Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
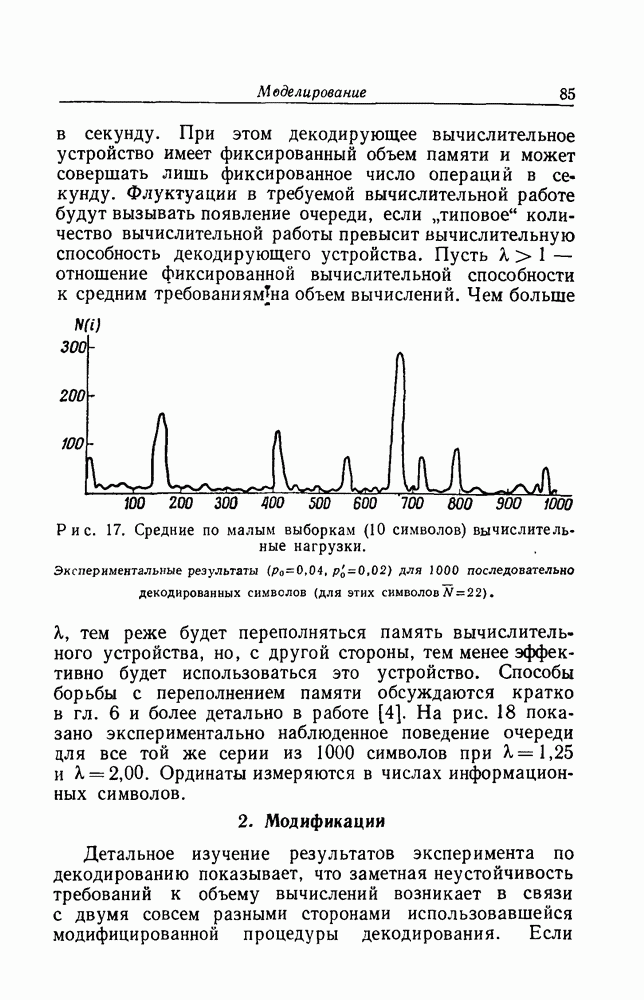
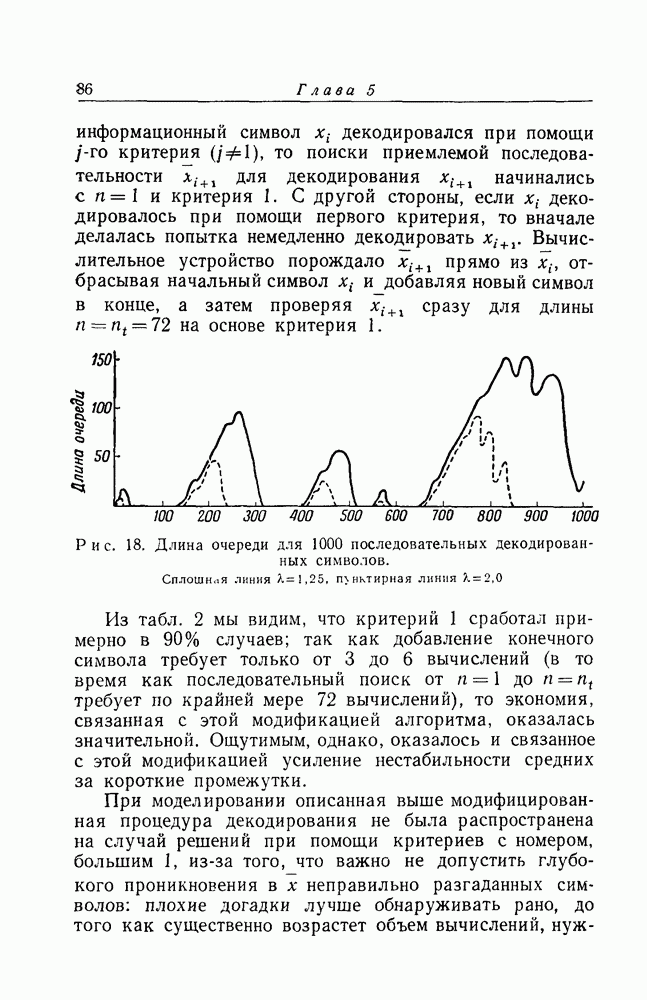
Глава 5. МОДЕЛИРОВАНИЕРезультаты гл. 3 показывают, что вычислительная машина при проведении последовательного декодирования сверточного кода может достичь пренебрежимо малой вероятности ошибки без необходимости проведения экспоненциально большого количества вычислений, связанных с неправильным множеством Существует предложение о видоизменении процедуры декодирования с тем, чтобы анализ среднего количества вычислений можно было бы провести как для Имеются и другие модификации процедуры декодирования, которые эвристически кажутся привлекательными, но для которых трудно, если вообще не невозможно, построить границу для среднего количества вычислений, необходимых при декодировании. Пусть, например, каждый информационный символ В подобных обстоятельствах представляется разумным при окончательной проверке метода последовательного декодирования и его модификаций положиться не на математический анализ, а на экспериментальные результаты. Исходя из этого, М. Хорстейн [15] моделировал операцию последовательного декодирования и двоичный симметрический канал на вычислительной машине ИБМ-704 Линкольновской лаборатории Массачусетского технологического института.
|
 |
Оглавление
|









































































































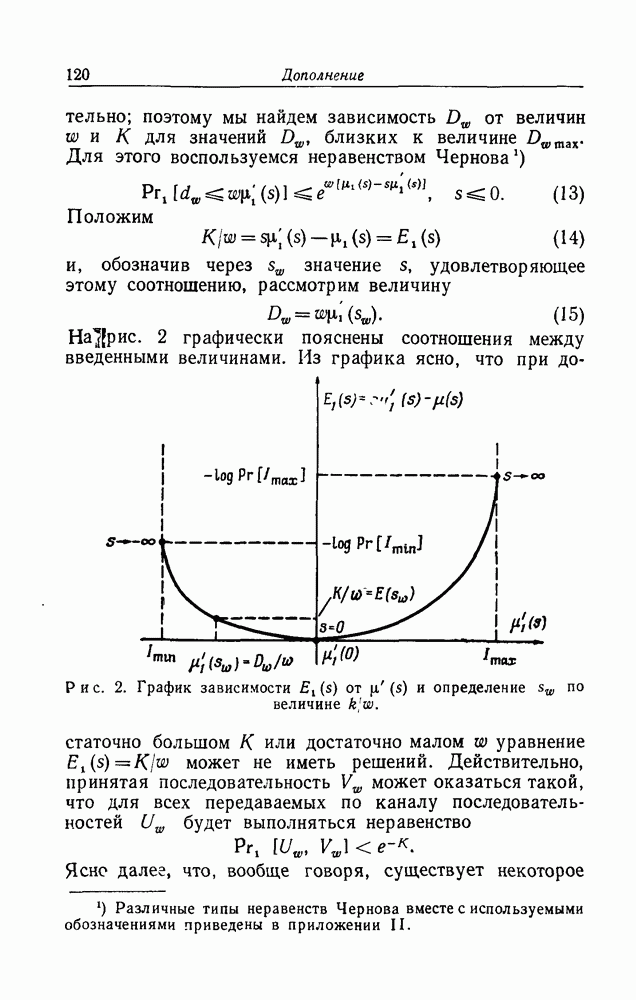











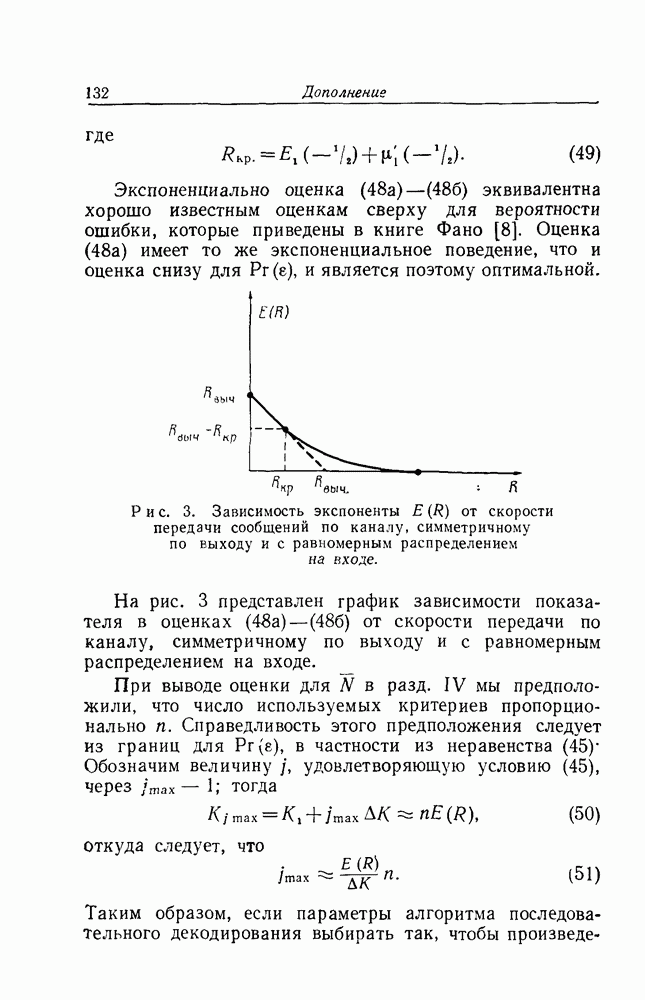



















 Однако задача оценки требуемого количества вычислений, связанных с правильным множеством
Однако задача оценки требуемого количества вычислений, связанных с правильным множеством  оказывается трудно преодолимой математически. По существу, проведенный выше анализ для
оказывается трудно преодолимой математически. По существу, проведенный выше анализ для  опирается на статистическую независимость полученной последовательности у и любой последовательности
опирается на статистическую независимость полученной последовательности у и любой последовательности  из
из  в статистическом ансамбле случайных порождающих элементов
в статистическом ансамбле случайных порождающих элементов  Так как у представляет собой сумму переданного сигнала и шума, эта статистическая независимость не имеет места для
Так как у представляет собой сумму переданного сигнала и шума, эта статистическая независимость не имеет места для  [10]).
[10]).
 так и для
так и для  Это предложение было исследовано. Мы показали [10], что это среднее ограничено сверху величиной, пропорциональной
Это предложение было исследовано. Мы показали [10], что это среднее ограничено сверху величиной, пропорциональной  Из эвристических соображений чувствуется, однако, что для этой модификации потребуется в среднем больше вычислений, чем необходимо для осуществления основного алгоритма.
Из эвристических соображений чувствуется, однако, что для этой модификации потребуется в среднем больше вычислений, чем необходимо для осуществления основного алгоритма.
 декодируется на основе некоторой предположительной последовательности, скажем охватывающей
декодируется на основе некоторой предположительной последовательности, скажем охватывающей  символов. Мы можем представить себе апостериорное распределение вероятностей для
символов. Мы можем представить себе апостериорное распределение вероятностей для  как "экспоненциальную воронку": мы почти наверняка знаем первый символ,
как "экспоненциальную воронку": мы почти наверняка знаем первый символ,  несколько хуже второй,
несколько хуже второй,  Относительно последнего символа в
Относительно последнего символа в  мы имеем мало информации или почти не имеем ее. Грубо говоря, процедура декодирования должна, используя у, расположить нашу воронку над тем х, для которого [правдоподобно получение из него этого у. Поэтому ясно, что должно быть эффективным начать поиски переменного
мы имеем мало информации или почти не имеем ее. Грубо говоря, процедура декодирования должна, используя у, расположить нашу воронку над тем х, для которого [правдоподобно получение из него этого у. Поэтому ясно, что должно быть эффективным начать поиски переменного  отбросив первый символ
отбросив первый символ  от
от  и добавив новый последний символ.
и добавив новый последний символ.