Глава 3. ПОСЛЕДОВАТЕЛЬНОЕ ДЕКОДИРОВАНИЕ
1. Основные идеи
Открытие того факта, что при скорости передачи  меньшей пропускной способности С канала можно достичь любой степени надежности передачи информации, заставило инженеров-связистов попытаться построить реальную систему, обладающую подобными свойствами. Мы уже видели в гл. 2, что вопрос о задании хорошего кода, удовлетворяющего почти всем нашим требованиям, не приводит к серьезным затруднениям. Такое кодирование может быть проведено с использованием оборудования, сложность которого с ростом
меньшей пропускной способности С канала можно достичь любой степени надежности передачи информации, заставило инженеров-связистов попытаться построить реальную систему, обладающую подобными свойствами. Мы уже видели в гл. 2, что вопрос о задании хорошего кода, удовлетворяющего почти всем нашим требованиям, не приводит к серьезным затруднениям. Такое кодирование может быть проведено с использованием оборудования, сложность которого с ростом  растет линейным образом.
растет линейным образом.
Проблема декодирования остается, однако, открытой: общая процедура декодирования по методу максимума правдоподобия требует или проведения  последовательных сравнений, или же наличия словаря с
последовательных сравнений, или же наличия словаря с  строками. Для многих интересных каналов из рассмотрения вероятности ошибки и эффективности передачи вытекает, что желательны значения
строками. Для многих интересных каналов из рассмотрения вероятности ошибки и эффективности передачи вытекает, что желательны значения  лежащие между 30 и хотя бы 60. Требуемые числа меняются в этом случае от
лежащие между 30 и хотя бы 60. Требуемые числа меняются в этом случае от  до
до  : с экспоненциальной функцией шутить нельзя!
: с экспоненциальной функцией шутить нельзя!
К счастью, при наших поисках разумных методов передачи мы не обязаны ограничиваться рассмотрением только идеальной процедуры декодирования по методу максимума правдоподобия. Экспоненциальное убывание  при возрастании
при возрастании  является достаточно сильным, чтобы можно было не заботиться об уменьшении коэффициента при экспоненциальном члене по крайней мере в пределе при больших
является достаточно сильным, чтобы можно было не заботиться об уменьшении коэффициента при экспоненциальном члене по крайней мере в пределе при больших  Для нас естественно попытаться найти другие схемы, которые вносят упрощение
Для нас естественно попытаться найти другие схемы, которые вносят упрощение
в декодирование, но не влияют на экспоненту, входящую в формулу для вероятности ошибки.
Например, интуитивно ясно, что почти все из совокупности случайно выбранных  сообщений будут в значительной мере отличаться от полученного сообщения у. Конечно, в
сообщений будут в значительной мере отличаться от полученного сообщения у. Конечно, в  может найтись подмножество сообщений, во многих позициях согласующихся с у, но объем этого подмножества будет невелик. И хотя выбор одной единстввнной наиболее вероятной последовательности из
может найтись подмножество сообщений, во многих позициях согласующихся с у, но объем этого подмножества будет невелик. И хотя выбор одной единстввнной наиболее вероятной последовательности из  при заданном
при заданном  может оказаться трудным, исключить из подробного рассмотрения большую часть возможных
может оказаться трудным, исключить из подробного рассмотрения большую часть возможных  сравнительно просто. Сосредоточение усилий не на выборе наиболее вероятной последовательности
сравнительно просто. Сосредоточение усилий не на выборе наиболее вероятной последовательности  а на исключении всех маловероятных последовательностей
а на исключении всех маловероятных последовательностей  должно представлять ключевую позицию стратегии декодирования, которую мы теперь обсудим. Слово "маловероятный" должно быть, конечно, точно определено.
должно представлять ключевую позицию стратегии декодирования, которую мы теперь обсудим. Слово "маловероятный" должно быть, конечно, точно определено.
Предположим, для начала, довольно произвольно, что слова "маловероятная последовательность" означают, что эта последовательность отличается от последовательности у длины  или более символах. Для заданной вероятности перехода
или более символах. Для заданной вероятности перехода  канала и заданного
канала и заданного  удобно определить эту исключающую функцию
удобно определить эту исключающую функцию  так, чтобы вероятность того, что при передаче произойдет
так, чтобы вероятность того, что при передаче произойдет  или более ошибок, была ограничена сверху числом
или более ошибок, была ограничена сверху числом  где К — некоторая произвольная положительная ронстанта, которую мы назовем "вероятностным критерием":
где К — некоторая произвольная положительная ронстанта, которую мы назовем "вероятностным критерием":

Найти точное решение этого неравенства для наибольшего возможного значения  было бы утомительной задачей. Однако мы можем совсем просто получить функцию, которая вполне соответствует нашим целям, используя границу Чернова
было бы утомительной задачей. Однако мы можем совсем просто получить функцию, которая вполне соответствует нашим целям, используя границу Чернова

Определим значение  соотношением
соотношением

и обозначим его  Положим далее
Положим далее

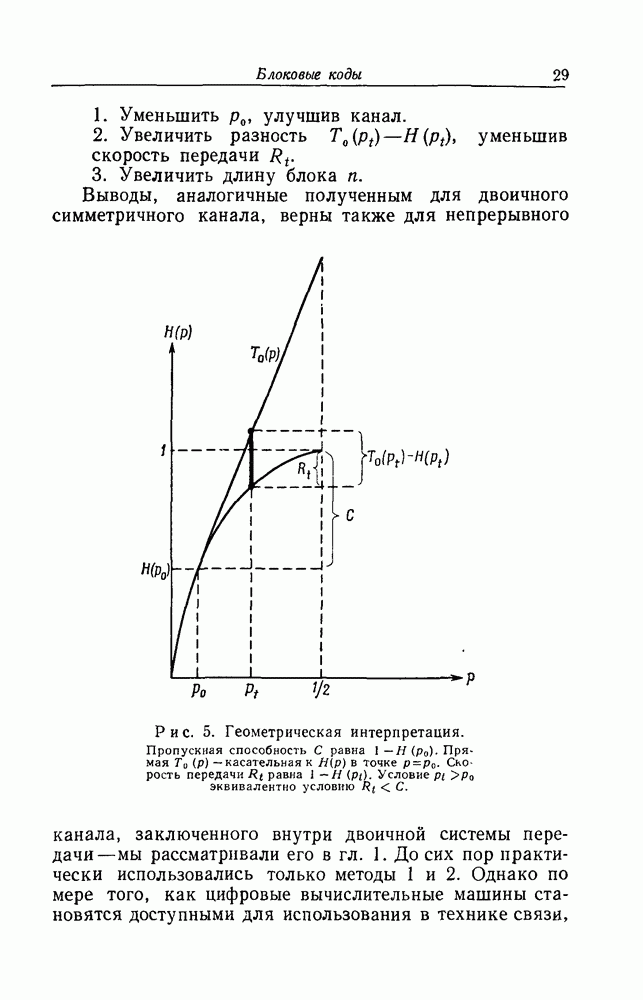
Обращаясь к рис. 8, мы видим, что  можно найти геометрически, вставив вертикальный отрезок длины
можно найти геометрически, вставив вертикальный отрезок длины  между кривыми
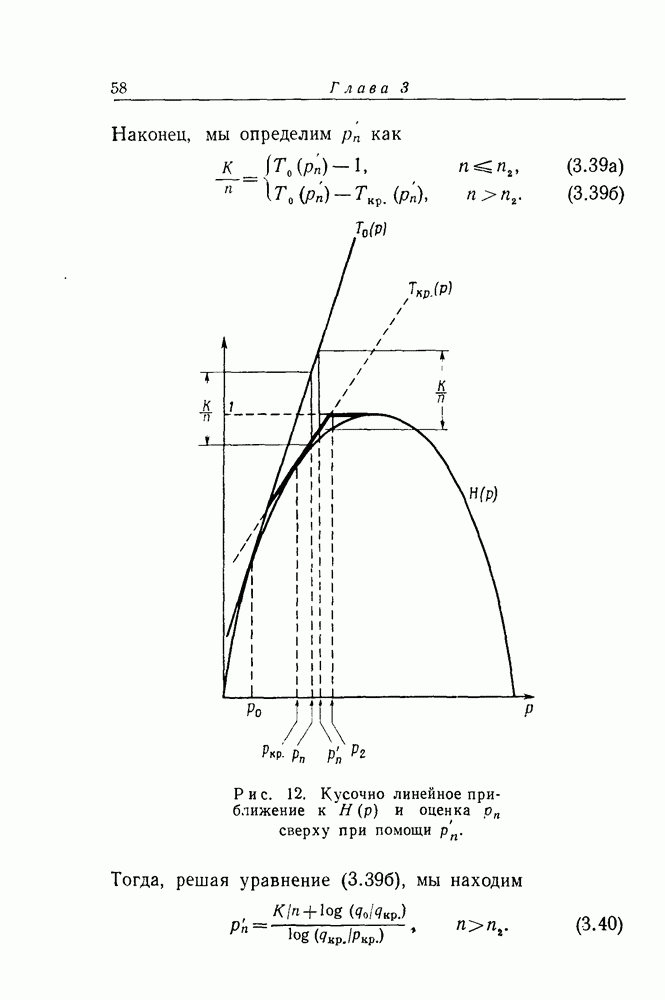
между кривыми  и
и  так, чтобы концы его лежали на этих кривых. Соответствующая абсцисса и будет тогда
так, чтобы концы его лежали на этих кривых. Соответствующая абсцисса и будет тогда 

Рис. 8. Графическое определение 
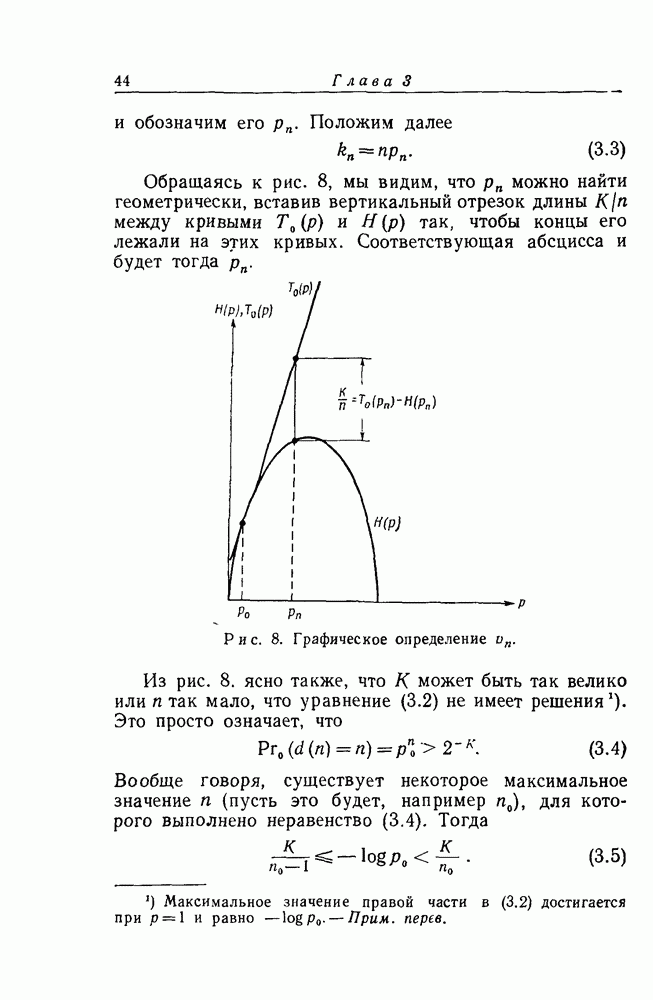
Из рис. 8. ясно также, что К может быть так велико или  так мало, что уравнение (3.2) не имеет решения. Это просто означает, что
так мало, что уравнение (3.2) не имеет решения. Это просто означает, что

Вообще говоря, существует некоторое максимальное значение  (пусть это будет, например
(пусть это будет, например  ), для которого выполнено неравенство (3.4). Тогда
), для которого выполнено неравенство (3.4). Тогда

Таким образом, мы определяем 

Если  задано [например, соотношением (3.6)], то наша цель состоит в том, чтобы исключить из
задано [например, соотношением (3.6)], то наша цель состоит в том, чтобы исключить из  все сообщения, отличающиеся от у не менее, чем в
все сообщения, отличающиеся от у не менее, чем в  из
из  символов. Мы попытаемся сделать это для каждого значения
символов. Мы попытаемся сделать это для каждого значения  которое меньше длины блока, выбираемого при кодировании. Чтобы отличать эту длину блока от переменного
которое меньше длины блока, выбираемого при кодировании. Чтобы отличать эту длину блока от переменного  мы будем обозначать ее
мы будем обозначать ее  В конечном счете мы хотим узнать, сколь велико число последовательностей, оставшихся в
В конечном счете мы хотим узнать, сколь велико число последовательностей, оставшихся в  и отличных от переданной.
и отличных от переданной.
Здесь нам снова удобно вернуться к случайному кодированию. В предположении, что каждый двоичный символ в кодовой книге  выбирается независимо и случайно с
выбирается независимо и случайно с  для оценки вероятности того, что фиксированная последовательность
для оценки вероятности того, что фиксированная последовательность  отличная от переданной, не будет отброшена вплоть до
отличная от переданной, не будет отброшена вплоть до  этапа, мы можем использовать границу Чернова, задаваемую соотношением
этапа, мы можем использовать границу Чернова, задаваемую соотношением  :
:

Достаточно точной верхней границей для  при
при  является единица. Существует некоторое минимальное значение
является единица. Существует некоторое минимальное значение  (мы будем обозначать его
(мы будем обозначать его  для которого
для которого  Из рис. 9 видно, что, так как
Из рис. 9 видно, что, так как

Теперь нам удобно ввести функцию

Таким образом, получаем, что

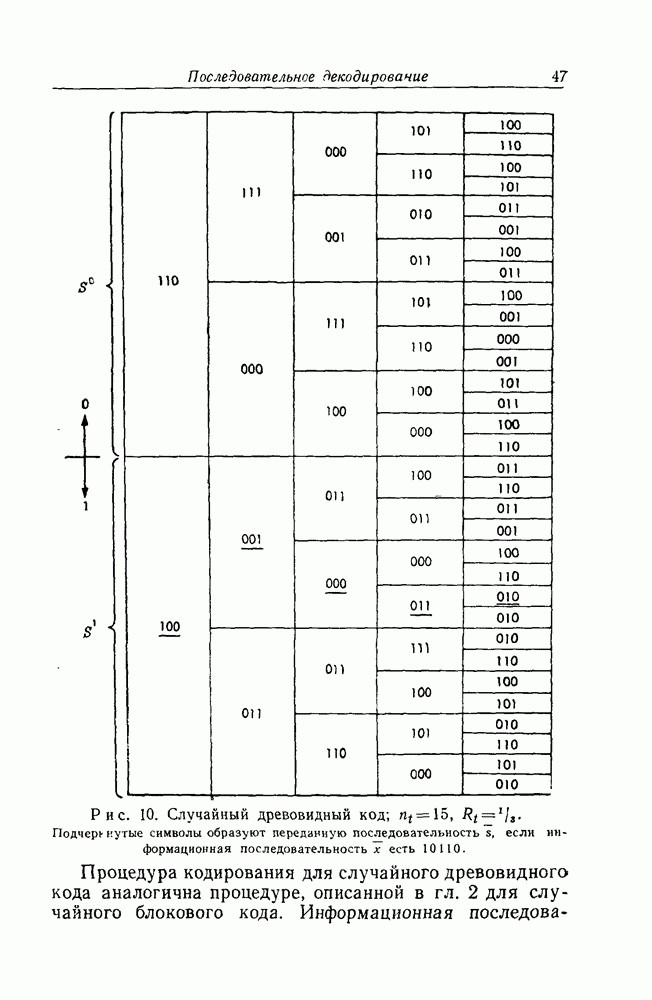
Рис. 10. (см. скан) Случайный древовидный код;  Подчеркнутые символы образуют переданную последовательность
Подчеркнутые символы образуют переданную последовательность  если информационная последовательность х есть 10110.
если информационная последовательность х есть 10110.
Процедура кодирования для случайного древовидного кода аналогична процедуре, описанной в гл. 2 для случайного блокового кода. Информационная
последовательность х задает правила, которые позволяют выбрать некоторый путь по дереву  Мы примем соглашение, что если
Мы примем соглашение, что если  символ
символ  последовательности х равен нулю, то мы пойдем по верхней ветви, исходящей из
последовательности х равен нулю, то мы пойдем по верхней ветви, исходящей из  узла дерева; если же
узла дерева; если же  равно единице, то по нижней ветви. Передаваемая последовательность
равно единице, то по нижней ветви. Передаваемая последовательность  состоит из символов, лежащих на выбранном пути по дереву. Иллюстрирующий пример приведен на рис. 10
состоит из символов, лежащих на выбранном пути по дереву. Иллюстрирующий пример приведен на рис. 10  .
.
Исходя из древовидной структуры множества сообщений, которое мы рассматриваем, мы будем при декодировании стараться принять решение только о первом информационном символе  Этот символ делит все древовидное множество
Этот символ делит все древовидное множество  на два подмножества:
на два подмножества:  подмножество всех
подмножество всех  для которых
для которых  — подмножество всех
— подмножество всех  для которых
для которых  Задача при декодировании первого символа состоит в том, чтобы решить, будет ли полученная последовательность у сопоставлена последовательности
Задача при декодировании первого символа состоит в том, чтобы решить, будет ли полученная последовательность у сопоставлена последовательности  из
из  или же из
или же из  . В гл. 4 мы рассмотрим построение бесконечного древовидного кода и проведение декодирующей процедуры для определения информационных символов
. В гл. 4 мы рассмотрим построение бесконечного древовидного кода и проведение декодирующей процедуры для определения информационных символов 
Разумность использования случайного древовидного кода вытекает из рассмотрения среднего числа сообщений  не совпадающих с истинным, но отличающихся от полученной последовательности у меньше, чем в
не совпадающих с истинным, но отличающихся от полученной последовательности у меньше, чем в  местах (которые, следовательно, не отбрасываются при заданном
местах (которые, следовательно, не отбрасываются при заданном  При фиксированном
При фиксированном  имеется всего
имеется всего  возможных неправильных последовательностей
возможных неправильных последовательностей  и для каждой из них вероятность отбрасы. вания ограничена числом
и для каждой из них вероятность отбрасы. вания ограничена числом  [5]). Следовательно, в предположении, что до
[5]). Следовательно, в предположении, что до  символа не происходило отбрасываний, мы находим, что среднее число
символа не происходило отбрасываний, мы находим, что среднее число  сообщений, остающихся на
сообщений, остающихся на  этапе равно
этапе равно








































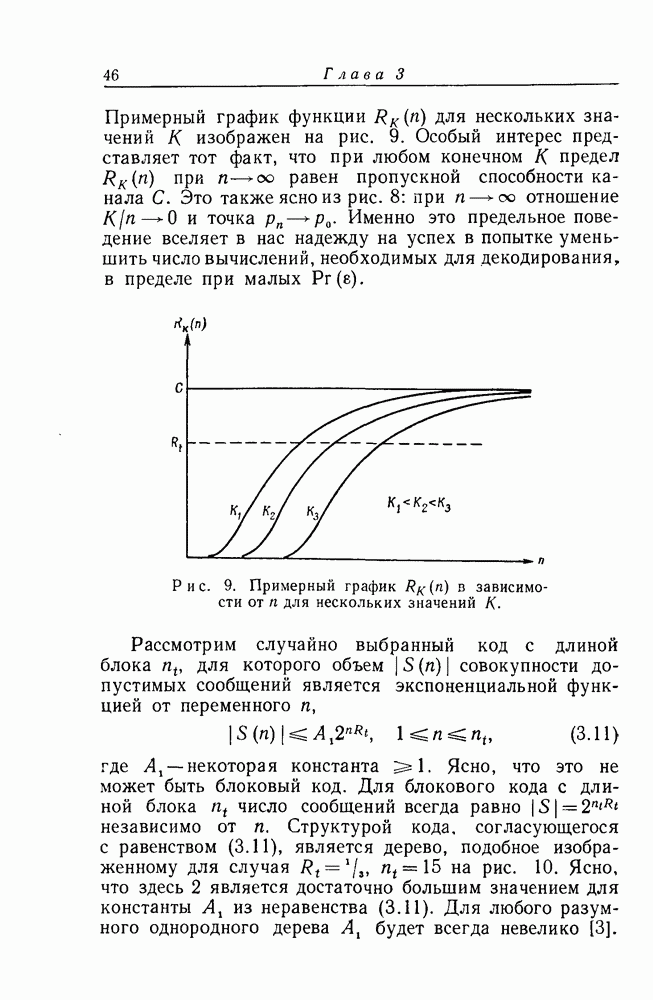







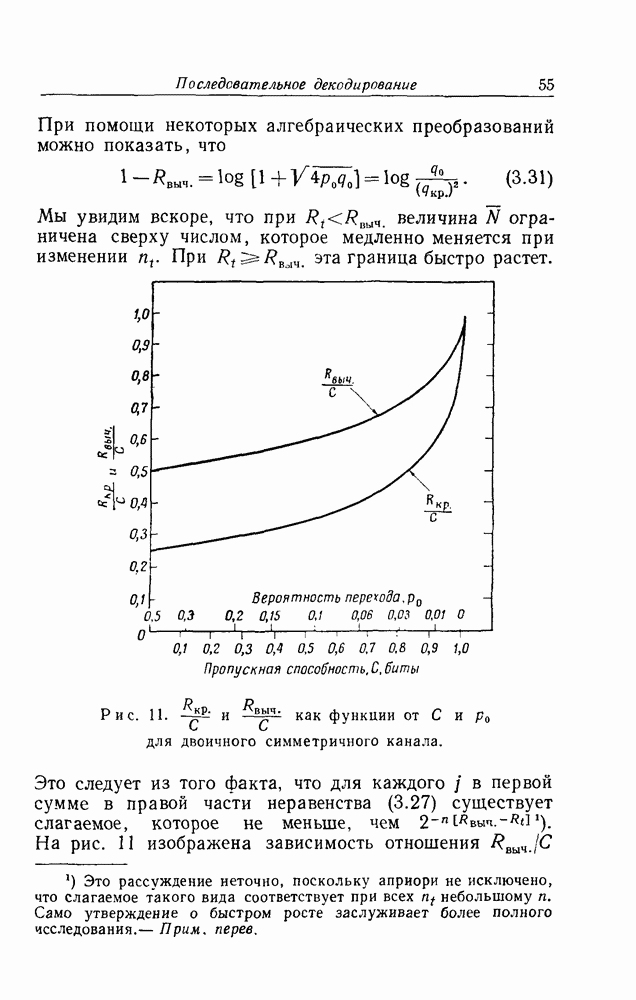



























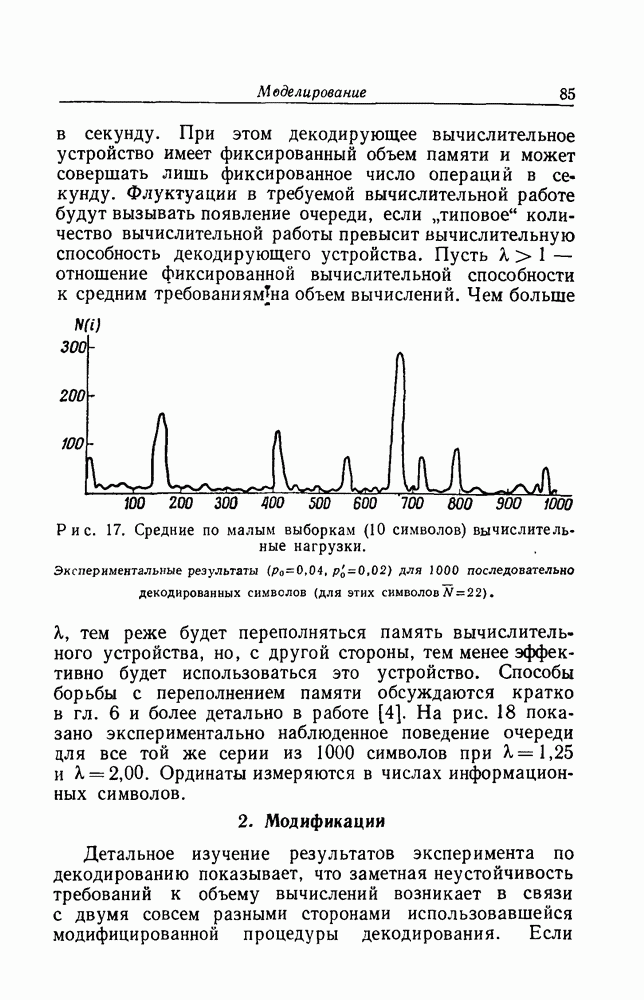































































 для нескольких значений К изображен на рис. 9. Особый интерес представляет тот факт, что при любом конечном К предел
для нескольких значений К изображен на рис. 9. Особый интерес представляет тот факт, что при любом конечном К предел  при
при  равен пропускной способности канала С. Это также ясно из рис. 8: при
равен пропускной способности канала С. Это также ясно из рис. 8: при  отношение
отношение  и точка
и точка  Именно это предельное поведение вселяет в нас надежду на успех в попытке уменьшить число вычислений, необходимых для декодирования, в пределе при малых
Именно это предельное поведение вселяет в нас надежду на успех в попытке уменьшить число вычислений, необходимых для декодирования, в пределе при малых 

 в зависимости от
в зависимости от  для нескольких значений К.
для нескольких значений К.
 для которого объем
для которого объем  совокупности допустимых сообщений является экспоненциальной функцией от переменного
совокупности допустимых сообщений является экспоненциальной функцией от переменного 

 некоторая константа
некоторая константа  Ясно, что это не может быть блоковый код. Для блокового кода с длиной блока
Ясно, что это не может быть блоковый код. Для блокового кода с длиной блока  число сообщений всегда равно
число сообщений всегда равно  независимо от
независимо от  Структурой кода, согласующегося с равенством (3.11), является дерево, подобное изображенному для случая
Структурой кода, согласующегося с равенством (3.11), является дерево, подобное изображенному для случая  на рис. 10. Ясно, что здесь 2 является достаточно большим значением для константы
на рис. 10. Ясно, что здесь 2 является достаточно большим значением для константы  из неравенства (3.11). Для любого разумного однородного дерева А, будет всегда невелико [3].
из неравенства (3.11). Для любого разумного однородного дерева А, будет всегда невелико [3].
 при
при  приближается к С, а скорость передачи
приближается к С, а скорость передачи  должна быть меньше, чем С. Из рис. 9 ясно, что при
должна быть меньше, чем С. Из рис. 9 ясно, что при  большем чем некоторое
большем чем некоторое  выражение, стоящее в показателе степени в неравенстве (3.12), оказывается отрицательным. Таким образом, мы можем надеяться сделать длину кодового блока
выражение, стоящее в показателе степени в неравенстве (3.12), оказывается отрицательным. Таким образом, мы можем надеяться сделать длину кодового блока  сколь угодно большой по сравнению с
сколь угодно большой по сравнению с  для фиксированного вероятностного критерия К, не увеличивая безгранично число неправильных сообщений, которые придется рассматривать.
для фиксированного вероятностного критерия К, не увеличивая безгранично число неправильных сообщений, которые придется рассматривать.