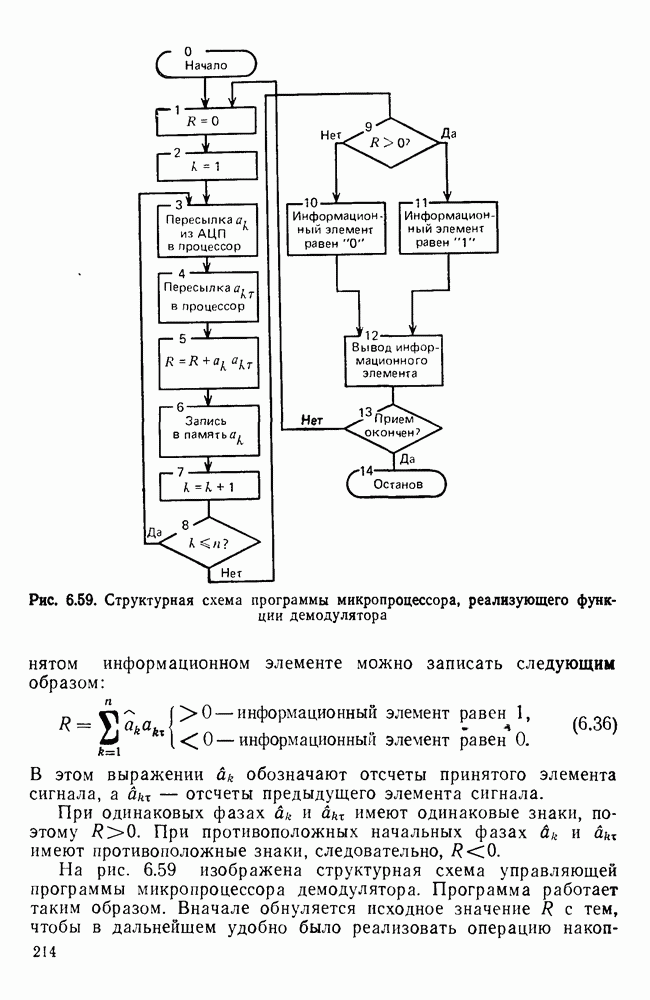
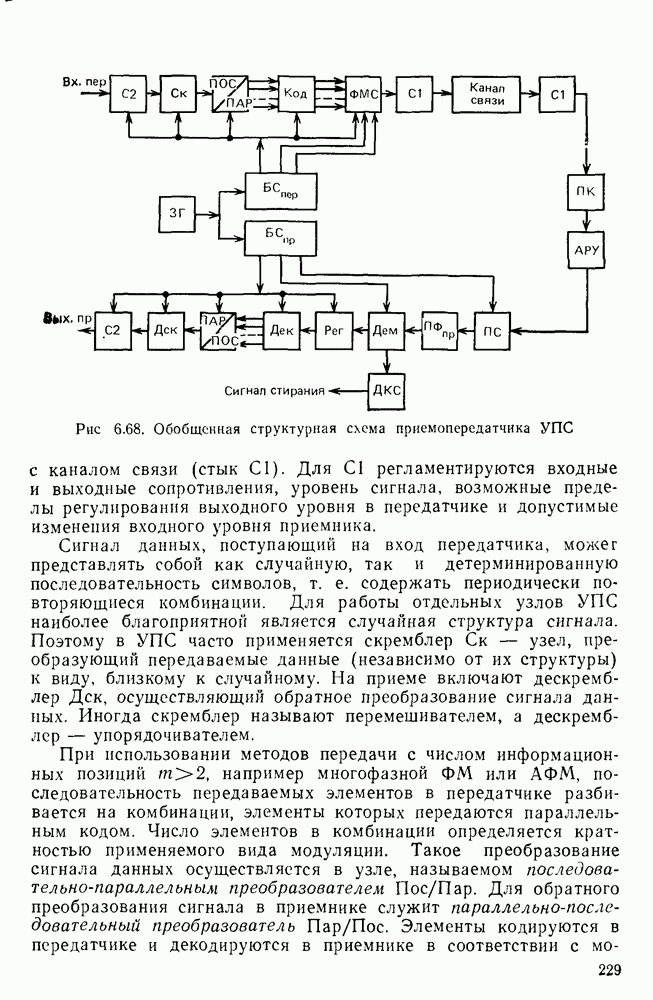
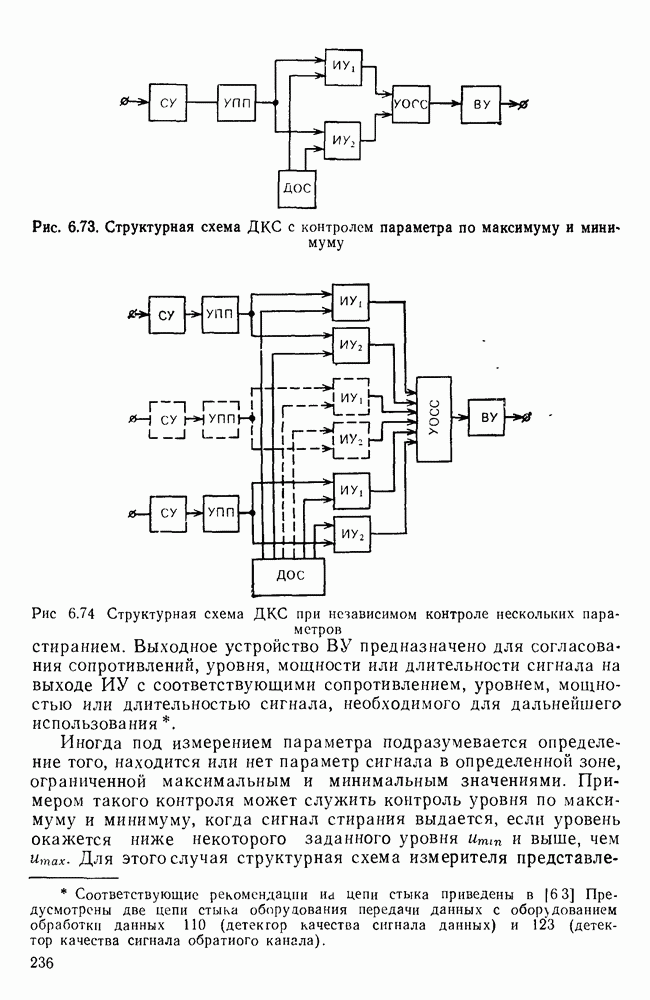
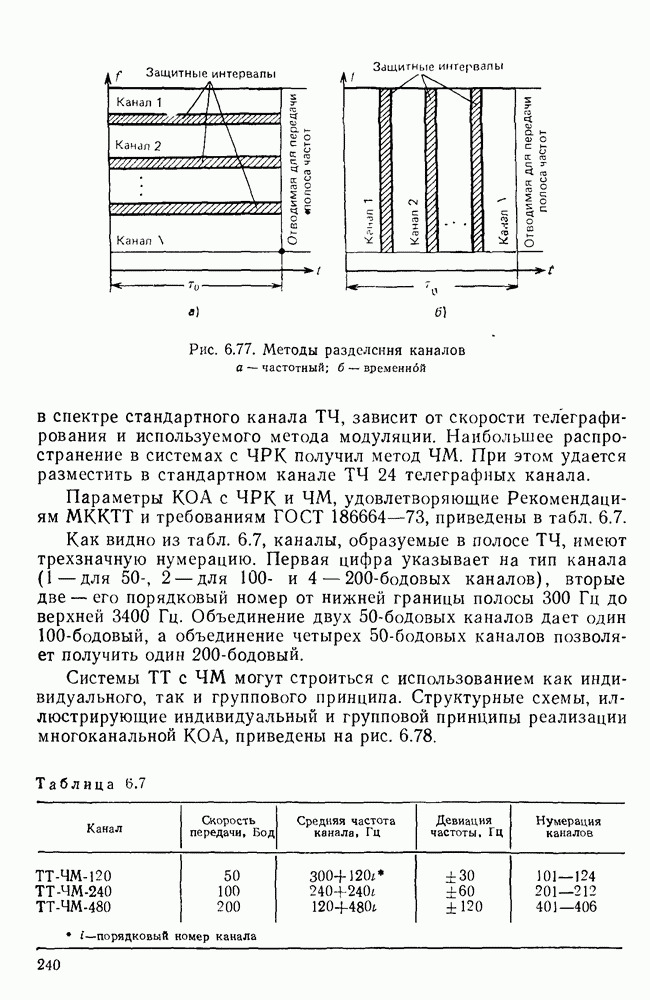
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
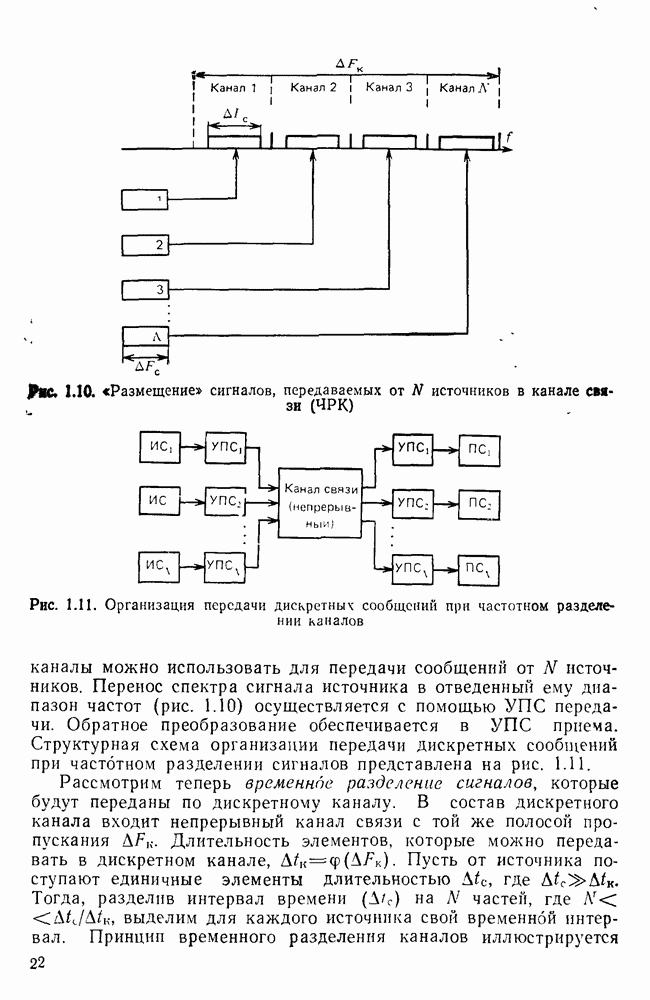
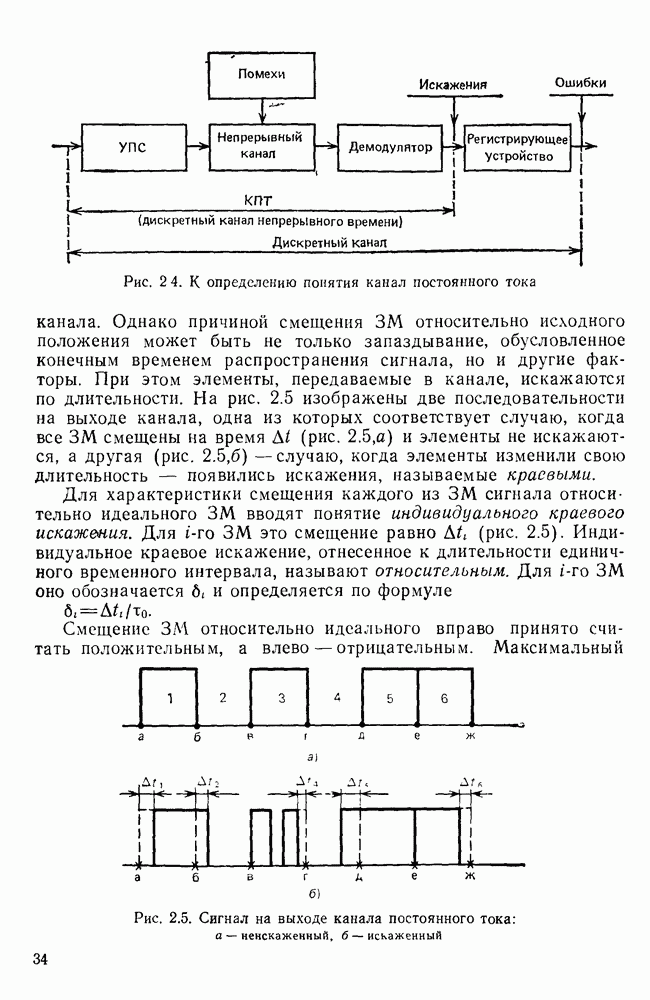
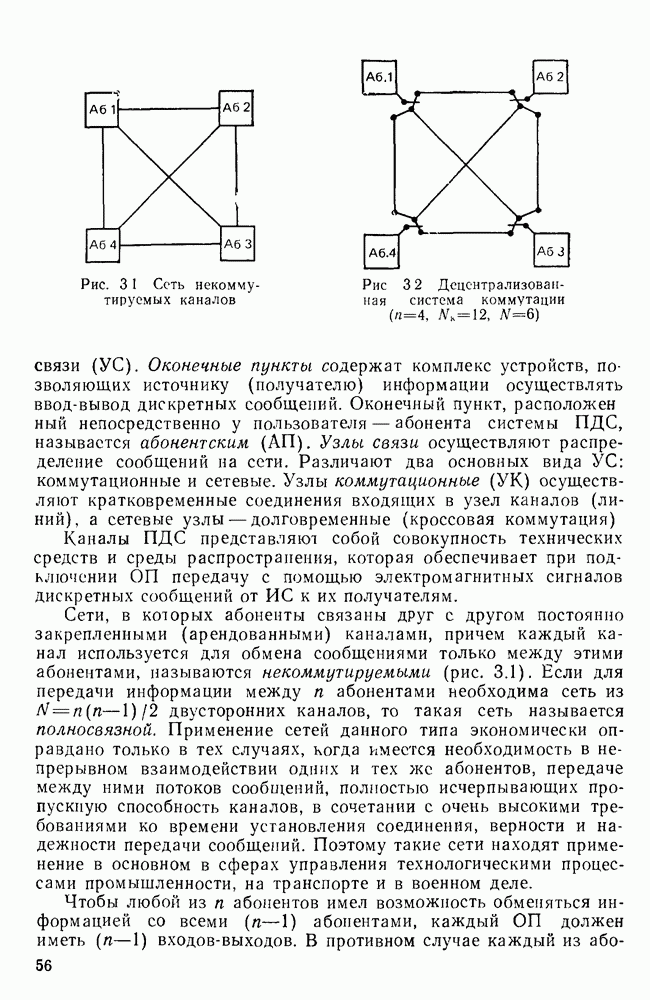
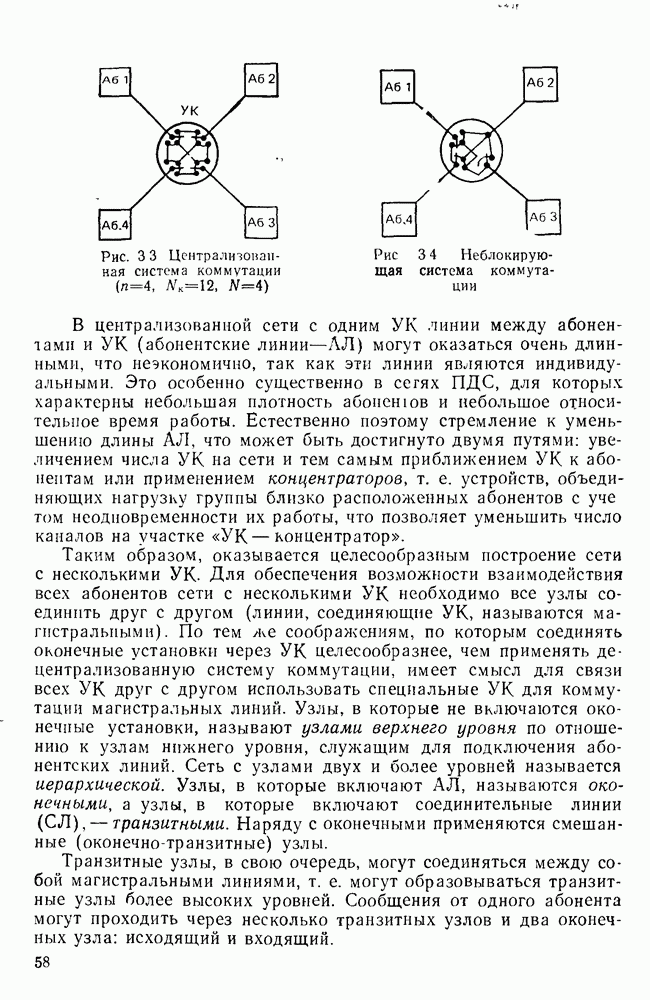
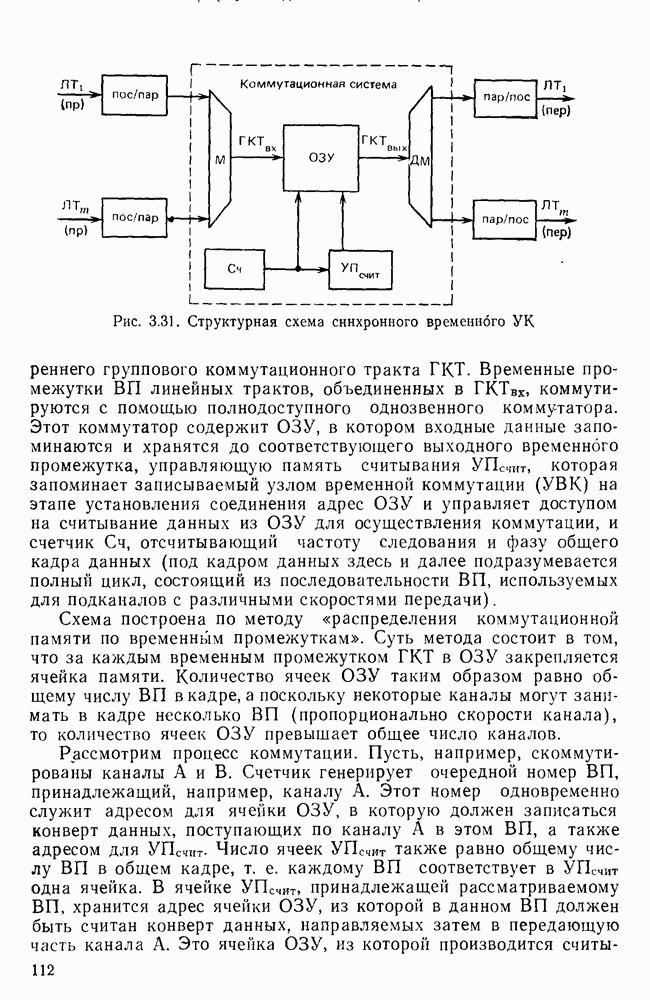
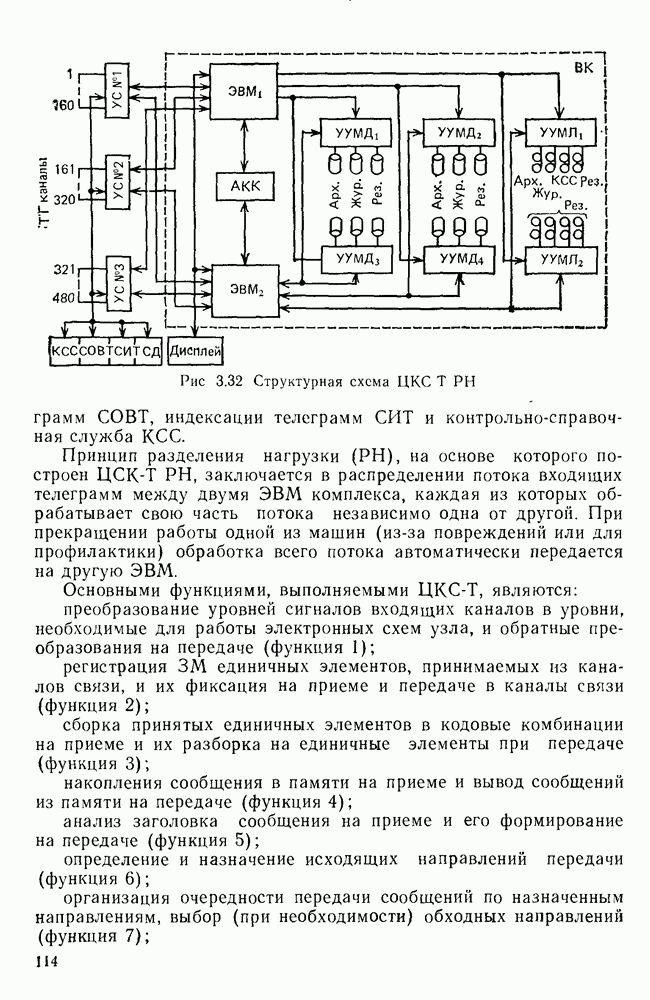
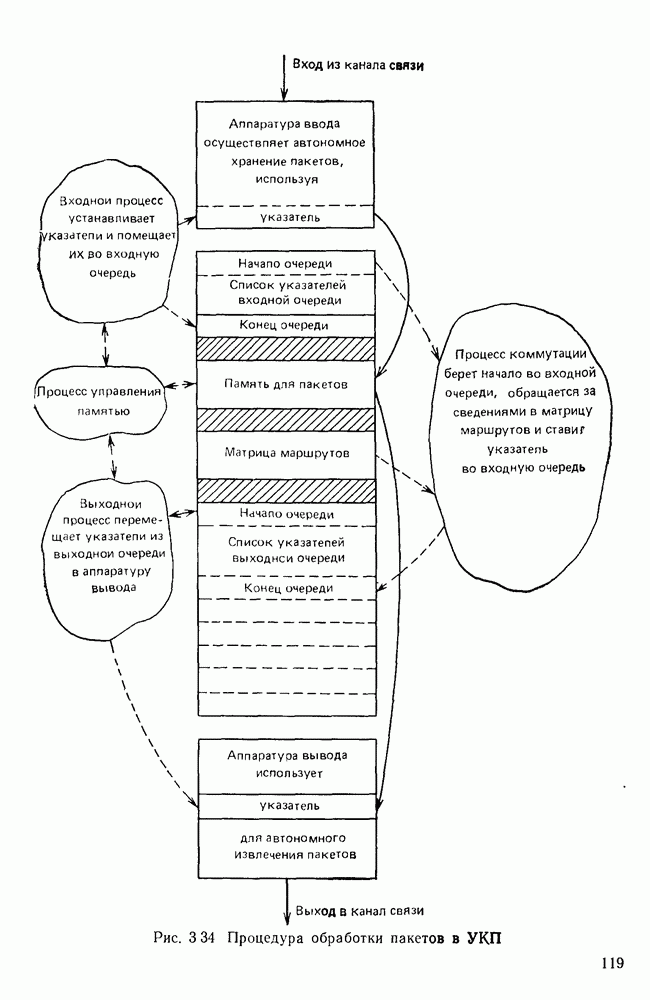
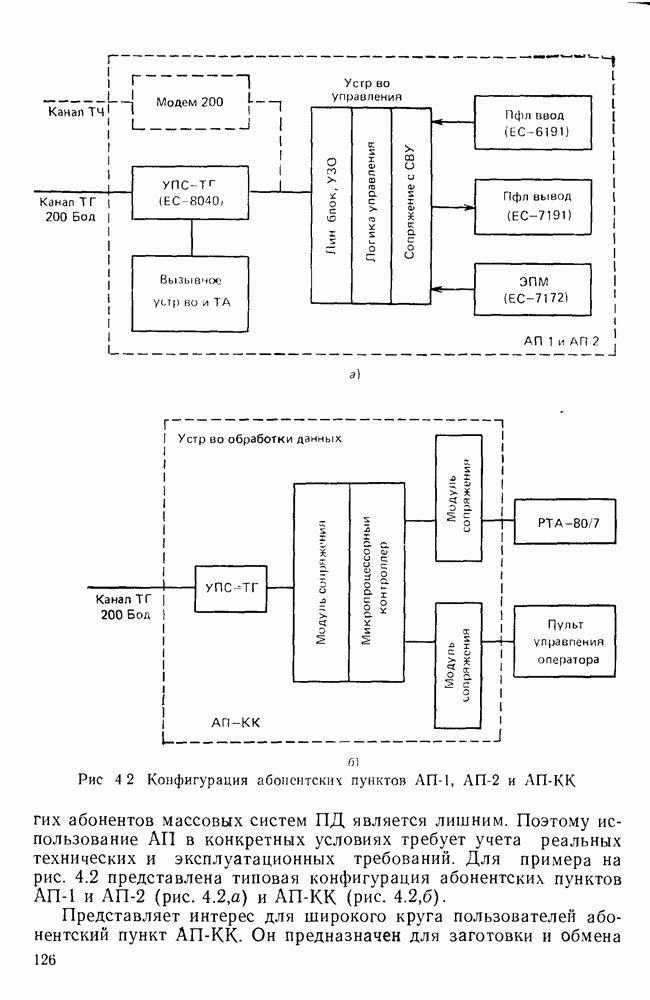
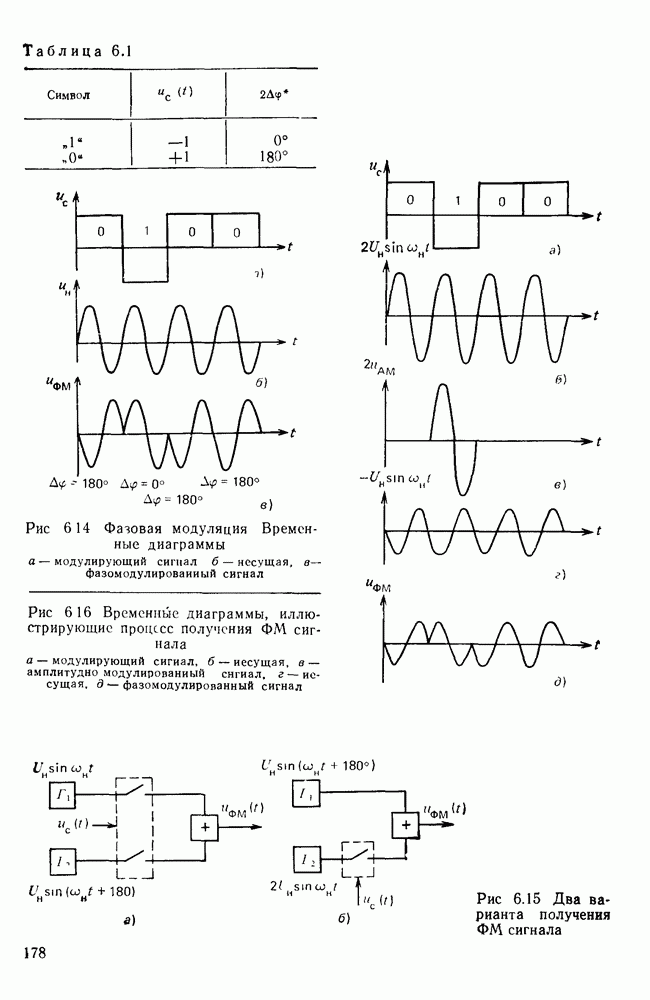
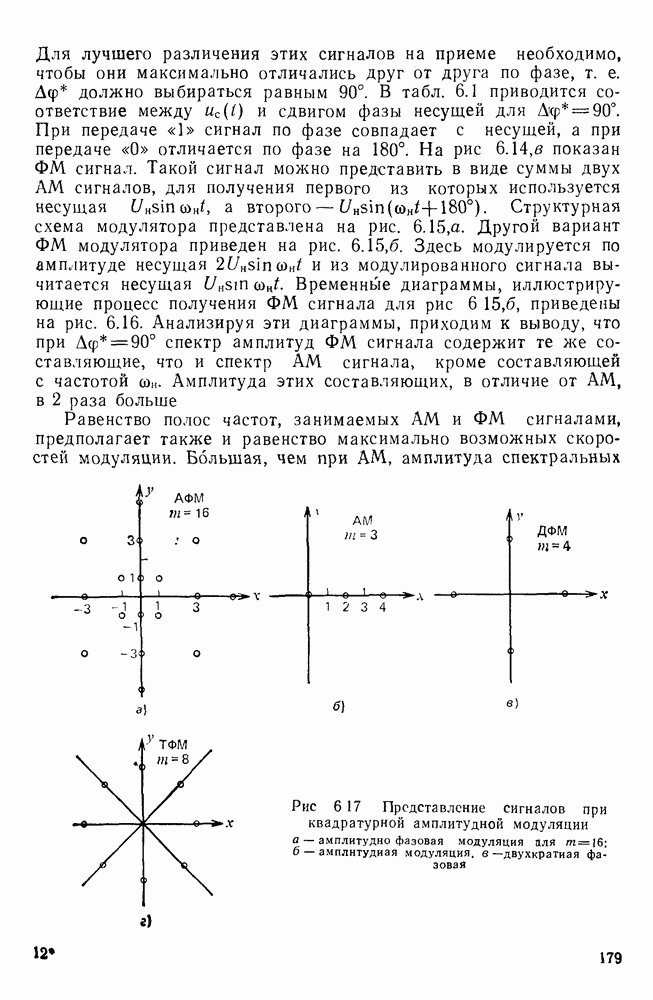
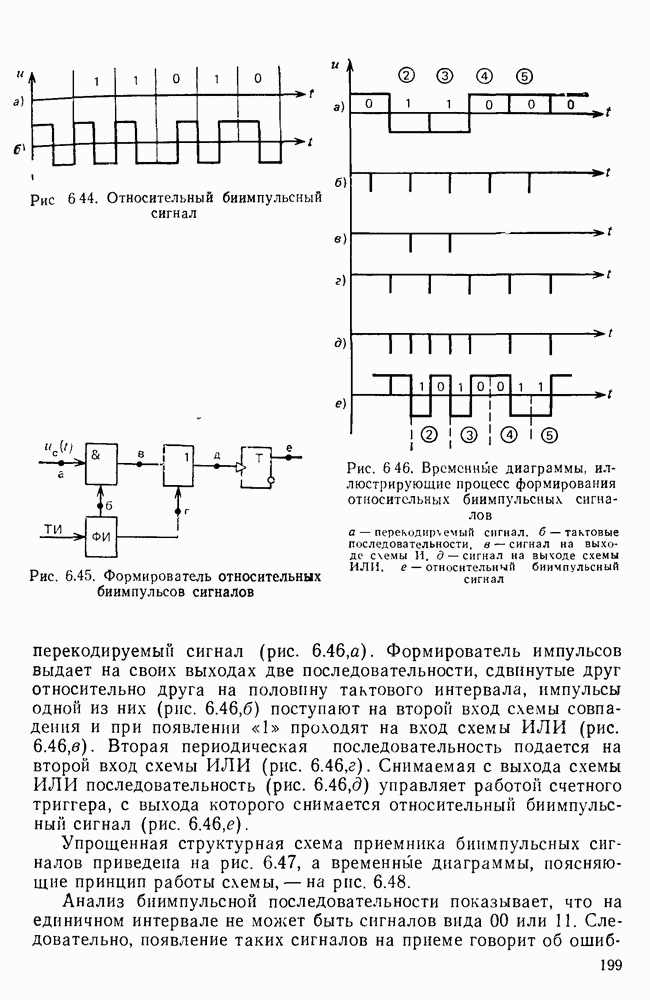
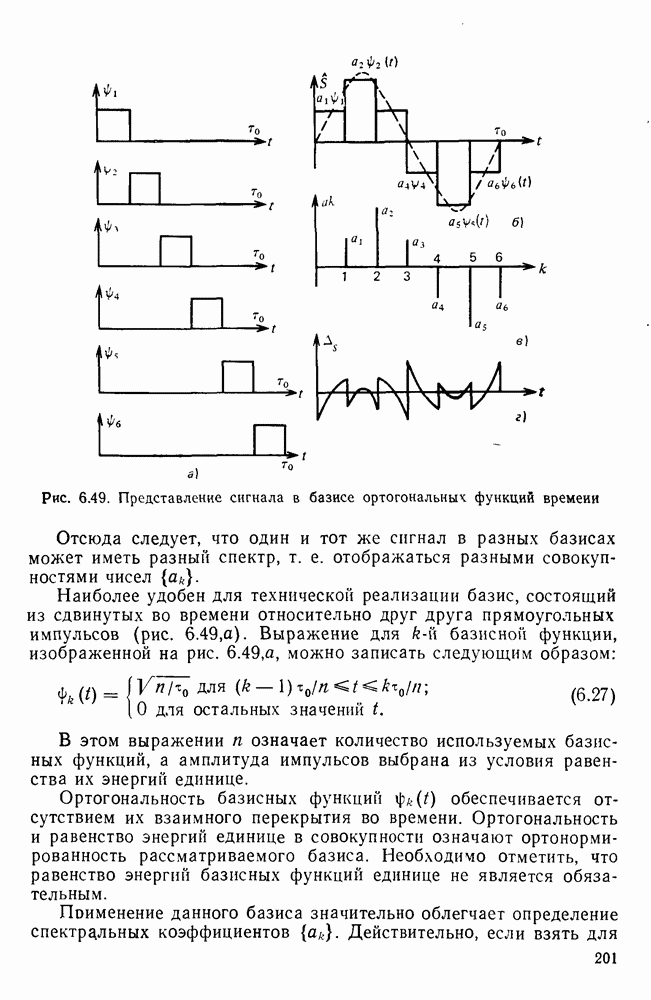
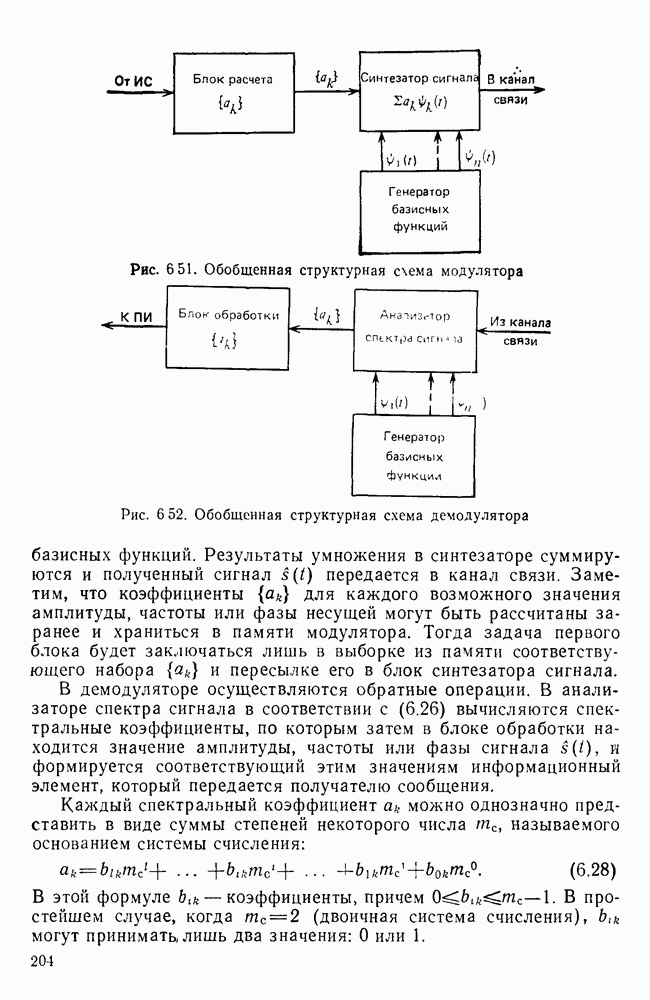
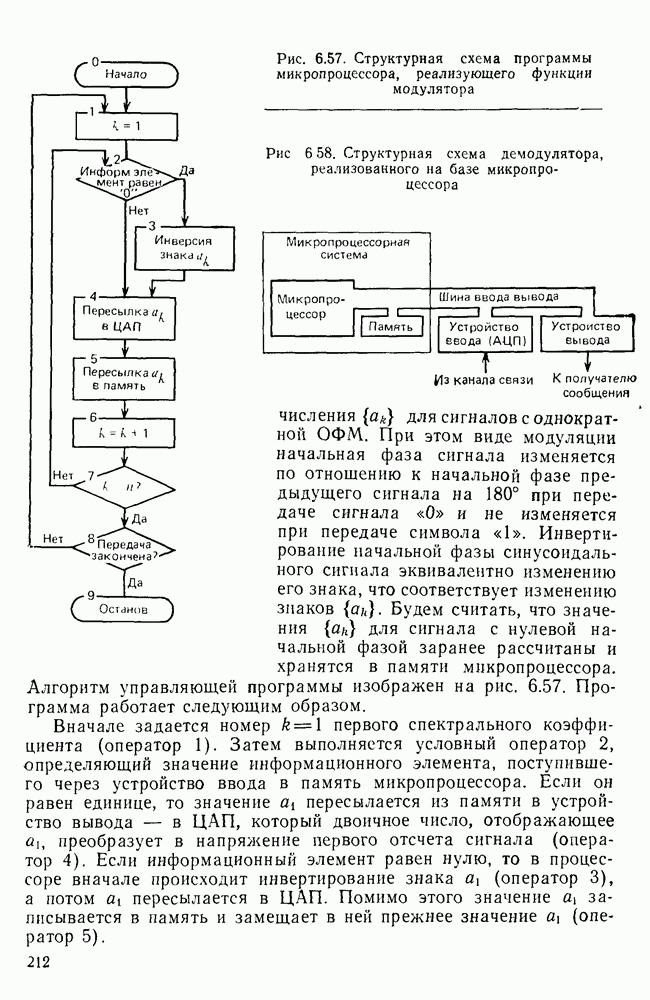
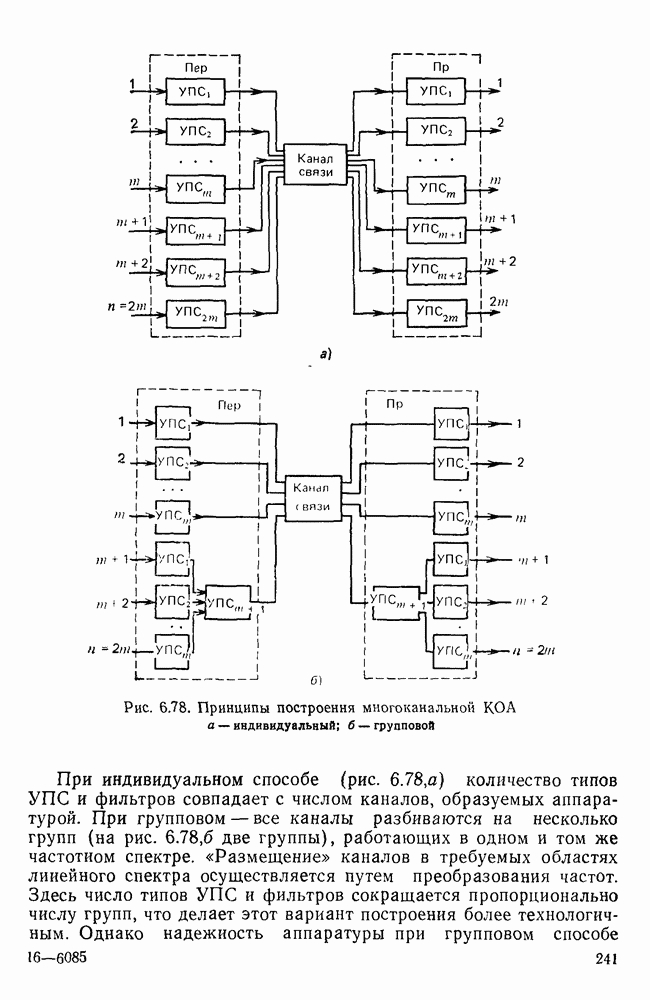
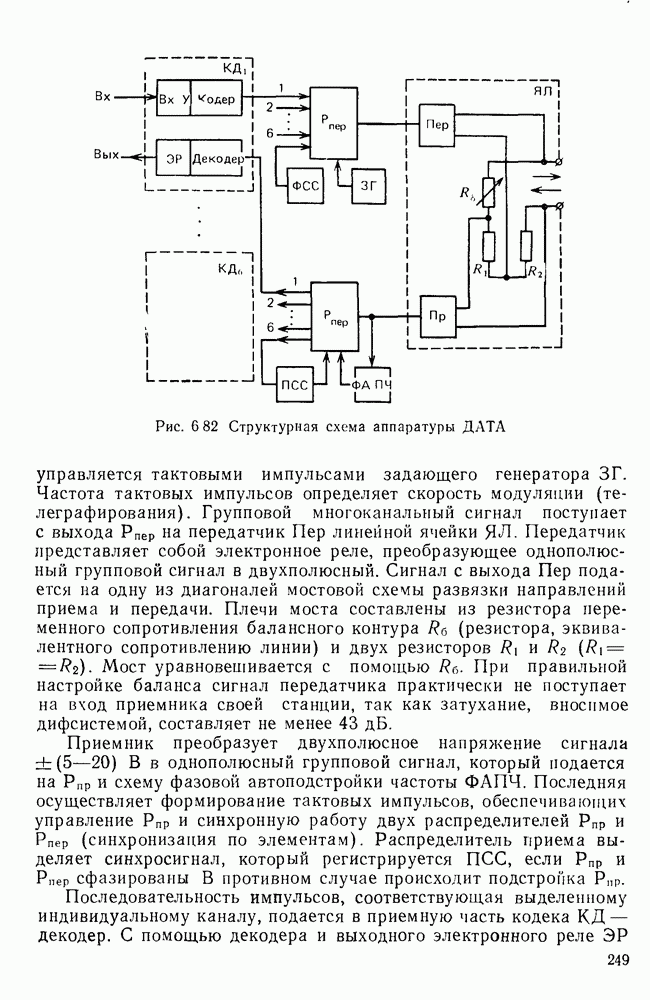
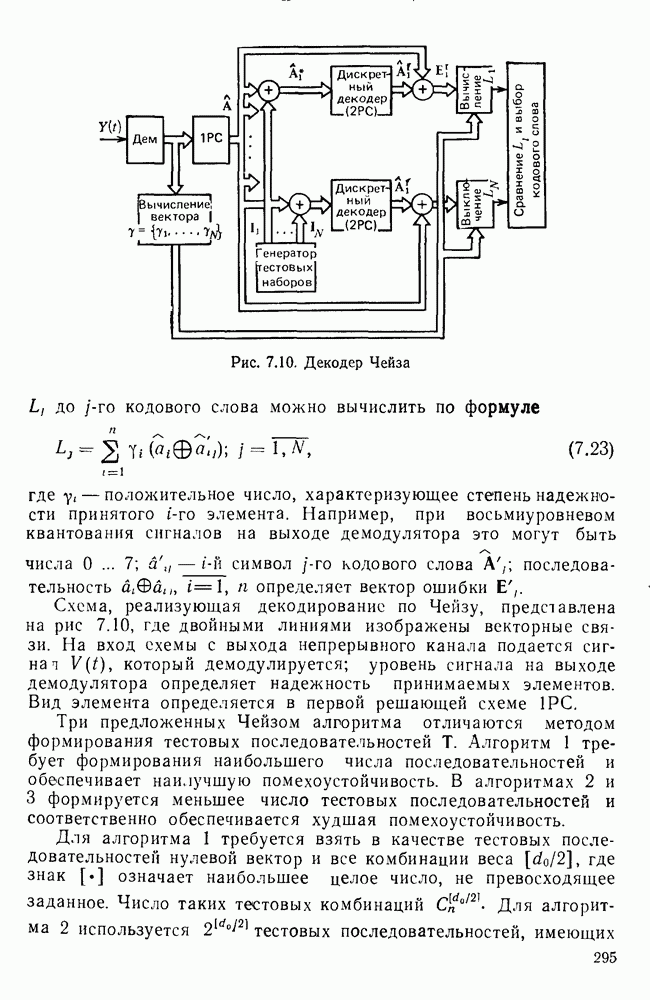
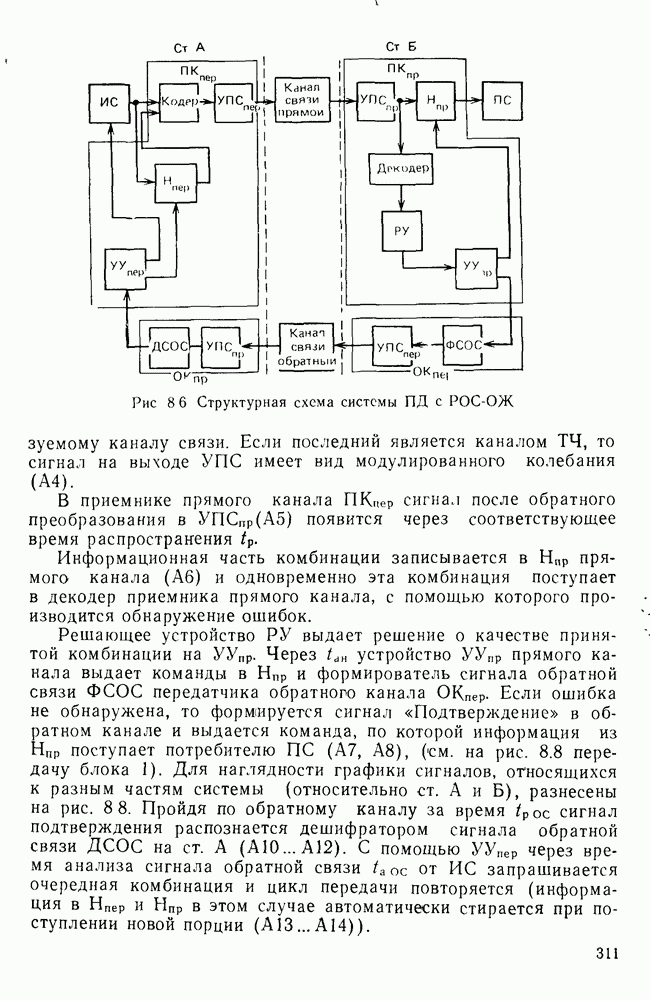
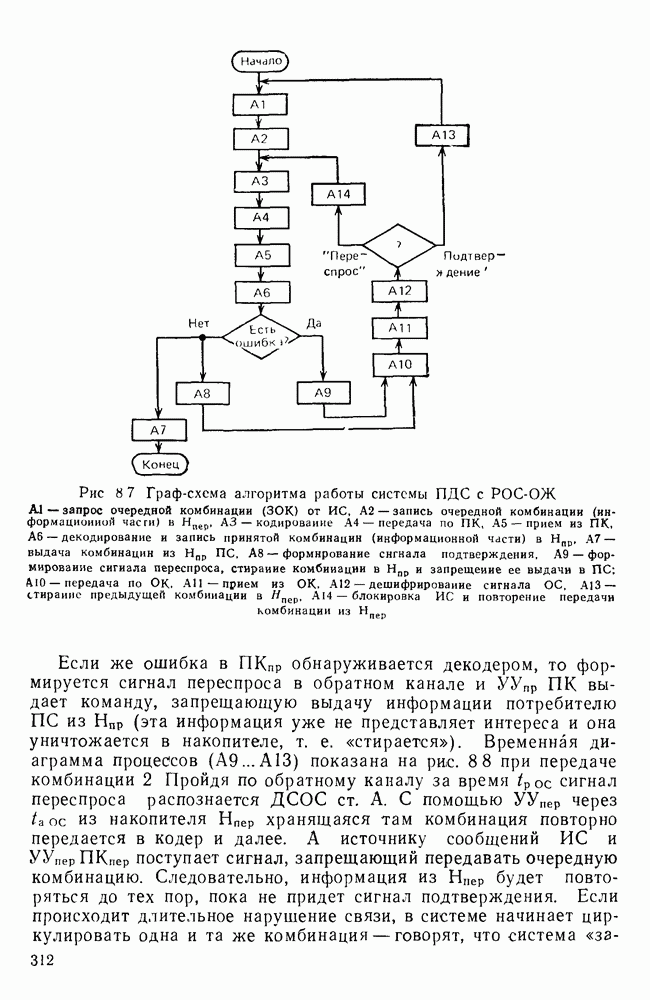
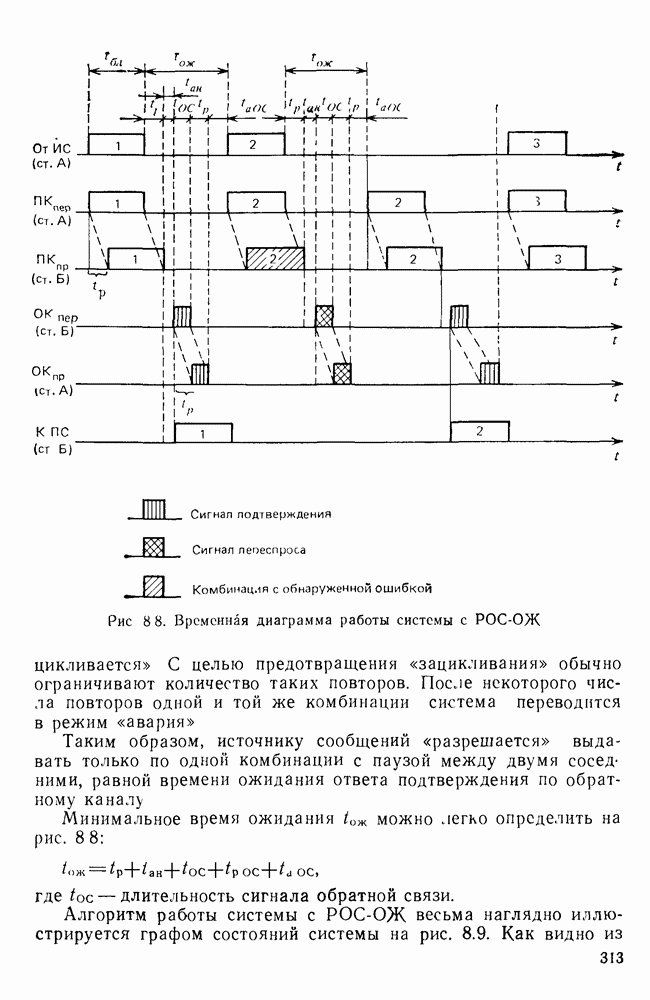
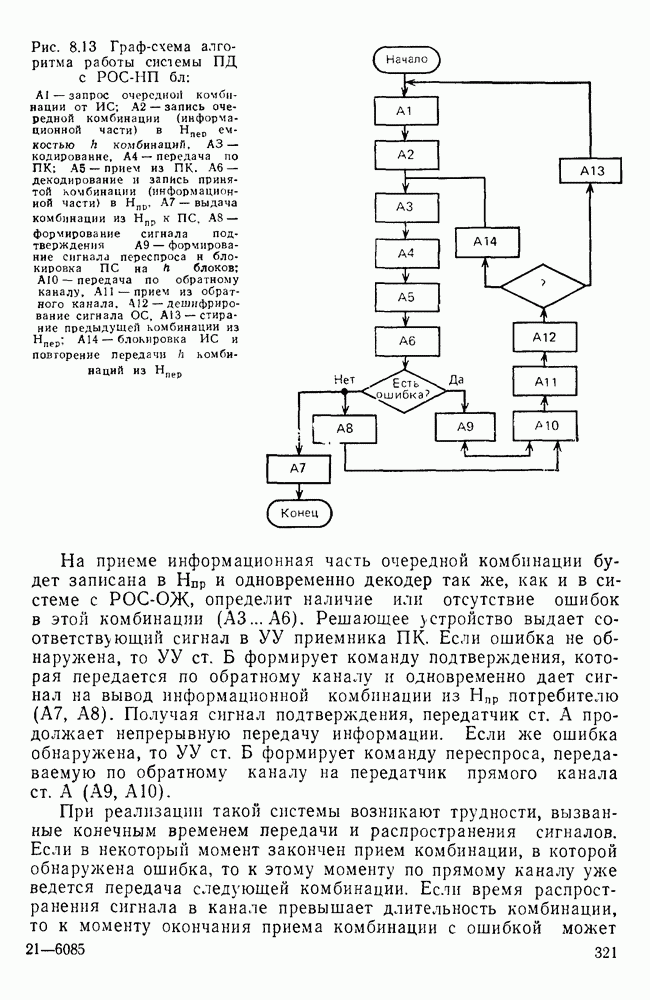
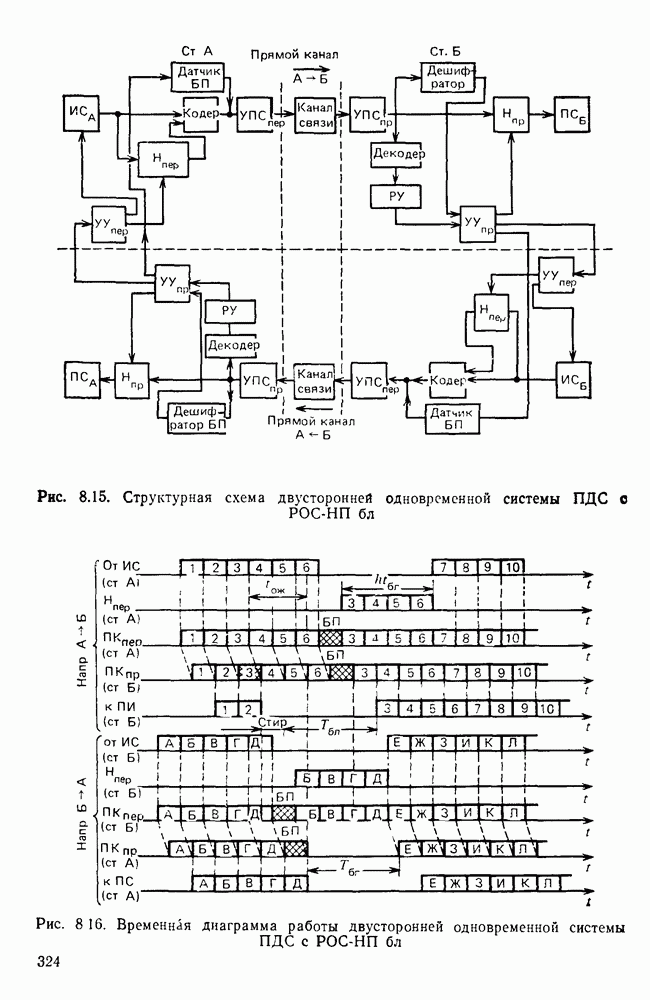
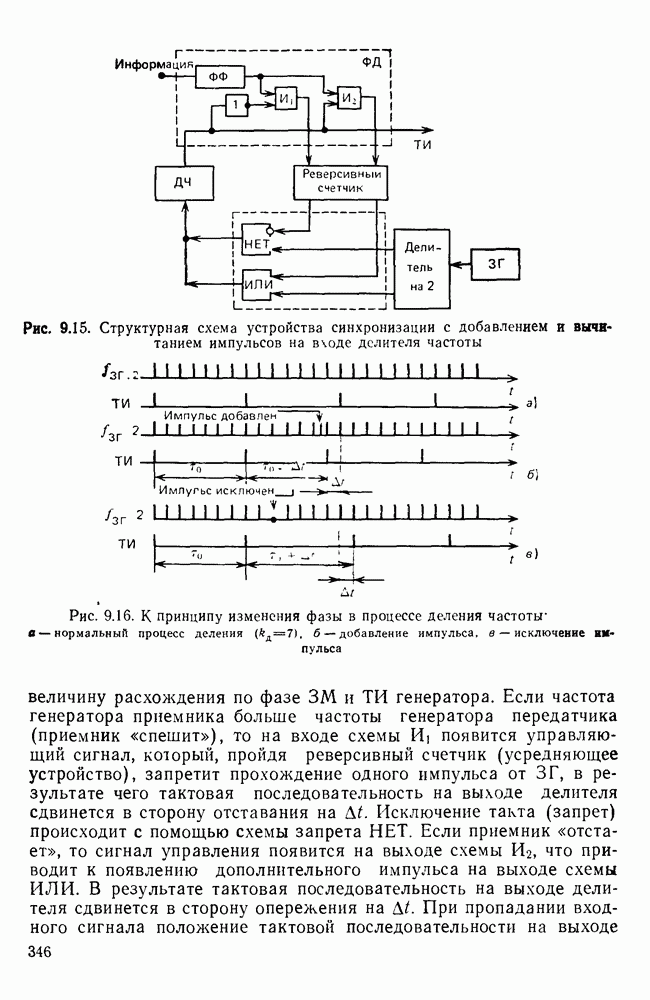
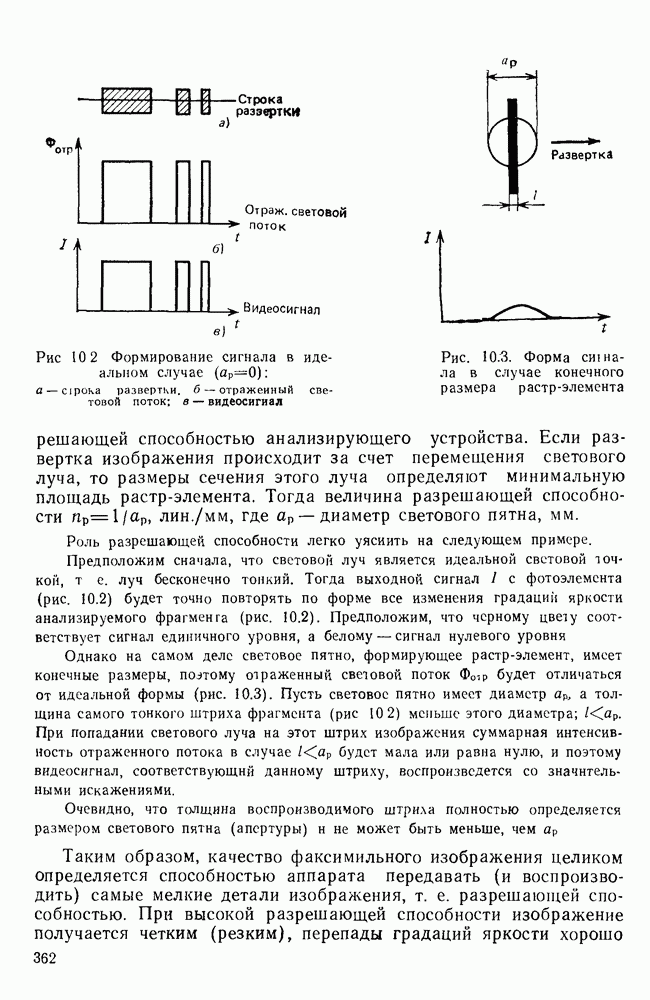
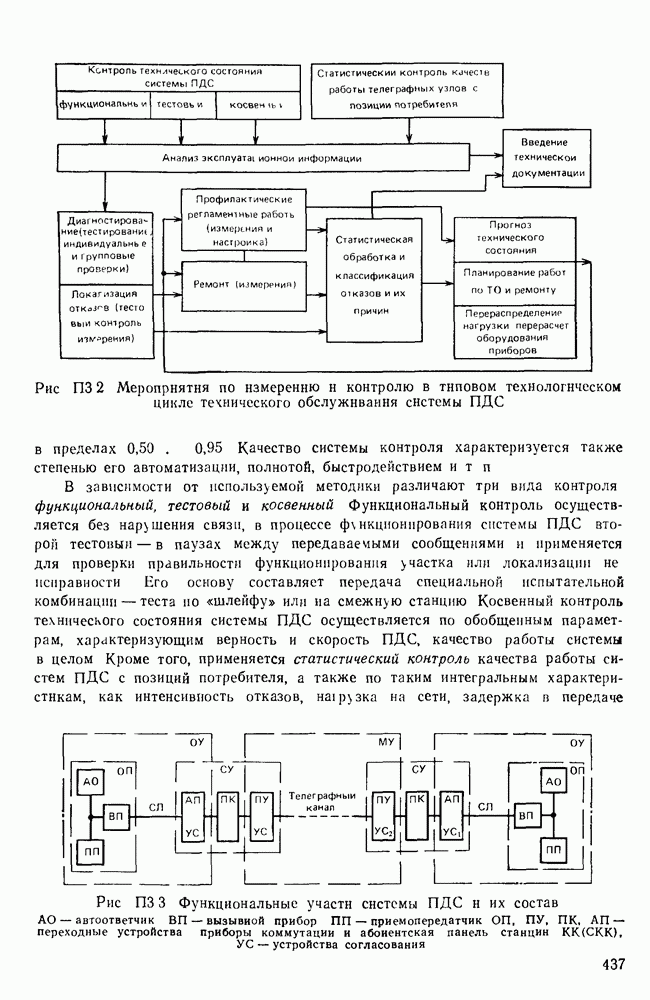
10.4. МОДЕЛИ ФАКСИМИЛЬНЫХ СООБЩЕНИЙВыше было показано, что поэлементный способ передачи изображений приводит к резкому увеличению времени передачи. Анализ статистической избыточности, содержащейся в изображениях, часто проводится на основе представления изображения как случайного объекта — в виде некоторой статистической модели, отражающей основные свойства изображения. Поскольку передача изображения происходит построчно, то целесообразно считать, что сигналы строк являются реализациями некоторой случайной последовательности. Статистические характеристики этой последовательности позволяют оценить среднее количество информации, содержащейся в элементе изображения, а следовательно, и возможный коэффициент сжатия. Простейшей моделью видеосигнала двухградационного изображения является случайная последовательность с независимыми значениями (1 и 0). Для полного статистического описания такого процесса достаточно знать вероятности появления значений сигнала При равновероятном появлении «1» и «0» В действительности элементы изображения нельзя считать статистически независимыми. На изображении имеются протяженные участки однородной градации яркости. Поэтому для видеосигналов двухградационных изображений характерно наличие чередующихся серий «1» и «0». В этом случае более полезной и адекватной моделью сигнала является марковская случайная последовательность. Значения марковской случайной последовательности статистически зависимы между собой. Степень этой зависимости отражается на так называемой вероятности перехода
Для полного задания последовательности необходимо задать начальные вероятности появления
Для последовательности с независимыми значениями очевидно, что
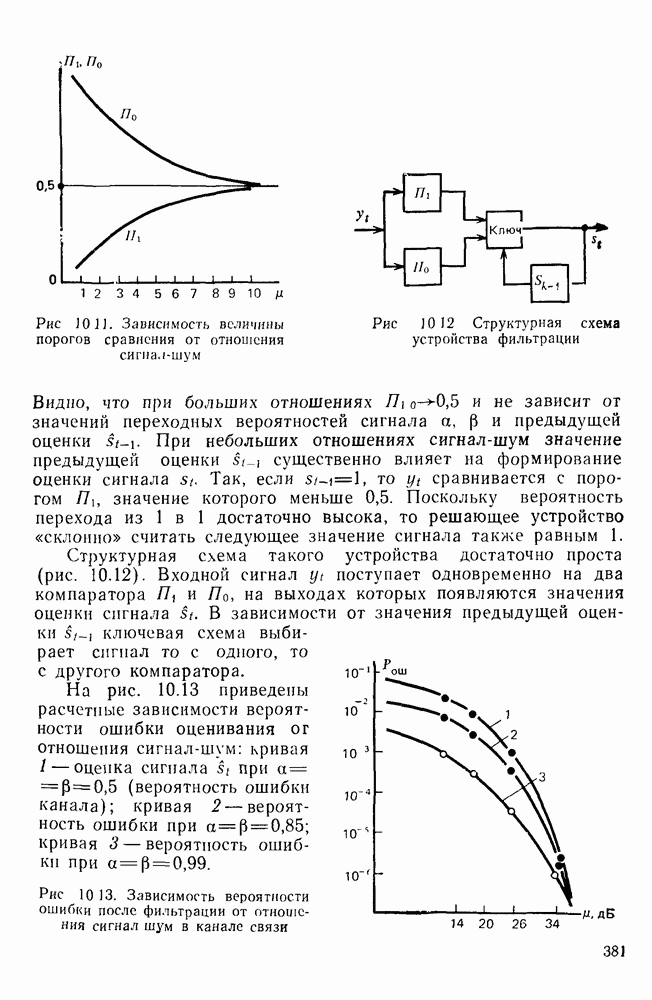
Рис. 10 6 Сигналы при различной разрешающей способности
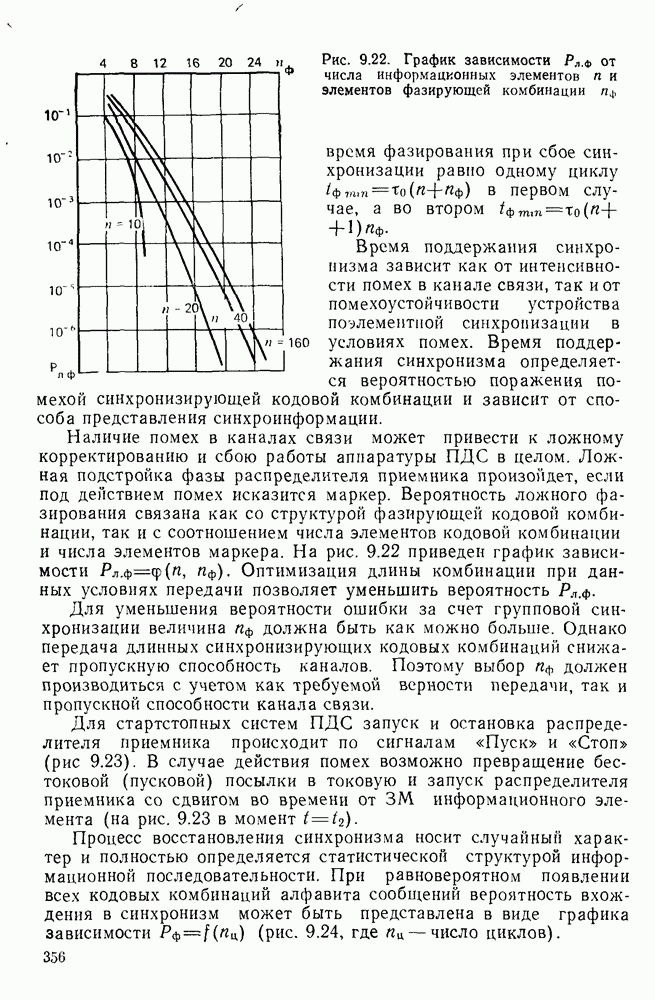
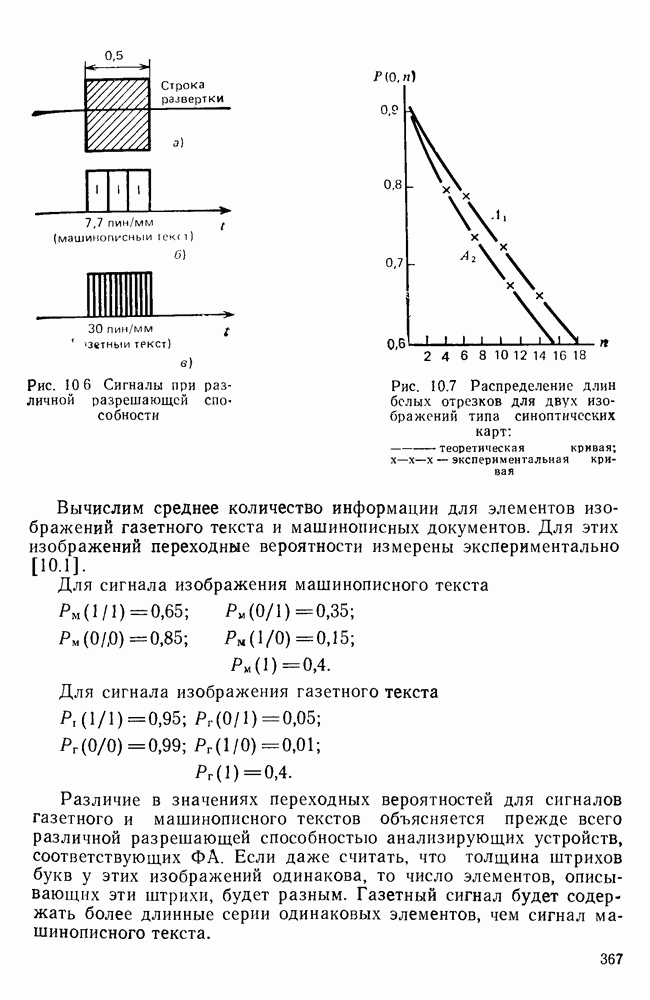
Рис. 10.7 Распределение длин белых отрезков для двух изображений типа синоптических карт: Вычислим среднее количество информации для элементов изображений газетного текста и машинописных документов. Для этих изображений переходные вероятности измерены экспериментально [10.1]. Для сигнала изображения машинописного текста
Для сигнала изображения газетного текста
Различие в значениях переходных вероятностей для сигналов газетного и машинописного текстов объясняется прежде всего различной разрешающей способностью анализирующих устройств, соответствующих ФА. Если даже считать, что толщина штрихов букв у этих изображений одинакова, то число элементов, описывающих эти штрихи, будет разным. Газетный сигнал будет содержать более длинные серии одинаковых элементов, чем сигнал машинописного текста. На рис. 10.6, а представлен увеличенный фрагмент буквы толщиной 0,5 мм. Соответствующие цифровые видеосигналы изображены ниже. Очевидно, что в случае на рис. 10.6, в переход из «1» в «1» осуществляется с более высокой вероятностью, поскольку в состоянии «1» сигнал пребывает большее число раз. Это означает, что значения сигнала (как случайного процесса) изображения газетного текста статистически сильнее связаны между собой. Степени этой связи и определяют переходные вероятности. Так, если определить вероятность совместного появления трех черных элементов (рис. 10.6, б), то для газетного изображения Из этого расчета видно, что марковская модель более точно отражает специфику сигнала реального изображения, чем модель в виде процесса с независимыми значениями. Пользуясь известным обобщением формулы Шеннона на источники с зависимыми сообщениями можно подсчитать количество информации, содержащееся в элементе машинописного или газетного изображения:
Если в (10.3) подставить значения переходных и безусловных вероятностей для газетного и машинописного текстов, то для газетного текста количество информации, содержащееся в элементе изображения Оценим избыточность изображений:
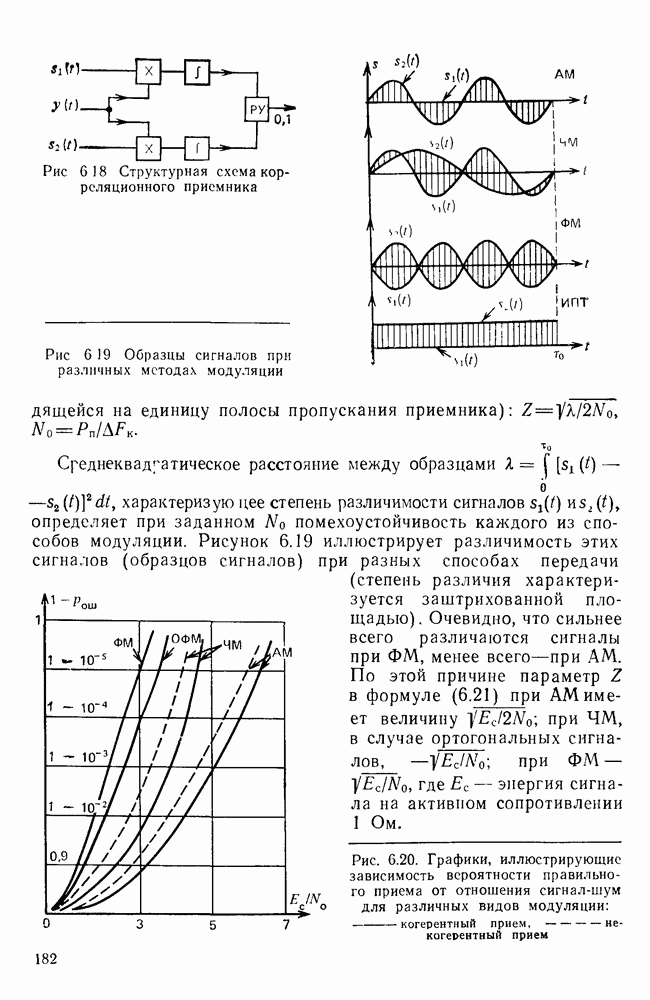
Для источника в виде модели с независимыми элементами и неравными вероятностями Полученные значения Введем коэффициент сжатия Расчет энтропии показывает, что потенциально при передаче изображений газет можно более, чем в 5 раз уменьшить объем передаваемой информации. Более подробные статистические расчеты, основывающиеся на учете связей элементов более, чем на один шаг, показывают, что возможные коэффициенты снятия могут быть еще выше Определяя возможные коэффициенты сжатия, в качестве модели исходного алфавита сообщений рассматриваем элементы изображения: значения цифровых сигналов строк развертки изображения (1,0). Известно, что идея эффективного кодирования сообщений связана с укрупнением алфавита сообщений, т. е. с возможным сокращением его исходного объема. В качестве элементов изображения можно рассматривать, например, отрезки строк из черных и белых элементов, далее можно еще больше укрупнить алфавит, разбивая изображение на некоторые типовые фрагменты, охватывающие несколько строк развертки. Так, при передаче изображения машинописного текста такими фрагментами могли бы быть уже изображения отдельных знаков текста. В этом случае факсимильная передача фактически свелась бы к кодовой передаче аналогично телеграфной передаче текста, однако необходимо автоматическое опознавание изображения знака. Рассмотрение этой задачи выходит за рамки данного раздела. Оставаясь в рамках факсимильной передачи, т. е. передачи сигналов строк развертки изображения, можно рассматривать модели этих сигналов в виде случайных серий, состоящих из черных и белых элементов. Таким образом, изображение представляется совокупностью различных отрезков черного и белого цветов. Здесь следует сделать одно замечание. Рассматривая изображение в виде набора различных отрезков белого и черного цветов, мы просто по-другому интерпретируем прежний источник, порождающий сообщения в виде единичных элементов «0» и «1». Поэтому, если в качестве такого источника выбрать марковскую последовательность, то серии, состоящие из «0» и «1», — это укрупненные состояния того же марковского процесса. И поэтому статистические характеристики этих состояний (серий) полностью определяются статистическими свойствами исходного источника. Отсюда следует, что избыточность обоих источников одинакова. Целесообразность представления изображения в виде источника длин серий белого и черного цветов обусловливается существенной неравномерностью распределения вероятностей длин этих серий, что и позволяет использовать методы статистического кодирования. Зная статистические характеристики марковского процесса, легко найти вероятности длин серий. Обозначим через
Здесь в качестве
На рис. 10.7 приведены теоретические и экспериментальные кривые вероятностей
где
Подставив в (10.6) выражение для
Тогда количество информации, содержащееся в серии средней длины
Возможный коэффициент сжатия для каждой серии длиной
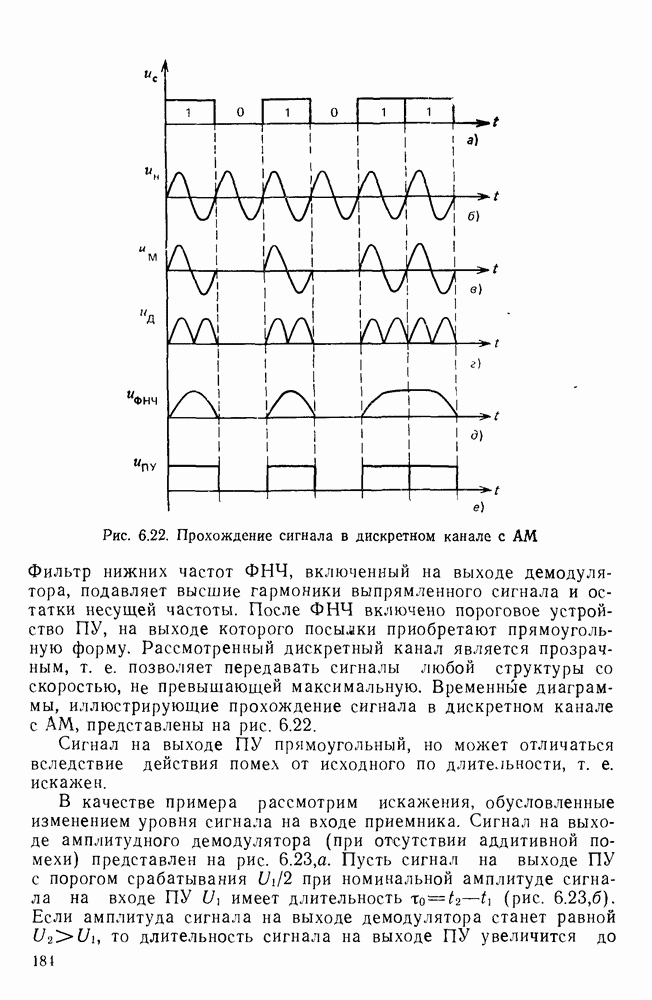
На рис. 10.8 приведена зависимость коэффициента сжатия Для изображения типа синоптических карт оптимальная длина серии белого равна 7 и 8, что определяет коэффициенты сжатия 2,55 и 2,75 соответственно.
Рис. 10.8. Зависимость коэффициента сжатия Обобщением рассмотренной модели может служить представление изображения в виде совокупности отрезков строк-блоков размером Заканчивая рассмотрение моделей факсимильных сообщений, следует отметить, что основной упор был сделан на статистическое представление элементов, серий, фрагментов изображений в виде случайных событий. Такой подход оправдан, когда в качестве методов эффективного кодирования используются статистические методы, в основу которых положено представление о случайном источнике сообщений. В этом случае понятия «избыточность» и «количество информации» трактуются на основе понятий теории информации, т. е. как статистические категории Не следует думать, что описание изображений в виде статистических моделей является единственно возможным. Целесообразность статистического описания определяется, прежде всего, свойствами изображения и требованиями к его воспроизведению получателем. Ниже будет рассмотрен нестатистический подход к описанию изображения.
|
 |
Оглавление
|





















































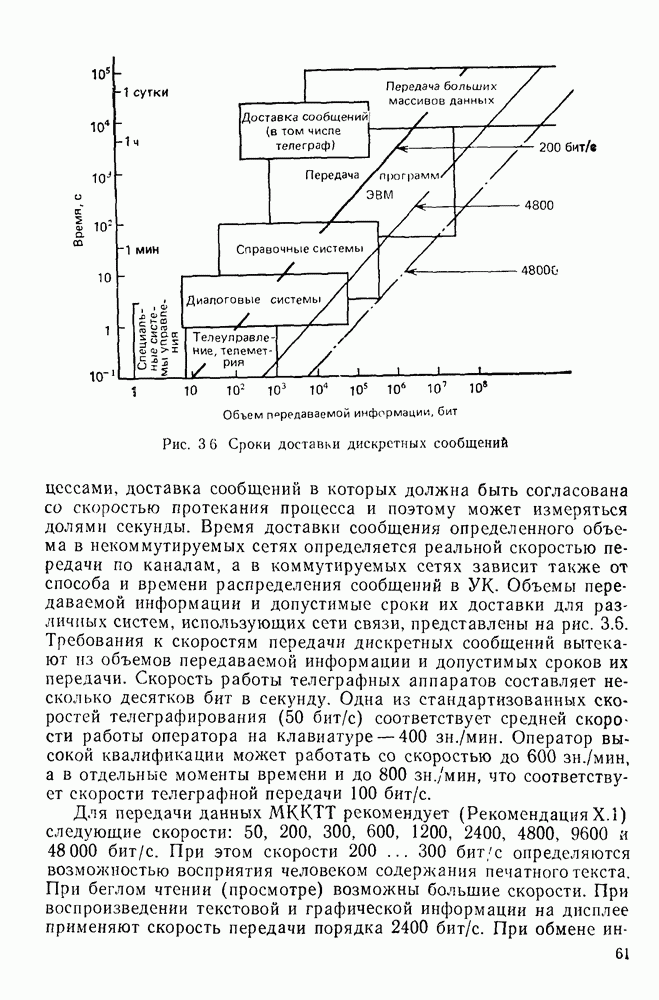


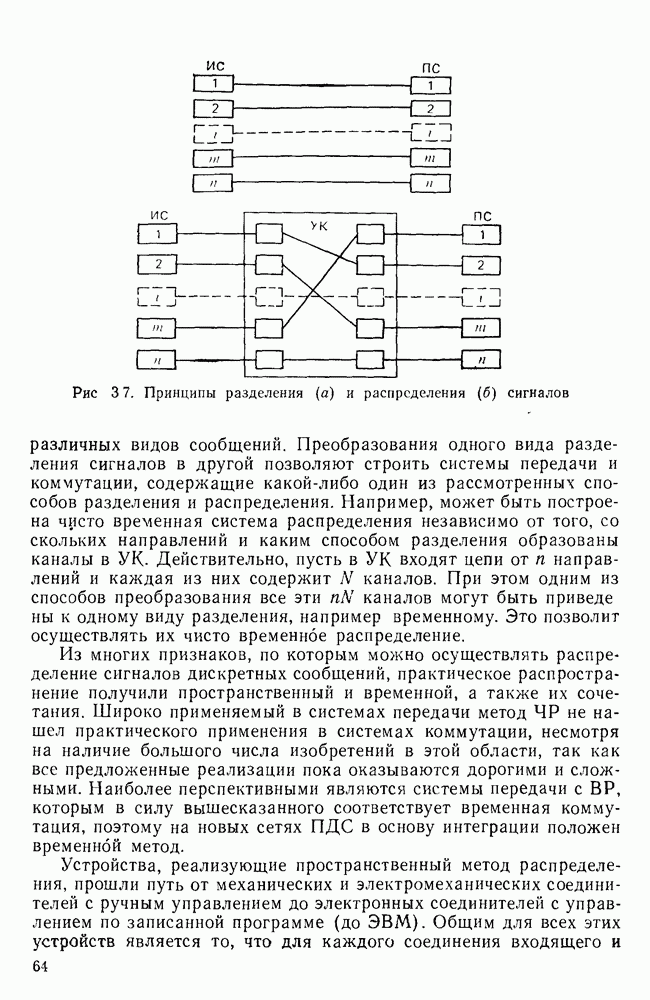





























































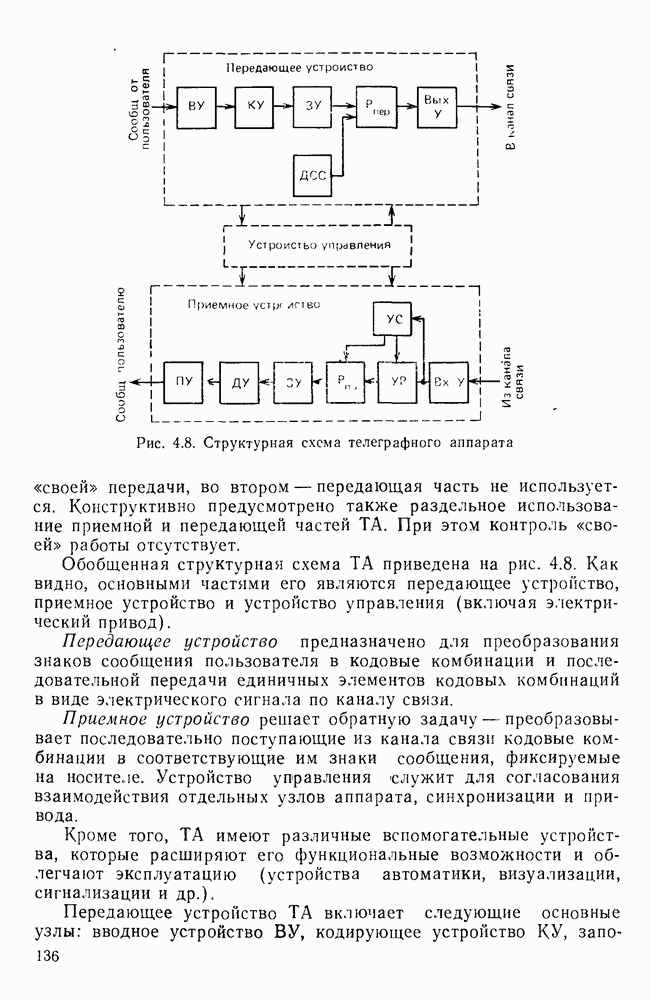









































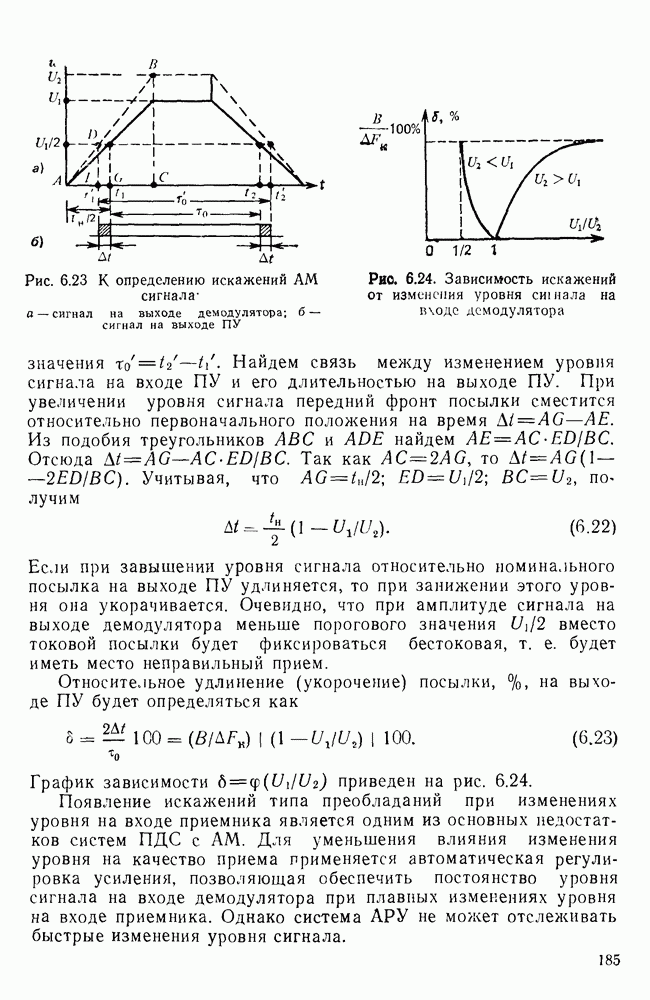







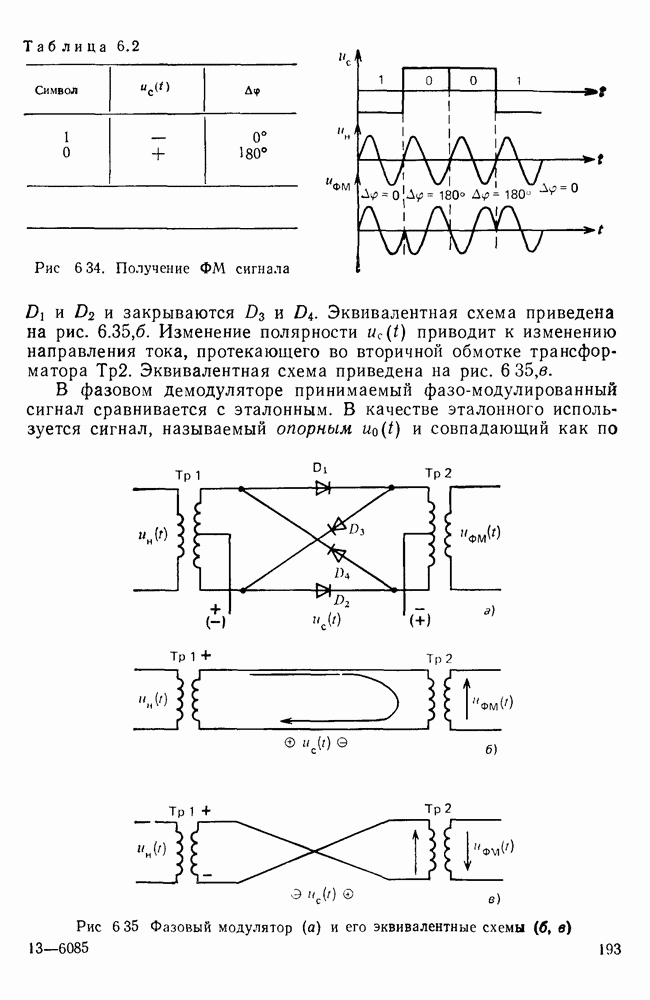

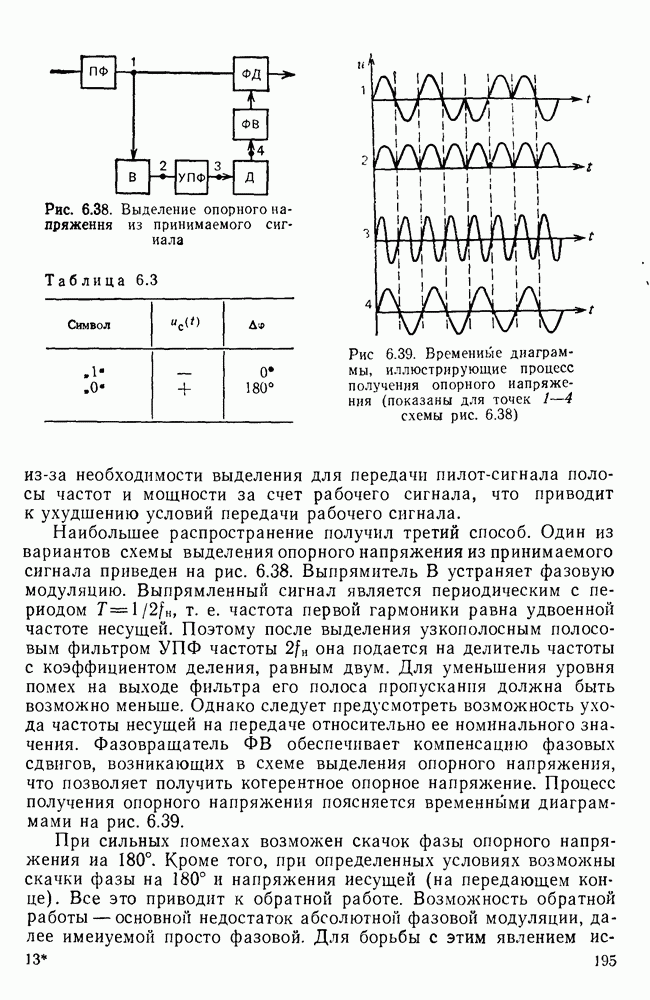
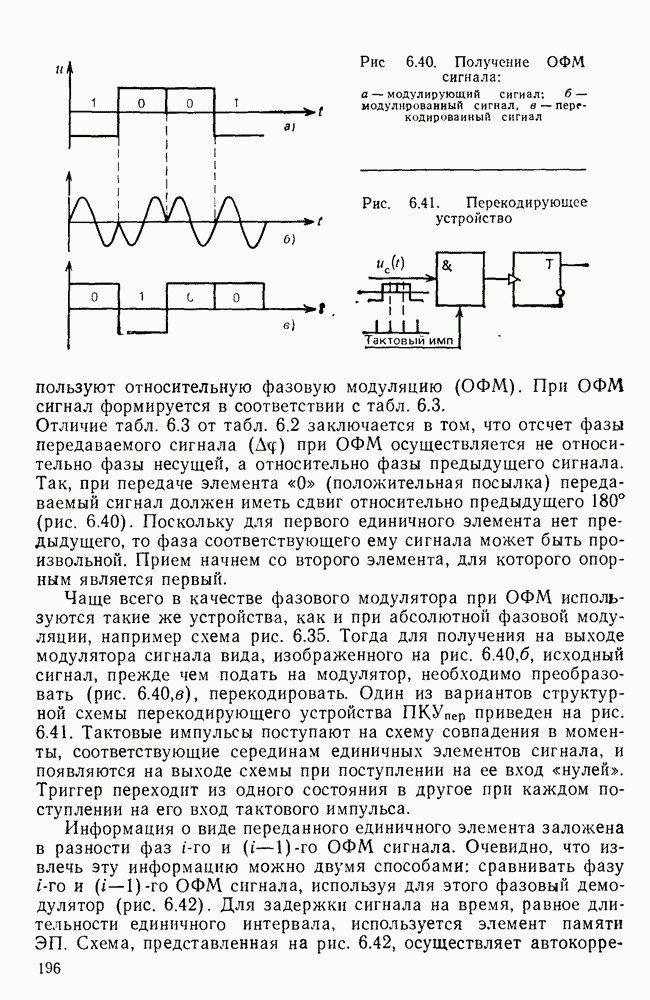


















































































































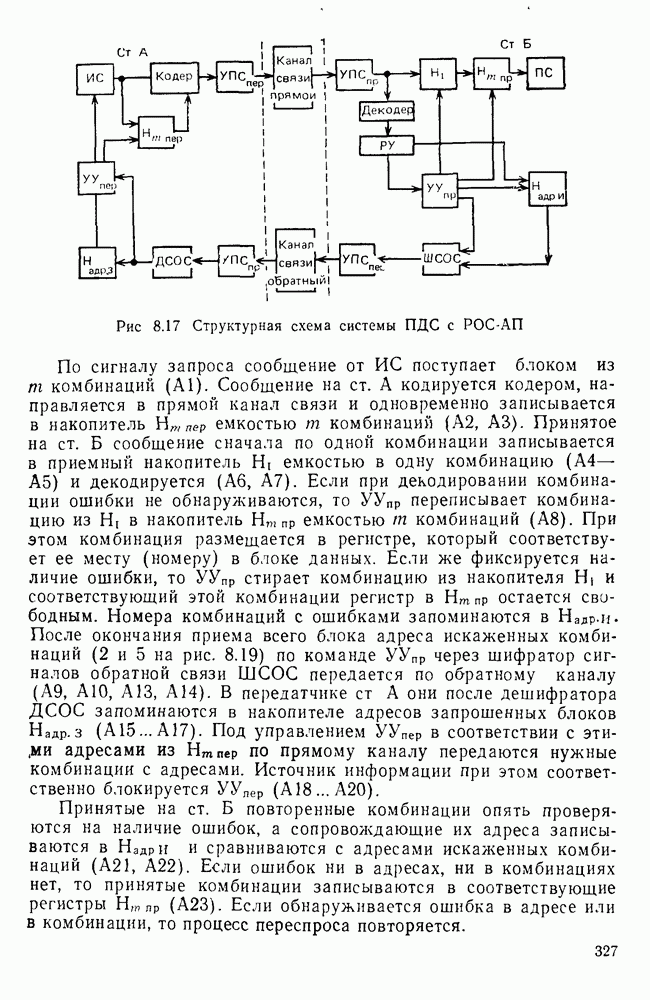
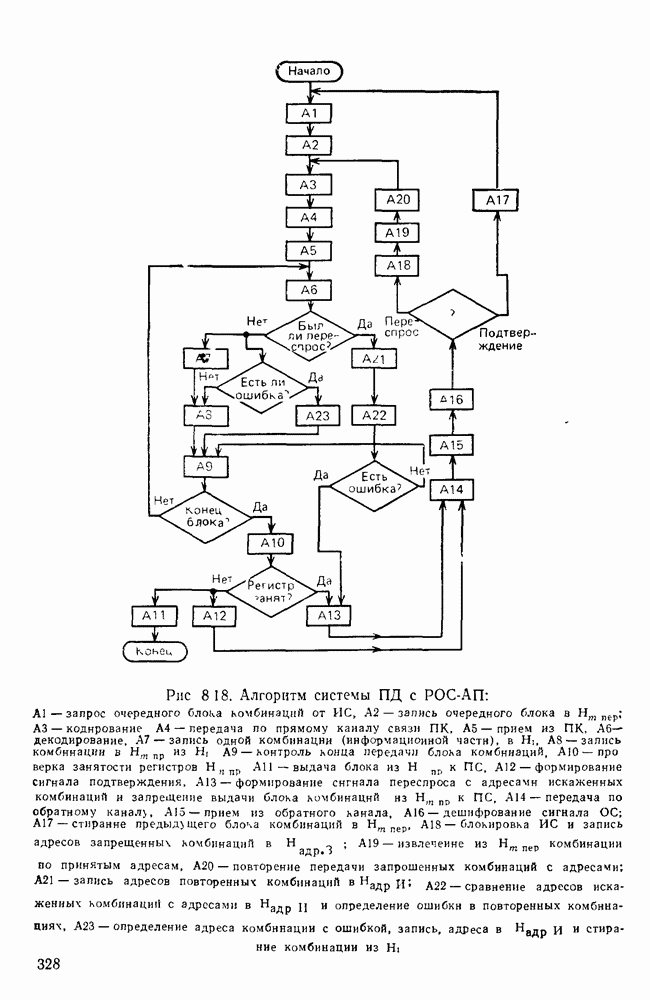

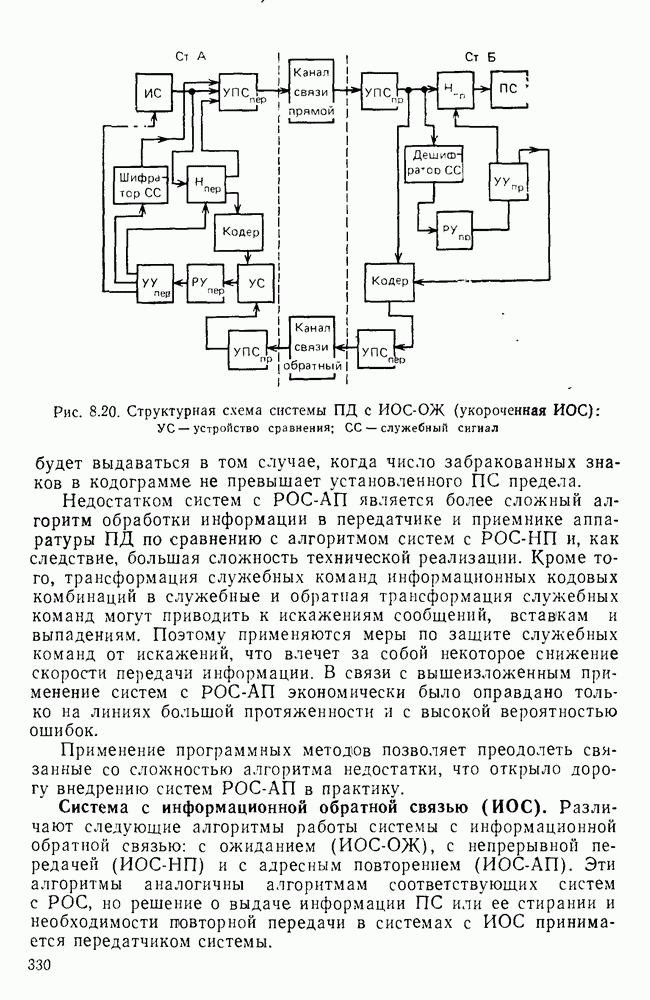
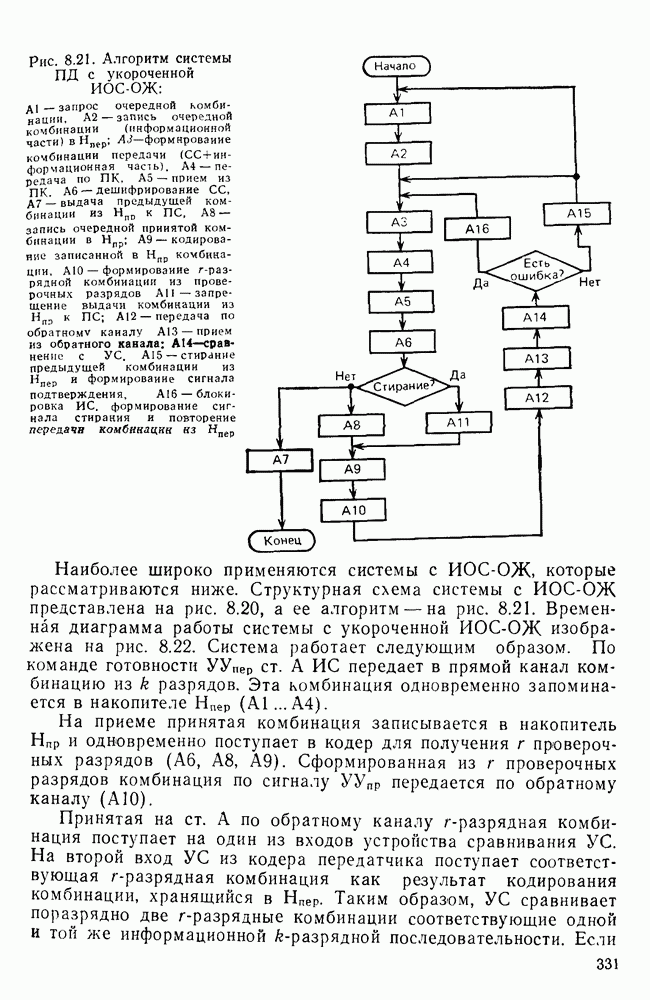















































































































 Эти вероятности легко оценить экспериментально, подсчитывая число белых и черных элементов двухградационного изображения. Так, для изображений типа документов
Эти вероятности легко оценить экспериментально, подсчитывая число белых и черных элементов двухградационного изображения. Так, для изображений типа документов  — черные, «0» — белые элементы). В этом случае энтропия, приходящаяся на один элемент изображения,
— черные, «0» — белые элементы). В этом случае энтропия, приходящаяся на один элемент изображения, 
 Избыточность
Избыточность  .
.
 которая указывает, с какой вероятностью появится значение сигнала
которая указывает, с какой вероятностью появится значение сигнала  в момент t, если на предыдущем шаге сигнал принял значение
в момент t, если на предыдущем шаге сигнал принял значение  случае, когда сигнал принимает два значения
случае, когда сигнал принимает два значения  вероятности перехода образуют для стационарной последовательности следующую матрицу переходных вероятностей:
вероятности перехода образуют для стационарной последовательности следующую матрицу переходных вероятностей:

 соответственно. Вероятность совместного распределения
соответственно. Вероятность совместного распределения  значений марковской последовательности
значений марковской последовательности  определяется выражением
определяется выражением

 где
где  — вероятность значения
— вероятность значения  причем
причем  для любых
для любых 


 - теоретическая кривая;
- теоретическая кривая;  — экспериментальная кривая
— экспериментальная кривая


 , а для изображения машинописного текста
, а для изображения машинописного текста  . Для случайного изображения с независимыми элементами при той же вероятности появления черного элемента
. Для случайного изображения с независимыми элементами при той же вероятности появления черного элемента  получим
получим 

 а для машинописного текста
а для машинописного текста 


 свидетельствуют о том, что в случае передачи газетного и машинописного изображений потери в скорости передачи информации составляют 81 и 24% соответственно.
свидетельствуют о том, что в случае передачи газетного и машинописного изображений потери в скорости передачи информации составляют 81 и 24% соответственно.
 показывающий, во сколько раз можно уменьшить количество двоичных цифр для представления источника с энтропией
показывающий, во сколько раз можно уменьшить количество двоичных цифр для представления источника с энтропией  по сравнению с тем, когда все сообщения равновероятны. При передаче газетного изображения
по сравнению с тем, когда все сообщения равновероятны. При передаче газетного изображения  , а машинописного текста
, а машинописного текста 

 вероятность того, что серия длиной
вероятность того, что серия длиной  содержит только белые элементы. Тогда, пользуясь соотношением (10.2), найдем, что
содержит только белые элементы. Тогда, пользуясь соотношением (10.2), найдем, что

 следует рассматривать не начальную вероятность появления значения «0», а финальную вероятность появления значения «0» на любом шаге определяемую формулой
следует рассматривать не начальную вероятность появления значения «0», а финальную вероятность появления значения «0» на любом шаге определяемую формулой

 для двух изображений
для двух изображений  типа синоптических карт. Пользуясь этими данными, можно найти среднее количество информации, приходящееся на серию длиной
типа синоптических карт. Пользуясь этими данными, можно найти среднее количество информации, приходящееся на серию длиной  . В случае равномерного распределения длин серий каждая серия длиной
. В случае равномерного распределения длин серий каждая серия длиной  содержала бы максимальное количество информации
содержала бы максимальное количество информации

 количество информации, приходящееся на один элемент серии. Однако распределение длин серий носит резко выраженный неравномерный характер. Средняя длина серии определяется как математическое ожидание случайной величины
количество информации, приходящееся на один элемент серии. Однако распределение длин серий носит резко выраженный неравномерный характер. Средняя длина серии определяется как математическое ожидание случайной величины  :
:

 из (10.4) и проведя суммирование,
из (10.4) и проведя суммирование,

 ,
,

 определится выражением
определится выражением

 от длины
от длины  . Анализируя кривые
. Анализируя кривые  можно сделать вывод, что существует некоторое оптимальное значение длины блока
можно сделать вывод, что существует некоторое оптимальное значение длины блока  , при котором коэффициент сжатия получается максимальным. Оно определяется прежде всего вероятностями
, при котором коэффициент сжатия получается максимальным. Оно определяется прежде всего вероятностями  которые в свою очередь зависят от разрешающей способности анализирующего устройства и конкретного изображения.
которые в свою очередь зависят от разрешающей способности анализирующего устройства и конкретного изображения.

 от длины
от длины  серии экспериментальная,
серии экспериментальная,  - теоретическая
- теоретическая
 . Статистические характеристики этих блоков можно получить, основываясь на рассмотренной выше модели марковской цепи. Подробнее с этими вопросами можно познакомиться в [10.2].
. Статистические характеристики этих блоков можно получить, основываясь на рассмотренной выше модели марковской цепи. Подробнее с этими вопросами можно познакомиться в [10.2].