Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
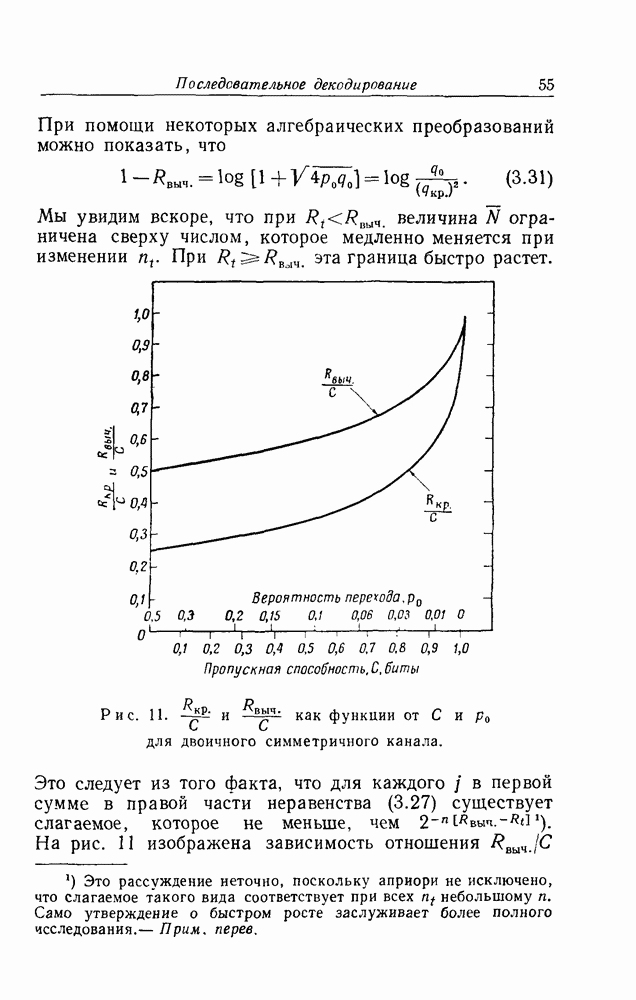
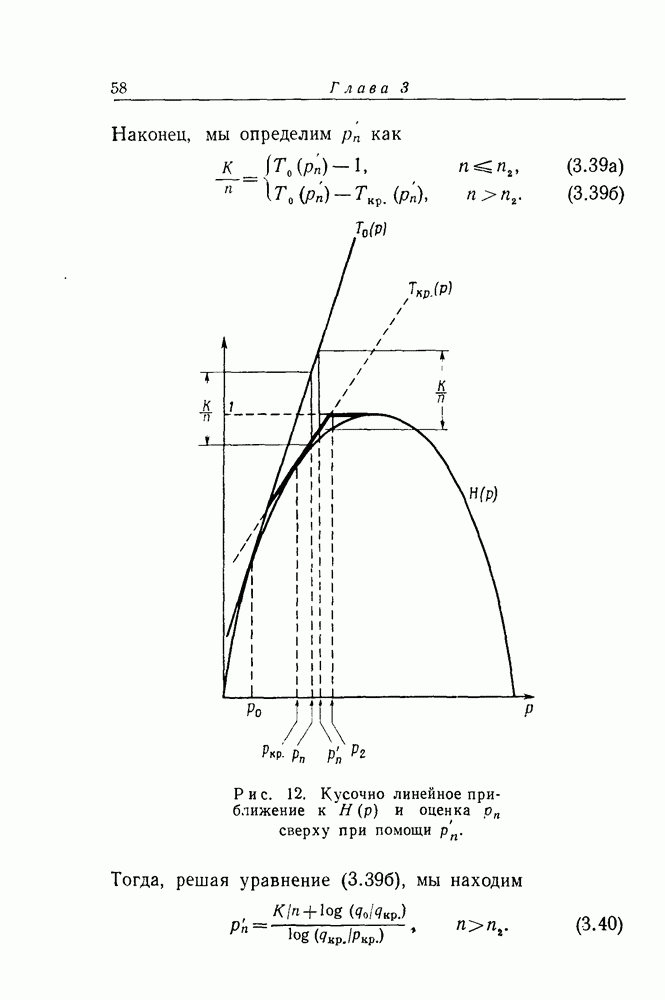
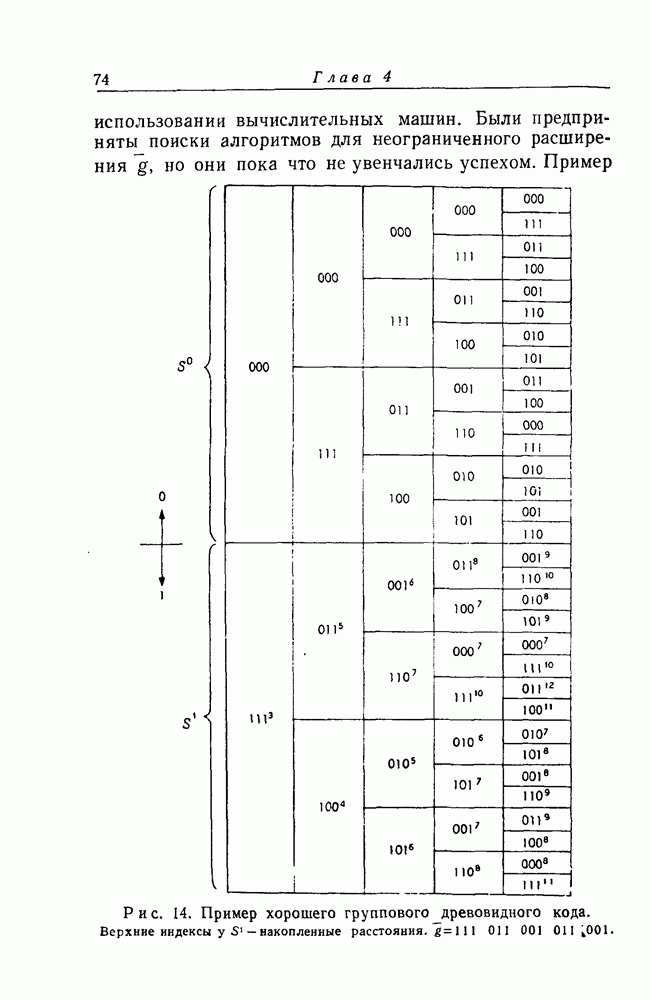
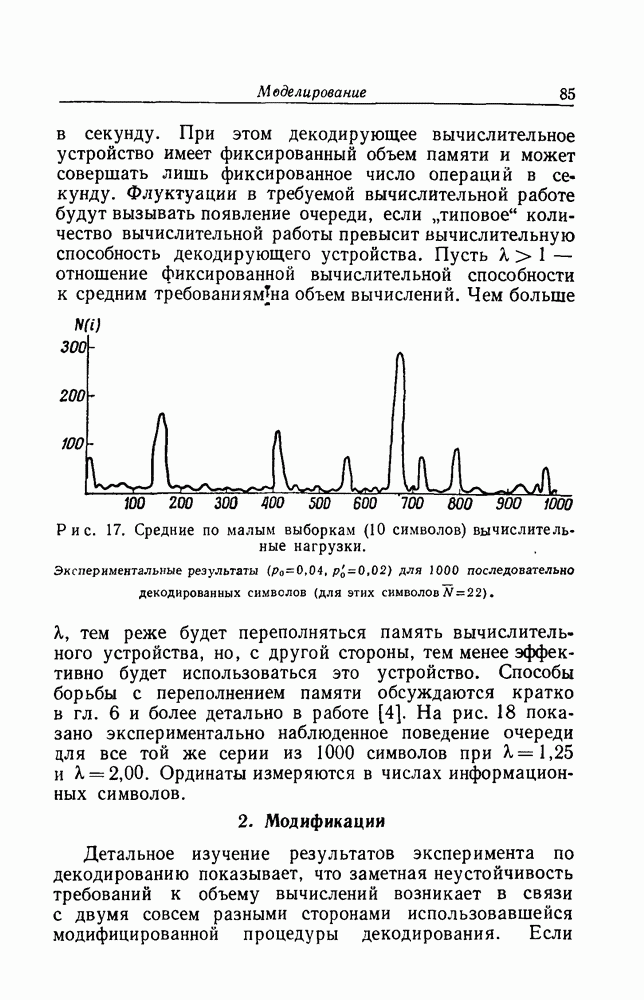
2. МодификацииДетальное изучение результатов эксперимента по декодированию показывает, что заметная неустойчивость требований к объему вычислений возникает в связи с двумя совсем разными сторонами использовавшейся модифицированной процедуры декодирования. Если информационный символ
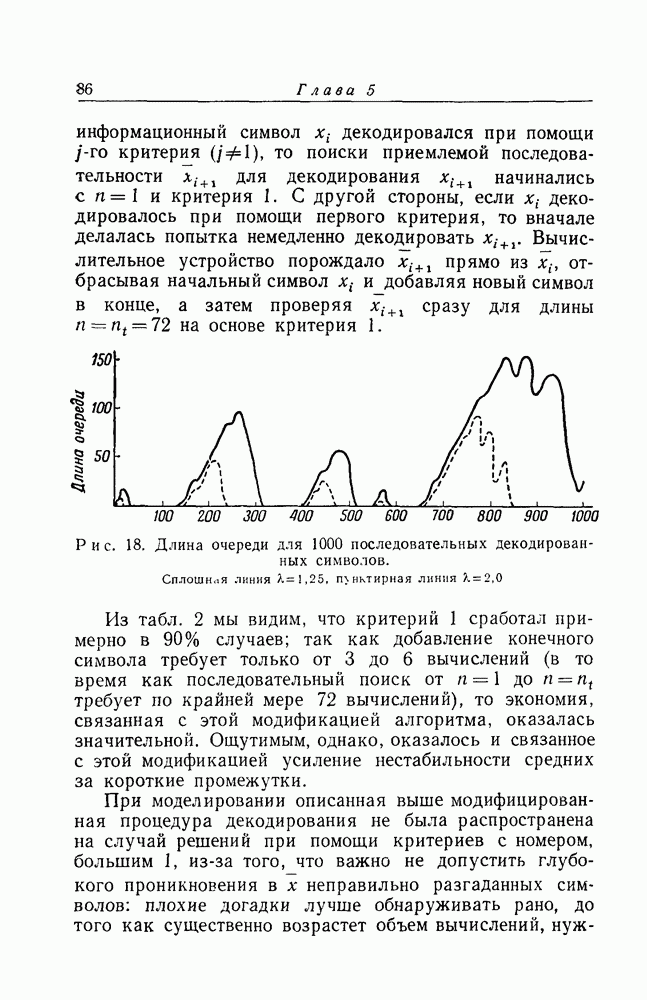
Рис. 18. Длина очереди для 1000 последовательных декодированных символов. Сплошная линия Из табл. 2 мы видим, что критерий 1 сработал примерно в 90% случаев; так как добавление конечного символа требует только от 3 до 6 вычислений (в то время как последовательный поиск от При моделировании описанная выше модифицированная процедура декодирования не была распространена на случай решений при помощи критериев с номером, большим 1, из-за того, что важно не допустить глубокого проникновения в х неправильно разгаданных символов: плохие догадки лучше обнаруживать рано, до того как существенно возрастет объем вычислений, нужный для отказа от этих догадок. Отсюда следует, что нужно стараться уменьшить, насколько это возможно, номер критерия. Но из табл. 2 видно, что если декодируется при помощи критерия у, то наиболее вероятно, что Мы видим, что относительно большой номер критерия не может быть достаточно быстро уменьшен. Поэтому кажется целесообразным применять модифицированный алгоритм при всех у, а не только при Движение в обратную сторону, начинающееся с Некоторые аномалии в данных табл. 1 указывают аторой источник устранимой нестабильности. Мы видим, что для достаточно мягким для того, чтобы неудачные предварительные догадки относительно символов из х могли фактически проникнуть на некоторую глубину в х. После этого перед вычислительным устройством возникает трудная задача изменения этих догадок. Надлежащее "лечение") состоит в том, чтобы всегда сначала вводить в х то значение Рассмотренные выше модификации предназначались в основном для того, чтобы уменьшить нестабильность объема вычислений путем повышения однородности процедуры декодирования. Можно, однако, ожидать, что те же методы послужат и для уменьшения среднего объема вычислений, требуемых для декодирования. Если включить в процедуру декодирования дополнительные нововведения, предназначенные для компенсации граничных условий, налагаемых схемой вычислений, то представляется возможным построение декодирующей вычислительной машины специального назначения, которая работала бы со скоростями передачи информации достигающими 3/4, и с числом бинарных импульсов в секунду, превышающим 50 000.
|
 |
Оглавление
|






































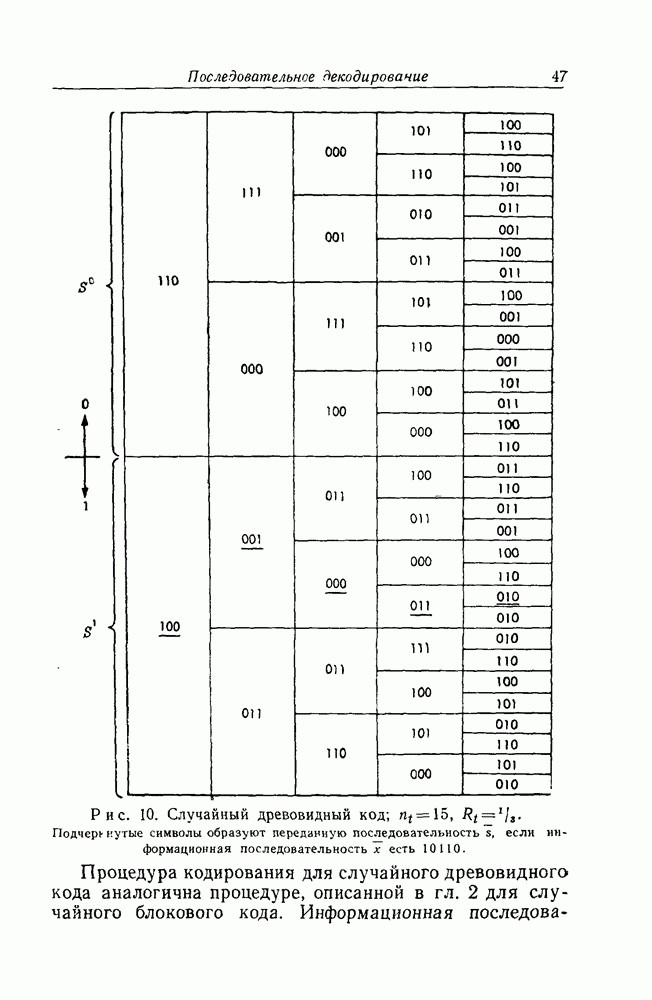

































































































 декодировался при помощи
декодировался при помощи  критерия
критерия  то поиски приемлемой последовательности
то поиски приемлемой последовательности  для декодирования
для декодирования  начинались с
начинались с  и критерия 1. С другой стороны, если
и критерия 1. С другой стороны, если  декодировалось при помощи первого критерия, то вначале делалась попытка немедленно декодировать
декодировалось при помощи первого критерия, то вначале делалась попытка немедленно декодировать  Вычислительное устройство порождало
Вычислительное устройство порождало  прямо из
прямо из  отбрасывая начальный символ
отбрасывая начальный символ  и добавляя новый символ в конце, а затем проверяя
и добавляя новый символ в конце, а затем проверяя  сразу для длины
сразу для длины  на основе критерия 1.
на основе критерия 1.

 пунктирная линия
пунктирная линия 
 до
до  требует по крайней мере 72 вычислений), то экономия, связанная с этой модификацией алгоритма, оказалась значительной. Ощутимым, однако, оказалось и связанное с этой модификацией усиление нестабильности средних за короткие промежутки.
требует по крайней мере 72 вычислений), то экономия, связанная с этой модификацией алгоритма, оказалась значительной. Ощутимым, однако, оказалось и связанное с этой модификацией усиление нестабильности средних за короткие промежутки.
 также будет декодироваться при помощи критерия у. Это утверждение выполнено для всех у, несмотря на то, что на каждом шагу делалась попытка уменьшить у.
также будет декодироваться при помощи критерия у. Это утверждение выполнено для всех у, несмотря на то, что на каждом шагу делалась попытка уменьшить у.
 . В дальнейших экспериментах представляется разумным попытаться перейти от
. В дальнейших экспериментах представляется разумным попытаться перейти от  используя тот же критерий у, при помощи которого был декодирован
используя тот же критерий у, при помощи которого был декодирован  Если эта попытка не увенчается успехом, то нужно идти в обратную сторону и уменьшать
Если эта попытка не увенчается успехом, то нужно идти в обратную сторону и уменьшать  начиная со значения
начиная со значения  до тех пор, пока впервые не останется начальная часть последовательности, удовлетворяющая критерию
до тех пор, пока впервые не останется начальная часть последовательности, удовлетворяющая критерию  а после этого вновь перейти к стандартной процедуре поиска. Если последовательным расширением
а после этого вновь перейти к стандартной процедуре поиска. Если последовательным расширением  было декодировано четыре или восемь информационных символов, то кажется разумным тем не менее уменьшить затем критерий у — 1 для того, чтобы предотвратить слишком глубокое проникновение ошибочных догадок.
было декодировано четыре или восемь информационных символов, то кажется разумным тем не менее уменьшить затем критерий у — 1 для того, чтобы предотвратить слишком глубокое проникновение ошибочных догадок.
 вместо движения в прямую сторону, начинающегося с
вместо движения в прямую сторону, начинающегося с  оказывается особенно выгодным для уменьшения неустойчивости объема вычислений, если имеются пачки ошибок. Иначе пачка ошибок, расположенная около того конца, где принимаются решения (малые
оказывается особенно выгодным для уменьшения неустойчивости объема вычислений, если имеются пачки ошибок. Иначе пачка ошибок, расположенная около того конца, где принимаются решения (малые  отрезка у полученного сообщения, вызывала бы использование критерия с неоправданно большим номером.
отрезка у полученного сообщения, вызывала бы использование критерия с неоправданно большим номером.
 число
число  оказывается меньше, чем для
оказывается меньше, чем для  Хорстейн первым указал на то, что, когда при передаче по каналу происходит слишком мало ошибок, первый критерий оказывается
Хорстейн первым указал на то, что, когда при передаче по каналу происходит слишком мало ошибок, первый критерий оказывается
 которое лучше всего согласуется с у, даже если какое-либо из значений (нуль или единица) может подходить при используемом критерии.
которое лучше всего согласуется с у, даже если какое-либо из значений (нуль или единица) может подходить при используемом критерии.