Пред.
След.
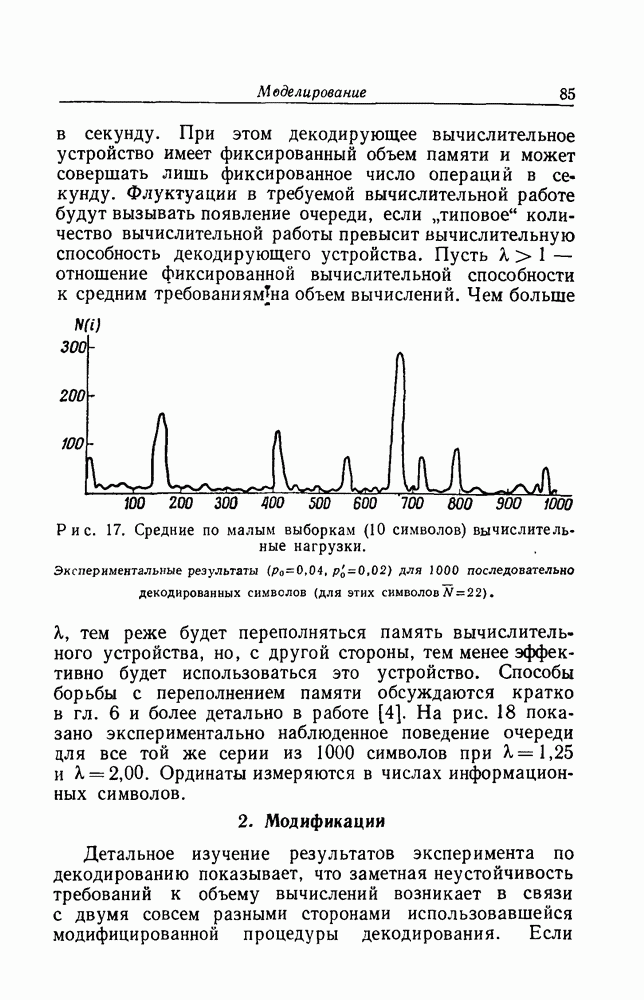
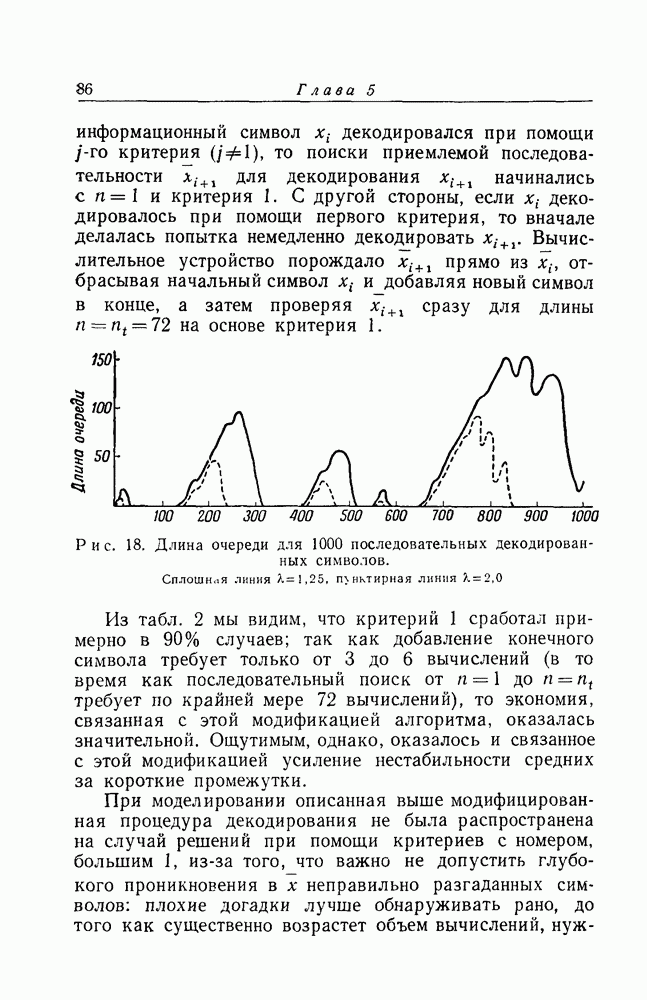
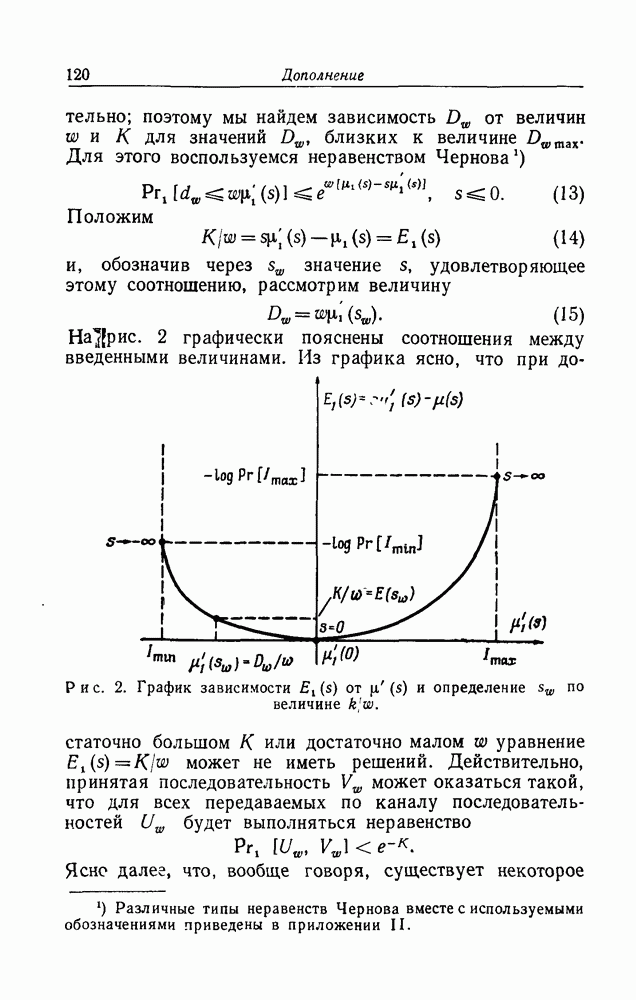
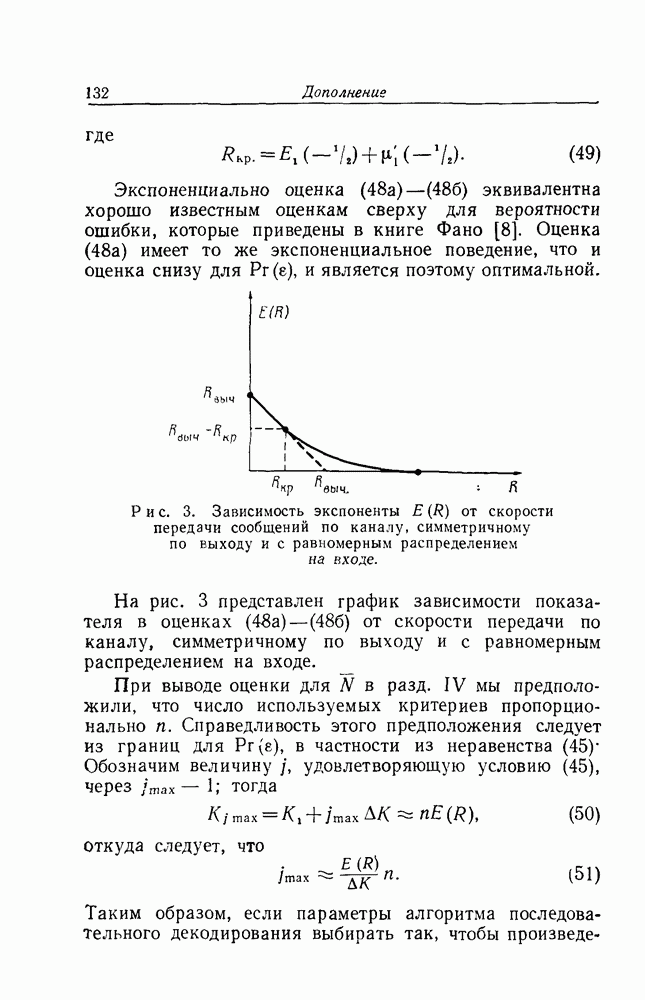
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
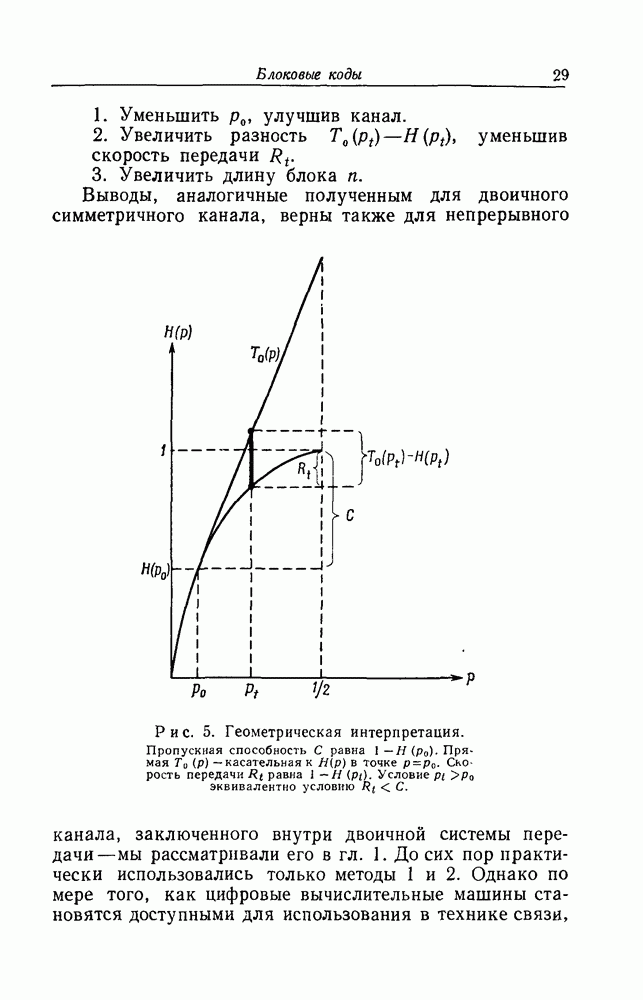
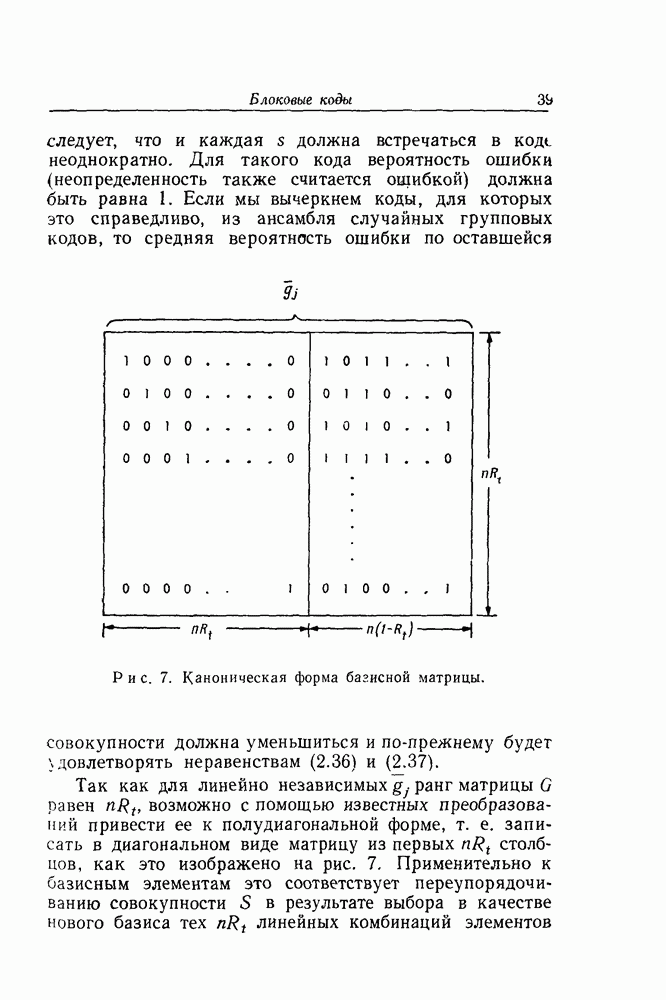
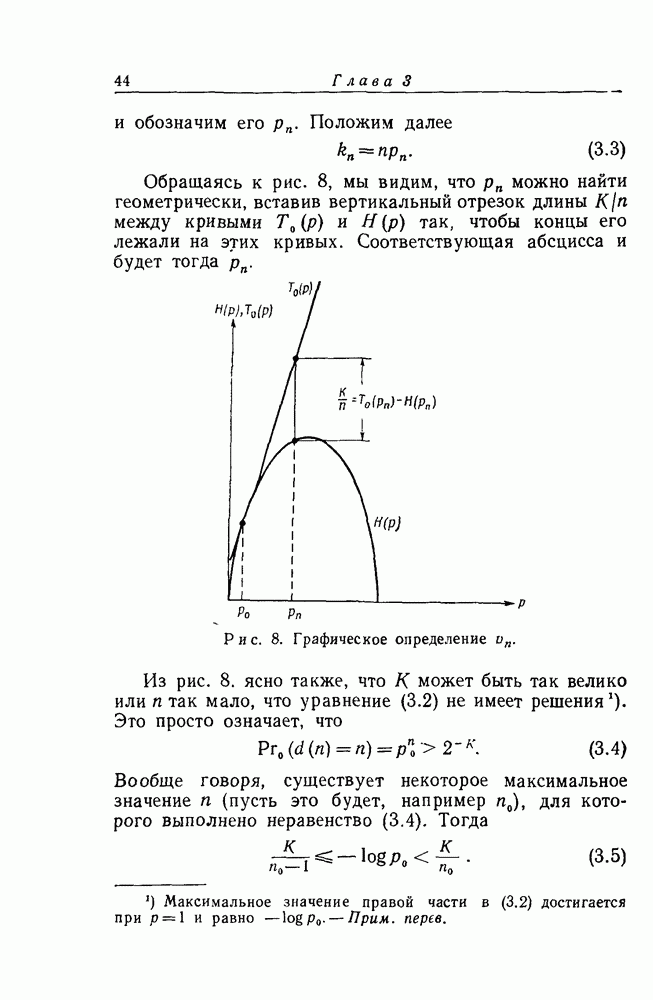
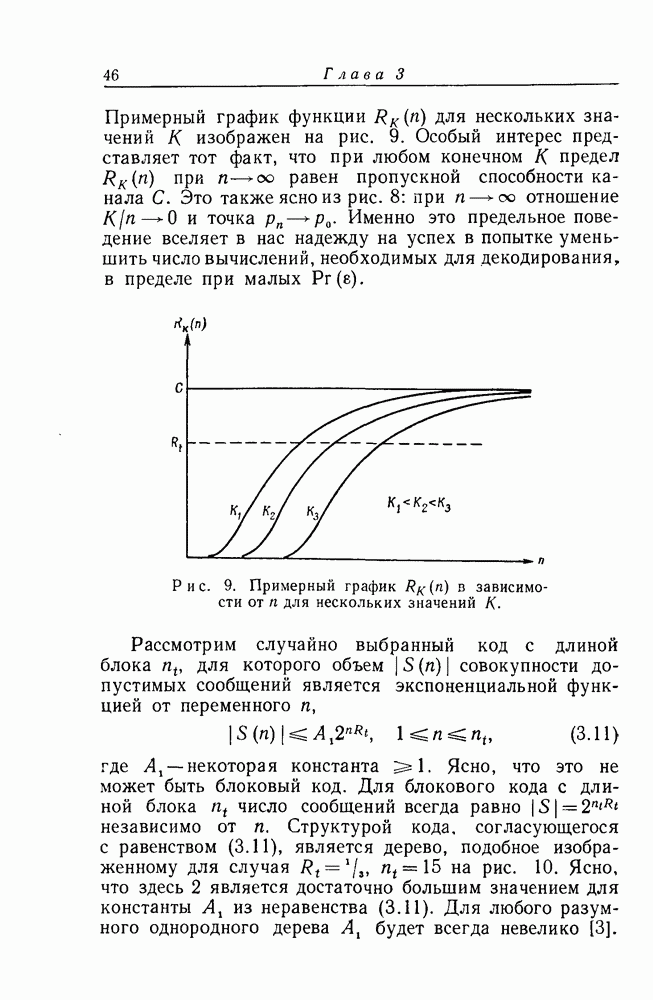
Грава 4. СВЕРТОЧНОЕ КОДИРОВАНИЕ1. Бесконечные деревьяВ гл. 3 мы рассмотрели задачу о декодировании первого информационного символа в предположении, что каждая последовательность х длиной в Бесконечное дерево
и предположим, что как и в случае конечного базиса
Рис. 13. Схематическое представление базисных элементов для бесконечного дерева. Каждое Для удобства мы будем всегда рассматривать лишь такие длины Наша цель — использовать алгоритм декодирования, описанный в гл. 3, для того, чтобы декодировать поочередно каждый символ в х. Первый информационный символ последовательности Аналогично, на том же рисунке совокупность образующих элементов, которые должны быть рассмотрены при декодировании третьего информационного символа (после того, как К счастью, тот факт, что все усеченные подмножества не идентичны, не помешает (пока еще не сделано ошибок при декодировании) перенесению на
то ясно, что прибавление любого известного "хвоста“ s к
|
 |
Оглавление
|






































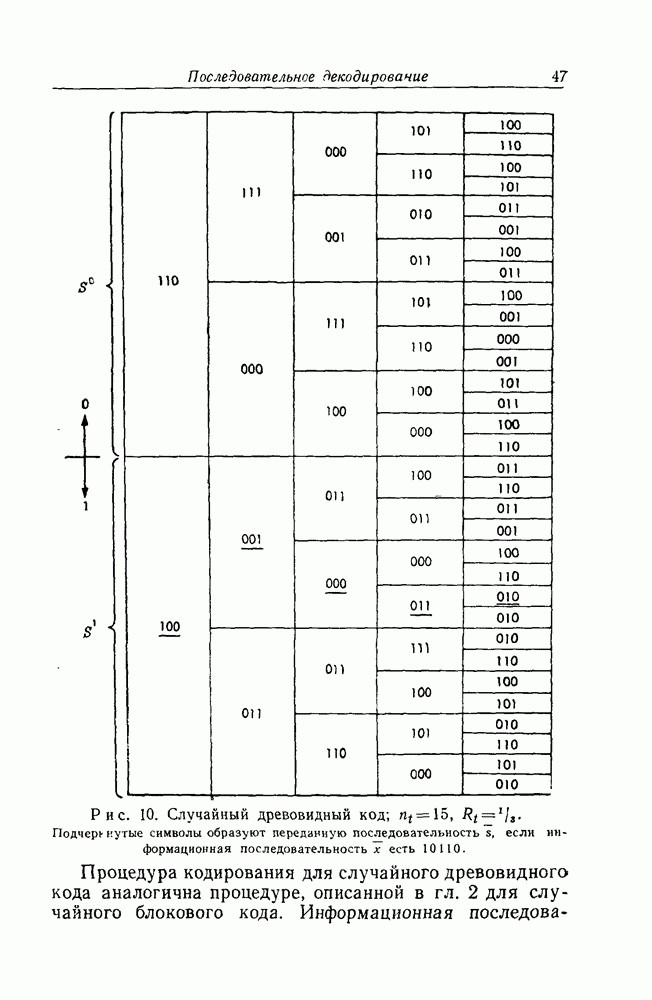

































































































 таких символов задает некоторое передаваемое сообщение
таких символов задает некоторое передаваемое сообщение  из конечного случайного древовидного множества
из конечного случайного древовидного множества  Если передача ведется непрерывным образом и первоначальная процедура декодирования приложима поочередно к каждому последовательному символу
Если передача ведется непрерывным образом и первоначальная процедура декодирования приложима поочередно к каждому последовательному символу  в бесконечной последовательности х, то полное кодовое множество
в бесконечной последовательности х, то полное кодовое множество  должно также простираться до бесконечности и расти как
должно также простираться до бесконечности и расти как  при всех
при всех  (как при
(как при  так и при
так и при  ).
).
 легко образовать, используя понятие образующих элементов группового кода, рассмотренное в гл. 2. Пусть длина кодовых ограничений (которая соответствует длине блока для блоковых кодов) есть и пусть скорость передачи
легко образовать, используя понятие образующих элементов группового кода, рассмотренное в гл. 2. Пусть длина кодовых ограничений (которая соответствует длине блока для блоковых кодов) есть и пусть скорость передачи  равна
равна  где
где  целое. число. Выберем порождающую последовательность
целое. число. Выберем порождающую последовательность  состоящую из
состоящую из  двоичных символов
двоичных символов

 представляет собой
представляет собой  перенесенное вправо на
перенесенное вправо на  символов. Множество всех таких
символов. Множество всех таких  бескончено и может быть использовано как базис (так же,
бескончено и может быть использовано как базис (так же,
 рассмотренном в гл. 2) для бесконечного группового кода. Напомним, что для группового кода передаваемая последовательность
рассмотренном в гл. 2) для бесконечного группового кода. Напомним, что для группового кода передаваемая последовательность  соответствующая информационной последовательности
соответствующая информационной последовательности  образуется сложением порождающих элементов
образуется сложением порождающих элементов  связанных с ненулевыми символами
связанных с ненулевыми символами  Тогда из схематического представления, данного на рис. 13, ясно, что действительно образует бесконечное дерево с узлами, расположенными на расстоянии
Тогда из схематического представления, данного на рис. 13, ясно, что действительно образует бесконечное дерево с узлами, расположенными на расстоянии  друг от друга
друг от друга  .
.

 переносится на
переносится на  символов относительно
символов относительно  подмножество базисных элементов для декодирования
подмножество базисных элементов для декодирования  подмножество базисных элементов для декодирования
подмножество базисных элементов для декодирования 
 кодовых ограничений, которые делятся на
кодовых ограничений, которые делятся на 
 из х определяет, должно или не должно
из х определяет, должно или не должно  использоваться при образовании передаваемой
использоваться при образовании передаваемой
 Так как порождающий элемент имеет длину
Так как порождающий элемент имеет длину  ясно, что
ясно, что  влияет только на первые
влияет только на первые  символов в
символов в  Определим далее усеченное множество
Определим далее усеченное множество  как множество всех последовательностей, которые являются первыми
как множество всех последовательностей, которые являются первыми  символами из и ограничимся при декодировании х, рассмотрением
символами из и ограничимся при декодировании х, рассмотрением  вместо
вместо  Из рис. 13 очевидно, что множество
Из рис. 13 очевидно, что множество  образует групповой код: оно состоит из
образует групповой код: оно состоит из  линейных комбинаций
линейных комбинаций  образующих элементов. Образующие элементы, которые используются при определении
образующих элементов. Образующие элементы, которые используются при определении  на рис. 13 заключены в пунктирный прямоугольник, обозначенный символом
на рис. 13 заключены в пунктирный прямоугольник, обозначенный символом 
 уже декодированы), также заключены в пунктирный прямоугольник, обозначенный
уже декодированы), также заключены в пунктирный прямоугольник, обозначенный  Так как
Так как  получаются друг из друга переносами, то совокупность всех
получаются друг из друга переносами, то совокупность всех  линейных комбинаций образующих элементов в
линейных комбинаций образующих элементов в  совпадает с
совпадает с  . Однако следует учесть, что множество усеченных последовательностей, используемых при декодировании
. Однако следует учесть, что множество усеченных последовательностей, используемых при декодировании  не совпадает с самим
не совпадает с самим  а представляет собой множество, возникающее при добавлении к каждому элементу
а представляет собой множество, возникающее при добавлении к каждому элементу  лежащих над прямоугольником
лежащих над прямоугольником  "хвостов" последовательностей
"хвостов" последовательностей  последовательность
последовательность  (соответственно
(соответственно  берется, конечно, лишь в том случае, когда
берется, конечно, лишь в том случае, когда  (соответственно
(соответственно  Таким образом, декодирующее устройство должно запомнить
Таким образом, декодирующее устройство должно запомнить  своих предыдущих решений с тем, чтобы использовать их при построении допустимых последовательностей для декодирования
своих предыдущих решений с тем, чтобы использовать их при построении допустимых последовательностей для декодирования  Если при декодировании однажды совершена ошибка, то при декодировании следующих
Если при декодировании однажды совершена ошибка, то при декодировании следующих  информационных символов декодирующее устройство будет стремиться добиться наибольшей близости полученной последовательности у с элементами неправильно определенного кодового множества. Ошибка будет, таким образом, иметь тенденцию к самовоспроизведению.
информационных символов декодирующее устройство будет стремиться добиться наибольшей близости полученной последовательности у с элементами неправильно определенного кодового множества. Ошибка будет, таким образом, иметь тенденцию к самовоспроизведению.
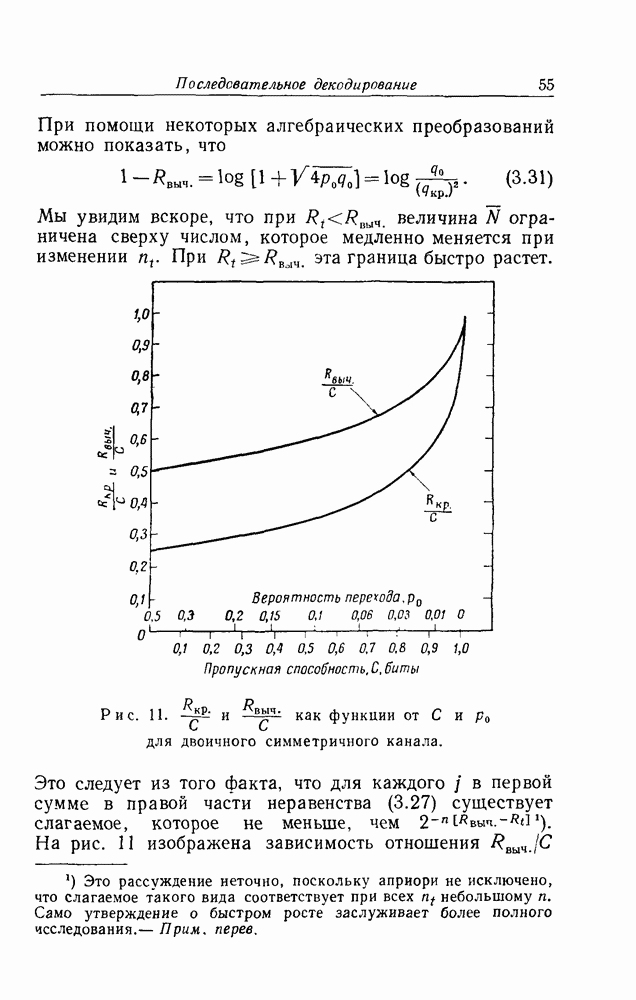
 проведенных в гл. 3 оценок объемов вычислений и вероятностей ошибок. Эти оценки зависят только от длины
проведенных в гл. 3 оценок объемов вычислений и вероятностей ошибок. Эти оценки зависят только от длины  усекаемого кода и числа
усекаемого кода и числа  символов 1 в
символов 1 в  Так как
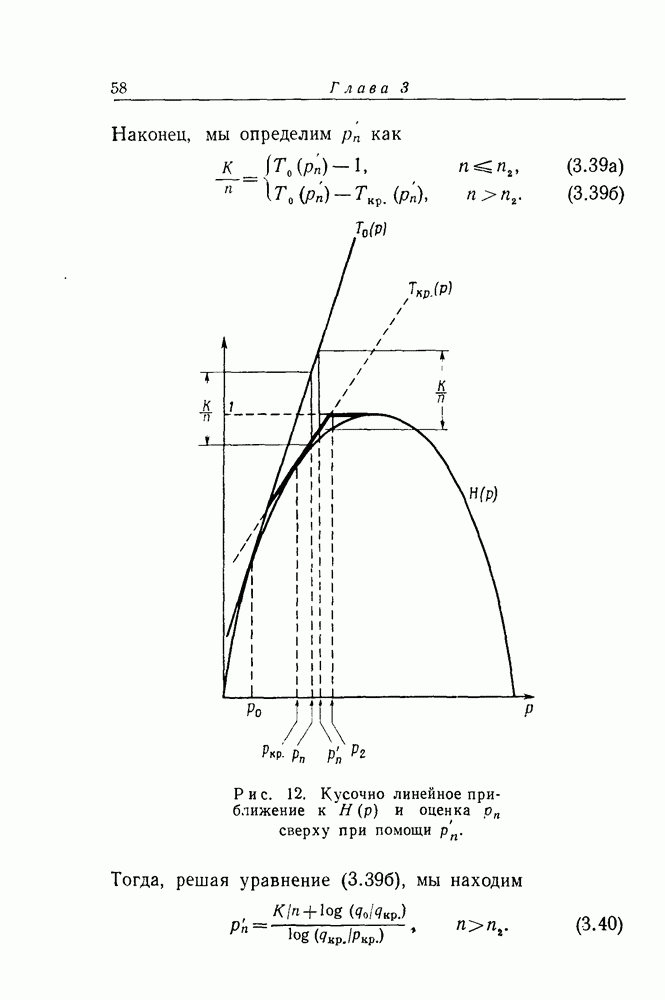
Так как

 и каждому из
и каждому из  оставляет совокупность
оставляет совокупность  неизменной. Таким образом, особый групповой код
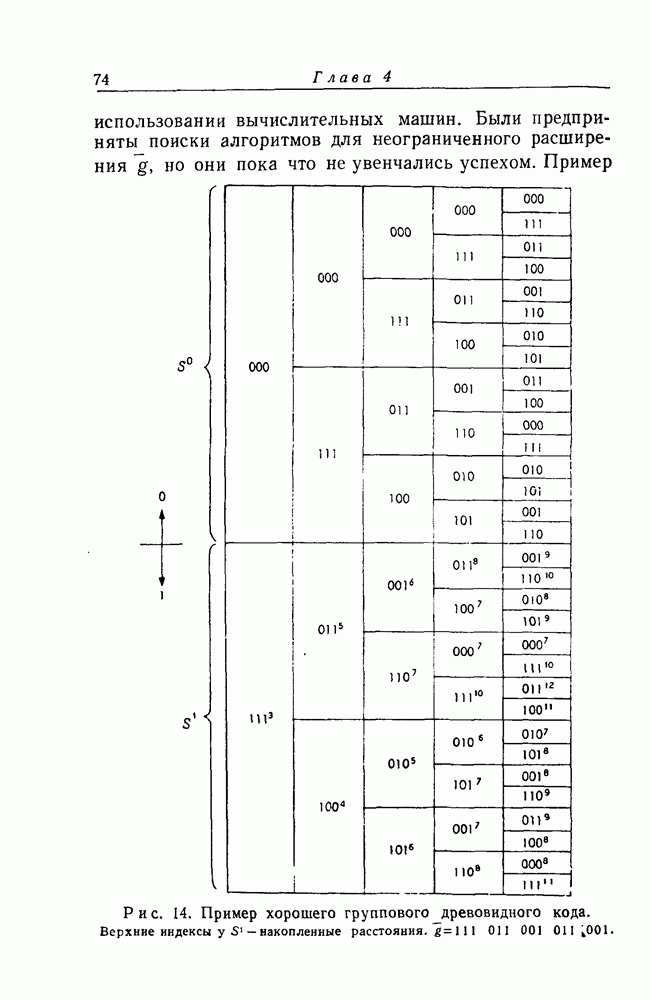
неизменной. Таким образом, особый групповой код  впервые рассмотренный Элайесом [21] и названный им сверточным кодом, обладает свойствами групповой симметрии, рассмотренными в гл. 2. Поведение этого кода при декодировании во всех отношениях не зависит от выбора информационной последовательности х.
впервые рассмотренный Элайесом [21] и названный им сверточным кодом, обладает свойствами групповой симметрии, рассмотренными в гл. 2. Поведение этого кода при декодировании во всех отношениях не зависит от выбора информационной последовательности х.