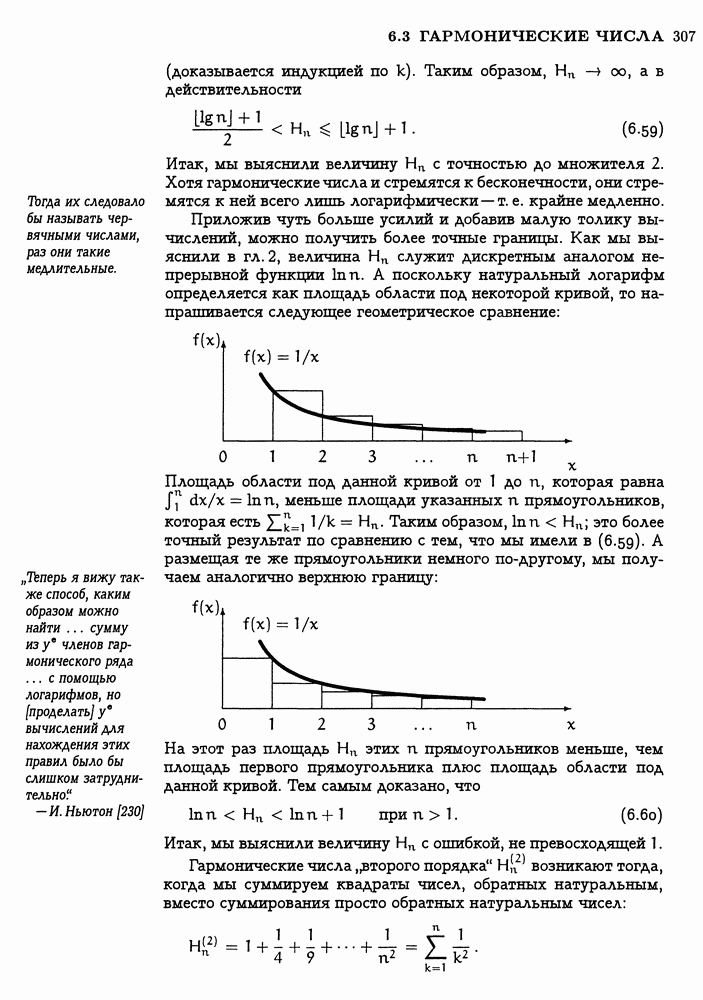
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
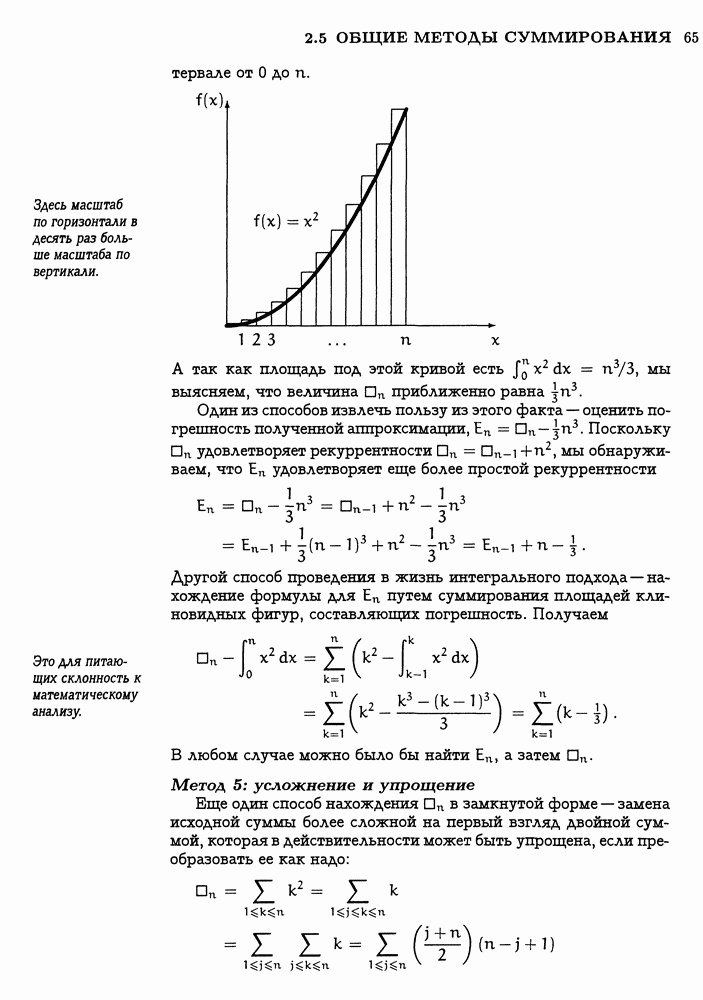
8.5 ХЕШИРОВАНИЕМы завершим эту главу приложением теории вероятностей к программированию. Ряд важных алгоритмов хранения и выборки информации в ЭВМ основаны на методе, который называется „хеширование". Общая задача заключается в хранении некоторого множества записей, каждая из которых содержит значение „ключа" и некоторые данные Реально используемые компьютеры не настолько вместительны, чтобы можно было выделить по отдельной ячейке для каждого возможного ключа; всего возможны миллиарды ключей, но в каждом конкретном приложении их присутствует не так уж много. Одно из решений состоит в том, чтобы хранить две таблицы, 51 Установить 52 Если 53 Если 54 Увеличить В случае успешного поиска нужное значение данных
в предположении, что таблица еще не заполнена до предела. Этот метод работает правильно, но его работа может быть ужасающе медленной; при безуспешном поиске шаг Хеширование было придумано как раз для того, чтобы ускорить поиск. Основная идея, в одном из популярных вариантов, состоит в использовании
Как и ранее, имеется переменная Пусть, например, ключами являются имена и имеются
Поначалу имеем четыре пустых списка и
(Значения
В массиве Ниже приведено точное описание алгоритма, который ищет ключ К в соответствие с этой схемой:
Например, при поиске имени После успешного поиска искомые данные
Теперь таблица вновь отвечает имеющимся данным. Мы надеемся, что все списки будут иметь примерно одинаковую длину, поскольку в этом случае задача поиска будет решаться примерно в Мы заранее не знаем, какие ключи будут в таблице, но обычно возможно так выбрать хеш-функцию Н, чтобы значения Анализ хеширования: введение „Анализ алгоритмов" — это раздел информатики, занимающийся выводом количественной информации об эффективности компьютерных методов. „Вероятностный анализ алгоритмов" — это изучение времени работы алгоритмов, рассматриваемого как случайная величина, зависящая от предполагаемых характеристик исходных данных. Хеширование особенно подходит для вероятностного анализа, поскольку метод хеширования исключительно эффективен в среднем, хотя его наихудший случай просто ужасен. (Наихудший случай здесь — когда все ключи имеют одинаковый хеш-код.) Так что программисту, использующему хеширование, лучше всего поверить в теорию вероятностей. Обозначим через Р количество выполнений шага
Таким образом, главная характеристика, определяющая время работы процедуры поиска, есть число проб Р. Чтобы представить себе работу алгоритма, можем вообразить, что у нас есть адресная книга, организованная неким специальным образом — на каждой странице размещается только одна запись. На обложке книги мы находим номер страницы первой записи в каждом из Если в таблицу помещено Случай 1: ключ отсутствует Рассмотрим сначала поведение Р в случае безуспешного поиска в предположении, что в таблицу уже было помещено
где Если, например,
Если Безуспешный поиск требует по одной пробе для каждого элемента списка
Вероятность того, что
Может быть, здесь нужно действовать медленнее. Пусть
Тогда
Что же, неплохо. Как мы и ожидали, среднее число проб в
следовательно, ПФСВ для общего числа проб в безуспешном поиске будет
Это биномиальное распределение бросании. Уравнение
Если Случай 2: ключ присутствует Обратимся теперь к успешным поискам. Вероятностное пространство для этого случая несколько сложнее, в соответствии с нашей задачей. Мы выберем в качестве П множество элементарных событий
где Пусть
если си — событие (8.86). (В некоторых приложениях чаще ищутся ключи, вставляемые первыми, или, наоборот, последние ключи, так что мы не будет предполагать, что все Число проб Р в случае успешного поиска равно р, если ключ К является
или, если обозначить через
Пусть, например, мы имеем
Число проб Уравнение (8.89) представляет Р в виде суммы случайных величин, но мы не можем просто вычислить Если А и В — некоторые события в вероятностном пространстве, то будем говорить, что условная вероятность А при условии В есть
Например, если X и Y — случайные величины, то условная вероятность события
Для любого фиксированного у в диапазоне изменения У сумма всех этих условных вероятностей по всем х в диапазоне изменения X составит Если X и Y независимы, то случайная величина Если X принимает только целые неотрицательные значения, то можно разложить ее ПФСВ в сумму условных ПФСВ по отношению к любой другой случайной величине У:
Это соотношение справедливо потому, что коэффициент при
Так, если X есть произведение очков, выпавших на двух правильных кубиках, а У — сумма очков, то ПФСВ
поскольку условные вероятности для
эту формулу достаточно один раз понять, и она станет очевидной. (Конец отвлечения.) Формула (8.92) позволяет выписать ПФСВ для числа проб в успешном поиске, если положить в ней
Следовательно, ПФСВ для самой величины Р может быть записана как
где
есть ПФСВ для вероятностей поиска Очень хорошо. Мы имеем производящую функцию для случайной величины Р; теперь найдем математическое ожидание и дисперсию путем дифференцирования. Вычисления несколько упрощаются, если убрать множитель
Следовательно,
Эти общие формулы выражают математическое ожидание и дисперсию числа проб Р через математическое ожидание и дисперсию заданного распределения искомых ключей Пусть, например,
Вновь мы получили ускорение в желаемой пропорции С другой стороны, мы могли бы принять В обоих случаях проведенный анализ позволяет спать спокойно тем пессимистам среди нас, кто опасается наихудшего случая: из неравенства Чебышёва следует, что списки будут хорошими и короткими, за исключением крайне редких случаев. Случай 2, продолжение: разнообразные дисперсии Мы только что вычислили дисперсию числа проб в случае успешного поиска, рассматривая Р как случайную величину на вероятностном пространстве из
как можно считать, представляет время выполнения успешного поиска. Величина
где с вероятностью
Ожидаемое значение Для иллюстрации этой разницы между дисперсиями выполним вычисления для произвольных
Успешный поиск, в котором любой из
проб. Наша цель — вычислить дисперсию величины Как оказывается, проще вычислить дисперсию несколько иной величины
Имеем
следовательно, математическое ожидание и дисперсия Л удовлетворяют соотношениям
Вероятность того, что размеры списков составят
деленному на
Для неискушенного глаза эта сумма выглядит жутковато, однако наш опыт, приобретенный в гл. 7, позволяет распознать в ней
то мы можем легко убедиться, что
Для проверки подставим Если бы мы нашли значения
Ничего не скажешь, сложные выражения; они, однако, значительно упростятся, если положить
откуда следует, что
Выражение для Формула для
поэтому находим
Теперь можно собрать все вместе и вычислить искомую дисперсию
Встретив такое „совпадение", мы можем заподозрить наличие какой-то математической причины; должен существовать другой способ решения задачи, объясняющий, почему ответ так прост. И действительно, такой способ имеется (в упр. 61), и он показывает, что в общем случае дисперсия среднего успешного поиска имеет вид
где Помимо дисперсии среднего мы можем также рассмотреть среднее дисперсии. Иными словами, каждая последовательность
Успешный поиск в результирующей таблице имеет ПФСВ
Только что мы занимались средним числом проб для успешного поиска в этой таблице, а именно,
Эта дисперсия является случайной величиной, зависящей от Таким образом, имеются три разумных вида дисперсии, которые могут быть полезны при изучении поведения успешного поиска. Это общая дисперсия числа проб, вычисляемая по всем берется по всем к, а затем среднее — по всем наборам
дисперсия среднего — это
и среднее дисперсии — это
Оказывается, что эти три величины связаны между собой простым соотношением:
В самом деле, условные распределения вероятностей всегда удовлетворяют тождеству
Здесь X и Y — случайные величины на произвольном вероятностном пространстве, причем X принимает вещественные значения. (Это тождество доказывается в упр. 22.) Уравнение (8.105) — это частный случай, в котором X — число проб в успешном поиске, Общее уравнение (8.106) требует внимательного рассмотрения, поскольку в нем скрыты несколько различных случайных величин и вероятностных пространств, в которых надлежит вычислять математические ожидания и дисперсии. Случайная величина стоит VX, безусловная дисперсия X. Поскольку дисперсии неотрицательны, мы всегда будем иметь
Вновь случай 1: пересмотр безуспешного поиска В завершение нашего микроскопического изучения хеширования проведем еще одно вычисление, типичное для анализа алгоритмов. На этот раз мы займемся более подробно общим временем работы в случае безуспешного поиска, в предположении, что компьютер вставляет в таблицу дотоле неизвестный ключ. В процессе вставки (8.83) возможны два случая, в зависимости от того, отрицательно ли
где а, (3 и До сих пор мы использовали вероятностные производящие функции только для случайных величин, принимающих целые неотрицательные значения. Оказывается, однако, что с выражением
для произвольной вещественнозначной случайной величины X можно работать ничуть не хуже, поскольку все существенные характеристики X зависят только от поведения
является ПФСВ даже в тех случаях, когда Производящей функцией для
Следовательно, имеем
Подсчет
В гл. 9 мы научимся оценивать подобные величины при больших та и
|
 |
Оглавление
|























































































































































































































































































































































































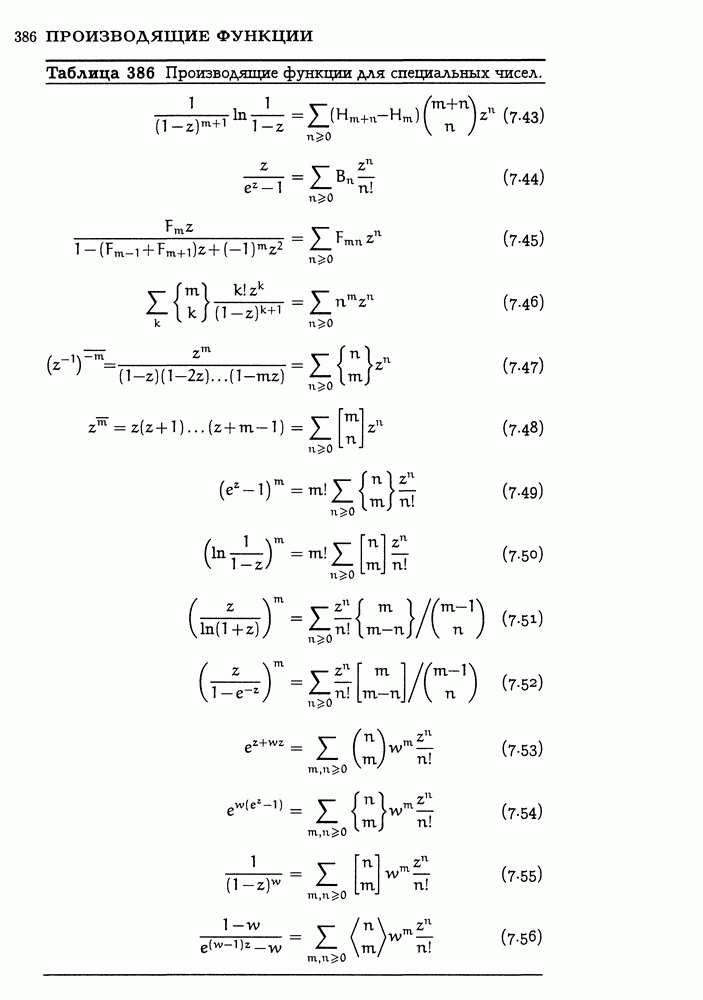







































































































































































































































































































 об этом ключе; мы бы хотели иметь возможность быстро находить
об этом ключе; мы бы хотели иметь возможность быстро находить  по заданному К. Ключами могут, например, быть фамилии студентов, а связанными с ключами данными — оценки за домашнее задание.
по заданному К. Ключами могут, например, быть фамилии студентов, а связанными с ключами данными — оценки за домашнее задание.
 — для ключей и
— для ключей и  — для данных,
— для данных,  , где
, где  — общее число записей, которые могут быть размещены; еще одна переменная,
— общее число записей, которые могут быть размещены; еще одна переменная,  показывает фактическое число записей. Тогда мы можем выполнять поиск заданного ключа К очевидным способом, последовательно просматривая таблицу:
показывает фактическое число записей. Тогда мы можем выполнять поиск заданного ключа К очевидным способом, последовательно просматривая таблицу:
 (Уже просмотрены все позиции
(Уже просмотрены все позиции 
 остановиться. (Безуспешный поиск.)
остановиться. (Безуспешный поиск.)
 остановиться. (Успешный поиск.)
остановиться. (Успешный поиск.)
 на 1 и вернуться к шагу
на 1 и вернуться к шагу  (Попробуем еще.)
(Попробуем еще.)
 лежит в
лежит в  После безуспешного поиска можно вставить К и
После безуспешного поиска можно вставить К и  в таблицу при помощи следующих установок:
в таблицу при помощи следующих установок:

 приходится повторить
приходится повторить  раз, а
раз, а  может быть весьма большим.
может быть весьма большим.
 отдельных списков вместо одного огромного. «Хеш-функция» преобразует любой возможный ключ К в номер списка
отдельных списков вместо одного огромного. «Хеш-функция» преобразует любой возможный ключ К в номер списка  лежащий в диапазоне от 1 до т. Вспомогательная таблица
лежащий в диапазоне от 1 до т. Вспомогательная таблица  содержит для каждого
содержит для каждого  указатель на первый элемент в списке
указатель на первый элемент в списке  еще одна вспомогательная таблица
еще одна вспомогательная таблица  указывает на запись, следующую за записью
указывает на запись, следующую за записью  в том списке, которому эта запись принадлежит. Будем считать, что
в том списке, которому эта запись принадлежит. Будем считать, что

 если запись
если запись  последняя в своем списке.
последняя в своем списке.
 содержащая информацию об общем числе хранящихся записей.
содержащая информацию об общем числе хранящихся записей.
 списка, разделяемые по первой букве имени:
списка, разделяемые по первой букве имени:

 Если ключом первой записи будет, скажем, имя
Если ключом первой записи будет, скажем, имя  то
то  поэтому Nora станет ключом первого элемента списка 3. Если следующими двумя именами окажутся Glenn и Jim, то оба они попадут в список 2. В этот момент таблица в памяти будет выглядеть так:
поэтому Nora станет ключом первого элемента списка 3. Если следующими двумя именами окажутся Glenn и Jim, то оба они попадут в список 2. В этот момент таблица в памяти будет выглядеть так:

 содержат секретную информацию и не показаны здесь.) После вставки 18 записей списки могли бы содержать следующие имена:
содержат секретную информацию и не показаны здесь.) После вставки 18 записей списки могли бы содержать следующие имена:

 те же имена будут записаны вперемежку, однако значения
те же имена будут записаны вперемежку, однако значения  позволяют разделить списки. Если мы теперь хотим найти имя
позволяют разделить списки. Если мы теперь хотим найти имя  то нам потребуется просмотреть шесть имен из списка 2 (этот список оказался самым длинным); но это все же не идет ни в какое сравнение с просмотром всех 18 имен.
то нам потребуется просмотреть шесть имен из списка 2 (этот список оказался самым длинным); но это все же не идет ни в какое сравнение с просмотром всех 18 имен.

 в приведенном примере мы установим на шаге
в приведенном примере мы установим на шаге  на шаге
на шаге  найдем, что
найдем, что  на шаге
на шаге  установим
установим  и на шаге
и на шаге  найдем, что
найдем, что  . Выполнив шаги
. Выполнив шаги  еще раз, мы найдем
еще раз, мы найдем  в таблице.
в таблице.
 содержатся в
содержатся в  как и в предыдущем алгоритме. В случае безуспешного поиска мы можем вставить К и
как и в предыдущем алгоритме. В случае безуспешного поиска мы можем вставить К и  в таблицу, выполнив следующие операции:
в таблицу, выполнив следующие операции:

 раз быстрее. Обычно значение
раз быстрее. Обычно значение  гораздо больше четырех, так что множитель
гораздо больше четырех, так что множитель  — это значительное улучшение.
— это значительное улучшение.
 можно было считать случайной величиной, равномерно распределенной в интервале от 1 до
можно было считать случайной величиной, равномерно распределенной в интервале от 1 до  и независимой от хеш-кодов других присутствующих ключей. В таких случаях вычисление хеш-функции подобно бросанию кубика с
и независимой от хеш-кодов других присутствующих ключей. В таких случаях вычисление хеш-функции подобно бросанию кубика с  гранями. Может случиться, что все записи попадут в один список, точно так же, как на кубике может все время выпадать
гранями. Может случиться, что все записи попадут в один список, точно так же, как на кубике может все время выпадать  однако теория вероятностей говорит нам, что списки почти всегда будут достаточно хорошо сбалансированы.
однако теория вероятностей говорит нам, что списки почти всегда будут достаточно хорошо сбалансированы.
 при работе предыдущего алгоритма. (Каждое выполнение шага
при работе предыдущего алгоритма. (Каждое выполнение шага  называется «пробой» в таблице.) Зная Р, мы можем узнать, сколько раз выполняется каждый шаг, в зависимости от успеха или неудачи поиска:
называется «пробой» в таблице.) Зная Р, мы можем узнать, сколько раз выполняется каждый шаг, в зависимости от успеха или неудачи поиска:

 списков; каждому ключу К соответствует список
списков; каждому ключу К соответствует список  которому тот принадлежит. На каждой странице книги содержится ссылка на следующую страницу в том списке, к которому эта страница относится. Число проб, требуемое для поиска адреса в такой
которому тот принадлежит. На каждой странице книги содержится ссылка на следующую страницу в том списке, к которому эта страница относится. Число проб, требуемое для поиска адреса в такой  -это число страниц, которые нам придется просмотреть.
-это число страниц, которые нам придется просмотреть.
 элементов, то их расположение зависит только от соответствующих хеш-кодов
элементов, то их расположение зависит только от соответствующих хеш-кодов  Все
Все  возможных последовательностей
возможных последовательностей  считаются равновероятными; случайная величина Р зависит от этой последовательности.
считаются равновероятными; случайная величина Р зависит от этой последовательности.
 записей. Вероятностное пространство, отвечающее данному случаю, состоит из
записей. Вероятностное пространство, отвечающее данному случаю, состоит из  элементарных событий
элементарных событий

 есть хеш-код для
есть хеш-код для  ключа в таблице,
ключа в таблице,  — хеш-код ключа, который не удалось найти. Мы предполагаем, что хеш-функция Н была выбрана надлежащим образом, так что
— хеш-код ключа, который не удалось найти. Мы предполагаем, что хеш-функция Н была выбрана надлежащим образом, так что  для любого такого
для любого такого 
 то имеются восемь равновероятных возможностей:
то имеются восемь равновероятных возможностей:

 то мы сделаем две неудачные пробы, прежде чем обнаружим, что новый ключ К не присутствует в таблице; если
то мы сделаем две неудачные пробы, прежде чем обнаружим, что новый ключ К не присутствует в таблице; если  то нам не придется делать ни одной пробы; и т. д. Этот исчерпывающий список показывает, что для
то нам не придется делать ни одной пробы; и т. д. Этот исчерпывающий список показывает, что для  распределение Р описывается ПФСВ
распределение Р описывается ПФСВ  .
.
 поэтому мы приходим к общей формуле
поэтому мы приходим к общей формуле

 составляет
составляет  для
для  поэтому
поэтому

 — следующая случайная величина:
— следующая случайная величина:

 для всех
для всех  следовательно,
следовательно,

 раз меньше, чем без хеширования. Более того, случайные величины
раз меньше, чем без хеширования. Более того, случайные величины  независимы и имеют одинаковую производящую функцию
независимы и имеют одинаковую производящую функцию


 иными словами, число проб в безуспешном поиске ведет себя точно так же, как число выпавших решек при бросании несимметричной монеты с вероятностью выпадания решки
иными словами, число проб в безуспешном поиске ведет себя точно так же, как число выпавших решек при бросании несимметричной монеты с вероятностью выпадания решки  при каждом
при каждом
 говорит нам теперь, что дисперсия Р равна
говорит нам теперь, что дисперсия Р равна

 велико, то дисперсия Р приблизительно равна
велико, то дисперсия Р приблизительно равна  так что стандартное отклонение есть примерно
так что стандартное отклонение есть примерно  .
.

 представляет собой хеш-код для
представляет собой хеш-код для  ключа, как раньше, а k есть индекс искомого ключа (он имеет хеш-код
ключа, как раньше, а k есть индекс искомого ключа (он имеет хеш-код  ). Таким образом,
). Таким образом,  для
для  всего имеется
всего имеется  элементарных событий.
элементарных событий.
 — вероятность того, что ищется
— вероятность того, что ищется  помещенный в таблицу ключ. Тогда
помещенный в таблицу ключ. Тогда

 Заметим, что
Заметим, что  следовательно, (8.87) определяет корректное распределение вероятностей.
следовательно, (8.87) определяет корректное распределение вероятностей.
 ключом в своем списке. Следовательно,
ключом в своем списке. Следовательно,

 случайную величину
случайную величину 

 и хеш-коды образовали следующую „случайную" последовательность:
и хеш-коды образовали следующую „случайную" последовательность:

 требуемых для поиска
требуемых для поиска  ключа, показано под
ключа, показано под 
 как
как  поскольку значение к само является случайной величиной. Какова же производящая функция случайной величины Р? Для ответа на этот вопрос нам придется на один момент отвлечься от нашей задачи и поговорить об условных вероятностях.
поскольку значение к само является случайной величиной. Какова же производящая функция случайной величины Р? Для ответа на этот вопрос нам придется на один момент отвлечься от нашей задачи и поговорить об условных вероятностях.

 при условии
при условии  равна
равна

 следовательно, (8.91) определяет распределение вероятностей, и мы можем определить новую случайную величину
следовательно, (8.91) определяет распределение вероятностей, и мы можем определить новую случайную величину  такую, что
такую, что 
 в сущности совпадает с X при любом у, поскольку
в сущности совпадает с X при любом у, поскольку  равняется
равняется  в силу (8.5); это как раз условие независимости. Однако если X и Y зависимы, то случайные величины
в силу (8.5); это как раз условие независимости. Однако если X и Y зависимы, то случайные величины  могут быть совершенно не похожи друг на друга при
могут быть совершенно не похожи друг на друга при  .
.

 в левой части есть
в левой части есть  для всех
для всех  тогда как в правой части он равен
тогда как в правой части он равен

 будет
будет

 содержат пять равновероятных событий
содержат пять равновероятных событий  Уравнение (8.92) в этом случае сведется к
Уравнение (8.92) в этом случае сведется к

 Для любого фиксированного к от 1 до
Для любого фиксированного к от 1 до  случайная величина
случайная величина  определяется как сумма независимых случайных величин
определяется как сумма независимых случайных величин  ; это в точности (8.89). Поэтому ее ПФСВ равна
; это в точности (8.89). Поэтому ее ПФСВ равна



 (поделенная для удобства на
(поделенная для удобства на 
 вычислив поначалу математическое ожидание и дисперсию случайной величины
вычислив поначалу математическое ожидание и дисперсию случайной величины 



 для
для  Это значит, что мы выполняем полностью „случайные" успешные поиски с равной вероятностью для всех ключей в таблице. Тогда
Это значит, что мы выполняем полностью „случайные" успешные поиски с равной вероятностью для всех ключей в таблице. Тогда  является равномерным распределением
является равномерным распределением  из (8.32) и мы имеем
из (8.32) и мы имеем  Следовательно,
Следовательно,

 . Если
. Если  то среднее число проб при успешном поиске будет примерно равно
то среднее число проб при успешном поиске будет примерно равно  , а стандартное отклонение асимптотически равно
, а стандартное отклонение асимптотически равно 
 для
для  это распределение называется „законом Зипфа“. Тогда
это распределение называется „законом Зипфа“. Тогда  Среднее число проб для
Среднее число проб для  при
при  примерно равно 2 со стандартным отклонением, асимптотически равным
примерно равно 2 со стандартным отклонением, асимптотически равным 
 элементов
элементов  . Но мы могли бы встать на другую точку зрения. Каждый набор хеш-кодов
. Но мы могли бы встать на другую точку зрения. Каждый набор хеш-кодов  определяет случайную величину
определяет случайную величину  представляющую число проб в случае успешного поиска в этой конкретной хеш-таблице, содержащей
представляющую число проб в случае успешного поиска в этой конкретной хеш-таблице, содержащей  заданных ключей. Среднее значение
заданных ключей. Среднее значение 

 является случайной величиной, которая зависит только от
является случайной величиной, которая зависит только от  но не от последней компоненты к; мы можем записать ее в форме
но не от последней компоненты к; мы можем записать ее в форме

 определена в (8.88), поскольку
определена в (8.88), поскольку 

 полученное суммированием по всем
полученное суммированием по всем  возможным наборам
возможным наборам  с последующим делением на
с последующим делением на  будет совпадать с ранее найденным в (8.95) математическим ожиданием. Однако дисперсия
будет совпадать с ранее найденным в (8.95) математическим ожиданием. Однако дисперсия  будет отличаться; это — дисперсия
будет отличаться; это — дисперсия  средних, а не
средних, а не  отдельных значений числа проб. Например, для
отдельных значений числа проб. Например, для  (так что у нас имеется только один список) „среднее" значение
(так что у нас имеется только один список) „среднее" значение  есть на самом деле константа, и поэтому ее дисперсия
есть на самом деле константа, и поэтому ее дисперсия  равна нулю; однако число проб в успешном поиске не постоянно, и его дисперсия
равна нулю; однако число проб в успешном поиске не постоянно, и его дисперсия  не нулевая.
не нулевая.
 в простейшем случае,
в простейшем случае,  для
для  Иными словами, мы предположим временно, что ключи поиска распределены равномерно. Любая данная последовательность хеш-кодов
Иными словами, мы предположим временно, что ключи поиска распределены равномерно. Любая данная последовательность хеш-кодов  определяет
определяет  списков, содержащих, соответственно,
списков, содержащих, соответственно,  элементов для некоторых чисел
элементов для некоторых чисел  причем
причем

 ключей в таблице равновероятен, потребует в среднем
ключей в таблице равновероятен, потребует в среднем

 на вероятностном пространстве, состоящем из всех
на вероятностном пространстве, состоящем из всех  последовательностей
последовательностей 



 равняется мультиномиальному коэффициенту
равняется мультиномиальному коэффициенту

 следовательно, ПФСВ для
следовательно, ПФСВ для  есть
есть

 -кратную свертку. И действительно, если определить экспоненциальную суперпроизводящую функцию
-кратную свертку. И действительно, если определить экспоненциальную суперпроизводящую функцию

 есть просто
есть просто  степень:
степень:

 мы получим
мы получим  так что коэффициентом при
так что коэффициентом при  будет
будет 
 то смогли бы вычислить
то смогли бы вычислить  Возьмем поэтому частную производную
Возьмем поэтому частную производную  по
по 

 Так, например,
Так, например,


 в
в  дает теперь
дает теперь  в полном согласии с (8.97).
в полном согласии с (8.97).
 включает похожую сумму
включает похожую сумму


 Очень много членов сокращается и результат оказывается удивительно простым:
Очень много членов сокращается и результат оказывается удивительно простым:


 — вероятность поиска элемента, вставленного
— вероятность поиска элемента, вставленного  по счету. Уравнение (8.103) является частным случаем
по счету. Уравнение (8.103) является частным случаем  для 1 к
для 1 к 
 задающая хеш-таблицу, определяет также распределение вероятностей для успешного поиска, и дисперсия этого распределения показывает, как сильно будет разбросано число проб в различных успешных поисках. В качестве примера вернемся вновь к ситуации, когда мы помещали
задающая хеш-таблицу, определяет также распределение вероятностей для успешного поиска, и дисперсия этого распределения показывает, как сильно будет разбросано число проб в различных успешных поисках. В качестве примера вернемся вновь к ситуации, когда мы помещали  объектов в
объектов в  списков:
списков:


 Но можно также рассмотреть дисперсию,
Но можно также рассмотреть дисперсию,

 так что вполне естественно поинтересоваться ее средним значением.
так что вполне естественно поинтересоваться ее средним значением.
 и
и  ; дисперсия среднего числа проб, где среднее берется по всем k, а затем вычисляется дисперсия по всем
; дисперсия среднего числа проб, где среднее берется по всем k, а затем вычисляется дисперсия по всем  и среднее дисперсии числа проб, где дисперсия
и среднее дисперсии числа проб, где дисперсия
 . В символической записи общая дисперсия выражается как
. В символической записи общая дисперсия выражается как





 последовательность хеш-кодов
последовательность хеш-кодов  .
.
 для каждого у из диапазона изменения Y была определена в (8.91), и эта случайная величина имеет ожидаемое значение
для каждого у из диапазона изменения Y была определена в (8.91), и эта случайная величина имеет ожидаемое значение  зависящее от у. Далее,
зависящее от у. Далее,  обозначает случайную величину, принимающую значения
обозначает случайную величину, принимающую значения  когда у принимает все возможные для У значения, а
когда у принимает все возможные для У значения, а  есть дисперсия этой случайной величины по отношению к распределению вероятностей У. Аналогично,
есть дисперсия этой случайной величины по отношению к распределению вероятностей У. Аналогично,  есть среднее значение случайной величины
есть среднее значение случайной величины  при изменении у. В левой части (8.106)
при изменении у. В левой части (8.106)

 или равно нулю. При этом
или равно нулю. При этом  тогда и только тогда, когда
тогда и только тогда, когда 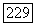 поскольку отрицательное значение может появиться только из элемента
поскольку отрицательное значение может появиться только из элемента 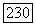 для пустого списка. Таким образом, если список был пуст, то
для пустого списка. Таким образом, если список был пуст, то 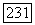 и мы должны выполнить установку
и мы должны выполнить установку 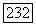 (Новая запись будет помещена в позицию
(Новая запись будет помещена в позицию  ) В противном случае
) В противном случае  и значение
и значение  следует установить в элемент
следует установить в элемент  Выполнение алгоритма в этих двух случаях может занять различное время; поэтому общее время работы для безуспешного поиска можно записать в виде
Выполнение алгоритма в этих двух случаях может занять различное время; поэтому общее время работы для безуспешного поиска можно записать в виде

 некоторые константы, зависящие от компьютера и от того, каким образом алгоритм хеширования закодирован в командах внутреннего языка компьютера. Было бы неплохо найти математическое ожидание и дисперсию случайной величины Т, поскольку эти показатели более важны для практики, чем математическое ожидание и дисперсия величины Р.
некоторые константы, зависящие от компьютера и от того, каким образом алгоритм хеширования закодирован в командах внутреннего языка компьютера. Было бы неплохо найти математическое ожидание и дисперсию случайной величины Т, поскольку эти показатели более важны для практики, чем математическое ожидание и дисперсия величины Р.

 вблизи
вблизи  ; а в этой области все степени z корректно определены. Например, время работы безуспешного поиска (8.108) является случайной величиной, определенной на вероятностном пространстве из равновероятных последовательностей хеш-кодов
; а в этой области все степени z корректно определены. Например, время работы безуспешного поиска (8.108) является случайной величиной, определенной на вероятностном пространстве из равновероятных последовательностей хеш-кодов  мы можем считать, что ряд
мы можем считать, что ряд

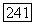 — не целые. (Фактически, параметры
— не целые. (Фактически, параметры 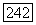 - физические величины, имеющие размерность времени; это даже не совсем числа! Тем не менее, их можно использовать в показателе степени при
- физические величины, имеющие размерность времени; это даже не совсем числа! Тем не менее, их можно использовать в показателе степени при 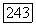 Мы можем по-прежнему вычислять математическое ожидание и дисперсию случайной величины Т, найдя
Мы можем по-прежнему вычислять математическое ожидание и дисперсию случайной величины Т, найдя  и скомбинировав эти значения обычным образом.
и скомбинировав эти значения обычным образом.
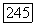 (а не Т) будет
(а не Т) будет


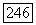 оказывается теперь рутинной операцией:
оказывается теперь рутинной операцией:

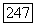 Если, например,
Если, например, 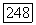 то с помощью методов гл. 9 можно показать, что математическое ожидание и дисперсия Т равны, соответственно, а
то с помощью методов гл. 9 можно показать, что математическое ожидание и дисперсия Т равны, соответственно, а 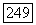 Если
Если 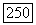 то соответствующие величины составят
то соответствующие величины составят
