4. Групповые коды
Хотя блоковый код, выбранный случайно, и будет при  (если исключить невезение) экспоненциально оптимальным, проблема задания
(если исключить невезение) экспоненциально оптимальным, проблема задания  двоичных символов, образующих
двоичных символов, образующих  все же остается устрашающей. Поэтому полезно разыскать подансамбли случайных блоковых кодов, которые все еще являются оптимальными с экспоненциальным убыванием вероятной ошибки, однако обладают меньшим числом степеней свободы. Слепян [12] первым отметил, что групповые коды просты для кодирования. В работе Элайеса [21] доказано, что вероятность ошибки, осредненная по ансамблю всех групповых кодов заданной размерности, не превышает границ, задаваемых для случайных кодов неравенствами (2.36) и (2.37).
все же остается устрашающей. Поэтому полезно разыскать подансамбли случайных блоковых кодов, которые все еще являются оптимальными с экспоненциальным убыванием вероятной ошибки, однако обладают меньшим числом степеней свободы. Слепян [12] первым отметил, что групповые коды просты для кодирования. В работе Элайеса [21] доказано, что вероятность ошибки, осредненная по ансамблю всех групповых кодов заданной размерности, не превышает границ, задаваемых для случайных кодов неравенствами (2.36) и (2.37).
Групповые коды можно рассматривать как линейные преобразования, превращающие информационную последовательность х длины  в передаваемую последовательность
в передаваемую последовательность  длины
длины  При этом
При этом  мы можем рассматривать как векторы-строки из нулей и единиц размерности
мы можем рассматривать как векторы-строки из нулей и единиц размерности  соответственно. Тогда мы можем записать в матричных обозначениях
соответственно. Тогда мы можем записать в матричных обозначениях

где  матрица из нулей и единиц с
матрица из нулей и единиц с  строками и
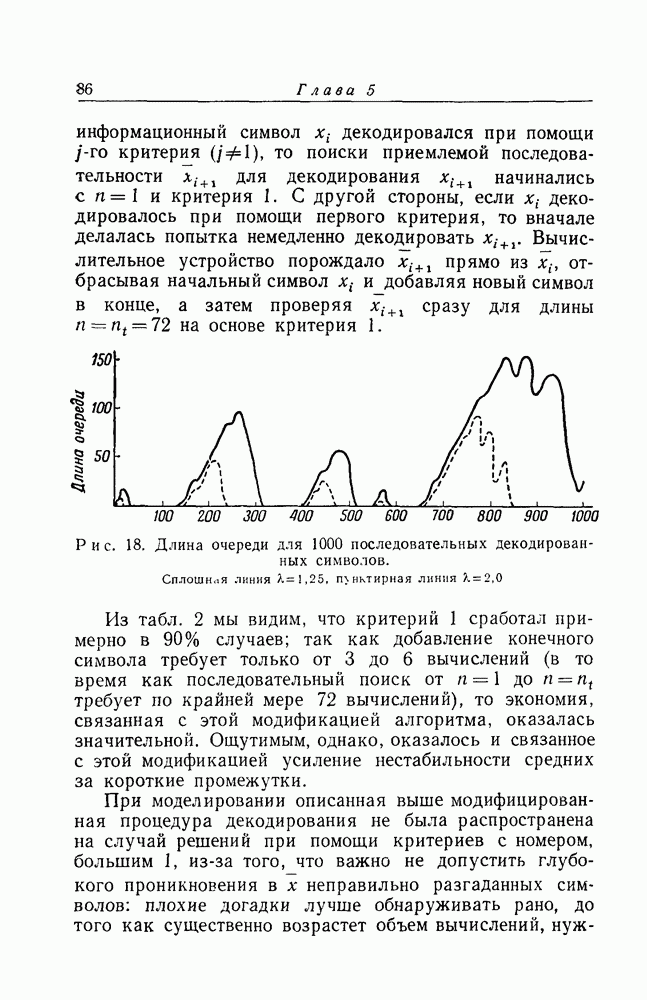
строками и  столбцами. Умножение матриц проводится по модулю 2. Пример кодовой матрицы
столбцами. Умножение матриц проводится по модулю 2. Пример кодовой матрицы  приведен на рис. 6.
приведен на рис. 6.
Матричный язык равенства (2.38) выражает сокращенно следующее правило конструирования последовательности  по х. Строками
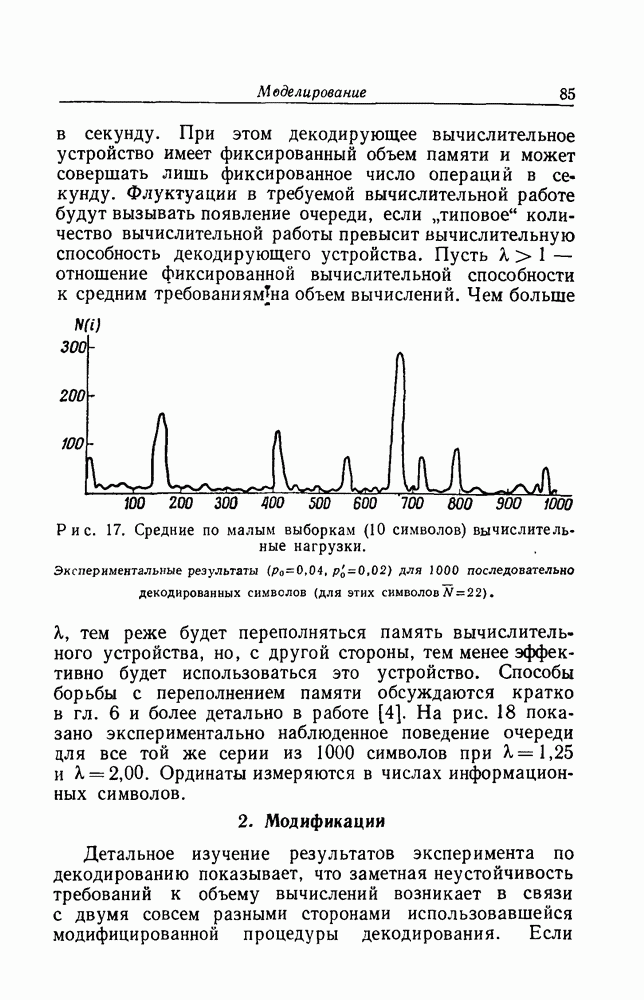
по х. Строками  будут
будут  Поставим в соответствие им компоненты
Поставим в соответствие им компоненты 
принятую последовательность у получатель может поочередно воспроизвести каждую из  последовательностей
последовательностей  из
из  вычислить совокупность шумовых последовательностей
вычислить совокупность шумовых последовательностей  и принять решение в пользу той последовательности
и принять решение в пользу той последовательности  для которой
для которой  минимально.
минимально.
Верхнюю границу для средней вероятности ошибки по ансамблю всех  возможных матриц
возможных матриц  мы определим с помощью простого рассуждения. Предположим, что каждый из
мы определим с помощью простого рассуждения. Предположим, что каждый из  порождающих элементов
порождающих элементов  выбран независимо и случайно (с возвращением) из совокупности
выбран независимо и случайно (с возвращением) из совокупности  возможных двоичных последовательностей длины
возможных двоичных последовательностей длины  Пусть
Пусть  переданная последовательность, у — полученная последовательность,
переданная последовательность, у — полученная последовательность,  шум в канале и
шум в канале и  некоторая последовательность из
некоторая последовательность из  отличная от переданной. Так как каждая
отличная от переданной. Так как каждая  отличается от
отличается от  (и, следовательно, от
(и, следовательно, от  тем, что с ней сложена по модулю 2 по крайней мере одна случайно выбранная последовательность
тем, что с ней сложена по модулю 2 по крайней мере одна случайно выбранная последовательность  то для каждого
то для каждого  за исключением
за исключением  мы имеем в соответствии с соотношением
мы имеем в соответствии с соотношением  из приложения, что
из приложения, что

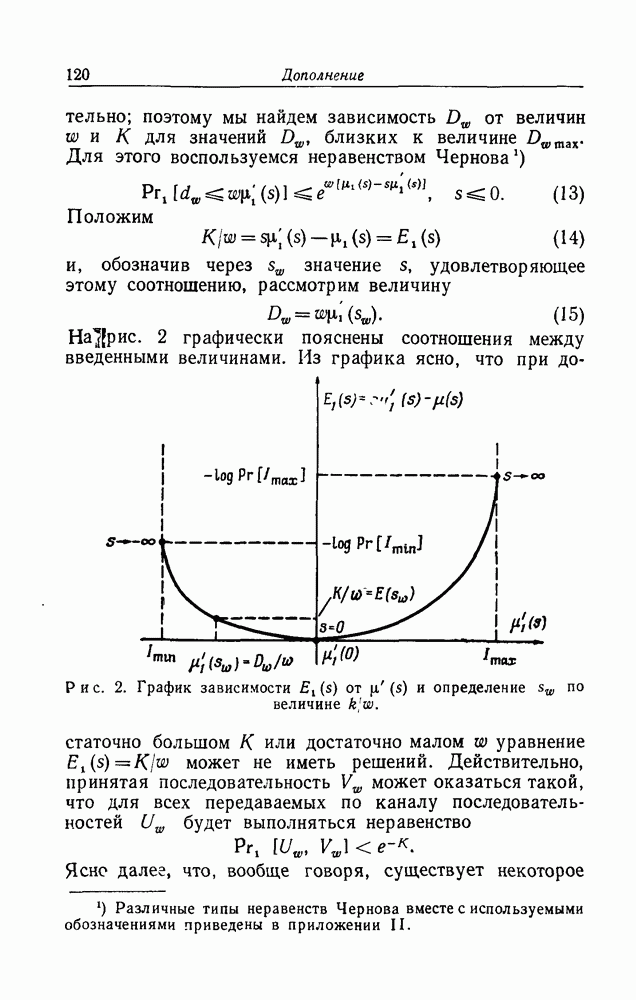
При получении неравенства (2.27) для общего случайного блокового кода мы уже использовали тот общеизвестный факт, что вероятность объединения событий не превосходит суммы вероятностей отдельных событий. Эта теорема верна безотносительно к статистической зависимости событий, входящих в объединение, и соотношение (2.27) верно, следовательно, и для случайных групповых кодов. Остальные соображения, использованные раньше для общих случайных кодов, переносятся без изменений.
В результате мы получаем, что для случайных групповых кодов сохраняются неравенства:

и

Симметрия. Схема кодирования с групповыми кодами должна обеспечивать по последовательности х на входе выбор для передачи одной из совокупности всех  линейных комбинаций (по модулю 2) порождающих элементов При декодировании мы образуем совокупность всех
линейных комбинаций (по модулю 2) порождающих элементов При декодировании мы образуем совокупность всех  "шумов"
"шумов"

Заметим, что прибавление любой фиксированной линейной комбинации  к каждому из членов
к каждому из членов  совокупности всех таких линейных комбинаций вновь порождает эту же совокупность. Поэтому совокупность шумов
совокупности всех таких линейных комбинаций вновь порождает эту же совокупность. Поэтому совокупность шумов  и соответствующих расстояний
и соответствующих расстояний  а следовательно, и вероятность ошибки абсолютно не зависят от того, какую последовательность
а следовательно, и вероятность ошибки абсолютно не зависят от того, какую последовательность  из
из  мы выбрали в качестве передаваемого сообщения
мы выбрали в качестве передаваемого сообщения  Это свойство симметричности групповых кодов дает возможность отказаться от принятого нами ранее ограничения о равновероятности всех информационных последовательностей х. Вероятность ошибки для группового кода не зависит от априорного распределения вероятностей для сообщения на Еходе.
Это свойство симметричности групповых кодов дает возможность отказаться от принятого нами ранее ограничения о равновероятности всех информационных последовательностей х. Вероятность ошибки для группового кода не зависит от априорного распределения вероятностей для сообщения на Еходе.
Каноническая форма. Хотя задавать групповые коды гораздо легче, чем произвольные блоковые коды (теперь у нас уже не  а только
а только  степеней свободы), обычно мы все-таки не знаем, как выбрать оптимальный код при больших
степеней свободы), обычно мы все-таки не знаем, как выбрать оптимальный код при больших  и исчезающе малых вероятностях
и исчезающе малых вероятностях  Однако двух заведомо неприятных возможностей можно легко избежать.
Однако двух заведомо неприятных возможностей можно легко избежать.
Во-первых, если какой-нибудь столбец матрицы порождающих элементов  тождественно равен нулю, то ясно, что все последовательности
тождественно равен нулю, то ясно, что все последовательности  из
из  имеют нуль в одном и том же положении. Такая строка не прибавляет ничего нового ни для различения разных
имеют нуль в одном и том же положении. Такая строка не прибавляет ничего нового ни для различения разных  ни для снижения вероятности ошибки.
ни для снижения вероятности ошибки.
Во-вторых, мы уже отмечали, что если совокупность порождающих элементов является линейно зависимой, то в  найдутся по крайней мере две последовательности
найдутся по крайней мере две последовательности  равные
равные  По свойству симметричности отсюда
По свойству симметричности отсюда
старого базиса, которые имеют только одну единицу среди первых  символов.
символов.
Полудиагональная форма матрицы  и будет рассматриваться как каноническая. Когда порождающие элементы группового кода записаны в такой форме,
и будет рассматриваться как каноническая. Когда порождающие элементы группового кода записаны в такой форме,  информационных символов х передаются без изменения. Как указал впервые Слепян [12], оставшиеся
информационных символов х передаются без изменения. Как указал впервые Слепян [12], оставшиеся  символов в любой последовательности
символов в любой последовательности  могут быть тогда вычислены при помощи проверок на четность по некоторым подмножествам информационных символов. Например, из первой строки на рис. 6 ясно, что первый информационный символ для этого кода входит в проверки на четность, соответствующие символам
могут быть тогда вычислены при помощи проверок на четность по некоторым подмножествам информационных символов. Например, из первой строки на рис. 6 ясно, что первый информационный символ для этого кода входит в проверки на четность, соответствующие символам 
Обсуждение. Для того чтобы задать матрицу группового кода в канонической форме, требуется только  бинарных символов. В действительности Элайес [21] показал, что границы, полученные для случайного кодирования, применимы также к "скользящим" кодам с проверкой на четность, имеющим только
бинарных символов. В действительности Элайес [21] показал, что границы, полученные для случайного кодирования, применимы также к "скользящим" кодам с проверкой на четность, имеющим только  степеней свободы. Для этих кодов в случайно выбранной бинарной последовательности длины
степеней свободы. Для этих кодов в случайно выбранной бинарной последовательности длины  символы от
символы от  до
до  определяют, какие из двоичных символов задают проверку на четность для первого информационного символа, символы от
определяют, какие из двоичных символов задают проверку на четность для первого информационного символа, символы от  до
до  определяют множество для проверки на четность для
определяют множество для проверки на четность для  д. Таким образом, мы видим, что задание и проведение кодирования для кода, являющегося почти наверняка хорошим при больших
д. Таким образом, мы видим, что задание и проведение кодирования для кода, являющегося почти наверняка хорошим при больших  не представляет особой трудности: для этого достаточно оборудования, сложность которого растет с ростом
не представляет особой трудности: для этого достаточно оборудования, сложность которого растет с ростом  лишь линейным образом.
лишь линейным образом.







































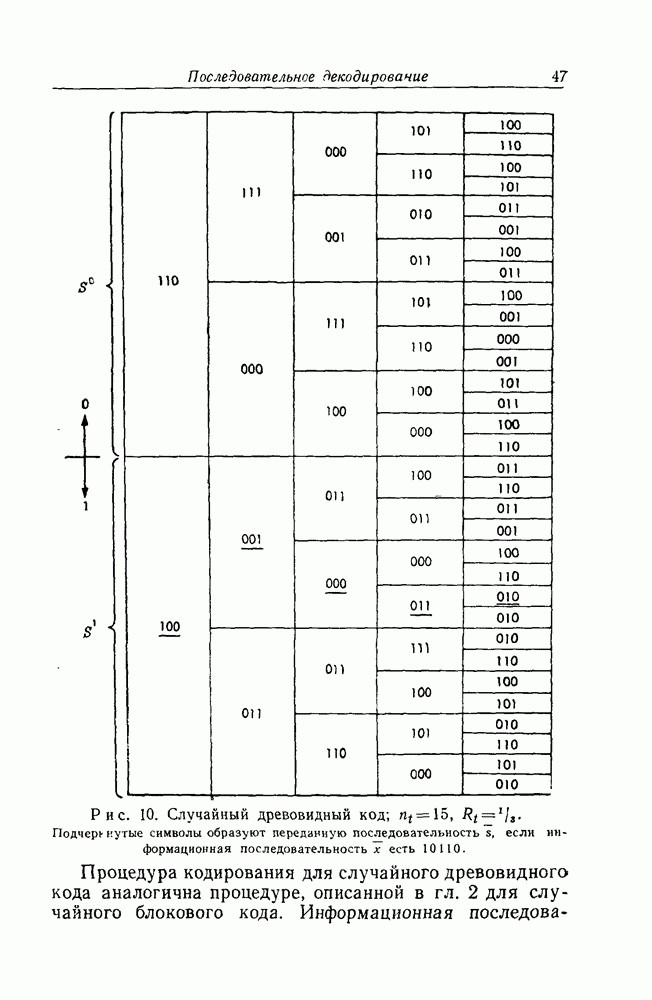







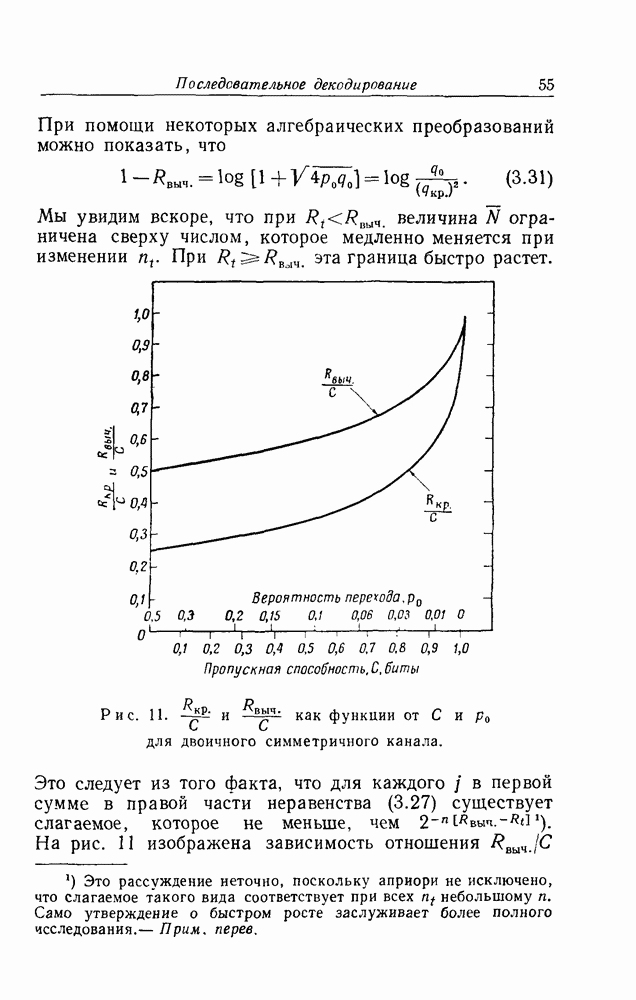


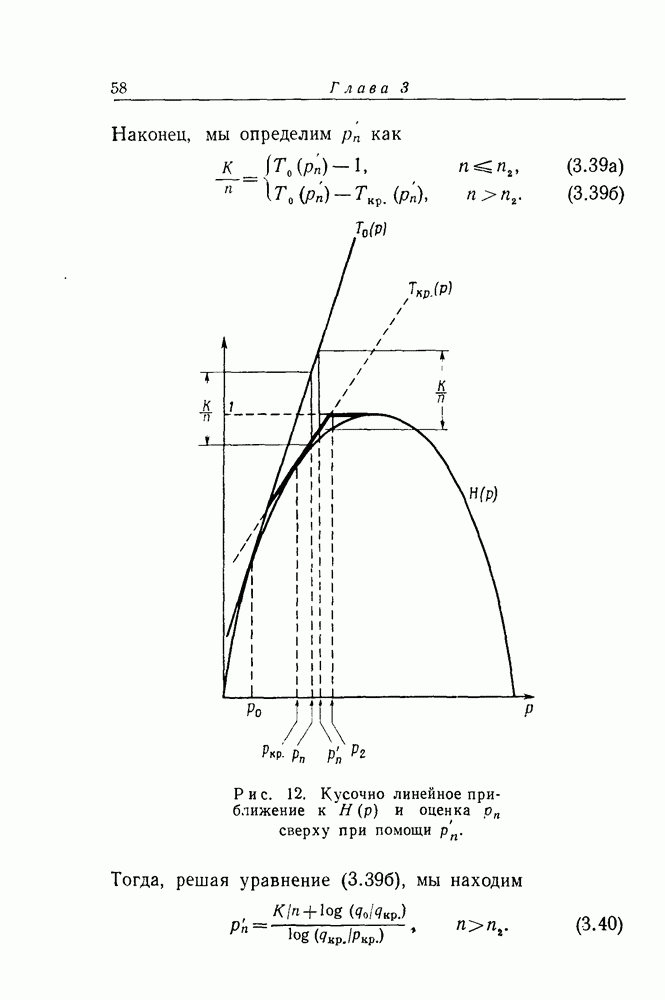















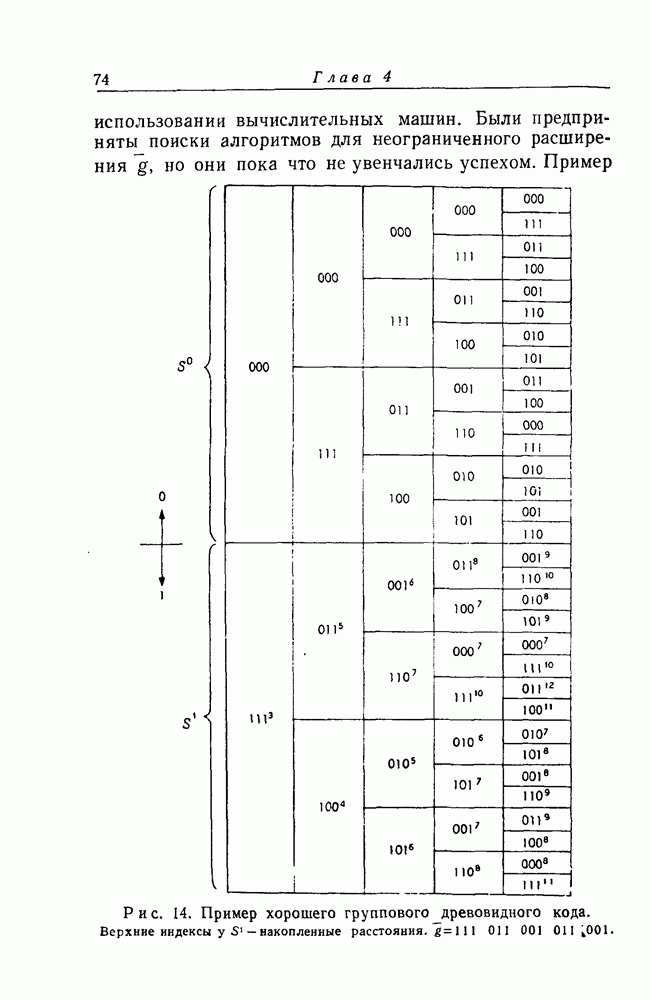









































































 для которых
для которых  равно 1, образуем
равно 1, образуем  Строки
Строки  матрицы
матрицы  называются образующими элементами групового кода
называются образующими элементами групового кода 
 состоит из всех
состоит из всех  возможных линейных комбинаций строк
возможных линейных комбинаций строк  в частности, содержит нулевую строку
в частности, содержит нулевую строку  длины
длины  которая есть не что иное, как образ последовательности
которая есть не что иное, как образ последовательности  длины
длины 

 для группового кода
для группового кода  базисные элементы.
базисные элементы.
 из
из  окажутся различными в том и только том случае, когда совокупность порождающих элементов является линейно независимой (по модулю 2). В противном случае считаем, что существует некоторое
окажутся различными в том и только том случае, когда совокупность порождающих элементов является линейно независимой (по модулю 2). В противном случае считаем, что существует некоторое  для которого
для которого  Это условие несовпадения
Это условие несовпадения  соответствует в матричной терминологии требованию, чтобы матрица
соответствует в матричной терминологии требованию, чтобы матрица  имела ранг
имела ранг 
 и
и
 должна встречаться в коде неоднократно. Для такого кода вероятность ошибки (неопределенность также считается ошибкой) должна быть равна 1. Если мы вычеркнем коды, для которых это справедливо, из ансамбля случайных групповых кодов, то средняя вероятность ошибки по оставшейся совокупности должна уменьшиться и по-прежнему будет удовлетворять неравенствам (2.36) и (2.37).
должна встречаться в коде неоднократно. Для такого кода вероятность ошибки (неопределенность также считается ошибкой) должна быть равна 1. Если мы вычеркнем коды, для которых это справедливо, из ансамбля случайных групповых кодов, то средняя вероятность ошибки по оставшейся совокупности должна уменьшиться и по-прежнему будет удовлетворять неравенствам (2.36) и (2.37).

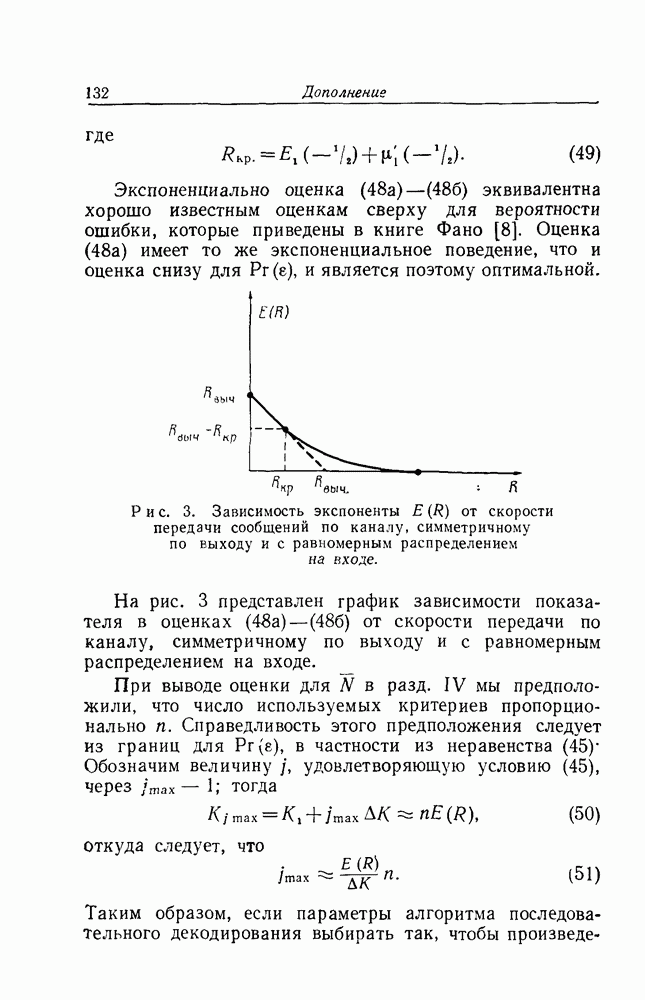
 ранг матрицы
ранг матрицы  равен
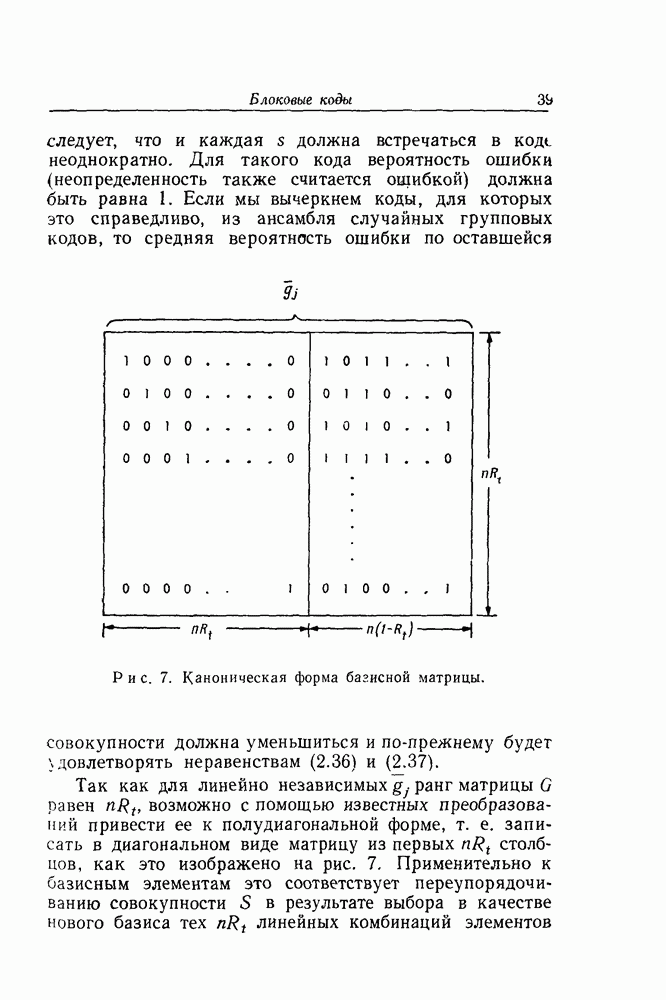
равен  возможно с помощью известных преобразований привести ее к полудиагональной форме, т. е. записать в диагональном виде матрицу из первых
возможно с помощью известных преобразований привести ее к полудиагональной форме, т. е. записать в диагональном виде матрицу из первых  столбцов, как это изображено на рис. 7. Применительно к базисным элементам это соответствует переупорядочиванию совокупности
столбцов, как это изображено на рис. 7. Применительно к базисным элементам это соответствует переупорядочиванию совокупности  в результате выбора в качестве нового базиса тех
в результате выбора в качестве нового базиса тех  линейных комбинаций элементов
линейных комбинаций элементов
 и произвольных канонических матрицах нам предоставляется выбор: мы можем или использовать матрицу для того, чтобы воспроизвести одновременно на приемнике каждую из
и произвольных канонических матрицах нам предоставляется выбор: мы можем или использовать матрицу для того, чтобы воспроизвести одновременно на приемнике каждую из  последовательностей
последовательностей  или же для каждой из
или же для каждой из  возможных последовательностей на выходе канала хранить в словаре наиболее вероятную последовательность х. Слепян [12] показал, что в силу симметричности групповых кодов этот словарь должен на самом деле содержать только
возможных последовательностей на выходе канала хранить в словаре наиболее вероятную последовательность х. Слепян [12] показал, что в силу симметричности групповых кодов этот словарь должен на самом деле содержать только  последовательностей.
последовательностей.
 обе эти возможности малопривлекательны. Это привело к тому, что было предпринято мдого попыток поиска методов кодирования и декодирования, не связанных с такого рода экспоненциальн возрастающими трудностями [8].
обе эти возможности малопривлекательны. Это привело к тому, что было предпринято мдого попыток поиска методов кодирования и декодирования, не связанных с такого рода экспоненциальн возрастающими трудностями [8].