Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
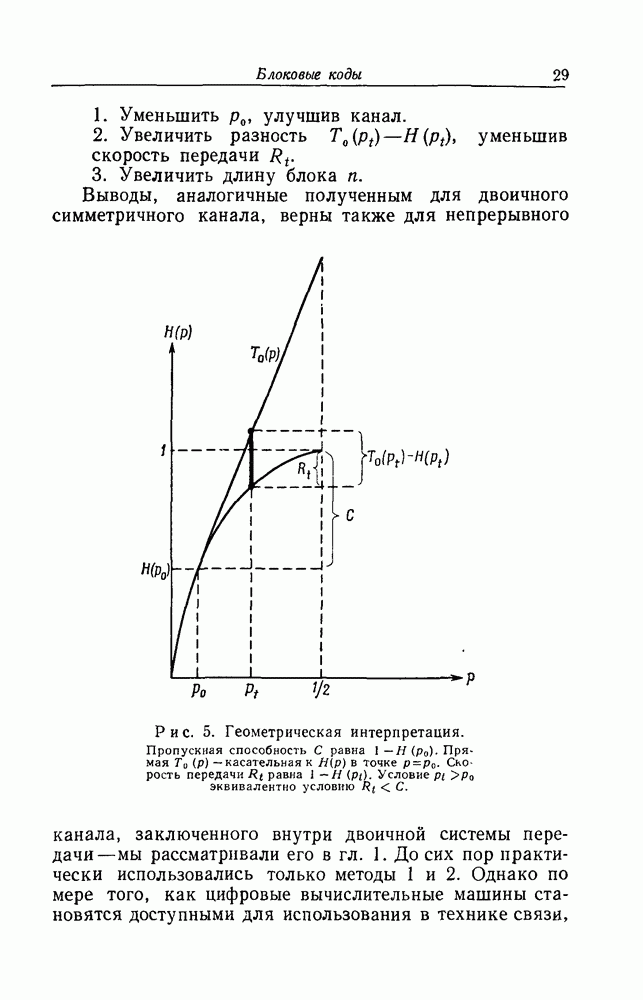
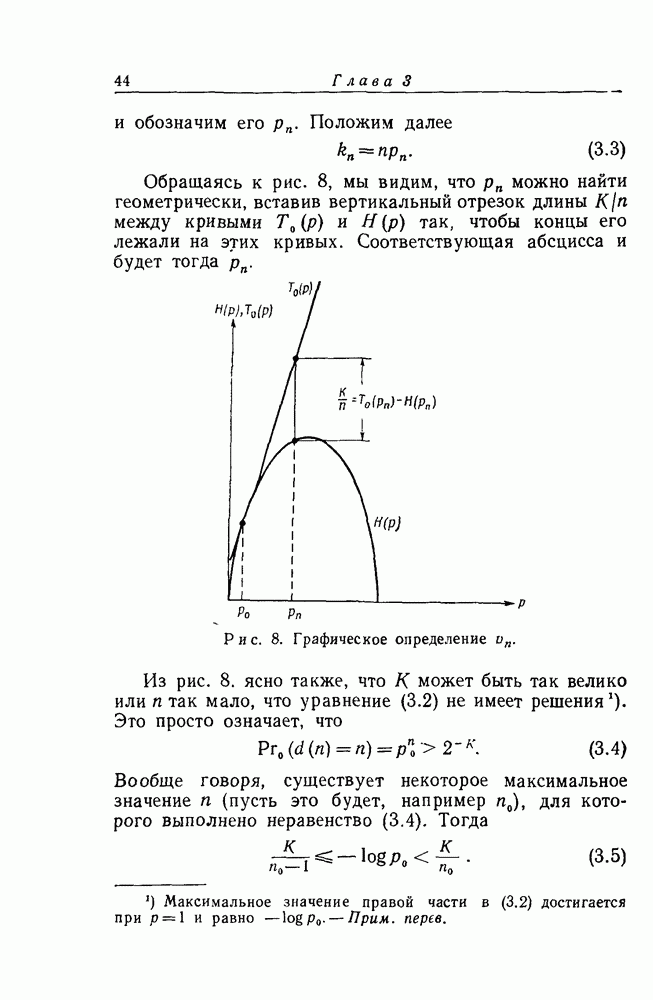
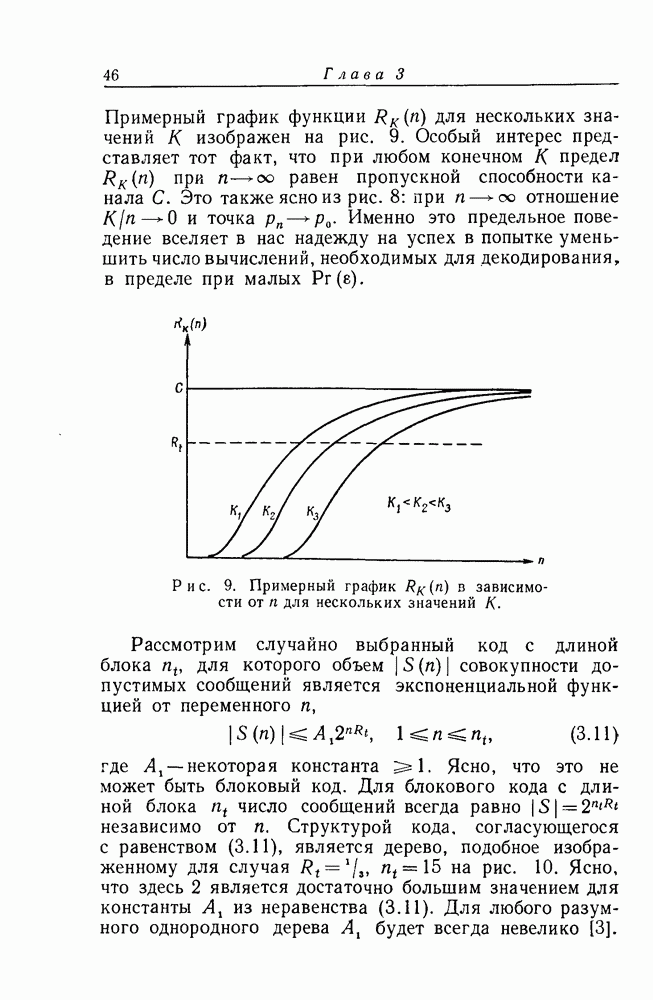
4. Вероятность ошибкиМы уже рассмотрели процедуру для декодирования первого символа случайного древовидного кода Мы ввели совокупность последовательных вероятностных критериев нашей процедуре поиска последовательность
для всех
отсюда следует, что
Далее, из случайного метода построения древовидного кода
Рассмотрим теперь вероятность
Если и
и, таким образом,
В соответствии с определением наших исключающих функций [см. соотношение (3.2)]
где, по определению,
Средняя вероятность ошибки
Определим
где
Последнее неравенство в соотношении (3.70) вытекает из того факта, что Более того, при
Это неравенство следует из соотношений (3.11) и
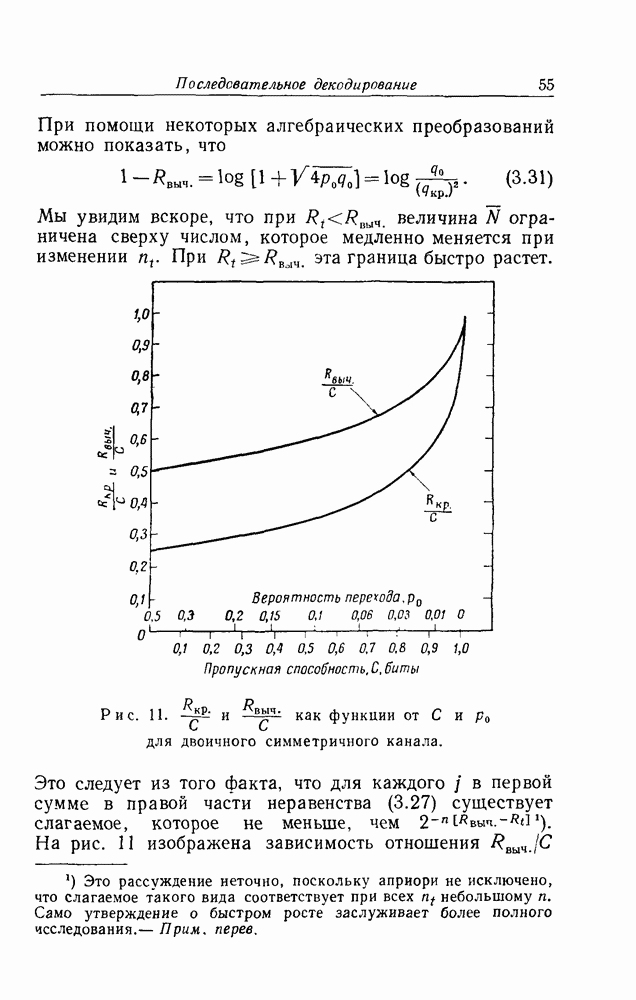
Мы интересуемся асимптотическим поведением выражений, входящих в (3.72), при больших неравенству (3.72), находим, что
В гл. 2 мы показали, что для случайных блоковых кодов длины
где Очевидно, что сумма, входящая в неравенство (2.33), мажорирует сумму, входящую в неравенство (3.73). Это верно в силу того, что индекс Итак, используя предыдущие результаты [неравенства (2.36) и (2.37)] и выбирая в качестве
и
Экспоненциальное поведение осредненной по ансамблю вероятности ошибки для последовательного декодирования совпадает с ее поведением для блоковых кодов.
|
 |
Оглавление
|

































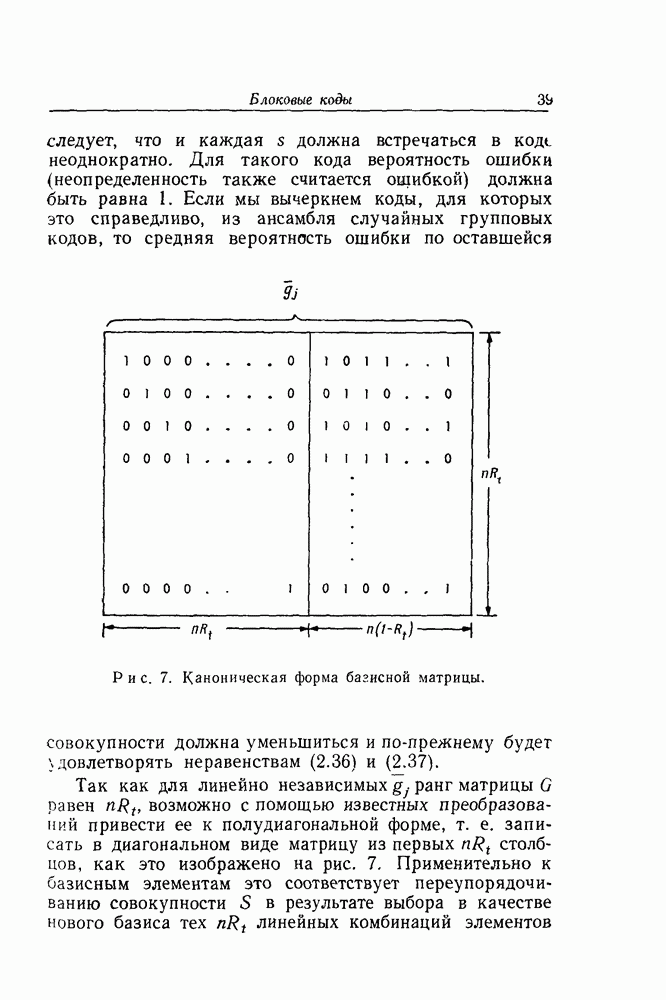





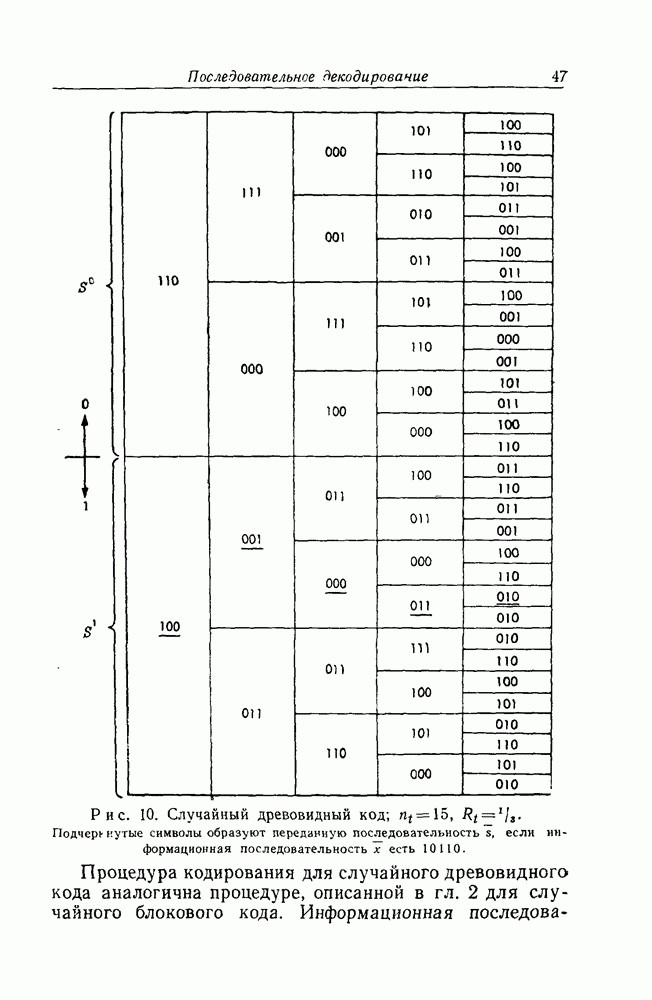
























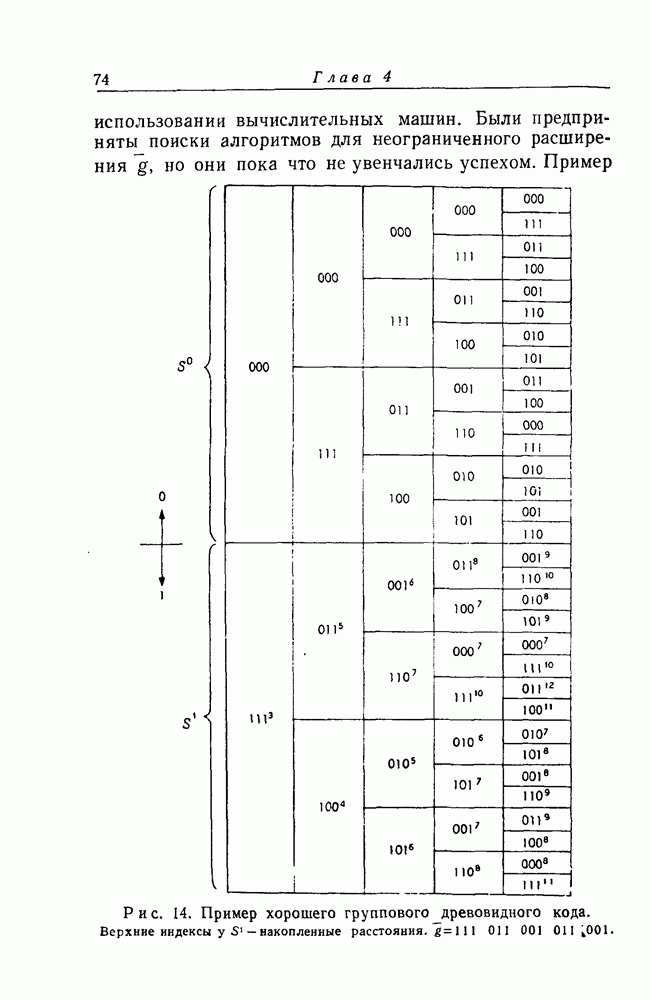










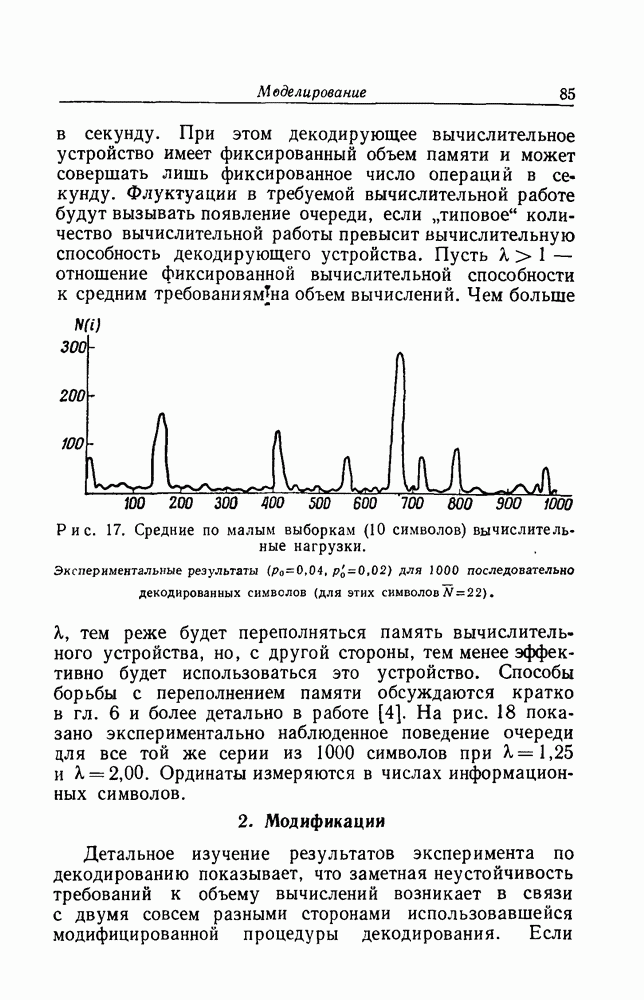
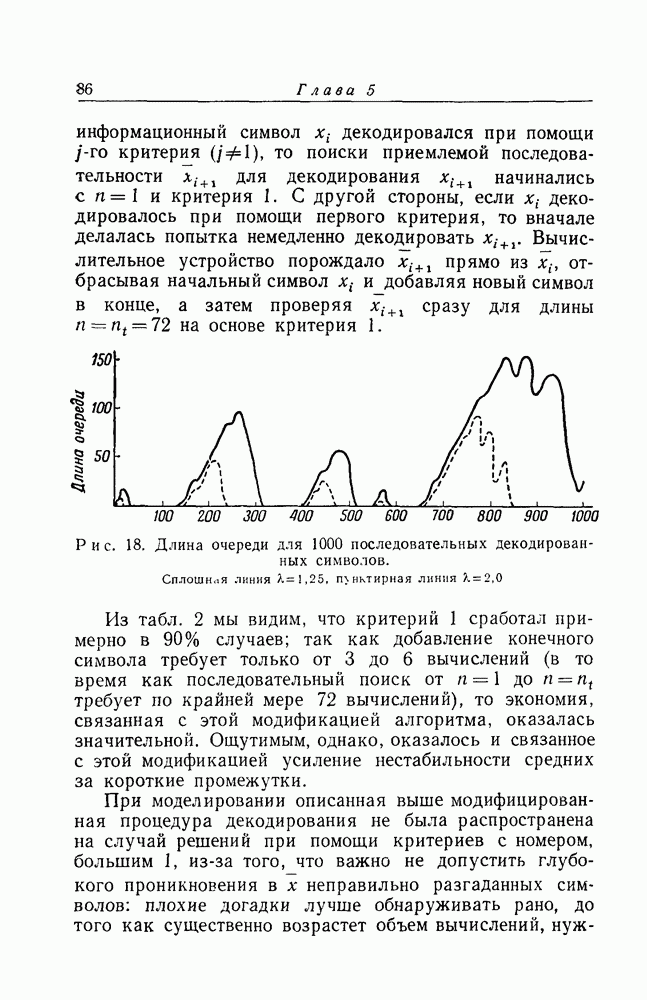

































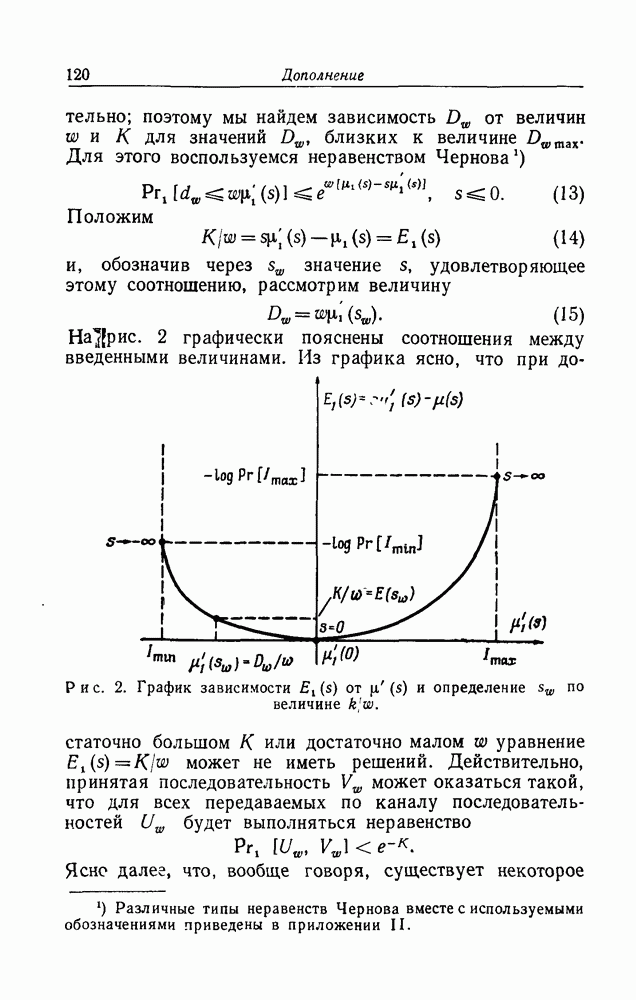











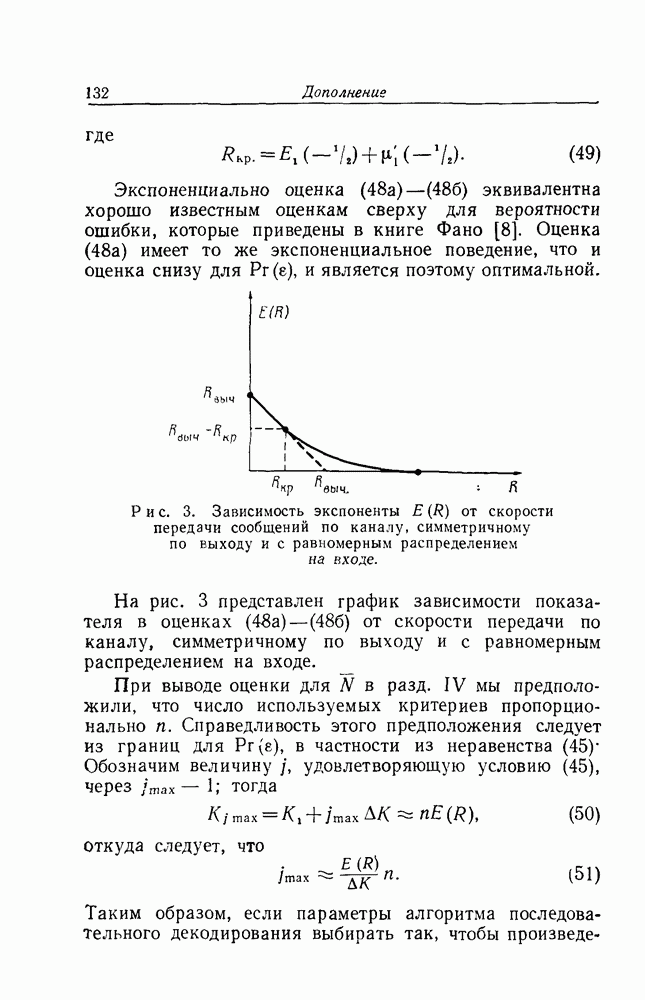



















 имеющего длину
имеющего длину  и скорость
и скорость  Остается показать, что эта процедура эффективна не только с точки зрения уменьшения среднего времени вычислений, но также и с точки зрения достижения малой вероятности ошибки.
Остается показать, что эта процедура эффективна не только с точки зрения уменьшения среднего времени вычислений, но также и с точки зрения достижения малой вероятности ошибки.
 и соответствующую ей совокупность исключающих функций
и соответствующую ей совокупность исключающих функций  Первый информационный символ, соответствующий переданной последовательности
Первый информационный символ, соответствующий переданной последовательности  декодируется, когда мы впервые обнаруживаем при
декодируется, когда мы впервые обнаруживаем при
 из
из  удовлетворяющую условию
удовлетворяющую условию

 в области
в области  Мы совершаем ошибку при декодировании в том и только том случае, когда эта последовательность
Мы совершаем ошибку при декодировании в том и только том случае, когда эта последовательность  принадлежит неправильному подмножеству
принадлежит неправильному подмножеству  Используем для
Используем для  сокращенное обозначение
сокращенное обозначение  Так как соотношение (3.51) выполнено для всех
Так как соотношение (3.51) выполнено для всех  то оно выполнено для
то оно выполнено для  и
и


 следует (с помощью тех же аргументов, что и в гл. 2), что
следует (с помощью тех же аргументов, что и в гл. 2), что

 того, что действительно используется
того, что действительно используется  критерий. Мы уже установили, что
критерий. Мы уже установили, что

 выбраны так же, как в равенствах (3.54) и (3.55), то
выбраны так же, как в равенствах (3.54) и (3.55), то



 для
для  Таким образом,
Таким образом,

 задается соотношением
задается соотношением

 так, чтобы выполнялись неравенства
так, чтобы выполнялись неравенства

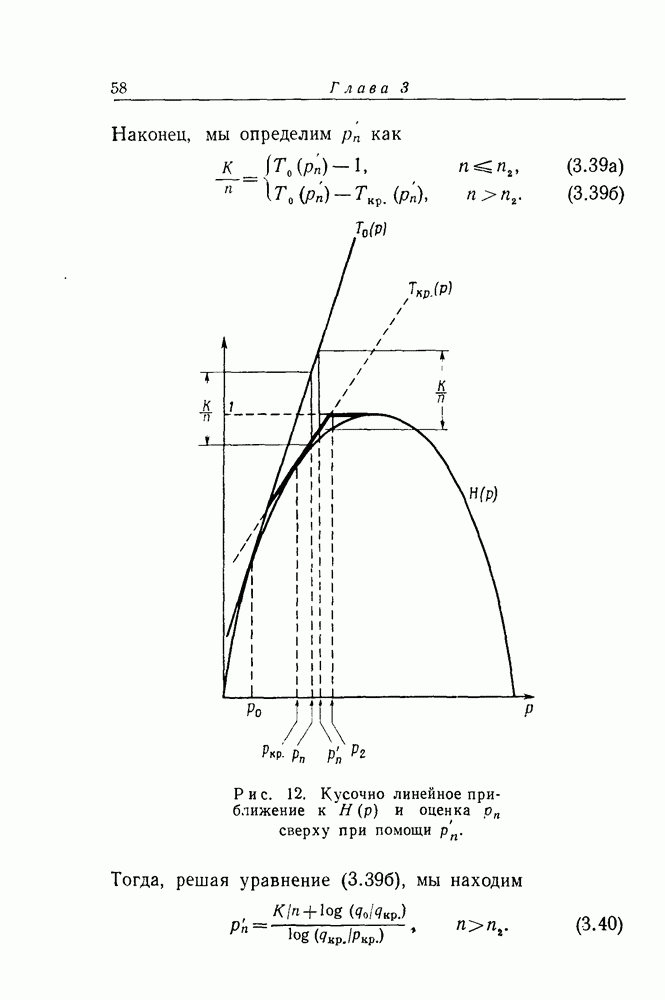
 решение уравнения
решение уравнения  Тогда
Тогда

 при
при  выбранном в соответствии с равенством (3.54).
выбранном в соответствии с равенством (3.54).


 Подставляя неравенства (3.64), (3.67), (3.70) и (3.71) в соотношение (3.68), мы получаем, что
Подставляя неравенства (3.64), (3.67), (3.70) и (3.71) в соотношение (3.68), мы получаем, что

 Так как
Так как  не зависит от
не зависит от  то
то  при
при  Поэтому из неравенства (3.69) вытекает, что
Поэтому из неравенства (3.69) вытекает, что  при
при  Применяя этот результат к
Применяя этот результат к

 вероятность ошибки ограничена сверху следующим образом:
вероятность ошибки ограничена сверху следующим образом:


 в неравенстве (2.33) пробегает все целые значения между
в неравенстве (2.33) пробегает все целые значения между  и
и  в то время как область изменения индекса
в то время как область изменения индекса  в неравенстве (3.73) может быть только некоторым подмножеством этой совокупности целых чисел.
в неравенстве (3.73) может быть только некоторым подмножеством этой совокупности целых чисел.
 его минимизирующее значение, задаваемое равенством (3.54), мы получаем, что для первых символов в случайном древовидном коде
его минимизирующее значение, задаваемое равенством (3.54), мы получаем, что для первых символов в случайном древовидном коде

