Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
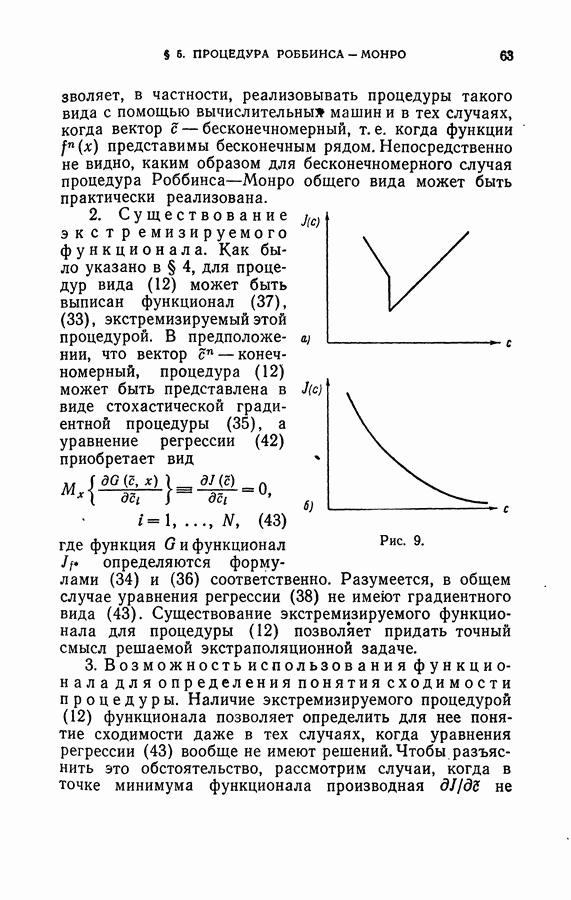
Глава VIII. ОБУЧЕНИЕ БЕЗ УЧИТЕЛЯ§ 1. Постановка задачиВ главе I было показано, как наряду с обычной задачей обучения машин распознаванию образов с использованием информации о том, к какому образу принадлежат объекты выборочной последовательности, показанной во время обучения (обучение машины с учителем), возникает и иная классификационная задача, названная там задачей обучения без учителя. Задача такого рода ставится следующим образом: машине одновременно либо последовательно предъявляются объекты; никакой информации о том, к какому классу каждый из показываемых объектов принадлежит, машине не сообщается. Цель машины состоит в том, чтобы классифицировать эти объекты по их «схожести», разделив таким образом все множество показанных объектов на классы «похожих» между собой объектов. Решение так поставленной задачи предопределяет необходимость формализовать интуитивное понятие «схожесть». Это интуитивное понятие употребляется человеком в различных аспектах и, соответственно, возможны различные пути для его формализации. Мы здесь рассмотрим такое понимание «схожести» и такой путь для формализации этого понятия, который естественно вытекает из геометрических представлений, развиваемых в этой книге. Как и в случае задачи обучения с учителем, введем в рассмотрение метрическое пространство X и отождествим каждый объект с точкой этого пространства. С точки зрения этих представлений естественно считать два объекта тем более «похожими» между собой, чем ближе соответствующие им точки в смысле введенной в пространстве X метрики. Конечно, разумность такого понимания «схожести» определяется тем, в какой мере введенная в пространстве X метрика адекватна конкретной рассматриваемой задаче. Вопрос о выборе метрики для каждой конкретной задачи — творческий акт, и вопрос о возможности алгоритмизации его здесь не ставится и не решается. Указанное выше отождествление понятия «схожести» объектов с близостью соответствующих им точек в пространстве приводит к представлению о том, что классу «схожих» объектов соответствует «компактное» множество точек в пространстве X — «кучка», а разным классам соответствуют удаленные друг от друга «кучки» в этом пространстве (рис. 17). Возможна и другая трактовка понятия «класса схожих объектов». Рассмотрим, например, рис. 18, где заштрихованные области достаточно плотно заполнены показанными точками.
Рис. 17.
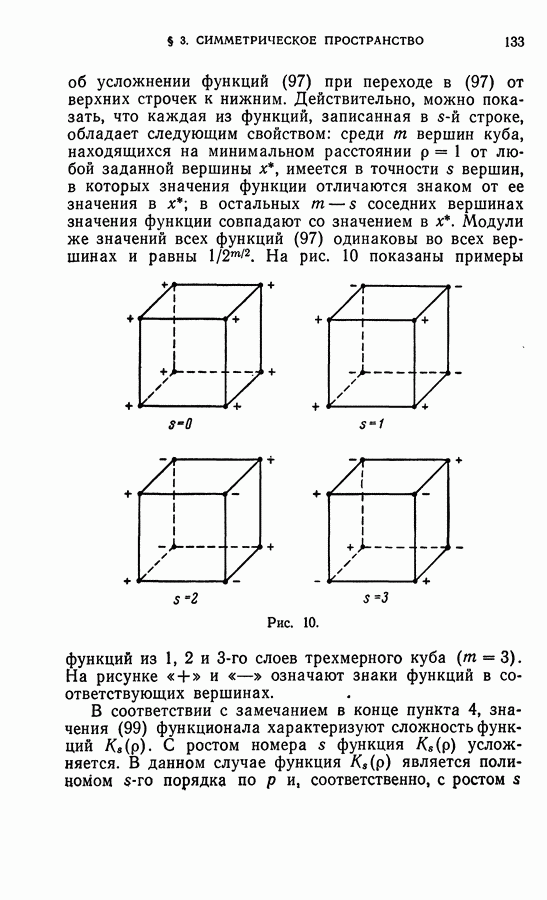
Рис. 18. При этом хотя расстояние между точками Из изложенных выше представлений (см. рис. 17 и 18) следует, что само взаимное расположение точек в пространстве уже содержит в себе информацию о том, каким образом можно было бы разделить показанные точки на классы. Это делает осмысленным саму постановку задачи обучения без учителя. Рис. 17 и 18 соответствует «чистым» идеализированным случаям. Рассмотрим теперь рис. 19 и 20, на которых, помимо точек, лежащих «кучно» (области таких точек выделены пунктиром), содержатся также точки, разбросанные по пространству редко, «не кучно». В этом случае естественно «не обращать внимания» на эти «редкие» точки и производить классификацию так же, как и в случаях, представленных на рис. 17 и 18 соответственно.
Рис. 19.
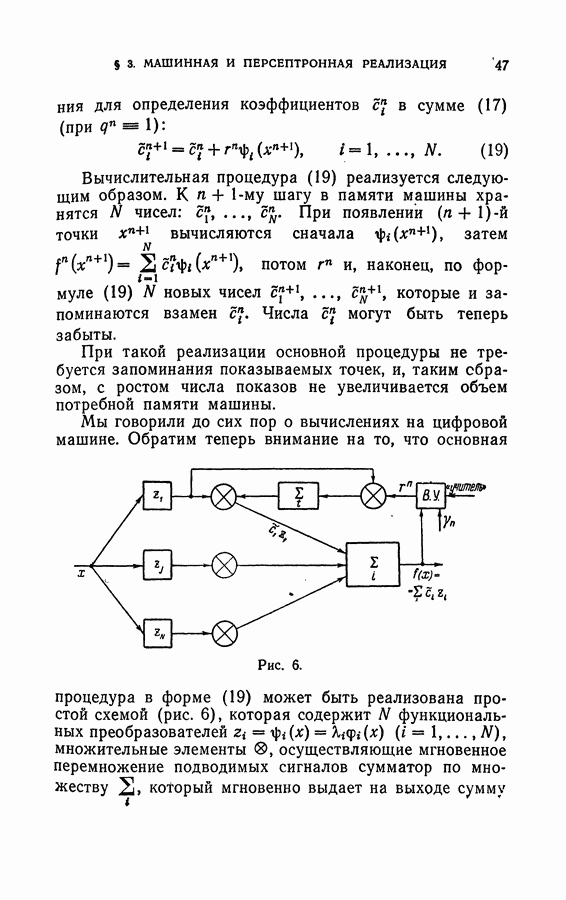
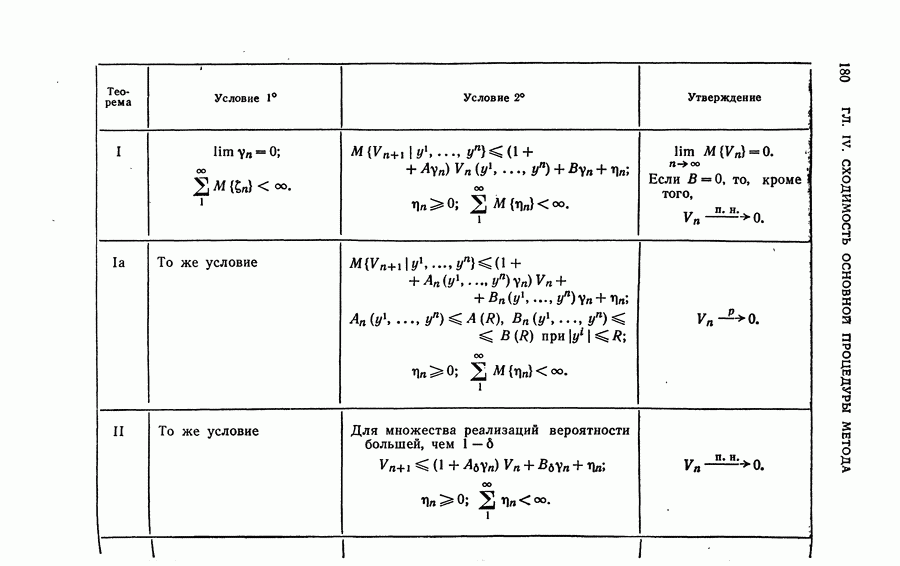
Рис. 20. В связи с этим машина, реализующая алгоритмы обучения без учителя, должна уметь выделять области с высокой плотностью точек (области «кучности») и не обращать внимания на области, где плотность точек мала. Поэтому при точной постановке задачи естественно использовать вероятностные представления, рассматривая конкретное предъявленное расположение точек как реализацию случайного процесса появления точек, порождаемого некоторой плотностью вероятности, заданной в пространстве X. При этом областям с большой «кучностью» соответствуют большие значения плотности вероятности. В результате задача обучения без учителя, соответствующая рис. 17 и 19, сводится к выделению удаленных друг от друга «горбов» плотности распределения (рис. 21), а в случае, соответствующем рис. 18 и 20— к поиску «ложбин» этой функции (рис. 22). Для того чтобы обнаружить удаленные друг от друга «горбы», нужно рассматривать функцию плотности распределения глобально, т. е. обозревая сразу большие области пространства
Рис. 21.
Рис. 22. При другой постановке задачи, когда требуется отыскивать и прослеживать узкие ложбины, приходится изучать локальные свойства функции распределения, принимая во внимание даже мелкие детали рельефа в окрестности ложбин. В связи с этим охарактеризованные выше подходы к постановке задачи обучения без учителя удобно назвать глобальным и локальным подходом. Далее в этой главе будет рассмотрен исключительно глобальный подход. Так же как и в случае обучения с учителем, рассмотренном в предыдущих главах этой книги, задачу обучения без учителя будем понимать как задачу построения разделяющей функции
Рис. 23. функционал так, чтобы минимизирующая функция Таким образом, постановку задачи обучения без учителя в рамках глобального подхода можно описать так. Пусть в последовательные моменты времени Поскольку различные функционалы достигают минимума на разных, вообще говоря, разделяющих функциях, естественно возникает проблема выбора функционала, адекватного задаче разделения «горбов» распределения Приступая теперь к рассмотрению примеров таких функционалов, ограничимся случаем, когда X есть евклидово пространство следующие обозначения. Множество тех точек
где
будут относиться к нормированным моментам по множествам В качестве первого примера рассмотрим функционал
где
есть просто дисперсии распределений вероятностей по множествам особенно ясным, если представить функционал (2) в эквивалентной форме:
Действительно, минимизация выражения (3) означает минимизацию «среднего расстояния» между парами точек в пределах каждого из множеств В качестве второго примера задания функционала
минимизация которого имеет примерно тот же смысл, что и для функционала (2). Третьим примером функционала, который может быть использован в задаче обучения без учителя, является функционал
максимум которого обеспечивает максимальное расстояние между средними точками множеств Комбинируя введенные выше функционалы (2), (4), (5), можно конструировать новые функционалы. Так, например, иногда используется функционал
максимизация которого в соответствии с изложенными выше соображениями обеспечивает требуемое разделение. Нам понадобится далее выражение функционалов
В следующих двух параграфах мы будем в основном иметь дело лишь с функционалом (2а) и лишь кратко касаться функционалов другого вида. В § 2 будет доказана теорема, устанавливающая соответствие между видом экстремизируемого функционала и характером экстремизирующей поверхности. В § 3 и 4 рассматривается вопрос о построении рекуррентного алгоритма, решающего задачу обучения без учителя в указанном выше смысле, и об его сходимости.
|
 |
Оглавление
|


































































































































































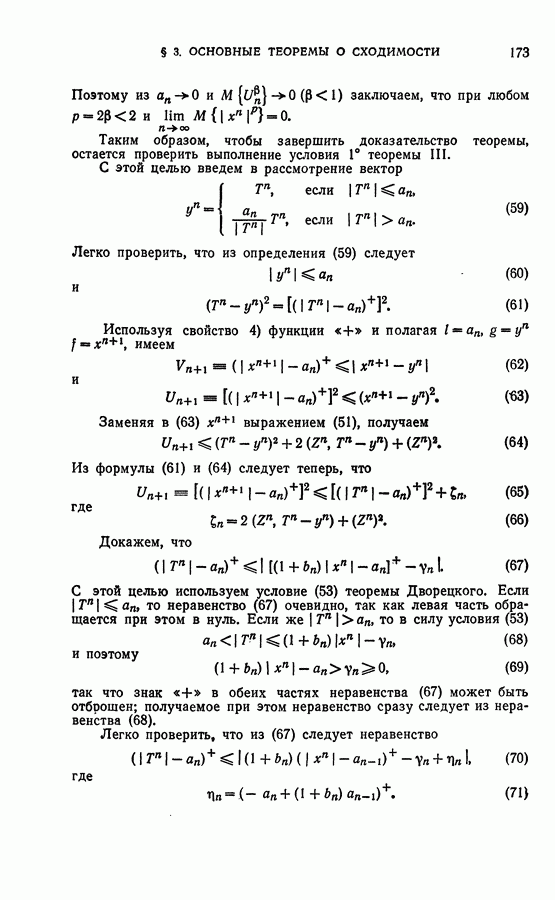































































































































































































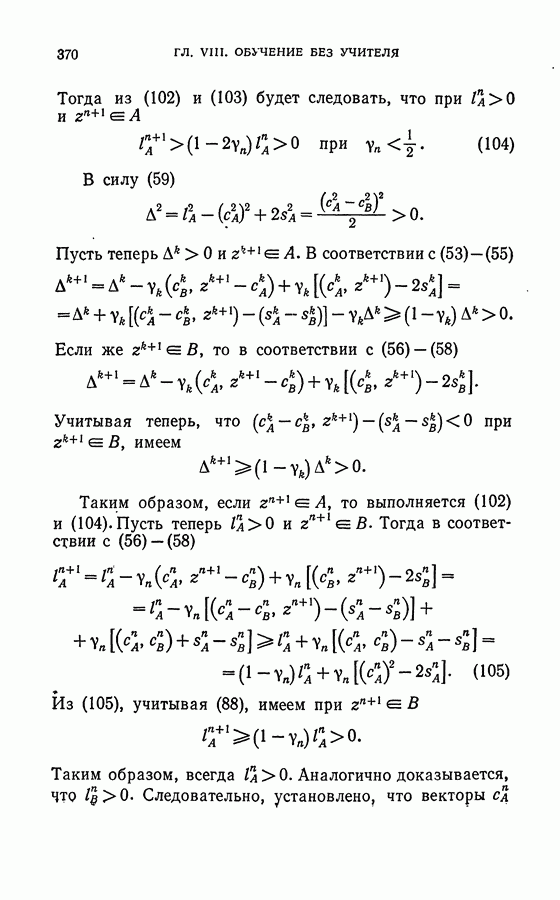
















 больше, чем расстояние между точками
больше, чем расстояние между точками  и с точки зрения развитого выше представления здесь вообще не могут быть выделены два класса объектов, тем не менее, может оказаться разумным считать принадлежащими к одному классу точки
и с точки зрения развитого выше представления здесь вообще не могут быть выделены два класса объектов, тем не менее, может оказаться разумным считать принадлежащими к одному классу точки  например, потому, что из точки
например, потому, что из точки  в точку
в точку  возможен «непрерывный» переход по показанным точкам, а из точки
возможен «непрерывный» переход по показанным точкам, а из точки  в точку
в точку  такого перехода нет.
такого перехода нет.


 При этом можно не интересоваться мелкими деталями рельефа (рис. 23).
При этом можно не интересоваться мелкими деталями рельефа (рис. 23).


 такой, что в точках, отнесенных к одному и тому же классу, она имеет одинаковый знак. Пусть теперь задан некоторый функционал, ставящий в соответствие каждой разделяющей функции
такой, что в точках, отнесенных к одному и тому же классу, она имеет одинаковый знак. Пусть теперь задан некоторый функционал, ставящий в соответствие каждой разделяющей функции  некоторую числовую оценку. Минимизация этого функционала выделяет некоторую конкретную разделяющую функцию
некоторую числовую оценку. Минимизация этого функционала выделяет некоторую конкретную разделяющую функцию  Если бы удалось подобрать
Если бы удалось подобрать

 разделяла удаленные друг от друга «горбы» плотности распределения, то глобальная задача обучения без учителя могла бы быть понята как задача минимизации такого функционала.
разделяла удаленные друг от друга «горбы» плотности распределения, то глобальная задача обучения без учителя могла бы быть понята как задача минимизации такого функционала.
 появляются точки
появляются точки  из X независимо и в соответствии с некоторым распределением вероятности
из X независимо и в соответствии с некоторым распределением вероятности  которое предполагается заранее не известным. Пусть далее задан подходящим образом выбранный функционал
которое предполагается заранее не известным. Пусть далее задан подходящим образом выбранный функционал  от разделяющей функции, зависящий от
от разделяющей функции, зависящий от  Требуется определить последовательность разделяющих функций
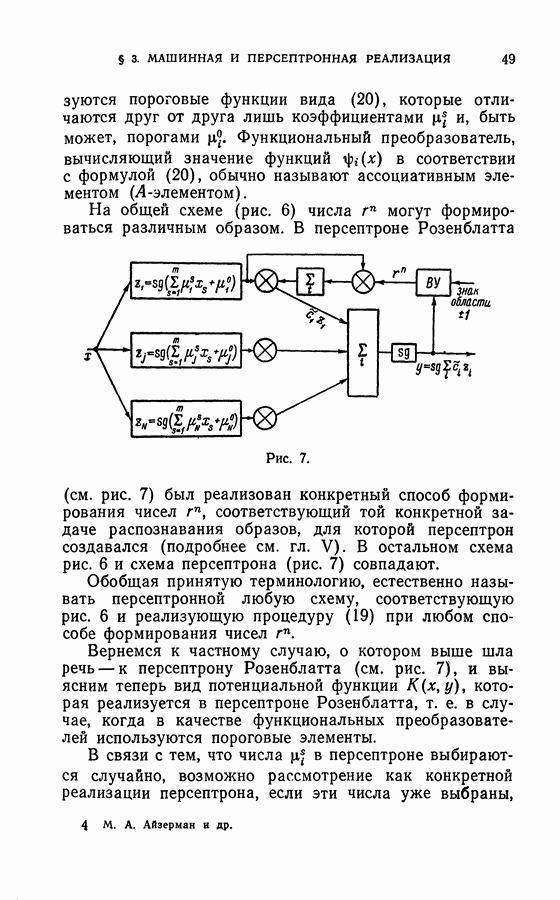
Требуется определить последовательность разделяющих функций  так, чтобы последовательность значений функционала
так, чтобы последовательность значений функционала  сходилась бы к минимальному (или максимальному) значению
сходилась бы к минимальному (или максимальному) значению  При этом в каждый момент времени
При этом в каждый момент времени  единственная информация, которая может быть использована для построения приближения
единственная информация, которая может быть использована для построения приближения  состоит в знании точек
состоит в знании точек  появившихся к этому шагу. Разумеется, если бы распределение
появившихся к этому шагу. Разумеется, если бы распределение  было бы известно заранее, задача минимизации функционала
было бы известно заранее, задача минимизации функционала  решалась бы обычными методами вариационного исчисления. Вся же специфика задачи в рассматриваемом случае и заключается в том, что приходится определять минимум функционала, зная лишь реализации
решалась бы обычными методами вариационного исчисления. Вся же специфика задачи в рассматриваемом случае и заключается в том, что приходится определять минимум функционала, зная лишь реализации 
 Такие функционалы в действительности можно построить — ниже проводятся примеры таких функционалов. Разумеется, выбор такого функционала — задача творческая, и в литературе рассматриваются функционалы различного вида.
Такие функционалы в действительности можно построить — ниже проводятся примеры таких функционалов. Разумеется, выбор такого функционала — задача творческая, и в литературе рассматриваются функционалы различного вида.
 в котором задано распределение вероятностей с плотностью
в котором задано распределение вероятностей с плотностью  и введем
и введем
 для которых
для которых  обозначим через
обозначим через  множество точек, для которых
множество точек, для которых  через В. Через
через В. Через  и
и  обозначаются ненормированные
обозначаются ненормированные  моменты, вычисленные по множествам
моменты, вычисленные по множествам  соответственно:
соответственно:

 понимается как скаляр
понимается как скаляр  если
если  четное, и как вектор
четное, и как вектор  если
если  нечетное; поэтому
нечетное; поэтому  есть скаляр или вектор, если
есть скаляр или вектор, если  четно или соответственно нечетно. Как обычно, при
четно или соответственно нечетно. Как обычно, при  есть просто вероятности
есть просто вероятности  и
и  множеств
множеств  Обозначения
Обозначения

 соответственно.
соответственно.


 соответственно. Поэтому функционал (2) имеет смысл «средней дисперсии» по
соответственно. Поэтому функционал (2) имеет смысл «средней дисперсии» по  В связи с тем, что дисперсия тем меньше, чем более «кучно» распределены точки, минимизация средней дисперсии означает наилучшее разделение в этом смысле двух «кучных» областей. Это обстоятельство становится
В связи с тем, что дисперсия тем меньше, чем более «кучно» распределены точки, минимизация средней дисперсии означает наилучшее разделение в этом смысле двух «кучных» областей. Это обстоятельство становится


 приведем следующую модификацию функционала (2):
приведем следующую модификацию функционала (2):


 Очевидно, что если плотность вероятности
Очевидно, что если плотность вероятности  имеет два четко выраженных и удаленных друг от друга «горба», то максимизация функционала (5) обеспечивает их разделение.
имеет два четко выраженных и удаленных друг от друга «горба», то максимизация функционала (5) обеспечивает их разделение.

 через ненормированные моменты
через ненормированные моменты  Эти выражения имеют вид
Эти выражения имеют вид
