Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3. Случайные блоковые кодыХотя мы без особого труда провели вывод нижней границы для вероятности ошибки, исследование вероятности ошибки Предположим, что
Если приемник работает по методу максимума правдоподобия, то переданное сообщение
и
где, как и прежде,
Черта в соотношениях (2.24) и (2.25) обозначает усреднение по ансамблю случайных кодов. Для каждого фиксированного сообщения Так как вероятность суммы событий ограничена сверху суммой вероятностей отдельных событий и вероятность всегда не превосходит единицы, справедливо неравенство
Обозначение В приложении показано, что
и
Используя первое из этих двух соотношений и равенство (2.23), мы можем переписать (2.27) в виде
Сумму, входящую в соотношение (2.25), удобно разбить на три слагаемых:
Тогда, используя соотношения
и
В соотношении (2.31) мы выбрали
Подставляя неравенства (2.30), (2.31) и (2.32) в соотношение (2.25), получаем, что осредненная по ансамблю вероятность ошибки удовлетворяет неравенству
Доминирующее слагаемое в сумме, входящей в правую часть соотношения (2.33), мы можем найти, дифференцируя выражение
Решение уравнения (2.34) мы будем обозначать
Графически В первом случае, когда
Аналогично, при
Таким образом,
В соотношениях (2.36) и (2.37) мы получили верхние границы для вероятности ошибки, умножая соответствующие наибольшие члены суммы на число слагаемых в ней. Используя более точные построения, можно получить искомые верхние границы с теми же самыми экспоненциальными членами, но с коэффициентами, не зависящими от Обсуждение. Для совокупности сообщений 5 длины К сожалению, поиски хороших кодов для больших 151 остались до сих пор безрезультатными, однако, как мы видели, почти все коды должны быть хорошими. Таким образом, мы испытываем искушение думать, что те коды, которые мы не можем придумать, как раз и являются хорошими. То, что это заключение ярляется отчасти резонным, следует из соображений, высказанных Шенноном. В любой совокупности положительных чисел не более чем и (2.37) не более, чем в 10 раз. Если некто столкнется на практике с задачей построения кода, то он может выбрать код случайно и постараться, чтобы ему повезло.
|
 |
Оглавление
|






































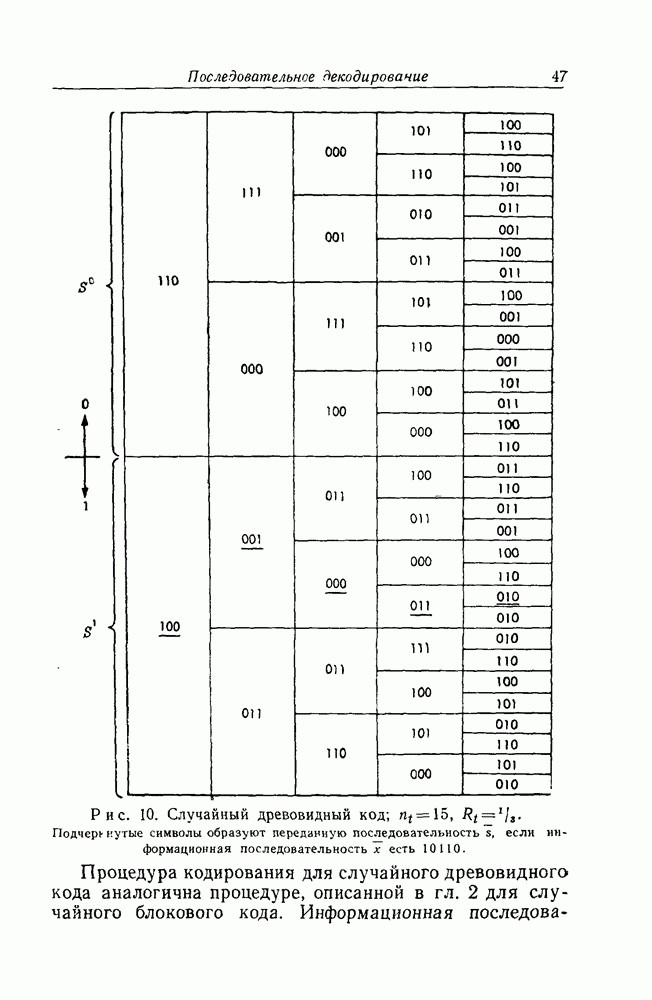
























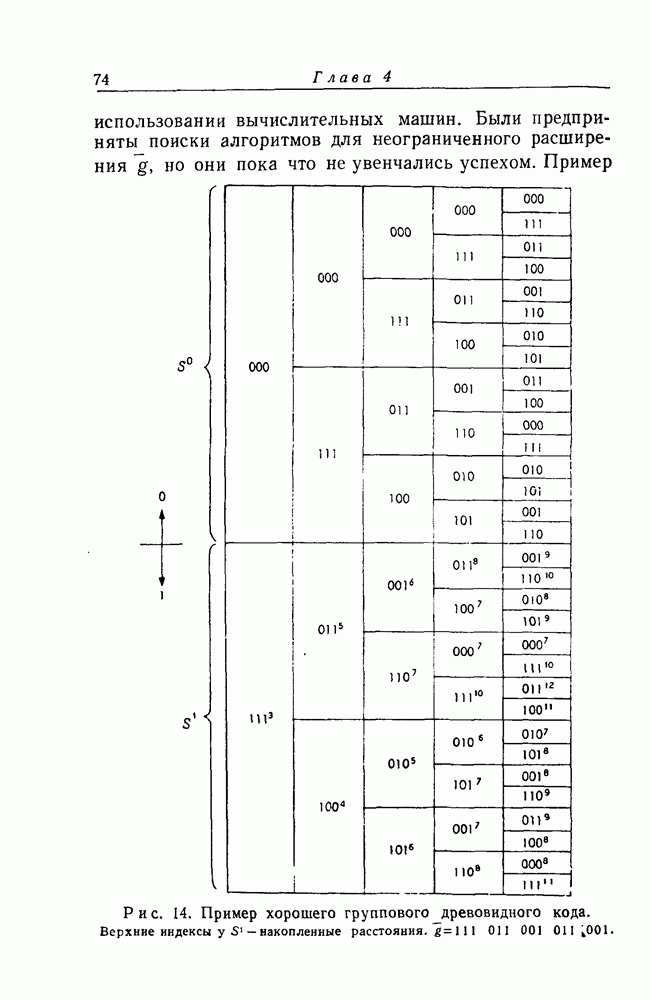










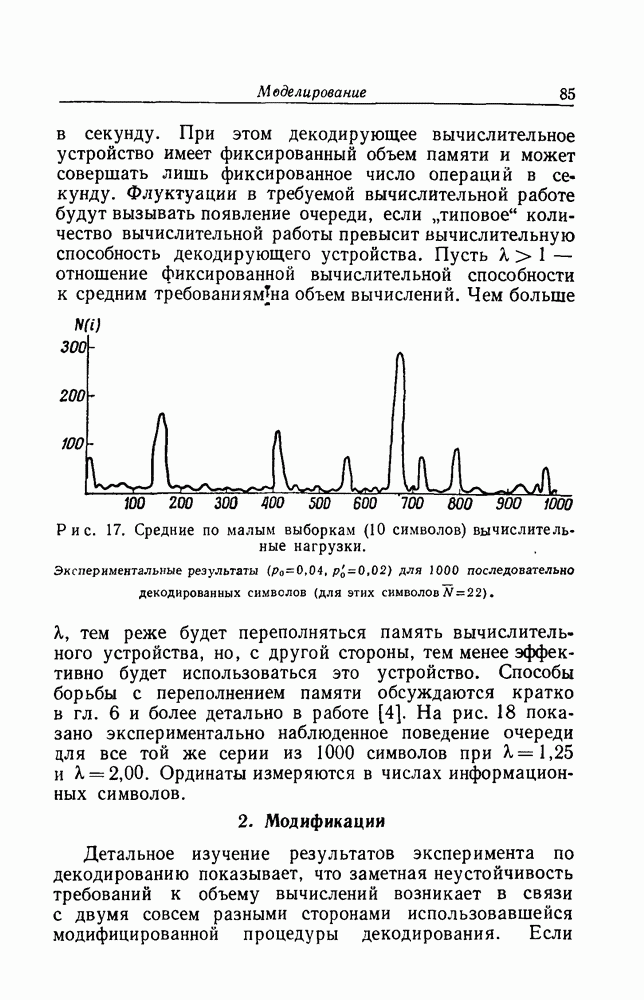
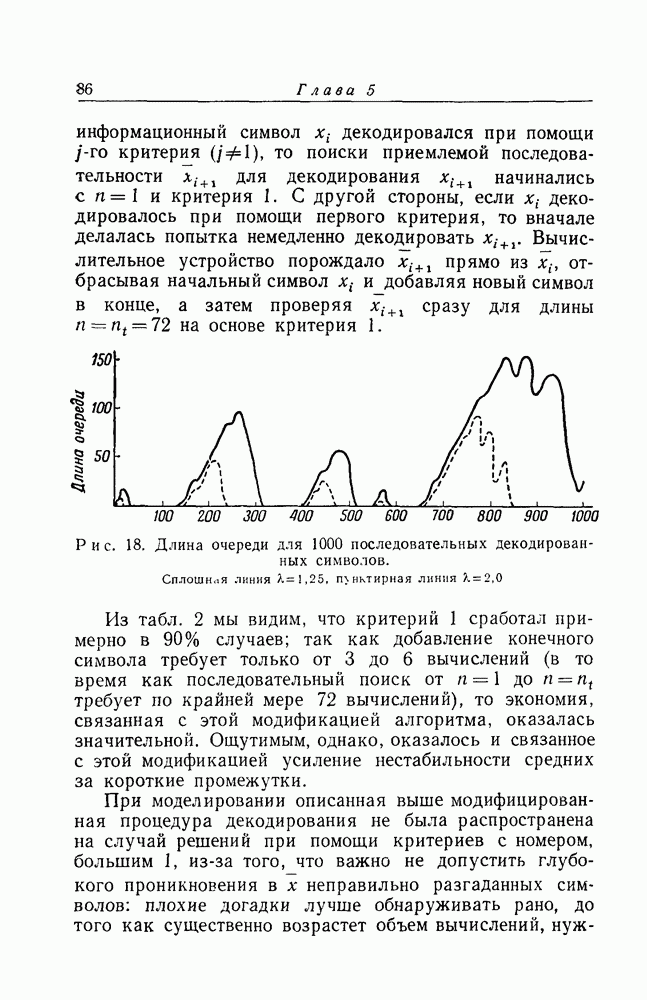

































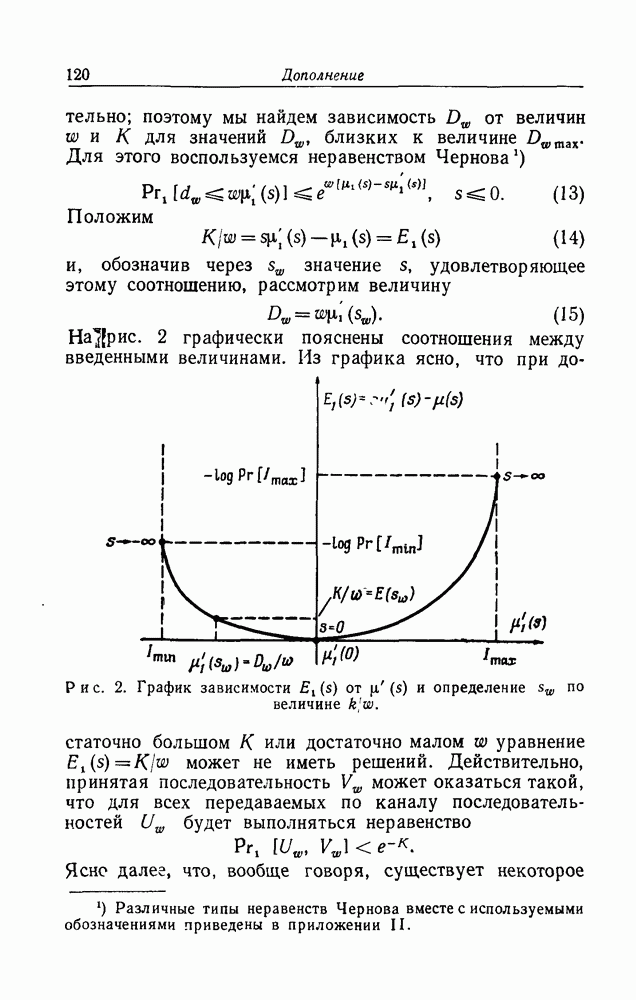











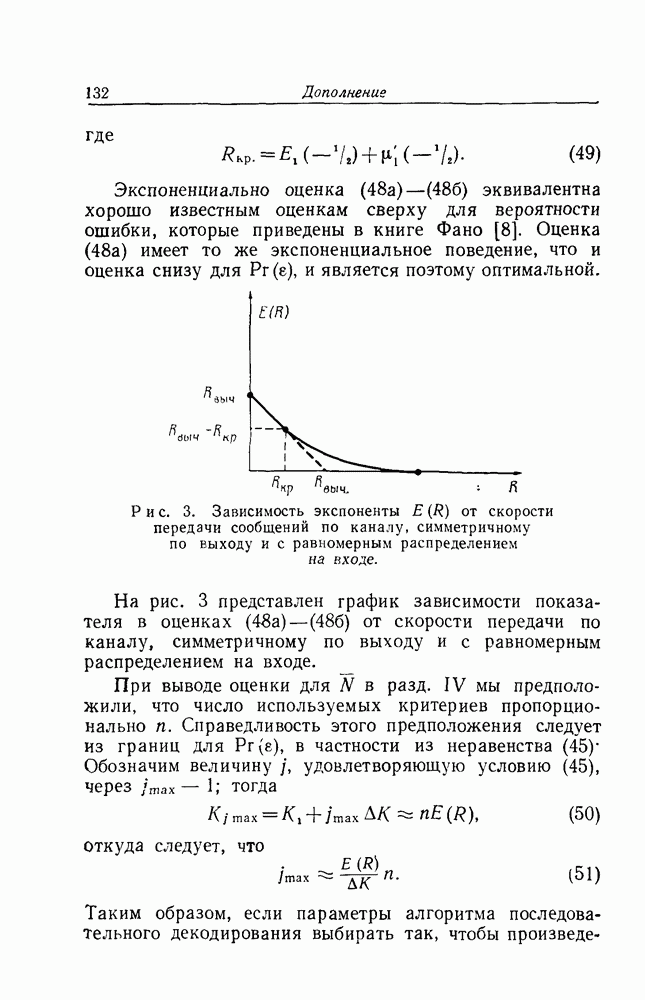



















 для отдельных интересных кодов оказывается практически невозможным. Однако мы можем изучить проблему вполне удовлетворительным образом, использовав преимущества, даваемые методом исследования, известным как метод "случайного кодирования".
для отдельных интересных кодов оказывается практически невозможным. Однако мы можем изучить проблему вполне удовлетворительным образом, использовав преимущества, даваемые методом исследования, известным как метод "случайного кодирования".
 сообщений, образующих наш блоковый код, выбраны случайно (с возвращением) и независимо друг от друга из совокупности
сообщений, образующих наш блоковый код, выбраны случайно (с возвращением) и независимо друг от друга из совокупности  всех возможных двоичных последовательностей длины
всех возможных двоичных последовательностей длины  Как и прежде, скорость передачи информации
Как и прежде, скорость передачи информации  и соответствующий ей вероятностный параметр
и соответствующий ей вероятностный параметр  определяются соотношением
определяются соотношением

 будет декодировано правильным образом лишь в том случае, когда любое другое сообщение
будет декодировано правильным образом лишь в том случае, когда любое другое сообщение  из
из  будет отличаться от полученного сообщения у более чем на
будет отличаться от полученного сообщения у более чем на  символов, где
символов, где  истинное число изменений, внесенных шумами при передаче по ДСК. Таким образом, среднее значение
истинное число изменений, внесенных шумами при передаче по ДСК. Таким образом, среднее значение



 отличного от действительно посланного, вероятность того, что
отличного от действительно посланного, вероятность того, что  совпадают в каком-либо символе, равна
совпадают в каком-либо символе, равна  (это вытекает из вероятностной конструкции, использованной для построения
(это вытекает из вероятностной конструкции, использованной для построения 

 с подстрочным индексом здесь и в дальнейшем используется для того, чтобы выделить вероятности, которые вычисляются при условии, что каждому символу в последовательности
с подстрочным индексом здесь и в дальнейшем используется для того, чтобы выделить вероятности, которые вычисляются при условии, что каждому символу в последовательности  равновероятно быть нулем или единицей [и что все эти символы независимы (см. примечание [2])- Перев.}.
равновероятно быть нулем или единицей [и что все эти символы независимы (см. примечание [2])- Перев.}.




 и (2.28), мы можем следующим образом ограничить сверху суммы, входящие в правую часть соотношения
и (2.28), мы можем следующим образом ограничить сверху суммы, входящие в правую часть соотношения 


 так, чтобы
так, чтобы  Далее,
Далее,


 относительно
относительно  и приравнивая производную нулю:
и приравнивая производную нулю:

 а соответствующую ему скорость передачи —
а соответствующую ему скорость передачи —  Тогда
Тогда

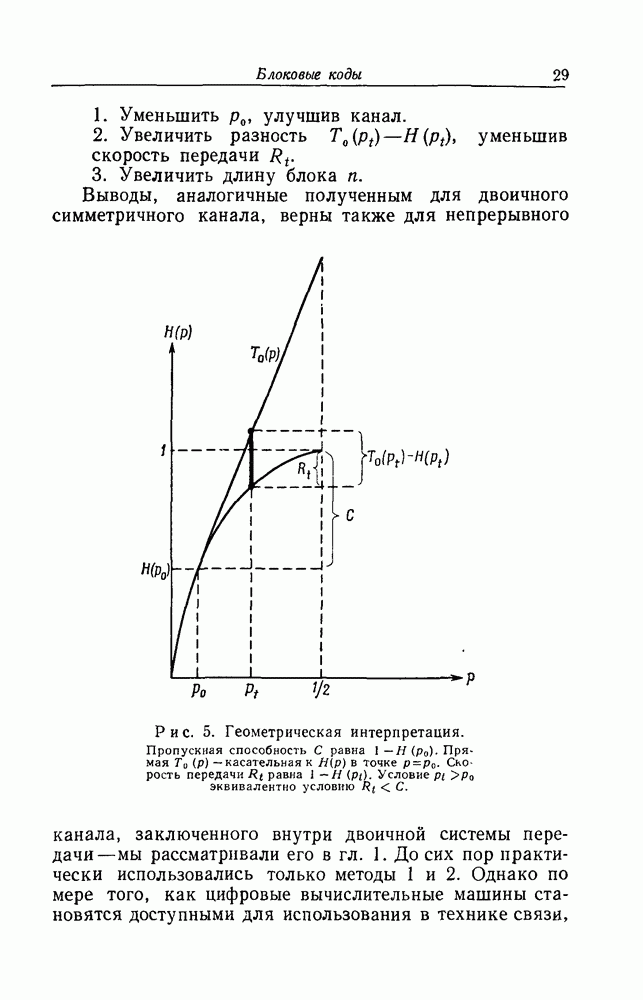
 представляет собой абсциссу точки, в которой наклон кривой энтропии вдвое меньше наклона этой кривой в точке
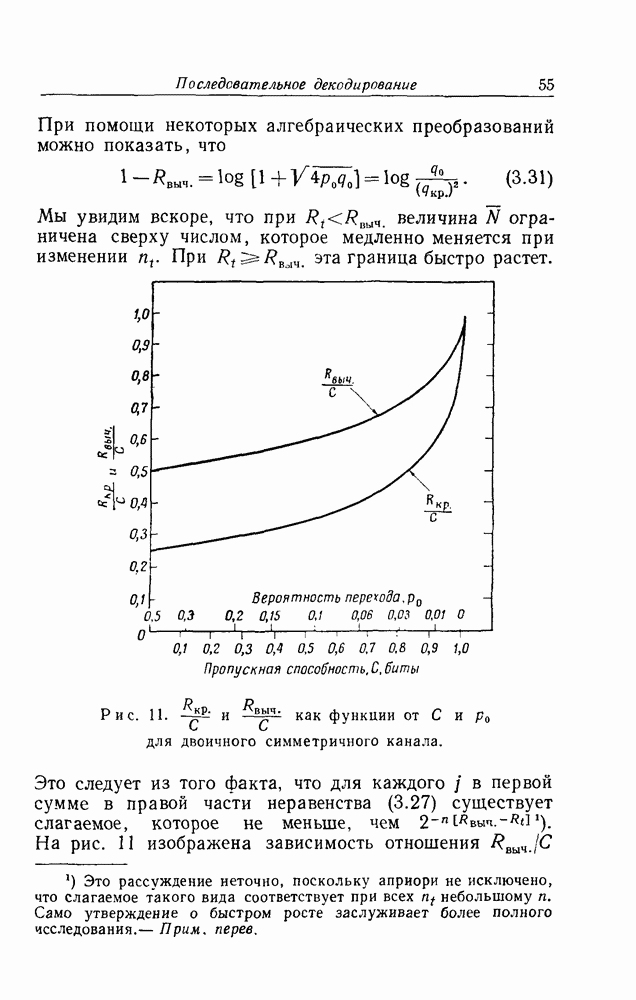
представляет собой абсциссу точки, в которой наклон кривой энтропии вдвое меньше наклона этой кривой в точке  переходной вероятности в канале. Из рис. 5 ясно, что имеются две возможности в зависимости от пропускной способности канала С и скорости передачи
переходной вероятности в канале. Из рис. 5 ясно, что имеются две возможности в зависимости от пропускной способности канала С и скорости передачи  число
число  может быть либогр (т. е.
может быть либогр (т. е.  ), либо
), либо  (т. е.
(т. е.  ).
).
 наибольшим в сумме, входящей в соотношение (2.33), является последнее слагаемое. Так как в этой сумме число слагаемых меньше, чем
наибольшим в сумме, входящей в соотношение (2.33), является последнее слагаемое. Так как в этой сумме число слагаемых меньше, чем  то мы имеем
то мы имеем

 максимальное слагаемое в сумме, входящей в равенство (2.33), не будет превышать
максимальное слагаемое в сумме, входящей в равенство (2.33), не будет превышать


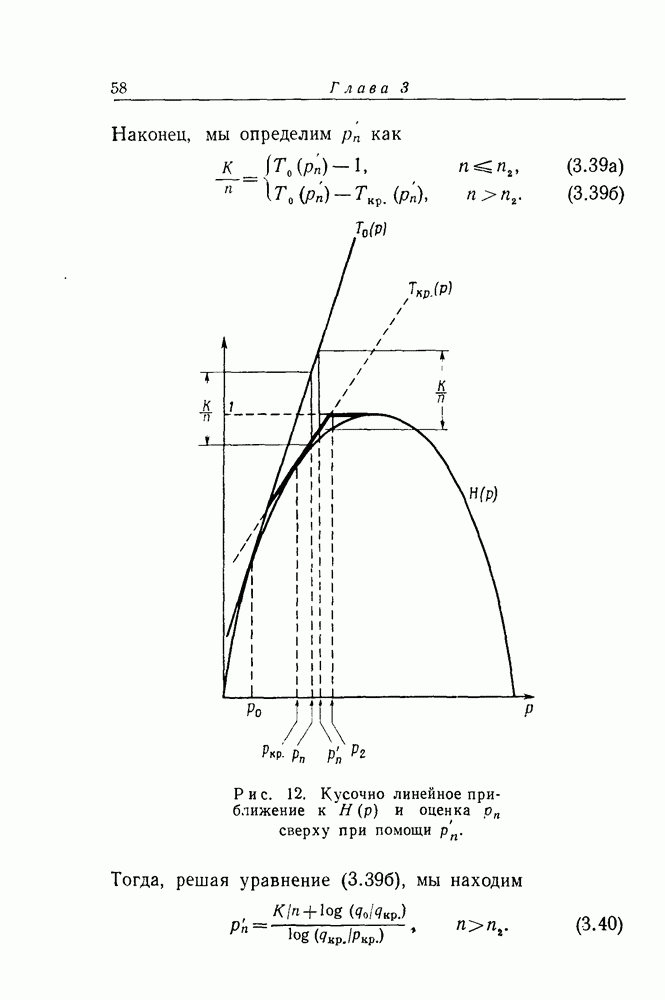
 при
при  и пропорциональными
и пропорциональными  при
при 
 состоящей из
состоящей из  последовательностей, существует
последовательностей, существует  различных блоковых кодов. Вычисление вероятности ошибки в ансамбле случайных кодов эквивалентно нахождению средней вероятности ошибки по всем возможным кодам заданной размерности. Тот факт, что при
различных блоковых кодов. Вычисление вероятности ошибки в ансамбле случайных кодов эквивалентно нахождению средней вероятности ошибки по всем возможным кодам заданной размерности. Тот факт, что при  верхняя граница для средней вероятности ошибки по всем кодам имеет тот же показатель убывания, что и нижняя граница для наилучшего возможного кода [что видно из сравнения соотношений (2.21) и (2.36)], является особенно примечательным. Во всех случаях соотношения (2.35) и (2.36) показывают, что при фиксированных
верхняя граница для средней вероятности ошибки по всем кодам имеет тот же показатель убывания, что и нижняя граница для наилучшего возможного кода [что видно из сравнения соотношений (2.21) и (2.36)], является особенно примечательным. Во всех случаях соотношения (2.35) и (2.36) показывают, что при фиксированных  случайно выбранный код будет иметь среднюю вероятность ошибки, которая при растущем
случайно выбранный код будет иметь среднюю вероятность ошибки, которая при растущем  приближается к нулю экспоненциально.
приближается к нулю экспоненциально.
 доля их может превышать в а раз среднее значение этой совокупности. Таким образом, например, из
доля их может превышать в а раз среднее значение этой совокупности. Таким образом, например, из  возможных блоковых кодов (скорость
возможных блоковых кодов (скорость  задана) по крайней мере 90% должно приводить к вероятности ошибки, превышающей правую часть соотношений (2.36)
задана) по крайней мере 90% должно приводить к вероятности ошибки, превышающей правую часть соотношений (2.36)