Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
§ 2.2. Обучающиеся системы распознаванияИспользование методов обучения для построения систем распознавания необходимо в случае, когда отсутствует полная первоначальная априорная информация. Ее объем позволяет подразделить объекты на классы и определить априорный словарь признаков. Однако объем априорной информации недостаточен для того, чтобы в многомерном признаковом пространстве путем непосредственной обработки исходных данных построить либо поверхности, которые в определенном смысле наилучшим образом разделяли бы это пространство на области, соответствующие классам, либо с достаточной точностью определить априорные вероятности появления объектов различных классов Рассмотрим суть процедуры обучения. Пусть исходная априорная информация позволяет составить список объектов с указанием, к какому классу каждый из них относится. Обозначим объекты этого списка через
Так как априорное признаковое пространство определено, то каждый объект может быть описан на языке признаков
Если признаки
либо если признаки статистически зависимы, но вид функций Если признаки статистически зависимы и вид функций распределения неизвестен, то обучающая последовательность может быть использована для того, чтобы в первом приближении определить гиперповерхности, разделяющие многомерное пространство на области, соответствующие классам. Однако ввиду того, что в рассматриваемом случае объем исходной информации не позволяет произвести достаточно точного описания классов, найденные границы классов не обеспечат предельно достижимой точности (безошибочности) решения задачи распознавания, ограниченной техническими характеристиками измерительной аппаратуры. Именно поэтому для уточнения описаний классов используется текущая апостериорная информация, образующаяся в результате функционирования предварительным образом сформированной системы в процессе распознавания неизвестных объектов, не относящихся к обучающей последовательности. Если обучающая последовательность достаточно представительна, т. е. содержит объекты, более или менее равномерно располагающиеся в областях признакового пространства, соответствующих классам, то в пределе подобная процедура приводит к достаточно точному описанию классов и, следовательно, к возможности определения таких границ классов, придерживаясь которых можно достичь потенциально достижимой точности работы системы распознавания. Пример. Пусть надлежит построить распознающее устройство для классификации объектов, подразделенных на классы и Обучающая выборка может быть использована для определения в первом приближении условных плотностей распределения значений признака
Рис. 2.1 Положим, что величина
то вероятность ошибки распознавания будет минимальна (см. § 3.1):
Вероятность ошибки определяется суммой площадей, которые ограничены осью абсцисс, а также осью ординат, проведенной в точке Точность работы распознающего устройства, определяемая отличаются от условных плотностей распределений В результате функционирования системы в режиме распознавания новых объектов образуется текущая (апостериорная) информация о принадлежности распознанных объектов соответствующим классам, которую можно использовать для непрерывной корректировки условных плотностей распределения. Обозначим через
соответствующая скорректированным описаниям классов Если образовавшаяся в процессе функционирования распознающего устройства апостериорная информация позволяет уточнить исходные априорные распределения и, значит,
где в предположении, что Каким условиям применительно к рассматриваемому примеру должна удовлетворять исходная выборка для того, чтобы процесс обучения протекал успешно? Предположим, что предварительно обученному распознающему устройству предъявлено для распознавания некоторое количество объектов. Пусть из числа Оценка математического ожидания значений признаков объектов класса
При достаточно большом истинному значению математического ожидания значений признаков объектов класса
Однако ввиду невозможности установить, какое количество объектов класса Обозначим оценку математического ожидания значений признаков объектов класса
Подставляя (2.30) и (2.31) в (2.29), получим
Новая оценка лучше исходной априорной оценки математического ожидания, если
или
где Аналогичные рассуждения применительно к классу
где Рассмотрим формальную постановку задачи обучения. При этом заметим следующее. Вслед за появлением первых работ в области распознавания, в частности работ Ф. Розенблатта, посвященных перцептрону, различными авторами был разработан целый ряд алгоритмов обучения. Только в середине 60-х годов Я. 3. Цыпкин установил, что все эти алгоритмы могут быть получены по одной и той же схеме (4, 5]. Дальнейшее изложение процедуры обучения осуществляется в соответствии с этой схемой. Пусть все множество объектов подразделено на классы В целях наглядности изложения ограничимся классами
где с Разделяющая функция представлена, как следует из (2.36), в виде некоторой функции скалярного произведения векторов
Наличие обучающей выборки озволяет получить указания о принадлежности объектов
Эти указания могут быть использованы для определения двух систем неравенств. Если с помощью разделяющей функции
а если ошибочно, то
В качестве меры уклонения
В процессе обучения предъявление объектов насколько хорошо выбрана разделяющая функция, целесообразно выбрать функционал, представляющий собой математическое ожидание меры уклонения:
Будем полагать, что наилучший выбор разделяющий функции сделан тогда, когда
При этом в качестве ограничивающего условия, накладываемого на получение оптимального решения, рассматривается вид разделяющей функции. Такова математическая постановка задачи. Относительно ее решения следует прежде всего сказать, что поскольку неизвестна плотность распределения, то неизвестно и математическое ожидание Этап 1. На основе использования априорной информации, содержащейся в обучающей последовательности, определяется значение вектора Этап 2. На этом этапе текущая апостериорная информация, полученная в результате распознавания этих объектов, используется для уточнения значения вектора Подразделение решения задачи на два этапа носит принципиальный характер, однако реализация каждого из этапов может быть достигнута применением единых алгоритмических методов. Пусть в некоторой системе протекает стационарный дискретный или непрерывный процесс, характеризуемый вектором
где Так как
Если функционал
где
— градиент функционала
— градиент случайного функционала Если функционал В условиях полной априорной, информации плотность распределения Отсутствие полной априорной информации заставляет для решения задачи определения вектора Алгоритм обучения (алгоритм определения оптимального вектора
а непрерывный алгоритм обучения может быть записан так:
В (2.50) и стремиться к нулю, так как только при этом условии вектор с Если
Обучение успешно в случае, когда алгоритмы обучения сходятся. Условия сходимости алгоритмов обучения в среднеквадратичном или почти наверное могут быть записаны так: для дискретного алгоритма обучения
или
где
или
где Возвратимся к исходной задаче обучения распознаванию объектов. Рассмотрим алгоритмы решения (2.46), заметив, что
или
где Подставляя (2.58) в (2.46), получаем
Полагая, что функционал
где
Применяя к (2.61) дискретный алгоритм обучения (2 50) либо непрерывный алгоритм (2.51), соответственно получим:
Пример. Пусть имеется обучающая совокупность объектов Если количество объектов, относящихся к каждому классу, достаточно велико, то значения априорных вероятностей могут быть определены с помощью (2.20). Если количество объектов, относящихся к каждому классу, сравнительно мало, то оценки априорных вероятностей могут быть определены на основе методов обучения. Для этого на первом этапе работы воспользуемся априорной информацией относительно принадлежности некоторых групп объектов обучающей совокупности соответствующим классам, т. е. информацией, содержащейся в соотношениях
Определим в первом приближении оценки:
На этом завершается первый этап работы. Положим, определены также в первом приближении оценки плотности вероятности Обозначим через
где Если
то последовательные оценки
|
 |
Оглавление
|


























































































































































































































 и условные плотности распределений
и условные плотности распределений 
 а классы — через
а классы — через  тогда исходная информация может быть представлена в виде
тогда исходная информация может быть представлена в виде

 Будем полагать, что значения признаков у объекта
Будем полагать, что значения признаков у объекта  составляют
составляют  у объекта
у объекта  составляют
составляют  и т. д. Тогда исходный список может быть представлен в виде обучающей последовательности или обучающей выборки:
и т. д. Тогда исходный список может быть представлен в виде обучающей последовательности или обучающей выборки:

 статистически независимы и функции условных плотностей распределения могут быть представлены в виде произведений:
статистически независимы и функции условных плотностей распределения могут быть представлены в виде произведений:

 пределения известен с точностью до значения параметров, то обучающая последовательность может быть использована для определения в первом приближении функций
пределения известен с точностью до значения параметров, то обучающая последовательность может быть использована для определения в первом приближении функций 
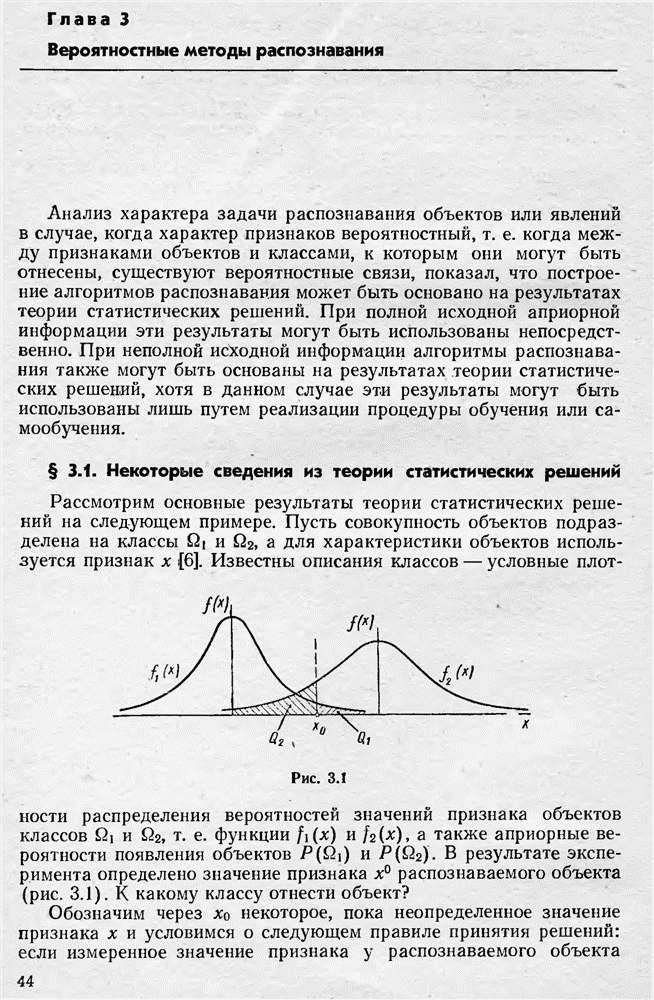
 Для описания объектов используется признак
Для описания объектов используется признак  Кроме того,
Кроме того, 
 по классам
по классам  (рис. 2.1).
(рис. 2.1).

 в каждом классе распределена по нормальному закону и обучающая выборка позволяет определить оценки параметров этих распределений — математических ожиданий
в каждом классе распределена по нормальному закону и обучающая выборка позволяет определить оценки параметров этих распределений — математических ожиданий  и среднеквадратичных отклонений
и среднеквадратичных отклонений  Пусть
Пусть  Тогда если в качестве границы между классами избрать
Тогда если в качестве границы между классами избрать


 и кривыми распределений
и кривыми распределений  на участке
на участке  на участке
на участке  (крупная штриховка).
(крупная штриховка).
 не равна предельно достижимой точности, ввиду того что в общем случае
не равна предельно достижимой точности, ввиду того что в общем случае 
 соответствующих генеральной совокупности объектов первого
соответствующих генеральной совокупности объектов первого  и второго
и второго  классов.
классов.
 скорректированные условные плотности распределений, полученные в результате совместной обработки исходной априорной информации и апостериорной информации, образовавшейся на некотором шаге работы распознающего устройства, а через и
скорректированные условные плотности распределений, полученные в результате совместной обработки исходной априорной информации и апостериорной информации, образовавшейся на некотором шаге работы распознающего устройства, а через и  оценки математических ожиданий признака
оценки математических ожиданий признака  в каждом классе. Пусть в этом случае
в каждом классе. Пусть в этом случае  Если в качестве границы, разделяющей классы, выбрать значение
Если в качестве границы, разделяющей классы, выбрать значение  то вероятность ошибки распознавания
то вероятность ошибки распознавания

 и также будет минимальна.
и также будет минимальна.
 точнее описывают классы
точнее описывают классы  чем
чем  то процесс обучения протекает успешно и
то процесс обучения протекает успешно и  Величина
Величина  на рис. 2.1 определяется суммой площадей, которые ограничены осью абсцисс, осью ординат, проведенной в точке
на рис. 2.1 определяется суммой площадей, которые ограничены осью абсцисс, осью ординат, проведенной в точке  и кривыми распределений
и кривыми распределений  на участке
на участке  на участке
на участке  (мелкая штриховка). В пределе может быть получена минимальная вероятность ошибочных решений:
(мелкая штриховка). В пределе может быть получена минимальная вероятность ошибочных решений:

 наилучшая граница между классами определяется величиной
наилучшая граница между классами определяется величиной  [здесь
[здесь  математические ожидания условных плотностей распределений объектов
математические ожидания условных плотностей распределений объектов  соответствующих генеральной совокупности классов
соответствующих генеральной совокупности классов  ].
].
 объектов, отнесенных распознающим устройством к первому классу,
объектов, отнесенных распознающим устройством к первому классу,  объектов действительно относятся к первому классу,
объектов действительно относятся к первому классу,  объектов принадлежат второму классу. Обозначим через
объектов принадлежат второму классу. Обозначим через  признаки объектов класса
признаки объектов класса  и через
и через  признаки объектов класса
признаки объектов класса 
 полученной выборки
полученной выборки

 величина
величина  приблизительно равна
приблизительно равна


 отнесено к классу
отнесено к классу  в качестве уточненной оценки математического ожидания значений признаков объектов класса
в качестве уточненной оценки математического ожидания значений признаков объектов класса  (в предположении, что число объектов, отнесенных распознающим устройством к классу
(в предположении, что число объектов, отнесенных распознающим устройством к классу  значительно больше, чем число объектов класса
значительно больше, чем число объектов класса  содержащихся в обучающей выборке) принимается величина
содержащихся в обучающей выборке) принимается величина  При этом величина
При этом величина  способствует ухудшению этой оценки.
способствует ухудшению этой оценки.
 отнесенных к классу
отнесенных к классу  через
через  и будем считать, что
и будем считать, что




 оценка математического ожидания значений признака объектов класса
оценка математического ожидания значений признака объектов класса  содержащихся в обучающей выборке.
содержащихся в обучающей выборке.
 приводят к следующему соотношению, определяющему условия уточнения оценки математического ожидания значений признаков объектов класса
приводят к следующему соотношению, определяющему условия уточнения оценки математического ожидания значений признаков объектов класса 

 оценка математического ожидания значений признаков объектов класса
оценка математического ожидания значений признаков объектов класса  ошибочно отнесенных к классу
ошибочно отнесенных к классу  число объектов, отнесенных к классу
число объектов, отнесенных к классу  из них
из них  правильно,
правильно,  оценка математического ожидания значений признака объектов класса
оценка математического ожидания значений признака объектов класса  содержащихся в обучающей выборке.
содержащихся в обучающей выборке.
 и определены вектор
и определены вектор  компоненты которого и составляют априорный словарь признаков, обучающая выборка фиксированной длины, т. е. объекты
компоненты которого и составляют априорный словарь признаков, обучающая выборка фиксированной длины, т. е. объекты  вектора, которыми они описываются в признаковом пространстве
вектора, которыми они описываются в признаковом пространстве  и принадлежность объектов соответствующим классам. Априорные вероятности
и принадлежность объектов соответствующим классам. Априорные вероятности  и условные плотности распределения
и условные плотности распределения  неизвестны. Требуется на основе предъявления системе распознавания объектов обучающей выборки с указанием классов, которым они принадлежат, построить в многомерном признаковом пространстве гиперповерхность, разделяющую это пространство на области
неизвестны. Требуется на основе предъявления системе распознавания объектов обучающей выборки с указанием классов, которым они принадлежат, построить в многомерном признаковом пространстве гиперповерхность, разделяющую это пространство на области  соответствующие классам
соответствующие классам  При этом разделение должно осуществляться в каком-либо смысле наилучшим образом.
При этом разделение должно осуществляться в каком-либо смысле наилучшим образом.
 т. е. ситуацией, носящей название дихотомии. К дихотомии можно последовательно свести и общий случай, когда число классов
т. е. ситуацией, носящей название дихотомии. К дихотомии можно последовательно свести и общий случай, когда число классов  Обозначим разделяющую функцию через
Обозначим разделяющую функцию через

 неизвестный вектор параметров.
неизвестный вектор параметров.
 и с. Знаки разделяющей функции определяют области в
и с. Знаки разделяющей функции определяют области в  -мерном признаковом пространстве
-мерном признаковом пространстве  соответствующие классам
соответствующие классам 

 классу
классу  или классу
или классу 

 объект классифицируется правильно, то
объект классифицируется правильно, то


 от у выберем некоторую выпуклую функцию от разности у и у:
от у выберем некоторую выпуклую функцию от разности у и у:

 осуществляется случайным образом, вследствие этого и мера уклонения также случайна, поэтому в качестве меры, характеризующей,
осуществляется случайным образом, вследствие этого и мера уклонения также случайна, поэтому в качестве меры, характеризующей,

 достигает минимума. Таким образом, задача сводится к определению вектора
достигает минимума. Таким образом, задача сводится к определению вектора  который доставляет
который доставляет

 которое определяется в соответствии с этой плотностью распределения. В этих условиях решение задачи, т. е. определение вектора
которое определяется в соответствии с этой плотностью распределения. В этих условиях решение задачи, т. е. определение вектора  требует реализации двух этапов.
требует реализации двух этапов.
 в первом приближении. Это дает возможность найти разделяющую поверхность, в первом приближении наилучшим образом разделяющую признаковое пространство на области, соответствующие классам, и организовать процесс распознавания новых объектов.
в первом приближении. Это дает возможность найти разделяющую поверхность, в первом приближении наилучшим образом разделяющую признаковое пространство на области, соответствующие классам, и организовать процесс распознавания новых объектов.
 и получения такого его значения
и получения такого его значения  при котором достигается минимальное значение вероятности ошибочных решений задачи распознавания.
при котором достигается минимальное значение вероятности ошибочных решений задачи распознавания.
 плотность распределения которого
плотность распределения которого  а также задан вектор
а также задан вектор  компоненты которого представляют собой либо значения характеристик управляющего воздействия на систему, либо значения ее параметров. Необходимо определить в каком-либо смысле наилучшее состояние системы. Наилучшее состояние может быть достигнуто за счет выбора соответствующего значения вектора с, поэтому в качестве функционала можно выбрать
компоненты которого представляют собой либо значения характеристик управляющего воздействия на систему, либо значения ее параметров. Необходимо определить в каком-либо смысле наилучшее состояние системы. Наилучшее состояние может быть достигнуто за счет выбора соответствующего значения вектора с, поэтому в качестве функционала можно выбрать

 - функционал вектора с, зависящий также от случайных реализаций процесса
- функционал вектора с, зависящий также от случайных реализаций процесса  пространство вектора
пространство вектора 
 для каждой реализации
для каждой реализации  случайный функционал, то
случайный функционал, то  математическое ожидание:
математическое ожидание:

 — непрерывно дифференцируем по с, то необходимые условия экстремума (2.46) можно записать в виде уравнения
— непрерывно дифференцируем по с, то необходимые условия экстремума (2.46) можно записать в виде уравнения


 по
по  , а
, а

 по
по  .
.
 выпуклый и имеет единственный экстремум, то условие (2.47) — необходимое и достаточное. В этом случае корень уравнения определяет оптимальное значение
выпуклый и имеет единственный экстремум, то условие (2.47) — необходимое и достаточное. В этом случае корень уравнения определяет оптимальное значение  при котором функционал
при котором функционал  достигает экстремума.
достигает экстремума.
 известна, поэтому функционал
известна, поэтому функционал  можно выразить в явной форме, а оптимальное значение
можно выразить в явной форме, а оптимальное значение  определить.
определить.
 применять методы обучения, используя на первом этапе априорную информацию, содержащуюся в обучающей выборке, и на втором этапе — текущую апостериорную информацию. Обучение как на основе априорной информации, так и на основе текущей апостериорной информации может быть организовано реализацией единой рекуррентной процедуры. Ее цель в том, чтобы на каждом шаге получать такое значение вектора с, которое с течением времени стремится к оптимальному значению
применять методы обучения, используя на первом этапе априорную информацию, содержащуюся в обучающей выборке, и на втором этапе — текущую апостериорную информацию. Обучение как на основе априорной информации, так и на основе текущей апостериорной информации может быть организовано реализацией единой рекуррентной процедуры. Ее цель в том, чтобы на каждом шаге получать такое значение вектора с, которое с течением времени стремится к оптимальному значению 
 должен позволять по наблюдаемым значениям вектора
должен позволять по наблюдаемым значениям вектора  определять либо оценку вектора
определять либо оценку вектора  на очередном
на очередном  шаге, если вектор с изменяется дискретно, либо оценку вектора
шаге, если вектор с изменяется дискретно, либо оценку вектора  если вектор с непрерывен, которая с течением времени стремится к оптимальному вектору
если вектор с непрерывен, которая с течением времени стремится к оптимальному вектору  Применительно к первой ситуации дискретный алгоритм обучения имеет вид
Применительно к первой ситуации дискретный алгоритм обучения имеет вид


 квадратная
квадратная  -мерная матрица, полная или диагональная, элементы которой зависят от текущего момента времени
-мерная матрица, полная или диагональная, элементы которой зависят от текущего момента времени  . С течением времени элементы матрицы должны
. С течением времени элементы матрицы должны
 стремится к оптимальному значению с вероятностью единица.
стремится к оптимальному значению с вероятностью единица.
 диагональная матрица (полная матрица соответствует линейному преобразованию диагональной) и ее элементы равны друг другу:
диагональная матрица (полная матрица соответствует линейному преобразованию диагональной) и ее элементы равны друг другу:

 единичная матрица), то алгоритмы обучения (2.50) и (2.51) представляют собой соответственно дискретные и непрерывные алгоритмы стохастической аппроксимации [5].
единичная матрица), то алгоритмы обучения (2.50) и (2.51) представляют собой соответственно дискретные и непрерывные алгоритмы стохастической аппроксимации [5].


 дискретная последовательность значений вектора с, полученных на основе дискретного алгоритма обучения; для непрерывного алгоритма обучения
дискретная последовательность значений вектора с, полученных на основе дискретного алгоритма обучения; для непрерывного алгоритма обучения


 - непрерывная последовательность значений вектора с, полученных на основе непрерывного алгоритма обучения.
- непрерывная последовательность значений вектора с, полученных на основе непрерывного алгоритма обучения.
 . Ограничивающее условие, накладываемое на поиск экстремума функционала
. Ограничивающее условие, накладываемое на поиск экстремума функционала  соблюдается, в частности, в случае, если
соблюдается, в частности, в случае, если  представляет собой конечную сумму:
представляет собой конечную сумму:


 -соответственно
-соответственно  -мерные векторы коэффициентов и линейно независимых функций;
-мерные векторы коэффициентов и линейно независимых функций;  знак транспонирования.
знак транспонирования.

 непрерывен по с, необходимые условия экстремума (2.59) можно записать в виде
непрерывен по с, необходимые условия экстремума (2.59) можно записать в виде



 относительно которых известно, какому из классов
относительно которых известно, какому из классов  каждый из них принадлежит. Требуется определить оценки априорных вероятностей
каждый из них принадлежит. Требуется определить оценки априорных вероятностей  появления объектов каждого класса.
появления объектов каждого класса.


 и таким образом выполнено первоначальное формирование системы распознавания. Пусть затем на вход системы поступают новые, неизвестные объекты и система начинает производить их классификацию. Это позволяет приступить ко второму этапу работы — последовательному уточнению оценок
и таким образом выполнено первоначальное формирование системы распознавания. Пусть затем на вход системы поступают новые, неизвестные объекты и система начинает производить их классификацию. Это позволяет приступить ко второму этапу работы — последовательному уточнению оценок  на основе использования текущей апостериорной информации, содержащейся в результатах отнесения новых объектов к соответствующим классам.
на основе использования текущей апостериорной информации, содержащейся в результатах отнесения новых объектов к соответствующим классам.
 количество объектов
количество объектов  класса, содержащихся в обучающей выборке, а через
класса, содержащихся в обучающей выборке, а через  количество объектов, отнесенных в результате распознавания
количество объектов, отнесенных в результате распознавания  объектов также к
объектов также к  классу. Тогда искомая последовательная оценка априорной вероятности на
классу. Тогда искомая последовательная оценка априорной вероятности на  шаге в соответствии с алгоритмом стохастической аппроксимации
шаге в соответствии с алгоритмом стохастической аппроксимации

 -оценка, полученная на предыдущем шаге (после распознавания
-оценка, полученная на предыдущем шаге (после распознавания  объектов).
объектов).
 выбрано так, что
выбрано так, что 

 стремятся к величине
стремятся к величине  в смысле среднего квадрата с вероятностью единица. На этом завершается второй этап работы.
в смысле среднего квадрата с вероятностью единица. На этом завершается второй этап работы.