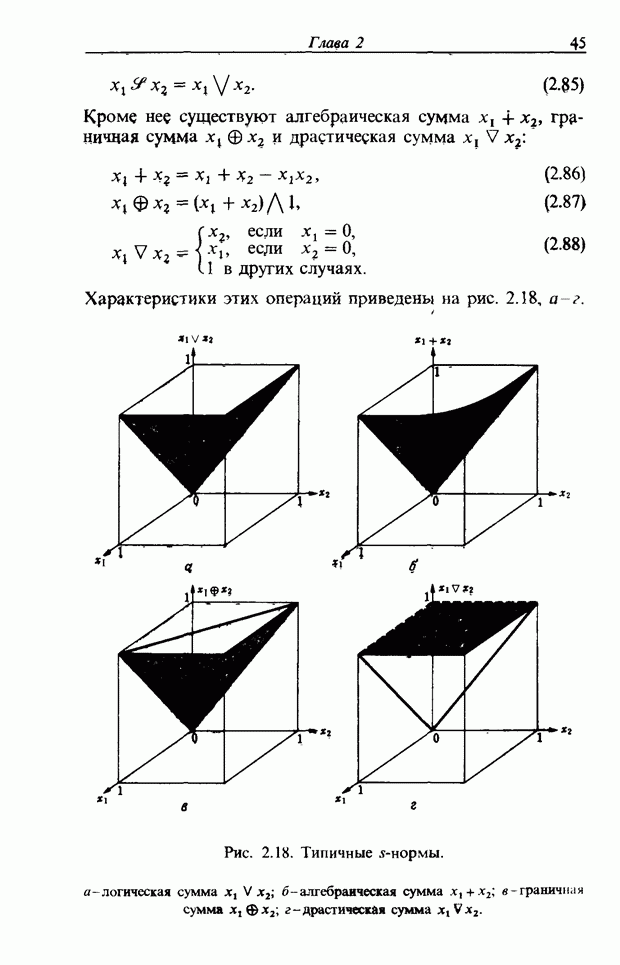
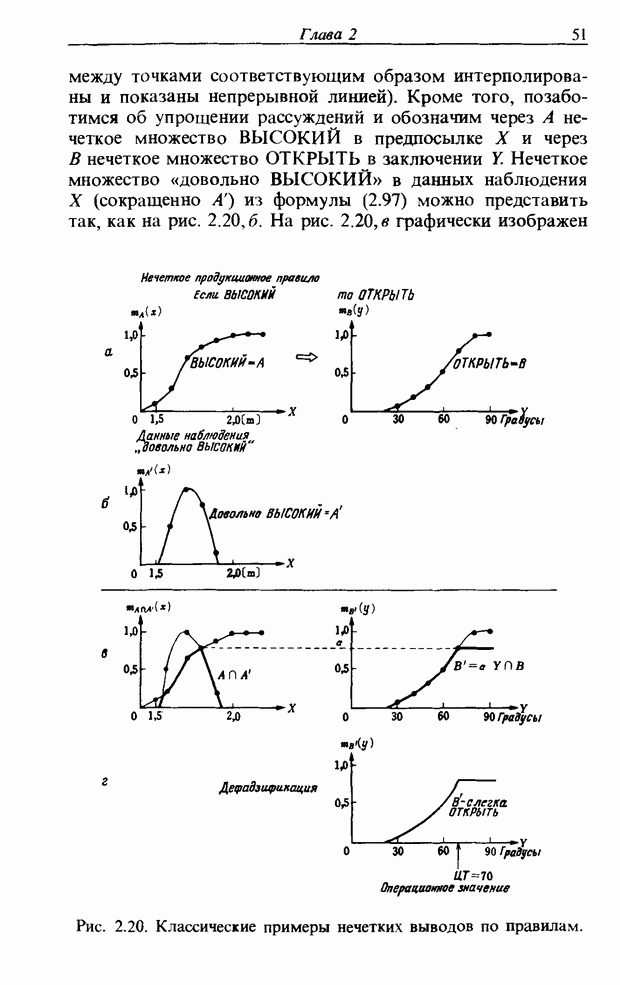
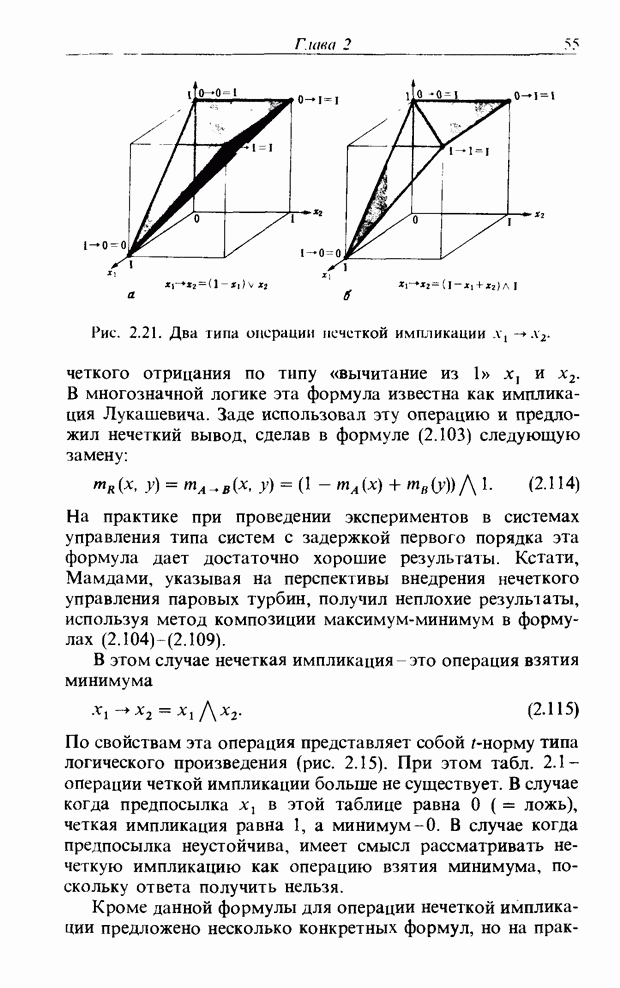
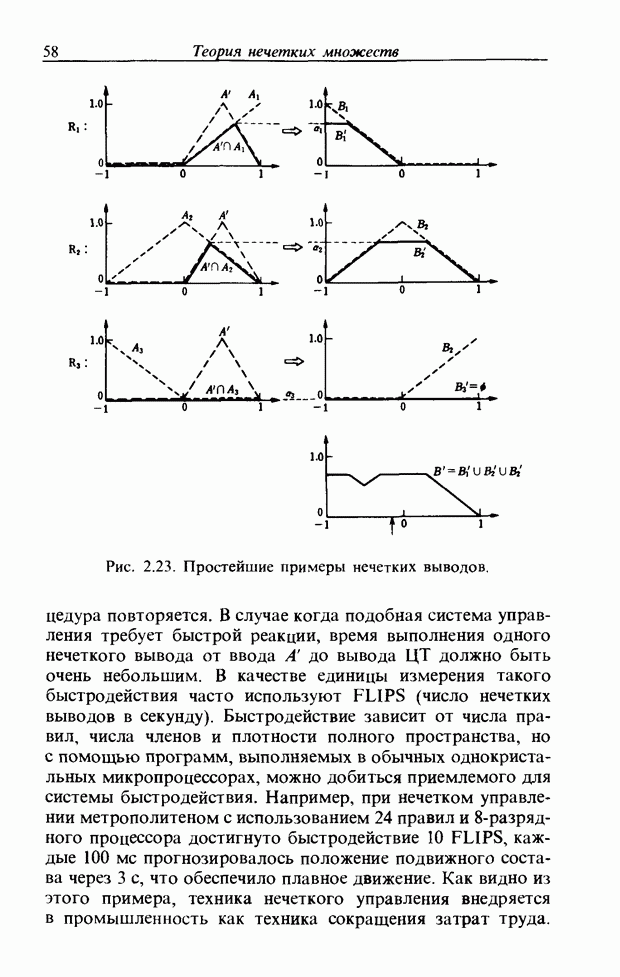
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
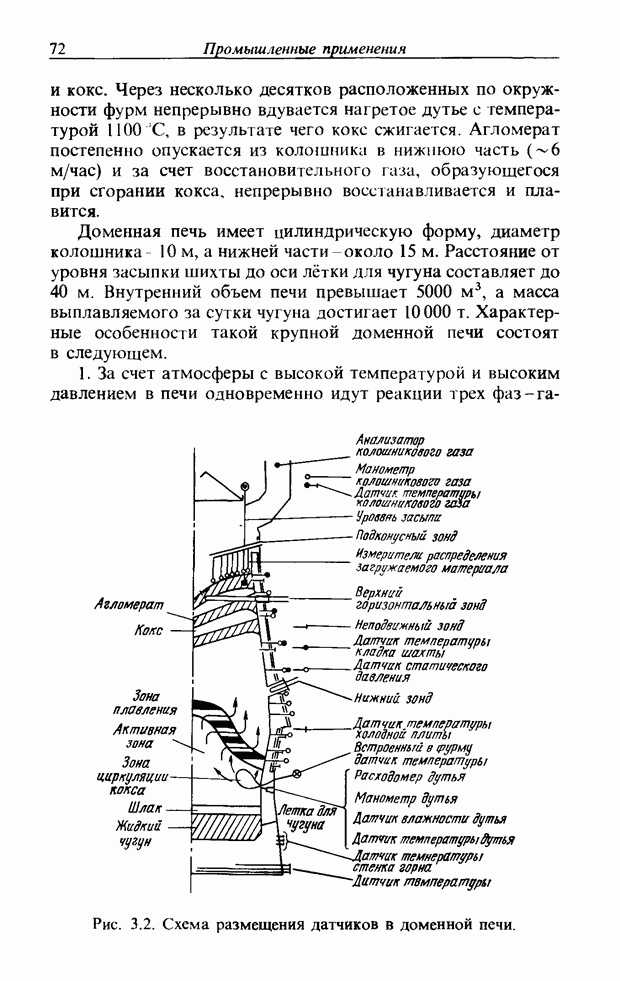
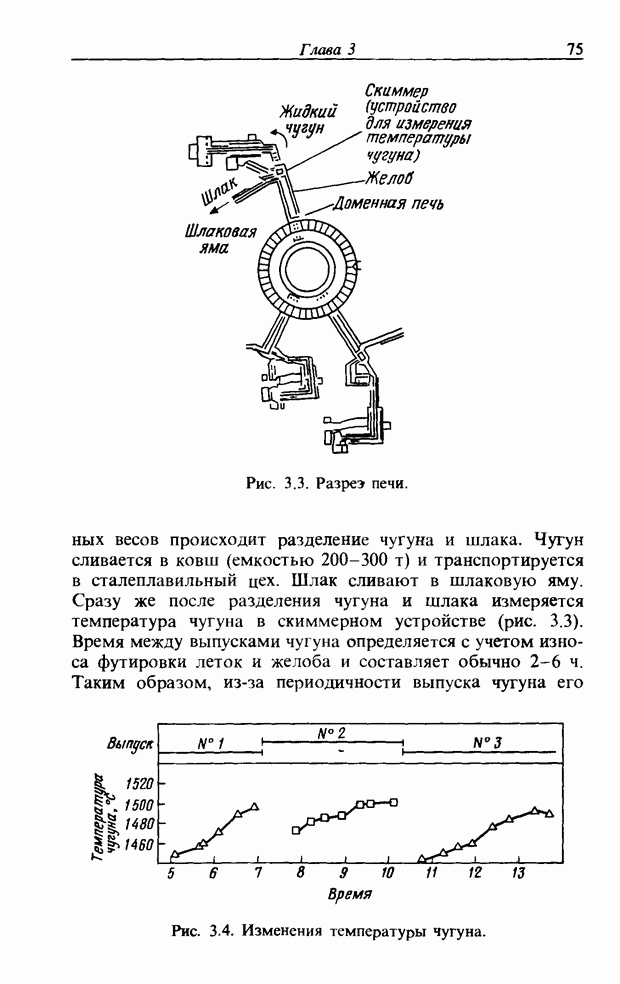
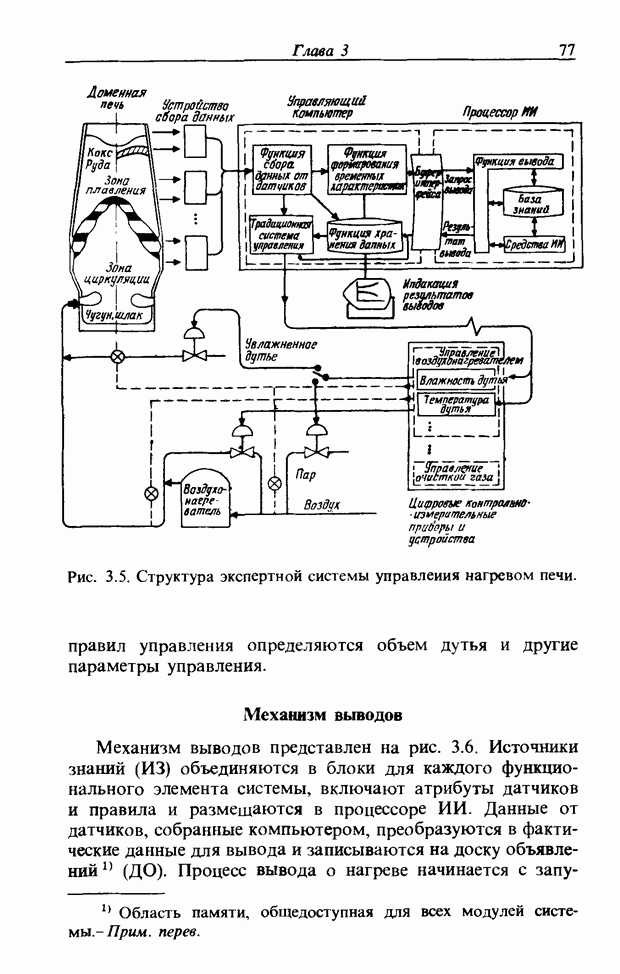
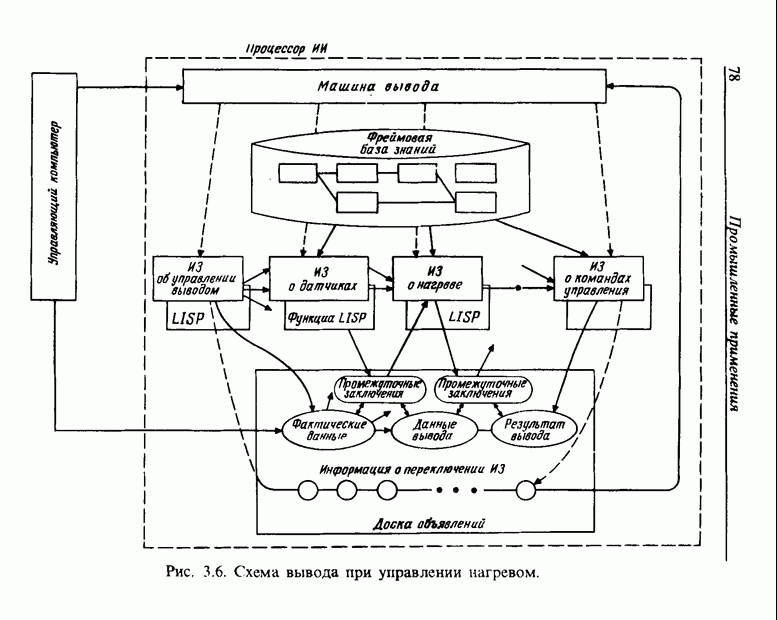
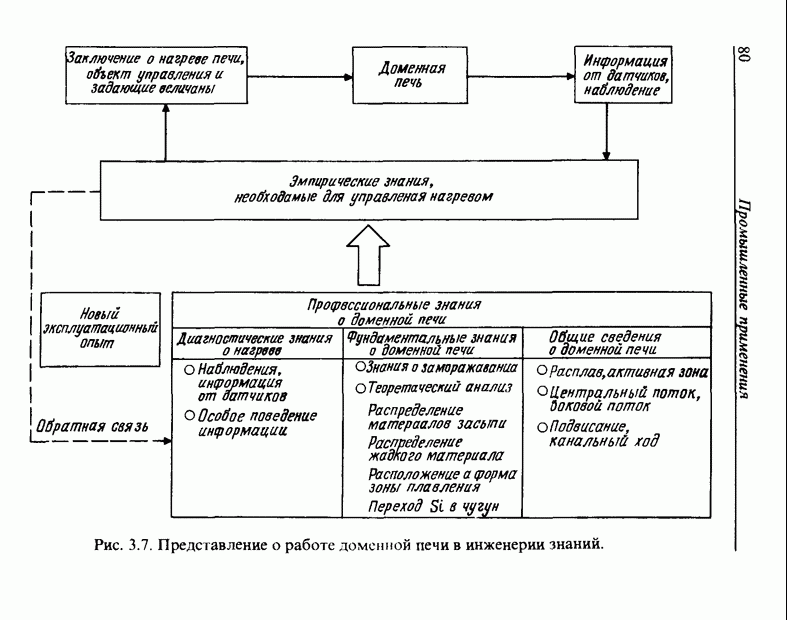
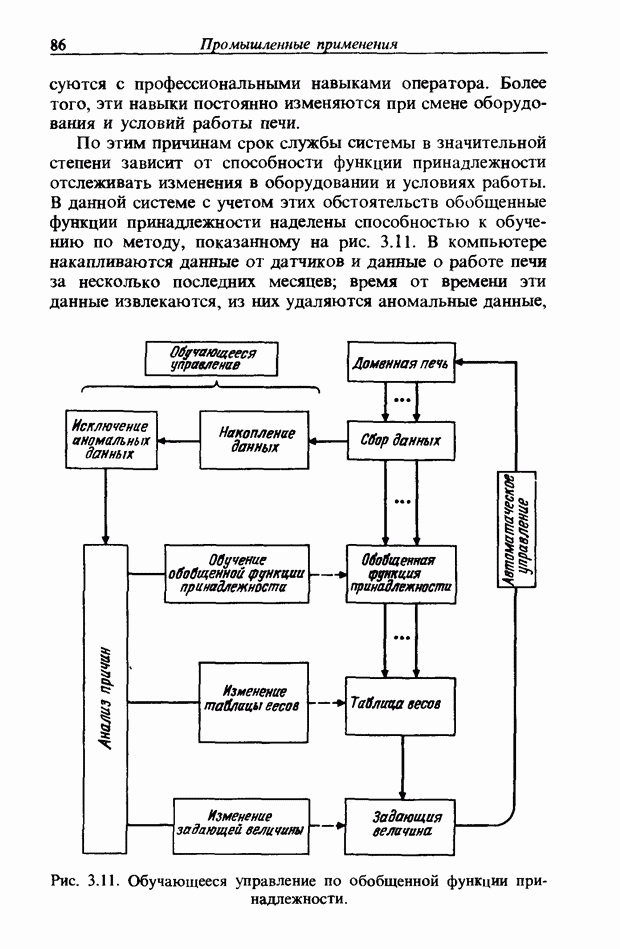
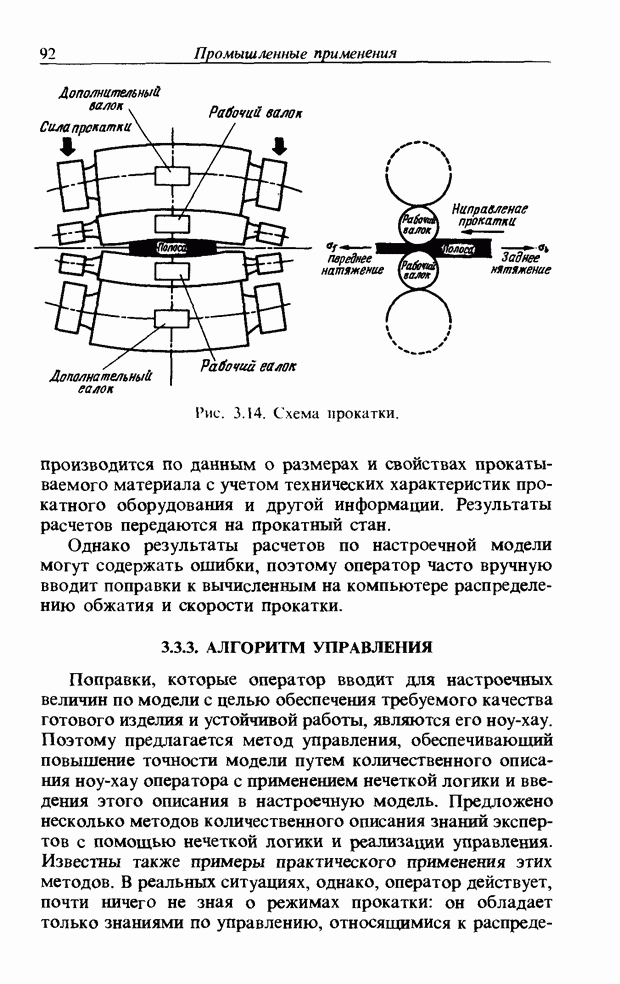
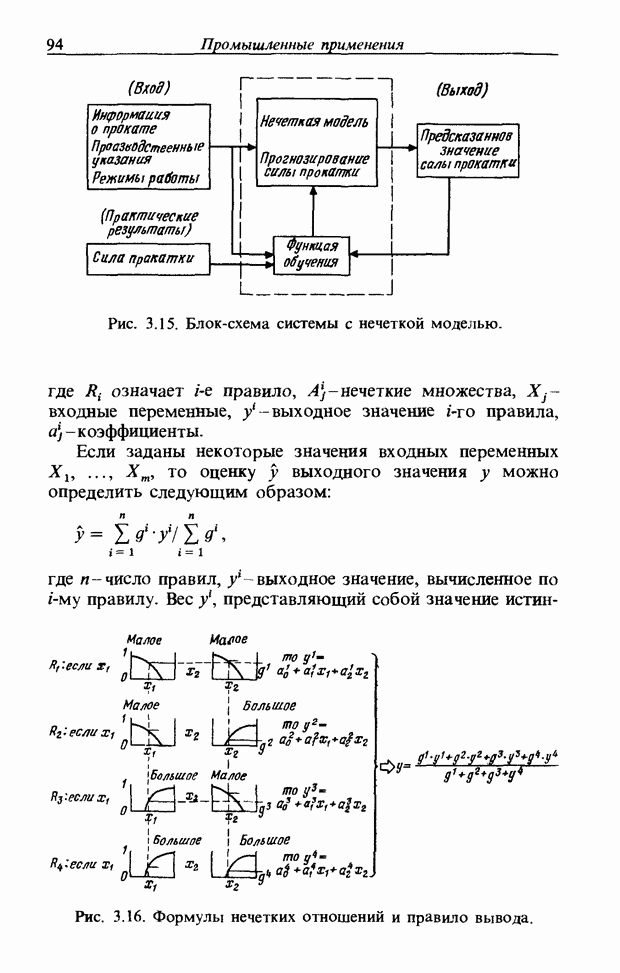
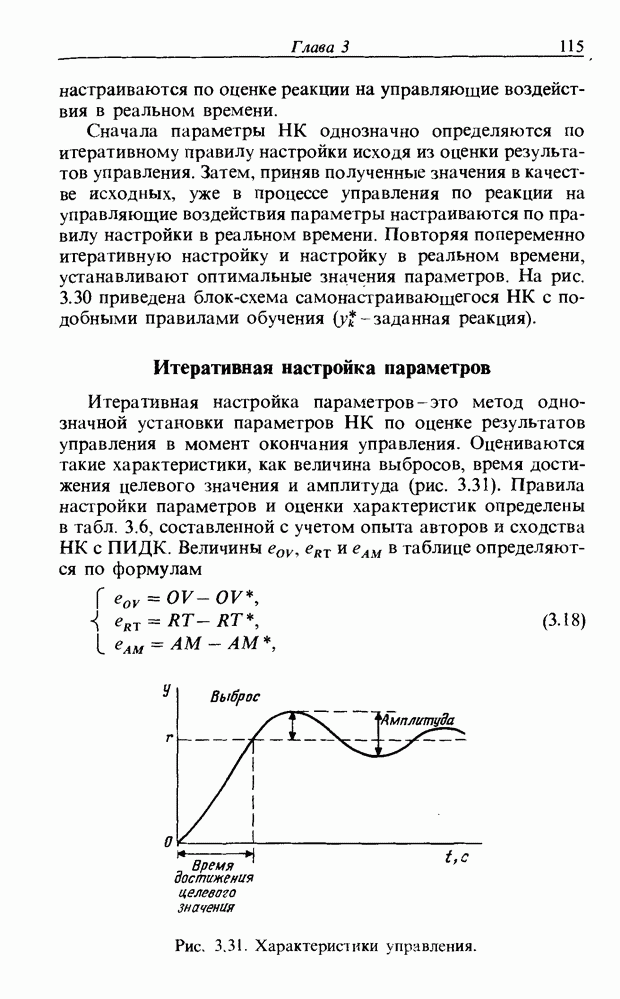
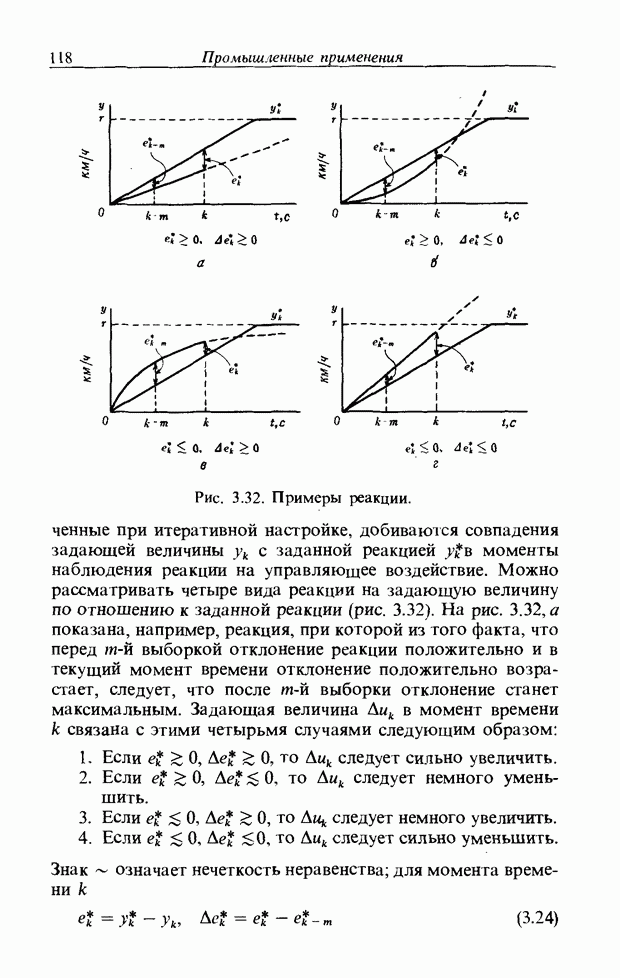
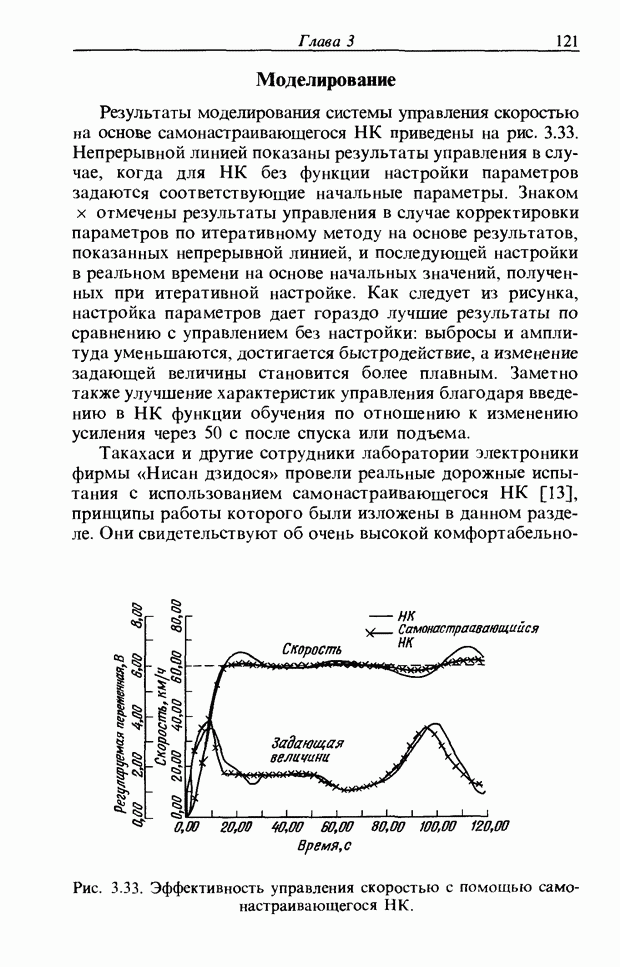
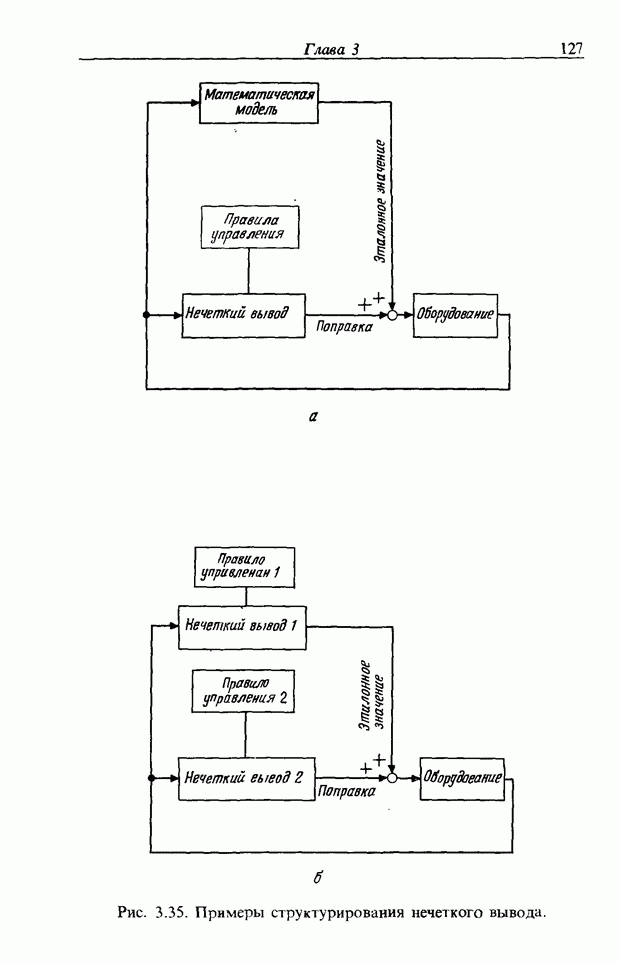
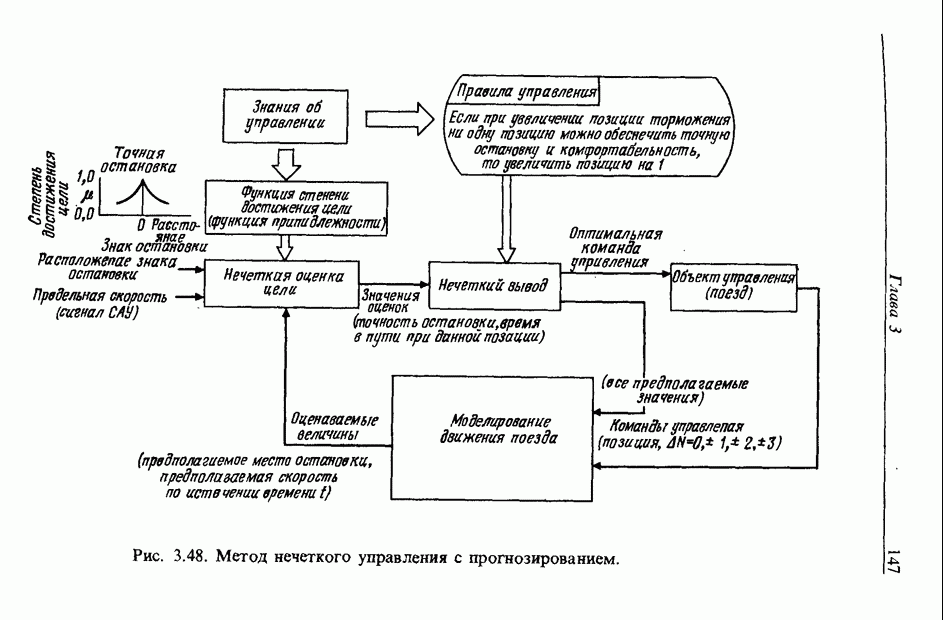
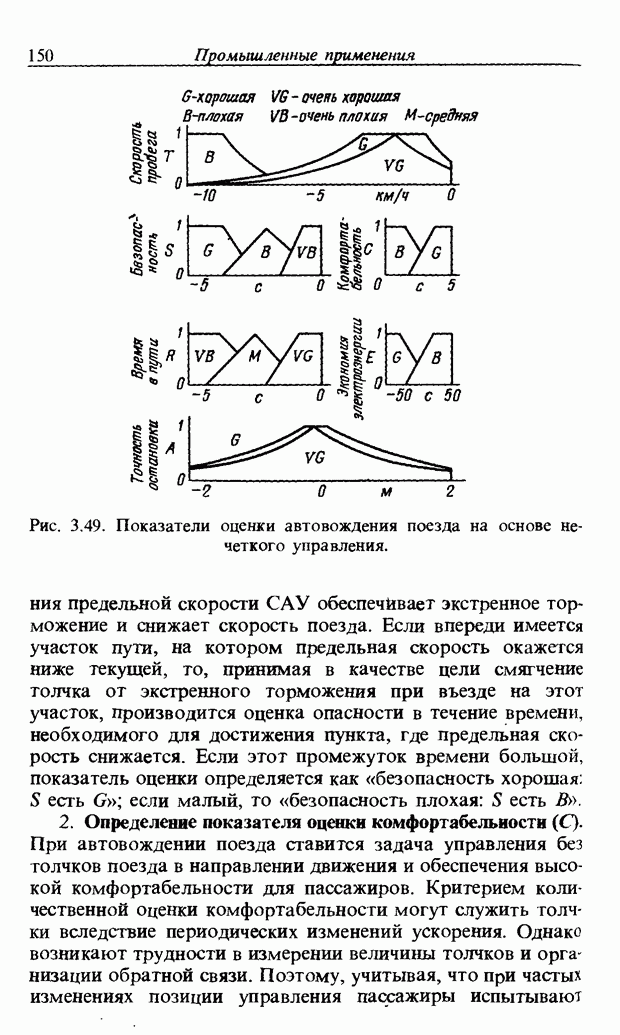
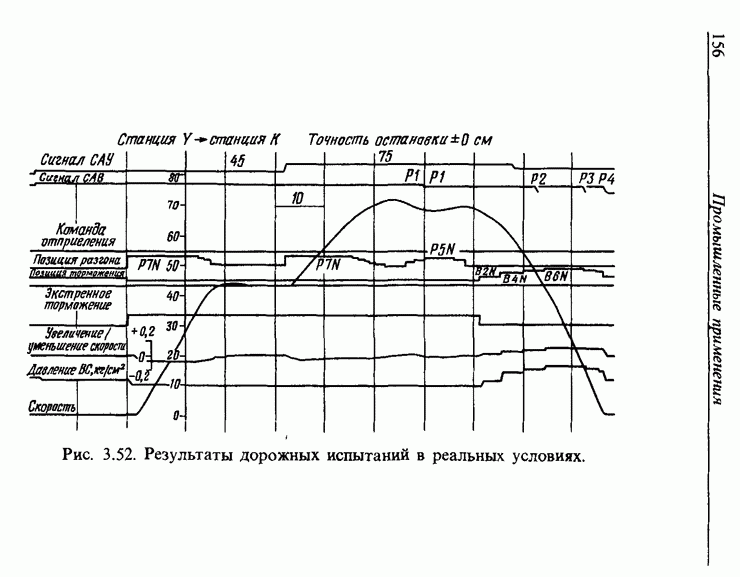
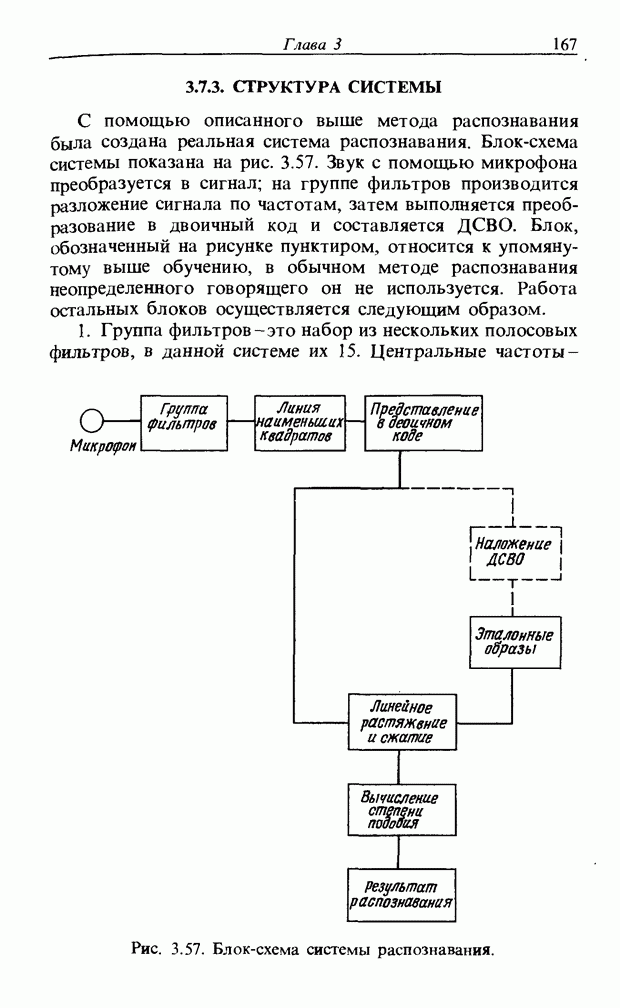
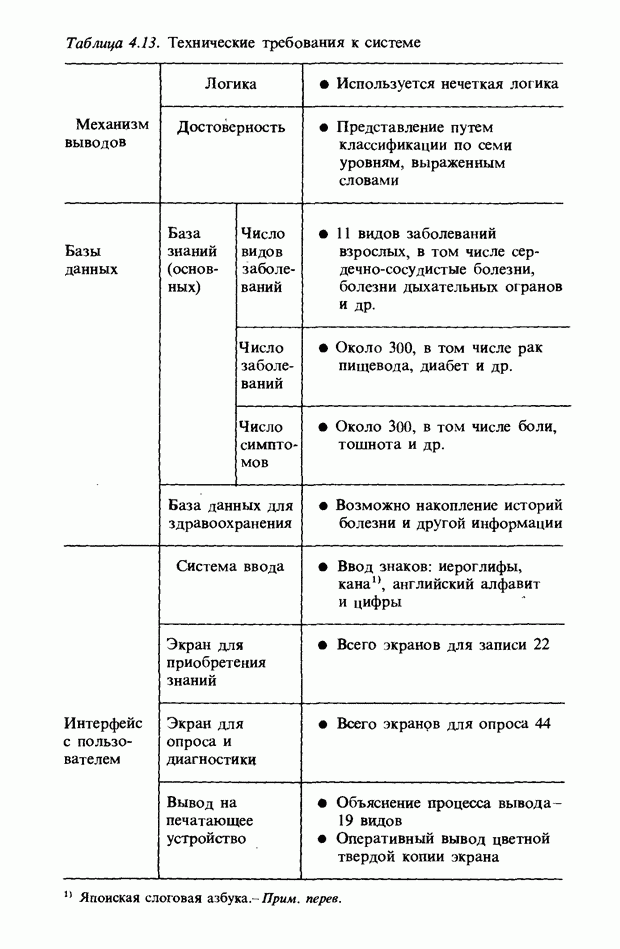
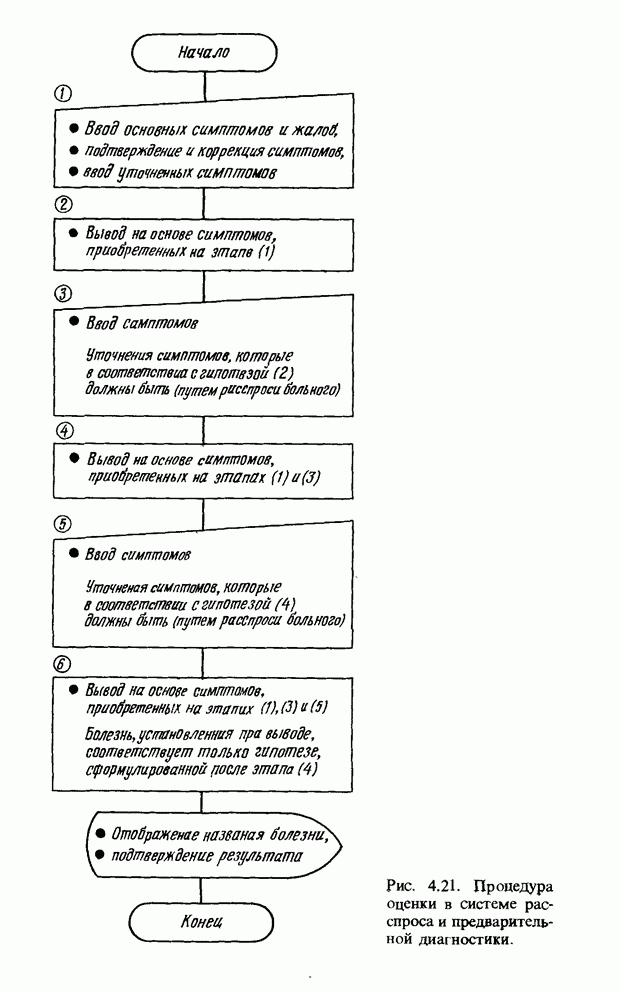
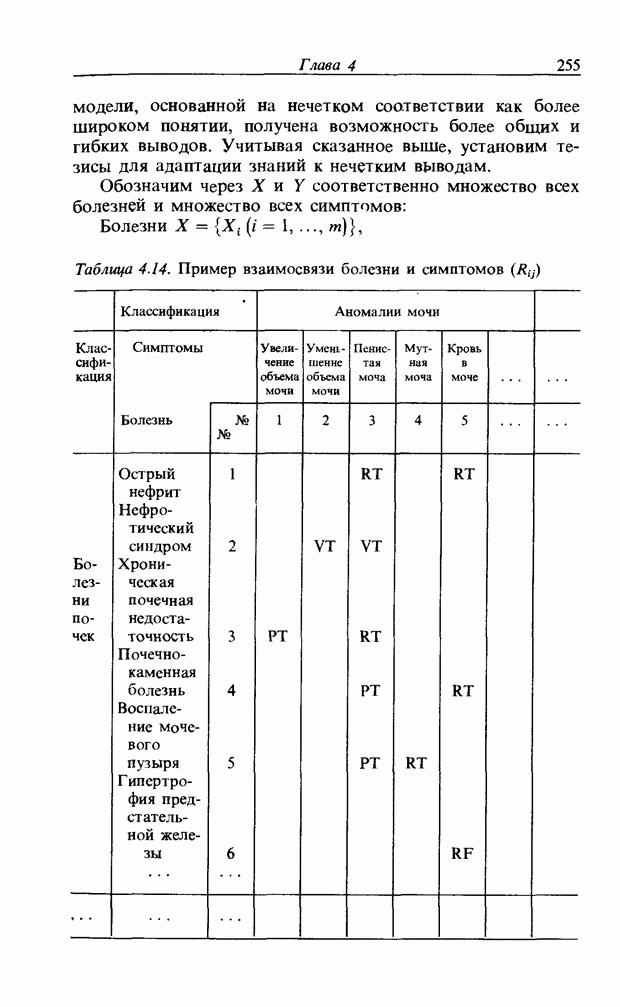
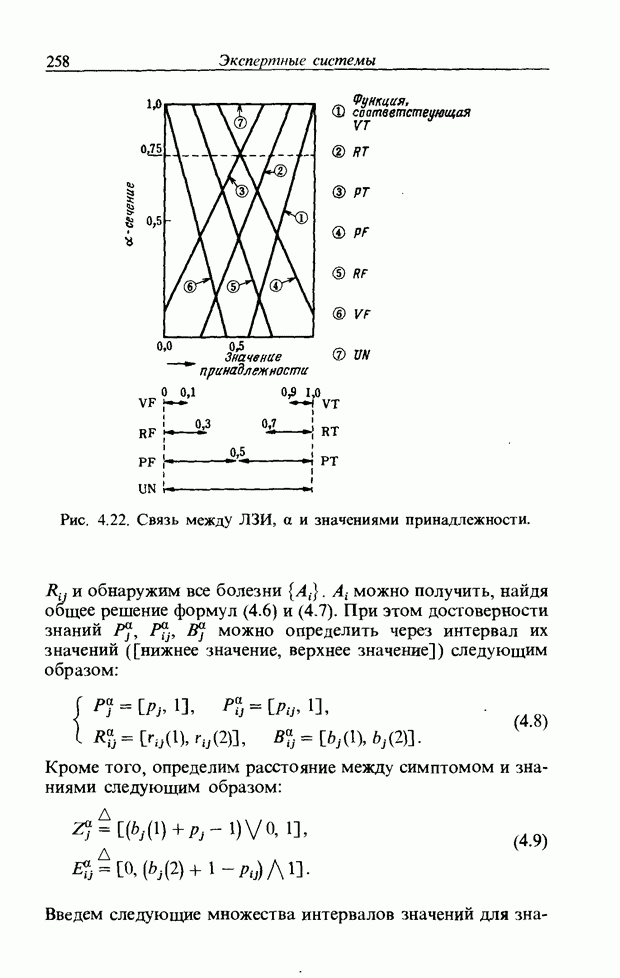
3.7. РАСПОЗНАВАНИЕ РЕЧИСловосочетание «человеко-машинный интерфейс» часто можно услышать в значении «контакт человека и машины». С точки зрения человека идеальным способом передачи своих намерений является диалог с машиной. Для этого человек может воспользоваться несколькими средствами, но только не речью, хотя с теми, кто находится рядом, он издавна привык разговаривать, не испытывая необходимости осваивать ради этого новые правила и средства. В настоящее время, когда появилась необходимость диалога с роботами или компьютерами, вполне естественно использовать дружественый диалог с помощью слов. Для этого, однако, в будущем придется решать многочисленные проблемы, а существующие сейчас средства имеют ряд ограничений, и им до диалога еще далеко, хотя практическое их применение так или иначе началось. В рассматриваемом ниже примере в процесс распознавания речи вводятся понятия нечетких множеств, благодаря чему появляется возможность справиться с различиями говорящих и изменениями речи во времени. 3.7.1. ПРОБЛЕМЫ РАСПОЗНАВАНИЯ РЕЧИРассмотрим механизм образования речи. Источником гласных звуков являются голосовые связки, изменение формы звукового пути в которых меняет условия их резонанса, преобразуя гласные звуки в звуковые колебания. Согласные звуки издаются не голосовыми связками - их источник располагается в другой части звукового пути. Распознавание речи - это процесс извлечения словесной информации, содержащейся в издаваемых таким образом звуках. Существуют различные методы распознавания речи, однако в последнее время основным стал метод сопоставления с эталоном. Это связано главным образом с прогрессом в области электронных компонентов, в частности с увеличением вычислительной мощности процессоров и объемов памяти. При сопоставлении с эталоном звуки преобразуются в характерные образы, которые сравниваются с заранее запасенными эталонными образами, и вычисляется степень их подобия. Результатом распознавания является наиболее похожий эталонный образ. При распознавании речи путем сопоставления с эталоном возникает несколько проблем, среди которых наиболее типичными являются следующие. 1. Временные изменения характерных образов речи. Причиной изменений является различная скорость произнесения одних и тех же звуков, т.е. непостоянство длительности звуков. Даже одни и те же слова, произносимые человеком, каждый раз меняются по длительности. Если же одни и те же слова произносятся разными людьми, их длительности могут еще больше различаться. 2. Влияние размеров органа речи на образы. Как уже говорилось выше, размеры органов речи у людей различны. Поэтому, даже если слова произносятся органами одинаковой формы, их резонансные частоты могут различаться. На образах это проявляется как индивидуальная особенность человека. Кроме этого существуют проблема артикуляционного сопряжения, т.е. различия одного и того же звука, обусловленные влиянием различных звуков до и после него, проблема акцента, возникающая за счет различия в манере говорить и в условиях жизни говорящих, и другие проблемы. Ниже обсуждаются только первые две проблемы. Первая проблема связана с необходимостью подстраивать временные интервалы при сопоставлении образов (временная нормализация). Известен простой способ согласования длительностей образов - линейное сопоставление. Однако, поскольку изменение длительности образов не обязательно должно быть линейным, для решения проблемы предлагается использовать ДП-сопоставление, вводящее в процедуру сопоставления образов принципы динамического программирования [26]. ДП-сопоставление, будучи нелинейным сопоставлением, устанавливает временное соответствие, обеспечивая при сопоставлении пары характерных образов минимальную ошибку или максимальную степень подобия. С этой целью используется метод динамического программирования, который позволяет повысить точность сопоставления и вносит существенный вклад в развитие распознавания речи, хотя и требует для своей реализации большого объема вычислений. Что касается изменений, связанных с говорящим (вторая проблема), то задача на первый взгляд кажется простой, поскольку человек способен распознавать любой голос, но на самом деле она чрезвычайно сложна. В настоящее время эта задача решается с помощью метода статистической обработки изменений, связанных с говорящим, или метода большого числа шаблонов. В соответствии с последним методом в процессе сопоставления образов применяется большое число разнотипных эталонных образов, относящихся к одной категории, благодаря чему даже при наличии изменений во входном образе удается установить соответствие одному из многочисленных эталонных образов. Число эталонных образов, подготовленных для каждой категории, не оговаривается; известно, что их число может быть 20-60 [27]. Вместе с тем следует отметить, что при большом числе образов объем вычислений в процессе сопоставления будет возрастать. Для того чтобы решить проблему артикуляционного сопряжения, часто применяют большие единицы распознавания типа слов, произносимые с паузой. Можно не принимать во внимание проблему частотных изменений (вторую проблему), если ограничиться одним пользователем. Распознавание в этом случае начинается после обучения по голосу этого человека. Такой метод называют распознаванием определенного говорящего. Почти все известные в настоящее время устройства распознавания речи созданы на основе распознавания слов определенного говорящего, что объясняется изложенными выше причинами. С другой стороны, распознавание без обучения для любого голоса называют распознаванием неопределенного говорящего. Создаются и устройства на основе этого метода, но число распознаваемых ими слов достигает всего нескольких десятков, а сами устройства довольно громоздки. Ниже рассматривается реализация устройства распознавания неопределенного говорящего на 100 и более слов с помощью простых вычислений с введением в процесс распознавания слов понятий нечетких множеств [28].
|
 |
Оглавление
|