Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
ПРИМЕЧАНИЯ ПЕРЕВОДЧИКА
Вывод и математическая интерпретация основной для дальнейшего формулы (2.25) нуждаются в уточнении. Введем случайные величины  так, чтобы так, чтобы  если если  сообщение декодировано правильно, и сообщение декодировано правильно, и  если оно декодировано неправильно. Так как по предположению априорные вероятности передачи различных если оно декодировано неправильно. Так как по предположению априорные вероятности передачи различных  равны, то вероятность ошибки при использовании фиксированного кода равны, то вероятность ошибки при использовании фиксированного кода  равна равна

где  это вероятности, вычисляемые при задании кода. Под это вероятности, вычисляемые при задании кода. Под  автор подразумевает усреднение (вычисление математического ожидания) автор подразумевает усреднение (вычисление математического ожидания)  при случайном выборе при случайном выборе  Из формулы (1) и того факта, что при случайном выборе Из формулы (1) и того факта, что при случайном выборе  все сообщения все сообщения  равноправны, следует, что равноправны, следует, что

Далее вводятся вероятности  вычисляемые в предположении, что случайно выбирается также и код (и, конечно, выбор кода не зависит от значения шумов). Именно так надо понимать вероятности в правой части (2.25). Очевидно, что вычисляемые в предположении, что случайно выбирается также и код (и, конечно, выбор кода не зависит от значения шумов). Именно так надо понимать вероятности в правой части (2.25). Очевидно, что

и, как разъясняют авторы,

Дело в том, что  принимает с равными вероятностями все принимает с равными вероятностями все  возможных значений. Далее используется следующий простой факт: если вектор и принимает с вероятностью возможных значений. Далее используется следующий простой факт: если вектор и принимает с вероятностью  каждое из каждое из  возможных значений, т. е. имеет равномерное распределение, возможных значений, т. е. имеет равномерное распределение,  статистически не зависит от и, то для любых возможных последовательностей а длины статистически не зависит от и, то для любых возможных последовательностей а длины 

и, следовательно, сумма  также имеет равномерное распределение. Поэтому имеет равномерное распределение также имеет равномерное распределение. Поэтому имеет равномерное распределение  так что вероятности того, что так что вероятности того, что  совпадают в некотором символе, равны 1/2 (это авторы утверждают), и, кроме того, соответствующие события для разных символов независимы (это авторы неявно используют далее). совпадают в некотором символе, равны 1/2 (это авторы утверждают), и, кроме того, соответствующие события для разных символов независимы (это авторы неявно используют далее).
Точнее, разность  число единиц, в которой есть число единиц, в которой есть  совпадает с суммой нескольких (выбор их зависит только от совпадает с суммой нескольких (выбор их зависит только от  ) строк ) строк  Все эти строки независимы по построению и имеют равномерное распределение. Следовательно (см. примечание [2]), их сумма имеет равномерное распределение и ввиду этого формула (2.39) для Все эти строки независимы по построению и имеют равномерное распределение. Следовательно (см. примечание [2]), их сумма имеет равномерное распределение и ввиду этого формула (2.39) для  выводится также, как в выводится также, как в 
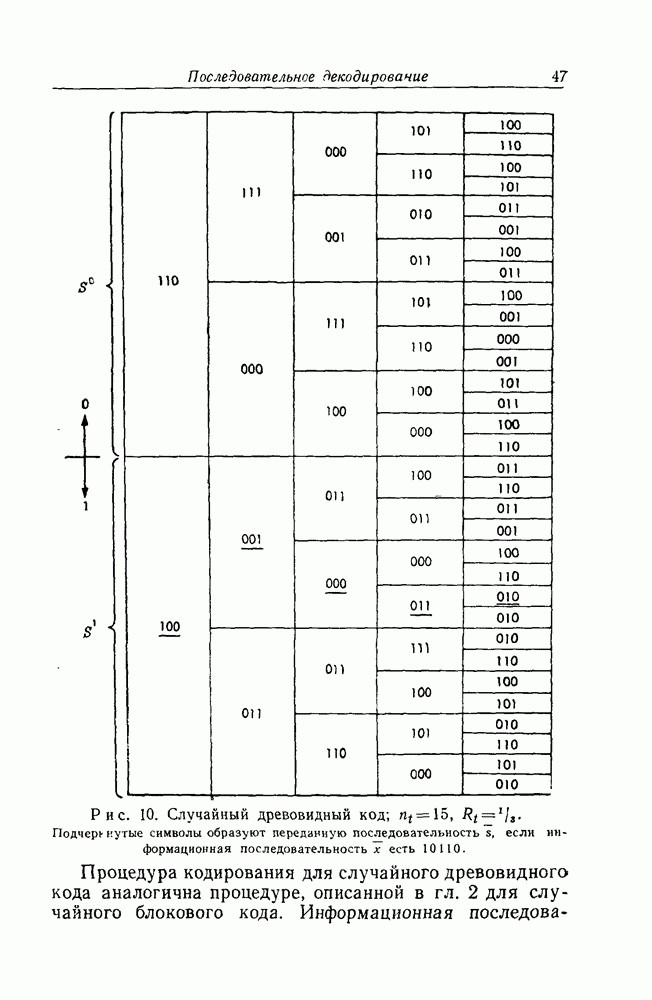
Точное определение древовидного кода для скорости передачи  где где  целое число, и длины блока целое число, и длины блока  состоит в следующем. Задаются некоторые последовательности из нулей и единиц длины состоит в следующем. Задаются некоторые последовательности из нулей и единиц длины  каждая: каждая:

где принимают значения  всего всего  значений. Подлежащему передаче набору информационных символов значений. Подлежащему передаче набору информационных символов  сопоставляется передаваемое по каналу сообщение, составленное из сопоставляется передаваемое по каналу сообщение, составленное из  идущих подряд последовательностей и, а именно, последовательностей идущих подряд последовательностей и, а именно, последовательностей  д. Этот код называется случайным древовидным кодом, если все последовательности и выбраны случайным образом, так что каждая из них с равными вероятностями принимает все д. Этот код называется случайным древовидным кодом, если все последовательности и выбраны случайным образом, так что каждая из них с равными вероятностями принимает все  возможных значений и все они статистически независимы. возможных значений и все они статистически независимы.
Автор использует формулу (3.10), которая, однако, была выведена в предположении, что код является случайным в смысле  Древовидный случайный код не является случайным в этом смысле. Тем не менее, этот факт верен, поскольку он основан лишь [см. (3.7)] на том, что Древовидный случайный код не является случайным в этом смысле. Тем не менее, этот факт верен, поскольку он основан лишь [см. (3.7)] на том, что  на том, что на том, что  есть число единиц в последовательности длины есть число единиц в последовательности длины  , для которой равновероятны все , для которой равновероятны все  ее возможных значений. По определению, ее возможных значений. По определению,  число единиц в число единиц в  переданная последовательность и наложенный на нее шум. Для случайного древовидного кода переданная последовательность и наложенный на нее шум. Для случайного древовидного кода  имеют равномерное распределение и (что существенно) если предположить, как делают авторы, что первые информационные символы для имеют равномерное распределение и (что существенно) если предположить, как делают авторы, что первые информационные символы для  не совпадают, то не совпадают, то  независимы. Используя замечание, сделанное в примечании [2] о сумме независимы. Используя замечание, сделанное в примечании [2] о сумме  независимых величин, одна из которых равномерно распределена, получим, что независимых величин, одна из которых равномерно распределена, получим, что  действительно имеет равномерное распределение. действительно имеет равномерное распределение.
Как отмечает автор на стр. 80, проводимая здесь и далее оценка неполна. Дело в том, что используемая автором для оценки формула (3.15) выведена как оценка числа действий, нужных для отбрасывания неправильного подмножества сообщений, в то время как при введенном здесь алгоритме нужно до перехода к следующему критерию проследить как правильное, так и неправильное подмножество. Таким образом, в формуле (3.27) и ее следствиях оценивается сверху лишь часть общего количества вычислений. Относительно оценки другой части см. примечание [10].
В обозначениях, использованных в примечании [4], древовидный код, задаваемый последовательностью  строится следующим образом. Пусть строится следующим образом. Пусть  где где  наборы по наборы по  символов. Тогда символов. Тогда  где где  при при 
Если понимать  как вероятности, вычисляемые для последовательностей независимых двоичных символов (как это делалось в предыдущих главах), то это равенство не нуждалось бы в новом доказательстве. Его содержательная трактовка состоит в следующем: если передано сообщение как вероятности, вычисляемые для последовательностей независимых двоичных символов (как это делалось в предыдущих главах), то это равенство не нуждалось бы в новом доказательстве. Его содержательная трактовка состоит в следующем: если передано сообщение  то на выходе появляется шумовая последовательность у (состоящая из последовательности независимых двоичных символов, с вероятностью то на выходе появляется шумовая последовательность у (состоящая из последовательности независимых двоичных символов, с вероятностью  равных 1). Если порождающая код последовательность равных 1). Если порождающая код последовательность  случайна, то случайно (и, конечно, статистически независимо от случайна, то случайно (и, конечно, статистически независимо от  соответствующее фиксированному соответствующее фиксированному  Под Под  здесь подразумевается число единиц в Для того чтобы было верно интересующее нас неравенство, достаточно показать, что здесь подразумевается число единиц в Для того чтобы было верно интересующее нас неравенство, достаточно показать, что  с равными вероятностями принимает все возможные значения, так как после этого окажутся применимыми все рассуждения предыдущих глав. Это, по существу, и делают авторы в следующих абзацах. с равными вероятностями принимает все возможные значения, так как после этого окажутся применимыми все рассуждения предыдущих глав. Это, по существу, и делают авторы в следующих абзацах.
Рассуждения авторов означают следующее. При фиксированном  любому значению у соответствуют некоторые значения любому значению у соответствуют некоторые значения  Авторы показывают, что и, наоборот, любому значению Авторы показывают, что и, наоборот, любому значению  соответствует некоторое значение соответствует некоторое значение  Поскольку число возможных значений Поскольку число возможных значений  одинаково, то между их значениями имеет место взаимно однозначное соответствие. По условию, одинаково, то между их значениями имеет место взаимно однозначное соответствие. По условию,  выбрано случайно, т. е. все его значения равновероятны — значит то же верно и для выбрано случайно, т. е. все его значения равновероятны — значит то же верно и для  Поскольку у не зависит от Поскольку у не зависит от  (см. примечание II), то это же верно для (см. примечание II), то это же верно для  Этои нужно было показать (см. примечание [8]). Этои нужно было показать (см. примечание [8]).
Переводчик провел анализ среднего объема вычислений, нужных для прослеживания правильного дерева (см. статью "По
поводу последовательного декодирования Возенкрафта — Рейффена", публикуемую в сборнике "Проблемы кибернетики". Этот анализ показывает, что средний объем растет с ростом  экспоненциальным образом. Строгое математическое доказательство этого факта длинно. Оно приведено в цитированной работе переводчика, здесь же мы лишь опишем его главную идею. Фиксируем некоторую длину последовательности экспоненциальным образом. Строгое математическое доказательство этого факта длинно. Оно приведено в цитированной работе переводчика, здесь же мы лишь опишем его главную идею. Фиксируем некоторую длину последовательности  где где  Заметим, что при прослеживании вплоть до длины Заметим, что при прослеживании вплоть до длины  истинной передававшейся последовательности символы последовательности, полученной на выходе, будут совпадать с соответствующим символом переданной последовательности с вероятностью, равной истинной передававшейся последовательности символы последовательности, полученной на выходе, будут совпадать с соответствующим символом переданной последовательности с вероятностью, равной  вероятность канала), а число вероятность канала), а число  символов, в которых эти последовательности отличаются, имеет биномиальное распределение с параметрами символов, в которых эти последовательности отличаются, имеет биномиальное распределение с параметрами  Среднее значение Среднее значение  равно равно  но при любом но при любом 

где  некоторая функция, которая может быть явно вычислена (см., например, Крамер некоторая функция, которая может быть явно вычислена (см., например, Крамер  Об одной новой предельной теореме теории вероятностей, Успехи мат. наук, ст. сер., 10 (1944), 166 — 178 или Добрушин Р. Асимптотические оценки вероятности ошибки при передаче сообщения по дискретному каналу связи без памяти с симметрической матрицей вероятностей перехода, Теор. вероят. и ее примен., 7 (1962), № 3 , 283 - 311). Об одной новой предельной теореме теории вероятностей, Успехи мат. наук, ст. сер., 10 (1944), 166 — 178 или Добрушин Р. Асимптотические оценки вероятности ошибки при передаче сообщения по дискретному каналу связи без памяти с симметрической матрицей вероятностей перехода, Теор. вероят. и ее примен., 7 (1962), № 3 , 283 - 311).
Для нас, однако, существенно лишь то, что  имеет максимум при имеет максимум при  так что так что  при при  Заметим теперь, что если Заметим теперь, что если  то при любом то при любом  имеет место неравенство имеет место неравенство  Так как исключающая функция Так как исключающая функция  то для то для  никаких отбрасываний не будет производиться при всех длинах никаких отбрасываний не будет производиться при всех длинах  таких, что таких, что  Таким образом, если Таким образом, если  и если правильная последовательность не была отброшена при длинах меньших и если правильная последовательность не была отброшена при длинах меньших  (возможностью такого отбрасывания пренебрежем как маловероятной), то до принятия решения придется проследить все ветви, ответвляющиеся от истинной при (возможностью такого отбрасывания пренебрежем как маловероятной), то до принятия решения придется проследить все ветви, ответвляющиеся от истинной при  лежащих между лежащих между  Общее число таких ветвей, а следовательно, и требуемое число действий при декодировании имеет порядок Общее число таких ветвей, а следовательно, и требуемое число действий при декодировании имеет порядок  Таким образом, в выражение для среднего объема декодирования должен войти множитель вида Таким образом, в выражение для среднего объема декодирования должен войти множитель вида

В силу того, что при  мы имеем мы имеем  для для  и достаточно близких к и достаточно близких к  экспонента в (1) будет положительной, что и доказывает сформулированный результат. экспонента в (1) будет положительной, что и доказывает сформулированный результат.
Экспоненциальный рост объема декодирования возникает из-за того, что с очень малой вероятностью объем декодирования
очень велик. Однако он будет большим и для основной массы реализаций декодирования. Дело в том, что в силу применимости к величине  центральной предельной теоремы, центральной предельной теоремы,  будет обычно принимать значение порядка будет обычно принимать значение порядка  Но из определения Но из определения  следует, что следует, что  при больших при больших  где в ряде интересных случаев где в ряде интересных случаев  большое число. Поэтому в течение промежутка времени порядка большое число. Поэтому в течение промежутка времени порядка  после момента после момента  не будет проводиться отбрасываний, откуда следует, что объем декодирования имеет порядок не меньший не будет проводиться отбрасываний, откуда следует, что объем декодирования имеет порядок не меньший  где где 
Хорошие результаты описываемого в этой главе моделирования, по-видимому, объясняются тем, что, как подсказывает дальнейший анализ развитых выше соображений, константы, определяющие скорость экспоненциального роста, малы при малой вероятности  [В экспоненту как для среднего объема вычислений, так и для объема вычислений, нужного для основной массы случаев, входит произведение [В экспоненту как для среднего объема вычислений, так и для объема вычислений, нужного для основной массы случаев, входит произведение  а в просчитанных Возенкрафтом примерах, хотя а в просчитанных Возенкрафтом примерах, хотя  и равно 72, но и равно 72, но  колеблется от 1 до 4 (число 2 еще не велико).] колеблется от 1 до 4 (число 2 еще не велико).]
В связи с тем, что цитируемый отчет недоступен советскому читателю, укажем одну из таких модификаций, предложенную В.  Кошелевым и М. С. Пинскером. Она состоит просто в том, что кроме числа Кошелевым и М. С. Пинскером. Она состоит просто в том, что кроме числа  несовпадений символов переданной и полученной последовательности на отрезке несовпадений символов переданной и полученной последовательности на отрезке  для каждого отрезка для каждого отрезка  подсчитывается также число подсчитывается также число  не совпадающих символов переданной и полученной последовательности на отрезке не совпадающих символов переданной и полученной последовательности на отрезке  Если при некотором Если при некотором  хотя бы для одного хотя бы для одного  число число  превосходит превосходит  то проводится отбрасывание испытываемой последовательности. то проводится отбрасывание испытываемой последовательности.
|
1 |
|