Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
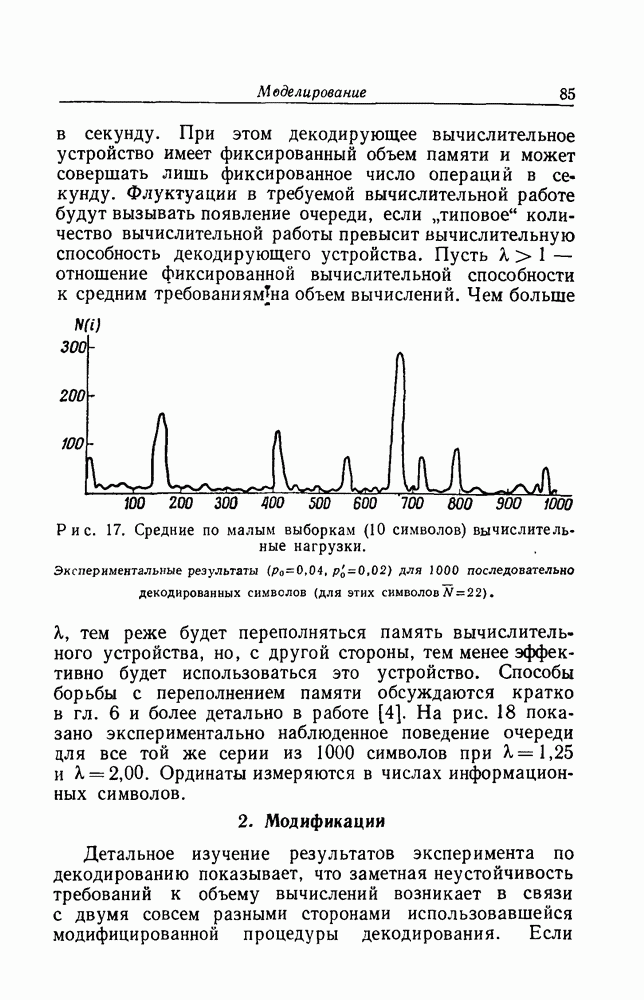
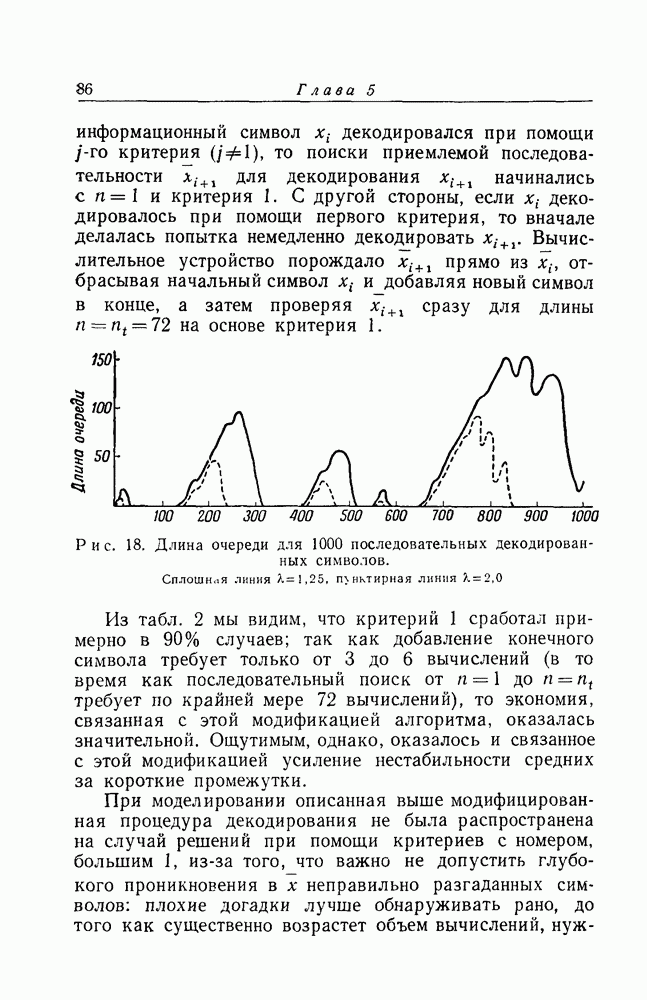
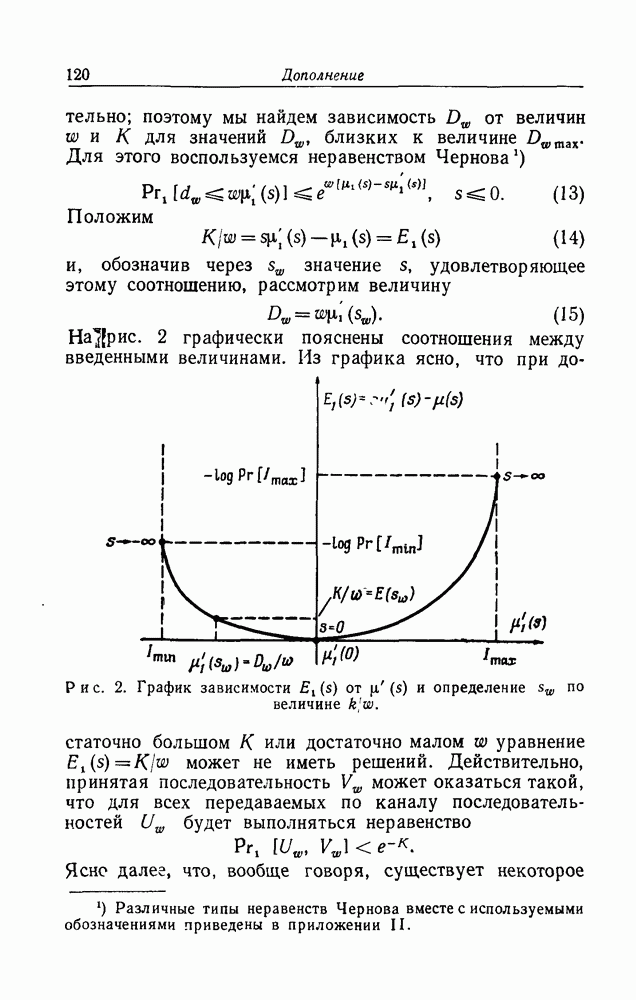
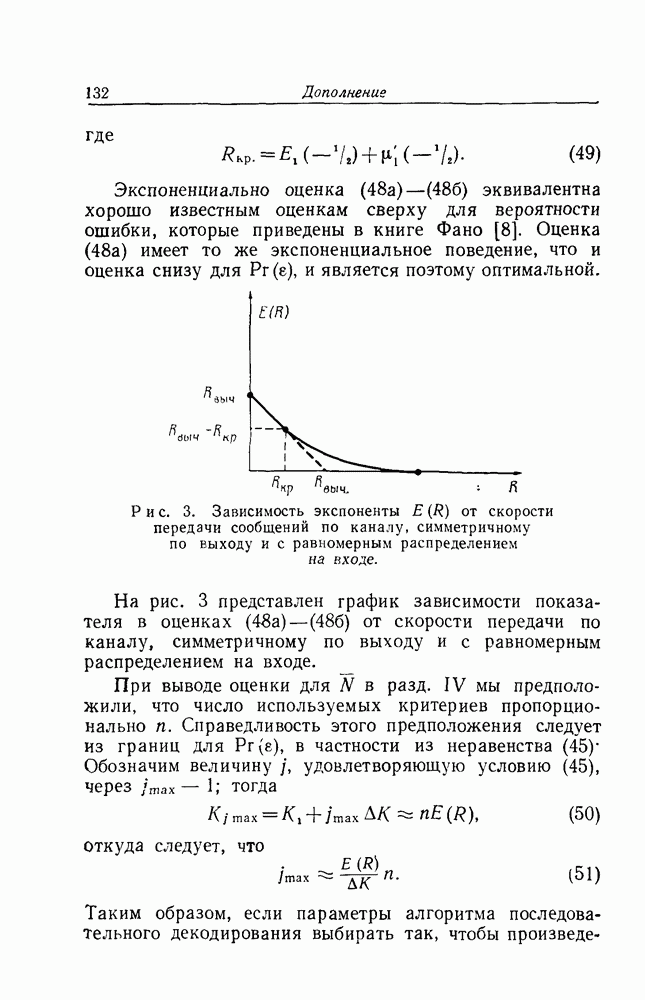
4. Действие ошибокВызывает некоторое смущение тот факт, что алгоритм последовательного декодирования полностью основывается на предположении, что при декодировании на предыдущих этапах не было совершено ни одной ошибки. Конечно, вероятность первой ошибки убывает экспоненциально при возрастании длины Имеется по существу два способа исправить этот дефект. Первый состоит в том, чтобы ресинхронизировать систему через подходящим образом выбранные интервалы времени. Предположим, что кодирование ведется так, что длина кодовых ограничений информационных символов в секунду (что можно считать удовлетворительным), то каждый интервал ресинхронизации будет иметь длину в одну секунду и в среднем один такой интервал будет искажаться раз в каждые тридцать лет. Второй метод борьбы с бедствием, приносимым первой ошибкой, состоит в том, чтобы, наоборот, использовать его. Мы видели, как теоретически, так и экспериментально, что появление ошибки сопровождается увеличением объема вычислений на один символ при декодировании. По существу ошибки декодирования объясняются неудачными комбинациями ошибок, которые должны найти свою дорогу к отрезку полученного сообщения, исследуемому в декодирующем устройстве при обработке последовательных символов. Мы можем ожидать, что с подавляюще высокой вероятностью прежде, чем произойдет ошибка, вырастет большая очередь недекодированного материала. Это утверждение подтверждается также тем замечанием, что по существу значение С контролирует вероятность ошибки, а значение Это возрастание очереди, служащее предвестником приближающейся беды, может быть использовано в двусторонней системе связи как сигнал к посылке запроса по обратному каналу с требованием о вторичной передаче трудного места. Когда в некоторой системе связи используется последовательное декодирование, то резкий рост требуемого объема вычислений, возникающий при приближении
|
 |
Оглавление
|
























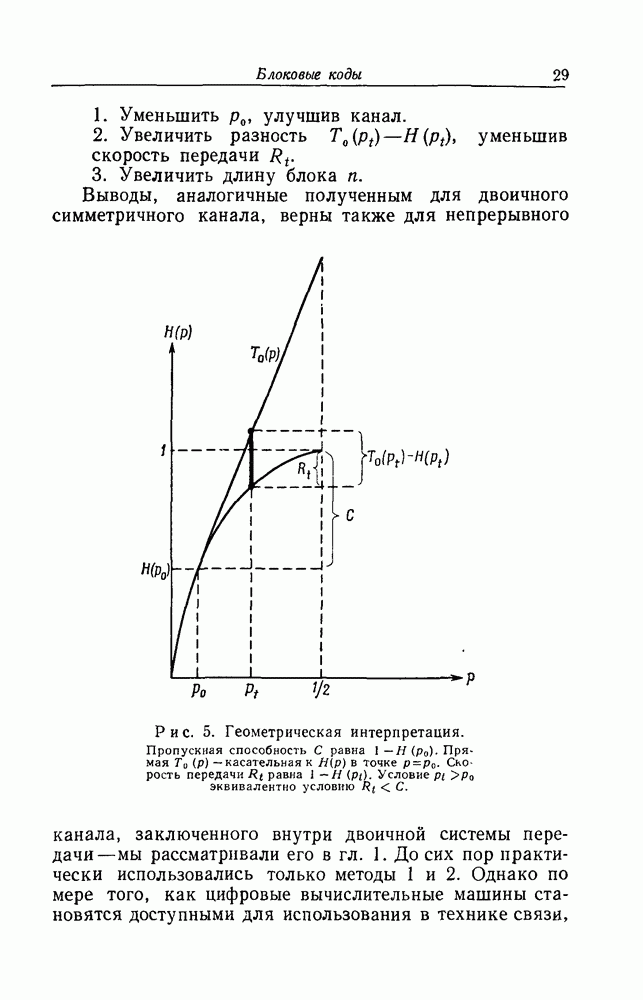









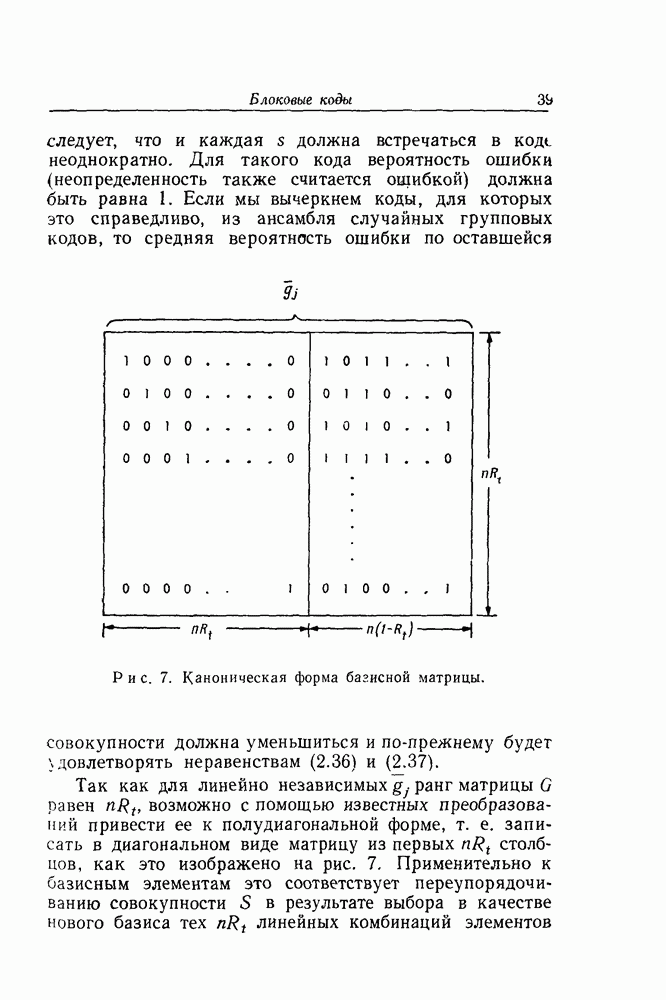




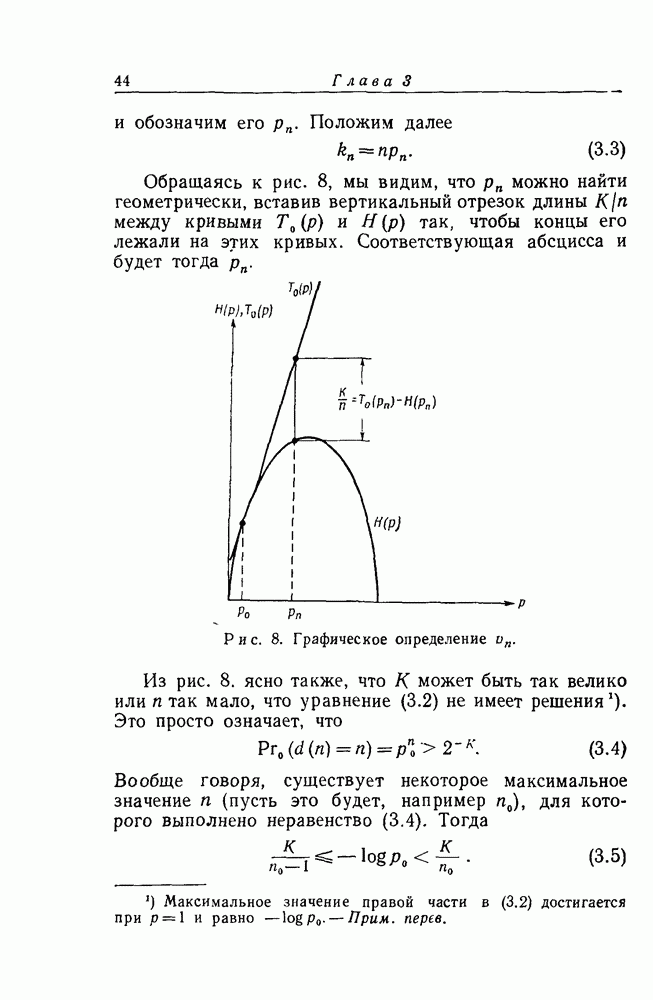

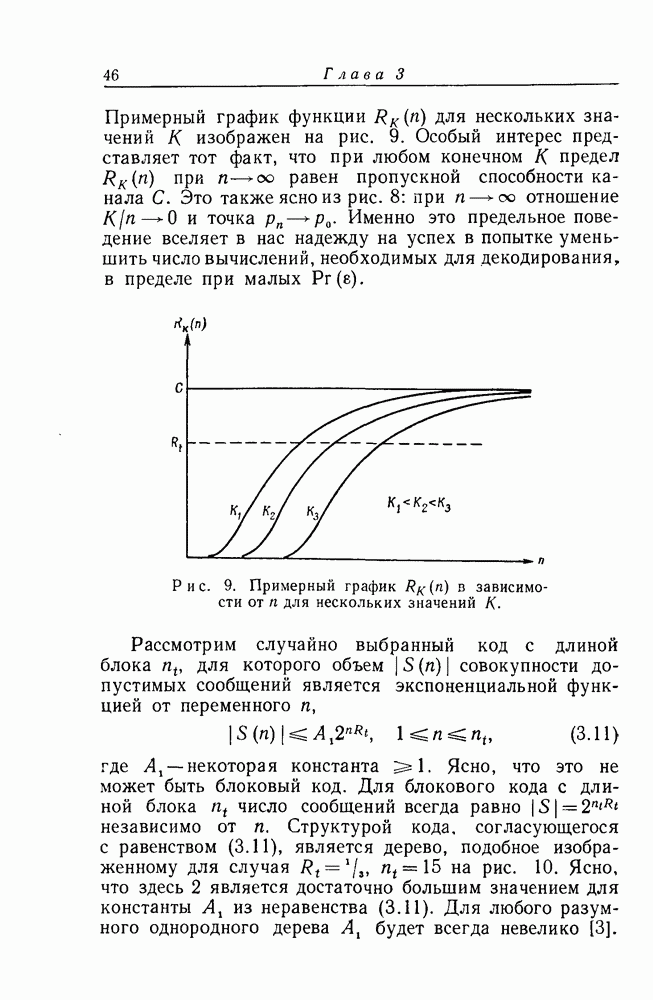
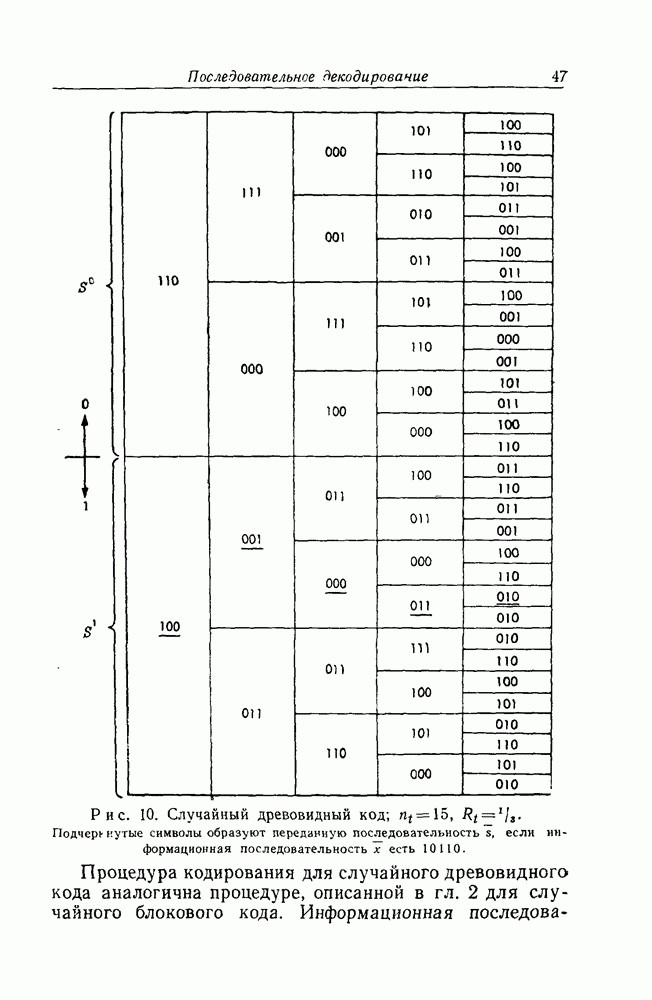







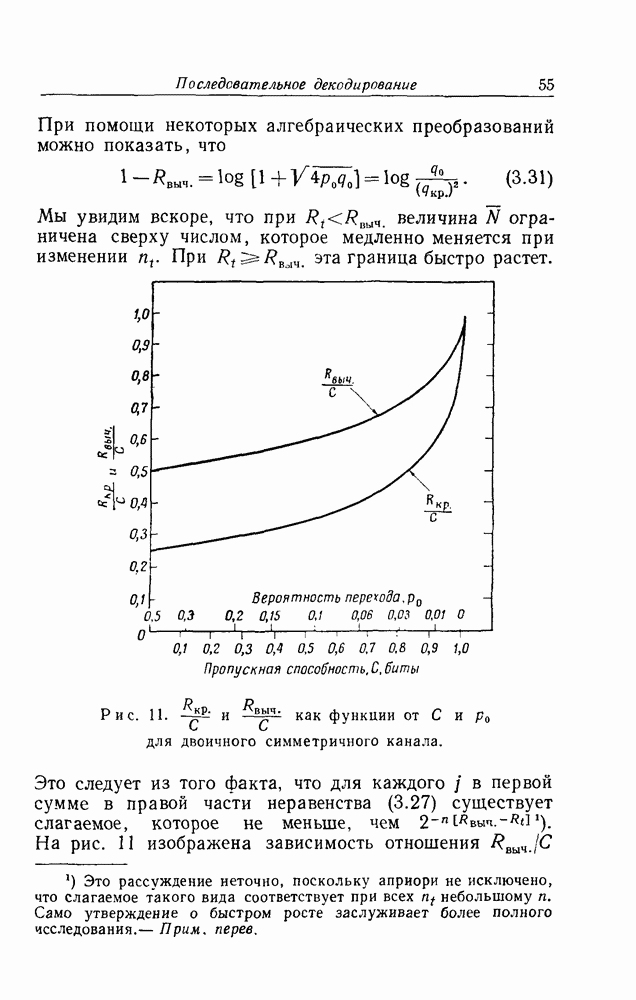


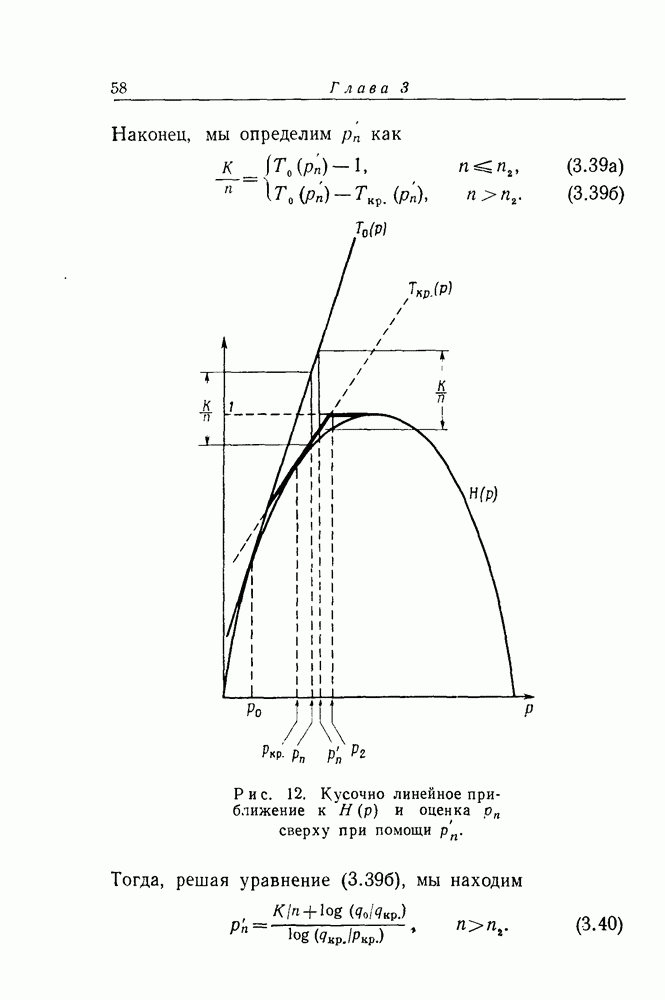















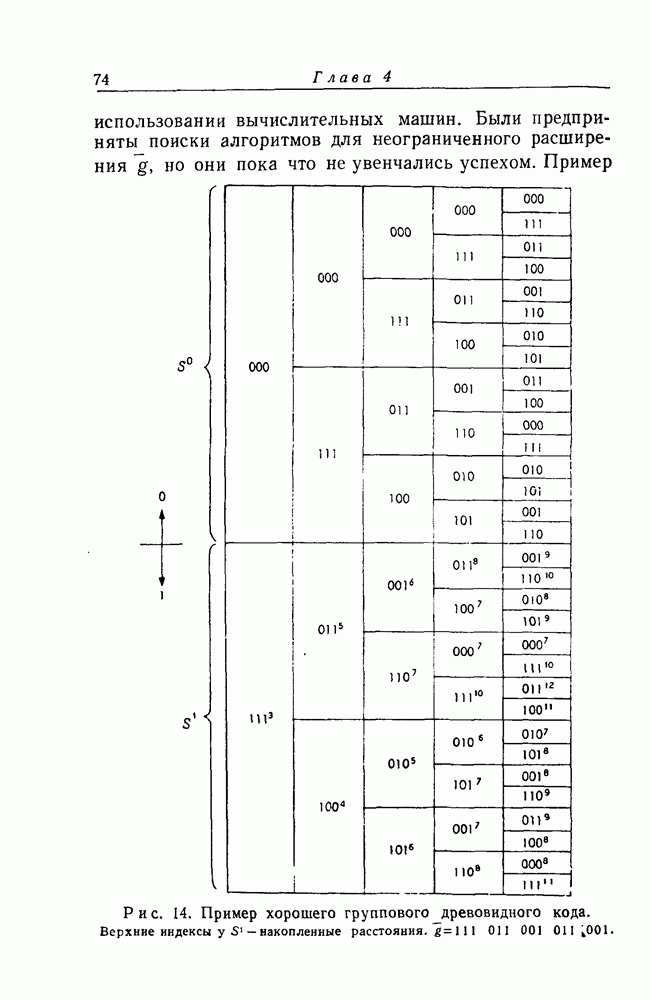









































































 кодовых ограничений. Тем не менее, при фиксированном
кодовых ограничений. Тем не менее, при фиксированном  ошибка в конце концов произойдет с вероятностью 1.
ошибка в конце концов произойдет с вероятностью 1.
 Если мы будем проводить ресинхронизацию через каждые
Если мы будем проводить ресинхронизацию через каждые  символов, то вероятность того, что в некотором интервале произойдет ошибка, будет равна примерно
символов, то вероятность того, что в некотором интервале произойдет ошибка, будет равна примерно  Для того чтобы осуществить эту ресинхронизацию, мы будем в начале каждого интервала передавать
Для того чтобы осуществить эту ресинхронизацию, мы будем в начале каждого интервала передавать  нулей до начала передачи информации. Поступив таким образом, мы уменьшим эффективную скорость передачи на
нулей до начала передачи информации. Поступив таким образом, мы уменьшим эффективную скорость передачи на  но зато предотвратим возможность распространения влияния ошибки в декодировании на соседние интервалы. Если мы передаем со скоростью
но зато предотвратим возможность распространения влияния ошибки в декодировании на соседние интервалы. Если мы передаем со скоростью 
 контролирует резкое возрастание объема вычислений.
контролирует резкое возрастание объема вычислений.
 означает, что окончательные ограничения на скорость передачи данных накладываются рабочей скоростью декодирующей вычислительной машины. Интересно, что при таких условиях, когда возможности системы связи ограничиваются возможностями вычислительной машины, наличие системы повторной передачи информации в ответ на запрос по некоторому каналу с шумами (если кодирование можно использовать при передаче в обоих направлениях [4,7]) позволяет существенно увеличить среднюю скорость передачи и уменьшить ее нестабильность. Есть основания ожидать, что последовательное декодирование окажется особенно хорошо приспособленным к передаче по двусторонней системе с шумами.
означает, что окончательные ограничения на скорость передачи данных накладываются рабочей скоростью декодирующей вычислительной машины. Интересно, что при таких условиях, когда возможности системы связи ограничиваются возможностями вычислительной машины, наличие системы повторной передачи информации в ответ на запрос по некоторому каналу с шумами (если кодирование можно использовать при передаче в обоих направлениях [4,7]) позволяет существенно увеличить среднюю скорость передачи и уменьшить ее нестабильность. Есть основания ожидать, что последовательное декодирование окажется особенно хорошо приспособленным к передаче по двусторонней системе с шумами.