Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
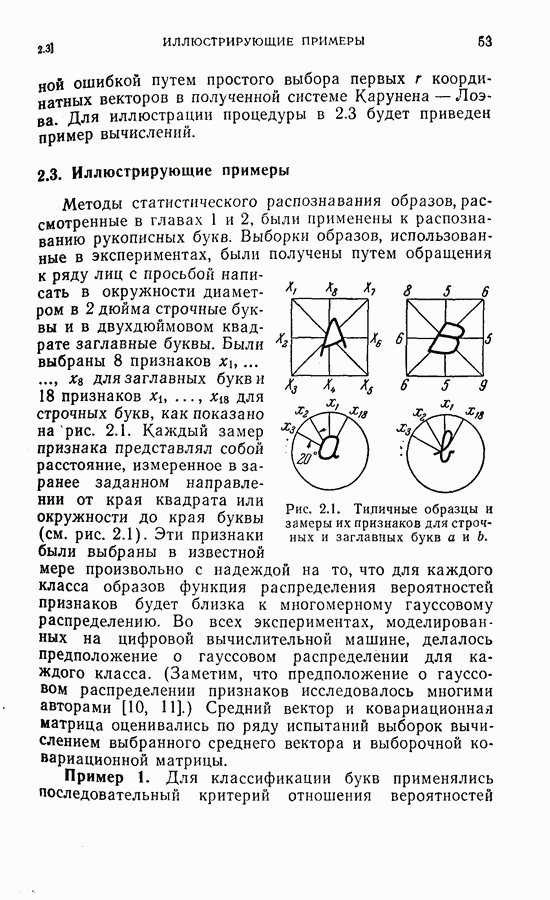
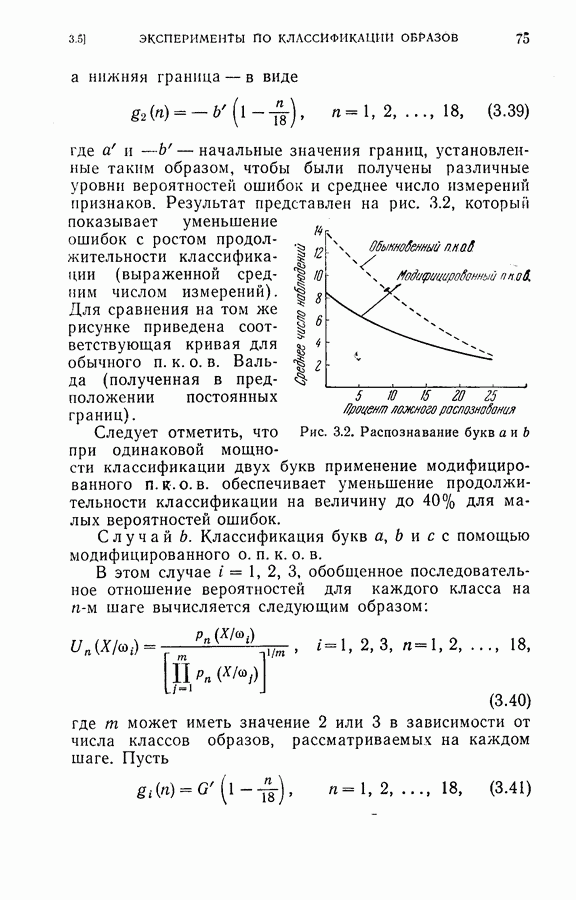
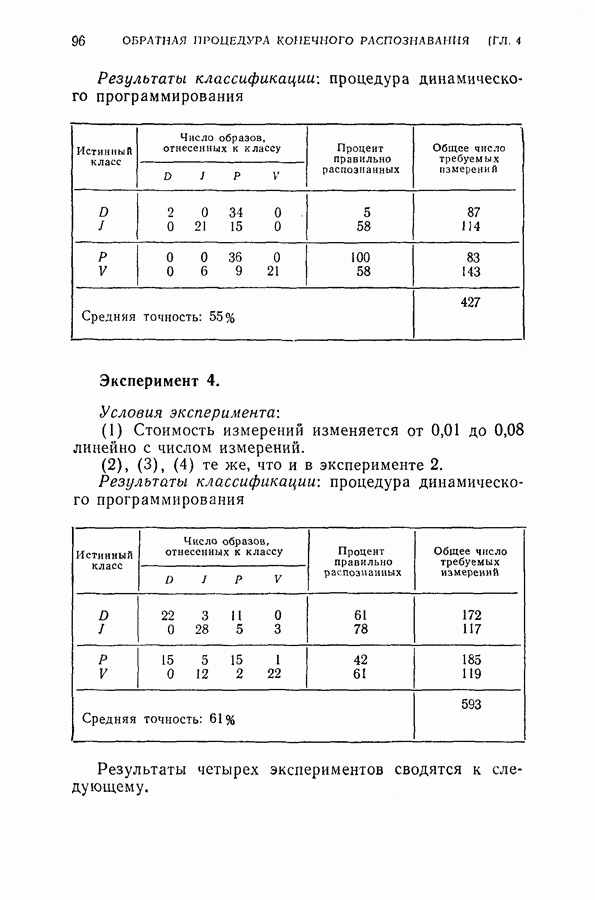
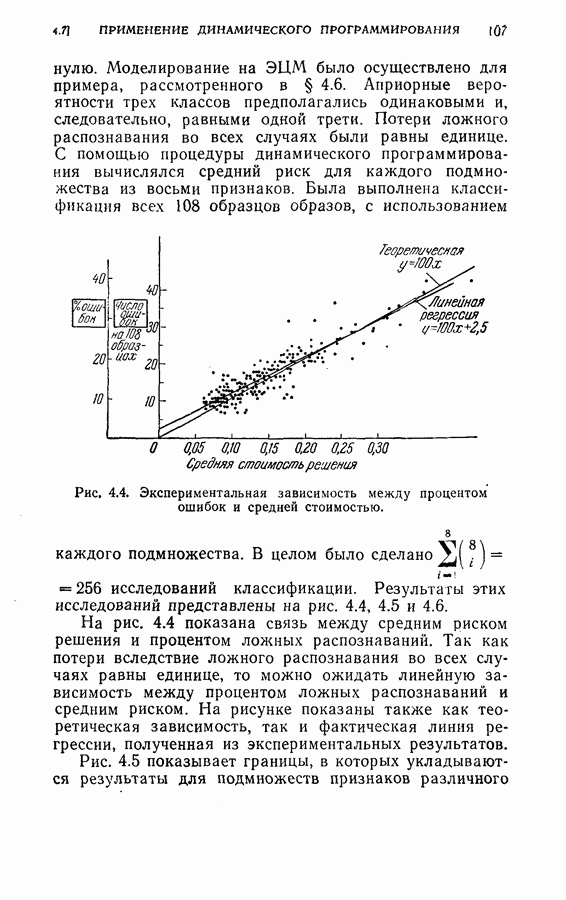
2.3. Иллюстрирующие примерыМетоды статистического распознавания образов, рассмотренные в главах 1 и 2, были применены к распознаванию рукописных букв. Выборки образов, использованные в экспериментах, были получены путем обращения к ряду лиц с просьбой написать в окружности диаметром в 2 дюйма строчные буквы и в двухдюймовом квадрате заглавные буквы. Были выбраны 8 признаков
Рис. 2.1. Типичные образцы и замеры их признаков для строчных и заглавных букв Пример 1. Для классификации букв применялись последовательный критерий отношения вероятностей и обобщенный последовательный критерий отношения вероятностей. Средние векторы и ковариационные матрицы для признаков оценивались по пятидесяти выборкам для каждой буквы. (1) Распознавание заглавных букв
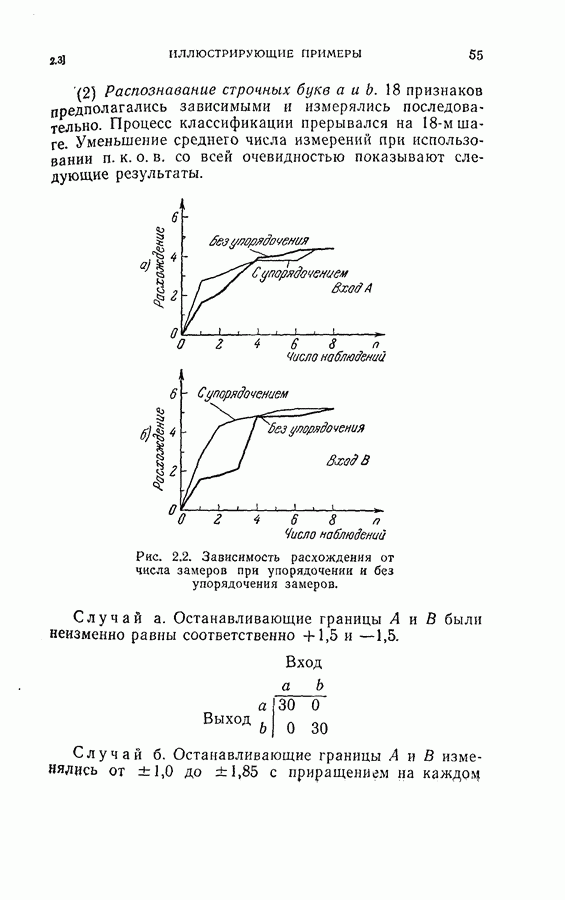
Процесс классификации прерывался на Таблица 2.1 (см. скан) Следует заметить, что при одном и том же множестве останавливающих границ процесс классификации заканчивался раньше в случае упорядоченных признаков, чем при неупорядоченных признаках (т. е. в естественном порядке). Расхождение в зависимости от числа измерений признаков при упорядоченных и неупорядоченных последовательных измерениях показано на рис. 2.2. Хотя расхождение для всех восьми признаков не зависит от упорядочения, первые несколько измерений могут быть очень эффективными для правильной классификации, когда измерения проводятся в предлагаемом порядке. (2) Распознавание строчных букв Рис. 2.2. (см. скан) Зависимость расхождения от числа замеров при упорядочении и без упорядочения замеров. Случай а. Останавливающие границы
Случай б. Останавливающие границы шаге на ±0,05.
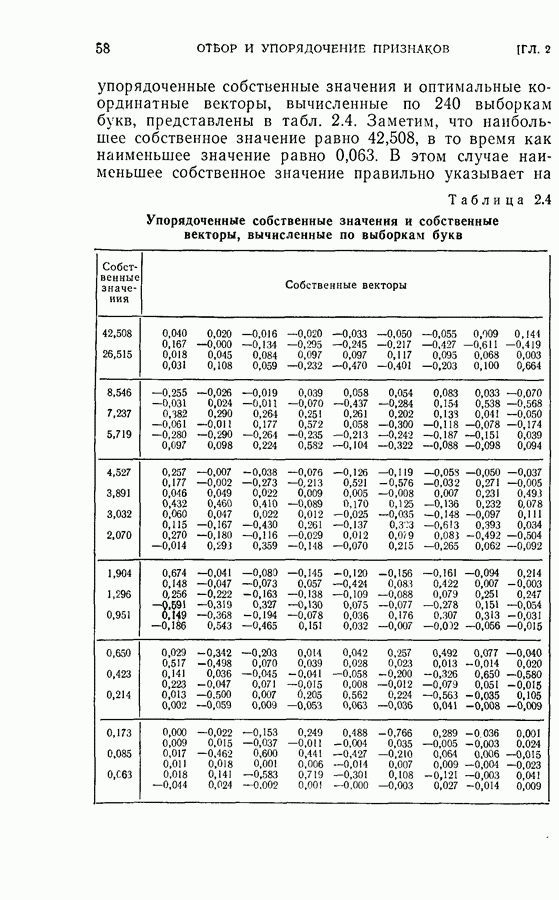
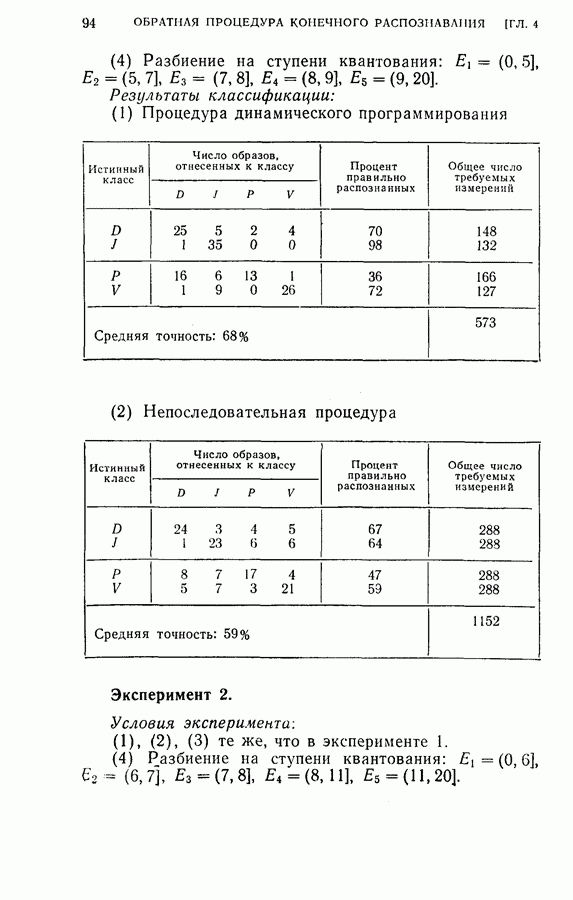
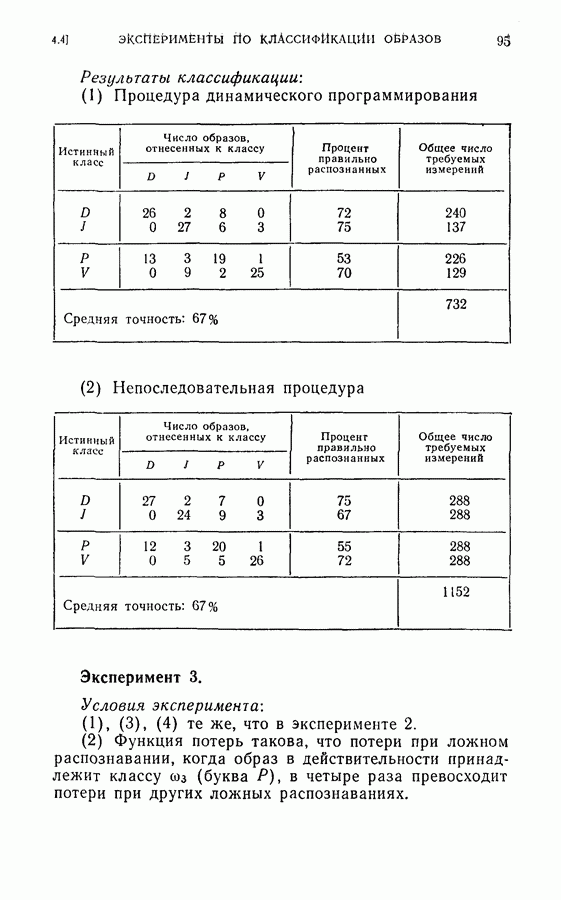
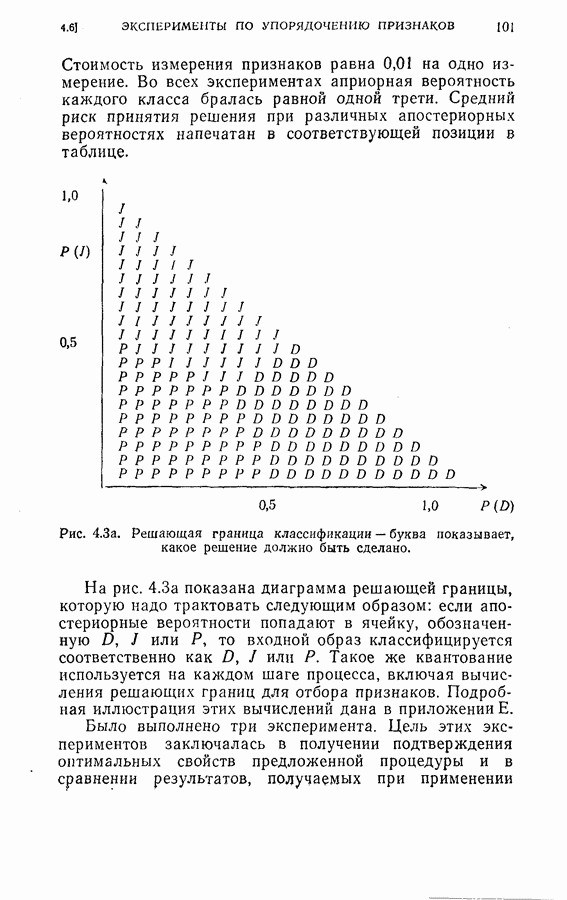
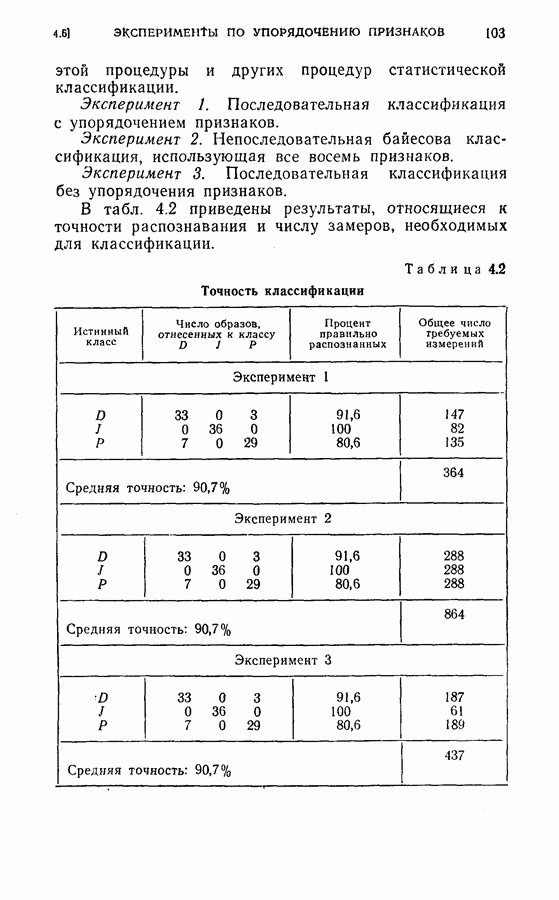
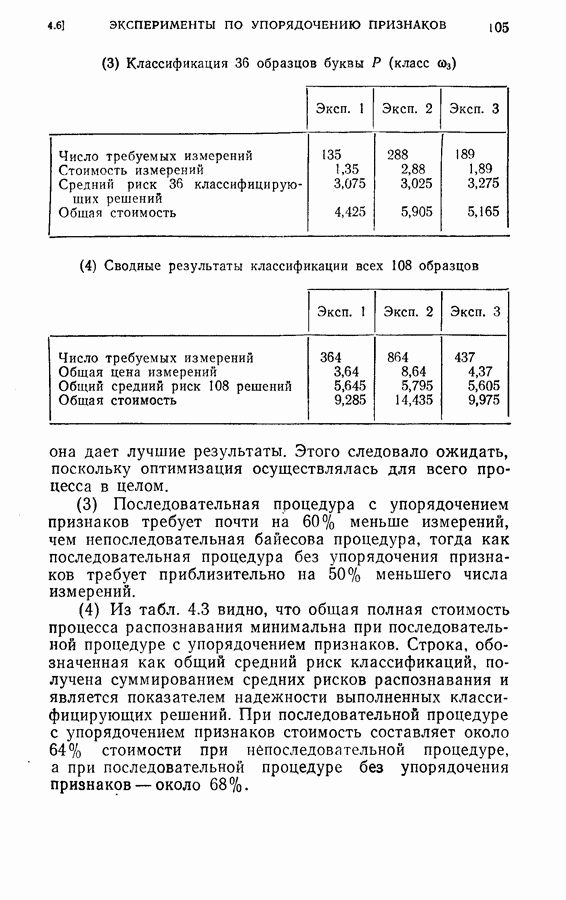
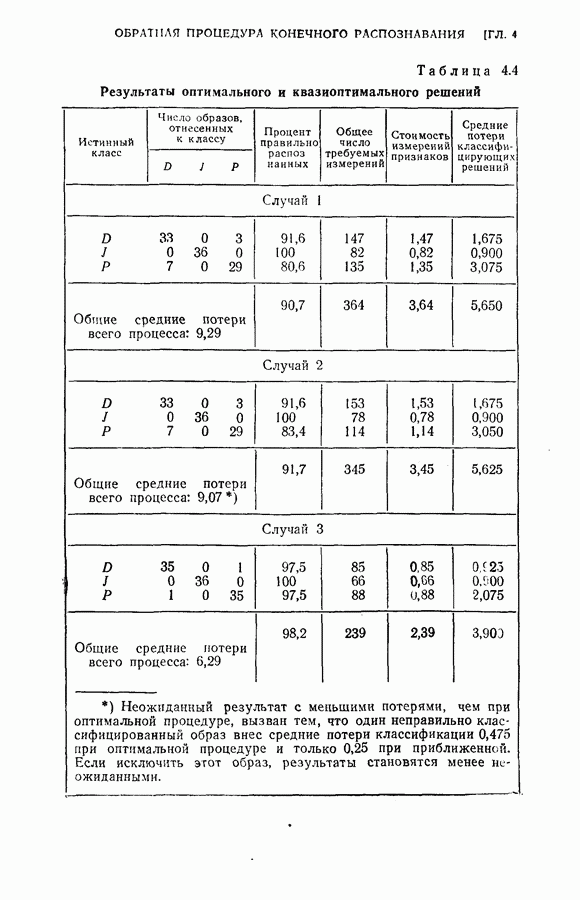
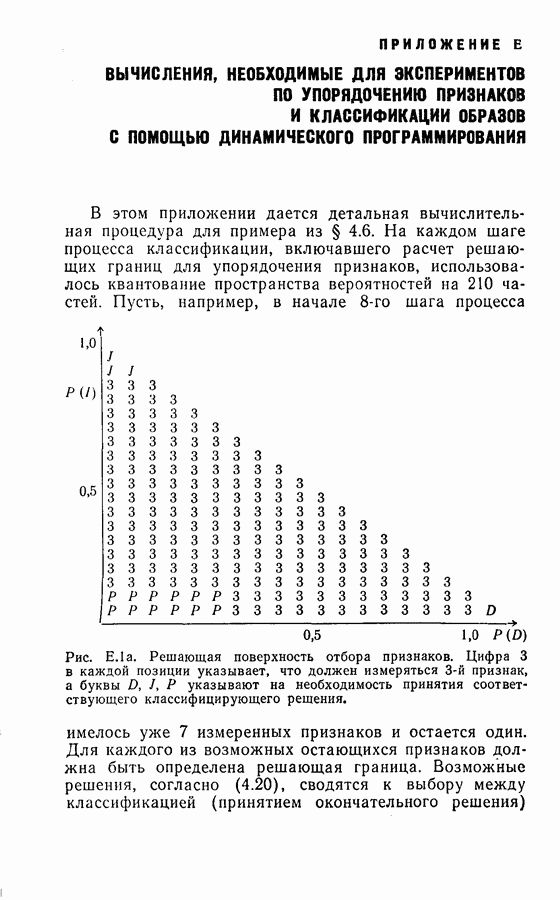
Среднее число измерений, необходимое в этом случае, равно 5,516. Моделирование на ЭЦМ показало, что для достижения той же точности распознавания процесс распознавания, использующий байесову решающую процедуру с фиксированным объемом выборки (3) Распознавание букв Следует заметить, что при небольшом снижении точности распознавания может быть уменьшено число измерений, необходимых для достижения окончательного решения, если должным образом упорядочены последовательные измерения. Таблица 2.2 (см. скан) Пример 2. Критерий отбора признаков, описанных в (2.17) — (2.20), был применен для отбора лучшего подмножества в шесть признаков из восьми признаков Таблица 2.3 (см. скан) Пример 3. Процедура отбора признаков и их упорядочения, описанная в § 2.2, была применена для распознавания букв упорядоченные собственные значения и оптимальные координатные векторы, вычисленные по 240 выборкам букв, представлены в табл. 2.4. Заметим, что наибольшее собственное значение равно 42,508, в то время как наименьшее значение равно 0,063. В этом случае наименьшее собственное значение правильно указывает на Таблица 2.4 (см. скан) Упорядоченные собственные значения и собственные векторы, вычисленные по выборкам букв
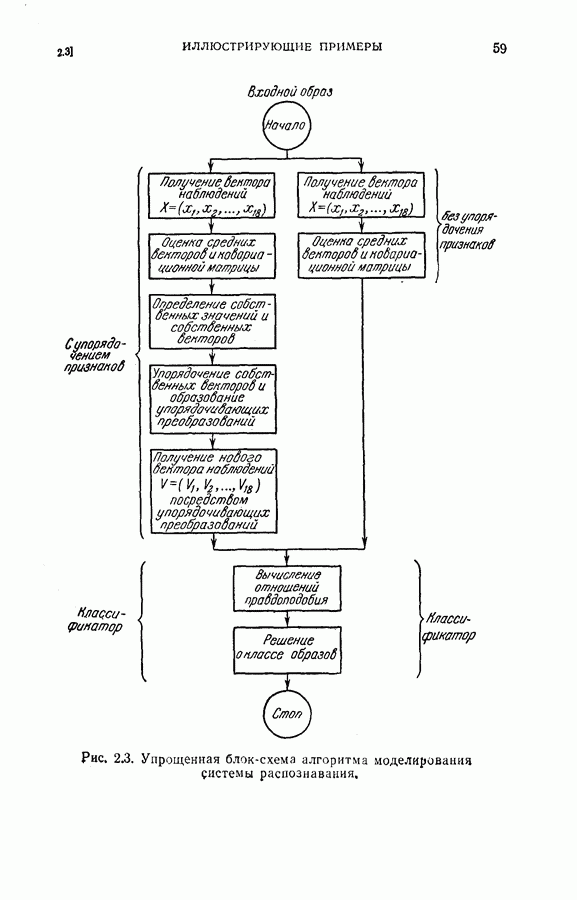
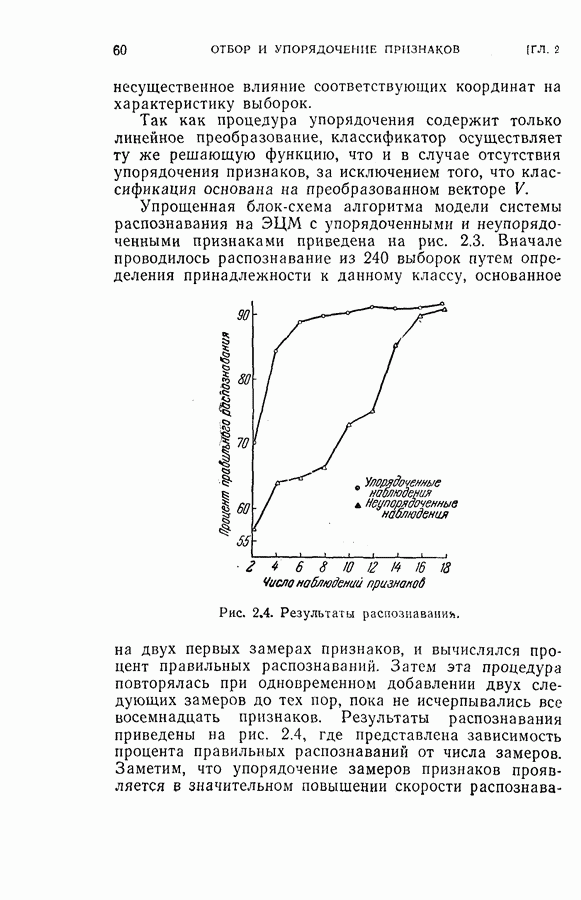
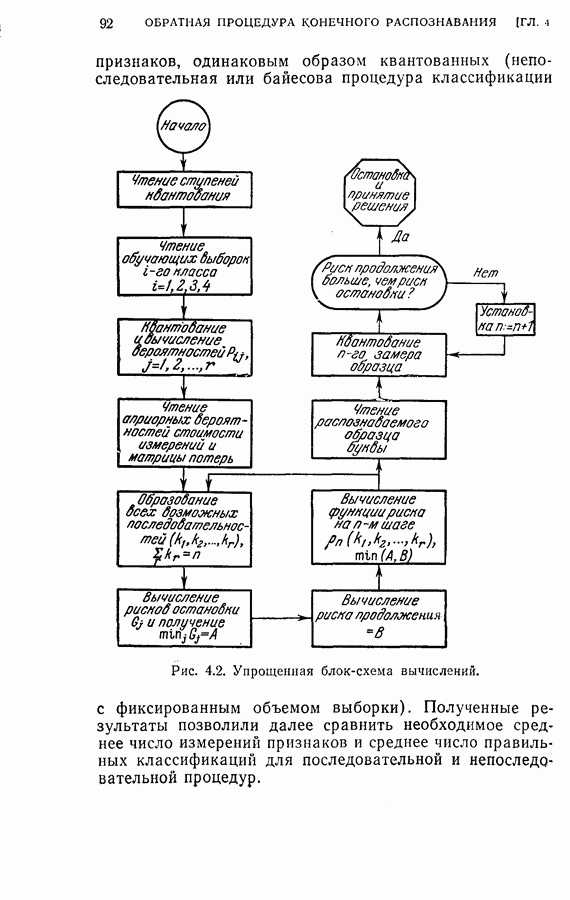
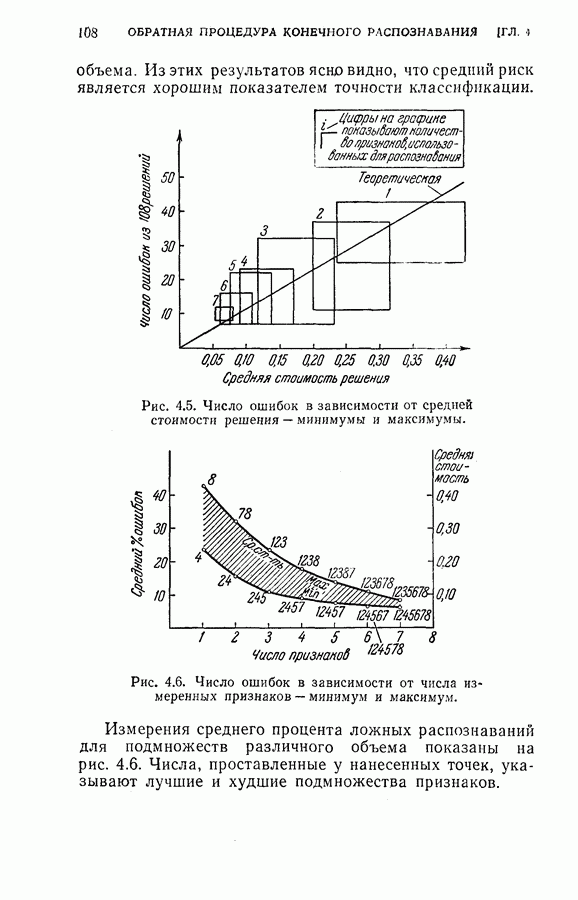
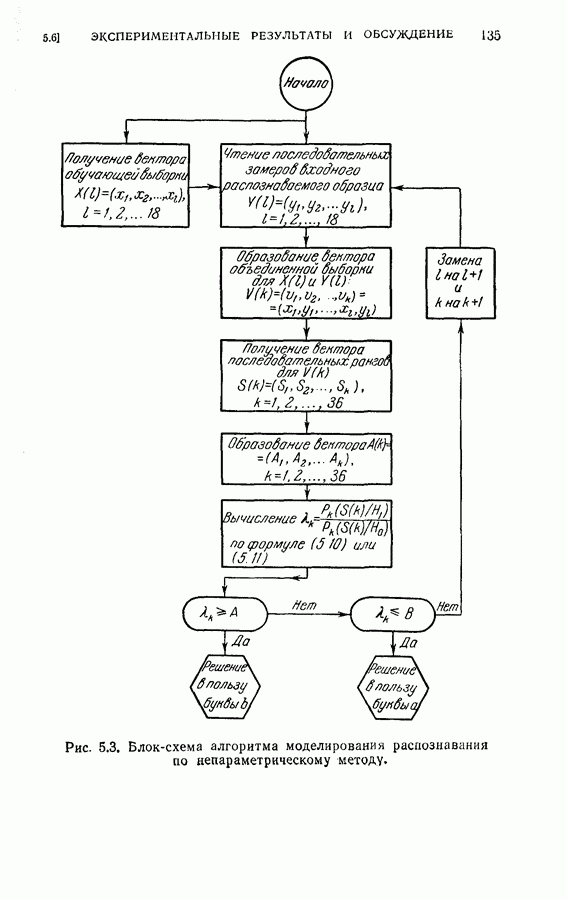
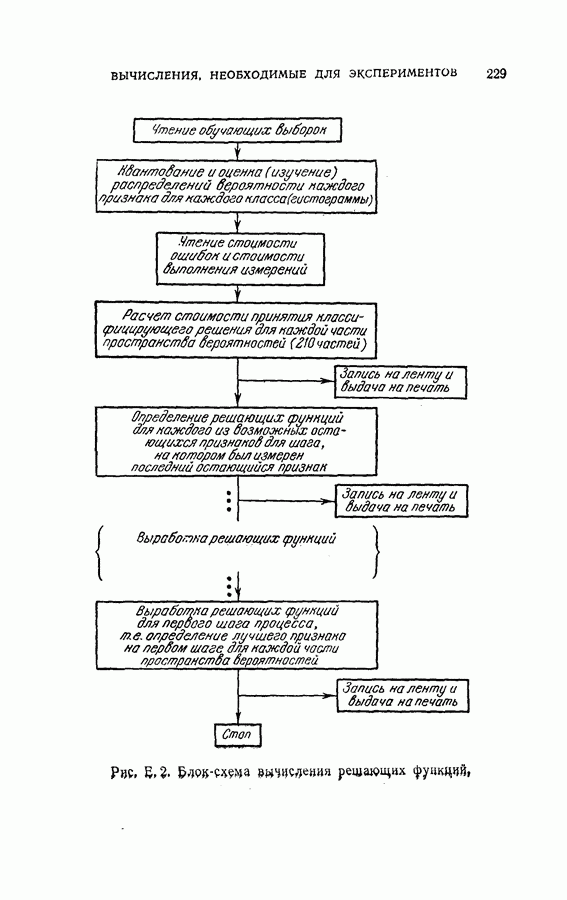
(кликните для просмотра скана) несущественное влияние соответствующих координат на характеристику выборок. Так как процедура упорядочения содержит только линейное преобразование, классификатор осуществляет ту же решающую функцию, что и в случае отсутствия упорядочения признаков, за исключением того, что классификация основана на преобразованном векторе Упрощенная блок-схема алгоритма модели системы распознавания на ЭЦМ с упорядоченными и неупорядоченными признаками приведена на рис. 2.3. Вначале проводилось распознавание из 240 выборок путем определения принадлежности к данному классу, основанное на двух первых замерах признаков, и вычислялся процент правильных распознаваний.
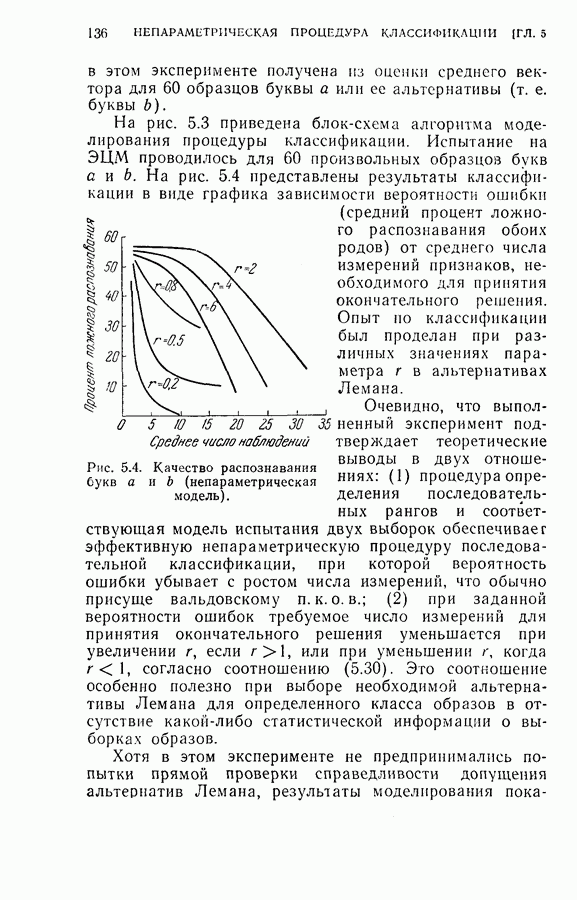
Рис. 2.4. Результаты распознавания. Затем эта процедура повторялась при одновременном добавлении двух следующих замеров до тех пор, пока не исчерпывались все восемнадцать признаков. Результаты распознавания приведены на рис. 2.4, где представлена зависимость процента правильных распознаваний от числа замеров. Заметим, что упорядочение замеров признаков проявляется распознавания во время нескольких первых измерений. Это обстоятельство особенно важно в тех случаях, когда число измерений признаков ограничено устройством обработки данных системы распознавания.
|
 |
Оглавление
|









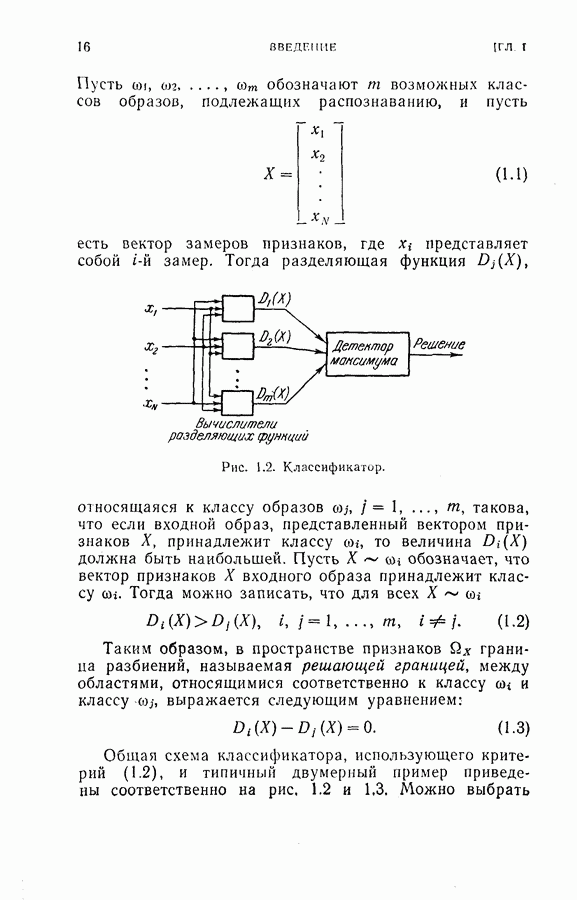
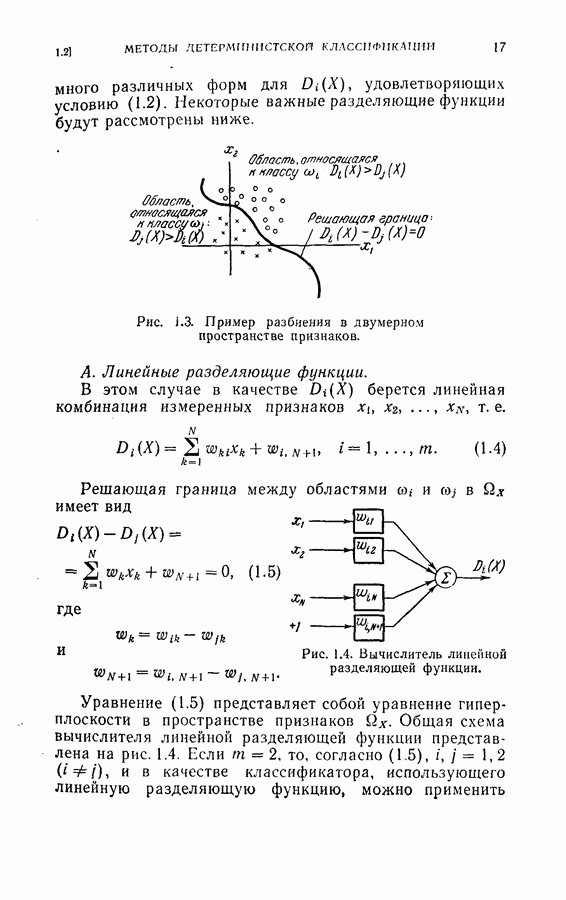








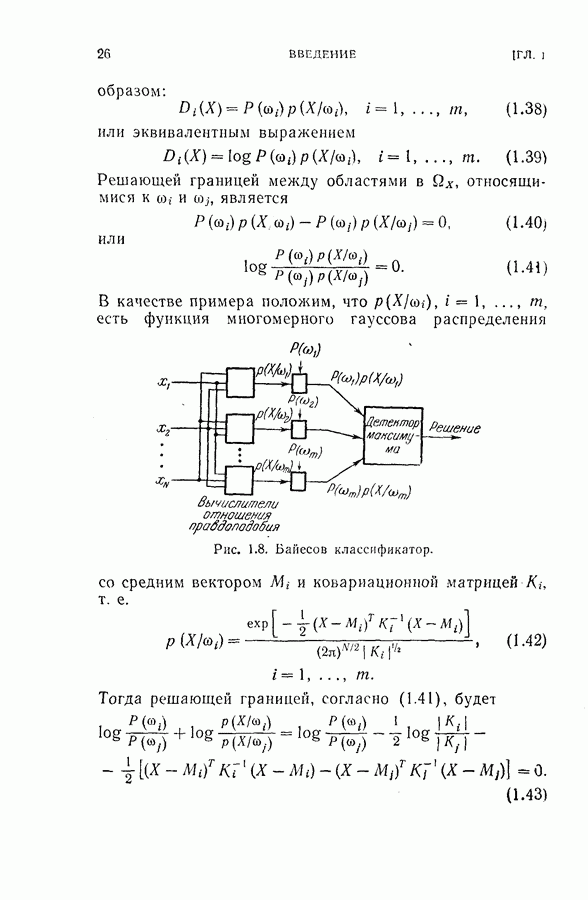






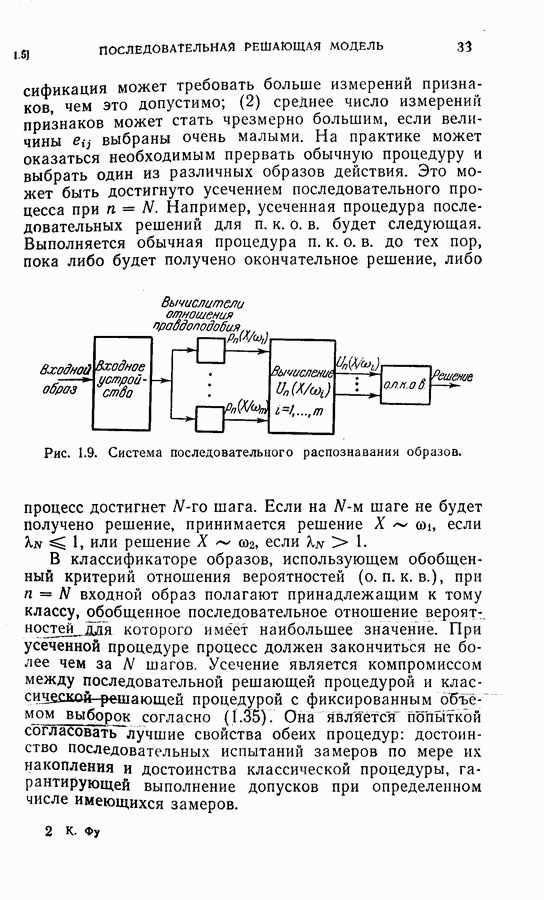


































































































































































































 для заглавных букв и 18 признаков
для заглавных букв и 18 признаков  для строчных букв, как показано на рис. 2.1. Каждый замер признака представлял собой расстояние, измеренное в заранее заданном направлении от края квадрата или окружности до края буквы (см. рис. 2.1). Эти признаки были выбраны в известной мере произвольно с надеждой на то, что для каждого класса образов функция распределения вероятностей признаков будет близка к многомерному гауссовому распределению. Во всех экспериментах, моделированных на цифровой вычислительной машине, делалось предположение о гауссовом распределении для каждого класса. (Заметим, что предположение о гауссовом распределении признаков исследовалось многими авторами
для строчных букв, как показано на рис. 2.1. Каждый замер признака представлял собой расстояние, измеренное в заранее заданном направлении от края квадрата или окружности до края буквы (см. рис. 2.1). Эти признаки были выбраны в известной мере произвольно с надеждой на то, что для каждого класса образов функция распределения вероятностей признаков будет близка к многомерному гауссовому распределению. Во всех экспериментах, моделированных на цифровой вычислительной машине, делалось предположение о гауссовом распределении для каждого класса. (Заметим, что предположение о гауссовом распределении признаков исследовалось многими авторами  Средний вектор и ковариационная матрица оценивались по ряду испытаний выборок вычислением выбранного среднего вектора и выборочной ковариационной матрицы.
Средний вектор и ковариационная матрица оценивались по ряду испытаний выборок вычислением выбранного среднего вектора и выборочной ковариационной матрицы.


 Восемь признаков предполагались статистически независимыми и измерялись последовательно. Предварительно были установлены симметричные останавливающие границы
Восемь признаков предполагались статистически независимыми и измерялись последовательно. Предварительно были установлены симметричные останавливающие границы  Их значения на поочередно следующих шагах равнялись:
Их значения на поочередно следующих шагах равнялись:

 шаге. Признаки в тех случаях, когда они были упорядочены, располагались соответственно их расхождениям, расставленным в порядке убывания. Для букв
шаге. Признаки в тех случаях, когда они были упорядочены, располагались соответственно их расхождениям, расставленным в порядке убывания. Для букв  в этом эксперименте порядок был следующим:
в этом эксперименте порядок был следующим:  Результаты распознавания показаны в табл. 2.1.
Результаты распознавания показаны в табл. 2.1.
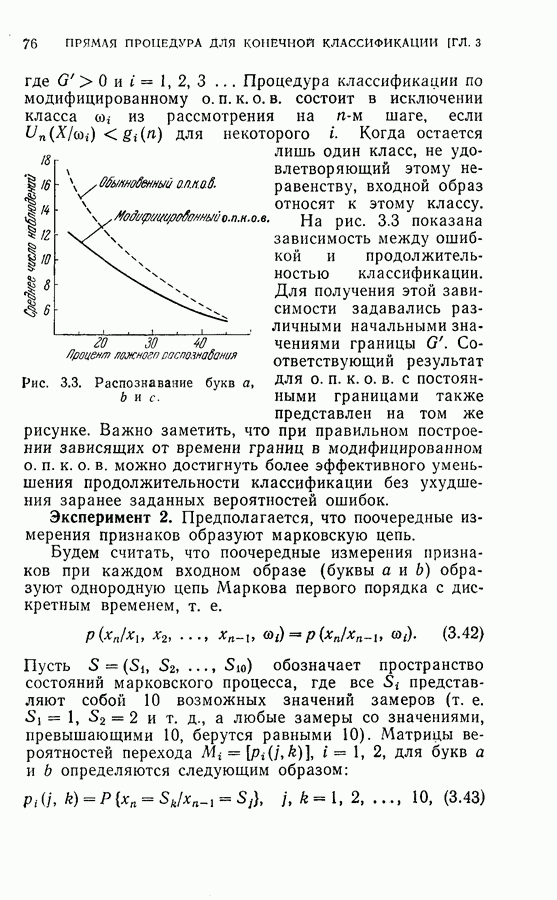
 признаков предполагались зависимыми и измерялись последовательно. Процесс классификации прерывался на
признаков предполагались зависимыми и измерялись последовательно. Процесс классификации прерывался на  шаге. Уменьшение среднего числа измерений при использовании п. к. о. в. со всей очевидностью показывают следующие результаты.
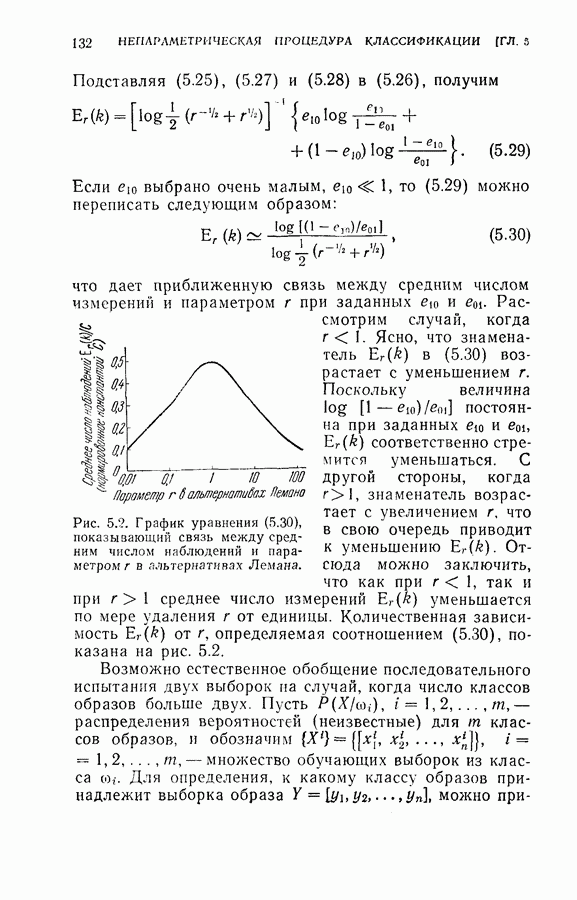
шаге. Уменьшение среднего числа измерений при использовании п. к. о. в. со всей очевидностью показывают следующие результаты.
 были неизменно равны соответственно +1,5 и —1,5.
были неизменно равны соответственно +1,5 и —1,5.

 изменялись от ±1,0 до ±1,85 с приращением на каждом
изменялись от ±1,0 до ±1,85 с приращением на каждом

 потребовал бы девять признаков.
потребовал бы девять признаков.
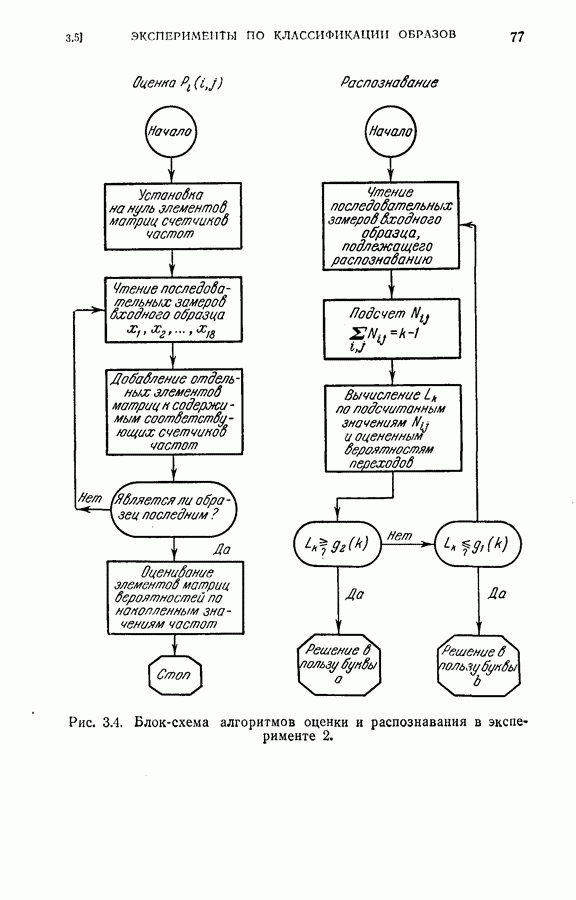
 Условия были такие же, как в (2), за исключением того, что для классификации был применен о. п. к. о. в. и признаки упорядочивались согласно соответствующим им значениям
Условия были такие же, как в (2), за исключением того, что для классификации был применен о. п. к. о. в. и признаки упорядочивались согласно соответствующим им значениям  Останавливающие границы
Останавливающие границы  были все равны 0,9. Результаты распознавания приведены в табл. 2.2.
были все равны 0,9. Результаты распознавания приведены в табл. 2.2.
 данных для заглавных букв
данных для заглавных букв  Имелось 28 возможных подмножеств по шесть признаков. Эти шесть признаков, дававших ближайшую верхнюю границу величины
Имелось 28 возможных подмножеств по шесть признаков. Эти шесть признаков, дававших ближайшую верхнюю границу величины  были
были  Эти же испытуемые выборки были затем использованы для испытания точности классификации. Процент правильных распознаваний при использовании этих шести признаков был 91,7%, а процент правильного распознавания при использовании всех восьми признаков был 93,1%. В общих случаях замеры признаков не были упорядочены. Результаты показаны в табл. 2.3.
Эти же испытуемые выборки были затем использованы для испытания точности классификации. Процент правильных распознаваний при использовании этих шести признаков был 91,7%, а процент правильного распознавания при использовании всех восьми признаков был 93,1%. В общих случаях замеры признаков не были упорядочены. Результаты показаны в табл. 2.3.
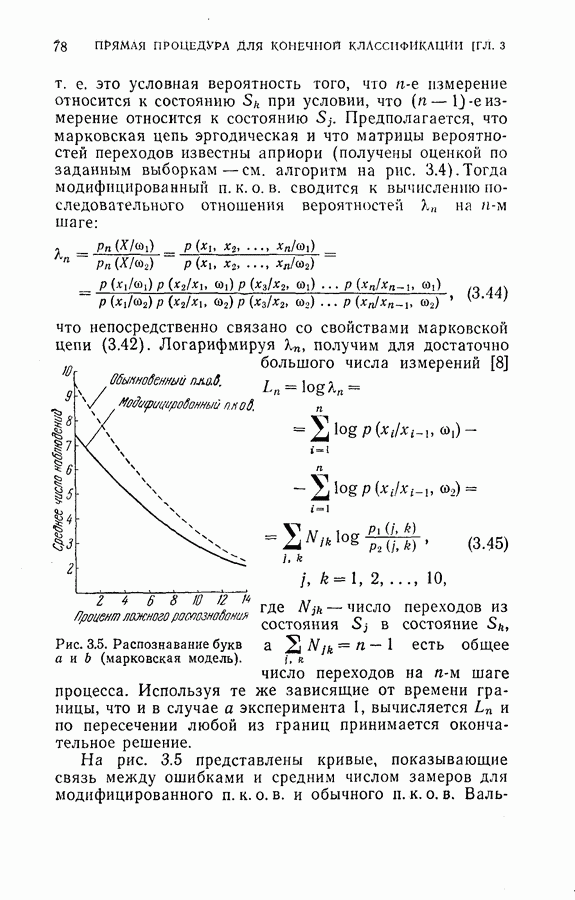
 Средние векторы и ковариационные матрицы оценивались по шестидесяти выборкам для каждой буквы (всего 240 выборок). Классификатор системы распознавания осуществлял байесово решающее правило с равными априорными вероятностями и функцией потерь (0,1). Вектор замеров признаков X преобразовывался в новый вектор
Средние векторы и ковариационные матрицы оценивались по шестидесяти выборкам для каждой буквы (всего 240 выборок). Классификатор системы распознавания осуществлял байесово решающее правило с равными априорными вероятностями и функцией потерь (0,1). Вектор замеров признаков X преобразовывался в новый вектор  согласно формуле преобразования (2.34). Оптимальные координатные векторы
согласно формуле преобразования (2.34). Оптимальные координатные векторы  в сущности являются собственными векторами, расположенными в порядке убывания соответствующих им собственных значений Функции ковариаций, определенной в (2.32). Эти
в сущности являются собственными векторами, расположенными в порядке убывания соответствующих им собственных значений Функции ковариаций, определенной в (2.32). Эти



 значительном повышении скорости
значительном повышении скорости