Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
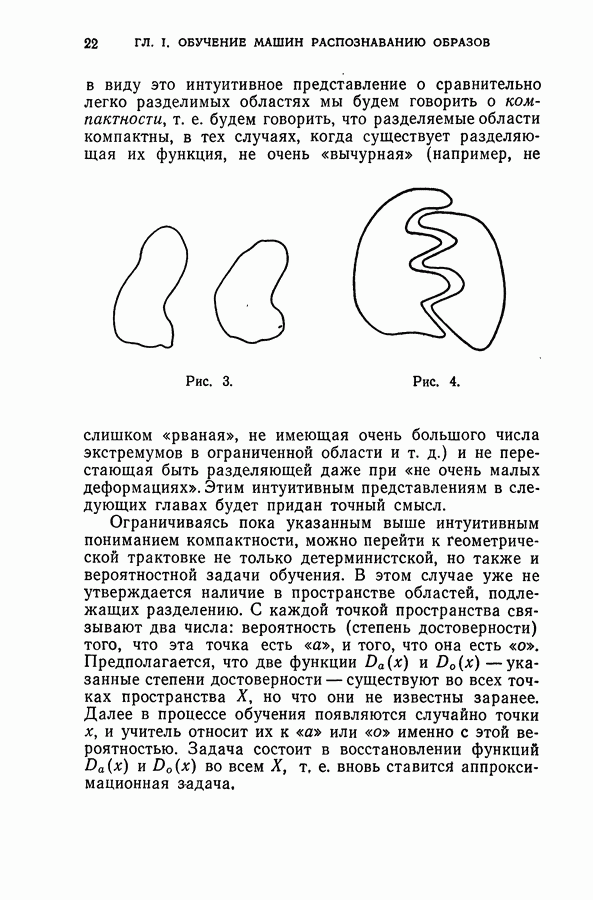
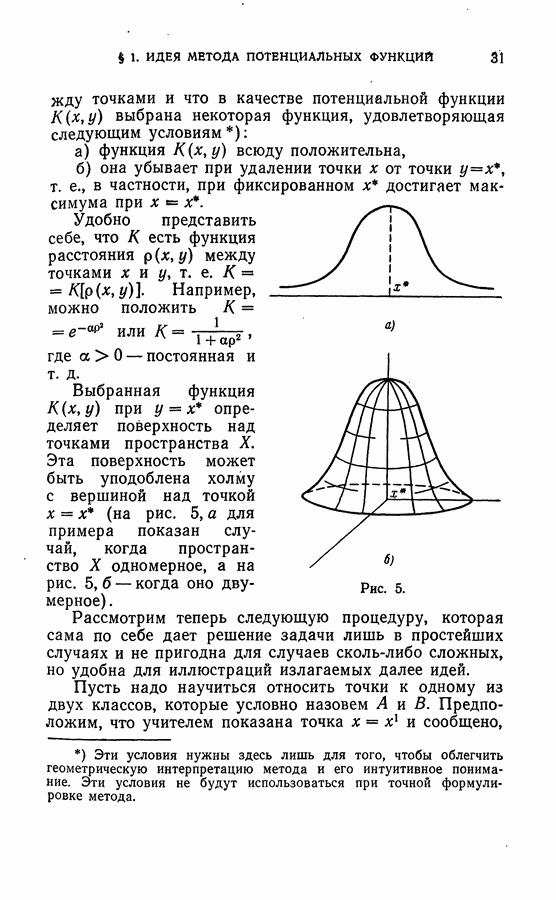
§ 3. Разделение сложных образов. Признаки. Лингвистический подход к задачам распознаванияГеометрическая интерпретация задачи распознавания образов, описанная в конце предыдущего параграфа, сводит задачу обучения распознаванию к аппроксимации разделяющей поверхности. Такое сведение удобно и исчерпывает задачу в тех случаях, когда речь идет о простых образах, т. е. когда подлежащие разделению области достаточно «разнесены» в пространстве, а сами области компактны, т. е. их границы не чересчур «вычурны». В более сложных случаях требуется либо предварительно упростить задачу, либо же искать иные пути ее решения, не связанные с аппроксимацией разделяющих поверхностей. 1. Упрощение задачи разделения путем преобразования пространства. Наряду с пространством X, о котором выше шла речь, рассмотрим пространство У и предположим, что каждой точке
Области, соответствующие различным образам и определенные в пространстве X, переводятся преобразованием (1) в области пространства У. Использование преобразования (1) для упрощения задачи связано с таким выбором функции В связи с тем, что преобразование (1) может не иметь однозначного обратного преобразования, переход в пространство У может быть использован для уменьшения размерности пространства, в котором должна решаться какая-либо из упомянутых выше аппроксимационных задач. В качестве примера представим себе, что пространство
Функции Характер областей, подлежащих разделению в пространстве X, ограничен лишь самыми общими соображениями о компактности и может варьироваться в широких пределах. Как бы ни было выбрано преобразование (1), всегда можно указать в пространстве X области, которые переводятся этим преобразованием в более «разнесенные» и более компактные, а значит, и легче разделимые области пространства в предыдущем параграфе шла речь, найти преобразование (1), упрощающее каждую конкретную задачу, т. е. выработать для этой задачи свои признаки. В том случае, когда пространство У есть пространство вершин 2. Лингвистический подход к задаче распознавания образов. Наряду с подходом, которому посвящена эта книга и который связан с описанными выше аппроксимационными задачами, существует иной подход к задачам обучения — его называют лингвистическим. Поясним лингвистический подход, вновь используя в качестве примера распознавание зрительных образов. Учитель предъявляет машине изображения, принадлежащие разным образам В машину заложен набор исходных понятий — типичных фрагментов, встречающихся на изображениях, и характеристик взаимного расположения фрагментов (например, таких как «слева», «сверху», «внутри» и т. д.) Эти исходные понятия образуют словарь машины, позволяющий строить различные логические высказывания. Задача машины состоит в том, чтобы из большого количества высказываний, которые могли бы быть построены с использованием этих понятий, отобрать наиболее существенные для данного конкретного случая. Далее, просматривая конечное и, по возможности, небольшое число объектов из каждого класса, машина должна построить описания этих классов. Построенные описания классов должны быть столь полными, чтобы машина для каждого показанного изображения, построив его описание и сравнив это описание с описанием классов, могла решить вопрос о том, к какому классу данное изображение относится. При реализации лингвистического подхода возникают две проблемы: проблема построения исходного словаря и проблема построения описания из элементов данного словаря. Проблема построения описаний является уже не аппроксимационной, а лингвистической проблемой, и она не рассматривается в этой книге. Отметим только, что трудности, которые возникают при решении этой проблемы, еще далеко не преодолены и, несмотря на большое число работ, эти методы не нашли еще широкого применения. Проблема выработки словаря распадается на две подзадачи. Первая подзадача состоит в выработке «имен существительных» для этого словаря, т. е. в отборе типичных фрагментов, встречающихся на изображениях и удобных для составления описания; эта подзадача может быть понята как аппроксимационная (см. следующий пункт этого параграфа), и для ее решения могут быть использованы методы, развиваемые в этой книге. Вторая подзадача связана с выработкой «имен прилагательных» и «наречий», т. е. понятий, определяющих взаимоотношение выделенных фрагментов изображений. Эта подзадача оказалась чрезвычайно сложной и до сих пор даже в принципе не решена. 3. Выработка словаря. Представим себе, что машина просматривает какое-либо изображение, но «глаз» машины устроен так, что он «видит» одновременно не все изображения, а некоторую его часть — фрагмент. То, что «видит» в данный момент машина, зависит от того, в какую точку нацелен «центр глаза». Если теперь случайным образом разбросать по изображению точки, куда последовательно нацеливается «глаз машины», то в результате будет отобрано несколько фрагментов. Поступим так не с одним, а с рядом изображений, принадлежащих тем классам, которые в конце концов подлежат разделению. В результате будет получено множество фрагментов. Среди этих фрагментов имеются похожие между собой. Задача заключается в том, чтобы определить, сколько классов «похожих» между собой фрагментов образуют отобранные фрагменты и каковы эти классы. Тогда каждый из этих классов может быть принят за одно «имя существительное». Для штриховых рисунков такими классами могут быть либо совокупность различных «перекрестий», либо «дужек», либо «концов линий», либо «кружков» и т. д. «Похожие» фрагменты в рецепторном пространстве «глаза» машины (например, в пространстве, соответствующем ее фотополю) образуют скопления точек, «кучки». Задача составления «имен существительных» в словаре сводится, таким образом, к задаче обучения распознаванию образов без учителя. Эта последняя задача понимается далее как аппроксимационная, и ей посвящена глава VIII. До сих пор, простоты ради, мы считали, что точки, куда «прицеливается глаз машины», выбираются случайно. Отбор фрагментов может быть значительно целенаправленнее, если отбирать их не случайно, а организовать поиск особо важных, «информативных» фрагментов. Но для этого понятие «информативный фрагмент» должно быть каким-либо образом формализовано. Имея в виду описать пример формализации этого понятия, введем в рассмотрение стандартное изображение. Это изображение полностью укладывается в поле зрения «глаза» машины и представляет собой пятно, максимально темное в центре и равномерно светлеющее к краям. Этому стандартному изображению в пространстве рецепторов соответствует некоторая фиксированная точка. При осмотре изображения каждому просматриваемому фрагменту в пространстве рецепторов соответствует своя точка, а значит, и свое расстояние до указанной выше фиксированной точки, соответствующей стандартному изображению. Тцким образом, это расстояние является функцией той точки, куда нацелен «глаз» машины, т. е. откуда вырезается фрагмент. Эта функция в некоторых местах просматриваемого изображения достигает экстремума — максимума или минимума. Фрагменты, соответствующие экстремальным точкам, т. е. наиболее «близкие» и наиболее «удаленные» от стандартного изображения принимаются за информативные. Опыт показал, что так выбираемые фрагменты являются содержательными, интересными. Таким образом, такая или какая-либо иная разумная формализация понятия «информативный фрагмент» в сочетании с методами обучения распознаванию образов без учителя позволяет автоматизировать один из наиболее трудных этапов лингвистического подхода — выработку словаря.
|
 |
Оглавление
|

































































































































































































































































































































































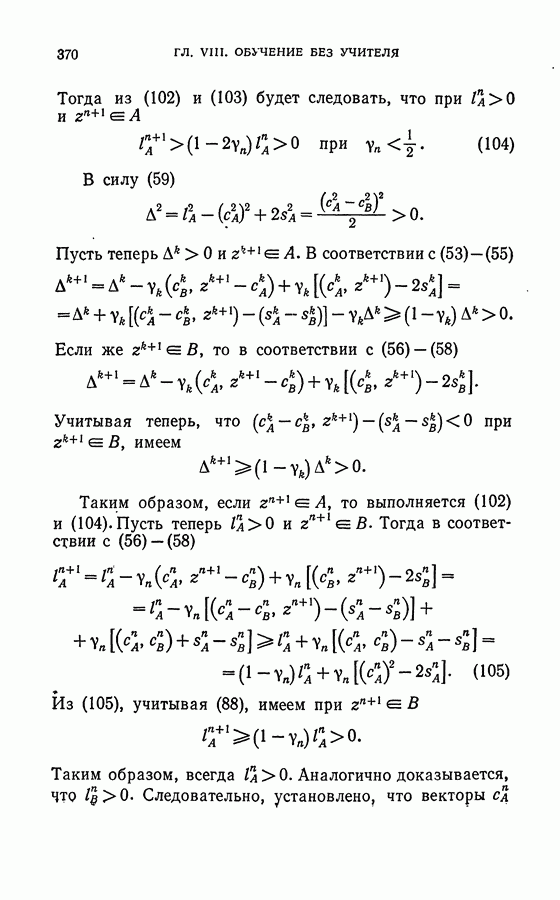














 соответствует вполне определенная точка
соответствует вполне определенная точка  , а обратное соответствие может быть и неоднозначным. Это значит, что существует преобразование
, а обратное соответствие может быть и неоднозначным. Это значит, что существует преобразование

 при котором расстояние между областями увеличивается, а сами области становятся более компактными, границы их более простыми, «менее вычурными».
при котором расстояние между областями увеличивается, а сами области становятся более компактными, границы их более простыми, «менее вычурными».
 -мерное евклидово пространство,
-мерное евклидово пространство,  пространство Хэмминга, т. е. пространство, состоящее из вершин
пространство Хэмминга, т. е. пространство, состоящее из вершин  -мерного куба (при этом
-мерного куба (при этом  может не совпадать с
может не совпадать с  в частности, быть значительно меньше
в частности, быть значительно меньше  ). В этом случае переменные
). В этом случае переменные  принимают одно из двух значений, например, —1 или
принимают одно из двух значений, например, —1 или  а преобразование (1) задается, например, системой уравнений вида
а преобразование (1) задается, например, системой уравнений вида

 могут пониматься тогда как признаки, как ответ на вопрос «имеется ли в предъявленном изображении признак
могут пониматься тогда как признаки, как ответ на вопрос «имеется ли в предъявленном изображении признак  Поэтому пространство У удобно называть пространством признаков. Естественно, и в общем случае преобразование (1) также можно рассматривать как переход к пространству признаков, считая, что относительно признаков можно не только отвечать на вопрос, есть они или нет, но и оценивать значением функции
Поэтому пространство У удобно называть пространством признаков. Естественно, и в общем случае преобразование (1) также можно рассматривать как переход к пространству признаков, считая, что относительно признаков можно не только отвечать на вопрос, есть они или нет, но и оценивать значением функции  «степень присутствия» признака в предъявленном изображении.
«степень присутствия» признака в предъявленном изображении.
 но можно всегда указать и такие области, разделимость которых лишь ухудшается в результате этого преобразования. Поэтому не существует универсального преобразования, пригодного для всех образов, которое можно было бы заранее заложить в программу машины. Если иметь в виду не машину, предназначенную для распознавания образов из какого-либо специального класса образов, а для решения общей задачи, то машина в процессе обучения должна сама, располагая лишь той информацией, о которой
но можно всегда указать и такие области, разделимость которых лишь ухудшается в результате этого преобразования. Поэтому не существует универсального преобразования, пригодного для всех образов, которое можно было бы заранее заложить в программу машины. Если иметь в виду не машину, предназначенную для распознавания образов из какого-либо специального класса образов, а для решения общей задачи, то машина в процессе обучения должна сама, располагая лишь той информацией, о которой
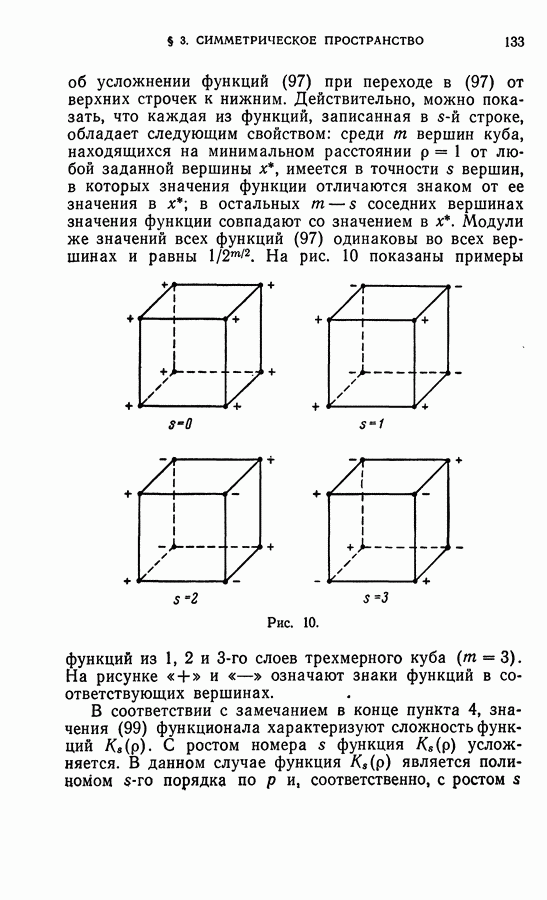
 -мерного куба (пространство Хэмминга), задача разделения областей в пространстве
-мерного куба (пространство Хэмминга), задача разделения областей в пространстве  может пониматься как задача построения логической функции при известных ее значениях в некоторых вершинах куба.
может пониматься как задача построения логической функции при известных ее значениях в некоторых вершинах куба.