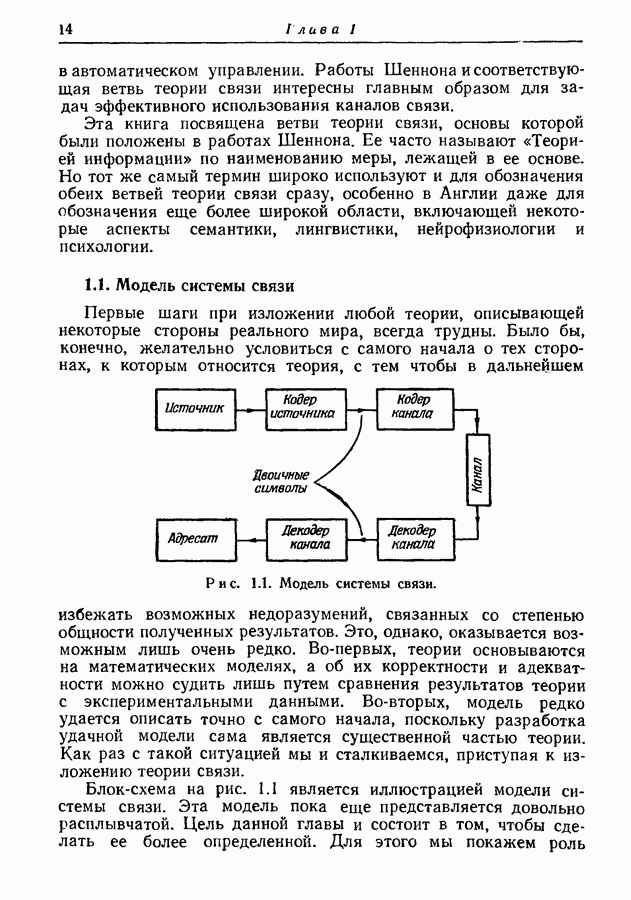
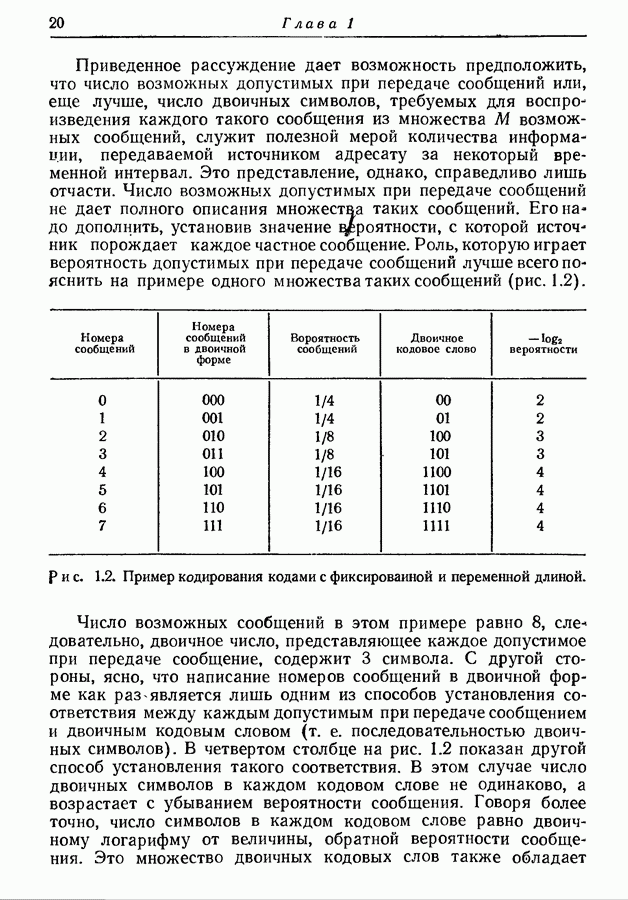
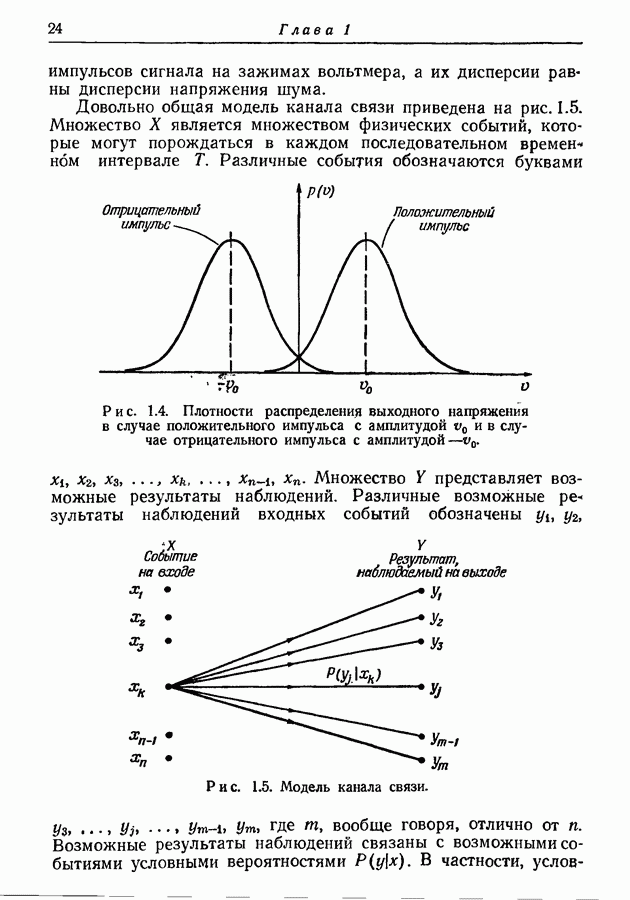
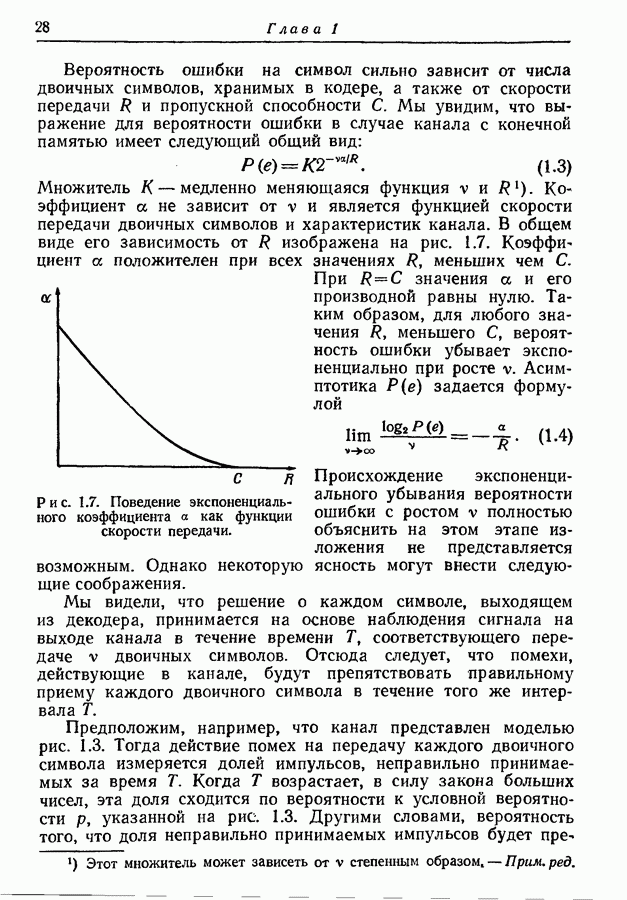
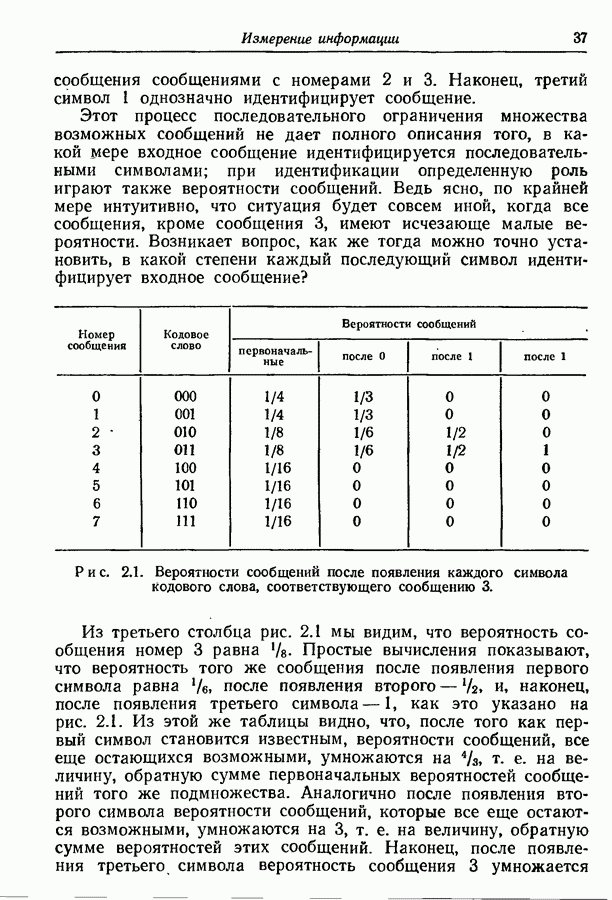
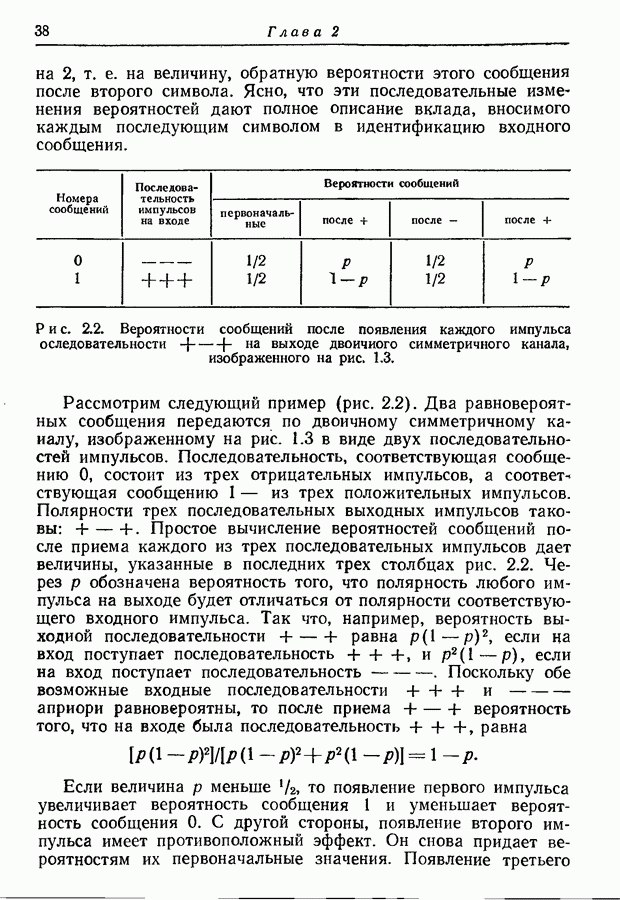
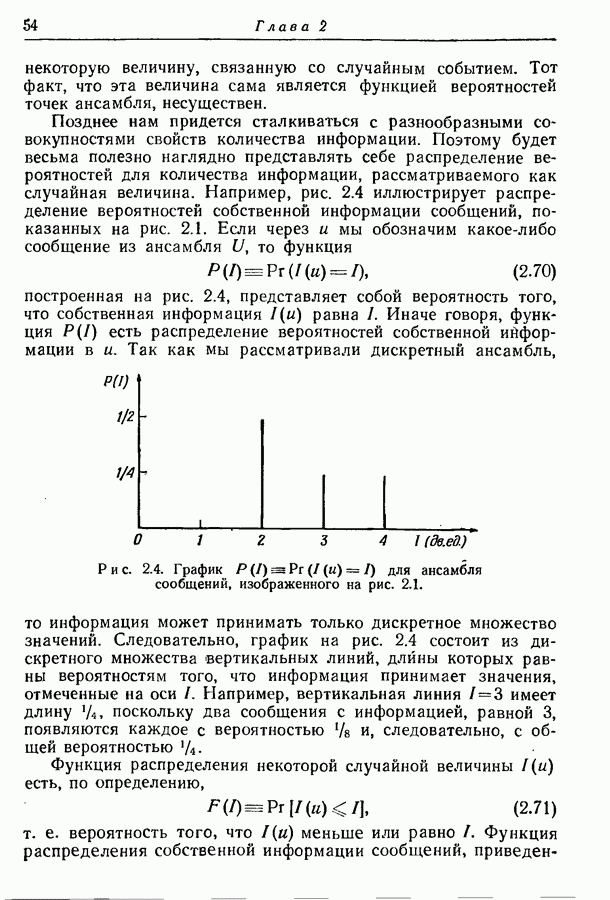
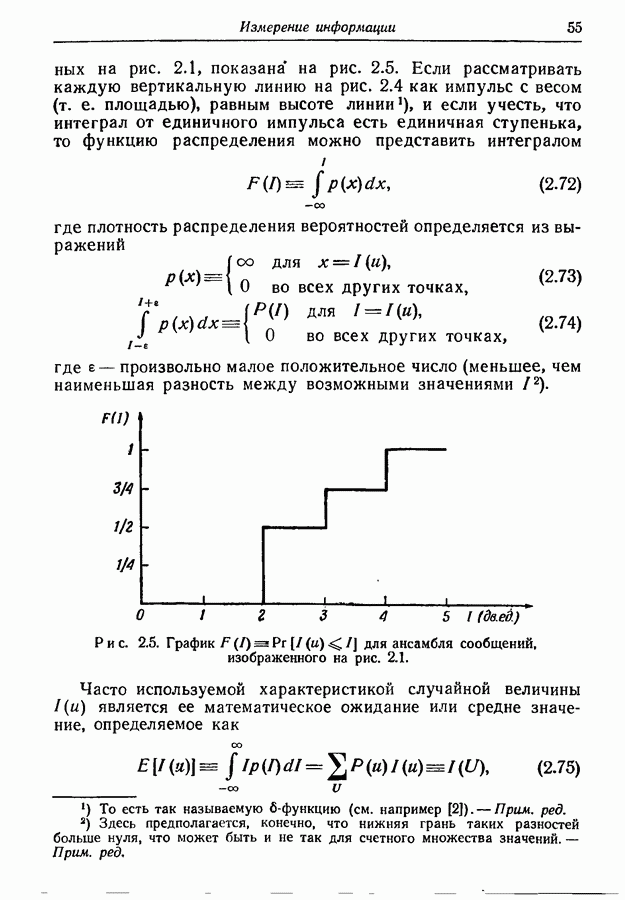
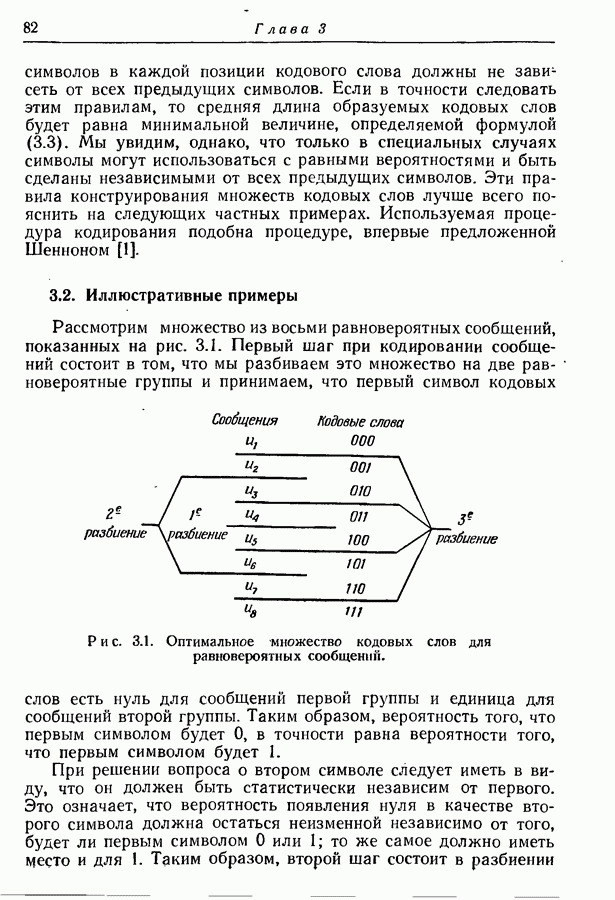
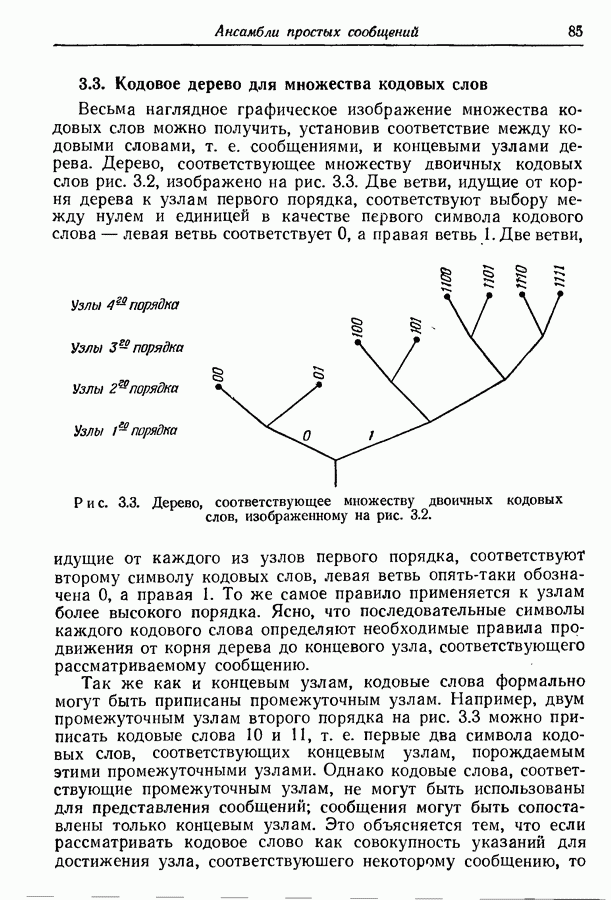
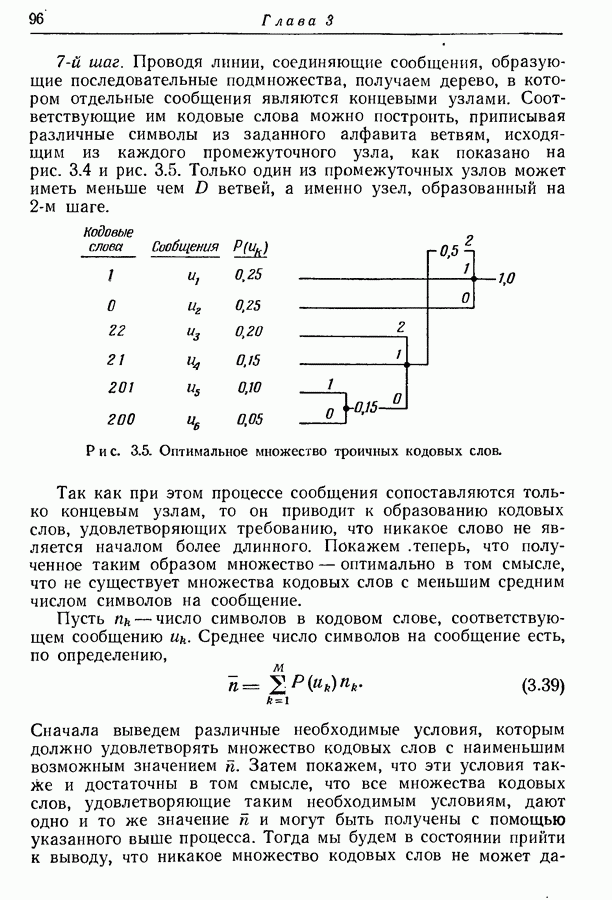
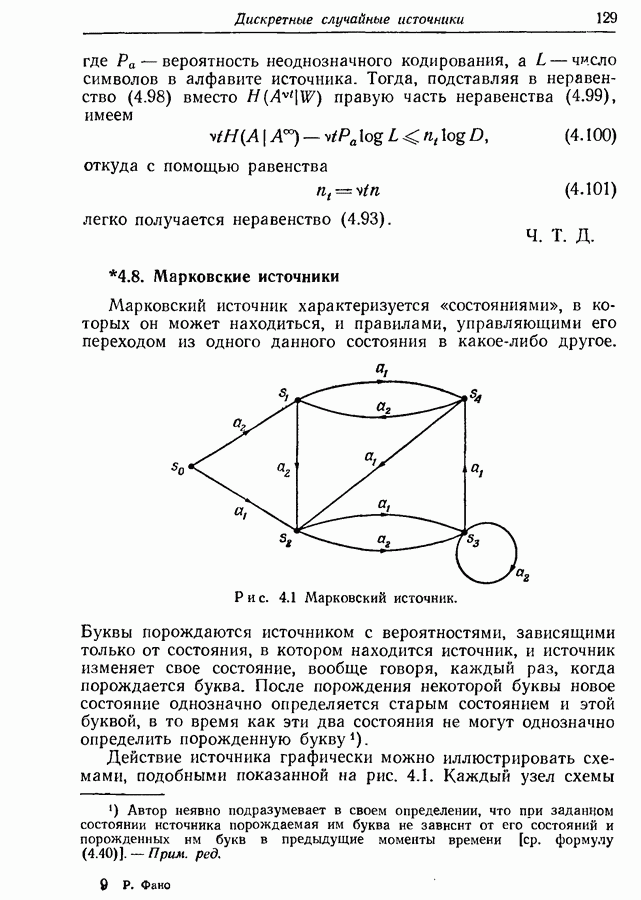
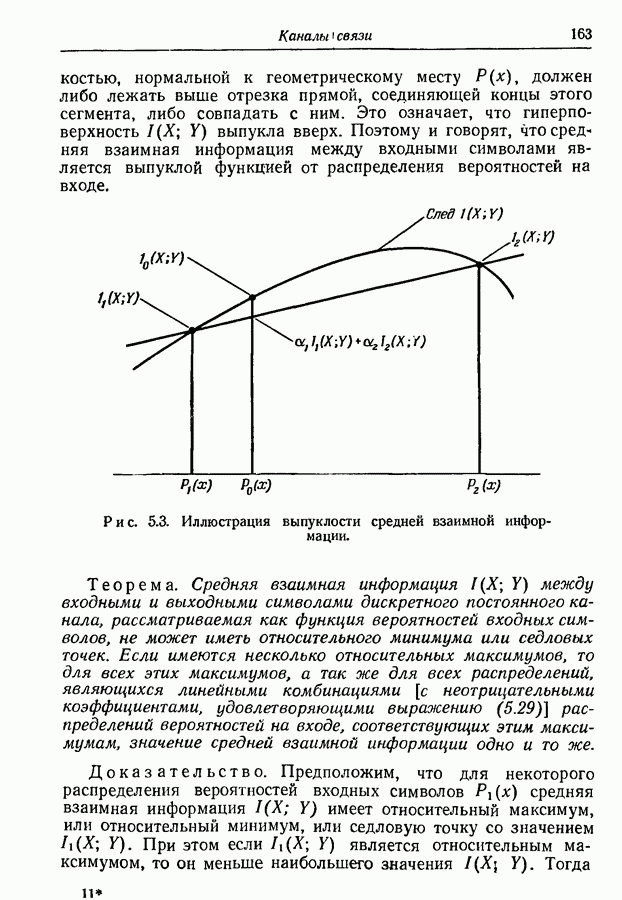
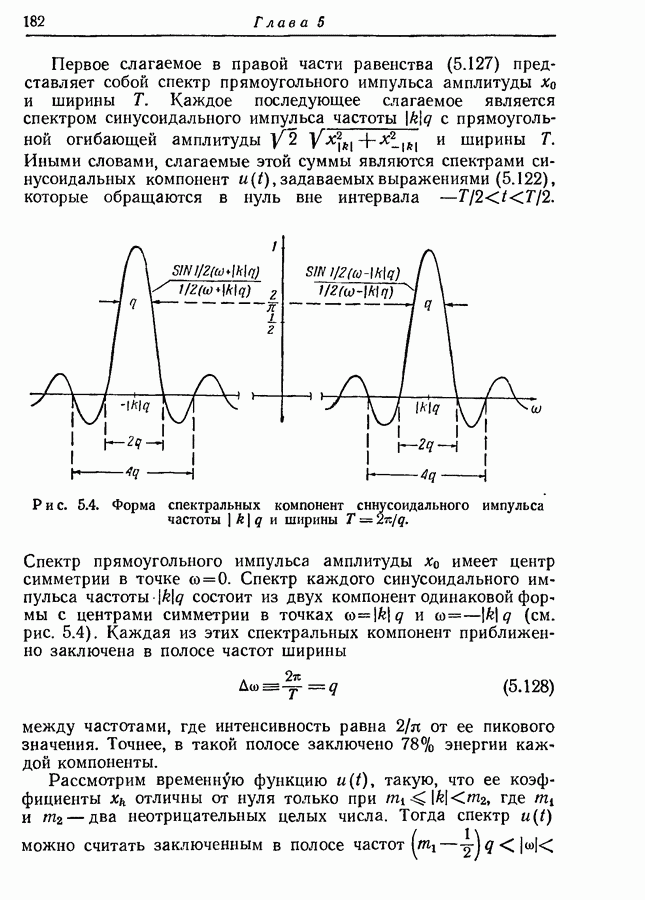
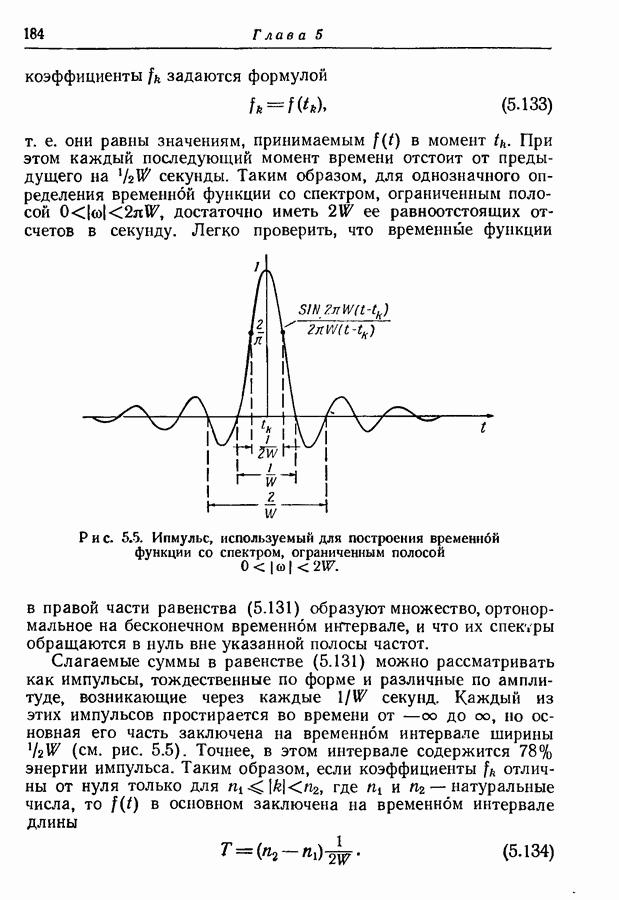
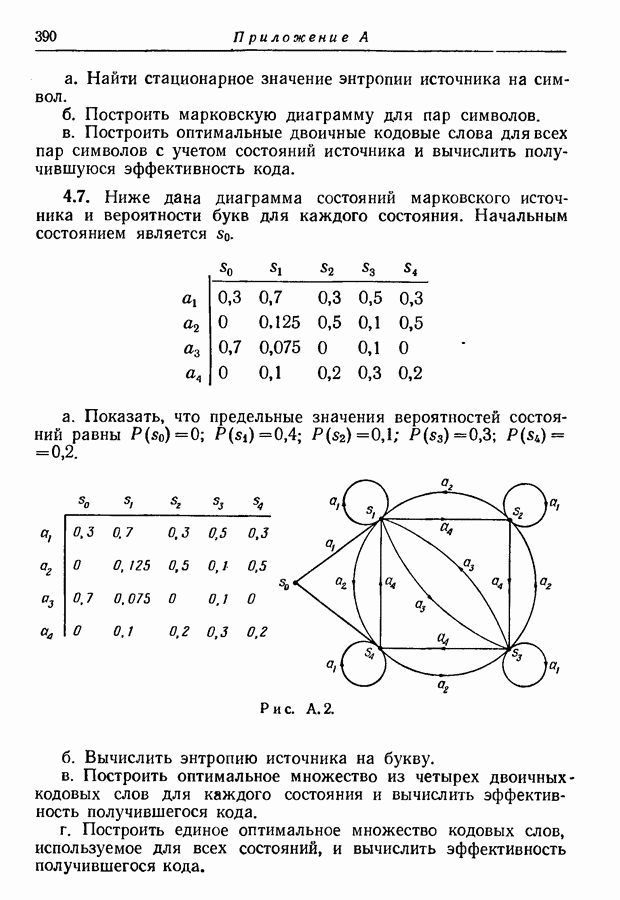
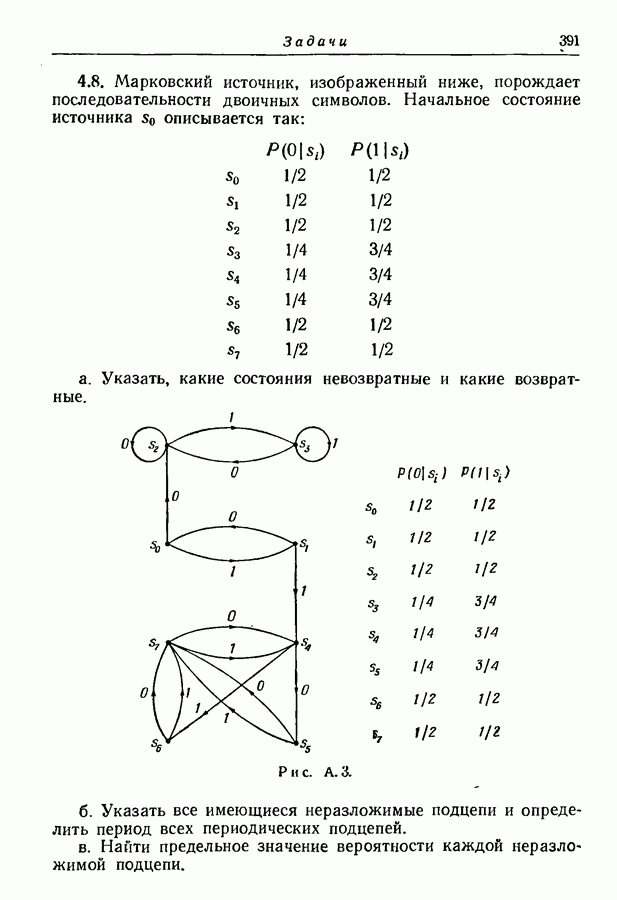
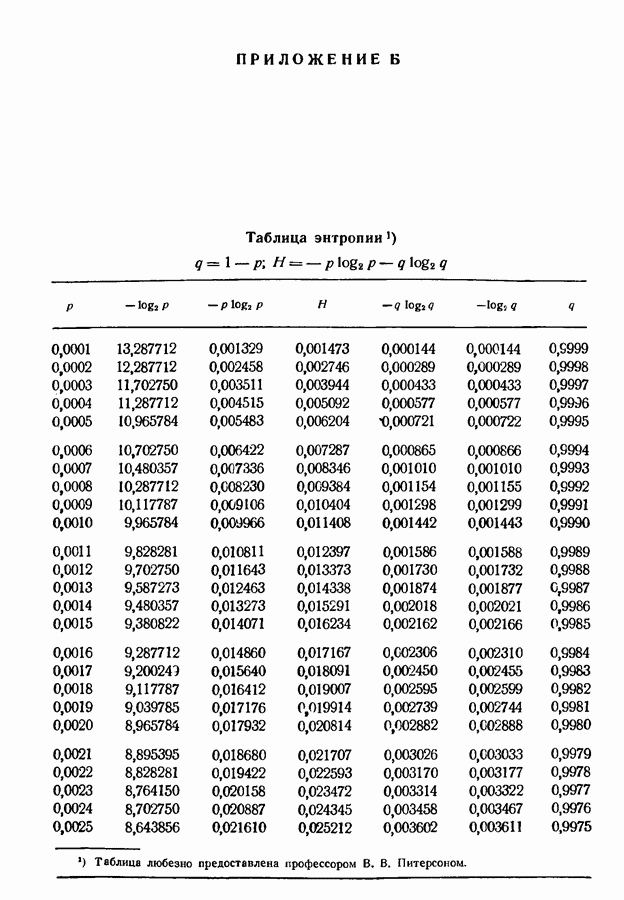
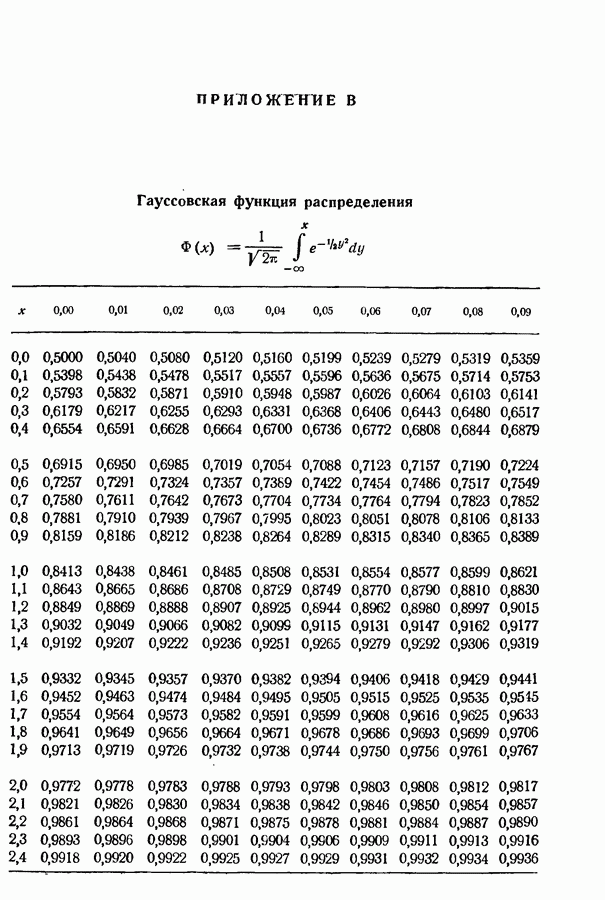
3.1. Нижняя граница для средней длины кодового слова
Рассмотрим ансамбль  из
из  сообщений
сообщений  им с соответствующими вероятностями
им с соответствующими вероятностями  Каждое сообщение должно быть представлено посредством кодового слова, состоящего из последовательных символов, принадлежащих заданному алфавиту. Обозначим через
Каждое сообщение должно быть представлено посредством кодового слова, состоящего из последовательных символов, принадлежащих заданному алфавиту. Обозначим через  число различных символов в алфавите, через
число различных символов в алфавите, через  число символов в кодовом слове, соответствующем сообщению
число символов в кодовом слове, соответствующем сообщению  Среднее число символов на одно сообщение равно по определению
Среднее число символов на одно сообщение равно по определению

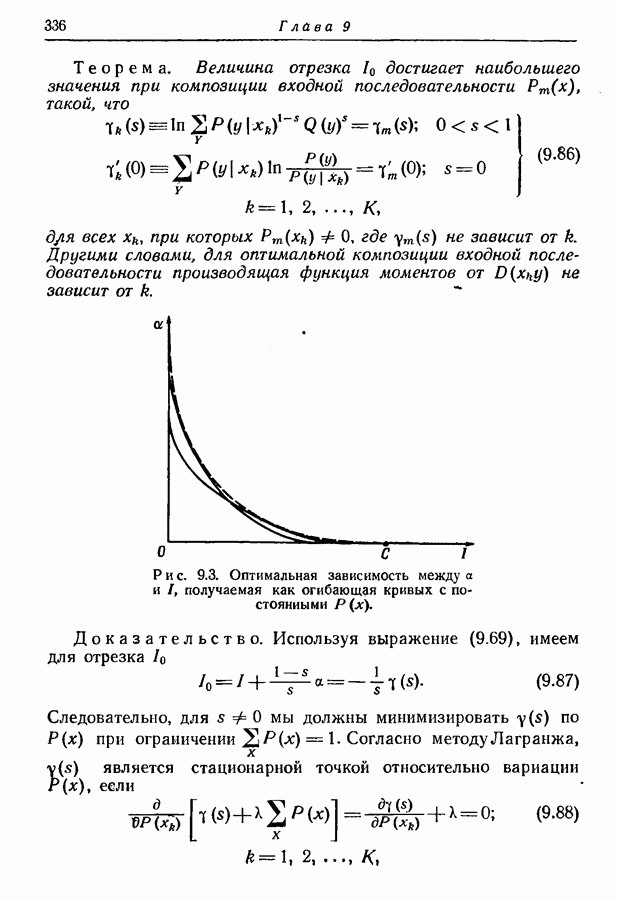
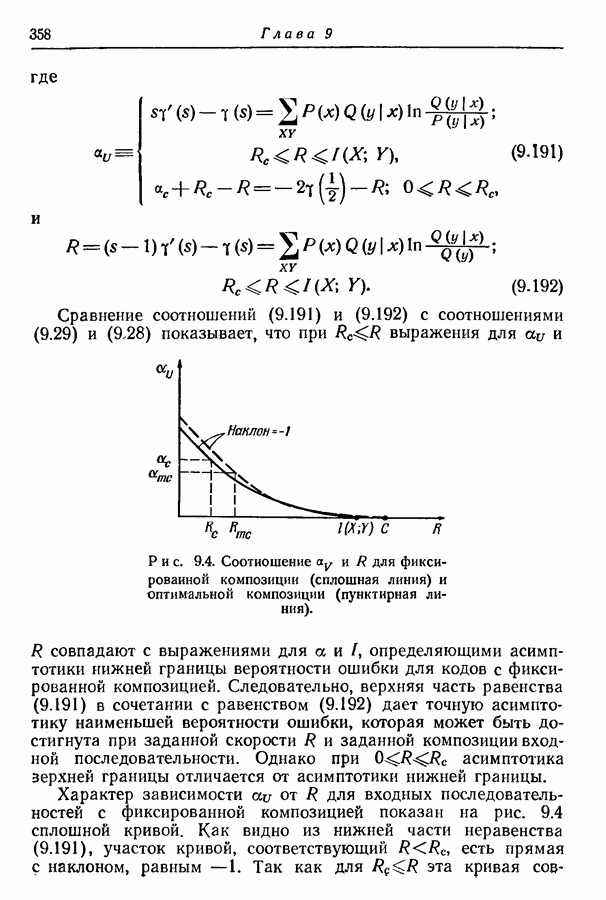
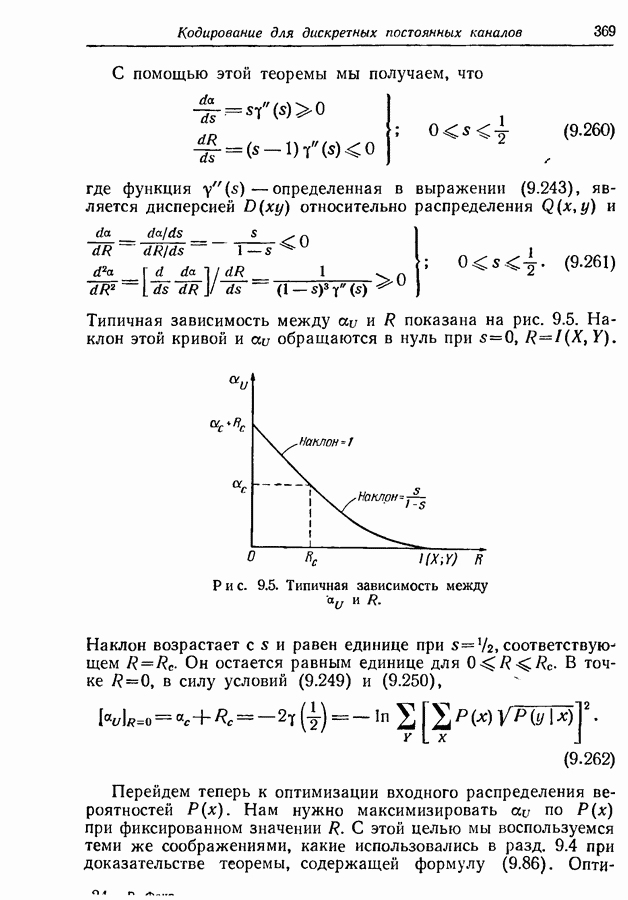
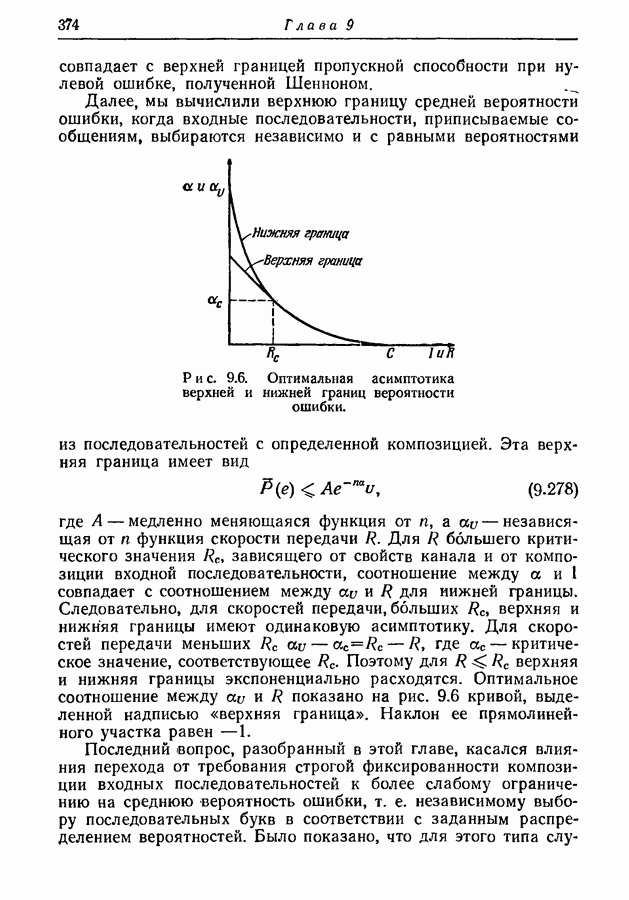
Нашей первой задачей является нахождение нижней границы для 
В разд. 2.8 мы видели, что энтропия  ансамбля сообщений представляет собой среднее количество информации, необходимое для однозначного определения сообщения из этого ансамбля. В том же разделе мы видели, что символы несут в среднем максимальное количество информации, когда они равновероятны. Эта максимальная величина, а именно
ансамбля сообщений представляет собой среднее количество информации, необходимое для однозначного определения сообщения из этого ансамбля. В том же разделе мы видели, что символы несут в среднем максимальное количество информации, когда они равновероятны. Эта максимальная величина, а именно  есть пропускная способность кодового алфавита. Кроме того, равенства (2.100) и (2.105) показывают, что статистическая зависимость некоторого символа от предыдущих не может увеличить среднее количество информации на этот символ. На этом основании мы можем заключить, что
есть пропускная способность кодового алфавита. Кроме того, равенства (2.100) и (2.105) показывают, что статистическая зависимость некоторого символа от предыдущих не может увеличить среднее количество информации на этот символ. На этом основании мы можем заключить, что

Откуда получаем

т. е. среднее число символов на сообщение не может быть меньше энтропии ансамбля сообщений, деленной на пропускную способность алфавита. Прямое доказательство этого результата дано в разд. 3.5.
Рассуждения, использованные при получении этой нижней границы, дают возможность предложить общие правила конструирования кодовых слов со средней длиной, достаточно близкой к этой границе. Первое правило состоит в том, что в каждой из позиций кодового слова различные символы алфавита должны использоваться с равными вероятностями, с тем чтобы максимизировать среднее количество информации, доставляемое ими. Второе правило состоит в том, что вероятности появления
символов в каждой позиции кодового слова должны не зависеть от всех предыдущих символов. Если в точности следовать этим правилам, то средняя длина образуемых кодовых слов будет равна минимальной величине, определяемой формулой (3.3). Мы увидим, однако, что только в специальных случаях символы могут использоваться с равными вероятностями и быть сделаны независимыми от всех предыдущих символов. Эти правила конструирования множеств кодовых слов лучше всего пояснить на следующих частных примерах. Используемая процедура кодирования подобна процедуре, впервые предложенной Шенноном [1].