Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
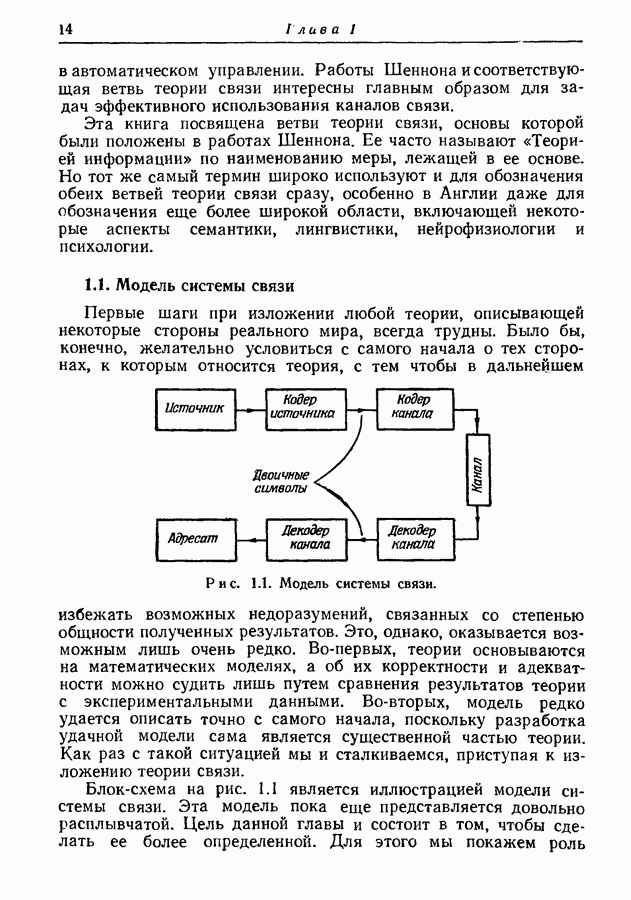
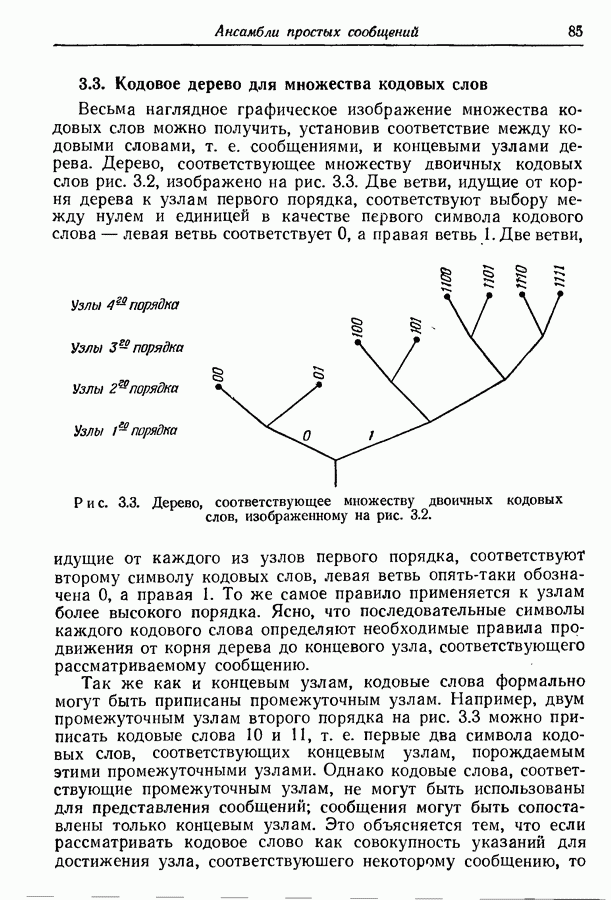
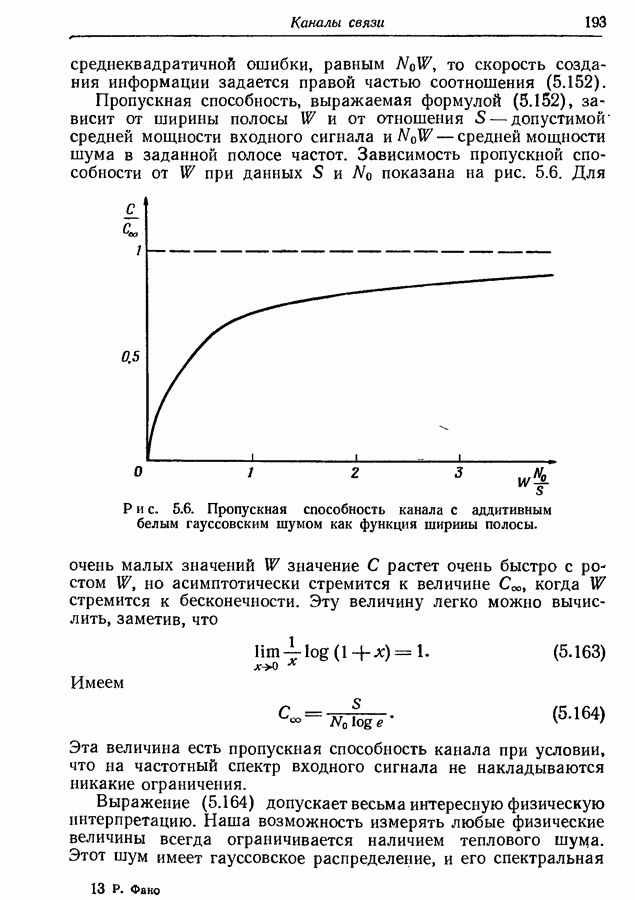
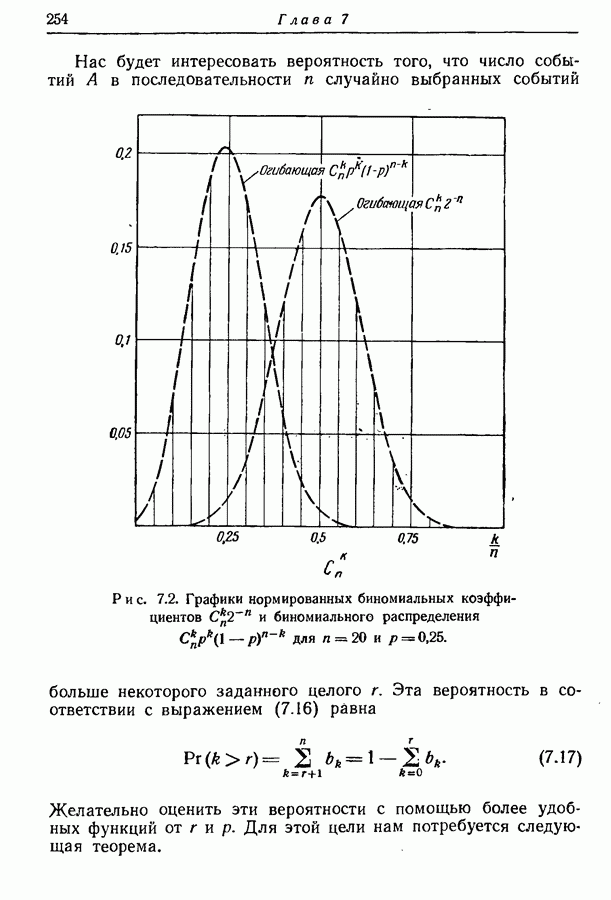
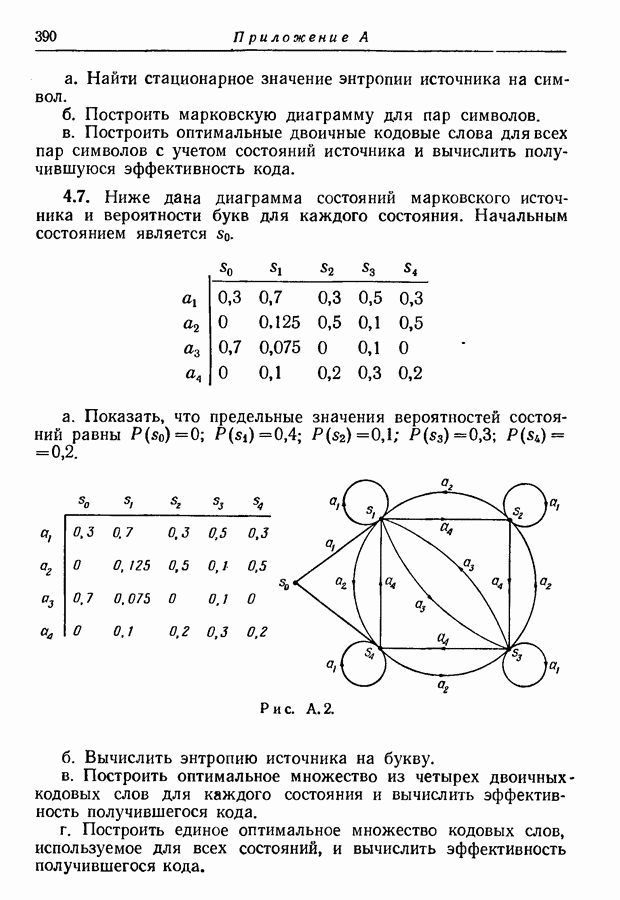
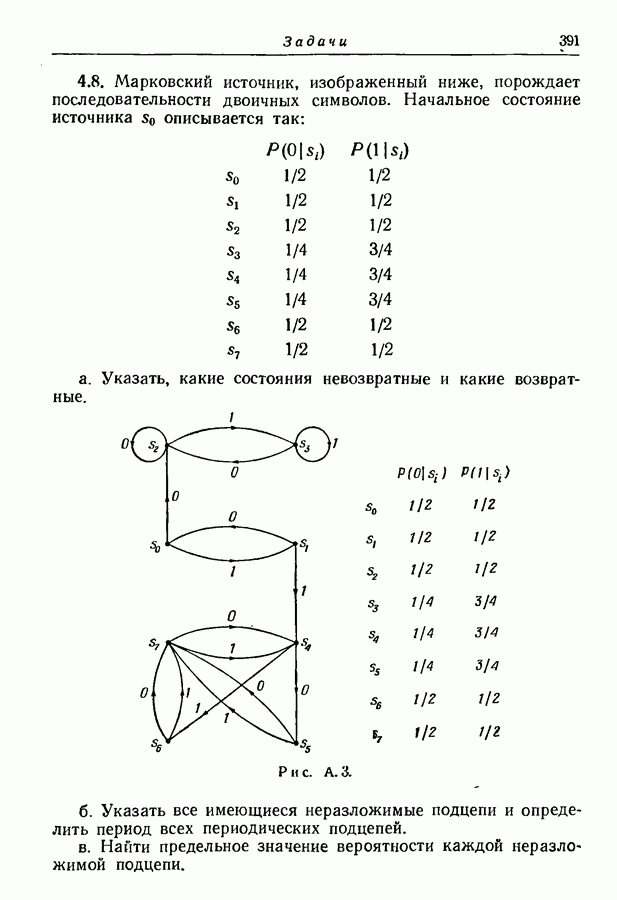
3.7. Метод оптимального кодированияМетод кодирования, рассмотренный в разд. 3.2, приводит обычно к получению довольно хорошего множества кодовых слов, однако не обязательно оптимального. В этом разделе мы изложим систематический метод кодирования, предложенный Этот метод всегда приводит к получению оптимального множества кодовых слов в том смысле, что никакое другое множество не имеет меньшего среднего числа символов на сообщение. Сначала мы опишем этот метод, а затем докажем, что полученное множество кодовых слов является оптимальным. Рассмотрим ансамбль из 1-й шаг. 2-й шаг. Пусть
Заметим, что
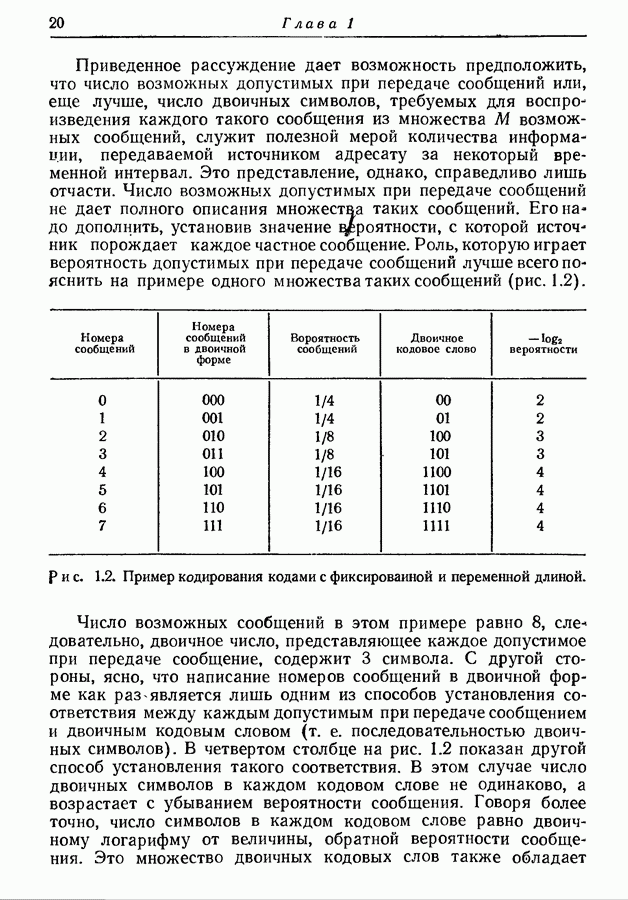
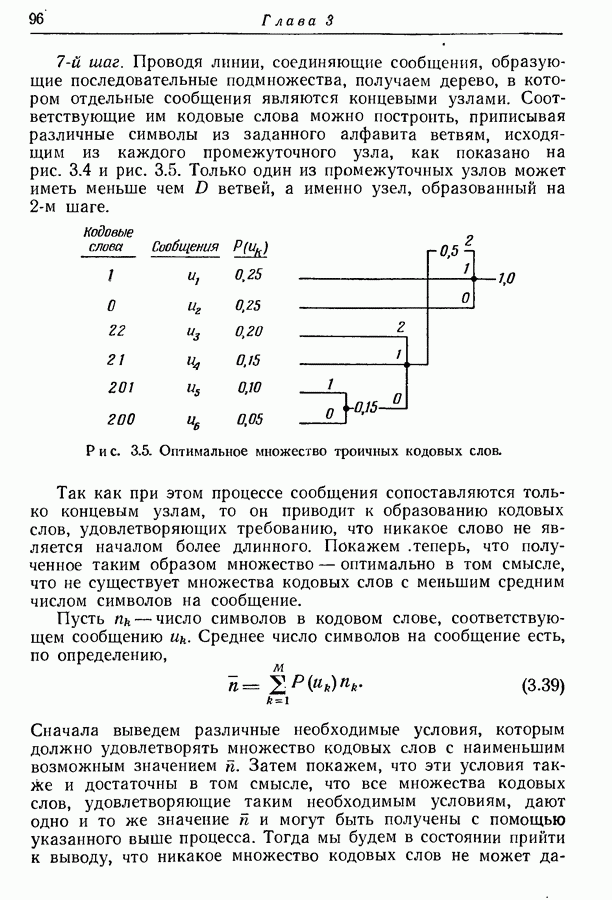
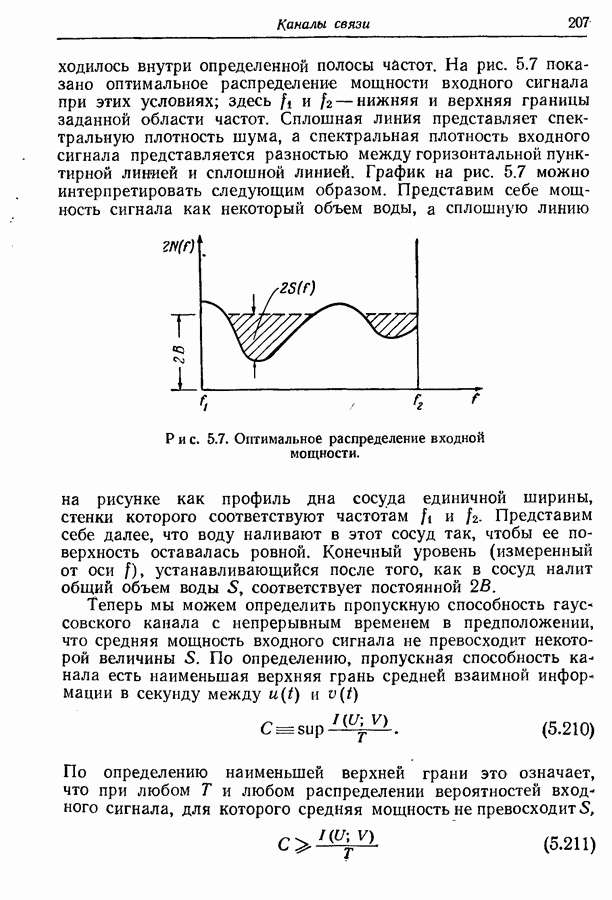
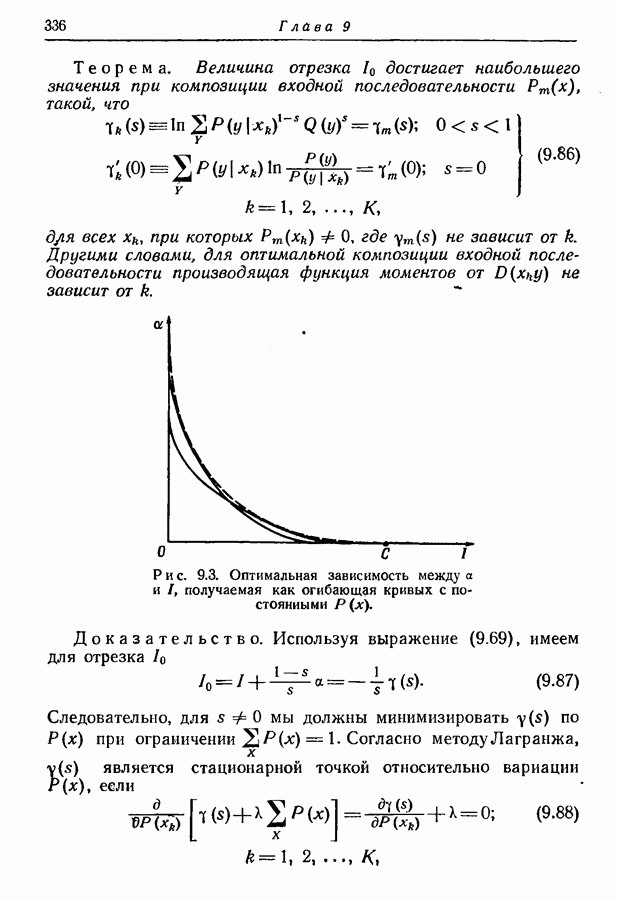
Рис. 3.4. Оптимальное множество двоичных кодовых слов. 3-й шаг. Из первоначального ансамбля образуем вспомогательный ансамбль сообщений, рассматривая подмножество из 4-й шаг. Образуем подмножество из 5-й шаг. Из первого вспомогательного ансамбля образуем второй вспомогательный ансамбль, рассматривая подмножество из 6-й шаг. Образуем последовательные вспомогательные ансамбли путем повторения 4-го и 5-го шагов, пока в ансамбле не останется единственное сообщение с вероятностью единица, как схематически показано на рис. 3.4 и рис. 3.5. 7-й шаг. Проводя линии, соединяющие сообщения, образующие последовательные подмножества, получаем дерево, в котором отдельные сообщения являются концевыми узлами. Соответствующие им кодовые слова можно построить, приписывая различные символы из заданного алфавита ветвям, исходящим из каждого промежуточного узла, как показано на рис. 3.4 и рис. 3.5. Только один из промежуточных узлов может иметь меньше чем
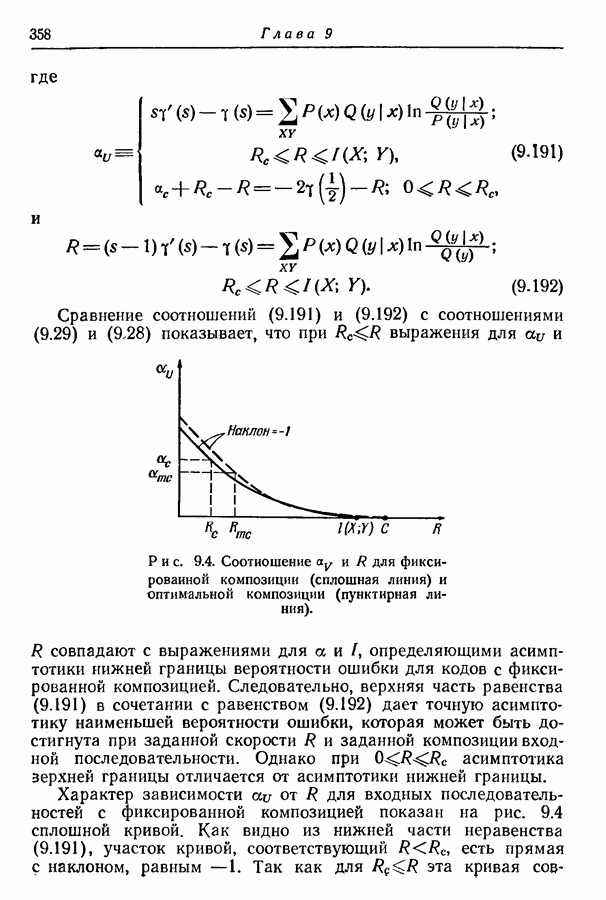
Рис. 3.5. Оптимальное множество троичных кодовых слов. Так как при этом процессе сообщения сопоставляются только концевым узлам, то он приводит к образованию кодовых слов, удовлетворяющих требованию, что никакое слово не является началом более длинного. Покажем теперь, что полученное таким образом множество — оптимально в том смысле, что не существует множества кодовых слов с меньшим средним числом символов на сообщение. Пусть
Сначала выведем различные необходимые условия, которым должно удовлетворять множество кодовых слов с наименьшим возможным значением давать значение, меньшее чем При рассмотрении деталей доказательства, удобно пронумеровать числами от 1 до Условие 1. Сообщениям меньшей вероятности должны быть сопоставлены слова большей длины, т. е. если при некоторых
то, должно быть,
Это условие необходимо, поскольку в противном случае мы можем уменьшить Условие 2. Два наименее вероятных сообщения должны соответствовать кодовым словам одной и той же длины Это условие необходимо, так как если бы только одно наименее вероятное сообщение соответствовало концевому узлу порядка Условие 3. Число
Это условие должно удовлетворяться, так как в противном случае по крайней мере один из промежуточных узлов порядка промежуточный узел порядка
концевых узлов порядка Условие 4. Из каждого промежуточного узла порядка меньшего, чем Это условие должно удовлетворяться, так как в противном случае можно построить добавочные концевые узлы порядка, меньшего чем Условие 5. Предположим, что некоторый промежуточный узел преобразован в концевой, т. е. исключены все порождаемые им ветви и узлы. Сопоставим этому узлу составное сообщение, имеющее вероятность, равную сумме вероятностей сообщений, сопоставленных исключенным концевым узлам. Тогда, если первоначальное дерево было оптимальным для исходного ансамбля сообщений, новое дерево должно быть оптимальным для нового ансамбля сообщений. Это условие должно быть удовлетворено, так как в противном случае мы могли бы уменьшить среднее число символов на сообщение для исходного ансамбля, оптимизируя дерево нового кодового ансамбля, а затем снова подсоединяя к концевому узлу, соответствующему составному сообщению, исключенную часть дерева. Покажем теперь, что для любого ансамбля сообщений все множества кодовых слов, удовлетворяющие приведенным выше условиям, дают одно и то же среднее число символов на сообщение и что по крайней мере одно из таких множеств можно получить с помощью описанного метода кодирования. Заметим прежде всего, что для наших целей условия 3 и 4 можно заменить следующим более жестким условием. Вспомогательное условие 6. Каждый промежуточный узел порядка, меньшего Исключением является лишь один узел порядка Очевидно, что это условие включает в себя условия 3 и 4, но оно жестче условия 3. С другой стороны, для заданного ансамбля сообщений множества кодовых слов, не удовлетворяющие этому более жесткому условию, но удовлетворяющие условиям 3 и 4, обеспечивают то же самое среднее число символов на сообщение, что и множества, удовлетворяющие более жесткому условию. В самом деле, эти множества различаются только тем, как сопоставлены сообщения доступным узлам порядка Продолжим исследование, рассматривая сначала случай Теперь становится ясным, что условия 1, 2 и 5 совместно с вспомогательным условием 6 требуют, чтобы вышеприведенный процесс повторялся до тех пор, пока вспомогательный ансамбль не будет состоять из единственного сообщения и что этот процесс при этого раздела. Приведенные условия однозначно определяют этот процесс, за исключением тех случаев, когда в исходном ансамбле или в любом из вспомогательных ансамблей содержатся равновероятные сообщения. В этих случаях могут быть более чем два сообщения, которые могут рассматриваться как наименее вероятные. С другой стороны, использование различных пар таких сообщений в качестве наименее вероятных эквивалентно перестановке кодовых слов, соответствующих равновероятным сообщениям или перестановке начал групп кодовых слов, имеющих одну и ту же общую вероятность. Ясно, что такие перестановки не изменяют среднего числа символов на сообщение. Следовательно, для любого заданного ансамбля сообщений все деревья или все множества кодовых слов, которые удовлетворяют приведенным выше необходимым условиям, имеют одно и то же среднее число символов на сообщение, что и множества, построенные по описанному выше процессу. Отсюда мы можем заключить, что для В случае
где
что эквивалентно равенству (3.38). Когда целое число Мы снова приходим к выводу, что приведенные условия определяют итеративный процесс кодирования однозначно, за исключением возможных перестановок кодовых слов между равновероятными сообщениями и перестановок начал слов между равновероятными группами сообщений. Такие перестановки не оказывают влияния на среднее число символов на сообщение. Следовательно, для любого ансамбля сообщений и любого алфавита все множества кодовых слов, удовлетворяющих условиям 1, 2, 3, 4 и 5, имеют одно и то же среднее число символов на сообщение. По крайней мере одно из таких множеств можно получить, следуя процессу, описанному выше. Поэтому мы приходим к выводу, что этот метод кодирования является оптимальным для всех ансамблей сообщений и всех алфавитов.
|
 |
Оглавление
|























































































































































































































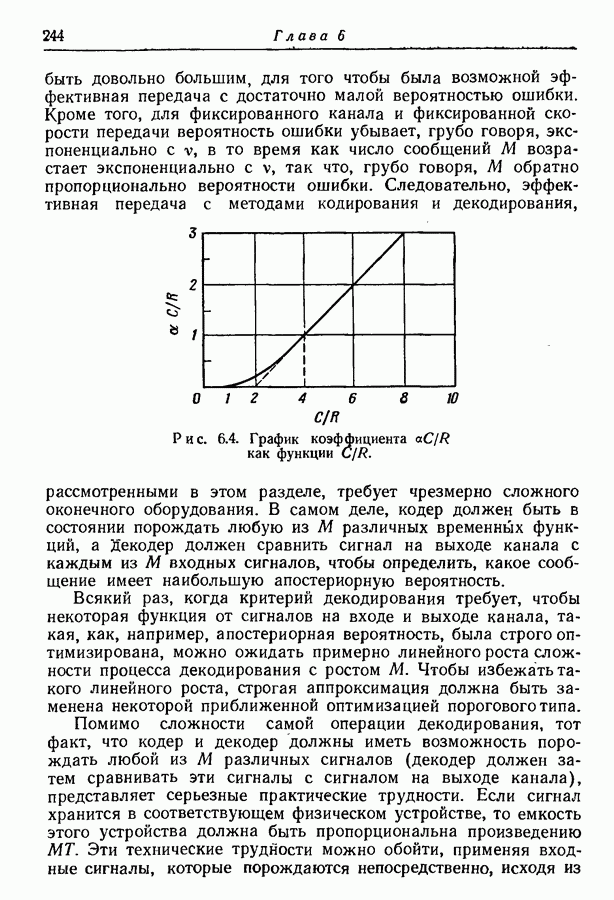





















































































































































 Хафманом [3].
Хафманом [3].
 сообщений
сообщений  им, появляющихся с вероятностями
им, появляющихся с вероятностями  и алфавит, состоящий из
и алфавит, состоящий из  символов. Следующий метод приводит к получению оптимального множества кодовых слов.
символов. Следующий метод приводит к получению оптимального множества кодовых слов.
 сообщений располагаются в порядке убывания вероятностей, как показано на рис. 3.4 и рис. 3.5.
сообщений располагаются в порядке убывания вероятностей, как показано на рис. 3.4 и рис. 3.5.
 целое число, удовлетворяющее двум требованиям
целое число, удовлетворяющее двум требованиям

 когда
когда  Группируем вместе
Группируем вместе  сообщений, имеющих наименьшие вероятности, и вычисляем общую вероятность такого подмножества сообщений.
сообщений, имеющих наименьшие вероятности, и вычисляем общую вероятность такого подмножества сообщений.

 сообщений, образованных на
сообщений, образованных на  шаге, как отдельное сообщение с вероятностью, равной вероятности всего подмножества. Вновь располагаем сообщения этого вспомогательного ансамбля в порядке убывания вероятностей, как показано на рис. 3.4 и рис. 3.5.
шаге, как отдельное сообщение с вероятностью, равной вероятности всего подмножества. Вновь располагаем сообщения этого вспомогательного ансамбля в порядке убывания вероятностей, как показано на рис. 3.4 и рис. 3.5.
 сообщений вспомогательного ансамбля, имеющих наименьшие вероятности, и вычисляем их общую вероятность.
сообщений вспомогательного ансамбля, имеющих наименьшие вероятности, и вычисляем их общую вероятность.
 сообщений, образованное на четвертом шаге, как отдельное сообщение с вероятностью, равной общей вероятности всего подмножества. Располагаем сообщения этого второго вспомогательного ансамбля в порядке убывания вероятностей.
сообщений, образованное на четвертом шаге, как отдельное сообщение с вероятностью, равной общей вероятности всего подмножества. Располагаем сообщения этого второго вспомогательного ансамбля в порядке убывания вероятностей.
 ветвей, а именно узел, образованный на
ветвей, а именно узел, образованный на  шаге.
шаге.

 число символов в кодовом слове, соответствующем сообщению
число символов в кодовом слове, соответствующем сообщению  Среднее число символов на сообщение есть, по определению,
Среднее число символов на сообщение есть, по определению,

 Затем покажем, что эти условия также и достаточны в том смысле, что все множества кодовых слов, удовлетворяющие таким необходимым условиям, дают одно и то же значение
Затем покажем, что эти условия также и достаточны в том смысле, что все множества кодовых слов, удовлетворяющие таким необходимым условиям, дают одно и то же значение  и могут быть получены с помощью указанного выше процесса. Тогда мы будем в состоянии прийти к выводу, что никакое множество кодовых слов не может
и могут быть получены с помощью указанного выше процесса. Тогда мы будем в состоянии прийти к выводу, что никакое множество кодовых слов не может
 и тем самым завершим доказательство.
и тем самым завершим доказательство.
 сообщения, расположенные в порядке убывания вероятностей, так что, например,
сообщения, расположенные в порядке убывания вероятностей, так что, например,  наиболее вероятное сообщение, а им — наименее вероятное сообщение. Кроме того, мы будем называть последовательность, образованную первыми
наиболее вероятное сообщение, а им — наименее вероятное сообщение. Кроме того, мы будем называть последовательность, образованную первыми  символами кодового слова,
символами кодового слова,  префиксом» слова.
префиксом» слова.



 меняя местами кодовые слова, соответствующие сообщениям
меняя местами кодовые слова, соответствующие сообщениям 
 (максимальная длина), т. е. узлам одного и того же порядка.
(максимальная длина), т. е. узлам одного и того же порядка.
 то имелся бы промежуточный узел меньшего порядка с единственной исходящей из него ветвью, а именно с ветвью, ведущей к единственному узлу порядка
то имелся бы промежуточный узел меньшего порядка с единственной исходящей из него ветвью, а именно с ветвью, ведущей к единственному узлу порядка  Тогда этот промежуточный узел можно было бы сделать концевым узлом и приписать ему наименее вероятное сообщение, тем самым уменьшая длину соответствующего кодового слова. Другими словами, если бы имелось единственное кодовое слово длины
Тогда этот промежуточный узел можно было бы сделать концевым узлом и приписать ему наименее вероятное сообщение, тем самым уменьшая длину соответствующего кодового слова. Другими словами, если бы имелось единственное кодовое слово длины  то последний символ в таком кодовом слове был бы бесполезен и его можно было бы отбросить.
то последний символ в таком кодовом слове был бы бесполезен и его можно было бы отбросить.
 концевых узлов порядка
концевых узлов порядка  сопоставленных сообщениям, и число
сопоставленных сообщениям, и число  промежуточных узлов порядка
промежуточных узлов порядка  должны удовлетворять неравенству
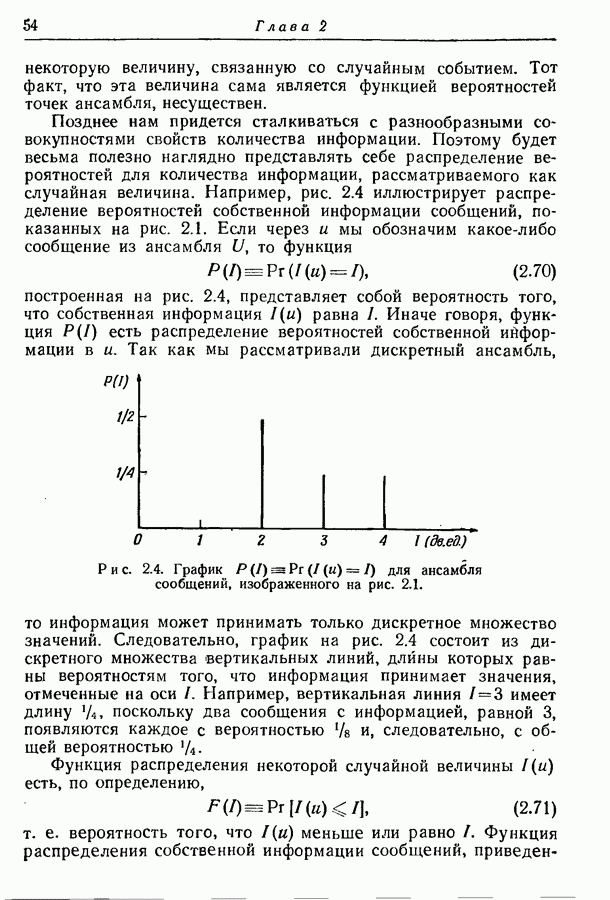
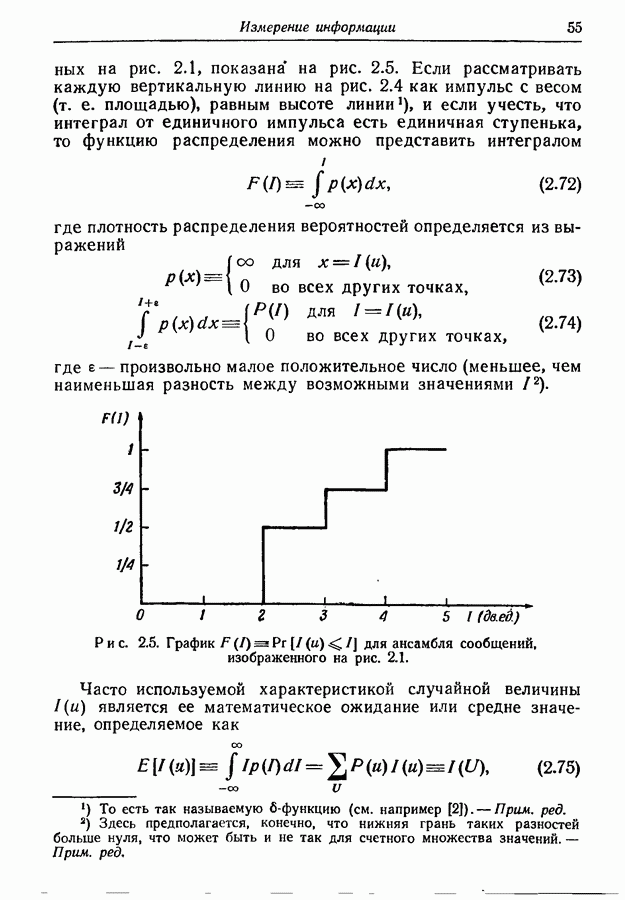
должны удовлетворять неравенству

 мог бы быть заменен на концевой узел и мы бы могли сопоставить ему одно из сообщений, ранее сопоставленных узлу порядка
мог бы быть заменен на концевой узел и мы бы могли сопоставить ему одно из сообщений, ранее сопоставленных узлу порядка  тем самым уменьшая длину соответствующего кодового слова. Иными словами, поскольку каждый
тем самым уменьшая длину соответствующего кодового слова. Иными словами, поскольку каждый
 может породить
может породить  узлов порядка
узлов порядка  число доступных узлов порядка
число доступных узлов порядка  не должно превышать числа сопоставленных им сообщений более чем на
не должно превышать числа сопоставленных им сообщений более чем на  этой связи следует заметить, что если
этой связи следует заметить, что если  не кратно
не кратно  то имеется много способов, с помощью которых сообщения могут быть приписаны доступным узлам. Все они будут эквивалентны в том смысле, что дают одно и то же значение
то имеется много способов, с помощью которых сообщения могут быть приписаны доступным узлам. Все они будут эквивалентны в том смысле, что дают одно и то же значение  среднее число символов на сообщение. Поэтому во всех случаях существует оптимальное множество кодовых слов, в котором
среднее число символов на сообщение. Поэтому во всех случаях существует оптимальное множество кодовых слов, в котором  концевых узлов порядка
концевых узлов порядка  порождается каждым из
порождается каждым из  промежуточных узлов порядка
промежуточных узлов порядка  и
и

 порождается остающимся промежуточным узлом порядка
порождается остающимся промежуточным узлом порядка 
 должно исходить
должно исходить  ветвей.
ветвей.
 и поставить им в соответствие сообщения, ранее уже сопоставленные узлам порядка
и поставить им в соответствие сообщения, ранее уже сопоставленные узлам порядка  тем самым уменьшая длины соответствующих кодовых слов.
тем самым уменьшая длины соответствующих кодовых слов.
 должен порождать
должен порождать  ветвей.
ветвей.
 порождающий
порождающий  ветвей, с
ветвей, с  определяемым соотношениями (3.37) и (3.38).
определяемым соотношениями (3.37) и (3.38).
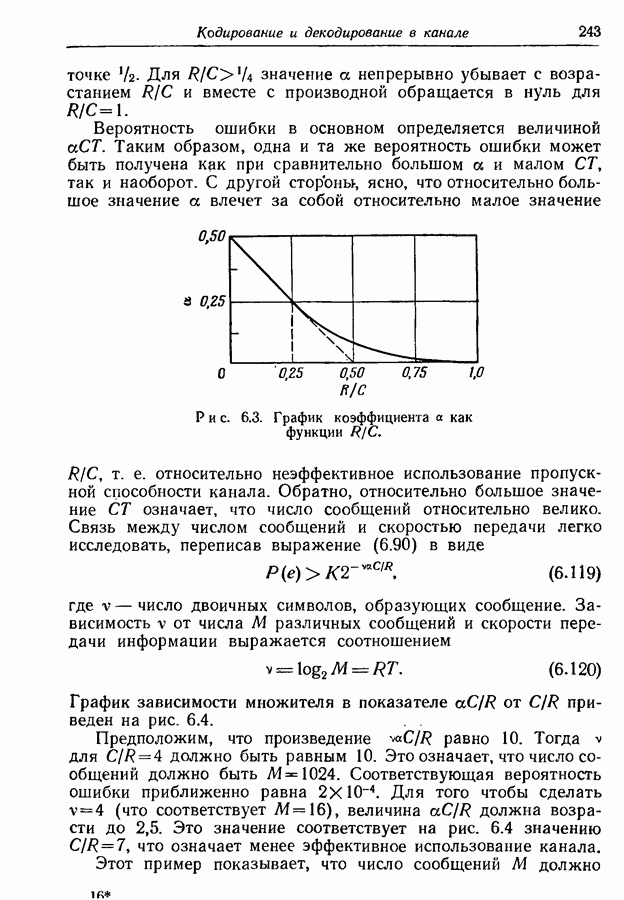
 (что ясно из проведенного выше обсуждения условия 3). Другими словами, хотя это более жесткое условие не является необходимым, можно быть уверенным, что существует по крайней мере одно удовлетворяющее ему оптимальное множество кодовых слов.
(что ясно из проведенного выше обсуждения условия 3). Другими словами, хотя это более жесткое условие не является необходимым, можно быть уверенным, что существует по крайней мере одно удовлетворяющее ему оптимальное множество кодовых слов.
 В этом случае условия 1 и 2 совместно с вспомогательным условием 6 требуют, чтобы два наименее вероятных сообщения, т. е. им и
В этом случае условия 1 и 2 совместно с вспомогательным условием 6 требуют, чтобы два наименее вероятных сообщения, т. е. им и  были сопоставлены концевым узлам одинакового порядка
были сопоставлены концевым узлам одинакового порядка  порождаемым одним и тем же промежуточным узлом порядка
порождаемым одним и тем же промежуточным узлом порядка  Это означает, другими словами, что соответствующие кодовые слова должны иметь одинаковые длины и должны всюду совпадать, кроме последней цифры. Общее начало этих двух кодовых слов, имеющее длину
Это означает, другими словами, что соответствующие кодовые слова должны иметь одинаковые длины и должны всюду совпадать, кроме последней цифры. Общее начало этих двух кодовых слов, имеющее длину  и соответствующий промежуточный узел порядка
и соответствующий промежуточный узел порядка  может рассматриваться как соответствующие «комбинированному сообщению», вероятность которого равна
может рассматриваться как соответствующие «комбинированному сообщению», вероятность которого равна  Тогда, если мы образуем вспомогательный ансамбль путем замены сообщений им и
Тогда, если мы образуем вспомогательный ансамбль путем замены сообщений им и  этим комбинированным сообщением, то, как мы знаем из условия 5, дерево (или множество кодовых слов), соответствующее этому новому ансамблю, должно быть оптимальным, ибо только в этом случае полное дерево будет оптимальным. Отсюда следует, что два наименее вероятных сообщения этого вспомогательного ансамбля должны быть снова сопоставлены концевым узлам одинакового порядка, порождаемым одним и тем же промежуточным узлом следующего более низкого порядка. Затем образуется второй вспомогательный ансамбль путем объединения второй пары сообщений во второе комбинированное сообщение.
этим комбинированным сообщением, то, как мы знаем из условия 5, дерево (или множество кодовых слов), соответствующее этому новому ансамблю, должно быть оптимальным, ибо только в этом случае полное дерево будет оптимальным. Отсюда следует, что два наименее вероятных сообщения этого вспомогательного ансамбля должны быть снова сопоставлены концевым узлам одинакового порядка, порождаемым одним и тем же промежуточным узлом следующего более низкого порядка. Затем образуется второй вспомогательный ансамбль путем объединения второй пары сообщений во второе комбинированное сообщение.
 идентичен процессу, описанному вначале
идентичен процессу, описанному вначале
 этот процесс приводит к оптимальному множеству кодовых слов.
этот процесс приводит к оптимальному множеству кодовых слов.
 условия 1, 2 и вспомогательное условие 6 требуют, чтобы
условия 1, 2 и вспомогательное условие 6 требуют, чтобы  наименее вероятных сообщений было бы приписано концевым узлам порядка
наименее вероятных сообщений было бы приписано концевым узлам порядка  порождаемым одним и тем же промежуточным узлом порядка
порождаемым одним и тем же промежуточным узлом порядка  и чтобы
и чтобы  удовлетворяло соотношениям (3.37) и (3.38). Таким образом, соответствующие
удовлетворяло соотношениям (3.37) и (3.38). Таким образом, соответствующие  кодовых слов должны совпадать всюду, кроме последнего символа. Далее, условие 5 требует, чтобы первый вспомогательный ансамбль (образованный объединением этих
кодовых слов должны совпадать всюду, кроме последнего символа. Далее, условие 5 требует, чтобы первый вспомогательный ансамбль (образованный объединением этих  сообщений в одно комбинированное сообщение с вероятностью, равной сумме вероятностей компонент) кодировался оптимальным образом. В свою очередь вспомогательное условие 6 требует, чтобы
сообщений в одно комбинированное сообщение с вероятностью, равной сумме вероятностей компонент) кодировался оптимальным образом. В свою очередь вспомогательное условие 6 требует, чтобы  наименее вероятных сообщений этого вспомогательного ансамбля были бы сопоставлены узлам, порождаемым одним и тем же промежуточным узлом следующего более низкого порядка. Это вытекает из того факта, что в законченном дереве только один промежуточный узел может иметь меньше чем
наименее вероятных сообщений этого вспомогательного ансамбля были бы сопоставлены узлам, порождаемым одним и тем же промежуточным узлом следующего более низкого порядка. Это вытекает из того факта, что в законченном дереве только один промежуточный узел может иметь меньше чем  ветвей. Такое же требование накладывается на все последующие вспомогательные ансамбли. Тогда, поскольку число сообщений должно убывать на
ветвей. Такое же требование накладывается на все последующие вспомогательные ансамбли. Тогда, поскольку число сообщений должно убывать на  каждый раз, когда образуется новый вспомогательный ансамбль и поскольку последний вспомогательный ансамбль должен содержать единственное составное сообщение, то число
каждый раз, когда образуется новый вспомогательный ансамбль и поскольку последний вспомогательный ансамбль должен содержать единственное составное сообщение, то число  должно удовлетворять соотношению
должно удовлетворять соотношению

 целое неотрицательное число. Решая его относительно
целое неотрицательное число. Решая его относительно  получаем
получаем

 равно
равно  то, как показано в разд. 3.4, получающееся множество концевых узлов является полным.
то, как показано в разд. 3.4, получающееся множество концевых узлов является полным.