Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
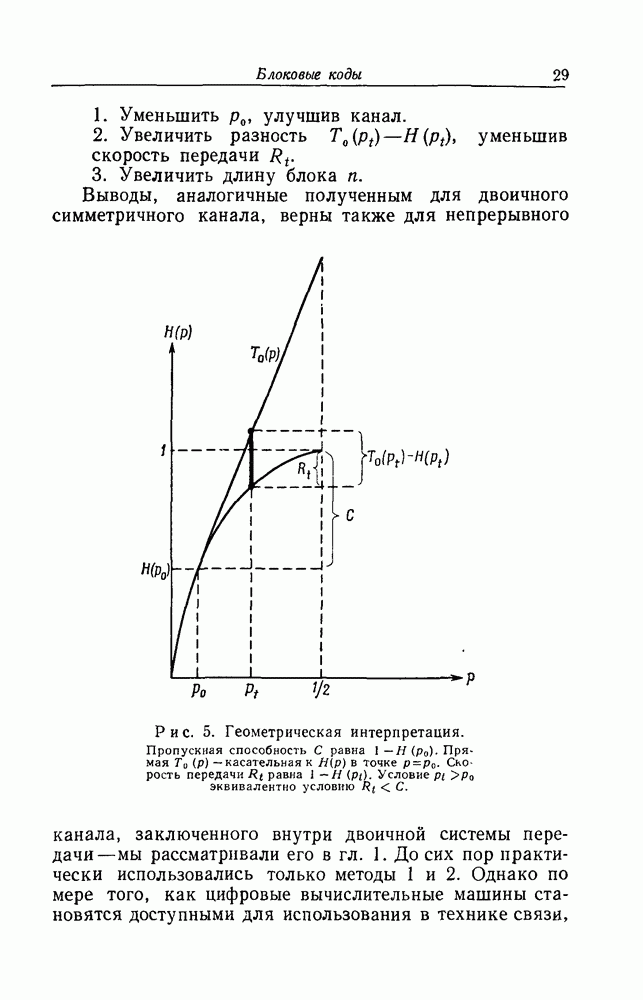
V. Оценка вероятности ошибкиОшибкой при последовательном декодировании мы будем называть наступление по меньшей мере одного из следующих двух событий: 1) пара 2) среди последовательностей Вероятность первого события, осредненная по ансамблю кодов, не превосходит величины События 1 и 2, вообще говоря, зависимы, но вероятность их суммы не превосходит суммы их вероятностей, так что вероятность появления ошибки
Полученное неравенство далеко от наилучшей известной оценки для вероятности ошибки, однако оно является очень общим и его вывод прост. Чтобы придать этой оценке компактную форму, введем случайную величину вывод не изменится, однако получить окончательное простое выражение не удастся. В разд. III мы положили величину равной
Функция
где
В силу условия
Производная функции следовательно, при любом
В силу условия (30)
откуда, согласно предыдущему неравенству,
Неравенство (46) указывает на то, что при больших значениях
верная при любых значениях
Неравенство (47) получается из (44в) заменой коэффициента Аналогичные рассуждения в случае
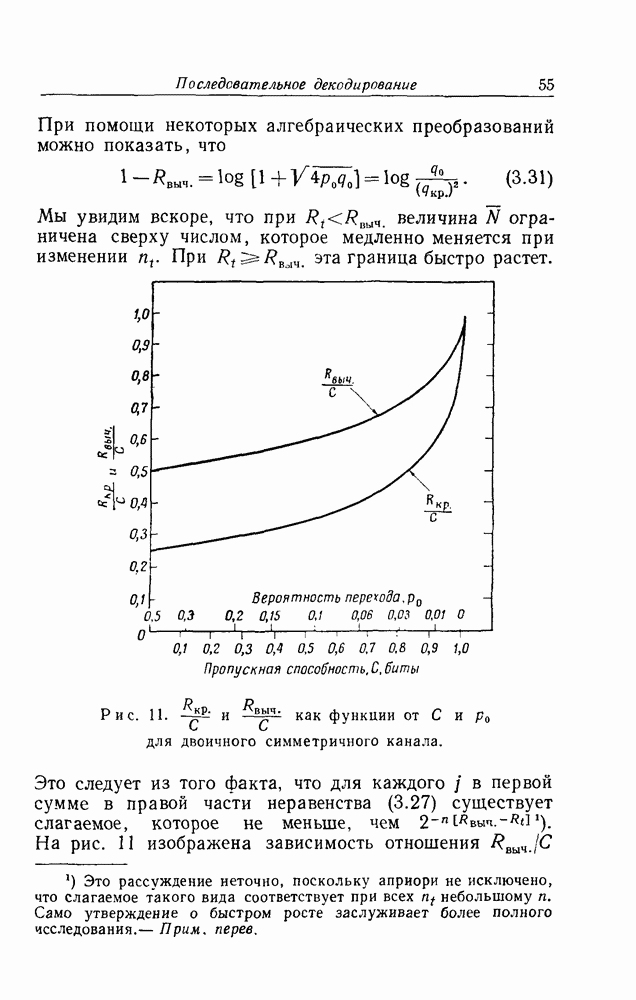
Для каналов, симметричных по выходу и с равномерным распределением на входе, автором были проведены более подробные исследования вероятности ошибки, в результате чего получились оценки, имеющие приблизительно следующую форму:
где
Экспоненциально оценка
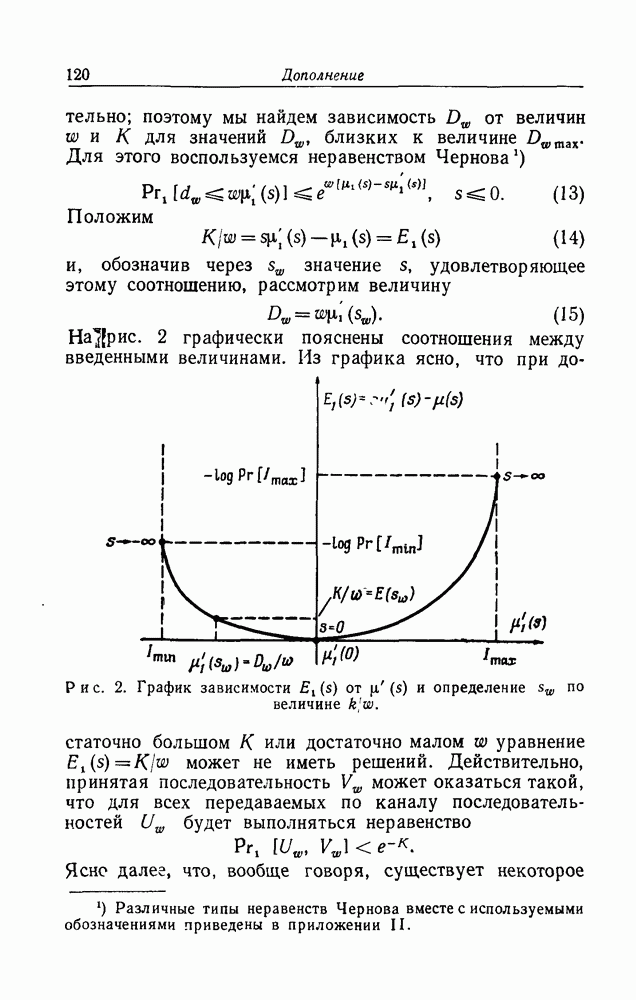
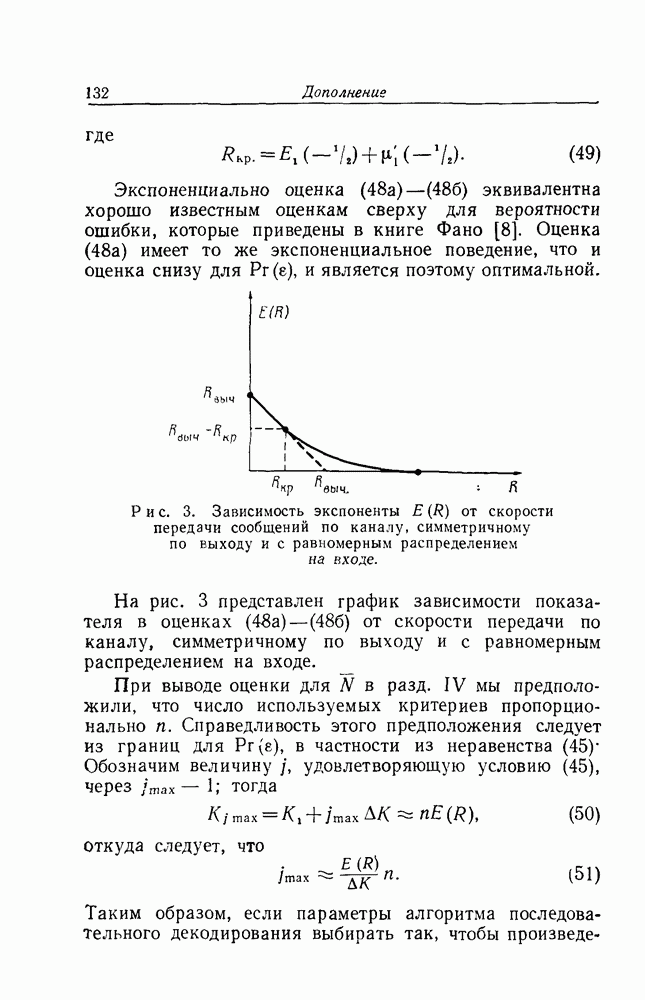
Рис. 3. Зависимость экспоненты На рис. 3 представлен график зависимости показателя в оценках При выводе оценки для
откуда следует, что
Таким образом, если параметры алгоритма последовательного декодирования выбирать так, чтобы произведение
|
 |
Оглавление
|






































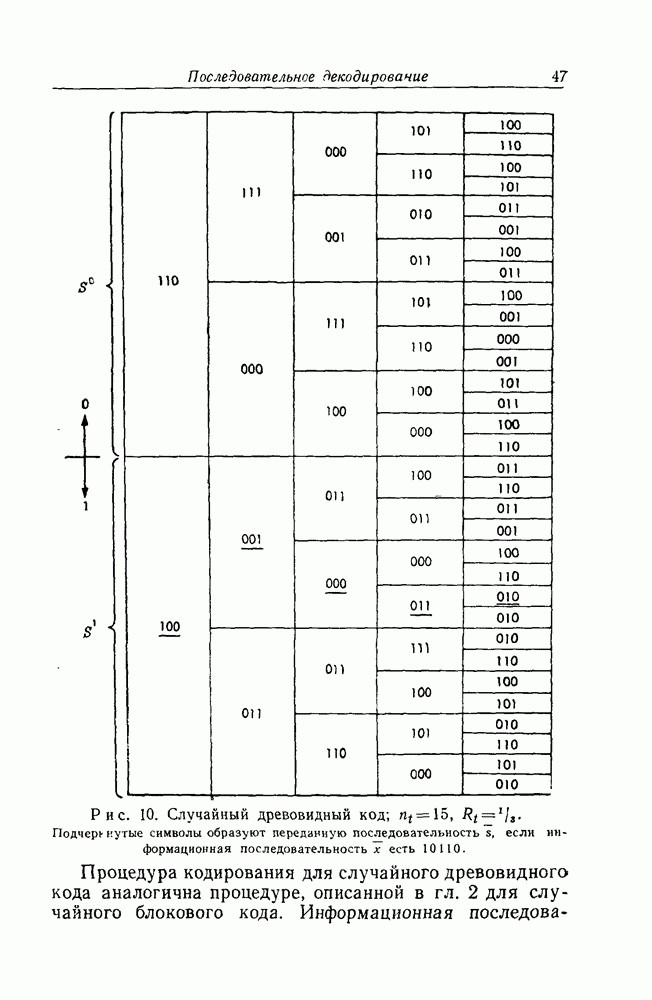
























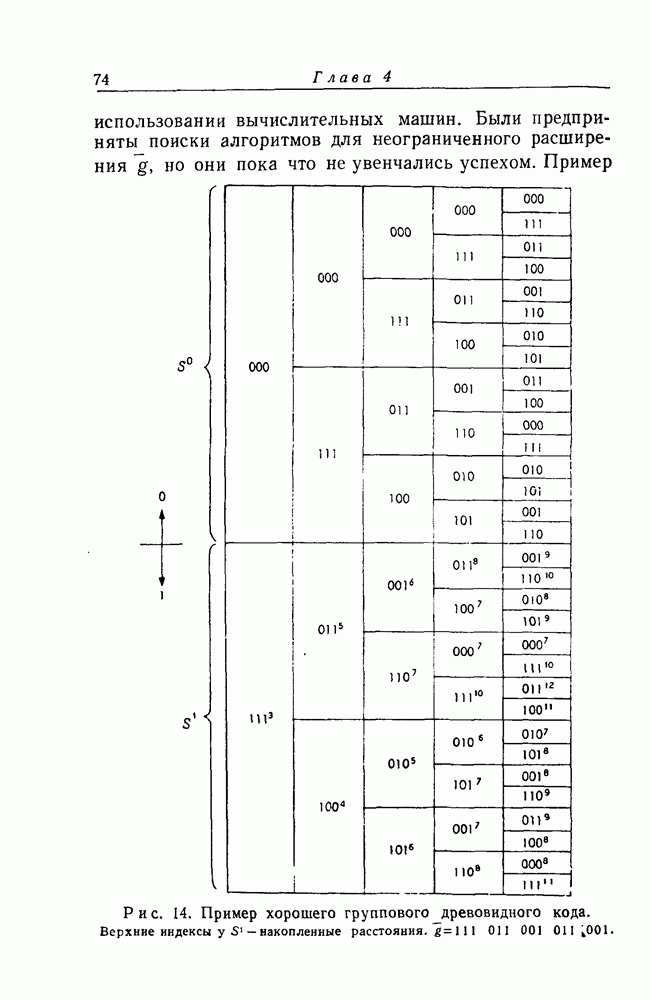









































































 где
где  переданная,
переданная,  принятая последовательности, не удовлетворяет некоторому, скажем,
принятая последовательности, не удовлетворяет некоторому, скажем,  критерию;
критерию;
 нашлась по крайней мере одна, которая вместе с принятой последовательностью
нашлась по крайней мере одна, которая вместе с принятой последовательностью  образует пару, удовлетворяющую
образует пару, удовлетворяющую  критерию.
критерию.
 Вероятность того, что случайно выбранная последовательность "неправильного" подмножества вместе с
Вероятность того, что случайно выбранная последовательность "неправильного" подмножества вместе с  образует пару, удовлетворяющую
образует пару, удовлетворяющую  критерию, равна
критерию, равна  Так как в подмножестве
Так как в подмножестве  не более
не более  элементов, а вероятность суммы событий не превосходит суммы вероятностей слагаемых, то вероятность того, что хотя бы одна из последовательностей
элементов, а вероятность суммы событий не превосходит суммы вероятностей слагаемых, то вероятность того, что хотя бы одна из последовательностей  образует с
образует с  пару, удовлетворяющую
пару, удовлетворяющую  критерию, не превосходит
критерию, не превосходит 
 удовлетворяет неравенству
удовлетворяет неравенству

 равную взаимной информации между символами
равную взаимной информации между символами  При другом определении величины
При другом определении величины 
 где
где  Оценка принимает различные формы в случае
Оценка принимает различные формы в случае  и в случае
и в случае  Мы рассмотрим только первый случай, как наиболее важный. Предположим, что
Мы рассмотрим только первый случай, как наиболее важный. Предположим, что  и выберем номер
и выберем номер  из условия 2)
из условия 2)

 монотонно возрастает с увеличением
монотонно возрастает с увеличением  поэтому из условия 1) следует, что
поэтому из условия 1) следует, что  и, наоборот, 1, если — 1). Так как
и, наоборот, 1, если — 1). Так как  то для
то для  найдется такое
найдется такое  что
что  действительно, для этого достаточно положить
действительно, для этого достаточно положить  Отсюда следует, что
Отсюда следует, что

 Так как
Так как  то
то  и оценка (44) для
и оценка (44) для  может быть переписана в следующем виде:
может быть переписана в следующем виде:

 величина
величина  меньше единицы и потому
меньше единицы и потому

 по
по  равна
равна 




 длина интервала (45), в котором заключена скорость передачи
длина интервала (45), в котором заключена скорость передачи  стремится к нулю. Отсюда следует приблизительная оценка для вероятности ощибки:
стремится к нулю. Отсюда следует приблизительная оценка для вероятности ощибки:

 меньших пропускной способности канала С. Эта оценка экспоненциально эквивалентна оценке, полученной Шенноном
меньших пропускной способности канала С. Эта оценка экспоненциально эквивалентна оценке, полученной Шенноном  для блоковых кодов; согласно Шеннону,
для блоковых кодов; согласно Шеннону,

 на коэффициент 2.
на коэффициент 2.
 приводят к результату
приводят к результату



 эквивалентна хорошо известным оценкам сверху для вероятности ошибки, которые приведены в книге Фано [8]. Оценка (48а) имеет то же экспоненциальное поведение, что и оценка снизу для
эквивалентна хорошо известным оценкам сверху для вероятности ошибки, которые приведены в книге Фано [8]. Оценка (48а) имеет то же экспоненциальное поведение, что и оценка снизу для  и является поэтому оптимальной.
и является поэтому оптимальной.

 от скорости передачи сообщений по каналу, симметричному по выходу и с равномерным распределением на входе.
от скорости передачи сообщений по каналу, симметричному по выходу и с равномерным распределением на входе.
 от скорости передачи по каналу, симметричному по выходу и с равномерным распределением на входе.
от скорости передачи по каналу, симметричному по выходу и с равномерным распределением на входе. 
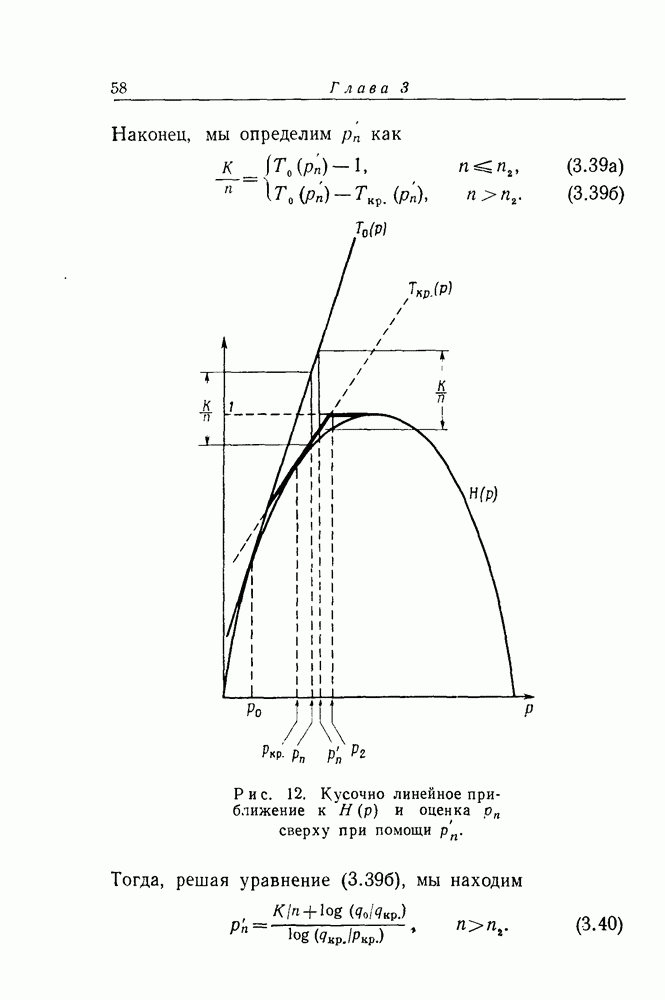
 в разд. IV мы предположили, что число используемых критериев пропорционально
в разд. IV мы предположили, что число используемых критериев пропорционально  Справедливость этого предположения следует из границ для
Справедливость этого предположения следует из границ для  в частности из неравенства
в частности из неравенства  Обозначим величину
Обозначим величину  удовлетворяющую условию (45), через
удовлетворяющую условию (45), через  ; тогда
; тогда


 приблизительно равнялось абсолютной величине показателя в оценке вероятности ошибки, то процесс декодирования будет характеризоваться не только степенной зависимостью числа операций от длины кода, но и вероятностью ошибки, близкой к оптимальной.
приблизительно равнялось абсолютной величине показателя в оценке вероятности ошибки, то процесс декодирования будет характеризоваться не только степенной зависимостью числа операций от длины кода, но и вероятностью ошибки, близкой к оптимальной.