Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
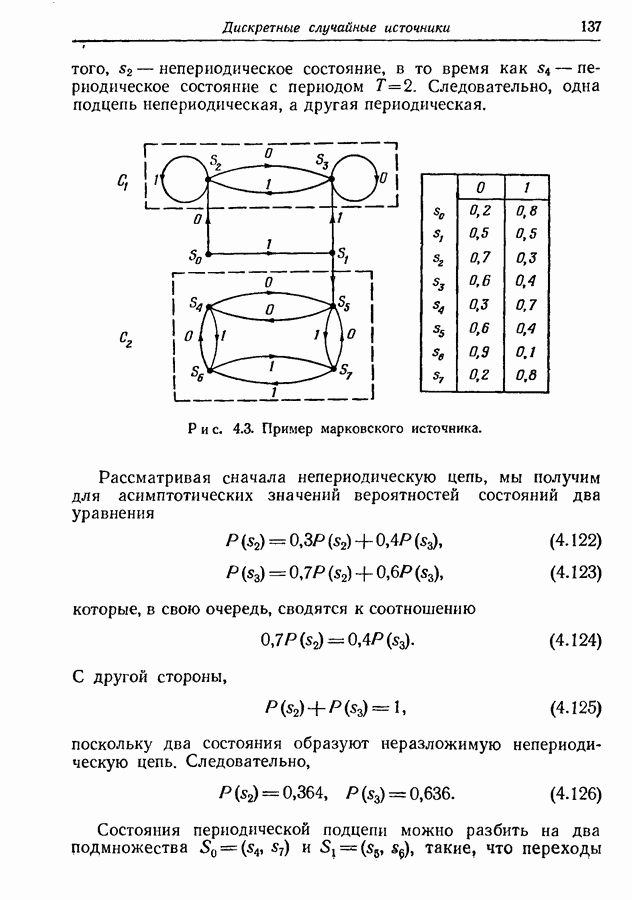
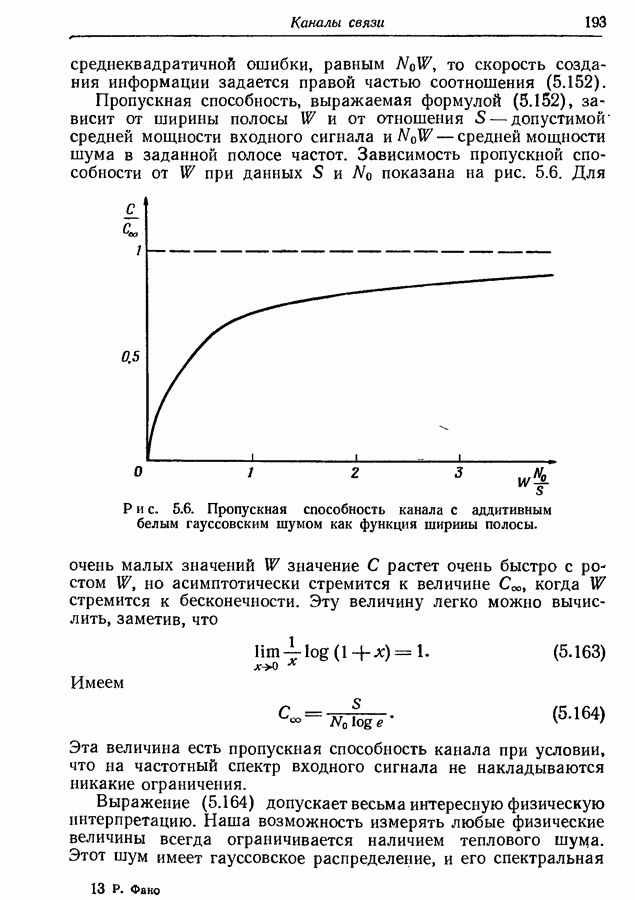
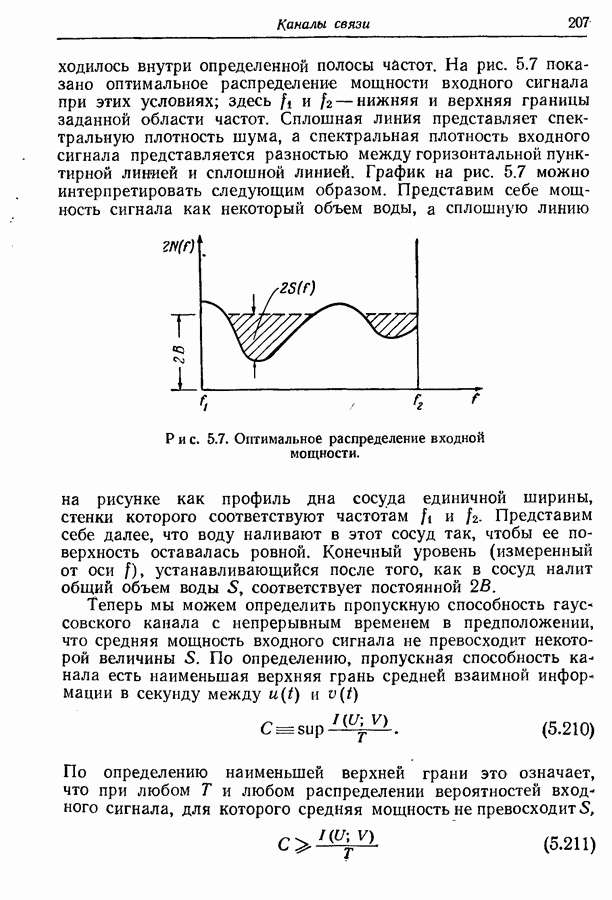
4.12. Кодирование марковских источников с управляемой скоростьюВернемся теперь к проблеме эффективного кодирования последовательностей букв, порождаемых марковскими источниками с управляемой скоростью. Мы ограничим обсуждение непериодическими источниками из-за их большей практической значимости и более простого асимптотического поведения. Если отождествить алфавит А с множеством сообщений состоит в том, что вероятности букв
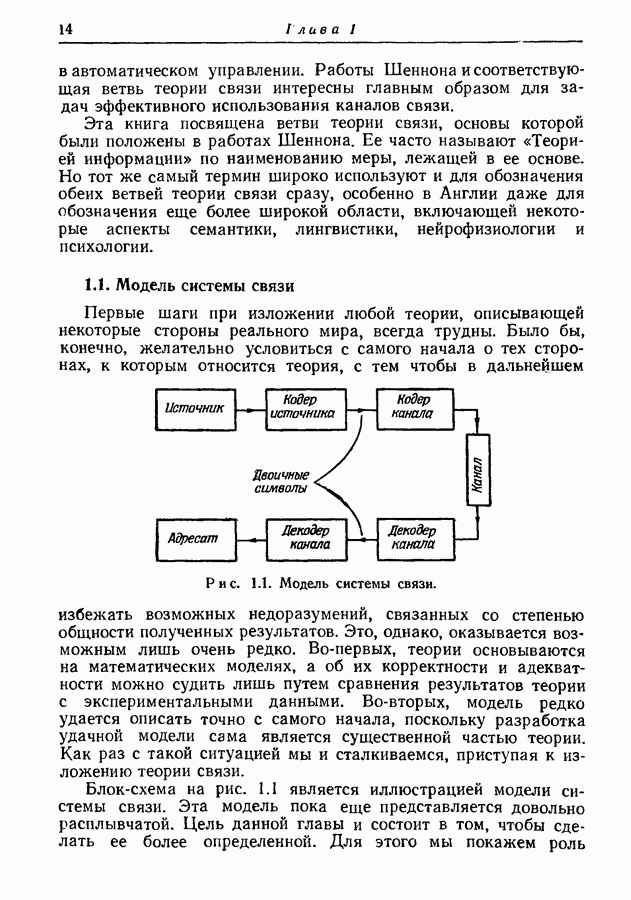
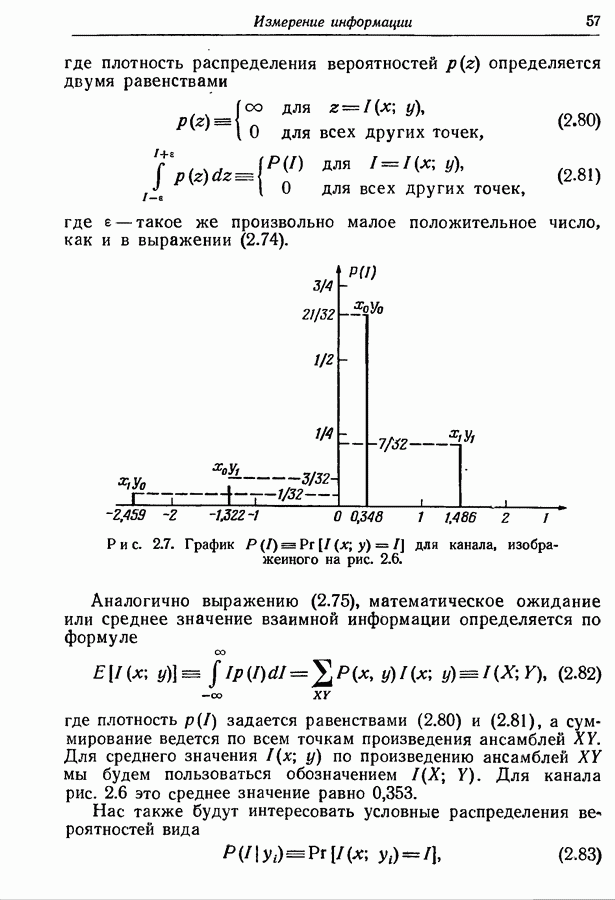
Рис. 4.4. Марковский источник. Если предположить, что источник начинает действовать всякий раз из одного и того же состояния, то последовательность принимаемых им состояний будет однозначно определяться буквами на его выходе. Следовательно, никогда не возникнет неоднозначность в отношении множества кодовых слов, используемых в любой заданный момент времени. Рассмотрим в качестве примера марковский источник, изображенный на рис. 4.4, где
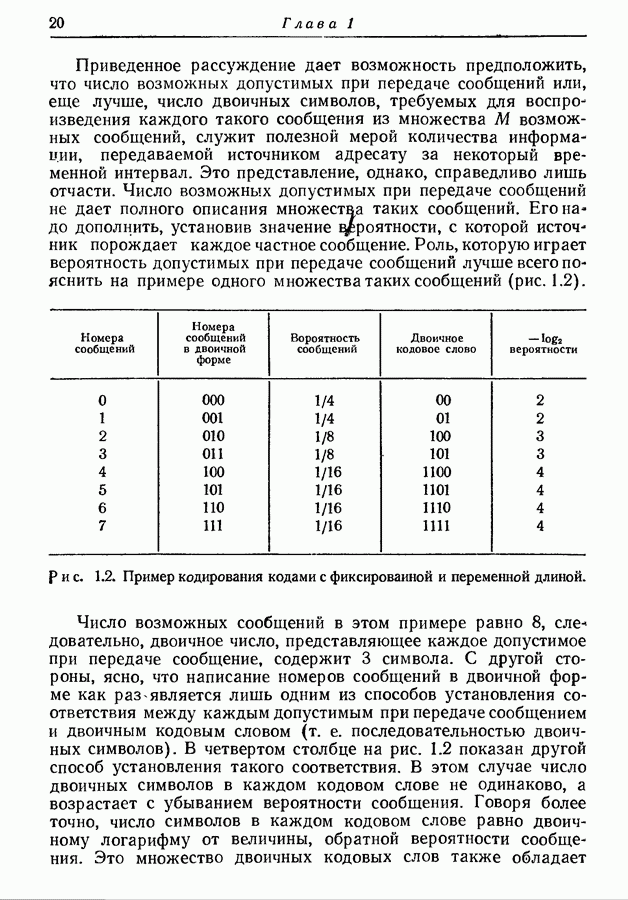
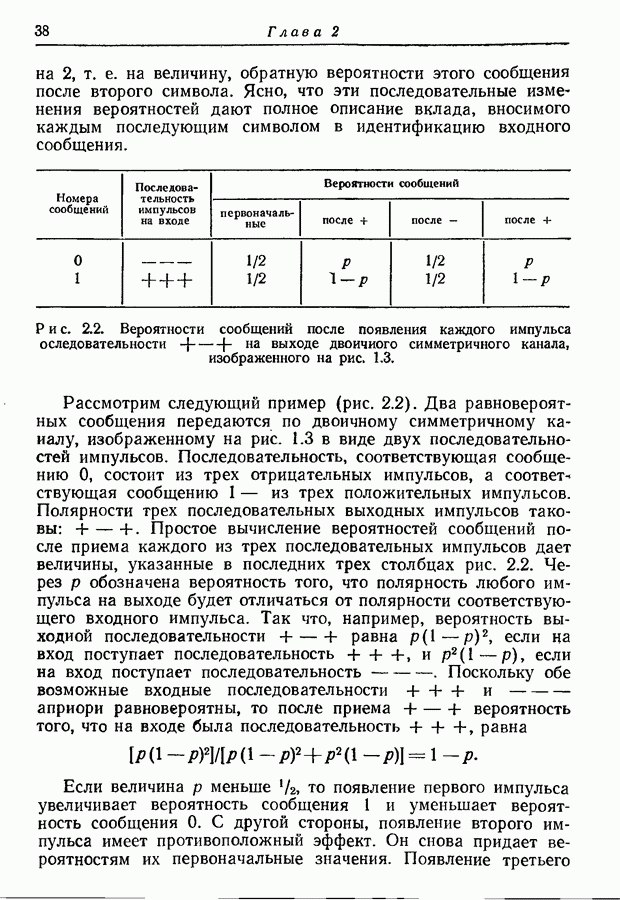
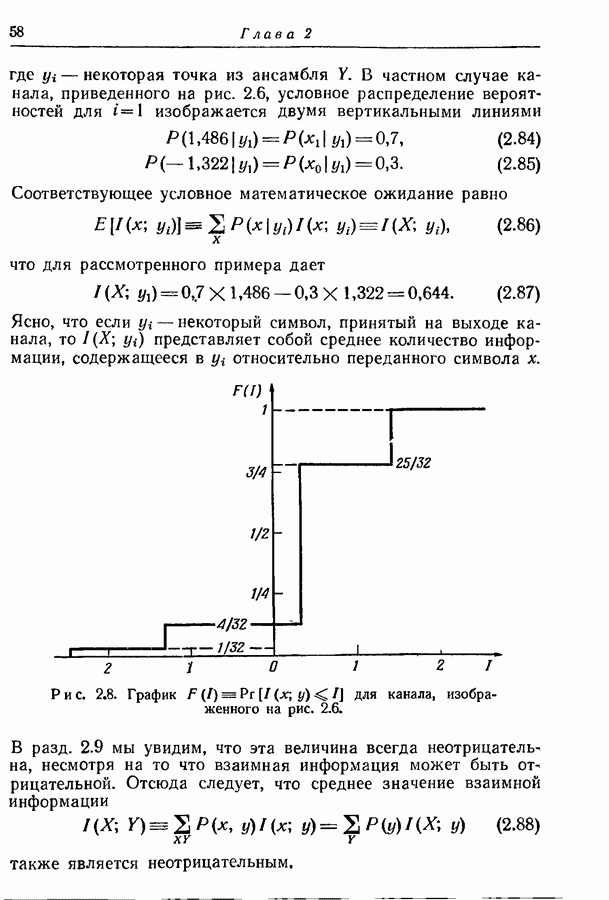
Рис. 4.5. Двоичные кодовые слова для состояний источника, изображенного на рис. 4.4. Найденное распределение вероятностей состояний будет
Используя эти величины, мы можем вычислить общую среднюю длину Двоичного кодового слова и асимптотическое значение энтропии на букву. Если определить эффективность кода как отношение второй из этих величин к первой, то для рассматриваемого множества кодовых слов она окажется равной 0,978. Общие границы для средней длины кодовых слов можно легко получить из результатов разд. 3.5. Пусть
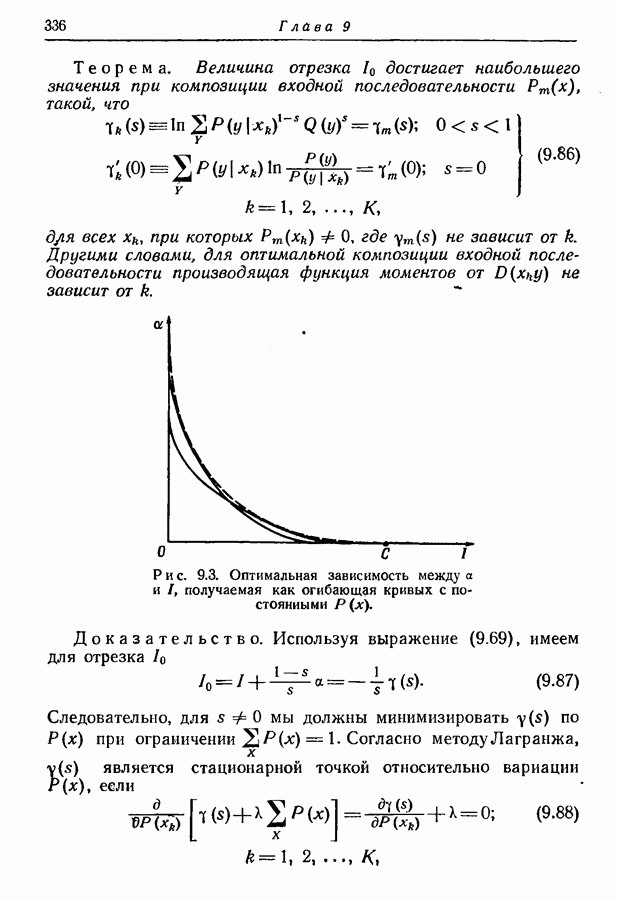
Таким образом, асимптотическое среднее значение длины кодовых слов
удовлетворяет неравенству
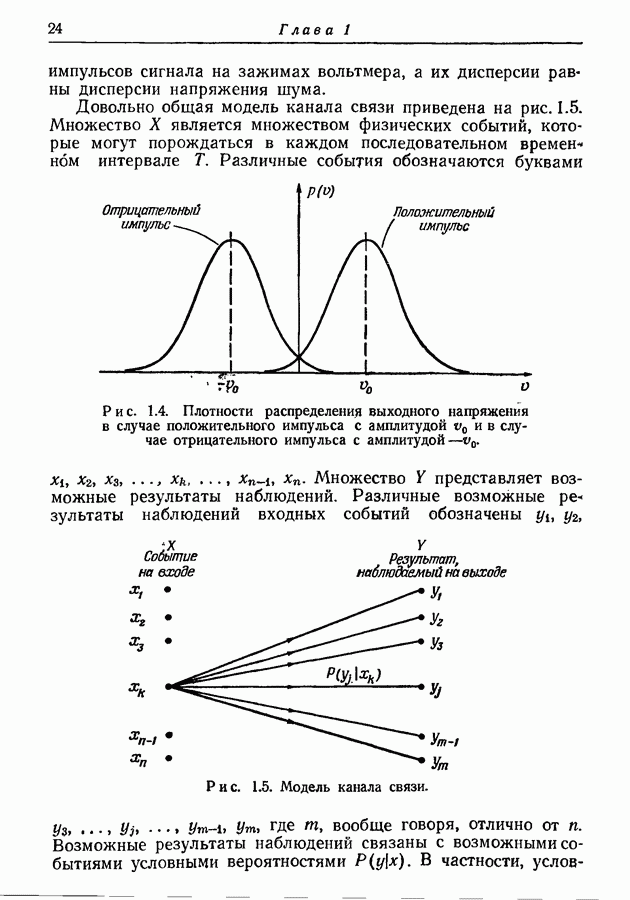
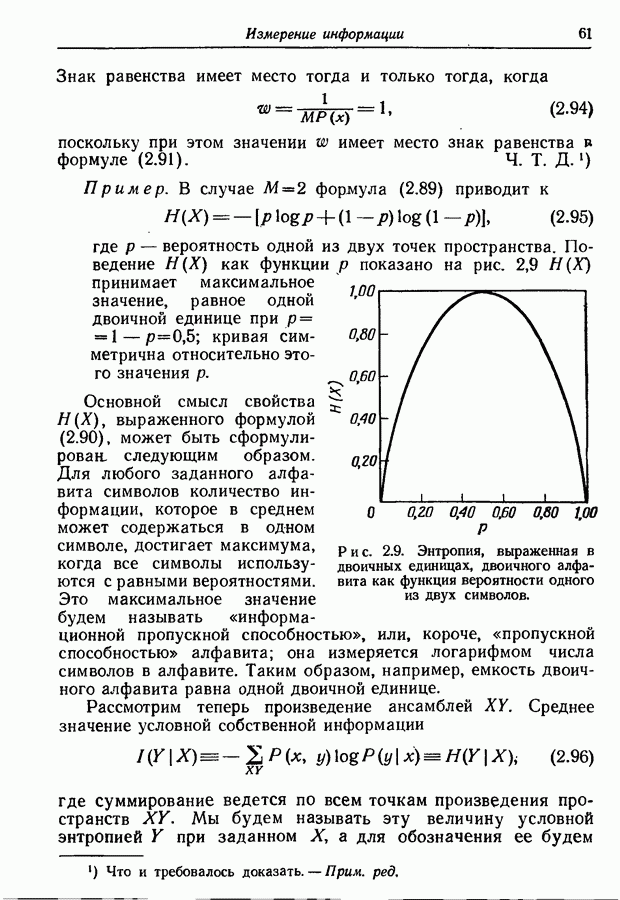
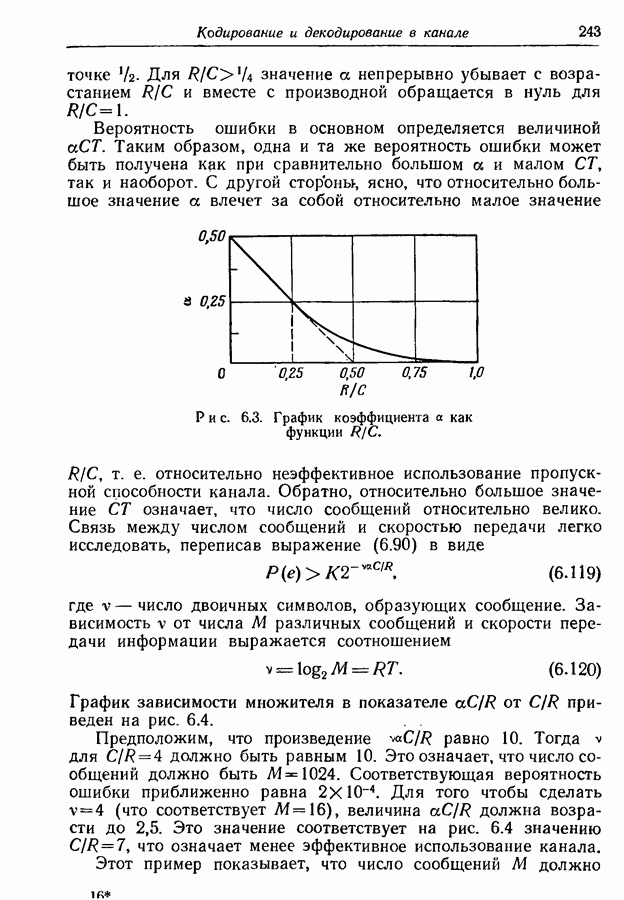
где Описанный метод кодирования требует, чтобы кодер и декодер хранили столько множеств кодовых слов, сколько состояний имеет источник. С другой стороны, из рис. 4.5 видно, что во всех трех множествах кодовых слов по два слова состоят из двух символов и по одному слову из одного символа. Мы знаем, кроме того, что если кодовые слова при известных состояниях источника однозначно определяют соответствующие буквы на выходе источника, то средняя длина кода зависит от числа символов в каждом слове, но не зависит от значений этих символов. Поэтому приведенные на рис. 4.6 множества кодовых слов пригодны для наших целей и дают ту же среднюю длину кода, что и множества рис. 4.5.
Рис. 4.6. Другие множества кодовых слов для источника, заданного на рис. 4.4. Эти новые множества кодовых слов обладают важным свойством — они тождественны, если не принимать во внимание вид соответствия между кодовыми словами и буквами. Сравнение с таблицей вероятностей рис. 4.4 показывает, что слово 0 во всех случаях соответствует букве, которая в рассматриваемом состоянии источника имеет наибольшую условную вероятность. Слово 11 во всех случаях соответствует букве, имеющей следующую за наибольшей условную вероятность, и слово 10 соответствует букве, имеющей наименьшую условную вероятность. Следовательно, при использовании множеств кодовых слов, приведенных на рис. 4.6, кодеру и декодеру необходимо хранить лишь одно множество кодовых слов. Правда, они должны при этом хранить еще таблицу, указывающую для каждого состояния соответствие между кодовыми словами и буквами. Преимущество, которым обладают кодовые слова, взятые из таблицы на рис. 4.6, не всегда можно получить без увеличения средней длины кода, так как число кодовых слов, имеющих заданную длину, вообще говоря, не одно и то же для всех состояний, если эти множества кодовых слов оптимальны. Метод кодирования, приводящий к использованию единого множества кодовых слов в общем виде может быть описан следующим образом. Для каждого состояния расположим буквы в порядке убывания вероятностей и обозначим через Асимптотическое значение вероятности
где
где можно построить согласно процессу, описанному в разд. 3.7, заменяя вероятности сообщений
— энтропия ансамбля, образованного различными рангами. Из выражения (3.18) имеем
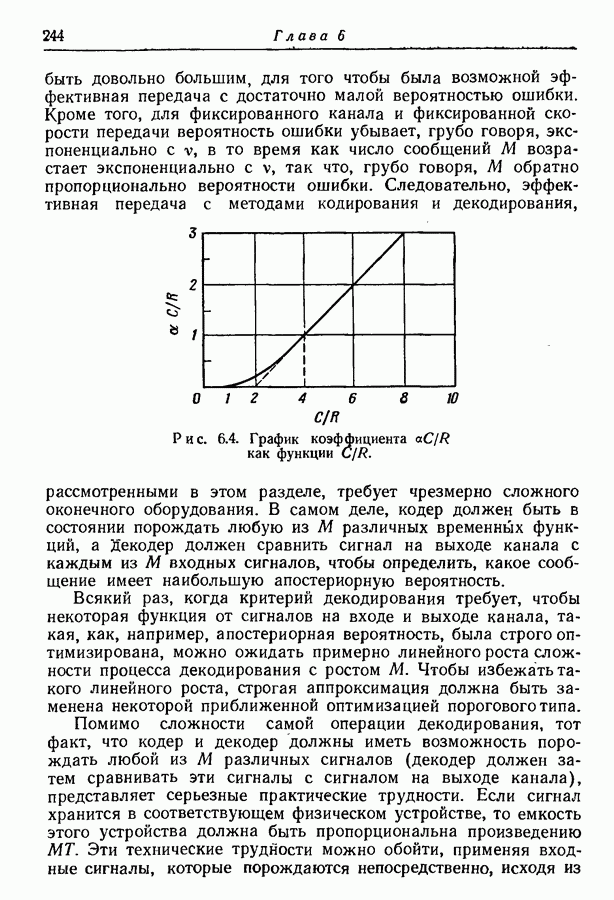
где Когда энтропии
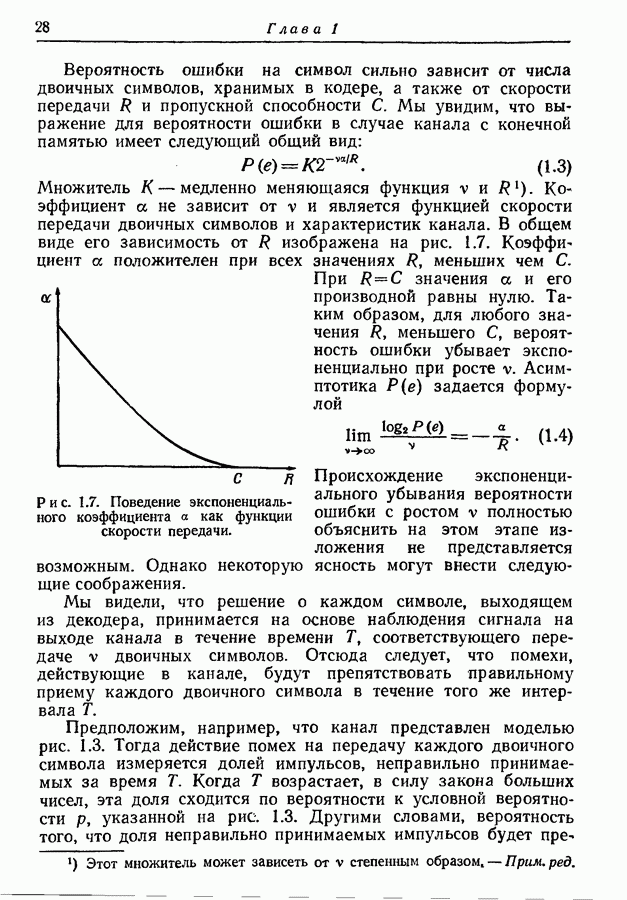
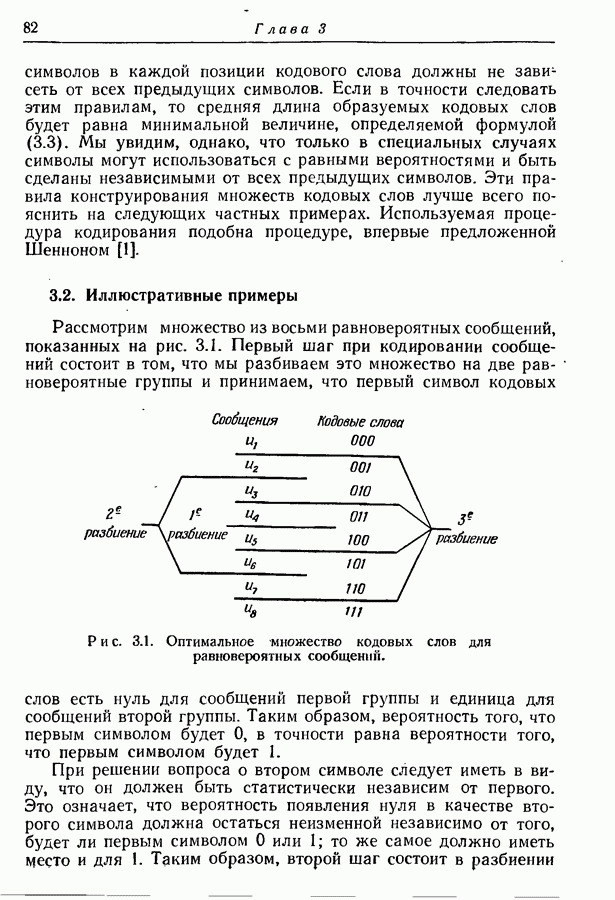
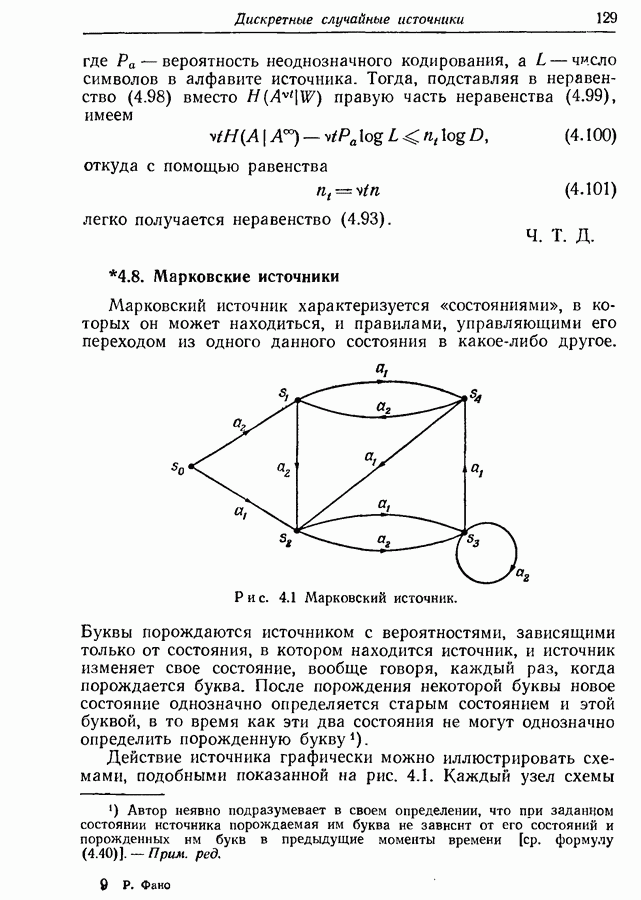
Рис. 4.7. Построение схемы для пар букв. Однако, как показано ниже, эту относительную ошибку можно сделать как угодно малой путем кодирования сообщений, состоящих не из отдельных букв, а из Рассмотрим порождаемые марковским источником буквы попарно, а не одну за другой. Тогда можно построить новую марковскую схему, в которой каждой линии перехода между состояниями соответствует порождение некоторой последовательности из двух букв. Например, схема на рис. 4.7, а приведет к схеме на рис. 4.7, б. Если Для каждого состояния
Этот процесс можно легко обобщить, рассматривая выходные символы группами по Асимптотическая (стационарная) условная энтропия
в котором относительное различие между двумя границами может быть сделано сколь угодно малым при выборе достаточно большого значения В заключение следует упомянуть, что метод кодирования, основанный на представлении ансамбля последовательностей с помощью марковского источника, иногда называют «кодированием с предсказанием» [6]. Объяснением такого наименования служит тот факт, что первый шаг в процессе кодирования может рассматриваться как предсказание следующей буквы или следующего сообщения по предыдущему, представленному его состоянием. Конечно, следующая буква или сообщение не может быть предсказано точно, а лишь оценивается через распределение вероятностей, используемое затем для построения оптимального множества кодовых слов. Кодер и декодер выполняют одну и ту же операцию предсказания, так что оба они независимо выбирают одно и то же множество кодовых слов.
|
 |
Оглавление
|



























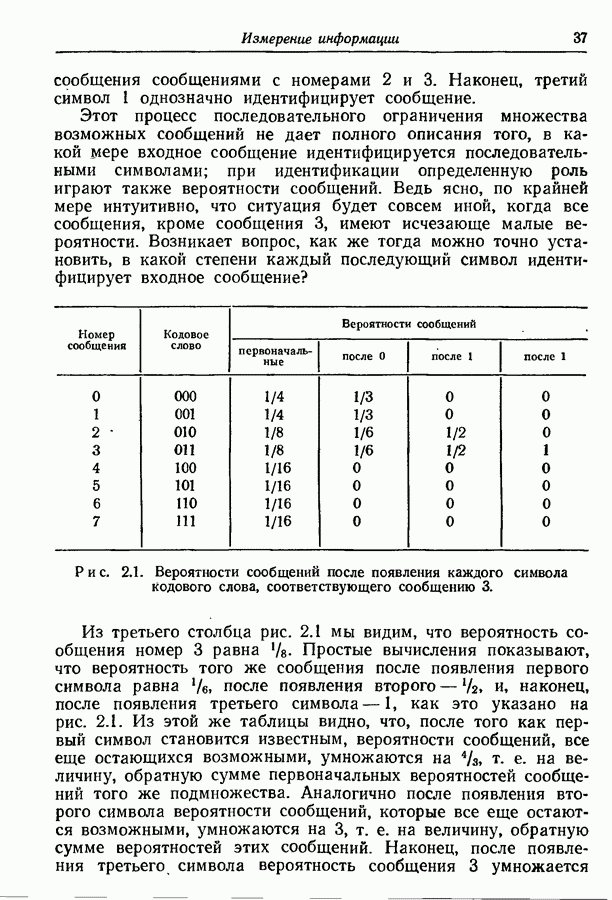








































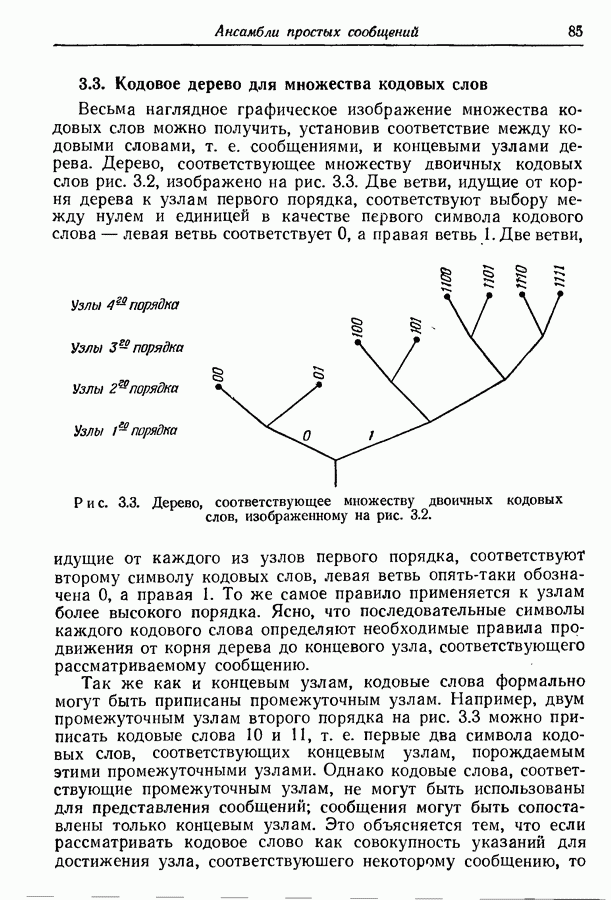





















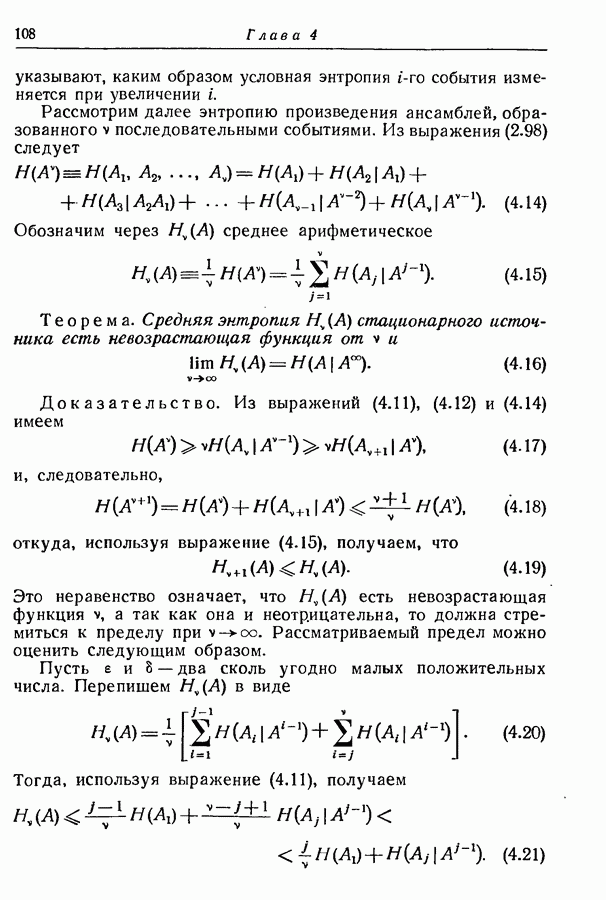




















































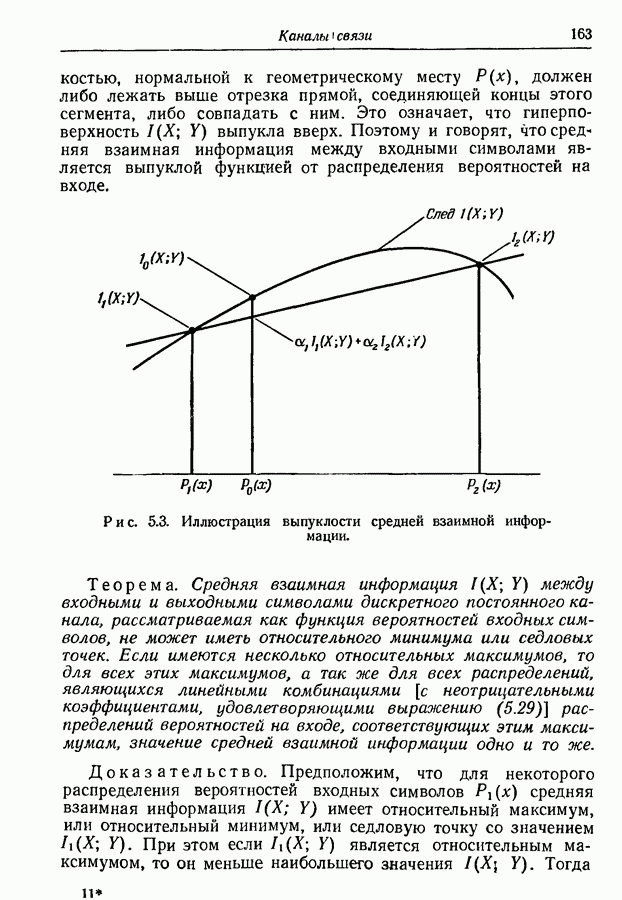


















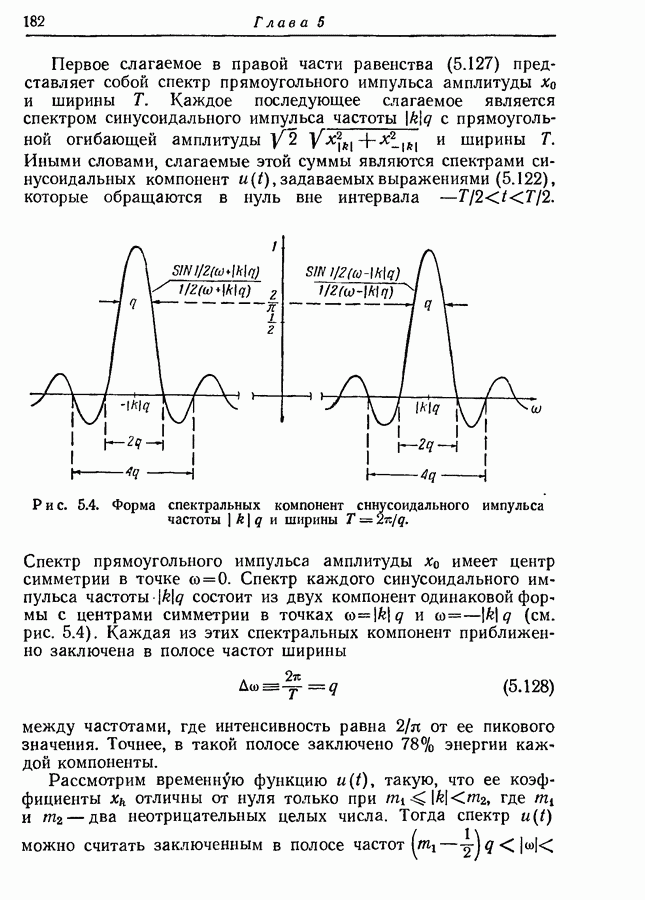

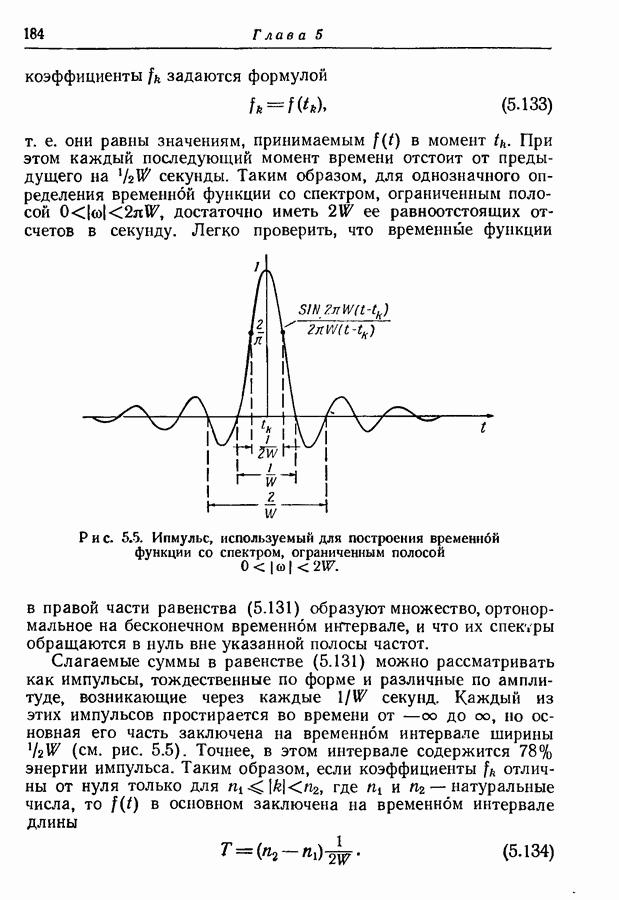













































































































































































































 то рассмотренный в разд. 3.7 метод кодирования можно применить и к марковским источникам. Различие между рассматриваемой теперь задачей и задачей, рассмотренной в разд. 3.7,
то рассмотренный в разд. 3.7 метод кодирования можно применить и к марковским источникам. Различие между рассматриваемой теперь задачей и задачей, рассмотренной в разд. 3.7,
 зависят от состояния источника, в то время как вероятности сообщений
зависят от состояния источника, в то время как вероятности сообщений  предполагались постоянными. Это обстоятельство приводит к необходимости использования различных множеств кодовых слов для каждого состояния источника.
предполагались постоянными. Это обстоятельство приводит к необходимости использования различных множеств кодовых слов для каждого состояния источника.

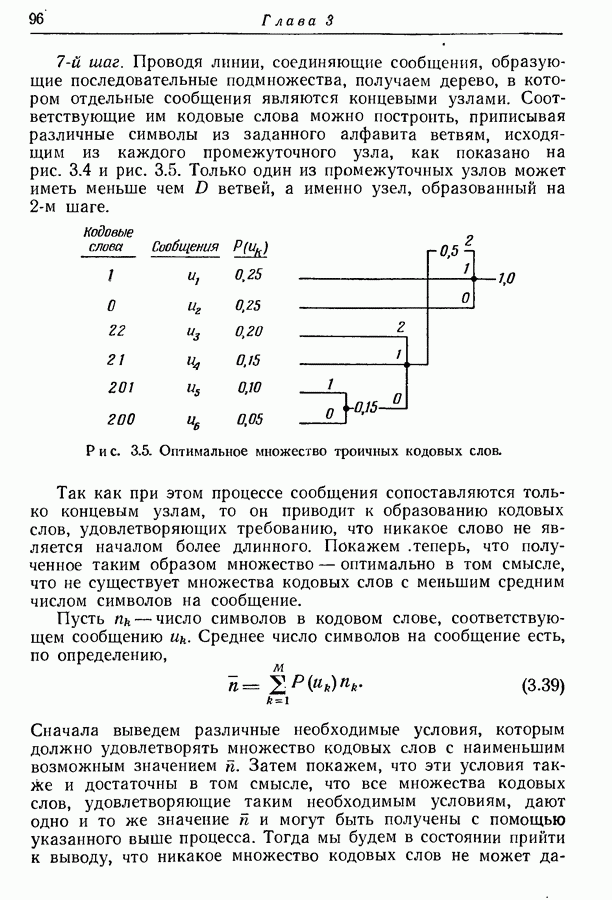
 начальное состояние. Таблица в правой части рисунка дает значение условных распределений вероятностей
начальное состояние. Таблица в правой части рисунка дает значение условных распределений вероятностей  Предположим, что мы хотим представить буквы на выходе двоичными символами. Следуя методу, изложенному в разд. 3.7, мы получаем для трех различных состояний три множества кодовых слов, показанных на рис. 4.5.
Предположим, что мы хотим представить буквы на выходе двоичными символами. Следуя методу, изложенному в разд. 3.7, мы получаем для трех различных состояний три множества кодовых слов, показанных на рис. 4.5.


 энтропия ансамбля А, когда источник находится в состоянии
энтропия ансамбля А, когда источник находится в состоянии  а
а  - среднее число символов в кодовых словах для состояния
- среднее число символов в кодовых словах для состояния  . С помощью соотношения (3.18) получаем
. С помощью соотношения (3.18) получаем



 как и прежде, представляет собой асимптотическое значение энтропии на букву, задаваемое равенством (4.113).
как и прежде, представляет собой асимптотическое значение энтропии на букву, задаваемое равенством (4.113).

 их ранг
их ранг  есть ранг буквы второй по величине вероятности). В разных состояниях источника той же букве, вообще говоря, пока еще сопоставлены разные кодовые слова, но каждому рангу поставлено в соответствие одно и то же слово. Следовательно, некоторая буква
есть ранг буквы второй по величине вероятности). В разных состояниях источника той же букве, вообще говоря, пока еще сопоставлены разные кодовые слова, но каждому рангу поставлено в соответствие одно и то же слово. Следовательно, некоторая буква  представлена в каждом состоянии кодовым словом, соответствующим рангу
представлена в каждом состоянии кодовым словом, соответствующим рангу  буквы в этом состоянии. Другими словами, мы кодируем ранги букв, а не сами буквы. Например, в случае рис. 4.6, буква с наименьшей вероятностью всегда представлена словом 10, а наиболее вероятная буква — словом 0.
буквы в этом состоянии. Другими словами, мы кодируем ранги букв, а не сами буквы. Например, в случае рис. 4.6, буква с наименьшей вероятностью всегда представлена словом 10, а наиболее вероятная буква — словом 0.
 того, что источник будет порождать букву ранга
того, что источник будет порождать букву ранга  задается выражением
задается выражением

 равно значению
равно значению  для буквы ранга
для буквы ранга  в состоянии
в состоянии  распределение вероятностей состояний источника. Средняя длина кодового слова
распределение вероятностей состояний источника. Средняя длина кодового слова

 число символов в кодовом слове, сопоставленном рангу
число символов в кодовом слове, сопоставленном рангу  Таким образом, оптимальное множество кодовых слов
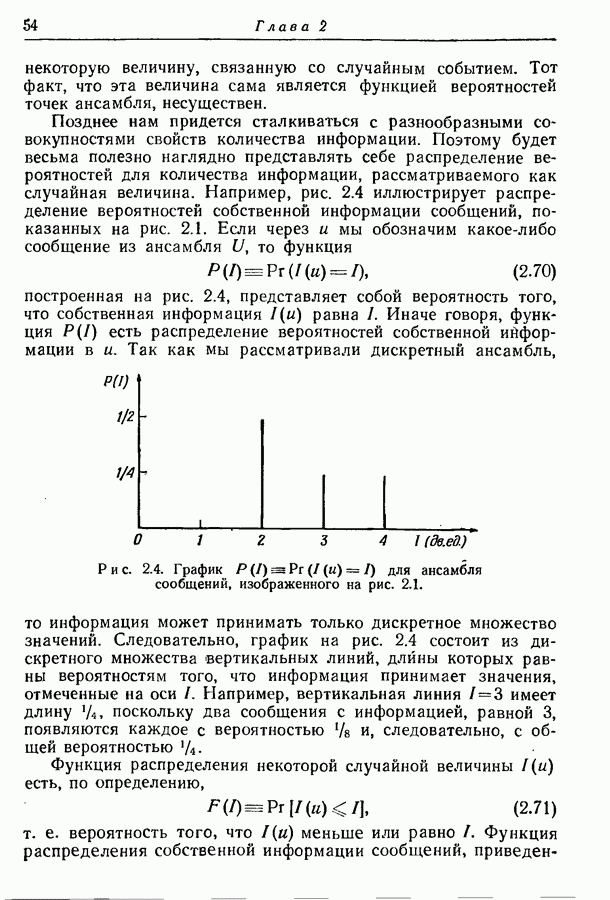
Таким образом, оптимальное множество кодовых слов
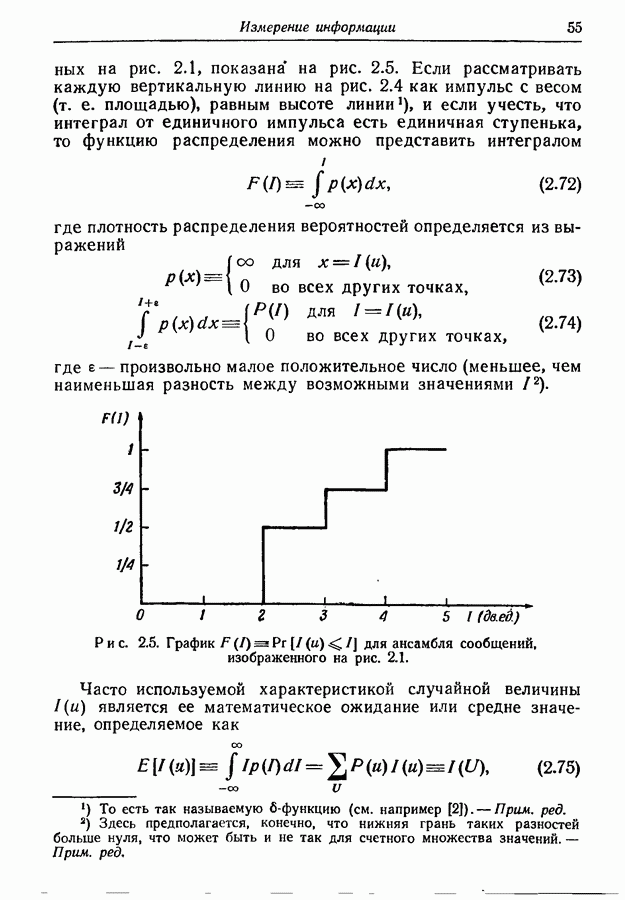
 вероятностями рангов
вероятностями рангов  Границы для асимптотического значения
Границы для асимптотического значения  можно получить следующим образом. Пусть
можно получить следующим образом. Пусть


 число букв в кодовом алфавите.
число букв в кодовом алфавите.
 и
и  сравнимы по величине с пропускной способностью
сравнимы по величине с пропускной способностью  кодового алфавита, границы сверху для
кодового алфавита, границы сверху для  в выражениях (4.143) и (4.147) могут заметно отличаться (в смысле относительной ошибки) от соответствующих нижних границ.
в выражениях (4.143) и (4.147) могут заметно отличаться (в смысле относительной ошибки) от соответствующих нижних границ.

 последовательных букв.
последовательных букв.
 число букв в алфавите источника, то этот процесс влечет за собой введение нового алфавита, состоящего из
число букв в алфавите источника, то этот процесс влечет за собой введение нового алфавита, состоящего из  букв, и замену каждой последовательности из двух исходных букв одной новой буквой. Схема на рис. 4.7, б изображает марковский источник, образованный в результате такой замены.
букв, и замену каждой последовательности из двух исходных букв одной новой буквой. Схема на рис. 4.7, б изображает марковский источник, образованный в результате такой замены.
 можно вычислить условные вероятности
можно вычислить условные вероятности  где
где  представляет первую букву, а
представляет первую букву, а
 вторую. А затем каждую упорядоченную пару букв мы можем закодировать, следуя одному из рассмотренных выше методов.
вторую. А затем каждую упорядоченную пару букв мы можем закодировать, следуя одному из рассмотренных выше методов.
 символов и строя соответствующие марковские схемы, в которых линии между состояниями соответствуют последовательностям из
символов и строя соответствующие марковские схемы, в которых линии между состояниями соответствуют последовательностям из  букв. Тогда для этих последовательностей можно построить оптимальные кодовые слова, используя условные вероятности
букв. Тогда для этих последовательностей можно построить оптимальные кодовые слова, используя условные вероятности 
 ансамбля последовательностей из
ансамбля последовательностей из  символов просто равна асимптотической условной энтропии на букву
символов просто равна асимптотической условной энтропии на букву  умноженной на
умноженной на  Это вытекает из того факта, что значение собственной информации букв зависит только от состояния источника, а вероятности состояний стационарны. Таким образом, для оптимальных, зависящих от состояния источника, кодовых слов среднее число символов на букву будет удовлетворять неравенству
Это вытекает из того факта, что значение собственной информации букв зависит только от состояния источника, а вероятности состояний стационарны. Таким образом, для оптимальных, зависящих от состояния источника, кодовых слов среднее число символов на букву будет удовлетворять неравенству

