Пред.
След.
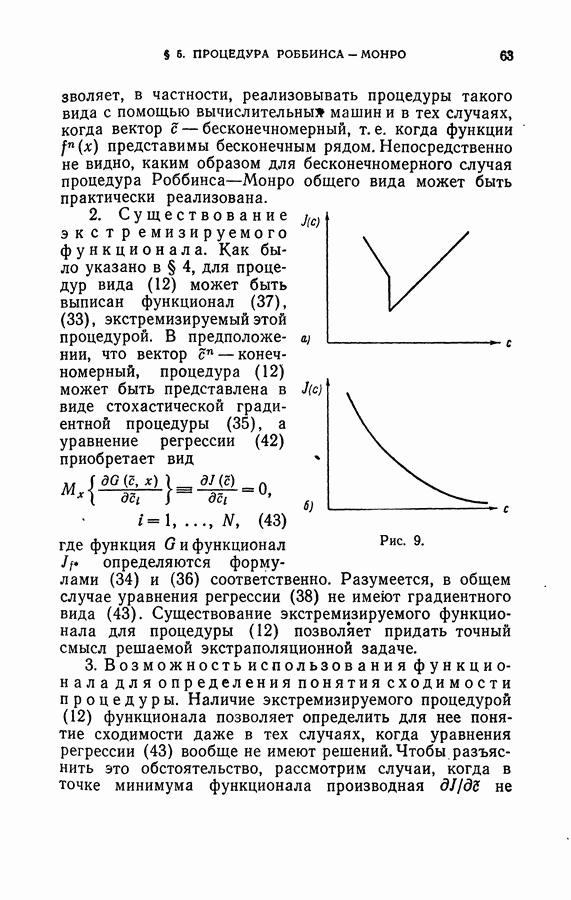
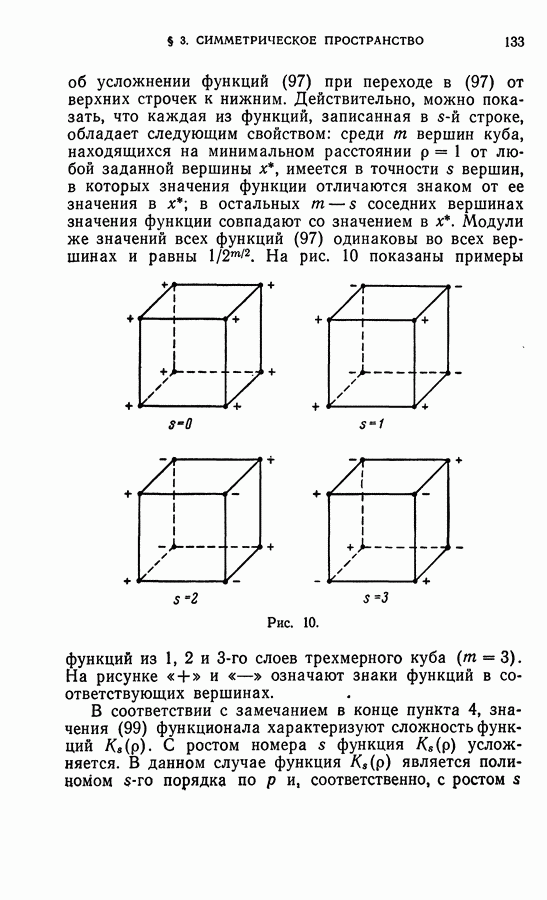
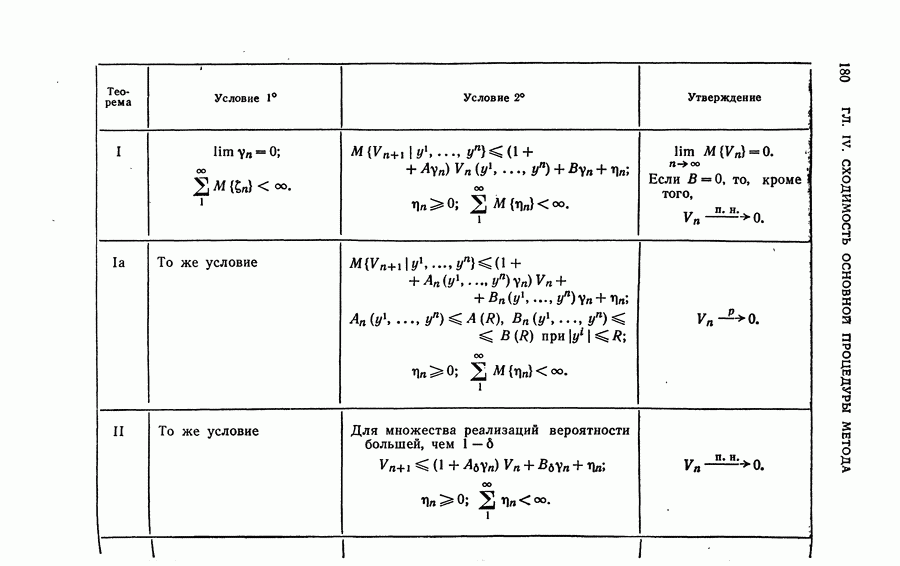
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
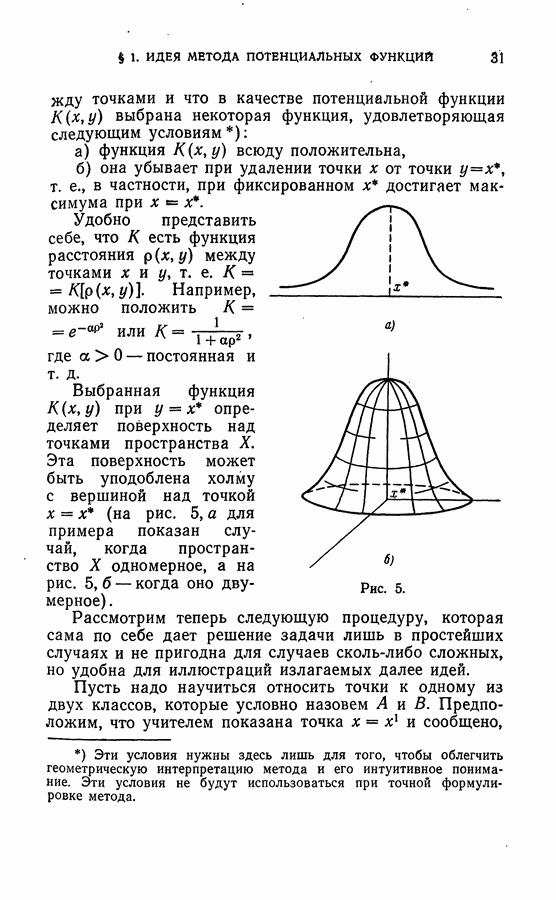
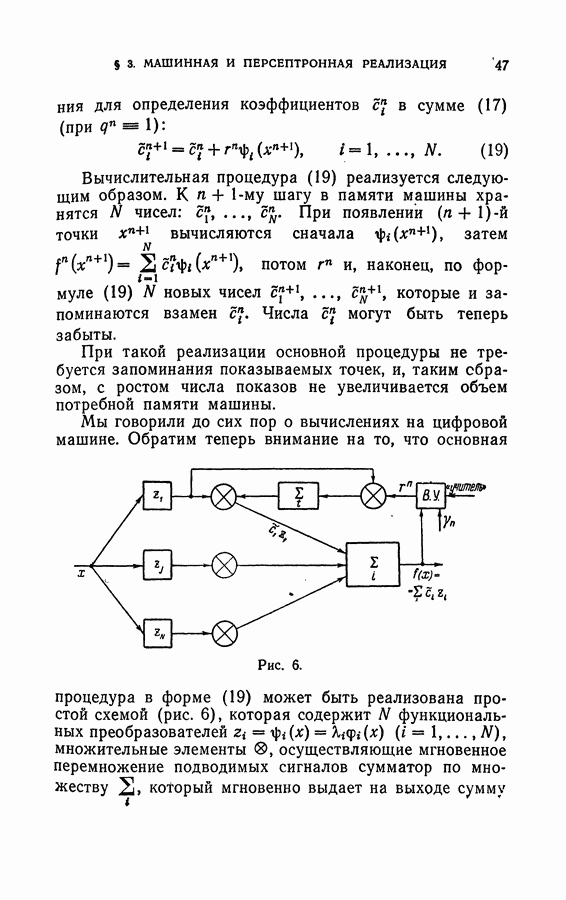
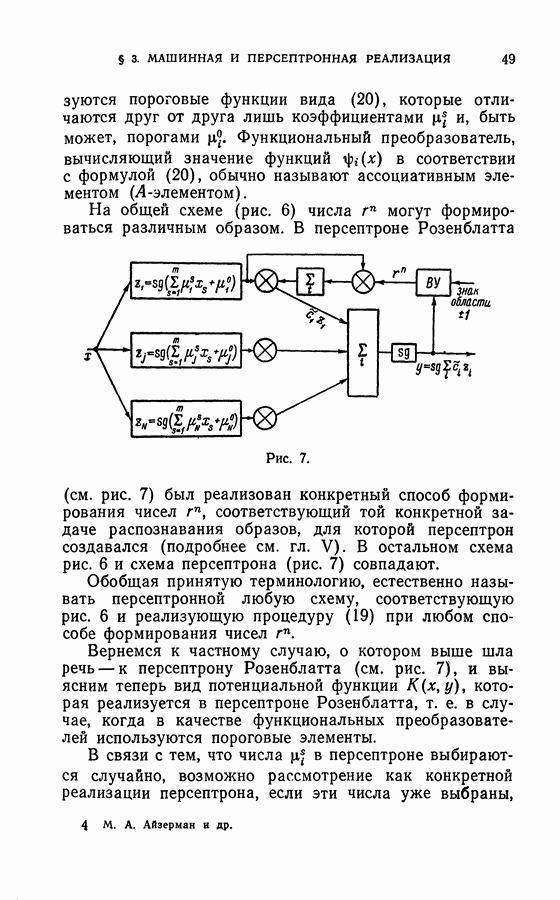
Глава VII. ВЕРОЯТНОСТНАЯ ЗАДАЧА ОБ ОБУЧЕНИИ МАШИН РАСПОЗНАВАНИЮ ОБРАЗОВ§ 1. Постановка задачиПусть на входе машины появляются ситуации, каждая из которых может относиться к одному из двух классов, А или В. В отличие от главы V, в процессе обучения одна и та же ситуация может быть при различных показах отнесена к разным классам. Предположим, что для каждой ситуации существуют вероятности принадлежности этой ситуации к классам Множество всех ситуаций, которые могут появиться на входе в автомат, образует пространство X. В соответствии с высказанным выше предположением объективно существуют заданные на всем пространстве X функции Детерминистская постановка задачи о разделении классов, сформулированная в главе V, и рассматриваемая здесь вероятностная постановка подобной задачи отличаются, во-первых, предположениями о классах Вероятностная постановка задачи охватывает детерминистскую постановку как частный случай, характеризующийся тем, что В качестве примера рассмотрим задачу об обучении машины прогнозированию исхода заболеваний по клиническим данным. Встречаются случаи, когда исход болезни может быть однозначно предсказан. В таких случаях возникает детерминистская задача, описанная в главе результате обучения правильно определяла вероятность исхода в новых случаях, то как раз и возникает задача, рассматриваемая в этой главе. В качестве технического примера можно привести типовую задачу об обнаружении какого-либо объекта локатором на фоне помех. Одна и та же «картинка», появляющаяся на экране локатора, может из-за сильных помех соответствовать как наличию, так и отсутствию обнаруживаемого объекта. Поэтому с каждой «картинкой» связывается лишь вероятность (степень достоверности) наличия объекта. Задача состоит в том, чтобы по отдельным наблюдаемым в процессе обучения случаям, когда факт наличия или отсутствия объекта точно установлен, научить машину правильно определять степень достоверности наличия той же ситуации для новых «картинок». Возможны два пути решения задачи об аппроксимации степеней достоверности Первый путь связан с использованием формулы Байеса и заключается в следующем. По показанным в процессе обучения точкам первоначально восстанавливаются не функции По окончании процесса обучения, при появлении новой точки х, степени достоверности, представляющие собой условные вероятности принадлежности классам
где Поскольку вероятности При таком способе аппроксимации степеней достоверности необходимо сделать некоторые предположения о классе функций, к которому принадлежат аппроксимируемые плотности вероятности Задача аппроксимации условных плотностей вероятности Могут быть предложены алгоритмы восстановления Любой метод аппроксимации плотности вероятности связан с введением предположений, обычных для аппроксимационных методов. Эти предположения связаны с требованием «достаточной гладкости», «нечрезмерной вычурности» аппроксимируемой функции; различные методы аппроксимации отличаются тем, как формализируется интуитивное предположение о «достаточной гладкости» и как такое предположение используется для построения алгоритма. Поэтому только в тех случаях, когда можно предполагать, что функции В ряде случаев — и такие случаи часто встречаются на практике — класс функций, к которому принадлежат плотности вероятности
В § 3 этой главы описываются алгоритмы, позволяющие при обычных для метода потенциальных функций предположениях относительно вида функций
|
 |
Оглавление
|


































































































































































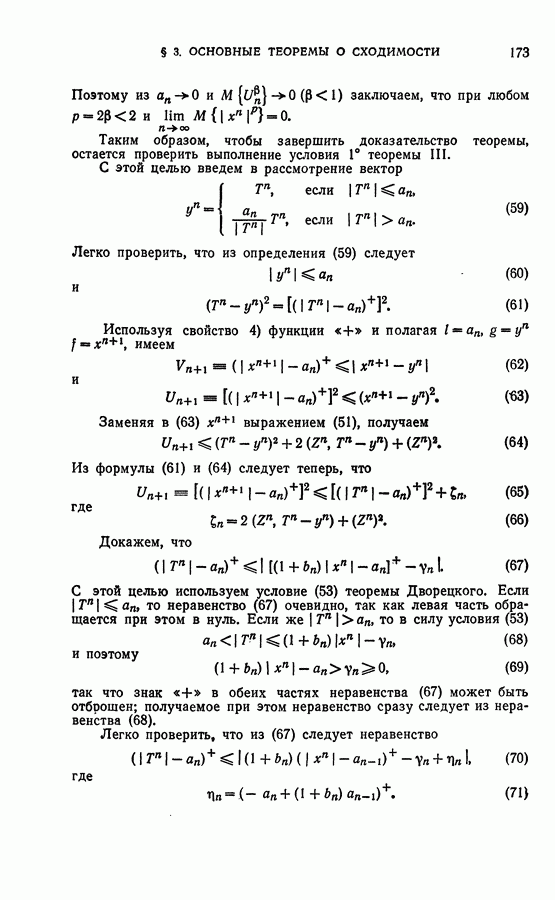













































































































































































































 и в процессе обучения каждая ситуация относится к А или В в соответствии с этими вероятностями.
и в процессе обучения каждая ситуация относится к А или В в соответствии с этими вероятностями.
 вероятности того, что точка х принадлежит соответственно классу
вероятности того, что точка х принадлежит соответственно классу  В. Эти функции в дальнейшем будем называть «степенями достоверности» принадлежности точки х классам А или В. Задача состоит в том, чтобы по появляющимся в процессе обучения точкам и по информации, которая сообщается «учителем» о том, к какому множеству (А или В) он относит эти точки, аппроксимировать
В. Эти функции в дальнейшем будем называть «степенями достоверности» принадлежности точки х классам А или В. Задача состоит в том, чтобы по появляющимся в процессе обучения точкам и по информации, которая сообщается «учителем» о том, к какому множеству (А или В) он относит эти точки, аппроксимировать  как функции, заданные на всем пространстве
как функции, заданные на всем пространстве 
 и, во-вторых, характером информации, сообщаемой машине в процессе обучения. Именно, в главе V предполагалось, что в пространстве X объективно существуют непересекающиеся множества точек (например,
и, во-вторых, характером информации, сообщаемой машине в процессе обучения. Именно, в главе V предполагалось, что в пространстве X объективно существуют непересекающиеся множества точек (например,  , и что поэтому всегда существуют разделяющие их функции; при показе точек из А или В учитель достоверно сообщает, к какому множеству они принадлежат; цель обучения состоит в построении какой-либо из этих разделяющих функций, т. е. функции, принимающей положительные значения на всех (а не только показанных в процессе обучения) точках из
, и что поэтому всегда существуют разделяющие их функции; при показе точек из А или В учитель достоверно сообщает, к какому множеству они принадлежат; цель обучения состоит в построении какой-либо из этих разделяющих функций, т. е. функции, принимающей положительные значения на всех (а не только показанных в процессе обучения) точках из  и отрицательные значения на всех точках из В. В настоящей же главе предполагается, что множества
и отрицательные значения на всех точках из В. В настоящей же главе предполагается, что множества  могут пересекаться. Поэтому не существует разделяющей их функции, но существуют указанные выше функции — степени достоверности, в связи с чем указание учителя о принадлежности точки к А или В не является достоверным. Цель же процесса обучения состоит в аппроксимации этих функций— степеней достоверности.
могут пересекаться. Поэтому не существует разделяющей их функции, но существуют указанные выше функции — степени достоверности, в связи с чем указание учителя о принадлежности точки к А или В не является достоверным. Цель же процесса обучения состоит в аппроксимации этих функций— степеней достоверности.
 принимают лишь значения, равные 0 или 1 на точках из А или В.
принимают лишь значения, равные 0 или 1 на точках из А или В.
 Часто, однако, клинические данные не дают оснований для однозначного предсказания исхода болезни, однако накопленная опытом медицины статистика дает вероятности исхода болезни. Если сообщать машине клинические данные о конкретных больных и исходы их болезней
Часто, однако, клинические данные не дают оснований для однозначного предсказания исхода болезни, однако накопленная опытом медицины статистика дает вероятности исхода болезни. Если сообщать машине клинические данные о конкретных больных и исходы их болезней  а от машины требовать, чтобы она в
а от машины требовать, чтобы она в

 а условные плотности вероятности появления в X точек из
а условные плотности вероятности появления в X точек из  и из
и из  соответственно. Одновременно оцениваются безусловные вероятности
соответственно. Одновременно оцениваются безусловные вероятности  и
и  появления точки из
появления точки из 
 при условии появления точки х, подсчитываются по формуле Байеса
при условии появления точки х, подсчитываются по формуле Байеса

 плотность вероятности появления
плотность вероятности появления 
 и
и  легко оцениваются, задача определения
легко оцениваются, задача определения  фактически сводится к аппроксимации плотностей вероятности
фактически сводится к аппроксимации плотностей вероятности 
 Так, часто предполагают, что эти плотности вероятности имеют известный вид (например, являются гауссовскими), и задача их аппроксимации сводится к статистической оценке заранее не известных параметров распределения.
Так, часто предполагают, что эти плотности вероятности имеют известный вид (например, являются гауссовскими), и задача их аппроксимации сводится к статистической оценке заранее не известных параметров распределения.
 является частным случаем общей задачи аппроксимации некоторой плотности вероятности
является частным случаем общей задачи аппроксимации некоторой плотности вероятности  появления точек в некотором пространстве
появления точек в некотором пространстве 
 в предположениях, обычных для развиваемых в этой книге идей. Соответствующая постановка задачи и описание одного из алгоритмов, решающих ее, содержится в следующем далее § 2.
в предположениях, обычных для развиваемых в этой книге идей. Соответствующая постановка задачи и описание одного из алгоритмов, решающих ее, содержится в следующем далее § 2.
 в каком-либо смысле являются «достаточно гладкими», использование формулы Байеса оправдано.
в каком-либо смысле являются «достаточно гладкими», использование формулы Байеса оправдано.
 таков, что их аппроксимация требует недопустимо большого числа показов, в то время как непосредственное восстановление
таков, что их аппроксимация требует недопустимо большого числа показов, в то время как непосредственное восстановление  может быть произведено по небольшому числу показов. Это имеет место, например, когда
может быть произведено по небольшому числу показов. Это имеет место, например, когда
 разрывны,
разрывны,  непрерывны и достаточно гладки. Поэтому способы непосредственной аппроксимации степени достоверности, не связанные с промежуточной аппроксимацией
непрерывны и достаточно гладки. Поэтому способы непосредственной аппроксимации степени достоверности, не связанные с промежуточной аппроксимацией  и с использованием формулы Байеса, вообще говоря, являются более предпочтительными.
и с использованием формулы Байеса, вообще говоря, являются более предпочтительными.
 аппроксимировать эти функции с помощью рекуррентных процедур.
аппроксимировать эти функции с помощью рекуррентных процедур.