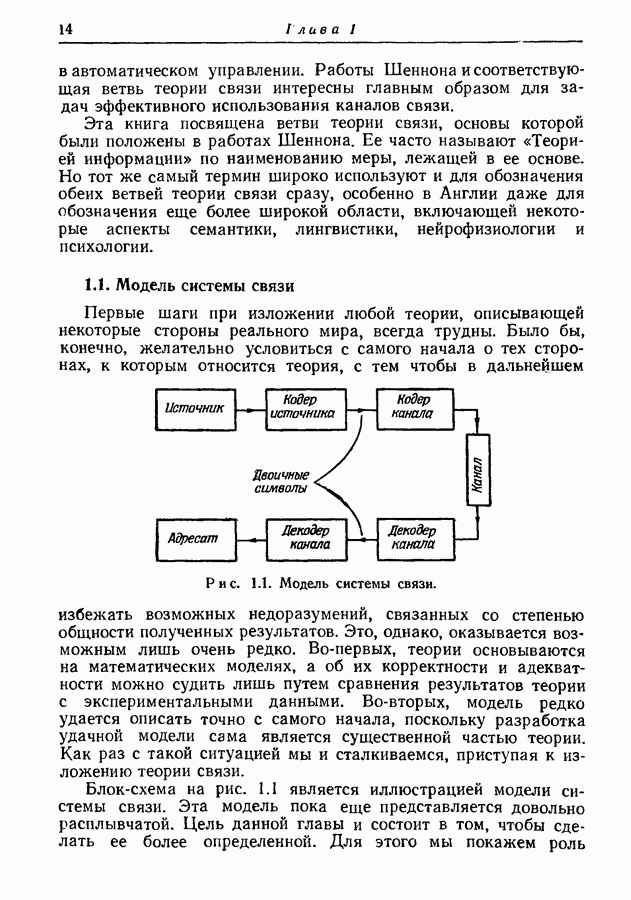
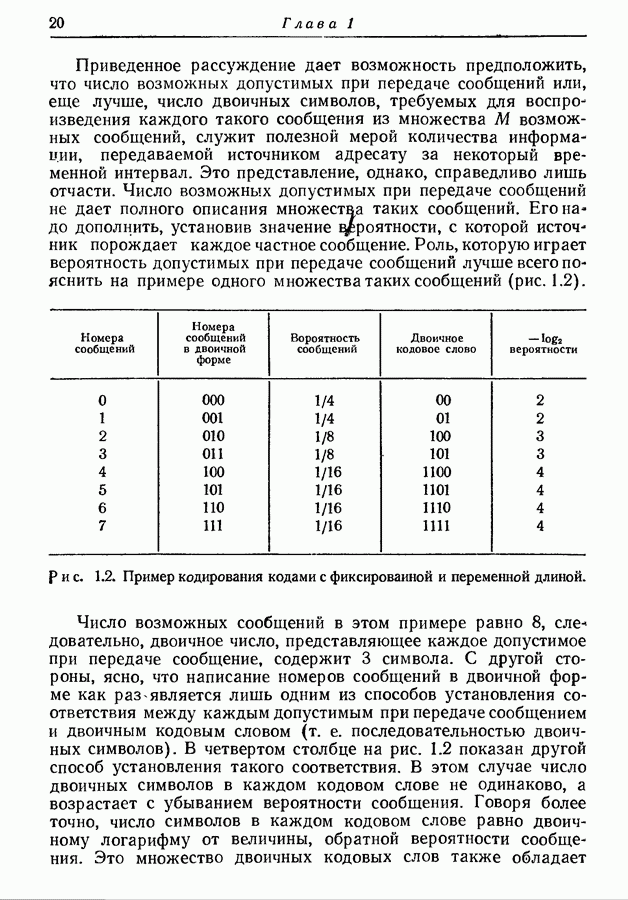
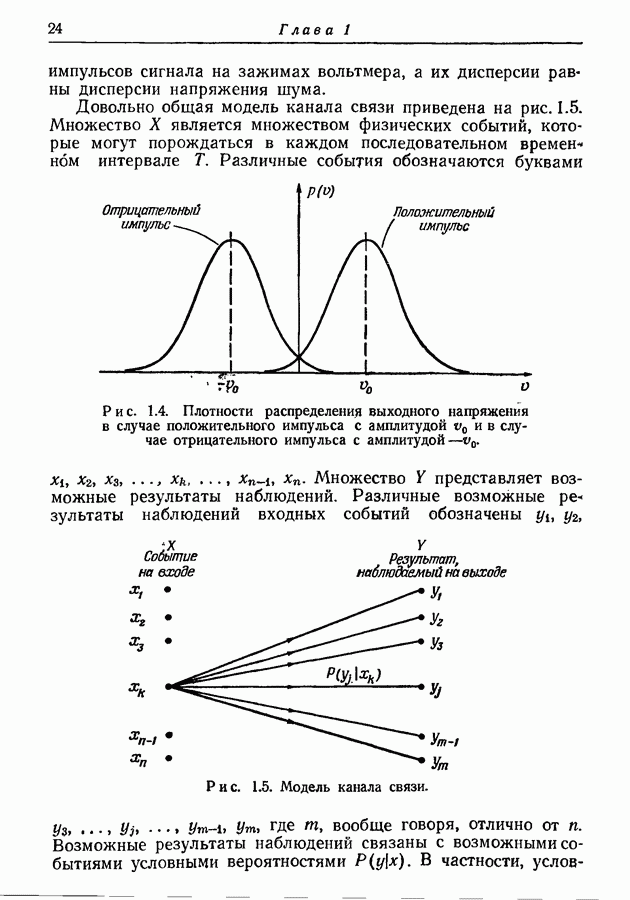
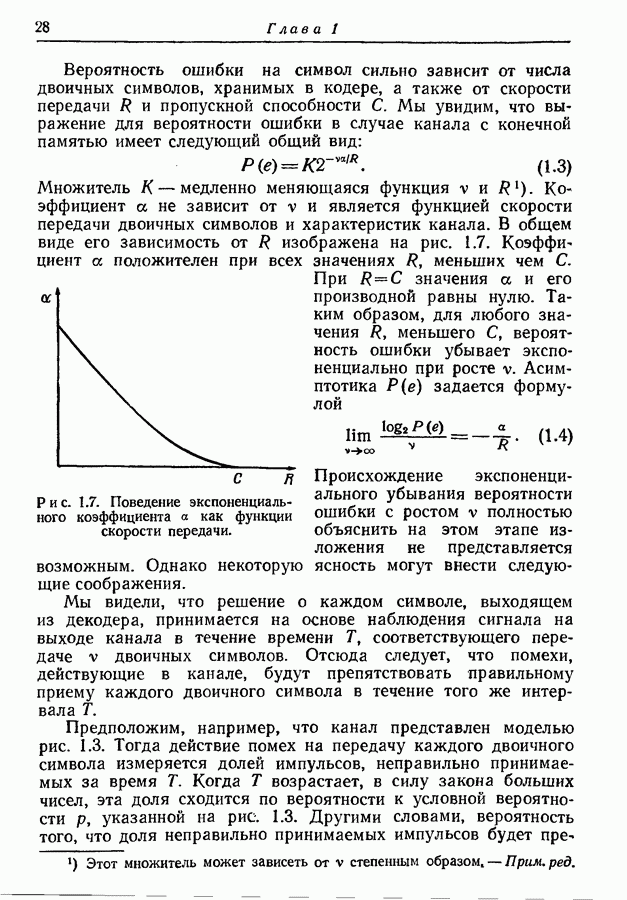
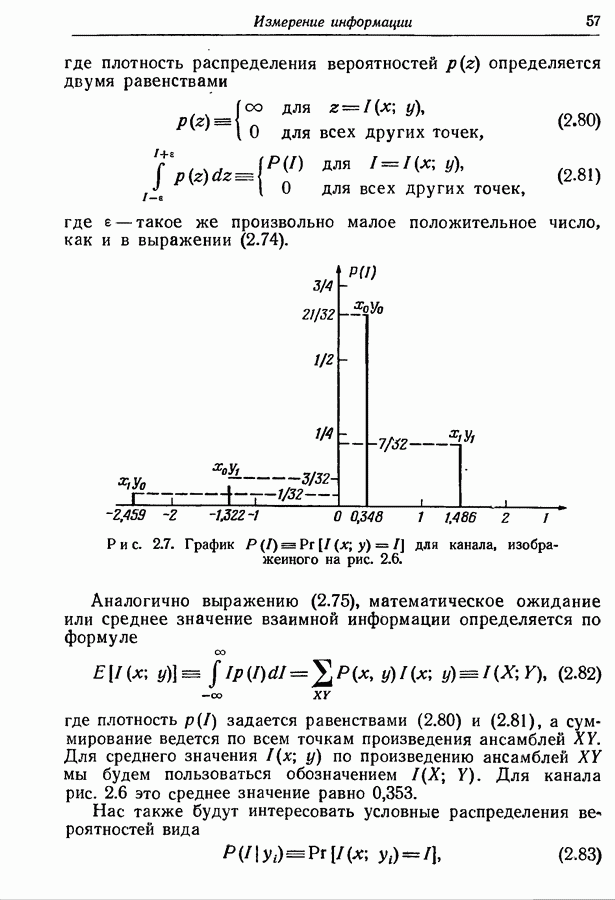
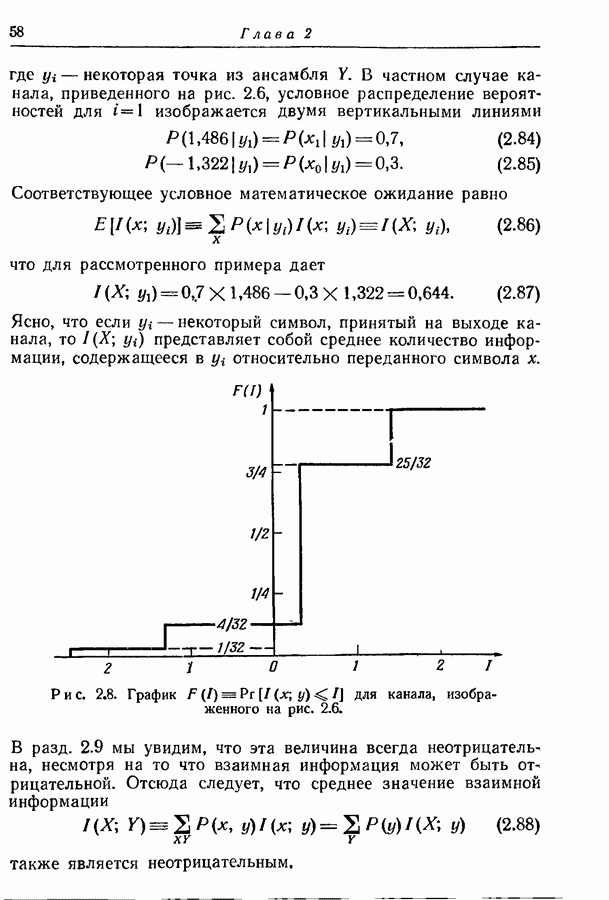
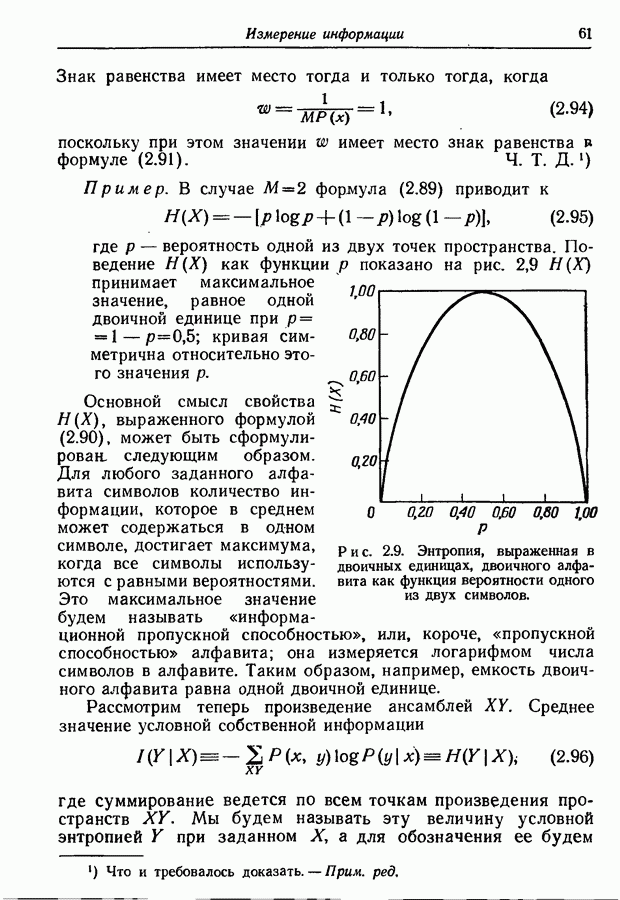
Пред.
След.
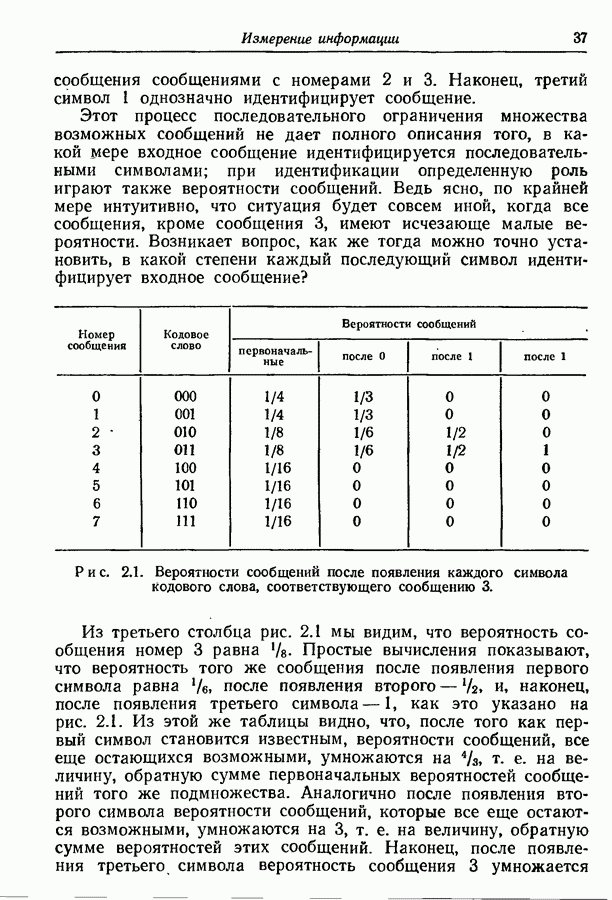
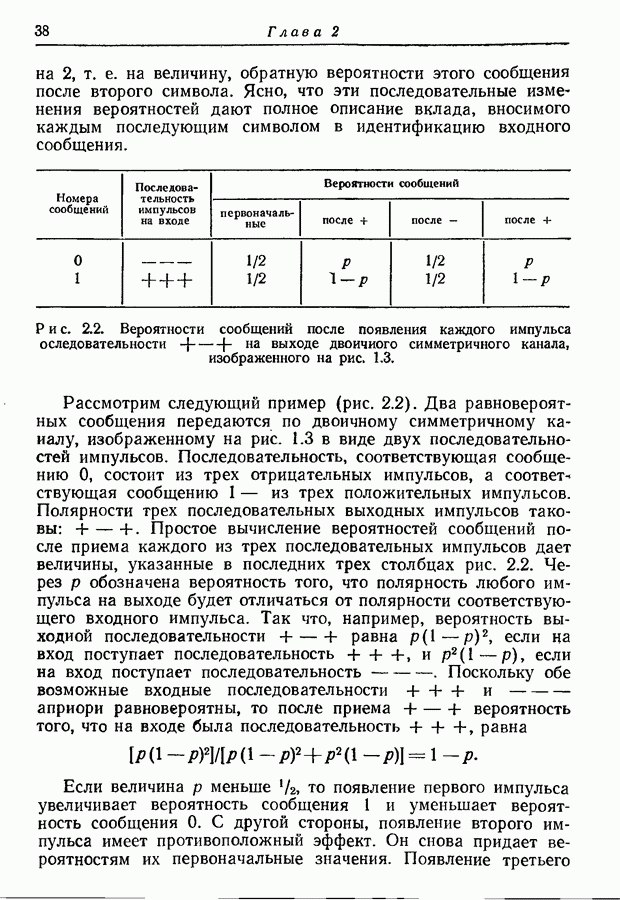
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
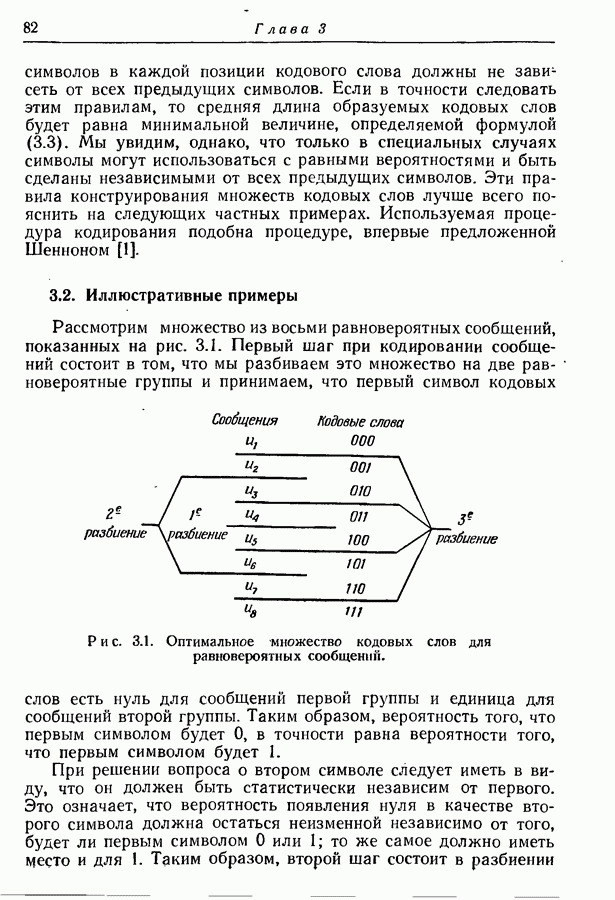
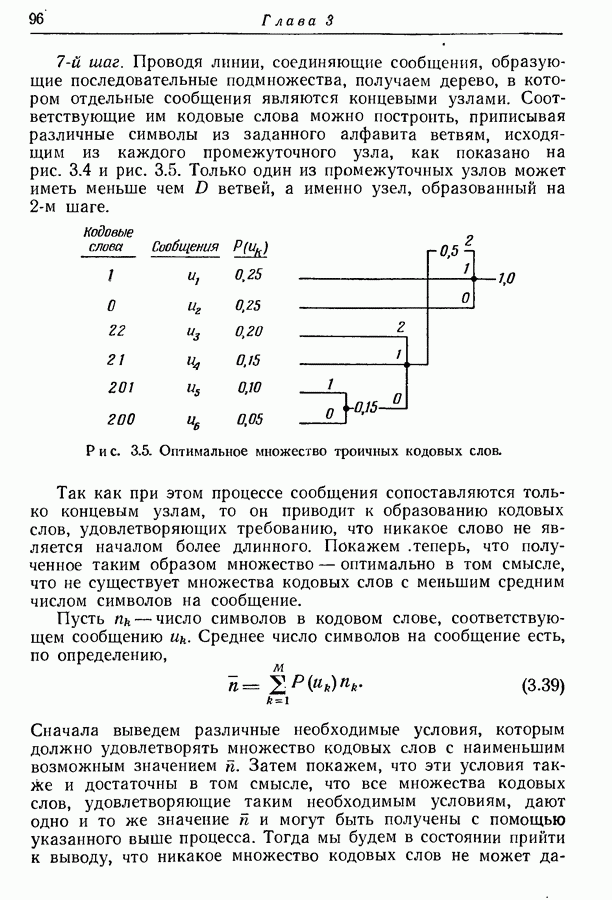
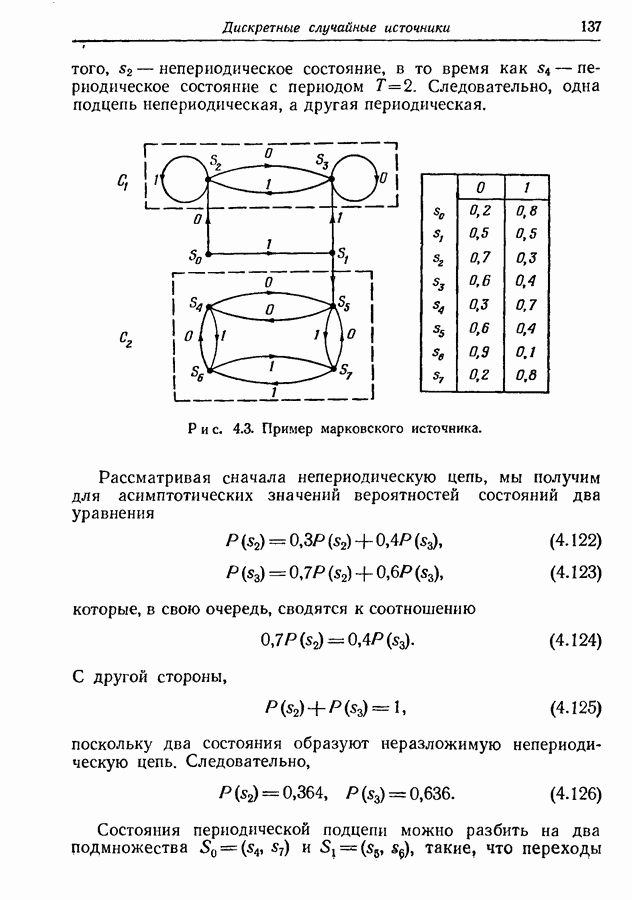
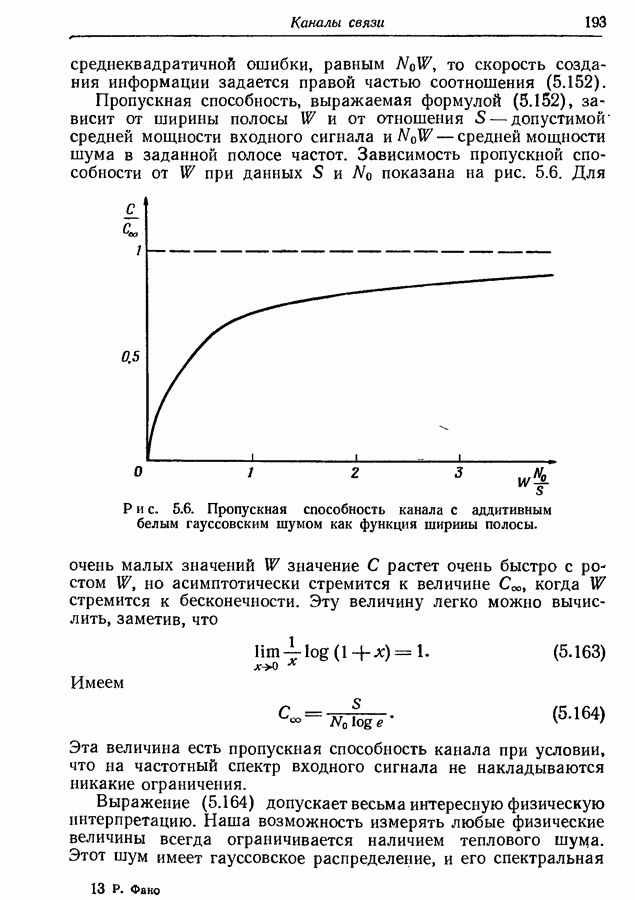
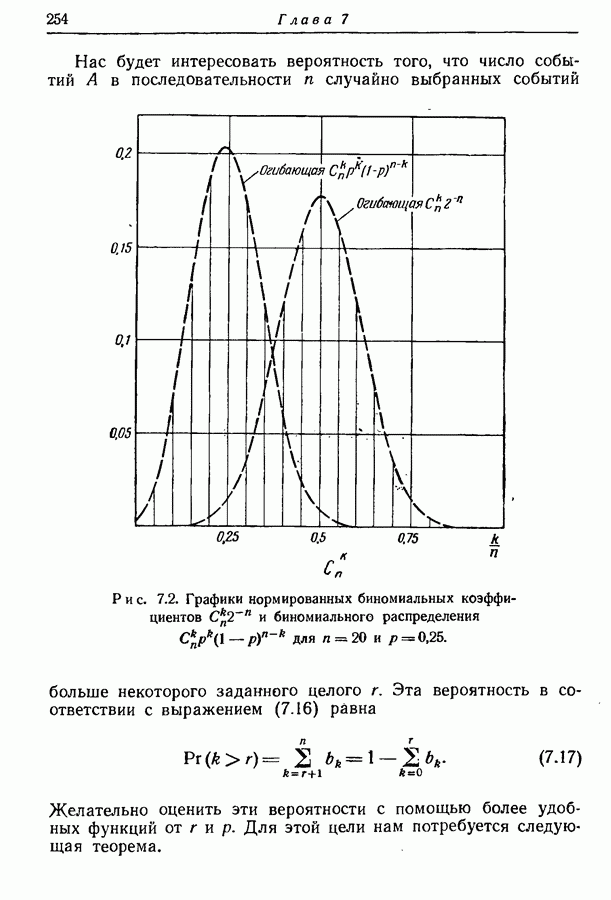
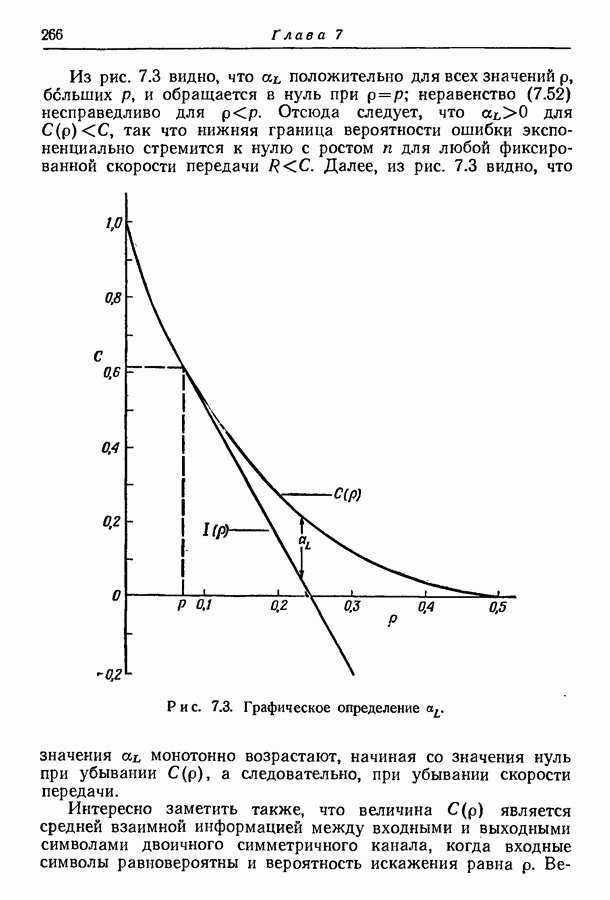
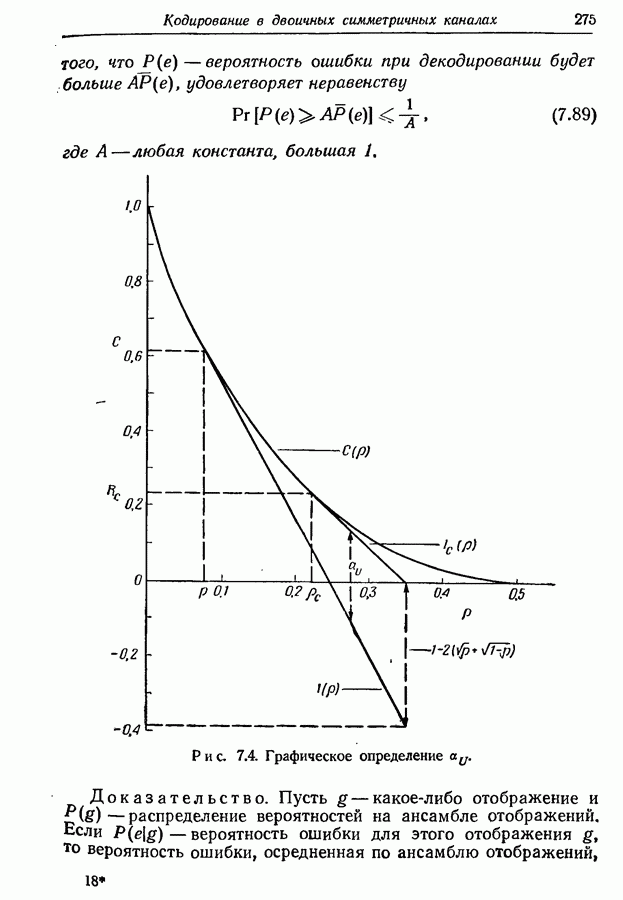
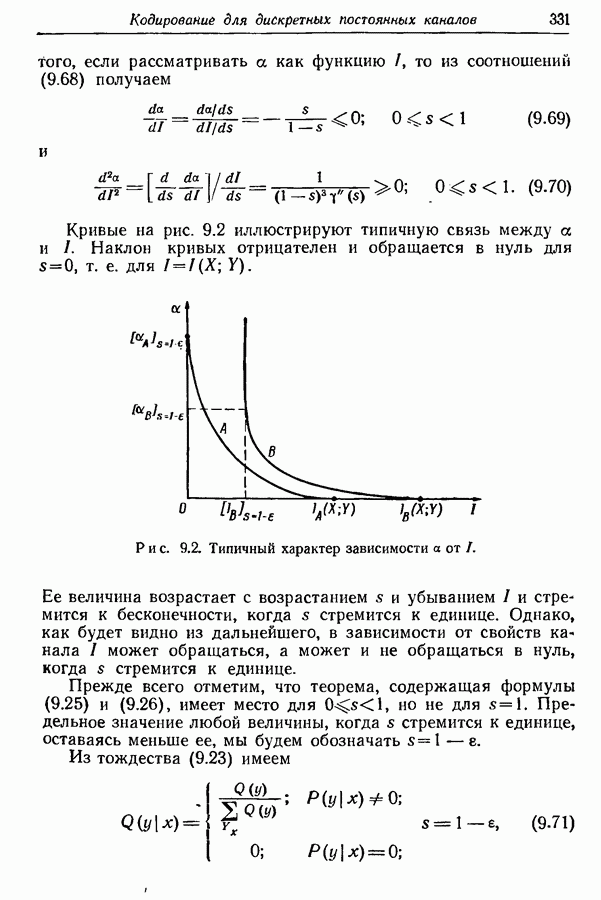
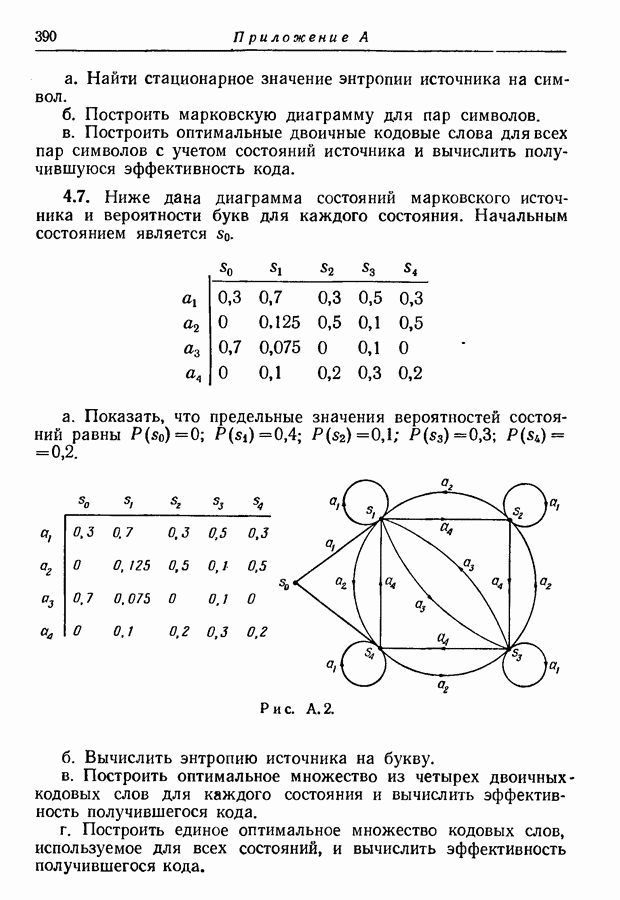
3.2. Иллюстративные примерыРассмотрим множество из восьми равновероятных сообщений, показанных на рис. 3.1. Первый шаг при кодировании сообщений состоит в том, что мы разбиваем это множество на две равновероятные группы и принимаем, что первый символ кодовых слов есть нуль для сообщений первой группы и единица для сообщений второй группы.
Рис. 3.1. Оптимальное множество кодовых слов для равновероятных сообщений. Таким образом, вероятность того, что первым символом будет 0, в точности равна вероятности того, что первым символом будет 1. При решении вопроса о втором символе следует иметь в виду, что он должен быть статистически независим от первого. Это означает, что вероятность появления нуля в качестве второго символа должна остаться неизменной независимо от того, будет ли первым символом 0 или 1; то же самое должно иметь место и для 1. Таким образом, второй шаг состоит в разбиении каждой из групп, образованных на первом шаге, на две равновероятные подгруппы, как это показано на рис. 3.1 линиями, выделенными надписью «2-е разбиение». Затем для каждой группы 0 приписывается сообщениям первой подгруппы и 1 — сообщениям второй подгруппы. Ясно, что четыре образованные подгруппы будут равновероятны. Третий, последний шаг подобен второму. Каждая из четырех подгрупп, показанных на рис. 3.1, снова подразбивается на две равновероятные части (каждая из которых состоит из единственного сообщения), отмеченные линиями с надписями «3-е разбиение». В каждой из этих подгрупп одному сообщению приписывается 0 в качестве третьего символа, а другому 1. Опять-таки эта процедура обеспечивает то, что третий символ будет статистически не зависеть от предыдущих двух и что 0 и 1 будут появляться с равными вероятностями. Поскольку восемь сообщений на рис. 3.1 равновероятны, энтропия их ансамбля равна трем двоичным единицам, пропускная способность двоичного алфавита равна одной двоичной единице. Таким образом, минимальное среднее число символов на сообщение равно 3, т. е. совпадает с числом символов в кодовых словах рис. 3.1.
Рис. 3.2. Оптимальное множество кодовых слов. Рассмотрим теперь ансамбль сообщений рис. 3.2. Вероятности сообщений больше не равны друг другу, но все еще являются отрицательными степенями 2. Кодовые слова, показанные на рис. 3.2, построены опять путем последовательного подразбиения ансамбля сообщений на равновероятные группы и подгруппы. В этом случае, однако, группы и подгруппы содержат неодинаковое число сообщений, а кодовые слова не имеют одного и того же числа знаков. Это следует из того факта, что сообщения, имеющие вероятность А, выделяются двумя последовательными разбиениями ансамбля сообщений на равновероятные группы, в то время как сообщения, имеющие вероятности Поскольку каждый символ, будь то ноль или единица, появляется с вероятностью Этот метод построения кодовых слов можно легко обобщить на случай произвольного алфавита из Кроме того, если нельзя образовать равновероятные группы и подгруппы, то описанный метод не обязательно приводит к множеству кодовых слов с наименьшей возможной средней длиной. Систематический метод построения оптимальных множеств кодовых слов будет дан в разд. 3.6.
|
 |
Оглавление
|



































































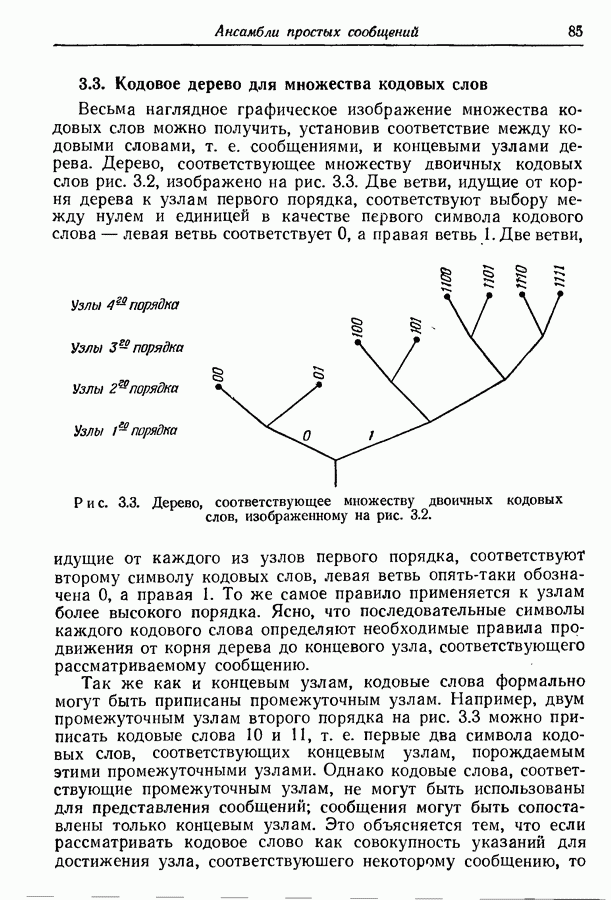









































































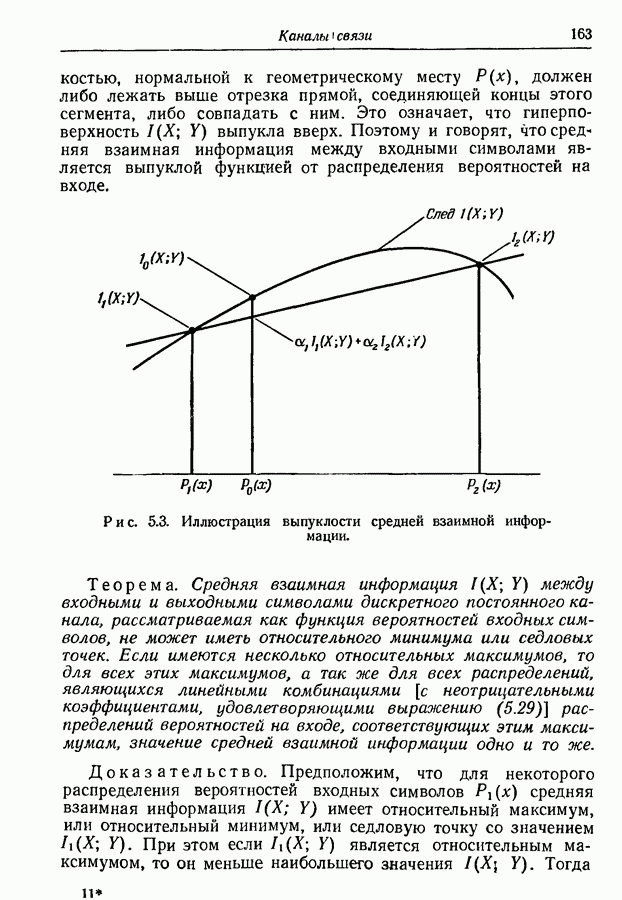








































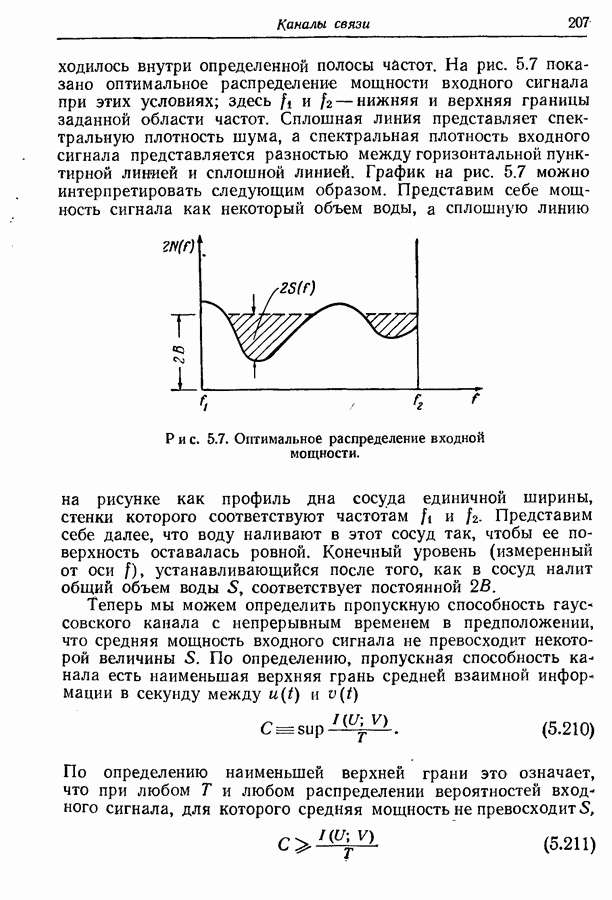



































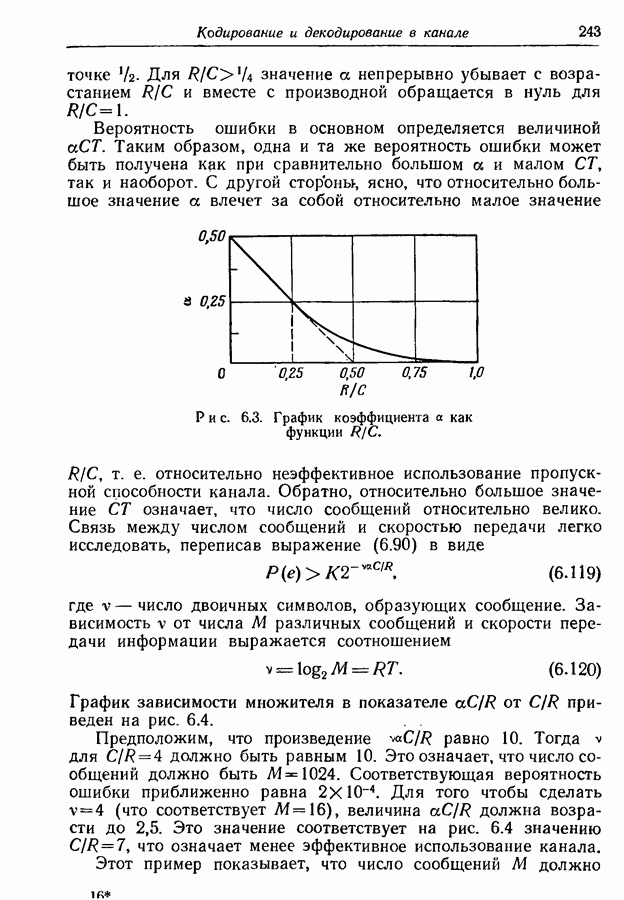
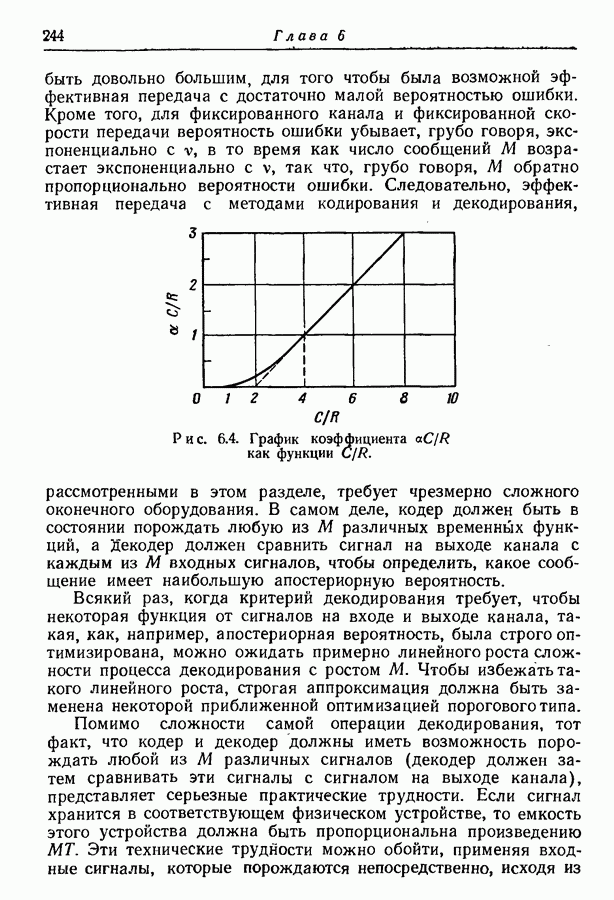









































































































































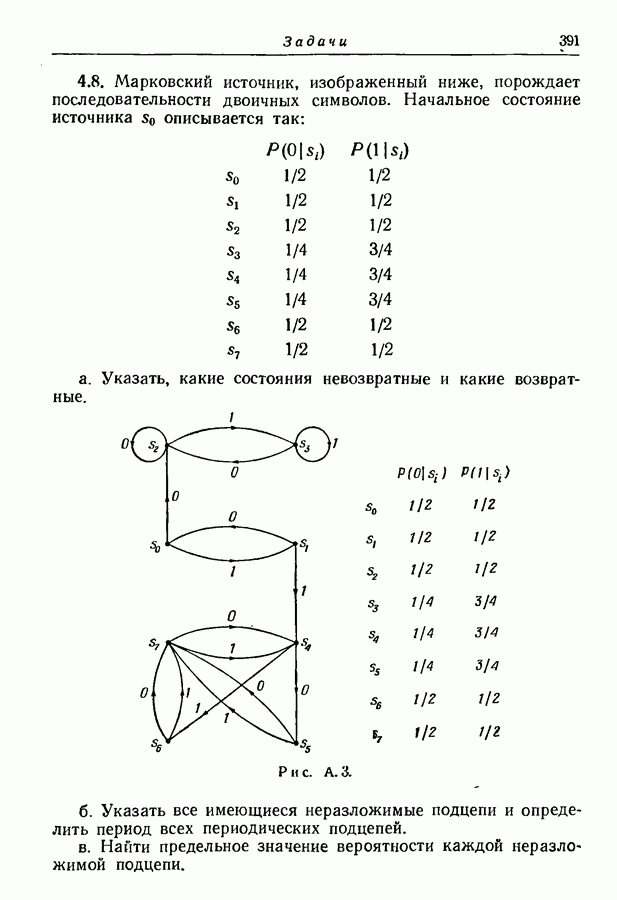














 выделяются только после четырех последовательных разбиений на равновероятные группы. Группы и подгруппы, образованные последовательными разбиениями, явно выделяются символами кодовых слов. Так как вероятности сообщений выражены отрицательными степенями 2, то возможно сделать все группы и под: группы равновероятными, а все символы статистически независимыми от предыдущих. В том, что это верно, легко убедиться непосредственной проверкой.
выделяются только после четырех последовательных разбиений на равновероятные группы. Группы и подгруппы, образованные последовательными разбиениями, явно выделяются символами кодовых слов. Так как вероятности сообщений выражены отрицательными степенями 2, то возможно сделать все группы и под: группы равновероятными, а все символы статистически независимыми от предыдущих. В том, что это верно, легко убедиться непосредственной проверкой.
 он может внести одну двоичную единицу информации относительно соответствующего сообщения. Это количество информации и вносится фактически, так как рассматриваемый символ однозначно определяется соответствующим сообщением (см. разд. 2.6). Отсюда следует, что число символов
он может внести одну двоичную единицу информации относительно соответствующего сообщения. Это количество информации и вносится фактически, так как рассматриваемый символ однозначно определяется соответствующим сообщением (см. разд. 2.6). Отсюда следует, что число символов  в каждом кодовом слове должно равняться собственной информации соответствующего сообщения. Можно легко проверить справедливость этого для всех кодовых слов рис. 3.2. Отсюда мы приходим к выводу, что среднее число двоичных символов на сообщение должно равняться энтропии ансамбля сообщений, т. е. минимальной величине, определяемой (3.3). Как энтропия, так и среднее число символов равны 2,75.
в каждом кодовом слове должно равняться собственной информации соответствующего сообщения. Можно легко проверить справедливость этого для всех кодовых слов рис. 3.2. Отсюда мы приходим к выводу, что среднее число двоичных символов на сообщение должно равняться энтропии ансамбля сообщений, т. е. минимальной величине, определяемой (3.3). Как энтропия, так и среднее число символов равны 2,75.
 символов путем последовательного подразбиения ансамбля сообщений не на две, а на
символов путем последовательного подразбиения ансамбля сообщений не на две, а на  равновероятных групп и подгрупп. Ясно, с другой стороны, что этот метод построения может оказаться успешным, только когда вероятности сообщений являются отрицательными степенями
равновероятных групп и подгрупп. Ясно, с другой стороны, что этот метод построения может оказаться успешным, только когда вероятности сообщений являются отрицательными степенями  независимо от того, равно ли
независимо от того, равно ли  двум или любому другому целому числу. Если вероятности сообщений не являются отрицательными степенями
двум или любому другому целому числу. Если вероятности сообщений не являются отрицательными степенями  то последовательные группы и подгруппы могут быть равновероятными не в точности, а лишь приближенно, и среднее число символов на сообщение не может быть сделано равным минимальной величине, определяемой выражением (3.3).
то последовательные группы и подгруппы могут быть равновероятными не в точности, а лишь приближенно, и среднее число символов на сообщение не может быть сделано равным минимальной величине, определяемой выражением (3.3).