Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
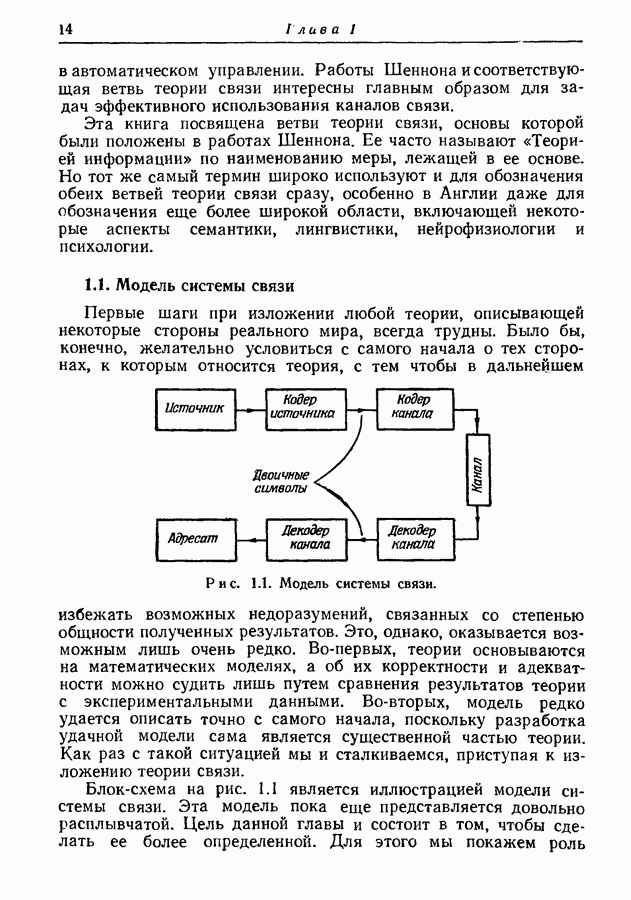
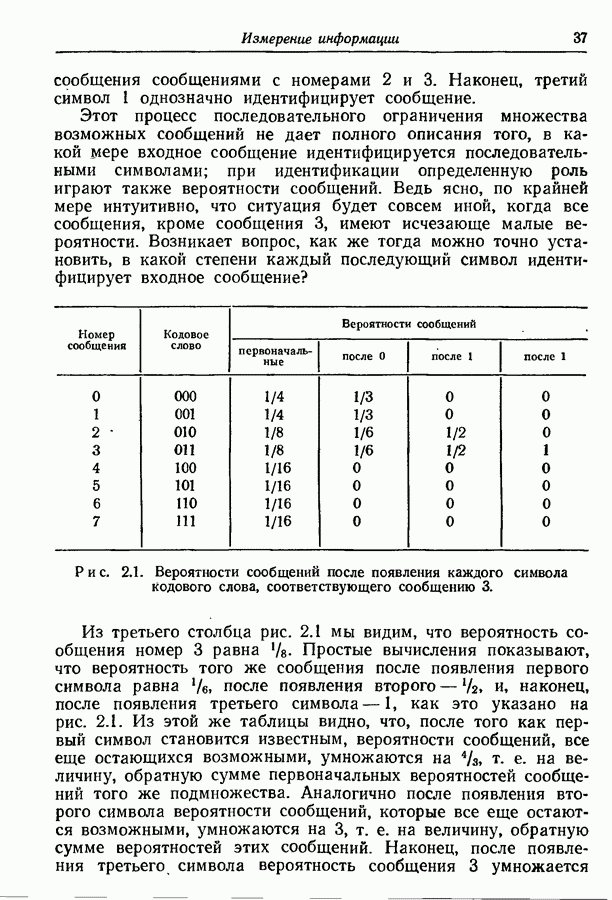
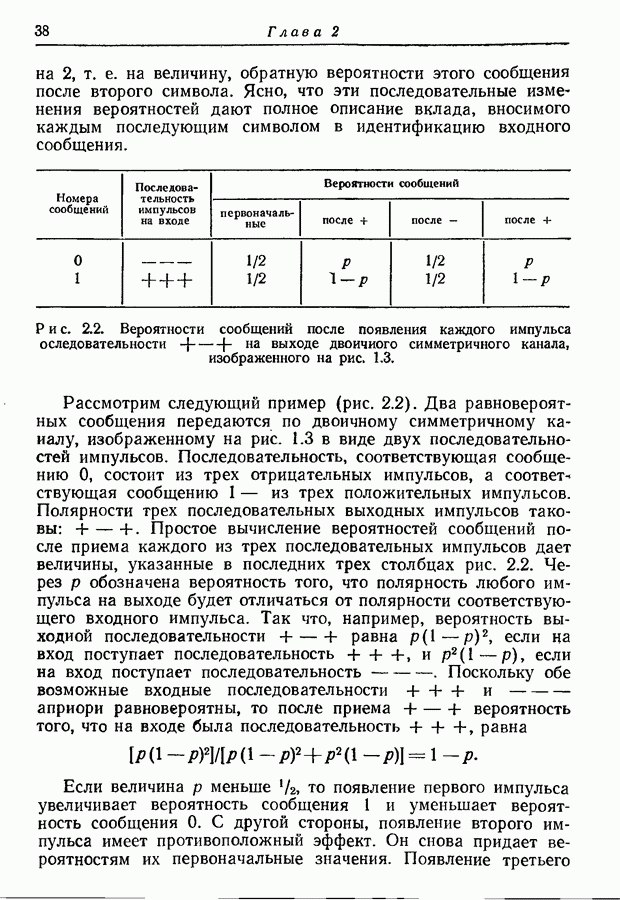
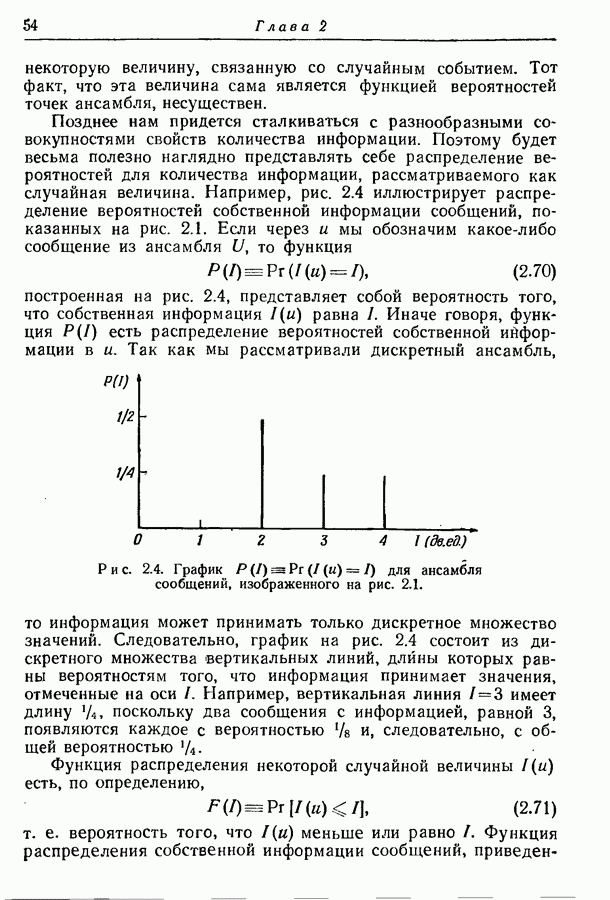
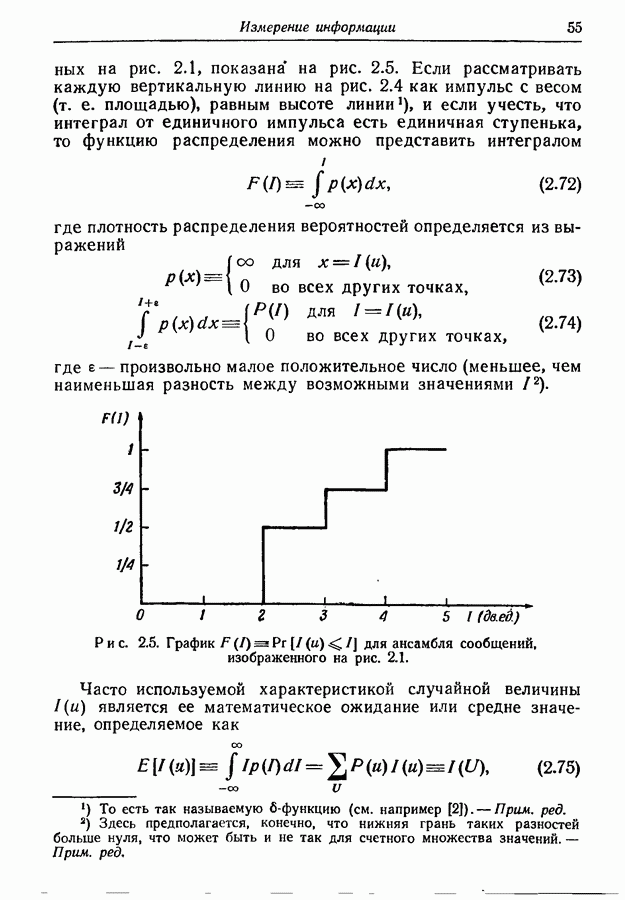
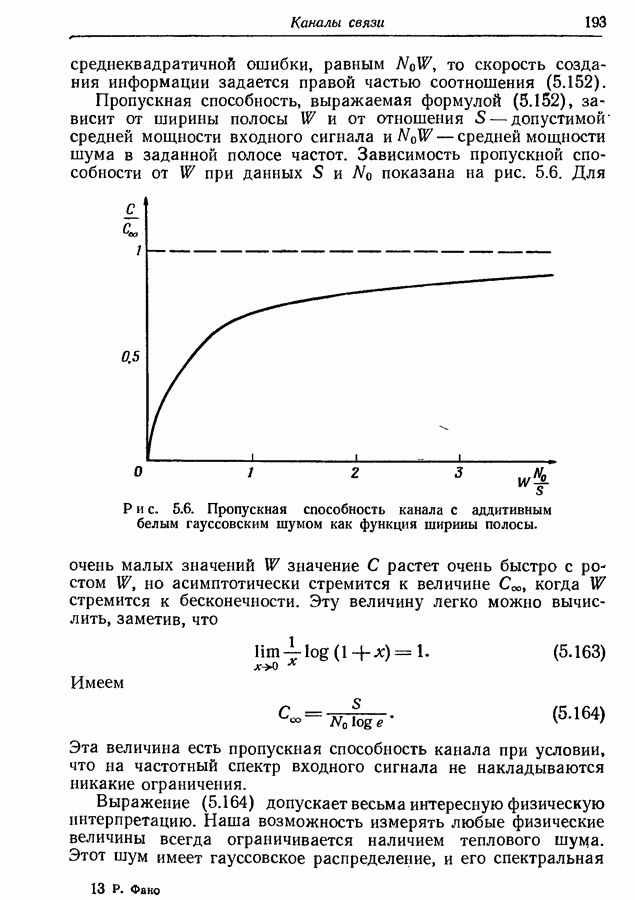
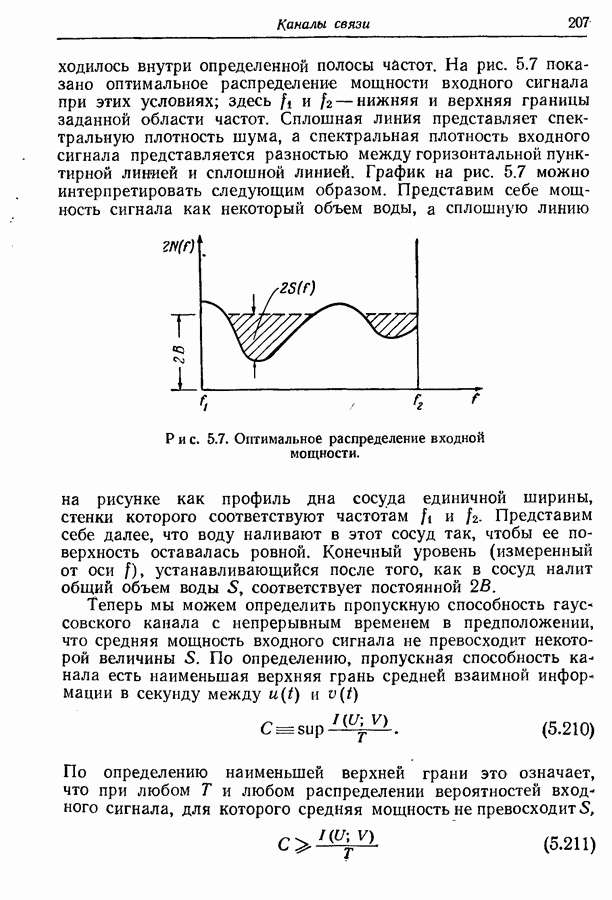
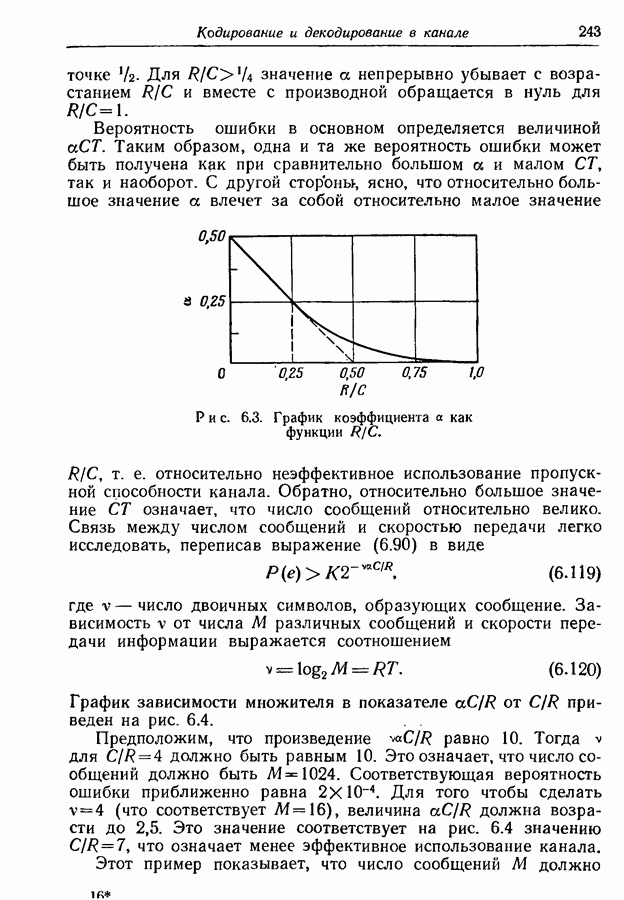
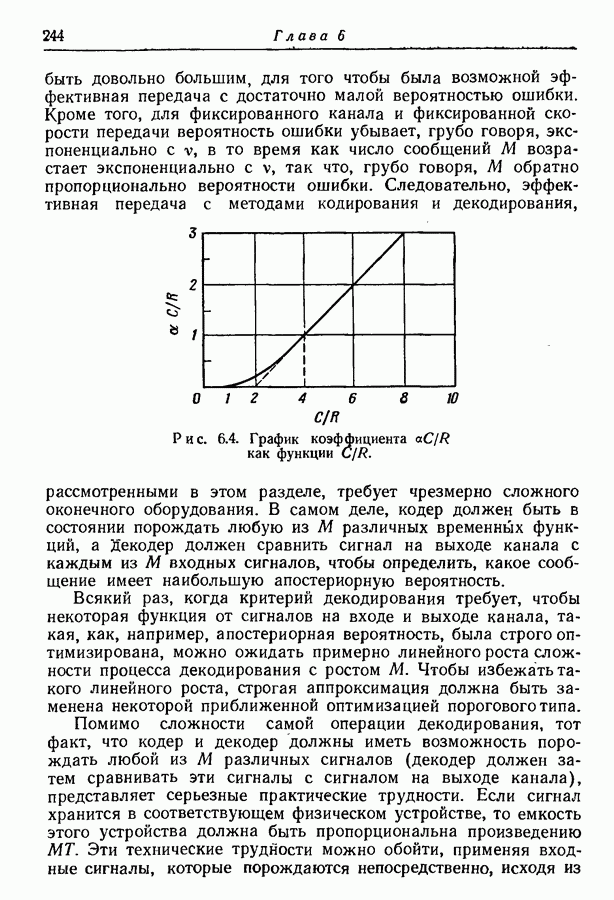
4.6. Кодирование статистически независимых событий, порождаемых источником с фиксированной скоростьюМетод кодирования, рассмотренный в разд. 4.3, предназначен для источников с управляемой скоростью, т. е. источников, в которых моменты порождения событий могут изменяться кодером источника. Однако такой метод нельзя использовать, когда фиксированы и скорость, с которой события порождаются источником, и скорость, с которой должны быть переданы символы, порождаемые кодером источника. Возникающую при этом трудность можно пояснить следующим образом. В предложенном выше методе кодирования последовательность на выходе источника разбивается на события, состоящие из последовательности событий фиксированной длины. Затем проводится кодирование, для чего каждому возможному сообщению из их множества приписывается кодовое слово длины, приблизительно равной собственной информации этого сообщения, деленной на Предположим, что источник порождает события, а следовательно, и сообщения с фиксированной скоростью. Так как, во обще говоря, последовательные сообщения имеют разную собственную информацию, то скорость передачи сообщения не может все время оставаться равной скорости, с которой сообщения попадают в кодер. С первого взгляда может показаться, что если эти средние скорости равны, то разницу между двумя мгновенными скоростями способно поглотить соответствующее накопительное устройство. Однако можно показать, что с вероятностью 1 любой конечный накопитель будет в конце концов переполнен. Переформулируем теперь проблему кодирования так, чтобы она оказалась пригодной для источников с фиксированной скоростью. Предположим опять, что выходная последовательность разбивается на последовательные сообщения, каждое из которых содержит фиксированное число Если каждое сообщение содержит
так что
т. е. число символов на сообщение, порождаемых кодером источника, не может быть меньше числа событий на сообщение, умноженного на отношение пропускных способностей двух алфавитов. Таким образом, кодер может только преобразовывать последовательность на выходе источника от одного алфавита к другому без какого-либо уменьшения числа символов на сообщение. Ясно, что никакое эффективное кодирование невозможно, если кодовые слова фиксированной длины должны быть сопоставлены всевозможным сообщениям. Однако оно становится снова возможным, если, отказавшись от требования сопоставления различных кодовых слов фиксированной длины всем сообщениям, мы потребуем лишь сопоставления различных кодовых слов фиксированной длины всем сообщениям, за исключением подмножества сообщений с исчезающе малой вероятностью появления. В этом разделе мы рассмотрим простой случай статистически независимых событий. Пусть
где
— собственная информация буквы, образующей Теорема. Пусть
Обозначим через
где Доказательство. Случайная величина
и, следовательно,
Отсюда и из определения множества
для всех последовательностей
где
где Эта теорема подсказывает следующий метод кодирования: Теорема. Пусть
где Доказательство. При использовании приведенного выше метода кодирования длина
так что требуемое число символов на выходное событие подчинено неравенству
С другой стороны, согласно предыдущей теореме, вероятность неоднозначного кодирования может быть сделана такой, чтобы она удовлетворяла неравенству
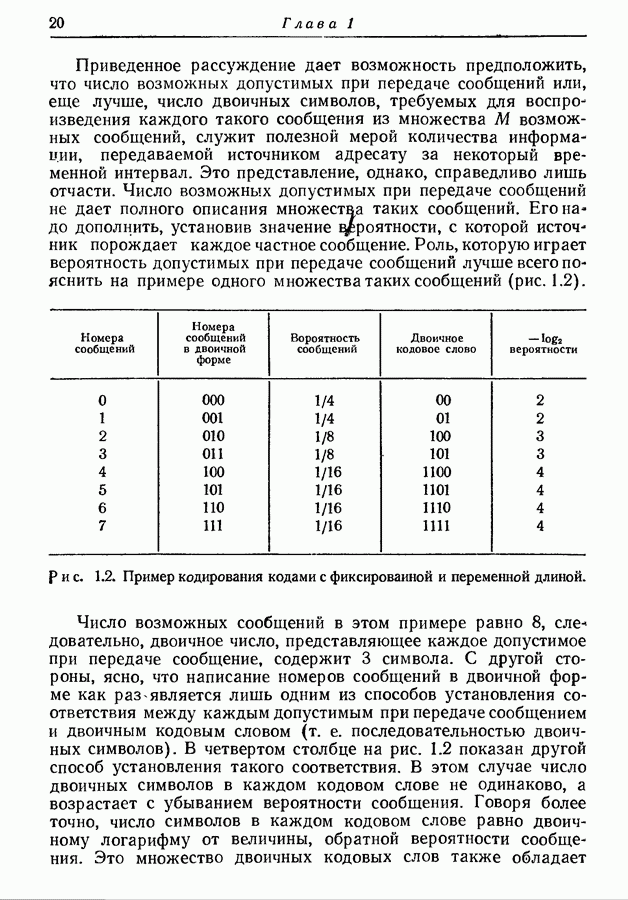
при любом положительном
неравенство (4.65) приводит к неравенству (4.62). Ч. Т. Д. Из этой теоремы мы можем заключить, что последовательность статистически независимых событий на выходе источника с фиксированной скоростью можно закодировать так, чтобы число символов на событие было как угодно близко к энтропии на событие, деленной на пропускную способность кодового алфавита (но все же не меньше ее). При этом вероятность неоднозначного кодирования исчезающе мала. Докажем теперь обратное утверждение, а именно что при исчезающе малой вероятности неоднозначного кодирования число символов на событие не может быть сделано меньше энтропии на событие, деленной на пропускную способность алфавита. Теорема. Вероятность неоднозначного кодирования для источника с фиксированной скоростью, порождающего статистически независимые события, удовлетворяет неравенству
где Доказательство. Обозначим через
С другой стороны, поскольку события, порождаемые источником, статистически независимы, то
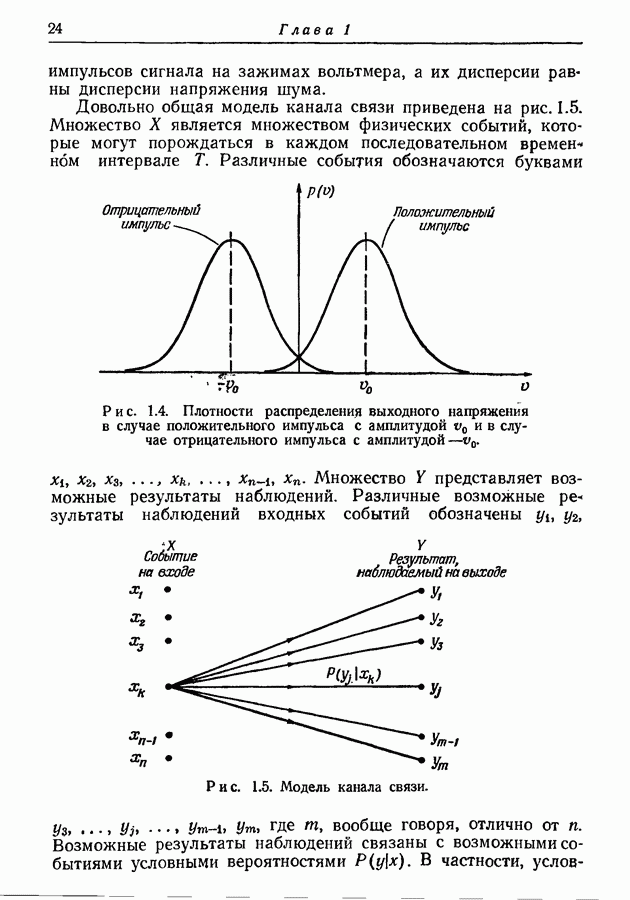
Кроме того,
где
Верхнюю границу условной энтропии принадлежащим множеству
Сумма в правой части равна нулю, так как каждое кодовое слово однозначно определяет соответствующую последовательность. Условная энтропия
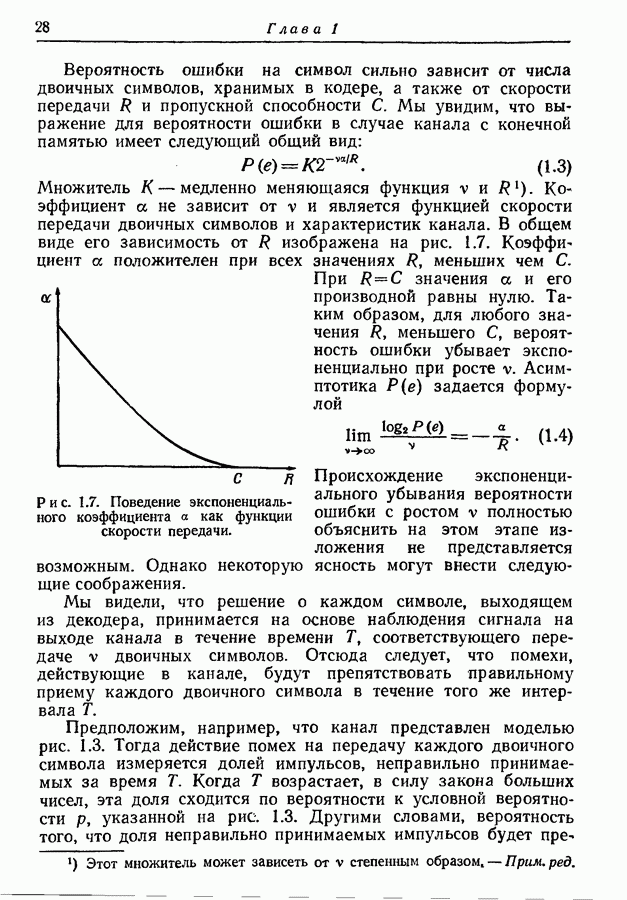
Наконец, подстановка правой части соотношения (4.74) вместо
Откуда, заменяя на
|
 |
Оглавление
|












































































































































































































































































































































































 т. е. на пропускную способность кодового алфавита. При этих условиях каждый символ, порождаемый кодером, содержит приблизительно
т. е. на пропускную способность кодового алфавита. При этих условиях каждый символ, порождаемый кодером, содержит приблизительно  двоичных единиц информации о выходной последовательности. Тогда, если порождаемый символ передается с постоянной скоростью, то время, требуемое для передачи любого частного сообщения, становится приближенно пропорциональным собственной информации сообщения.
двоичных единиц информации о выходной последовательности. Тогда, если порождаемый символ передается с постоянной скоростью, то время, требуемое для передачи любого частного сообщения, становится приближенно пропорциональным собственной информации сообщения.
 событий на выходе источника. Теперь мы хотим закодировать множество возможных сообщений так, чтобы все кодовые слова, соответствующие сообщениям, имели одну и ту же длину, а потому могли бы быть переданы в течение одного и того же временного интервала.
событий на выходе источника. Теперь мы хотим закодировать множество возможных сообщений так, чтобы все кодовые слова, соответствующие сообщениям, имели одну и ту же длину, а потому могли бы быть переданы в течение одного и того же временного интервала.
 событий и каждое событие может быть одной из
событий и каждое событие может быть одной из  различных букв, то число возможных сообщений равно
различных букв, то число возможных сообщений равно  Тогда, если каждому сообщению будет соответствовать кодовое слово, то длина кодовых слов должна удовлетворять соотношению
Тогда, если каждому сообщению будет соответствовать кодовое слово, то длина кодовых слов должна удовлетворять соотношению


 энтропия ансамбля возможных букв, т. е. математическое ожидание собственной информации каждого события. Собственная информация последовательности
энтропия ансамбля возможных букв, т. е. математическое ожидание собственной информации каждого события. Собственная информация последовательности  букв в этом случае равна просто сумме собственных информаций этих
букв в этом случае равна просто сумме собственных информаций этих  букв, т. е.
букв, т. е.


 событие последовательности. Метод кодирования с фиксированной скоростью для статистически независимых событий основан на следующей теореме.
событие последовательности. Метод кодирования с фиксированной скоростью для статистически независимых событий основан на следующей теореме.
 — любые два положительных числа и
— любые два положительных числа и  множество последовательностей
множество последовательностей  из
из  букв, для которых
букв, для которых

 число последовательностей в
число последовательностей в  а через
а через  вероятность появления последовательности, принадлежащей
вероятность появления последовательности, принадлежащей  Тогда, если события статистически независимы, то существует целое
Тогда, если события статистически независимы, то существует целое  такое, что для любого
такое, что для любого 

 выражается в двоичных единицах.
выражается в двоичных единицах.
 есть сумма
есть сумма  одинаково распределенных статистически независимых случайных величин с математическим ожиданием, равным
одинаково распределенных статистически независимых случайных величин с математическим ожиданием, равным  Тогда, согласно закону больших чисел (см. раздел 4.4), существует целое
Тогда, согласно закону больших чисел (см. раздел 4.4), существует целое  такое, что для любого
такое, что для любого 


 легко вытекает существование верхней границы числа
легко вытекает существование верхней границы числа  последовательностей в
последовательностей в  задаваемой неравенством (4.56). В самом деле, из неравенства (4.54) и определения собственной информации следует, что
задаваемой неравенством (4.56). В самом деле, из неравенства (4.54) и определения собственной информации следует, что

 из
из  Поэтому вероятность появления какой-либо последовательности, принадлежащей
Поэтому вероятность появления какой-либо последовательности, принадлежащей  удовлетворяет неравенству
удовлетворяет неравенству

 выражено в двоичных единицах. Отсюда вытекает, что
выражено в двоичных единицах. Отсюда вытекает, что 

 множество всех последовательностей
множество всех последовательностей  Искомая верхняя граница для
Искомая верхняя граница для  немедленно следует из неравенства (4.61). Ч. Т. Д.
немедленно следует из неравенства (4.61). Ч. Т. Д.
 последовательностей из
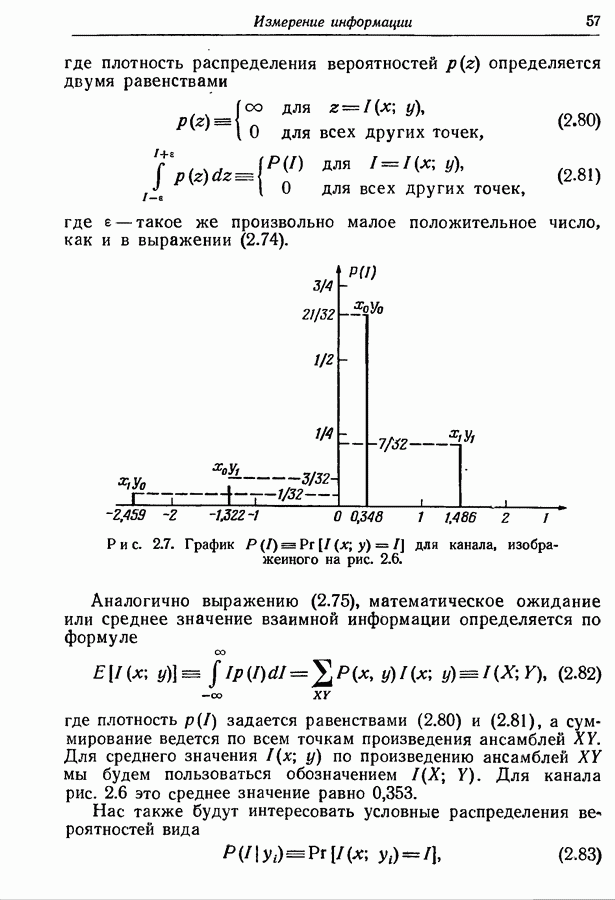
последовательностей из  букв, принадлежащих множеству
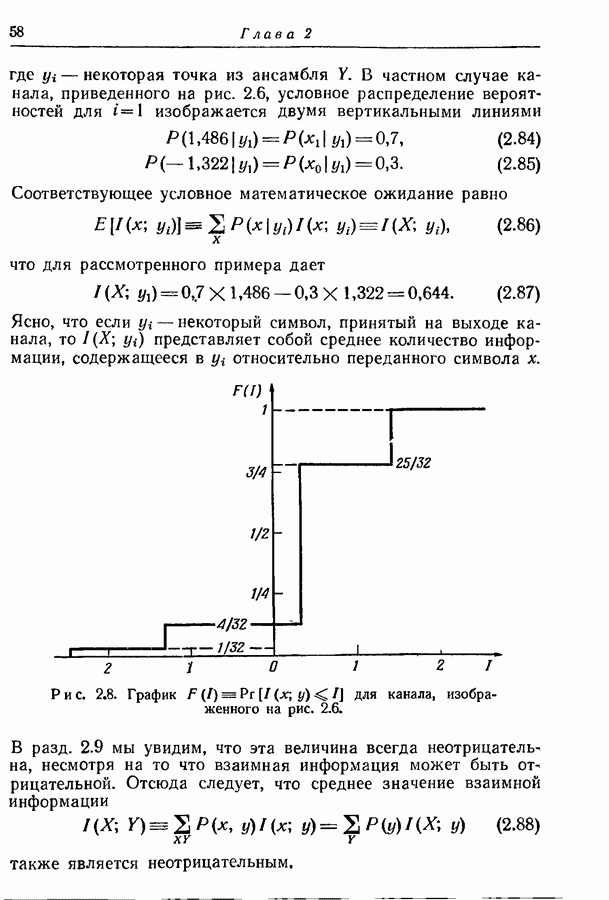
букв, принадлежащих множеству  теоремы, представляются различными кодовыми словами длины а все оставшиеся последовательности — одним и тем же кодовым словом. Соответственно этому кодер источника разбивает выходную последовательность на сообщения, содержащие
теоремы, представляются различными кодовыми словами длины а все оставшиеся последовательности — одним и тем же кодовым словом. Соответственно этому кодер источника разбивает выходную последовательность на сообщения, содержащие  последовательных букв, и порождает для каждого последовательного сообщения соответствующее кодовое слово. Возникающая при этом вероятность неоднозначного кодирования равна вероятности появления последовательности, не принадлежащей множеству
последовательных букв, и порождает для каждого последовательного сообщения соответствующее кодовое слово. Возникающая при этом вероятность неоднозначного кодирования равна вероятности появления последовательности, не принадлежащей множеству 
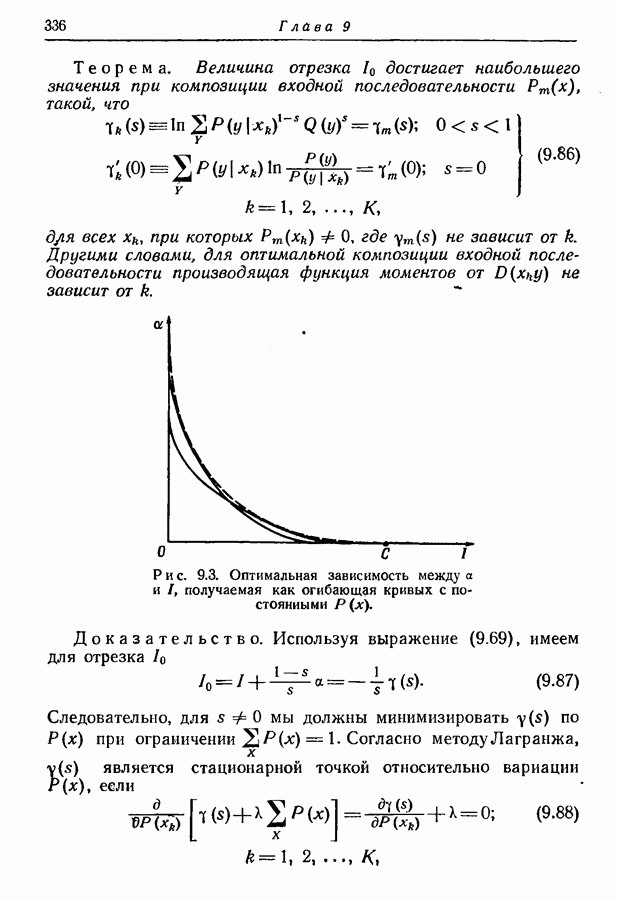
 и 6 — любые два положительные числа. Тогда последовательность на выходе источника с фиксированной скоростью, порождающего статистически независимые события с энтропией
и 6 — любые два положительные числа. Тогда последовательность на выходе источника с фиксированной скоростью, порождающего статистически независимые события с энтропией  можно закодировать так, чтобы число символов
можно закодировать так, чтобы число символов  на события и вероятность
на события и вероятность  неоднозначности кодирования удовлетворяли неравенствам
неоднозначности кодирования удовлетворяли неравенствам

 число символов в кодовом алфавите.
число символов в кодовом алфавите.
 каждого из
каждого из  различных кодовых слов удовлетворяет неравенству
различных кодовых слов удовлетворяет неравенству



 если
если  взять достаточно большим. Тогда, если
взять достаточно большим. Тогда, если  выбрано так, что
выбрано так, что


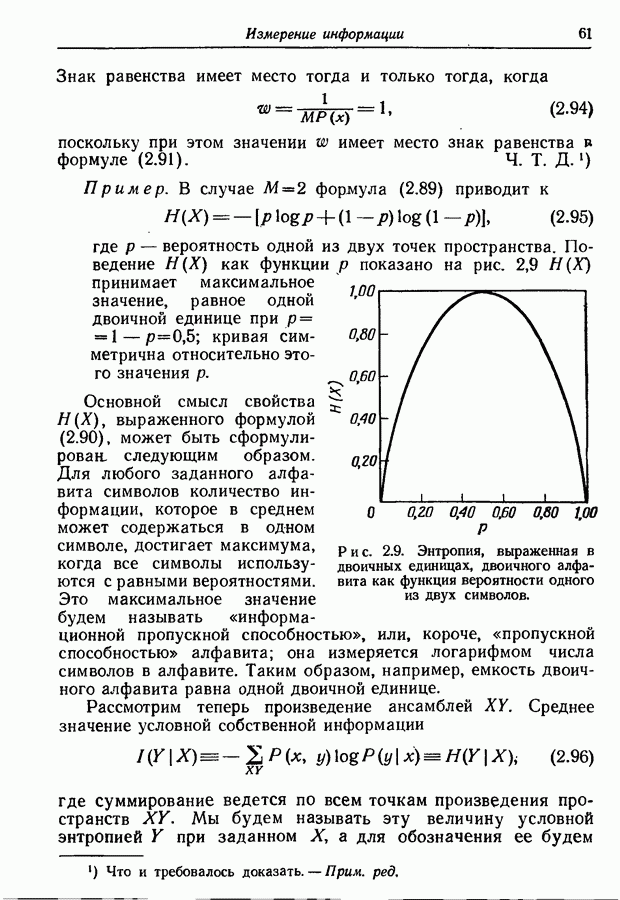
 - энтропия на событие;
- энтропия на событие;  число символов на событие, L - число букв алфавита источника, D - число символов кодового алфавита.
число символов на событие, L - число букв алфавита источника, D - число символов кодового алфавита.
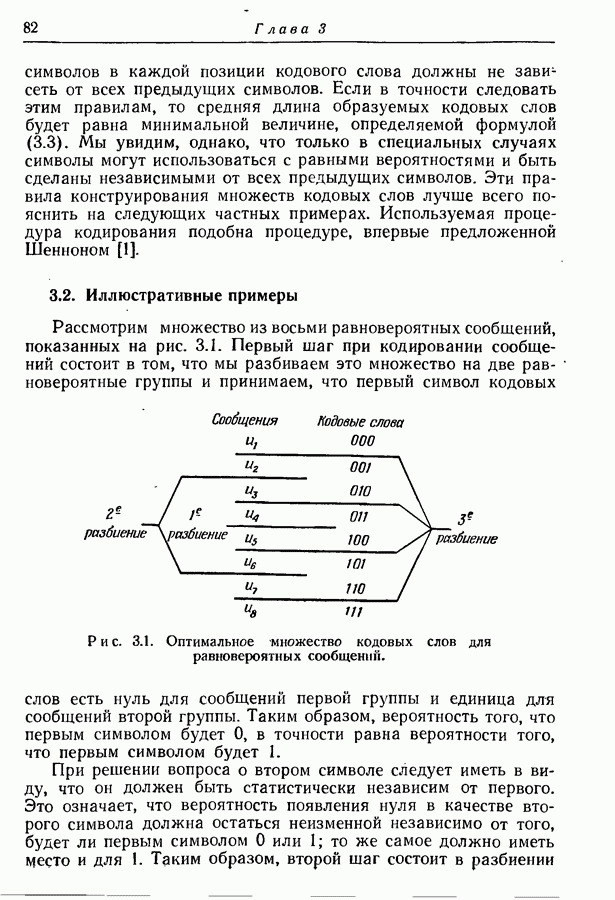
 ансамбль кодовых слов, а через
ансамбль кодовых слов, а через  ансамбль последовательностей из
ансамбль последовательностей из  букв, представляемых этими кодовыми словами. Среднее значение количества информации, содержащейся в кодовых словах относительно этих последовательностей, можно выразить в виде
букв, представляемых этими кодовыми словами. Среднее значение количества информации, содержащейся в кодовых словах относительно этих последовательностей, можно выразить в виде



 число символов в каждом кодовом слове. Отсюда следует, что
число символов в каждом кодовом слове. Отсюда следует, что

 можно легко получить следующим образом. Обозначим через
можно легко получить следующим образом. Обозначим через  кодовое слово, соответствующее последовательностям, не
кодовое слово, соответствующее последовательностям, не
 и через
и через  кодовое слово, соответствующее
кодовое слово, соответствующее  последовательности из
последовательности из  Мы имеем, по определению,
Мы имеем, по определению,

 не может превзойти логарифма числа возможных последовательностей,
не может превзойти логарифма числа возможных последовательностей,  равно
равно  поскольку неоднозначность кодирования имеет место тогда и только тогда, когда появляется
поскольку неоднозначность кодирования имеет место тогда и только тогда, когда появляется  Отсюда следует, что
Отсюда следует, что

 в неравенство (4.72) дает
в неравенство (4.72) дает

 легко получаем неравенство (4.68), Ч. Т. Д.
легко получаем неравенство (4.68), Ч. Т. Д.