Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 6.6. Алгоритмы распознавания, основанные на вычислении оценокЛогические алгоритмы распознавания, рассмотренные выше, в ряде случаев не позволяют получить однозначное решение о принадлежности распознаваемого объекта к определенному классу. Ю. И. Журавлевым предложен класс алгоритмов, называемый алгоритмами распознавания, основанными на вычислении оценок (АВО), который дает возможность получить однозначное решение о принадлежности объекта к определенному классу [19], [20]. Пусть множество объектов Опыт решения задач распознавания свидетельствует о том, что часто основная информация заключена не в отдельных признаках, а в их различных сочетаниях. Поскольку не всегда известно, какие именно сочетания информативны, то в алгоритмах типа АВО степень похожести объектов вычисляется не последовательным сопоставлением отдельных признаков, а сопоставлением всех возможных (или определенных) сочетаний признаков, входящих в описание объектов. Рассмотрим полный набор признаков Строки Рассмотрим процедуру вычисления оценок по подмножеству
представляют собой оценки строки со для соответствующих классов по системе опорных множеств алгоритма Пример. Заданы следующая таблица обучения и подлежащая распознаванию - строка
Пусть Применение вышеописанной процедуры вычисления оценок позволяет получить следующее:
Согласно решающему правилу, реализующему принцип простого большинства голосов, и так как Определение класса АВО сводится к формализации следующих этапов, соответствующих последовательности реализации процедуры распознавания: 1) выделяется система опорных множеств алгоритма, по которым производится анализ распознаваемых объектов; 2) вводится понятие близости на множестве частей описаний объектов; 3) задаются правила: а) позволяющее по вычисленной оценке степени подобия эталонного и распознаваемого объектов вычислить величину, называемую оценкой для пар объектов; б) формирования величин оценок для каждого из эталонных классов по фиксированному опорному множеству на основе оценок для пар объектов; в) формирования суммарной оценки для каждого из эталонных классов по всем опорным подмножествам; г) принятия решения, которое на основе оценок для классов обеспечивает отнесение распознаваемого объекта к одному из классов или отказывает ему в классификации. Фиксация способа выбора системы опорных множеств, типа функции близости, правил вычисления оценок и решающего правила определяет выбор подкласса алгоритмов типа АВО, а задание значений соответствующих параметров — конкретный алгоритм типа АВО. Модель класса — параметрическая, т. е. имеет место взаимно однозначное соответствие между конкретными алгоритмами и наборами числовых параметров. В. таком случае задание конкретного алгоритма, принадлежащего рассматриваемому классу, позволяет сопоставить ему значение функционала качества (например, число ошибок и отказов от распознавания на таблице обучения) и, следовательно, определить последний на точках параметрического пространства алгоритма. Если строить вычислительную процедуру по данному выше описанию алгоритма, то при большой мощности системы опорных множеств требуется значительное число машинных операций. Особенность и важнейшее достоинство класса АВО в том, что для вычисления оценок, определяющих принадлежность распознаваемого объекта, существуют простые аналитические формулы, заменяющие сложные переборные процедуры (возникающие при вычислении оценок близости по системе опорных множеств). Поскольку эффективность (в вычислительном смысле) вычисления функционала качества в АВО полностью определяется эффективностью процедуры вычисления оценок, то принципиально возможно построение оптимального алгоритма. В случаях, когда может быть найден абсолютно экстремальный алгоритм, имеется гарантия, что при заданном исходном материале Остановимся на аналитических формулах, обеспечивающих эффективное вычисление оценок 1. Эффективные формулы, моделирующие работу АВО при наличии ограничений на систему опорных множеств [19], [20]: а)
где б)
Пример. Проиллюстрируем применение (6.67) на задаче, рассмотренной в предыдущем примере. Для вычисления оценок распознаваемой строки со по классам Отметим, что число непустых подмножеств множества из шести признаков равно 2. Эффективные формулы, моделирующие работу АВО при отсутствии ограничений на систему опорных множеств [24]. Практика распознавания показывает, что в некоторых случаях априори известны поднаборы признаков, которые следует учитывать при сопоставлении распознаваемого объекта с объектами обучающей таблицы. Эти подмножества признаков не всегда совпадают с частными случаями (6.66) и (6.67); они могут иметь различную длину, исключать запрещенные комбинации и т. п. В [24] аналитические формулы получены для случая произвольных опорных множеств. Расширение области применения АВО основано на введении характеристической булевой функции системы опорных множеств алгоритма между подмножествами множества признаков и булевыми векторами длины N (вершинами Пример. Заданы таблица обучения и подлежащая распознаванию строка (см. скан) Закодировав вхождение признака в опорное множество через 1, а невхождение — через 0, каждому подмножеству множества признаков
Рис. 6.3 На множестве этих векторов можно определить характеристическую булеву функцию, единицы которой будут определять подмножества множества признаков, включенные в систему опорных множеств алгоритма Пусть В [24] показано, что в тех случаях, когда множество единиц Система опорных множеств организована следующим образом (соответствующий интервал представлен ребром, соединяющим вершины 6 и 14): в нее включены все признаки, входящие в ДНФ характеристической функции без отрицания Эффективная аналитическая формула для вычисления оценок в. тех случаях, когда характеристической функции системы опорных множеств соответствует интервал, имеет вид
В (6.68) учитывается вклад только тех строк таблицы обучения, («эффективных»), постоянная часть которых (в нашем случае Таким образом, при условии Полученный результат означает, что при указанном выборе системы опорных множеств строка со не классифицируется. Если характеристической функции соответствует сумма непересекающихся интервалов (представляется ортогональной В [24] показано, что сложность формулы вычисления оценок в АВО при произвольном представляющей характеристическую функцию системы опорных множеств алгоритма. Это означает, что построение простой формулы для вычисления оценок Таким образом, если для вычисления расстояний Число операций при распознавании одного объекта в фиксированном алгоритме А пропорционально «площади» таблицы Таблица 6.5. (см. скан) Класс АВО успешно используется для решения задач медицинской диагностики, прогнозирования геологического и свойств химических соединений, идентификации и управления технологическими процессами, оптимального выбора алгоритма и оптимизации процесса принятия решений, обработки результатов биологического эксперимента. Алгоритмы этого класса позволяют решать задачи распознавания всех основных типов: отнесение объекта к одному из заданных классов, автоматическая классификация, выбор системы признаков для описания объектов распознавания и оценка их информативности.
|
 |
Оглавление
|










































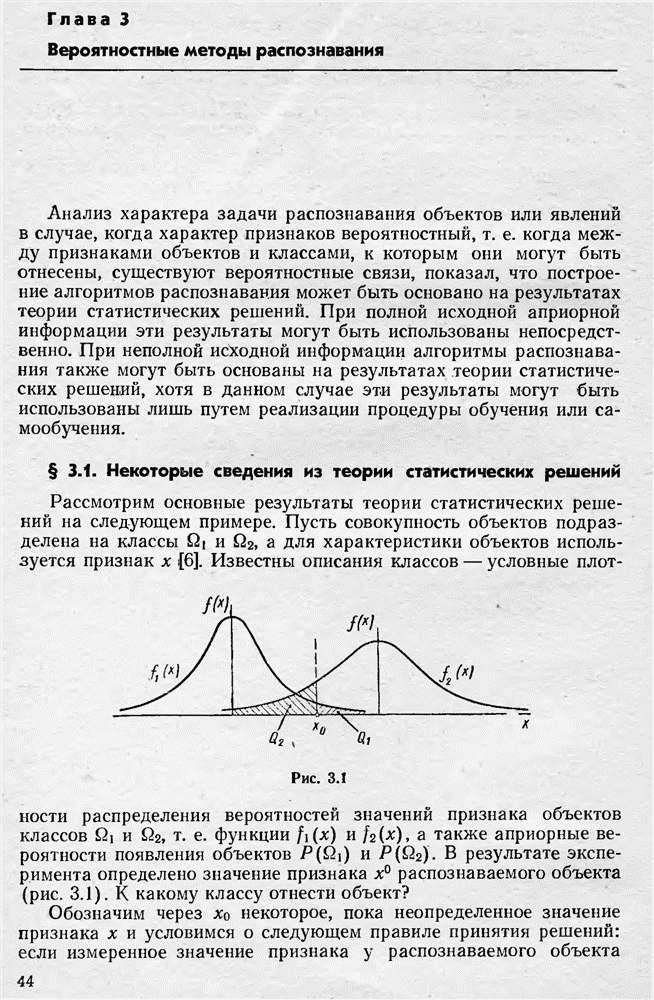
















































































































































































 подразделено на классы
подразделено на классы  и для описания объектов используются признаки
и для описания объектов используются признаки  Все объекты описываются одним и тем же набором признаков. Каждый из признаков может принимать значения из различных множеств, например из следующих:
Все объекты описываются одним и тем же набором признаков. Каждый из признаков может принимать значения из различных множеств, например из следующих:  признак не выражен,
признак не выражен,  -признак выражен;
-признак выражен;  информация о признаке отсутствует;
информация о признаке отсутствует;  степень выраженности признака имеет различные градации;
степень выраженности признака имеет различные градации;  признак принимает значения из числового отрезка;
признак принимает значения из числового отрезка;  условная плотность распределения значений признаков. Априорная информация представляется в виде таблицы обучения
условная плотность распределения значений признаков. Априорная информация представляется в виде таблицы обучения  Алгоритм распознавания сравнивает описание распознаваемого объекта
Алгоритм распознавания сравнивает описание распознаваемого объекта  и принимает решение о том, к какому классу отнести объект. Классификация основана на вычислении степени похожести (оценки) распознаваемой строки на строки, принадлежность которых к классам известна. Эта процедура включает в себя два этапа: сначала подсчитывается оценка для каждой строки из
и принимает решение о том, к какому классу отнести объект. Классификация основана на вычислении степени похожести (оценки) распознаваемой строки на строки, принадлежность которых к классам известна. Эта процедура включает в себя два этапа: сначала подсчитывается оценка для каждой строки из  а затем полученные оценки используются для получения суммарных оценок по каждому из классов
а затем полученные оценки используются для получения суммарных оценок по каждому из классов 
 и выделим систему подмножеств множества признаков (систему опорных множеств алгоритма)
и выделим систему подмножеств множества признаков (систему опорных множеств алгоритма)  . В АВО при наличии ограничений на систему опорных множеств обычно рассматриваются либо все подмножества множества признаков фиксированной длины
. В АВО при наличии ограничений на систему опорных множеств обычно рассматриваются либо все подмножества множества признаков фиксированной длины  либо вообще все подмножества множества признаков. Удалим произвольный поднабор признаков из строк
либо вообще все подмножества множества признаков. Удалим произвольный поднабор признаков из строк  согт,
согт,  и обозначим полученные строки через
и обозначим полученные строки через  Правило близости, позволяющее оценить похожесть строк
Правило близости, позволяющее оценить похожесть строк  состоит в следующем. Пусть «усеченные» строки содержат
состоит в следующем. Пусть «усеченные» строки содержат  первых признаков, т. е.
первых признаков, т. е.  и заданы пороги
и заданы пороги 
 считаются похожими, если выполняется не менее чем
считаются похожими, если выполняется не менее чем  неравенств вида
неравенств вида  Величины
Величины  входят в качестве параметров в модель класса алгоритмов типа АВО.
входят в качестве параметров в модель класса алгоритмов типа АВО.
 Для остальных подмножеств она полностью аналогична. В таблице
Для остальных подмножеств она полностью аналогична. В таблице  выделяются столбцы, соответствующие признакам, входящим в
выделяются столбцы, соответствующие признакам, входящим в  остальные столбцы вычеркиваются. Проверяется близость строки
остальные столбцы вычеркиваются. Проверяется близость строки  со строками
со строками  принадлежащими классу
принадлежащими классу
 . Число строк этого класса, близких по выбранному критерию классифицируемой строке
. Число строк этого класса, близких по выбранному критерию классифицируемой строке  обозначается через
обозначается через  последняя величина представляет собой оценку строки
последняя величина представляет собой оценку строки  для класса
для класса  по опорному множеству
по опорному множеству  Аналогичным образом вычисляются оценки для остальных классов:
Аналогичным образом вычисляются оценки для остальных классов:  Применение подобной процедуры ко всем остальным опорным множествам алгоритма позволяет получить систему оценок
Применение подобной процедуры ко всем остальным опорным множествам алгоритма позволяет получить систему оценок  Величины
Величины

 На основании анализа этих величин принимается решение либо об отнесении объекта сок одному из классов
На основании анализа этих величин принимается решение либо об отнесении объекта сок одному из классов  либо об отказе от его распознавания. Решающее правило может принимать различные формы, в частности распознаваемая строка может быть отнесена к классу, которому соответствует максимальная оценка, либо эта оценка будет превышать оценки всех остальных классов не меньше чем на определенную пороговую величину
либо об отказе от его распознавания. Решающее правило может принимать различные формы, в частности распознаваемая строка может быть отнесена к классу, которому соответствует максимальная оценка, либо эта оценка будет превышать оценки всех остальных классов не меньше чем на определенную пороговую величину  либо величина отношения соответствующей оценки к сумме оценок для всех остальных классов будет не менее величины порога
либо величина отношения соответствующей оценки к сумме оценок для всех остальных классов будет не менее величины порога  и т. д. Параметры типа
и т. д. Параметры типа  такжевключаются в модель АВО.
такжевключаются в модель АВО.


 строки будем считать близкими, если они полностью совпадают.
строки будем считать близкими, если они полностью совпадают.

 строка со зачисляется в класс
строка со зачисляется в класс 
 в данном классе алгоритмов не существует лучшего алгоритма распознавания.
в данном классе алгоритмов не существует лучшего алгоритма распознавания.
 при различных способах задания системы опорных множеств
при различных способах задания системы опорных множеств 
 совпадает с системой всех подмножеств мощности
совпадает с системой всех подмножеств мощности  множества
множества 

 -число выполненных неравенств вида
-число выполненных неравенств вида 
 совпадает с системой всех непустых подмножеств множества
совпадает с системой всех непустых подмножеств множества 

 необходимо определить величины
необходимо определить величины  ; как и раньше, будем полагать
; как и раньше, будем полагать  . В таком случае имеем:
. В таком случае имеем:  Применение (6.67) позволяет вычислить значения оценок:
Применение (6.67) позволяет вычислить значения оценок:  . Из полученных результатов видна принадлежность строки со классу
. Из полученных результатов видна принадлежность строки со классу  Расхождение с результатом предыдущего примера определяется выбором системы опорных множеств и подчеркивает необходимость чрезвычайно внимательного отношения к тому, по каким признакам или их комбинациям следует сопоставлять объекты при распознавании.
Расхождение с результатом предыдущего примера определяется выбором системы опорных множеств и подчеркивает необходимость чрезвычайно внимательного отношения к тому, по каким признакам или их комбинациям следует сопоставлять объекты при распознавании.
 и при отсутствии формулы, элиминирующей перебор, процедуру прямого сравнения со со строками из обучающей таблицы по всем опорным множествам пришлось бы выполнить
и при отсутствии формулы, элиминирующей перебор, процедуру прямого сравнения со со строками из обучающей таблицы по всем опорным множествам пришлось бы выполнить  раз.
раз.
 и установлении взаимно однозначного соответствия
и установлении взаимно однозначного соответствия
 -мерного единичного куба) [24], [25].
-мерного единичного куба) [24], [25].

 можно сопоставить бинарный вектор, или, что то же самое, вершину единичного «четырехмерного куба (рис. 6.3).
можно сопоставить бинарный вектор, или, что то же самое, вершину единичного «четырехмерного куба (рис. 6.3).


 (вершина 6),
(вершина 6),  (вершина 14). В таком случае
(вершина 14). В таком случае 
 образует в единичном
образует в единичном  -мерном кубе интервал или сумму непересекающихся интервалов, также существуют аналитические формулы для вычисления оценок. Напомним, что подмножество вершин единичного
-мерном кубе интервал или сумму непересекающихся интервалов, также существуют аналитические формулы для вычисления оценок. Напомним, что подмножество вершин единичного  -мерного куба называется интервалом, если оно соответствует некоторой элементарной конъюнкции. Очевидно, что все грани, ребра и вершины единичного
-мерного куба называется интервалом, если оно соответствует некоторой элементарной конъюнкции. Очевидно, что все грани, ребра и вершины единичного  -мерного куба являются интервалами.
-мерного куба являются интервалами.
 не включены признаки, входящие в ДНФ с отрицанием
не включены признаки, входящие в ДНФ с отрицанием  а по остальным признакам
а по остальным признакам  происходит полная вариация, т. е. рассматриваются подмножества, как включающие, так и не включающие эти признаки
происходит полная вариация, т. е. рассматриваются подмножества, как включающие, так и не включающие эти признаки 

 близка постоянной части
близка постоянной части  — число выполненных неравенств вида
— число выполненных неравенств вида  на варьируемой части (в нашем случае
на варьируемой части (в нашем случае 
 и учитывая, что эффективны в
и учитывая, что эффективны в  строки юг и
строки юг и  строки
строки  имеем:
имеем: 
 как, например, в случаях
как, например, в случаях  (вершина 6),
(вершина 6),  (вершина 14),
(вершина 14),  (вершина 11),
(вершина 11),  (вершина 10),
(вершина 10),  (вершина
(вершина  то при вычислении оценок (6.68) применяется к каждому интервалу отдельно и результаты суммируются.
то при вычислении оценок (6.68) применяется к каждому интервалу отдельно и результаты суммируются.
 пропорциональна сложности ДНФ,
пропорциональна сложности ДНФ,
 связано с задачей минимизации булевых функций в классе
связано с задачей минимизации булевых функций в классе  а точнее — с задачей построения кратчайшей ортогональной ДНФ или ДНФ, в которой каждый интервал имеет небольшое число пересечений с соседними. В общем случае задача такого синтеза неразрешима и потому следует пользоваться приближенными алгоритмами, обеспечивающими получение «достаточно простых» ортогональных ДНФ или ДНФ с небольшим числом взаимных пересечений интервалов [24], [25].
а точнее — с задачей построения кратчайшей ортогональной ДНФ или ДНФ, в которой каждый интервал имеет небольшое число пересечений с соседними. В общем случае задача такого синтеза неразрешима и потому следует пользоваться приближенными алгоритмами, обеспечивающими получение «достаточно простых» ортогональных ДНФ или ДНФ с небольшим числом взаимных пересечений интервалов [24], [25].
 существует эффективный алгоритм и число операций при одном таком вычислении не превосходит некоторой величины
существует эффективный алгоритм и число операций при одном таком вычислении не превосходит некоторой величины  то число операций при вычислении всех величин
то число операций при вычислении всех величин  не превосходит
не превосходит 
 с коэффициентом пропорциональности, не превосходящим
с коэффициентом пропорциональности, не превосходящим  (табл. 6.5). Сведение задачи построения экстремальных алгоритмов типа АВО к отысканию экстремумов функции многих переменных было обосновано Ю. И. Журавлевым (19]. Для проведения оптимизации могут быть применены методы переборного типа (при небольшом числе параметров), градиентного типа или случайного поиска.
(табл. 6.5). Сведение задачи построения экстремальных алгоритмов типа АВО к отысканию экстремумов функции многих переменных было обосновано Ю. И. Журавлевым (19]. Для проведения оптимизации могут быть применены методы переборного типа (при небольшом числе параметров), градиентного типа или случайного поиска.