Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
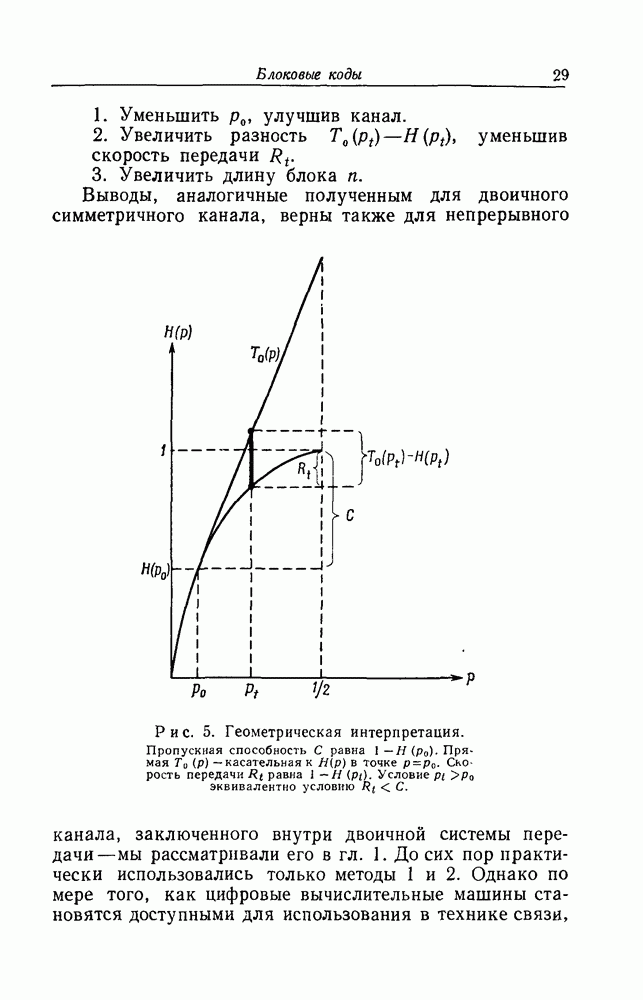
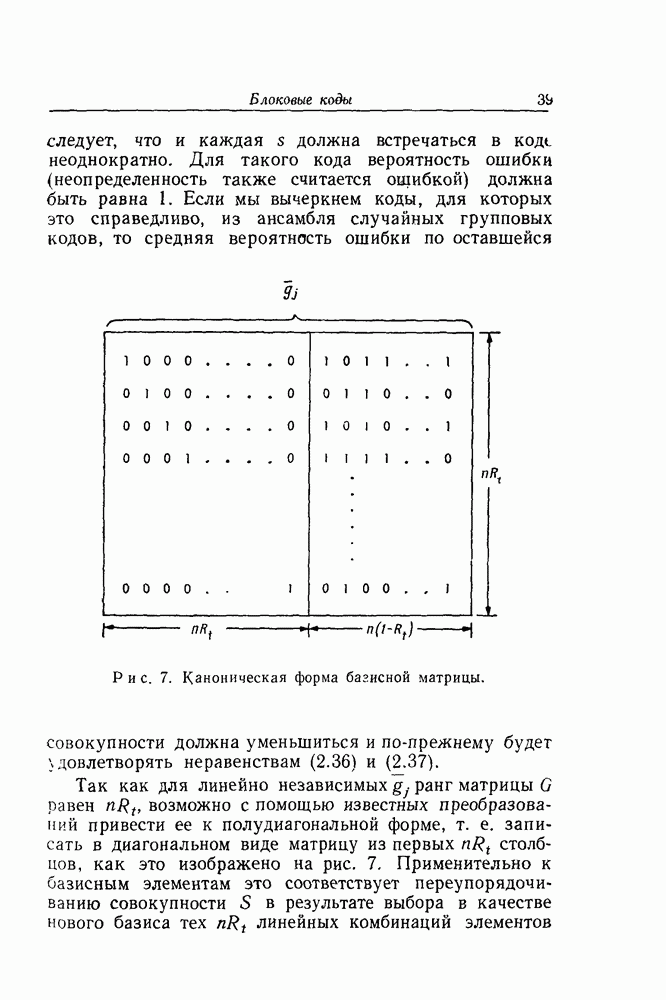
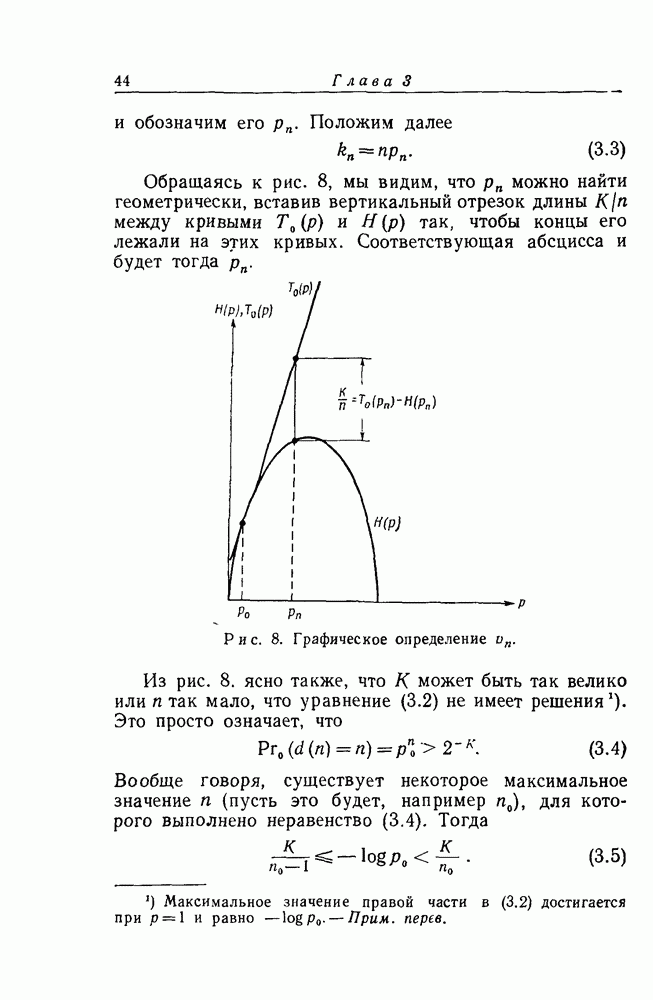
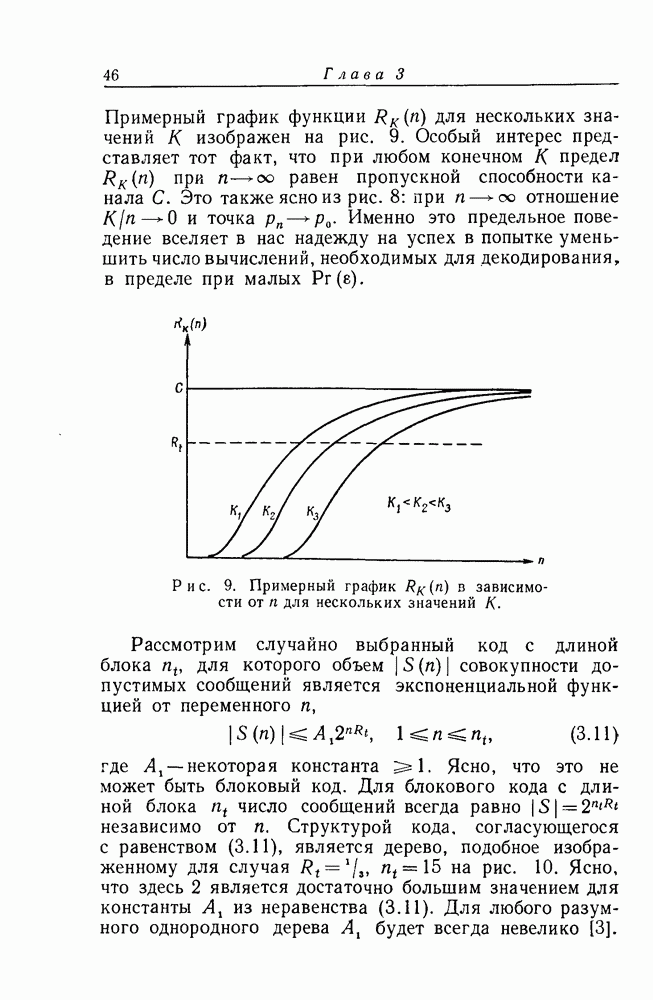
1. Результаты экспериментаВ эксперименте, поставленном в Линкольновской лаборатории, скорость передачи Основные экспериментальные результаты сведены в табл. 1. Всего было декодировано Таблица I (см. скан) символов, причем для каждой из 6 выбранных пар Ни один из 24 000 информационных символов не был декодирован ошибочно. Это неудивительно: для наихудшего случая
и в этом случае было декодировано только 4000 символов. Так как первые 24 символа порождающей последовательности при помощи процедуры, описанной в гл. 4, нижняя граница этой вероятности, по-видимому, более точна. Вслед за этим регулярным экспериментом был намеренно введен чисто шумовой отрезок, сменивший случайный шум с Полученные выше результаты относительно среднего за большое время объема вычислений были рассмотрены с целью подтверждения общей пригодности последовательного декодирования. Однако с технической точки зрения степень стабильности рабочих характеристик системы столь же важна, как и их средние значения. Последовательно декодирующее устройство наблюдает отрезок полученной последовательности у длиной в из
Рис. 16. Бесконечное марковское приближение. Каждый шаг марковского процесса соответствует декодированию одного информационного символа. Попадание в состояние Марковское представление кажется здесь хорошо оправдывающимся. Таблица 2 (см. скан) В связи с равенством (3.21) заметим, что среднее количество вычислений, нужное для того, чтобы проследить множество В реальной системе связи мы чаще всего встречаемся с ситуацией, когда сообщение у на выходе возникает с постоянной скоростью, измеряемой числом символов в секунду. При этом декодирующее вычислительное устройство имеет фиксированный объем памяти и может совершать лишь фиксированное число операций в секунду. Флуктуации в требуемой вычислительной работе будут вызывать появление очереди, если "типовое" количество вычислительной работы превысит вычислительную способность декодирующего устройства. Пусть
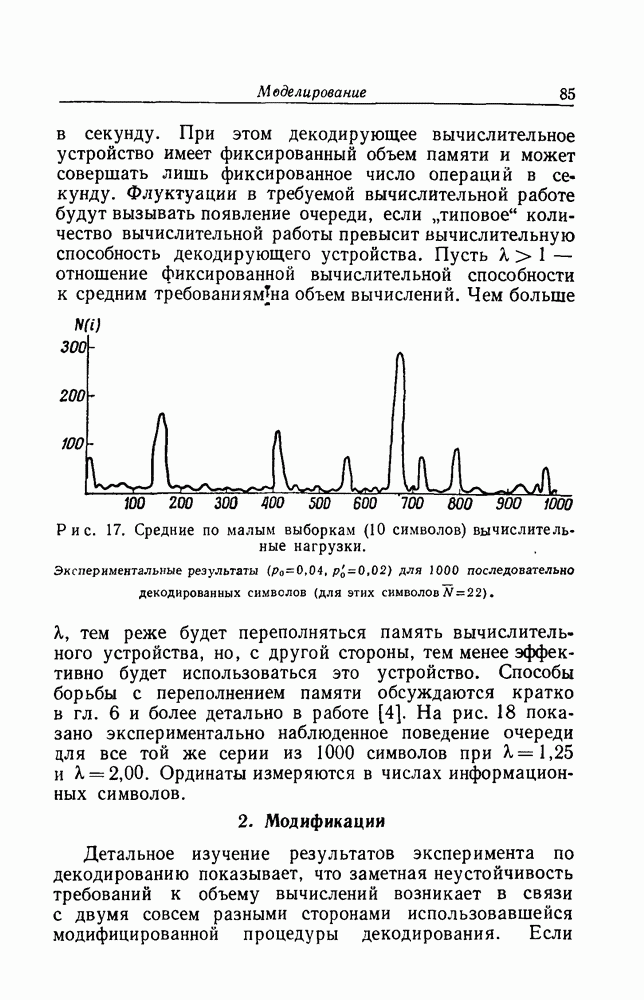
Рис. 17. Средние по малым выборкам (10 символов) вычислительные нагрузки. Экспериментальные результаты Чем больше
|
 |
Оглавление
|






































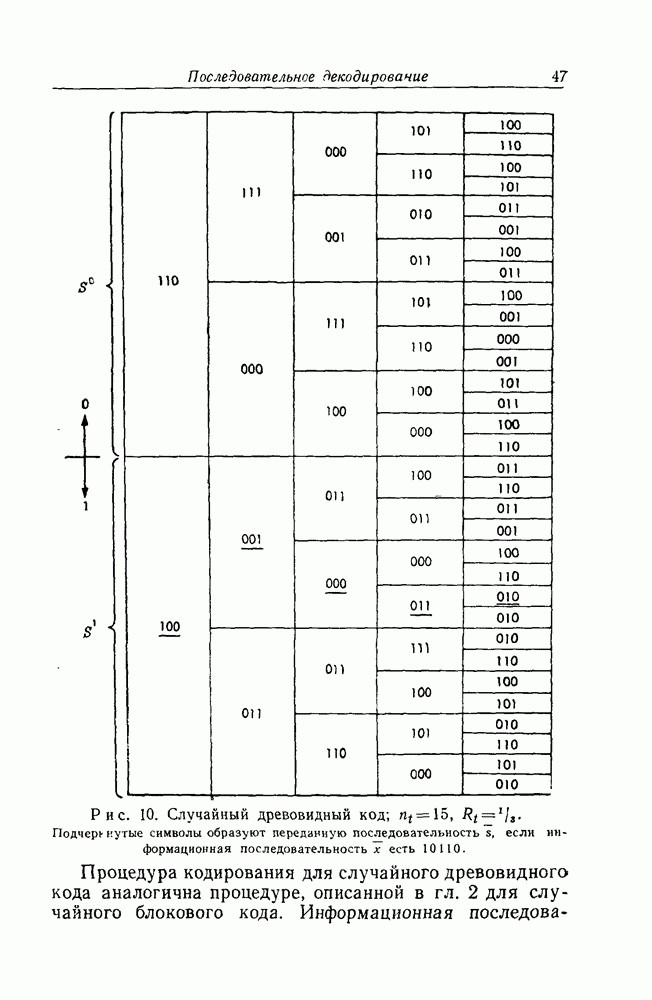

































































































 и длина кодового ограничения
и длина кодового ограничения  поддерживались постоянными и равными
поддерживались постоянными и равными  соответственно. Рассматривались две совокупности переходных вероятностей: истинная переходная вероятность моделируемого ДСК (обозначается
соответственно. Рассматривались две совокупности переходных вероятностей: истинная переходная вероятность моделируемого ДСК (обозначается  ) и переходная вероятность, используемая при вычислении функций
) и переходная вероятность, используемая при вычислении функций  задающих критерий (обозначается
задающих критерий (обозначается  ).
).
 информационных
информационных
 декодировались 4 серии по 1000 последовательных символов. Через
декодировались 4 серии по 1000 последовательных символов. Через  в таблице обозначено общее число фактически проделанных вычислительной машиной сравнений двоичных символов, деленное на число (4000). обработанных двоичных символов. Для полноты в таблицу внесено также отношение
в таблице обозначено общее число фактически проделанных вычислительной машиной сравнений двоичных символов, деленное на число (4000). обработанных двоичных символов. Для полноты в таблицу внесено также отношение  (скорости передачи к пропускной способности канала) и параметр В, входящий в формулу для определения границы количества вычислений. На протяжении всего эксперимента из 72 000 переданных двоичных символов было исключено 2434 ошибки передачи. Для самой плохой серии из 1000 информационных символов средний объем вычислений для декодирования
(скорости передачи к пропускной способности канала) и параметр В, входящий в формулу для определения границы количества вычислений. На протяжении всего эксперимента из 72 000 переданных двоичных символов было исключено 2434 ошибки передачи. Для самой плохой серии из 1000 информационных символов средний объем вычислений для декодирования  оказался равным 93,3 и из 3000 переданных символов было исключено 204 ошибки передачи. Наибольшее число ошибок, появившихся одновременно внутри отрезка длины
оказался равным 93,3 и из 3000 переданных символов было исключено 204 ошибки передачи. Наибольшее число ошибок, появившихся одновременно внутри отрезка длины  равнялось 13.
равнялось 13.
 узкие границы для достижимой вероятности ошибки блокового кода при
узкие границы для достижимой вероятности ошибки блокового кода при  равны
равны

 примененной в эксперименте, были выбраны
примененной в эксперименте, были выбраны
 для того, чтобы гарантировать появление ошибки. После того как была сделана первая ошибка, декодирование продолжалось еще для 61 дополнительного информационного символа. Примерно половина из этих символов была декодирована ошибочно, по-видимому со случайным выбором самих этих символов. Объем декодирования для одного решения менялся между 1489 и 6574. Экспериментаторы предприняли это для того, чтобы подтвердить первоначальную гипотезу о том, что после первой ошибки декодирующее устройство полностью "теряет рассудок".
для того, чтобы гарантировать появление ошибки. После того как была сделана первая ошибка, декодирование продолжалось еще для 61 дополнительного информационного символа. Примерно половина из этих символов была декодирована ошибочно, по-видимому со случайным выбором самих этих символов. Объем декодирования для одного решения менялся между 1489 и 6574. Экспериментаторы предприняли это для того, чтобы подтвердить первоначальную гипотезу о том, что после первой ошибки декодирующее устройство полностью "теряет рассудок".
 символов. После того как принято решение о декодировании, декодирующее устройство отбрасывает начало отрезка последовательности у и добавляет к ней новое окончание. Неблагоприятные наборы шумовых символов воздействуют на
символов. После того как принято решение о декодировании, декодирующее устройство отбрасывает начало отрезка последовательности у и добавляет к ней новое окончание. Неблагоприятные наборы шумовых символов воздействуют на  идущих друг за другом решений, и соседние решения о декодировании оказываются в сильной степени зависимыми. Если информационный символ
идущих друг за другом решений, и соседние решения о декодировании оказываются в сильной степени зависимыми. Если информационный символ  декодируется при помоши
декодируется при помоши  критерия, то мы можем ожидать, что символ
критерия, то мы можем ожидать, что символ  будет декодироваться при помощи
будет декодироваться при помощи  или же
или же  критерия. Поэтому кажется разумным аппроксимировать процесс декодирования бесконечным марковским процессом, показанным на рис. 16. Вероятность перехода из состояния
критерия. Поэтому кажется разумным аппроксимировать процесс декодирования бесконечным марковским процессом, показанным на рис. 16. Вероятность перехода из состояния  снова в состояние
снова в состояние  отражает устойчивость процесса декодирования и должна увеличиваться при возрастании
отражает устойчивость процесса декодирования и должна увеличиваться при возрастании  В табл. 2 мы привели для одной типичной выборки из 1000 последовательных декодируемых символов число решений, принятых при помощи каждого
В табл. 2 мы привели для одной типичной выборки из 1000 последовательных декодируемых символов число решений, принятых при помощи каждого
 критериев, и число переходов вверх, в то же состояние и вниз. Кроме того, имели место три более длинных перескока: из 3 в 1, из 4 в 2 и из 5 в 2.
критериев, и число переходов вверх, в то же состояние и вниз. Кроме того, имели место три более длинных перескока: из 3 в 1, из 4 в 2 и из 5 в 2.

 соответствует декодированию при помощи
соответствует декодированию при помощи  критерия.
критерия.
 при помощи
при помощи  критерия, при изменении
критерия, при изменении  меняется экспоненциально. Этот результат в совокупности с марковским представлением заставляет ожидать значительной нестабильности средних по малым выборкам объемов вычислений для последовательных алгоритмов. Рис. 17 ярко иллюстрирует это явление на материале той же типичной серии из 1000 символов, которую мы рассматривали в табл. 2. Заметим, что длительность пиков вычислений равна примерно
меняется экспоненциально. Этот результат в совокупности с марковским представлением заставляет ожидать значительной нестабильности средних по малым выборкам объемов вычислений для последовательных алгоритмов. Рис. 17 ярко иллюстрирует это явление на материале той же типичной серии из 1000 символов, которую мы рассматривали в табл. 2. Заметим, что длительность пиков вычислений равна примерно  символам, как и следовало ожидать.
символам, как и следовало ожидать.
 отношение фиксированной вычислительной способности к средним требованиямна объем вычислений.
отношение фиксированной вычислительной способности к средним требованиямна объем вычислений.

 для 1000 последовательно декодированных символов (для этих символов
для 1000 последовательно декодированных символов (для этих символов 
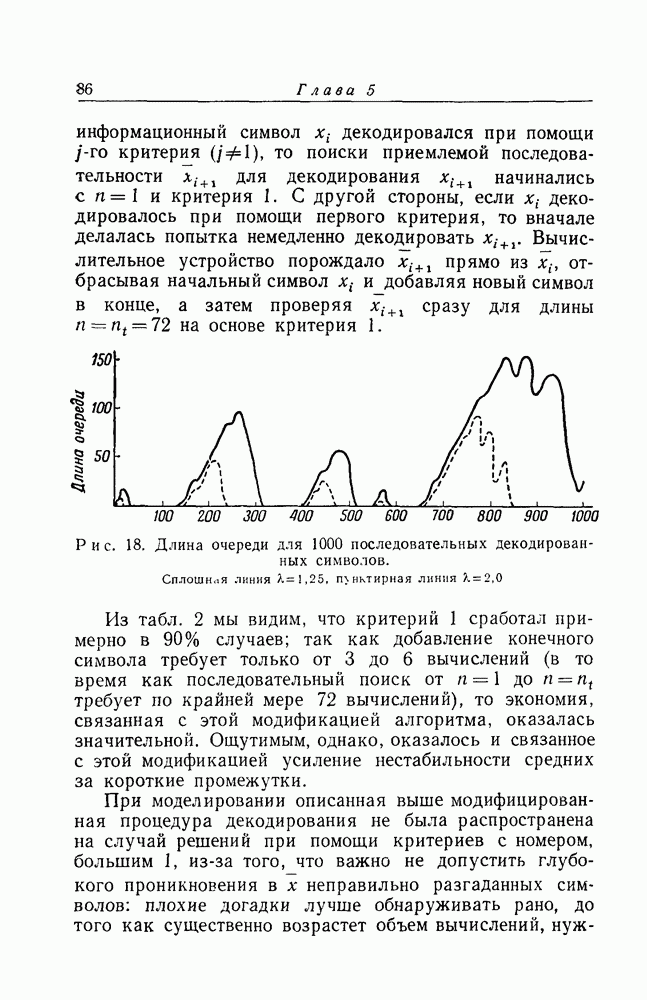
 , тем реже будет переполняться память вычислительного устройства, но, с другой стороны, тем менее эффективно будет использоваться это устройство. Способы борьбы с переполнением памяти обсуждаются кратко в гл. 6 и более детально в работе [4]. На рис. 18 показано экспериментально наблюденное поведение очереди для все той же серии из 1000 символов при
, тем реже будет переполняться память вычислительного устройства, но, с другой стороны, тем менее эффективно будет использоваться это устройство. Способы борьбы с переполнением памяти обсуждаются кратко в гл. 6 и более детально в работе [4]. На рис. 18 показано экспериментально наблюденное поведение очереди для все той же серии из 1000 символов при  Ординаты измеряются в числах информационных символов.
Ординаты измеряются в числах информационных символов.