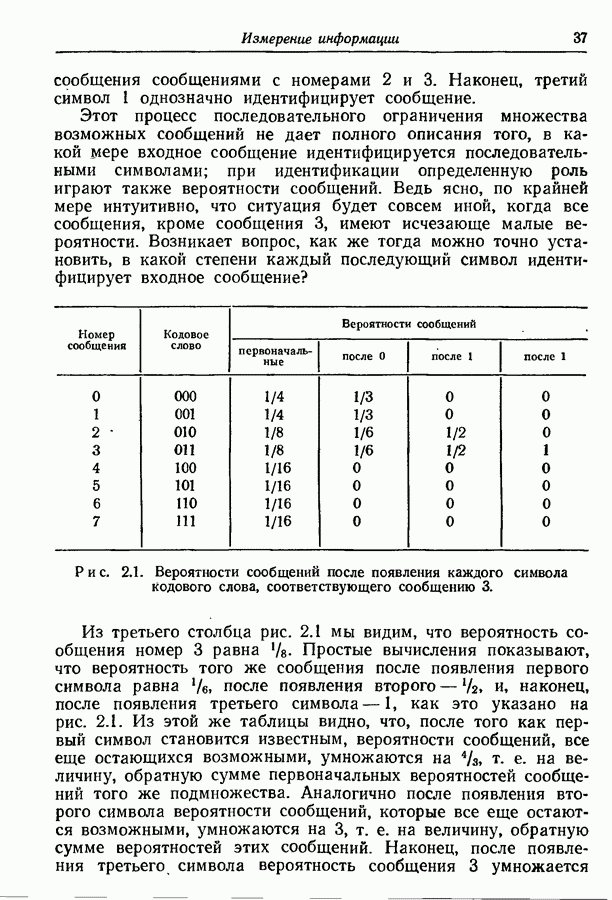
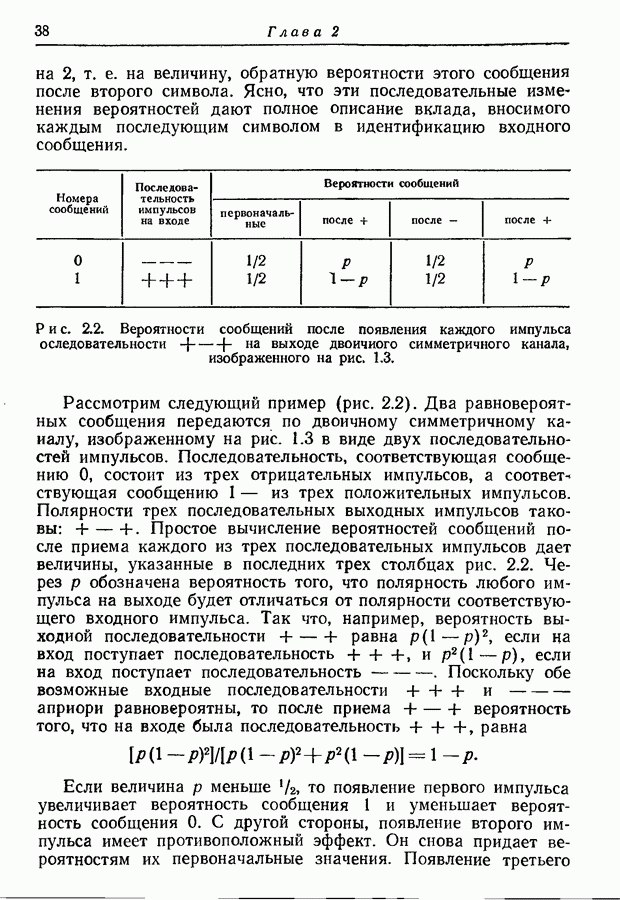
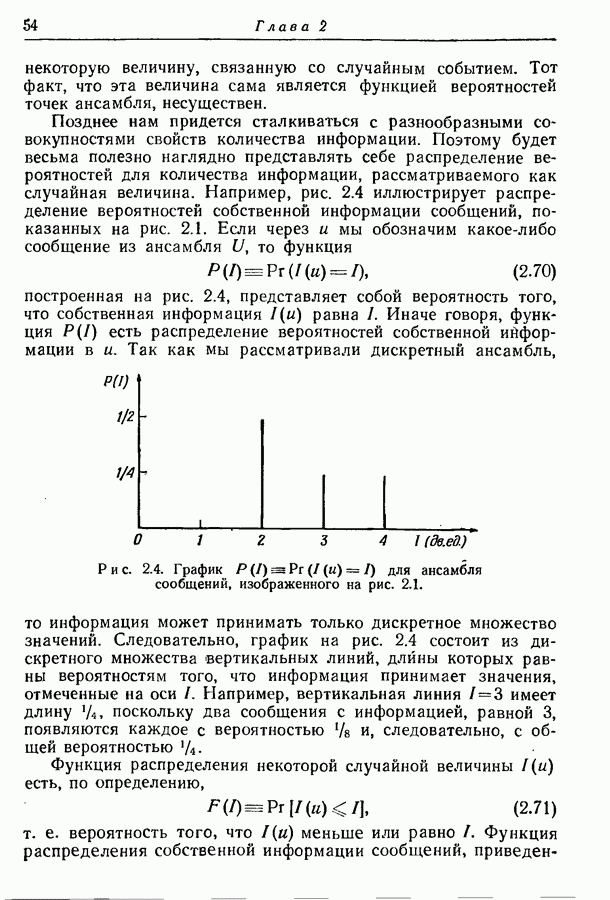
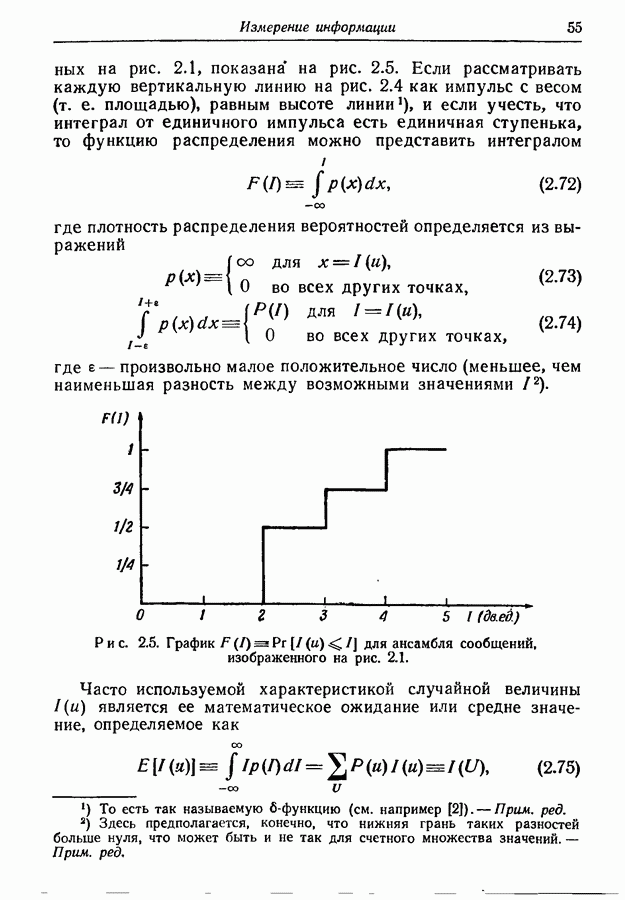
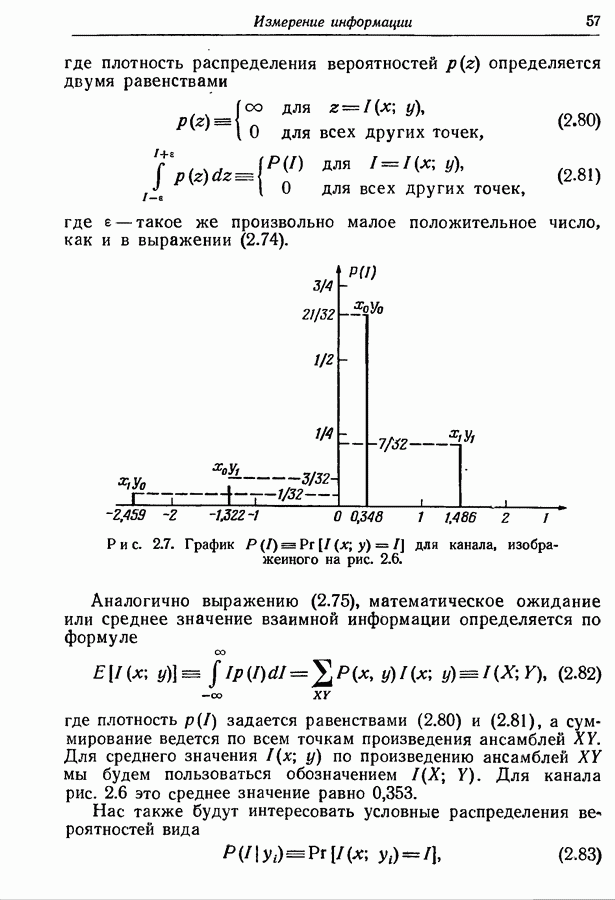
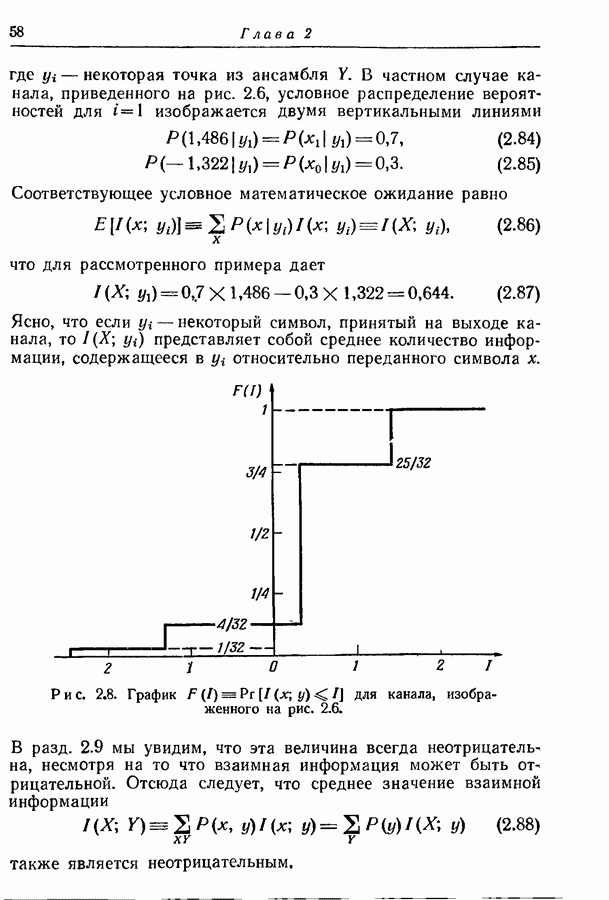
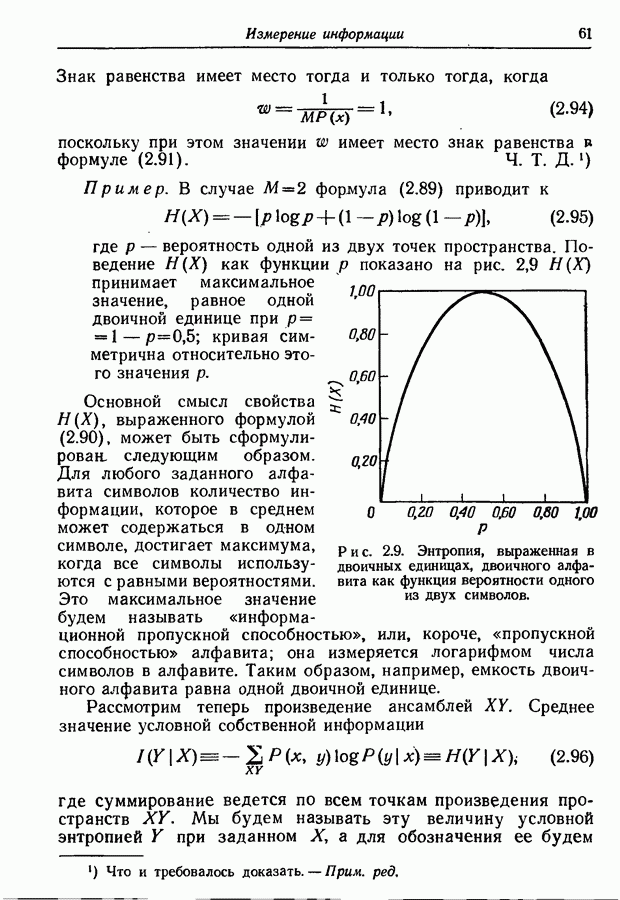
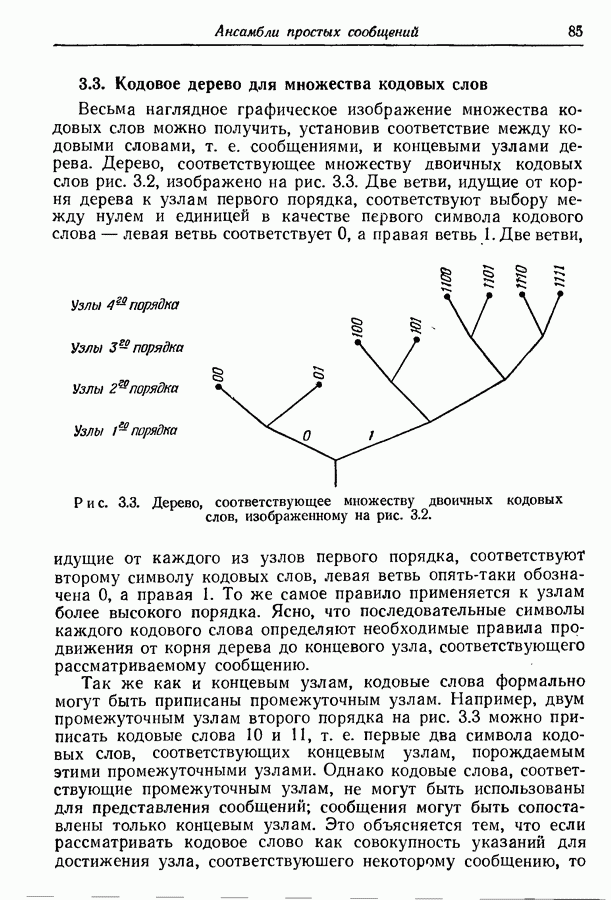
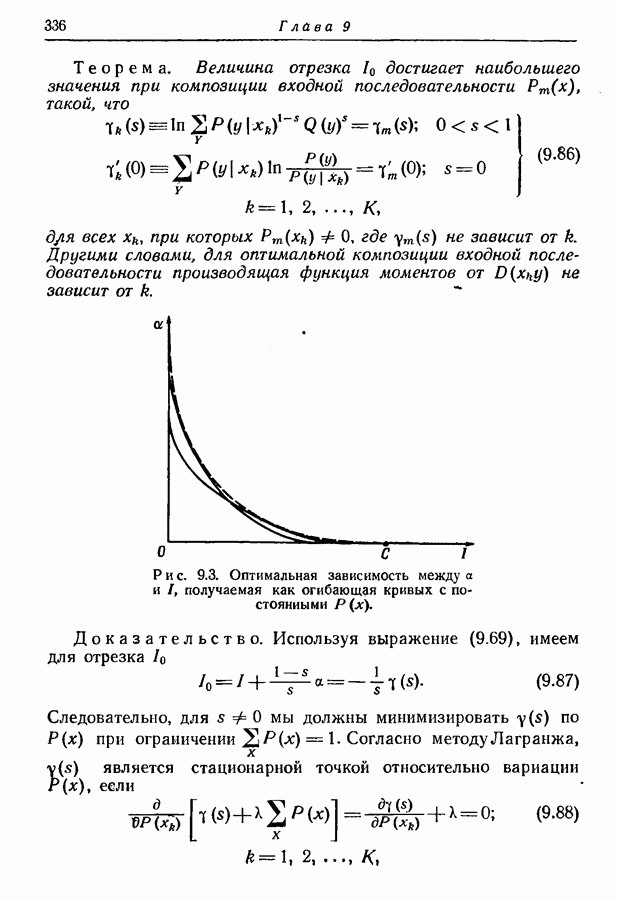
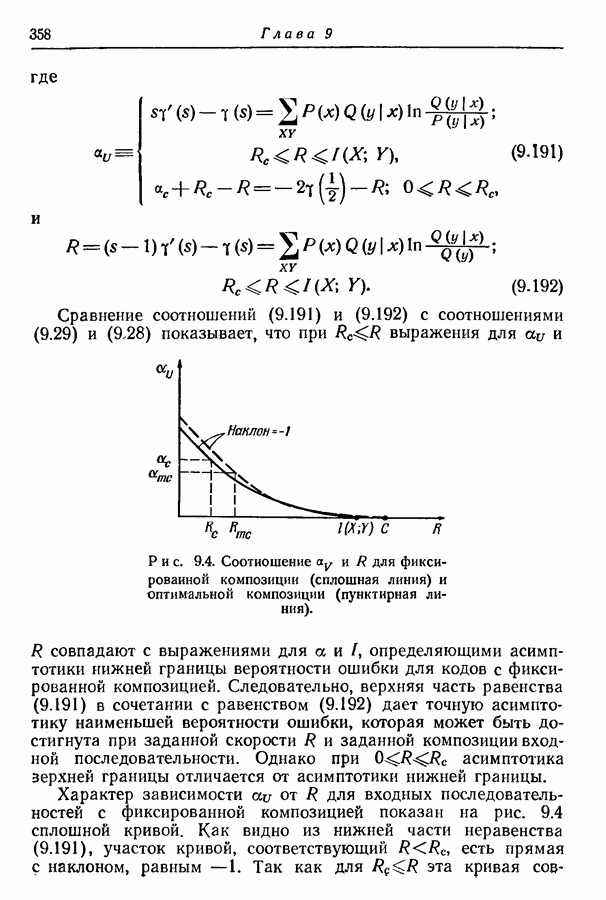
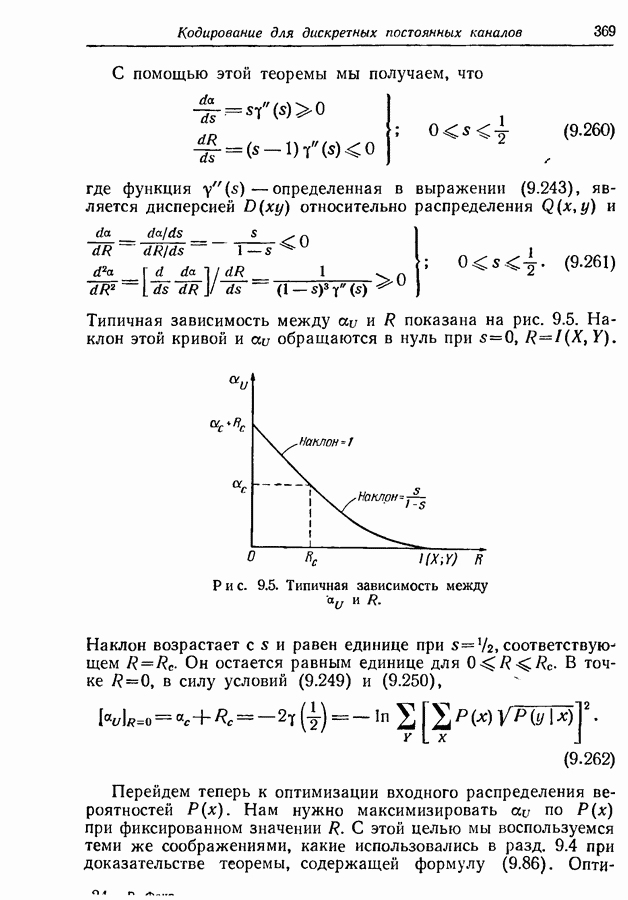
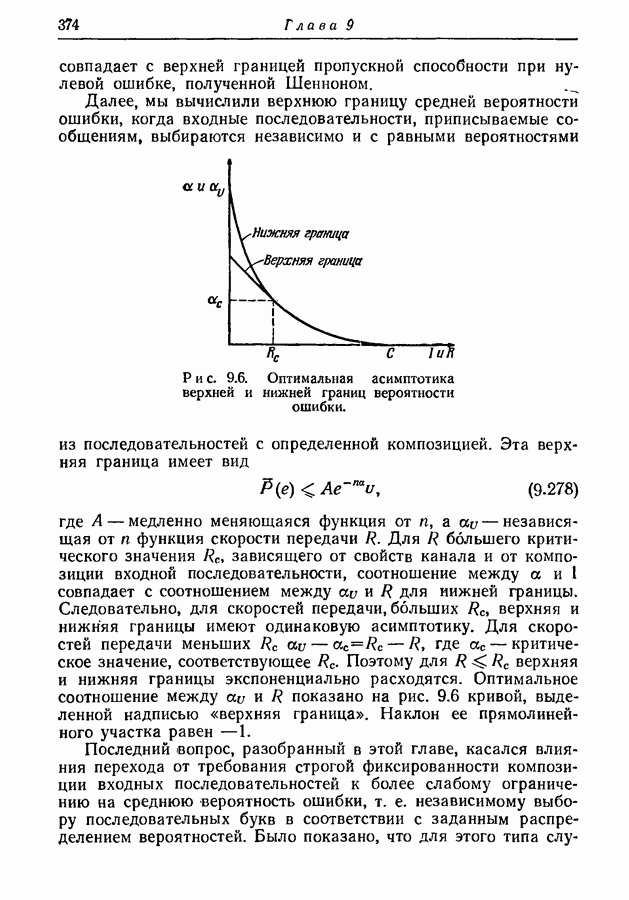
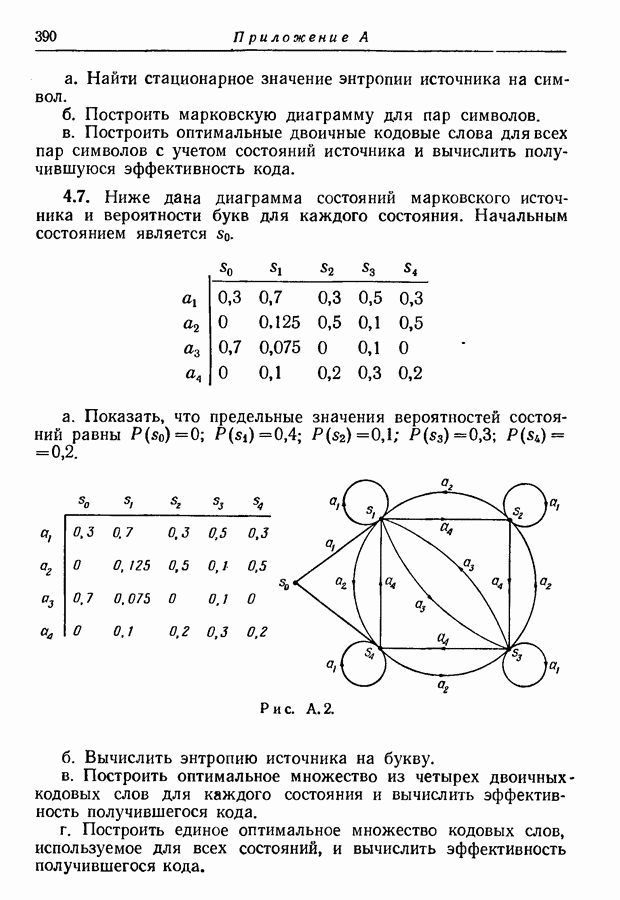
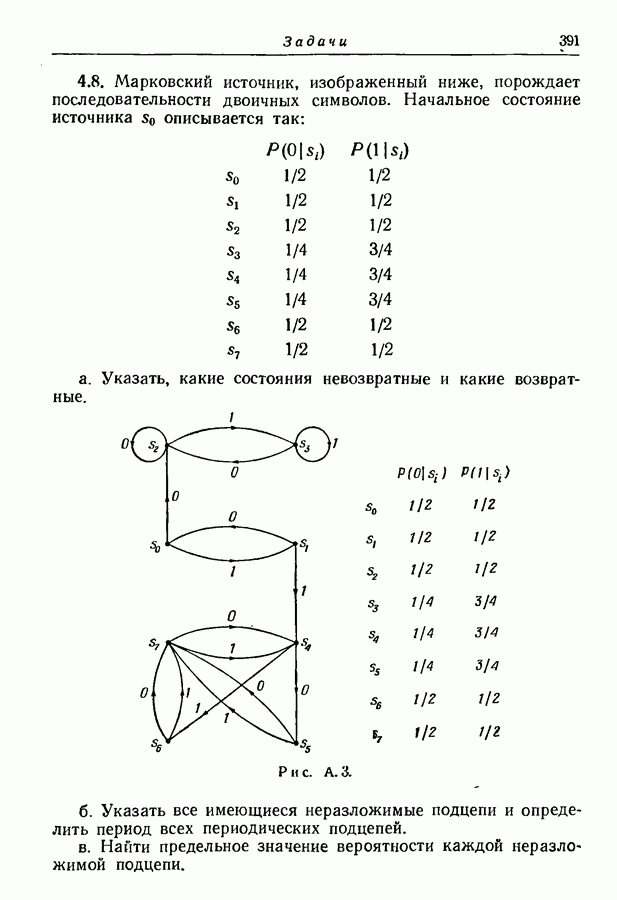
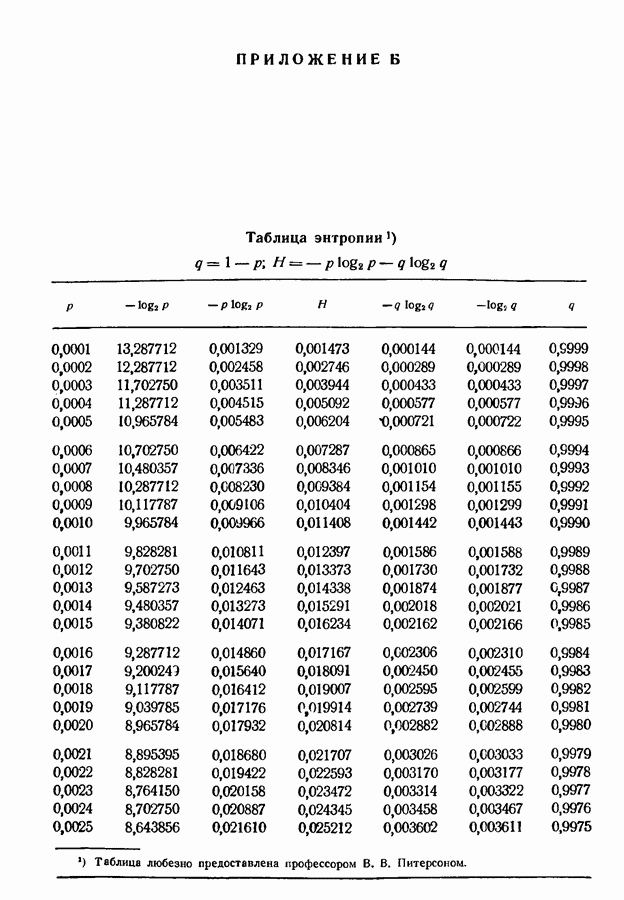
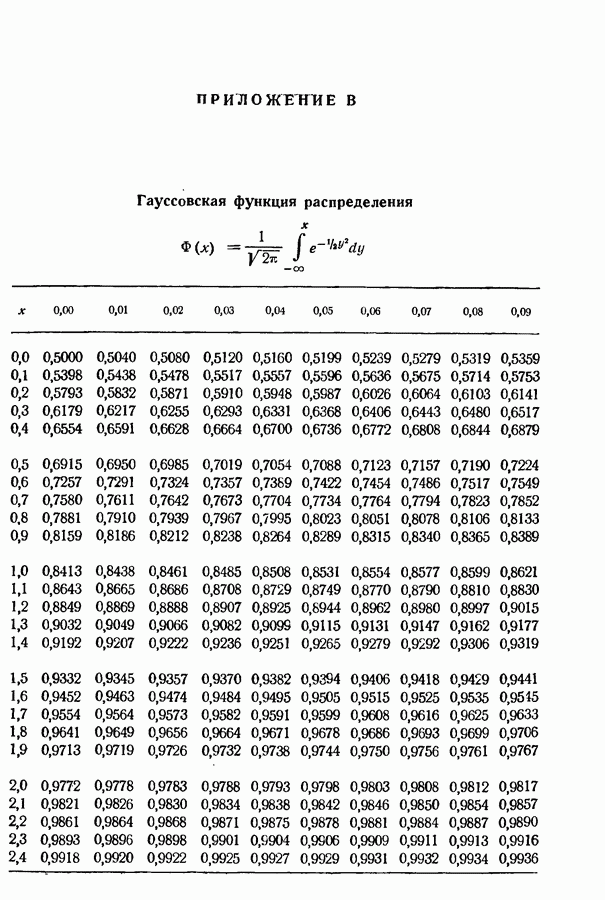
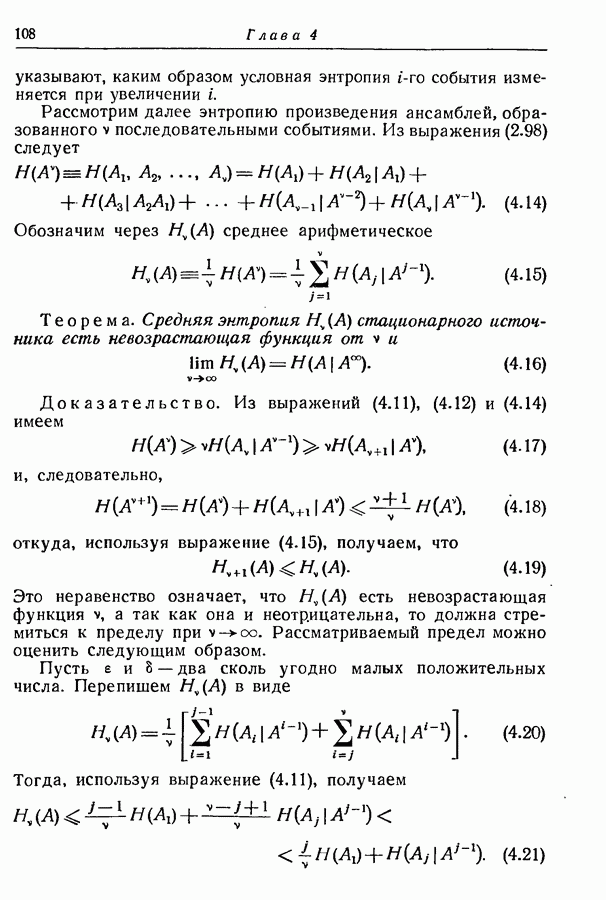9.5. Случайное кодирование для дискретного постоянного канала
В этом разделе мы рассмотрим общие методы вычисления верхней границы вероятности появления ошибки декодирования, когда множество  равновероятных сообщений кодируются в последовательности
равновероятных сообщений кодируются в последовательности  входных событий для передачи по дискретному постоянному каналу. Под верхней границей вероятности ошибки мы понимаем величину
входных событий для передачи по дискретному постоянному каналу. Под верхней границей вероятности ошибки мы понимаем величину  зависящую от целого
зависящую от целого  и скорости передачи
и скорости передачи

такую, что для любых  существует множество
существует множество  входных последовательностей и метод декодирования, для которых вероятность ошибки меньше или равна
входных последовательностей и метод декодирования, для которых вероятность ошибки меньше или равна  Этот метод, известный как «случайное кодирование», является обобщением метода, использованного в разд. 7.3 в связи с исследованием двоичных симметричных каналов. Он основывается на тех же соображениях, которые использовал Шеннон в своем первоначальном доказательстве утверждения, что вероятность ошибки может быть сделана как угодно малой для любого
Этот метод, известный как «случайное кодирование», является обобщением метода, использованного в разд. 7.3 в связи с исследованием двоичных симметричных каналов. Он основывается на тех же соображениях, которые использовал Шеннон в своем первоначальном доказательстве утверждения, что вероятность ошибки может быть сделана как угодно малой для любого  при
при  стремящемся к бесконечности.
стремящемся к бесконечности.
Рассмотрим постоянный канал с входными событиями, представленными точками х дискретного пространства X, и выходными событиями, представленными точками у дискретного пространства  Условное распределение вероятностей
Условное распределение вероятностей  по предположению, не зависит от прошлого передачи. В разд. 6.1 была определена
по предположению, не зависит от прошлого передачи. В разд. 6.1 была определена  степень такого канала, как канал с входным пространством
степень такого канала, как канал с входным пространством  состоящим из всех возможных последовательностей и из
состоящим из всех возможных последовательностей и из  событий, принадлежащих X, и выходным пространством V, состоящим из всех возможных последовательностей из
событий, принадлежащих X, и выходным пространством V, состоящим из всех возможных последовательностей из  событий, принадлежащих
событий, принадлежащих  Как и в разд. 6.1, i-e событие последовательности и обозначим через а
Как и в разд. 6.1, i-e событие последовательности и обозначим через а
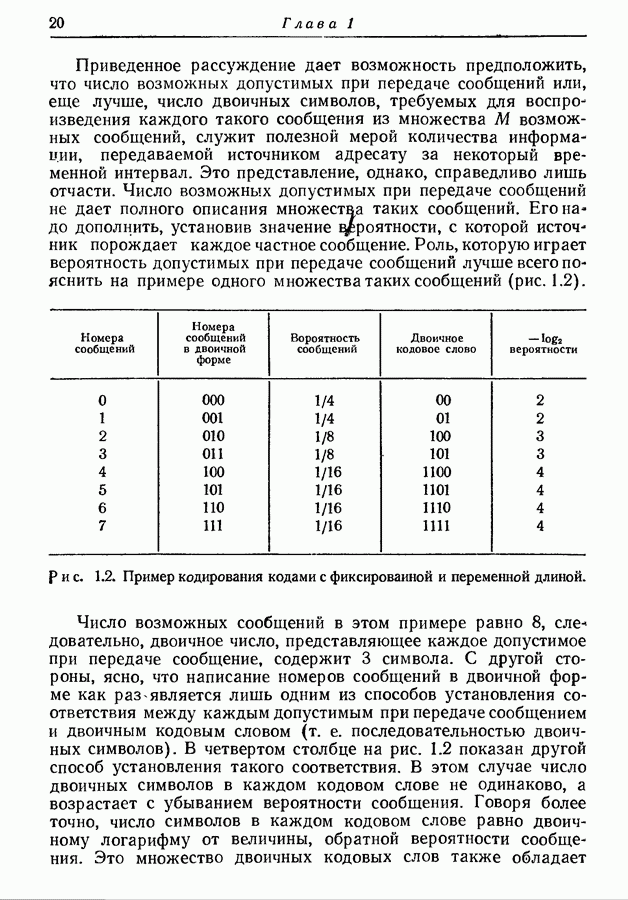
соответствующее выходное событие последовательности  через
через  Таким образом,
Таким образом,

где  может быть любой точкой входного пространства X, а
может быть любой точкой входного пространства X, а  любой точкой выходного пространства
любой точкой выходного пространства 
Так как канал постоянный, то условное распределение вероятностей  для
для  степени канала задается соотношением
степени канала задается соотношением

где

Примем в дальнейшем, что пространство сообщений состоит из  равновероятных сообщений
равновероятных сообщений  Символ
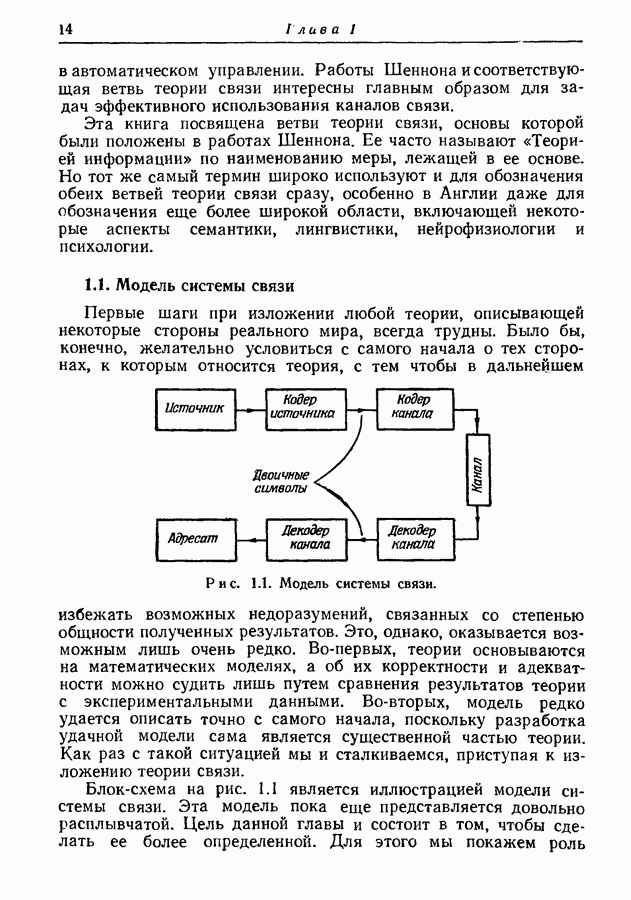
Символ  будет использоваться для обозначения как пространства сообщений, так и числа сообщений в нем. Обращаясь к общему исследованию блокового кодирования (разд. 6.1), и в частности к рис. 6.1, мы видим, что блоковое кодирование может рассматриваться как отображение пространства
будет использоваться для обозначения как пространства сообщений, так и числа сообщений в нем. Обращаясь к общему исследованию блокового кодирования (разд. 6.1), и в частности к рис. 6.1, мы видим, что блоковое кодирование может рассматриваться как отображение пространства  сообщений во входное пространство
сообщений во входное пространство  степени канала. Это отображение, конечно, должно быть выбрано так, чтобы декодер был в состоянии определить переданное сообщение с возможно меньшей вероятностью ошибки. К сожалению, пока еще не найдены никакие общие пути для построения оптимального или хотя бы достаточно хорошего отображения. Однако весьма полезные верхние границы для вероятности ошибки можно получить с помощью вычисления вероятности ошибки, осредненной по ансамблю отображений, образованных случайным сопоставлением входных последовательностей сообщениям. В самом деле, если
степени канала. Это отображение, конечно, должно быть выбрано так, чтобы декодер был в состоянии определить переданное сообщение с возможно меньшей вероятностью ошибки. К сожалению, пока еще не найдены никакие общие пути для построения оптимального или хотя бы достаточно хорошего отображения. Однако весьма полезные верхние границы для вероятности ошибки можно получить с помощью вычисления вероятности ошибки, осредненной по ансамблю отображений, образованных случайным сопоставлением входных последовательностей сообщениям. В самом деле, если  осредненная вероятность ошибки, то должно существовать некоторое отображение с вероятностью ошибки, не превышающей
осредненная вероятность ошибки, то должно существовать некоторое отображение с вероятностью ошибки, не превышающей  Более того, теорема, содержащая неравенство (7.89), устанавливает, что для любого числа
Более того, теорема, содержащая неравенство (7.89), устанавливает, что для любого числа  при случайном сопоставлении входных последовательностей сообщениям с вероятностью, меньшей
при случайном сопоставлении входных последовательностей сообщениям с вероятностью, меньшей  вероятность ошибки будет превосходить
вероятность ошибки будет превосходить 
Пусть  распределение вероятностей на входном пространстве канала
распределение вероятностей на входном пространстве канала  степени. Входные последовательности, сопоставляемые сообщениям, выбираются случайно и независимо с вероятностью
степени. Входные последовательности, сопоставляемые сообщениям, выбираются случайно и независимо с вероятностью  Следовательно, если мы обозначим через
Следовательно, если мы обозначим через  некоторое сообщение и через
некоторое сообщение и через  некоторую входную последовательность, то вероятность того, что для передачи сообщения
некоторую входную последовательность, то вероятность того, что для передачи сообщения  будет использована входная последовательность
будет использована входная последовательность 
равна  независимо от того, какие входные последовательности используются для представления других сообщений. Тогда вероятность во всем ансамбле отображений того, что какая-либо входная последовательность и будет использована для передачи, равна
независимо от того, какие входные последовательности используются для представления других сообщений. Тогда вероятность во всем ансамбле отображений того, что какая-либо входная последовательность и будет использована для передачи, равна  Однако весьма важно заметить, что это верно только для всего ансамбля отображений, но не для какого-либо отдельного отображения. В самом деле, при использовании какого-то определенного отображения
Однако весьма важно заметить, что это верно только для всего ансамбля отображений, но не для какого-либо отдельного отображения. В самом деле, при использовании какого-то определенного отображения  входных последовательностей, сопоставленных сообщениям, передаются с одинаковыми вероятностями, в то время как все другие входные последовательности вообще никогда не передаются.
входных последовательностей, сопоставленных сообщениям, передаются с одинаковыми вероятностями, в то время как все другие входные последовательности вообще никогда не передаются.
Осредненная вероятность ошибки, соответствующая любому такому случайному отображению сообщений во входные последовательности, зависит, конечно, от распределения вероятностей  Оно используется при выборе входных последовательностей, определяющем ансамбль отображений, по которому осредняется вероятность ошибки. Математически простейший класс распределений вероятностей получается, если положить
Оно используется при выборе входных последовательностей, определяющем ансамбль отображений, по которому осредняется вероятность ошибки. Математически простейший класс распределений вероятностей получается, если положить

где

а  - произвольное распределение вероятностей на входном пространстве
- произвольное распределение вероятностей на входном пространстве  Для этого класса распределений
Для этого класса распределений  ансамбль входных последовательностей
ансамбль входных последовательностей  становится произведением
становится произведением  статистически независимых ансамблей
статистически независимых ансамблей  с одинаковыми распределениями вероятностей
с одинаковыми распределениями вероятностей  Это равносильно тому, что входная последовательность, соответствующая каждому сообщению, образуется независимым и случайным с вероятностями
Это равносильно тому, что входная последовательность, соответствующая каждому сообщению, образуется независимым и случайным с вероятностями  выбором ее последовательных событий.
выбором ее последовательных событий.
В разд. 9.7 будет вычислена средняя вероятность ошибки для такого ансамбля отображений.
Указанный класс распределений вероятностей  сопоставляет одну и ту же вероятность всем последовательностям, имеющим одинаковую композицию, т. е. всем последовательностям, отличающимся друг от друга перестановкой образующих их событий. Однако вероятность выбора входной последовательности зависит от ее композиции, и последовательности всех композиций имеют ненулевую вероятность выбора. Другой важный класс ансамблей отображений можно определить, ограничивая входные последовательности, используемые для
сопоставляет одну и ту же вероятность всем последовательностям, имеющим одинаковую композицию, т. е. всем последовательностям, отличающимся друг от друга перестановкой образующих их событий. Однако вероятность выбора входной последовательности зависит от ее композиции, и последовательности всех композиций имеют ненулевую вероятность выбора. Другой важный класс ансамблей отображений можно определить, ограничивая входные последовательности, используемые для
представления сообщений, последовательностями с определенной заданной композицией,  приписывая равные вероятности последовательностям с определенной композицией и нулевую вероятность всем другим последовательностям. Этот тип кодирования будем называть «кодированием с фиксированной композицией». В разд. 9.6 будет вычислена средняя вероятность ошибки для кодирования с фиксированной композицией.
приписывая равные вероятности последовательностям с определенной композицией и нулевую вероятность всем другим последовательностям. Этот тип кодирования будем называть «кодированием с фиксированной композицией». В разд. 9.6 будет вычислена средняя вероятность ошибки для кодирования с фиксированной композицией.
Вычисление средней вероятности ошибки можно описать независимо от использованного распределения вероятности  Мы примем в этой связи, что сигнал на выходе канала декодируется в соответствии с критерием максимума правдоподобия, т. е. что каждая выходная последовательность
Мы примем в этой связи, что сигнал на выходе канала декодируется в соответствии с критерием максимума правдоподобия, т. е. что каждая выходная последовательность  декодируется в сообщение
декодируется в сообщение  максимизирующее условную вероятность
максимизирующее условную вероятность  Так как, по предположению, сообщения равновероятны, то этот критерий декодирования равносилен максимизации апостериорной вероятности
Так как, по предположению, сообщения равновероятны, то этот критерий декодирования равносилен максимизации апостериорной вероятности  что в свою очередь приводит к минимизации вероятности ошибки. Едва ли нужно подчеркивать, что на декодере известно частное отображение, используемое кодером. Другими словами, отображение случайно только в том смысле, что вероятность ошибки усредняется по ансамблю отображений.
что в свою очередь приводит к минимизации вероятности ошибки. Едва ли нужно подчеркивать, что на декодере известно частное отображение, используемое кодером. Другими словами, отображение случайно только в том смысле, что вероятность ошибки усредняется по ансамблю отображений.
Предположим, что передано некоторое сообщение, и обозначим через и соответствующую входную последовательность, а через  полученную выходную последовательность. Согласно приведенному выше критерию декодирования, ошибка может возникнуть только тогда, когда одно из остальных
полученную выходную последовательность. Согласно приведенному выше критерию декодирования, ошибка может возникнуть только тогда, когда одно из остальных  сообщений представляется входной последовательностью и, для которой
сообщений представляется входной последовательностью и, для которой

Пусть, как и в разд. 9.2,  - произвольная положительная функция
- произвольная положительная функция  удовлетворяющая условию
удовлетворяющая условию

и

есть расстояние между  Условие (9.109), выраженное через расстояние, имеет вид
Условие (9.109), выраженное через расстояние, имеет вид

Ясно, что независимо от выбора функции  использованной в определении расстояния, неравенство (9.109) влечет за собой неравенство (9.112), и наоборот,
использованной в определении расстояния, неравенство (9.109) влечет за собой неравенство (9.112), и наоборот,
При вычислении средней вероятности ошибки будем рассматривать произведение ансамблей  состоящее из троек последовательностей
состоящее из троек последовательностей  и характеризуемое совместным распределением вероятностей
и характеризуемое совместным распределением вероятностей

Ансамбль  идентичен ансамблю
идентичен ансамблю  единственное различие между ними состоит в том, что и представляет собой входную последовательность, соответствующую действительно переданному сообщению, в то время как и представляет собой входную последовательность, соответствующую какому-либо другому сообщению. Так как при сопоставлении сообщений входным последовательностям выборка всех последовательностей производится с одним и тем же распределением вероятностей
единственное различие между ними состоит в том, что и представляет собой входную последовательность, соответствующую действительно переданному сообщению, в то время как и представляет собой входную последовательность, соответствующую какому-либо другому сообщению. Так как при сопоставлении сообщений входным последовательностям выборка всех последовательностей производится с одним и тем же распределением вероятностей  то распределение вероятностей
то распределение вероятностей  совпадает с
совпадает с 
Теорема. Пусть  произвольная постоянная. Обозначим через
произвольная постоянная. Обозначим через  множество последовательностей и, удовлетворяющих неравенству (9.112) для некоторой пары
множество последовательностей и, удовлетворяющих неравенству (9.112) для некоторой пары  через
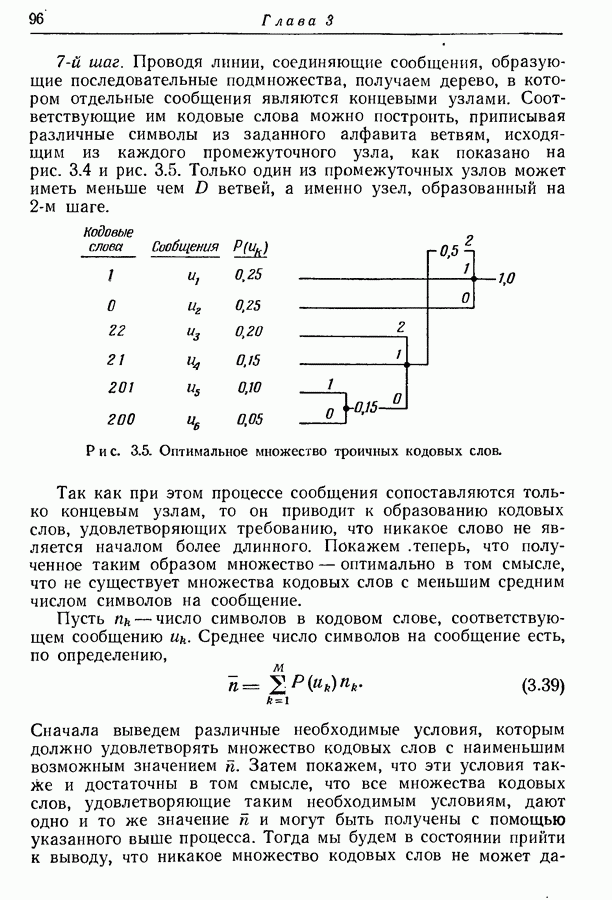
через  множество последовательностей пар
множество последовательностей пар  для которых
для которых  и через
и через  дополнительное множество, на котором
дополнительное множество, на котором  Тогда вероятность ошибки, осредненная по ансамблю отображений, характеризуемому распределением вероятностей
Тогда вероятность ошибки, осредненная по ансамблю отображений, характеризуемому распределением вероятностей  удовлетворяет неравенству
удовлетворяет неравенству

где

Доказательство. Предположим, что было передано некоторое сообщение, представленное входной последовательностью и, и что на выходе канала появляется некоторая последовательность  Вероятность того, что какое-либо другое сообщение представлено последовательностью и, не принадлежащей множеству
Вероятность того, что какое-либо другое сообщение представлено последовательностью и, не принадлежащей множеству  равна
равна

Так как входные последовательности сопоставляются сообщениям независимо и случайно, то вероятность того, что все последовательности и, сопоставляемые остальным  сообщениям, не принадлежат множеству
сообщениям, не принадлежат множеству  представляет собой
представляет собой  степень правой части равенства (9.117). Отсюда следует, что условная средняя вероятность ошибки для данной пары
степень правой части равенства (9.117). Отсюда следует, что условная средняя вероятность ошибки для данной пары  равна
равна

Оставляя только два первых члена в разложении бинома  степени, мы получаем верхнюю границу правой части неравенства (9.118) в виде
степени, мы получаем верхнюю границу правой части неравенства (9.118) в виде

Но правая часть этой формулы возрастает с возрастанием множества  а тем самым и с расстоянием
а тем самым и с расстоянием  и в конечном счете превзойдет единицу. Следовательно, более удобной является верхняя граница
и в конечном счете превзойдет единицу. Следовательно, более удобной является верхняя граница  вида
вида

где  произвольное постоянное, значение которого будет выбрано позднее.
произвольное постоянное, значение которого будет выбрано позднее.
Вероятность ошибки, осредненная по всему ансамблю отображений, получается усреднением  по произведению ансамблей
по произведению ансамблей  т. е.
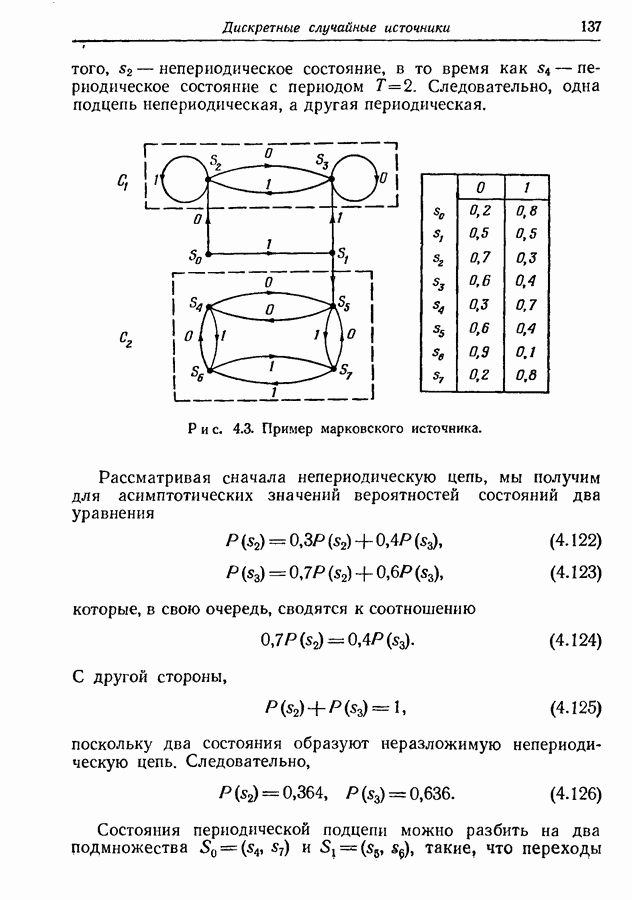
т. е.

Тогда подстановка для  правой части неравенства (9.120) дает выражение (9.114), (9.115) и (9.116). Ч. Т. Д.
правой части неравенства (9.120) дает выражение (9.114), (9.115) и (9.116). Ч. Т. Д.
Для оценки двух вероятностей  задаваемых выражениями (9.115) и (9.116), требуется задание распределения вероятностей
задаваемых выражениями (9.115) и (9.116), требуется задание распределения вероятностей  определяющего ансамбль отображений. В следующем разделе мы оценим эти две вероятности для случая кодирования с фиксированной композицией. В разд. 9.7 будет проведено вычисление
определяющего ансамбль отображений. В следующем разделе мы оценим эти две вероятности для случая кодирования с фиксированной композицией. В разд. 9.7 будет проведено вычисление  для распределения вероятностей
для распределения вероятностей  принадлежащего к классу распределения, определяемому равенствами (9.107) и (9.108).
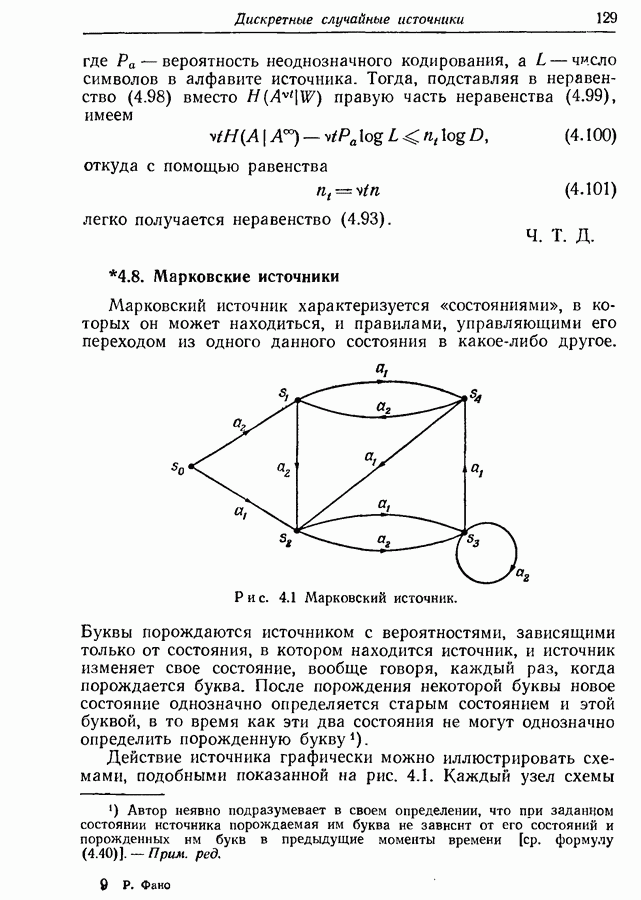
принадлежащего к классу распределения, определяемому равенствами (9.107) и (9.108).