Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
5.5.1. Пространственное масштабирование
Базовый слой
несет версию видеопотока в которой каждый кадр закодирован с низким
разрешением. Декодирование только базового слоя приводит к выходной
видеопоследовательности ограниченного качества, а декодирование базового слоя и
уточняющих слоев производит выходной видеоряд с высоким разрешением. При
кодировании видеопоследовательности по двум слоям необходимо совершить
следующие шаги.
1. Сделать
подсэмллирование каждого входного кадра (рис. 5.58) (или видеообъекта) по горизонтали
и вертикали (рис. 5.59), используя укрупненные сэмплы.
2. Кодировать
кадры с сокращенным разрешением для формирования базового слоя.
3. Декодировать
базовый слой и сделать измельчающее сэмплирование до исходного разрешения для
нахождения кадра-прогноза (рис. 5.60).
4. Вычесть исходный кадр с полным
разрешением из кадра-прогноза (рис. 5.61).
5. Кодировать
полученную разность (остаток) для получения улучшающего слоя.

Рис. 5.58. Исходный видеокадр.

Рис.
5.59. Подсэмплированный кадр для кодирования базового слоя.

Рис. 5.60. Кадр базового слоя (приведенный к
исходному разрешению).

Рис. 5.61. Остаточный кадр для кодирования
улучшающего слоя.
Однослойный
декодер будет декодировать только базовый слой для получения выходной
последовательности низкого разрешения. Двухслойный декодер будет
реконструировать видео с полным разрешением по следующей схеме.
1. Декодировать
базовый слой и сделать измельчающее сэмплирование до исходного разрешения.
2. Декодировать улучшающий слой.
3. Сложить
декодированный остаток из улучшающего слоя и декодированный базовый слой для
получения требуемого выходного видеоряда.
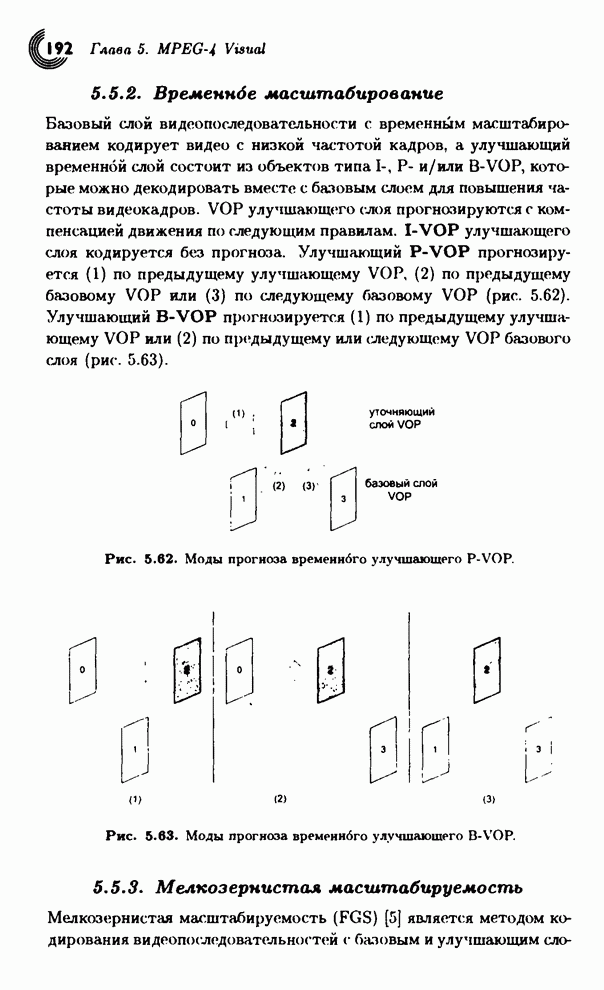
Объекты
I-VOP улучшающего слоя
кодируются без пространственного прогнозирования, т.е. как полный кадр или
видеообъект с улучшающим разрешением. В объектах P-VOP улучшающего слоя
для предсказания используется укрупненный объект VOP базового слоя (с
теми же координатами по времени) без компенсации движения. Разность между
прогнозом и входным кадром кодируется с помощью инструмента текстурного
кодирования, т.е. не посылаются векторы движения для улучшающих P-VOP. Объекты B-VOP улучшающего слоя
прогнозируются по двум направлениям. Обратный прогноз делается по
декодированному и укрупненному VOP базового слоя (с
синхронизацией по времени) без всякой компенсации движения (а значит, и без
векторов движения). Прямой прогноз делается по предыдущему VOP улучшающего слоя
(даже если он является объектом типа B-VOP) без компенсации
движения (и без векторов движения).
Если
VOP имеет
произвольную (бинарную) форму, в базовом и улучшающем слоях требуется построить
ВАВ для каждого макроблока. ВАВ для базового слоя кодируется обычным методом,
основываясь на форме и размерах объекта базового слоя. ВАВ для объекта P-VOP улучшающего слоя
кодируется с использованием прогноза по ВАВ укрупненного объекта базового слоя.
ВАВ для объекта B-VOP улучшающего слоя
можно кодировать аналогично или используя прямое предсказание по предыдущему VOP (как это описано
в § 5.4.1.1).