Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Глава 2. Методы обработки априорной информацииПостроение и функционирование систем распознавания связано с накоплением и анализом априорной информации. Рассмотрим основные методы обработки априорной информации в системах распознавания без обучения, с обучением и с самообучением. В каждой из названных систем объем первоначальной априорной информации различен: в системе распознавания без обучения конкретных объектов или явлений он больше, чем в обучающейся системе распознавания тех же объектов, а в последней больше, чем в самообучающейся системе распознавания. Это обстоятельство и предопределяет существование различных методов обработки исходной априорной информации, цель которой — описание классов объектов на языке словаря признаков. § 2.1. Системы распознавания без обученияПостроение систем распознавания без обучения возможно при наличии полной первоначальной априорной информации, которая представляет собой совокупность: сведений о том, какова естественная или социальная природа объектов или явлений, для распознавания которых предназначается создаваемая система, какие решения могут и будут приниматься на основе результатов распознавания. Подобные сведения - исходные для определения принципа классификации и проведения собственно классификации, т. е. подразделения всего множества объектов или явлений на классы; данных, обеспечивающих построение априорного словаря признаков системы распознавания, и сведений относительно ограничений, накладываемых на создание измерительной аппаратуры системы; зависимостей между классами объектов Описание классов на языке признаков после составления алгоритмов распознавания, базирующихся на соответствующей мере близости, позволяет решить задачу построения рабочего словаря признаков системы распознавания и затем вновь вернуться к задаче описания классов, но уже на языке рабочего словаря признаков Для обсуждения задачи накопления и анализа априорной информации, носящей логический характер, и описания классов на языке логических признаков требуются специальные знания в области алгебры логики. Именно поэтому данная задача рассматривается непосредственно вслед за изложением основ теории алгебры логики. Построение функций Построение систем распознавания без обучения возможно, если либо априорно известны вид и параметры функций Устанавливают, существует ли вероятностная зависимость между признаками Если построение признакового пространства осуществляется с учетом ограничений, естественным образом накладываемых на создание измерительной аппаратуры, то связь между признаками либо вообще отсутствует, либо, не делая слишком грубых допущений, ею можно пренебречь без существенных последствий для эффективности системы распознавания. С точки зрения практики построения систем распознавания это обстоятельство имеет существенное значение, так как размещение в ЭВМ априорной информации в виде многомерных законов распределений требует значительных расходов памяти. Это в свою очередь приводит к необходимости записывать априорную информацию во внешних накопителях, что увеличивает время решения задачи распознавания. Значение этого вопроса еще больше возрастает тогда, когда уточнение априорной информации происходит сравнительно часто, поскольку практически часто осуществлять построение многомерных законов распределений затруднительно даже при использовании современной вычислительной техники. Итак, чтобы определить, существует ли вероятностная зависимость между признаками утверждать, что признаки подчинены нормальному, закону распределения, то для суждения о вероятностной зависимости между ними достаточно проверить наличие между признаками корреляции следующим способом. Пусть проведено
где Оценка для коэффициента корреляции
где При малой выборке и сравнительно высокой корреляции следует с помощью преобразования Фишера проверить, не отличается ли существенно полученное значение Ты от коэффициента корреляции в общей совокупности Если
где число степеней свободы
Чтобы установить, действительно ли некоррелированы признаки в общей совокупности, следует при принятом уровне значимости с помощью специально разработанных таблиц определить, не превосходит ли рассчитанное значение
Если рассчитанное значение Следующий шаг при анализе априорных статистических данных — подбор кривой распределения, сглаживающей изучаемый ряд распределения. Задача сглаживания или выравнивания априорных статистических данных состоит в представлении их в наиболее компактном виде с помощью простых аналитических зависимостей. Выравнивание статистических рядов — это подбор теоретической плавной кривой распределения, которая с той или другой точки зрения наилучшим образом описывала бы данное статистическое распределение. Принципиальный вид теоретической кривой распределения может быть выбран либо на основе анализа существа задачи описания распознаваемых объектов на языке признаков, либо просто по внешнему виду статистического распределения. При этом любая аналитическая функция, с помощью которой производится выравнивание статистического распределения, должна обладать основными свойствами функции распределения:
Если вид функции известен или выбран из тех или других соображений и функция зависит от некоторых параметров При решении задачи выравнивания может оказаться полезной система кривых Пирсона, каждая из которых в общем случае зависит от четырех параметров. Выбор этих параметров производится так, чтобы сохранить первые четыре момента статистического распределения — математическое ожидание, дисперсию, третий и четвертый моменты. Задачу выравнивания статистических распределений необходимо завершать проверкой правдоподобия гипотез, т. е. исследованием вопроса о согласовании теоретического (гипотетического) и исходного априорного (эмпирического) распределений. Проверка может быть произведена с помощью критериев согласия (критериев соответствия), которые основаны на выборе определенной меры расхождения между названными распределениями [1, 2]. Если гипотеза о теоретическом распределении не отвергается, то может быть принято окончательное решение о виде и значениях параметров функции распределения таблица чисел
Построим статистический ряд распределений, полагая, что
На основании изучения законов изменения во времени границ признака
а также параметр
где Найдем значения функции
а затем аппроксимируем ее тригонометрическим полиномом
таким образом, чтобы
В практике построения систем распознавания бывают ситуации, когда отсутствуют данные, необходимые для построения функции распределения, но известны границы интервалов изменения признаков
В случае, когда признаки Далее будем полагать, что
где Как правило, ошибки измерения подчиняются нормальному закону. Пусть
где Теперь необходимо найти совместный закон распределения суммы двух независимых случайных величин, или, иначе, композицию законов распределений:
где
Пусть
Здесь подынтегральная функция есть нормальный закон распределения с центром рассеивания
где В данном случае
Построение функций
где В некоторых системах распознавания, в частности в системах медицинской диагностики, Эвристический подход к описанию классов. Когда непосредственное изучение априорной информации невозможно, приходится прибегать к эвристическому конструированию законов распределений значений признаков по классам Задача определения функций
Положим, что при определении значения признака
Будем полагать следующее: статистическая вероятность того, что значение признака
Это соотношение позволяет сформировать статистические ряды:
а на их основе путем сглаживания определить оценки искомых функций распределения вероятностей Метод определения функций
|
 |
Оглавление
|


























































































































































































































 и признаками априорного словаря
и признаками априорного словаря  которыми они характеризуются, или сведений, достаточных для непосредственного составления подобных зависимостей.
которыми они характеризуются, или сведений, достаточных для непосредственного составления подобных зависимостей.

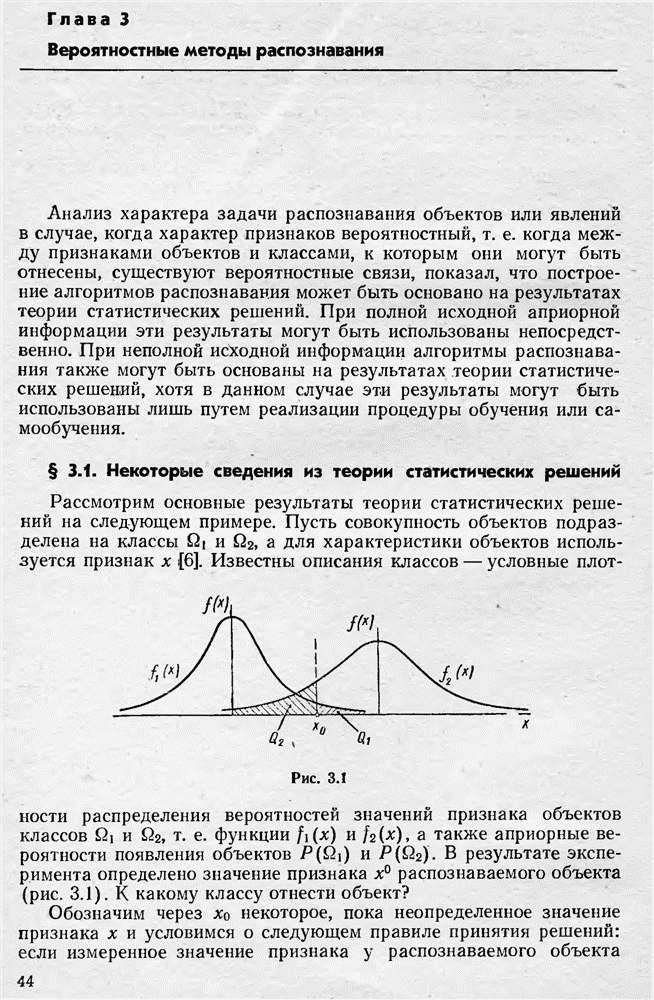
 Когда признаки — вероятностные, то описаниями классов являются условные плотности распределения вероятностей значений признаков
Когда признаки — вероятностные, то описаниями классов являются условные плотности распределения вероятностей значений признаков  для каждого класса
для каждого класса  т. е. функции
т. е. функции  а также априорные вероятности появления объектов соответствующих классов, т. е. функции
а также априорные вероятности появления объектов соответствующих классов, т. е. функции 
 функции
функции  а также платежная матрица (1.7), либо объем исходной априорной информации позволяет непосредственной обработкой исходных данных определить эти функциональные зависимости с точностью, обеспечивающей решение задач распознавания с заданной вероятностью ошибочных решений. Практически последнее реализуемо тогда, когда функции распределения вероятностей известны с точностью до значения параметров или когда координаты вектора признаков
а также платежная матрица (1.7), либо объем исходной априорной информации позволяет непосредственной обработкой исходных данных определить эти функциональные зависимости с точностью, обеспечивающей решение задач распознавания с заданной вероятностью ошибочных решений. Практически последнее реализуемо тогда, когда функции распределения вероятностей известны с точностью до значения параметров или когда координаты вектора признаков  распределены независимо, поскольку в этом случае задача восстановления
распределены независимо, поскольку в этом случае задача восстановления  -мерных функций распределения вероятностей (их число равно числу классов) вырождается в задачу восстановления
-мерных функций распределения вероятностей (их число равно числу классов) вырождается в задачу восстановления  одномерных функций
одномерных функций  Поэтому исходную информацию целесообразно анализировать в определенной последовательности.
Поэтому исходную информацию целесообразно анализировать в определенной последовательности.

 надо установить, не «Подчинены ли случайные величины
надо установить, не «Подчинены ли случайные величины  нормальному закону распределения. Если из физических соображений можно однозначно
нормальному закону распределения. Если из физических соображений можно однозначно
 экспериментов, в результате которых установлено
экспериментов, в результате которых установлено  пар значений признаков
пар значений признаков  Тогда несмещенная оценка для корреляционного момента
Тогда несмещенная оценка для корреляционного момента

 — оценки математических ожиданий значений признаков
— оценки математических ожиданий значений признаков 

 оценки среднеквадратичных отклонений величин
оценки среднеквадратичных отклонений величин  .
.

 то необходимо проверить, соответствует ли это факту отсутствия корреляции в общей совокупности. Проверка может быть осуществлена с помощью критерия
то необходимо проверить, соответствует ли это факту отсутствия корреляции в общей совокупности. Проверка может быть осуществлена с помощью критерия  в данном случае равного
в данном случае равного


 значения, приведенного в таблице; если не превосходит, то можно полагать, что корреляция между признаками в общей совокупности отсутствует [2]. Критерий
значения, приведенного в таблице; если не превосходит, то можно полагать, что корреляция между признаками в общей совокупности отсутствует [2]. Критерий  надлежит использовать для проверки связи только при нормальном законе распределения, однако им можно пользоваться и для других распределений, не слишком отличающихся от нормальных. Для величин
надлежит использовать для проверки связи только при нормальном законе распределения, однако им можно пользоваться и для других распределений, не слишком отличающихся от нормальных. Для величин  при известных
при известных  и выбранных доверительных вероятностях составлены специальные таблицы. Так, при вероятности правильного решения
и выбранных доверительных вероятностях составлены специальные таблицы. Так, при вероятности правильного решения  таблица имеет следующий вид:
таблица имеет следующий вид:

 меньше приведенного, то с
меньше приведенного, то с  статистическая связь между признаками отсутствует, и наоборот
статистическая связь между признаками отсутствует, и наоборот 

 то в качестве метода, обеспечивающего наилучшее описание априорного статистического материала, может быть взят метод моментов. В соответствии с этим методом параметры
то в качестве метода, обеспечивающего наилучшее описание априорного статистического материала, может быть взят метод моментов. В соответствии с этим методом параметры  выбираются так, чтобы несколько важнейших числовых характеристик (моментов) аппроксимирующего распределения были равны соответствующим статистическим характеристикам.
выбираются так, чтобы несколько важнейших числовых характеристик (моментов) аппроксимирующего распределения были равны соответствующим статистическим характеристикам.
 При этом если функция может быть представлена в виде произведения:
При этом если функция может быть представлена в виде произведения:  то признаки
то признаки  независимы. Применительно к случаю независимости признаков построение функций
независимы. Применительно к случаю независимости признаков построение функций  удобно запрограммировать в следующем виде [3]. Пусть составлена
удобно запрограммировать в следующем виде [3]. Пусть составлена
 для
для  класса. Определим максимальное и минимальное значения признака и весь диапазон разобьем на
класса. Определим максимальное и минимальное значения признака и весь диапазон разобьем на  интервалов. Вычислим величину
интервалов. Вычислим величину


 для каждого класса определим
для каждого класса определим  Введем в рассмотрение вспомогательную величину
Введем в рассмотрение вспомогательную величину

 следующим образом зависящий от
следующим образом зависящий от 

 — значение признака
— значение признака  в середине каждого интервала,
в середине каждого интервала, 
 в точках
в точках 


 Тогда искомая функция распределения
Тогда искомая функция распределения

 и относительно закона распределения уместно предположение, что он равномерен. Пусть
и относительно закона распределения уместно предположение, что он равномерен. Пусть

 измеряются с ошибками
измеряются с ошибками 

 — значение признака для
— значение признака для  класса
класса 

 —математическое ожидание ошибки измерения
—математическое ожидание ошибки измерения  признака;
признака;  ее среднеквадратичное значение.
ее среднеквадратичное значение.

 — символ композиции [1].
— символ композиции [1].

 тогда
тогда

 и средним квадратичным отклонением а, а интеграл есть вероятность попадания случайной величины, подчиненной этому закону, на участок
и средним квадратичным отклонением а, а интеграл есть вероятность попадания случайной величины, подчиненной этому закону, на участок  Следовательно,
Следовательно,

 — функция Лапласа.
— функция Лапласа.
 так как систематическая ошибка в измерении признаков
так как систематическая ошибка в измерении признаков  отсутствует и
отсутствует и  Поэтому
Поэтому

 Если априорная вероятность не зависит от времени, значения
Если априорная вероятность не зависит от времени, значения  могут быть определены на основании частот событий:
могут быть определены на основании частот событий:

 общее количество доступных изучению объектов во всех классах;
общее количество доступных изучению объектов во всех классах;  количество объектов в
количество объектов в  классе.
классе.
 может зависеть от времени. Это связано, например, с распространением эпидемии какого-либо заболевания, составляющего или входящего в определенный класс системы. При этом следует изучить поведение функций
может зависеть от времени. Это связано, например, с распространением эпидемии какого-либо заболевания, составляющего или входящего в определенный класс системы. При этом следует изучить поведение функций  во времени до текущего момента, а затем на основе тщательного изучения явления произвести их экстраполяцию на определенный промежуток времени.
во времени до текущего момента, а затем на основе тщательного изучения явления произвести их экстраполяцию на определенный промежуток времени.
 и функций
и функций 
 может быть решена следующим образом. Положим, что группа квалифицированных специалистов, веса мнений которых
может быть решена следующим образом. Положим, что группа квалифицированных специалистов, веса мнений которых  согласилась дать экспертные оценки возможных значений признаков
согласилась дать экспертные оценки возможных значений признаков  объектов всех классов. Пусть применительно к классу
объектов всех классов. Пусть применительно к классу  относительно признака
относительно признака  эксперт
эксперт  указал, что его значение составляет величину
указал, что его значение составляет величину  При этом, во-первых, некоторые из значений признака
При этом, во-первых, некоторые из значений признака  объектов класса
объектов класса  указанные разными экспертами, могут совпадать [например,
указанные разными экспертами, могут совпадать [например,  во-вторых, отдельные эксперты могут указать на несколько возможных значений признака
во-вторых, отдельные эксперты могут указать на несколько возможных значений признака  классе [например, вероятны следующие значения признака:
классе [например, вероятны следующие значения признака:  и т. д.]; в-третьих, кто-либо из экспертов может отказаться от указания о возможном значении некоторых признаков в ряде классов. Для наглядности суждения экспертов целесообразно свести в следующую таблицу:
и т. д.]; в-третьих, кто-либо из экспертов может отказаться от указания о возможном значении некоторых признаков в ряде классов. Для наглядности суждения экспертов целесообразно свести в следующую таблицу:

 применительно к объектам класса
применительно к объектам класса  эксперты подразделились на группы
эксперты подразделились на группы  при этом число экспертов в группе
при этом число экспертов в группе  равно
равно  Пусть группа экспертов
Пусть группа экспертов  указала, что значение признака
указала, что значение признака  в классе
в классе  составляет
составляет  Усредненный вес мнений экспертов группы
Усредненный вес мнений экспертов группы 

 у объектов, принадлежащих классу
у объектов, принадлежащих классу  равно величине
равно величине  указанной группой экспертов
указанной группой экспертов  пропорциональна усредненному весу мнений этой группы:
пропорциональна усредненному весу мнений этой группы:




 аналогичен приведенному. Таким образом, эвристический подход к формированию априорных сведений основывается на обработке результатов опроса группы экспертов с учетом их авторитета. При этом предполагается, что научно-технический уровень экспертов достаточно высок, а их решения носят объективный характер.
аналогичен приведенному. Таким образом, эвристический подход к формированию априорных сведений основывается на обработке результатов опроса группы экспертов с учетом их авторитета. При этом предполагается, что научно-технический уровень экспертов достаточно высок, а их решения носят объективный характер.