Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
3.2. Видеокодек
Видеокодек (рис.
3.3) кодирует исходное изображение или видеопоследовательность в сжатой форме,
а также декодирует сжатую видеопоследовательность, производя цифровую видеокопию,
которая или совпадает, или близка к исходной видеопоследовательности. Если
декодированная последовательность совпадает с исходной, то процесс кодирования
называется кодированием без потерь. Если же эти последовательности отличаются
друг от друга, то процесс называется кодированием с потерями.

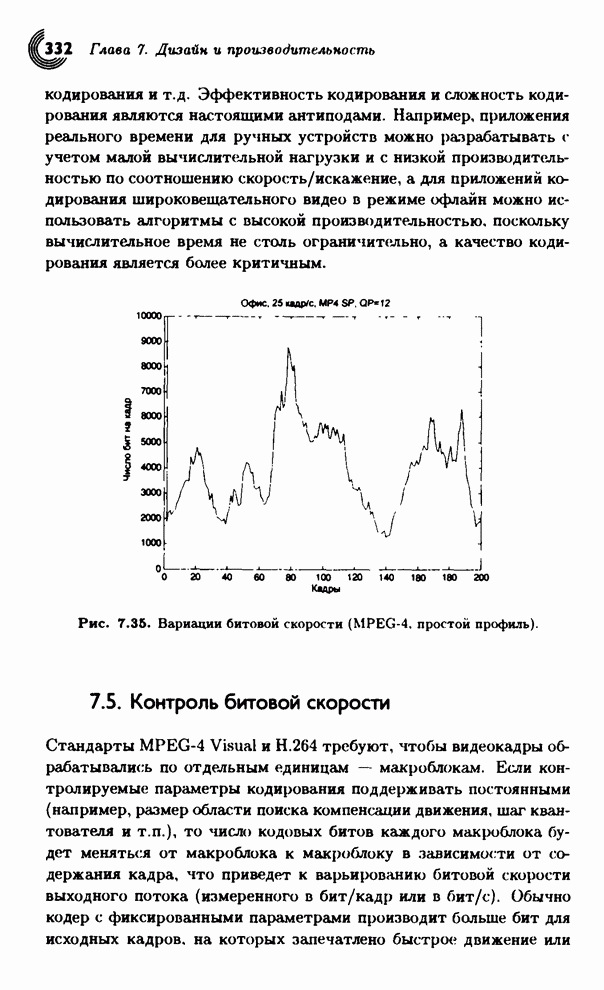
Рис. 3.3. Блок-схема видеокодера.
Кодек
преобразовывает исходный видеоряд с помощью определенной модели
(эффективное кодированное представление видеоданных, с помощью которого можно
реконструировать эти данные с той или иной степенью точности). В идеале модель
должна представлять последовательность с наименьшим числом бит и наибольшей
возможной точностью. Эти две цели (эффективность сжатия и высокое качество),
как правило, противоречат друг другу, так как высокая степень сжатия
видеоданных обычно предполагает существенное снижение качества изображения на
выходе декодера. Компромисс между степенью сжатия и качеством сжатых данных
(степенью расхождения) будет обсуждаться в гл. 7.
Видеокодер
(рис. 3.3) состоит из трех основных функциональных единиц: временной
модели, пространственной модели и энтропийного кодера. На вход
временной модели подается несжатый цифровой видеосигнал. Временная модель
стремится сократить временную избыточность, используя схожесть между
последовательными видеокадрами, обычно строя прогноз для следующего кадра по
соседним кадрам последовательности. В стандартах MPEG-4 Visual и Н.264 прогноз
формируется по одному или нескольким предыдущим или будущим кадрам, при этом
делается коррекция расхождения между кадрами (предсказание компенсации
движения). Выходом временной модели служит остаточный кадр (производимый
вычитанием кадра-прогноза из подлинного текущего кадра) и некоторое семейство
числовых параметров модели, обычно множество векторов движения, описывающих,
как это движение было скомпенсировано.
Остаточный
кадр является входом для пространственной модели, которая использует схожесть
или подобие соседних пространственных сэмплов этого кадра, сокращая тем самым
пространственную избыточность. В стандартах MPEG-4 Visual и Н.264 это осуществляется
применением специальных преобразований к остаточному кадру и квантованием
результата. Преобразование переводит сэмпл в другую область, в которой он
представляется в виде последовательности коэффициентов используемого
преобразования. Коэффициенты квантуются методом удаления несущественных значений;
при этом оставляется небольшое число существенных коэффициентов, которые
обеспечивают более компактное представление остаточного кадра. Выходом
пространственной модели выступает семейство квантованных коэффициентов
преобразования.
Параметры
временной модели (векторы движения) и пространственной модели (коэффициенты
преобразования) сжимаются энтропийный кодером. При этом удаляется статистическая
избыточность данных (например, кодируя часто встречающиеся векторы и
коэффициенты более короткими двоичными кодами) и формируется сжатый битовый
поток или файл, который можно передавать по сетям или хранить на носителях
цифровых данных. Файл сжатой последовательности состоит из закодированных
векторов движения, закодированных остаточных коэффициентов и некоторого
информационного заголовка.
Видеодекодер
реконструирует видеокадр по сжатому битовому потоку данных. Коэффициенты и
векторы движения декодируются энтропийным декодером, после чего
пространственная модель декодирует полученные данные, формируя некоторую
версию остаточного кадра. Декодер использует параметры векторов движения
вместе с одним или несколькими ранее декодированными кадрами для построения
прогноза текущего кадра, а сам кадр реконструируется добавлением остаточного
кадра к этому кадру-прогнозу.