Пред.
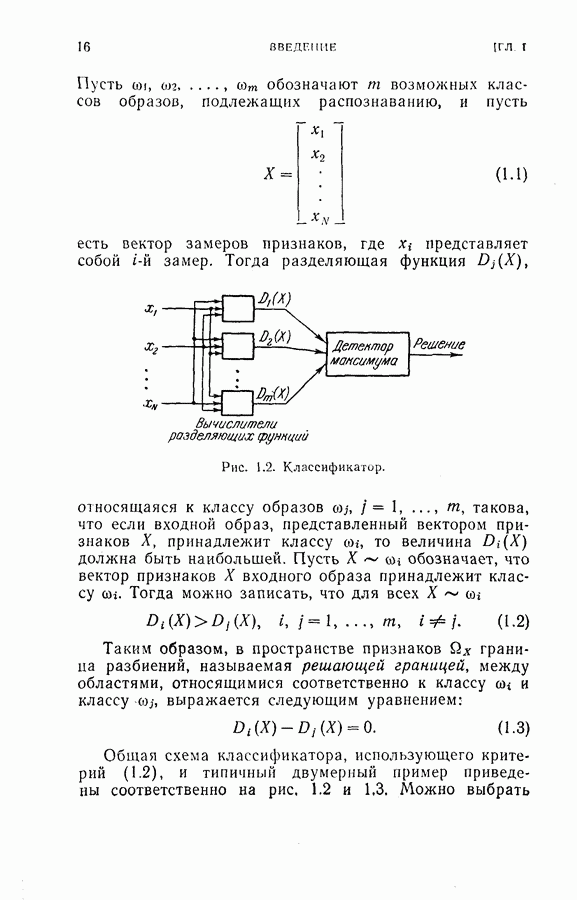
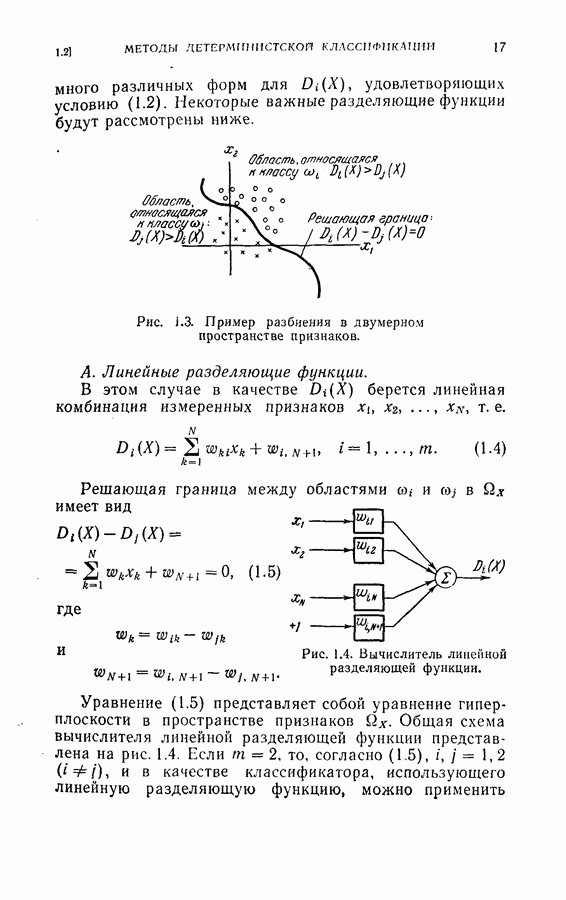
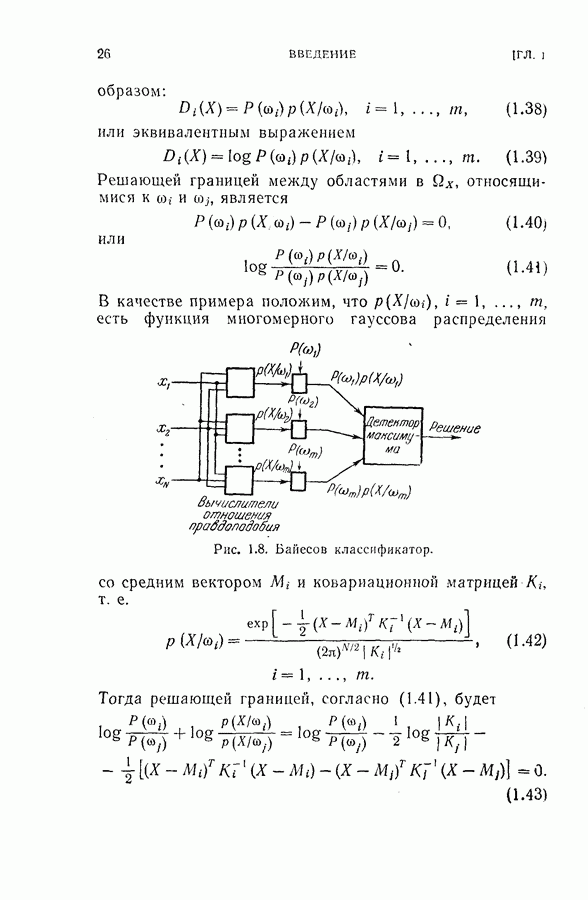
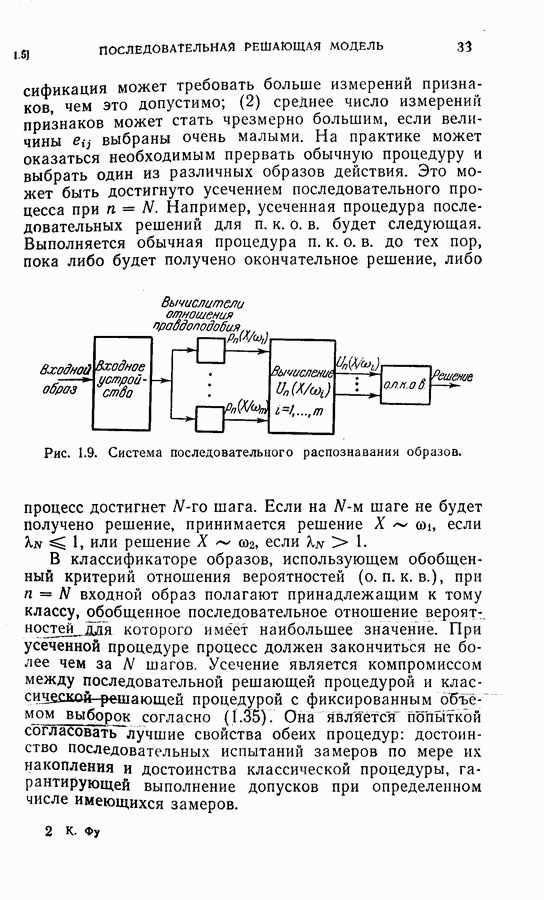
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
4. Методы ускорения сходимостиДля ускорения сходимости процедуры стохастической аппроксимации были предложены два подхода. Первый заключается в ускорении сходимости путем подбора соответствующей весовой последовательности Впервые такой метод ускорения сходимости процесса стохастической аппроксимации был предложен Кестеном [16]. Основная его идея заключается в том, что когда оценка далека от искомой величины 0, будет мало изменений знака
где
а
Это означает, что
для процедуры Роббинса-Монро
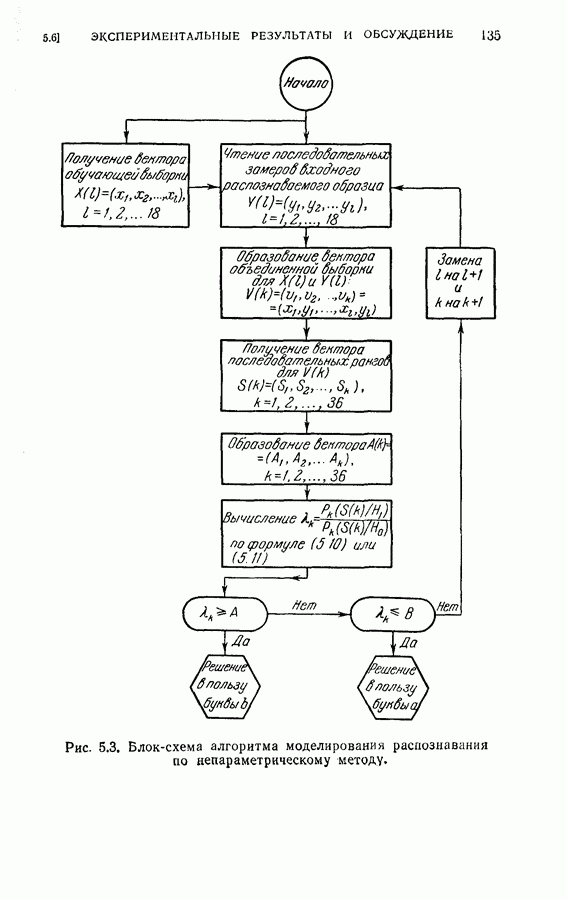
для процедуры Кифера — Вольфовица Алгоритмы
или в случае процедуры Кифера — Вольфовица, если
При весьма общих условиях, налагаемых на Второй подход к задаче ускорения сходимости заключается в использовании большего числа наблюдений на каждом шаге итераций. Интуитивно ясно, что, беря большее число наблюдений на каждом шаге, мы исследуем функцию регрессии более детально, чем в обычной процедуре стохастической аппроксимации [18, 19], и соответственно получаем возможность использовать дополнительную информацию для повышения скорости сходимости. Вентер и Фабиан предложили ускоренные алгоритмы для процедур Роббинса-Монро и Кифера— Вольфовица [20, 21]. Процедура Вентера заключается в оценке крутизны функции регрессии вблизи корня с помощью двух наблюдений на каждом шаге и в использовании этой информации для ускорения сходимости и уточнения асимптотической дисперсии процедуры Роббинса — Монро. Рекуррентный алгоритм имеет следующий вид:
где
и
Алгоритм
|
 |
Оглавление
|









































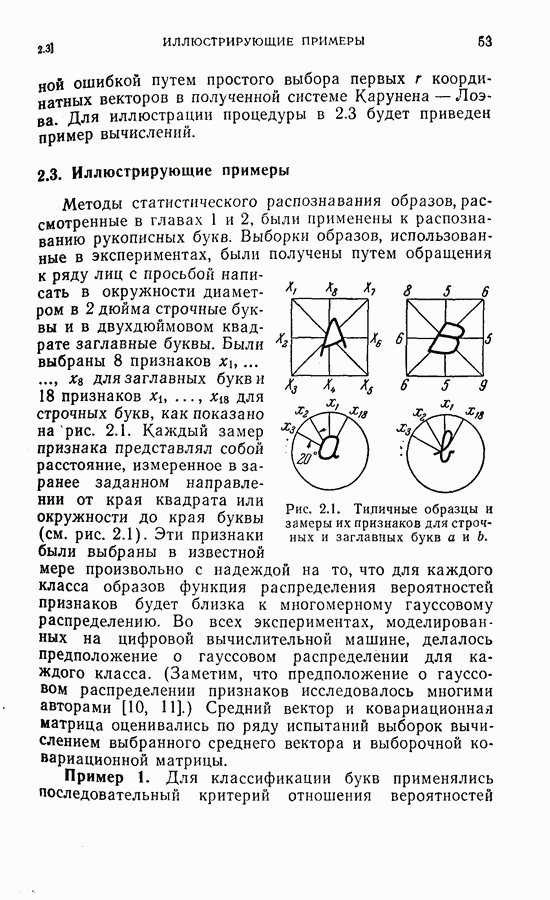

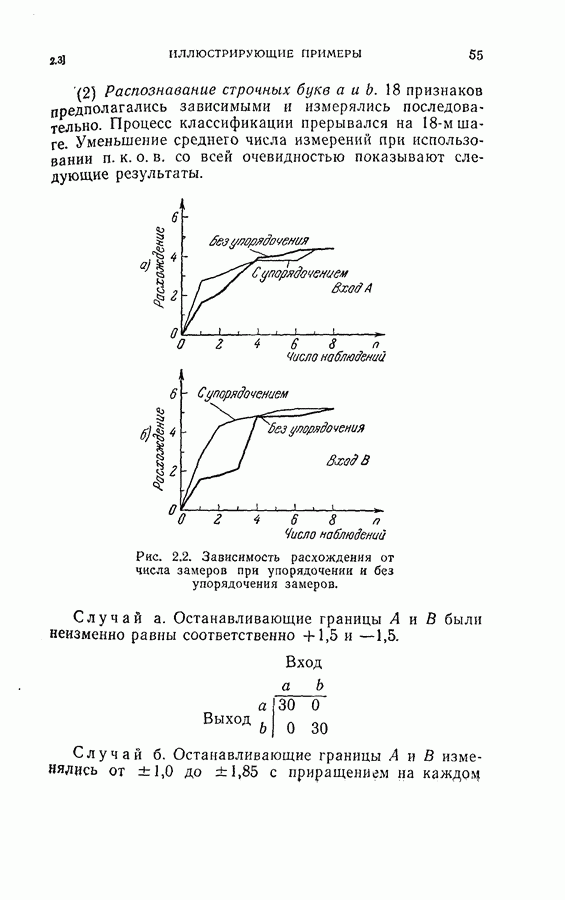


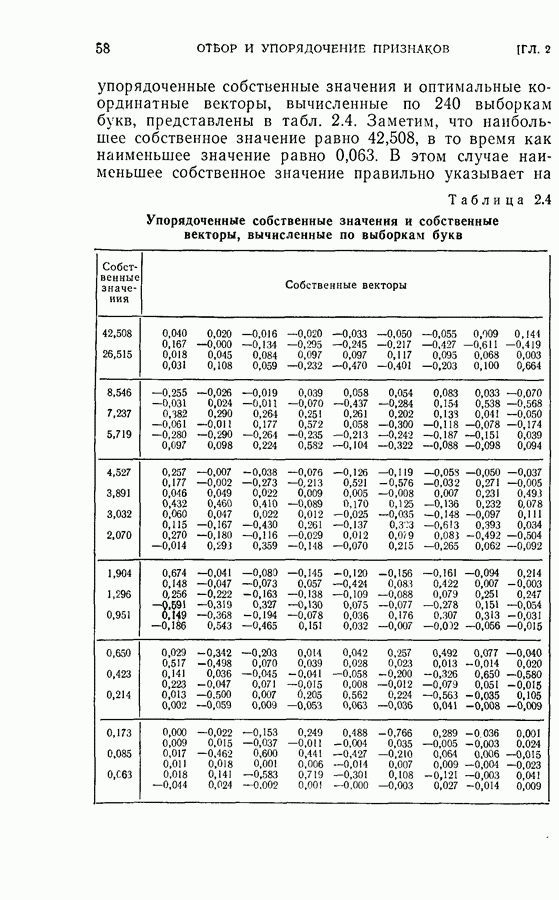
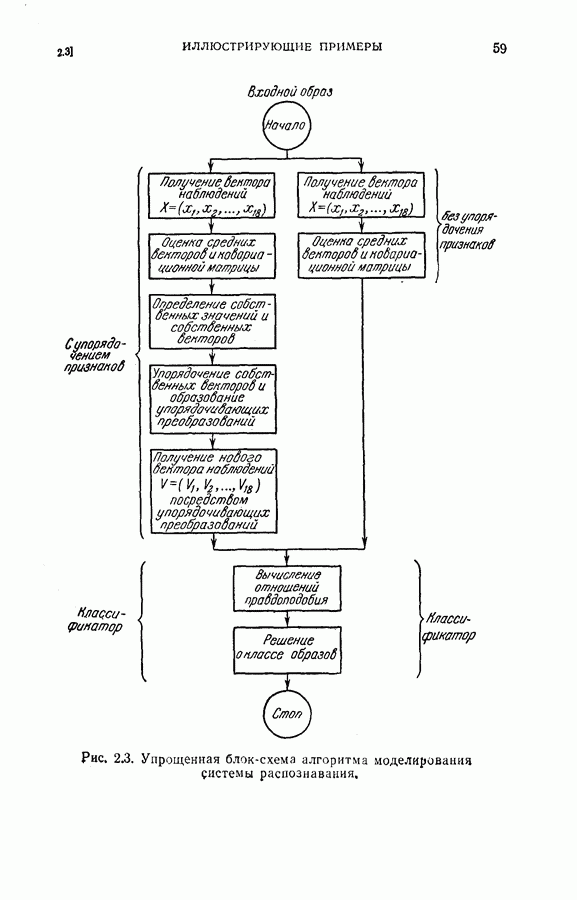













































































































































































 или
или  Интуитивно ясно, что разумный выбор весовой последовательности, основанный на информации, относящейся к поведению функции регрессии, должен улучшить скорость сходимости.
Интуитивно ясно, что разумный выбор весовой последовательности, основанный на информации, относящейся к поведению функции регрессии, должен улучшить скорость сходимости.
 Вблизи цели
Вблизи цели  можно ожидать превышений, вызывающих осцилляции вокруг значения 0. Кестен предложил использовать число перемен знака разности
можно ожидать превышений, вызывающих осцилляции вокруг значения 0. Кестен предложил использовать число перемен знака разности  как признак того, близка оценка к
как признак того, близка оценка к  или далека от него. В частности, величина
или далека от него. В частности, величина  не уменьшается, если
не уменьшается, если  сохраняет свой знак. Математически алгоритм может быть записан в форме процедуры Дворецкого
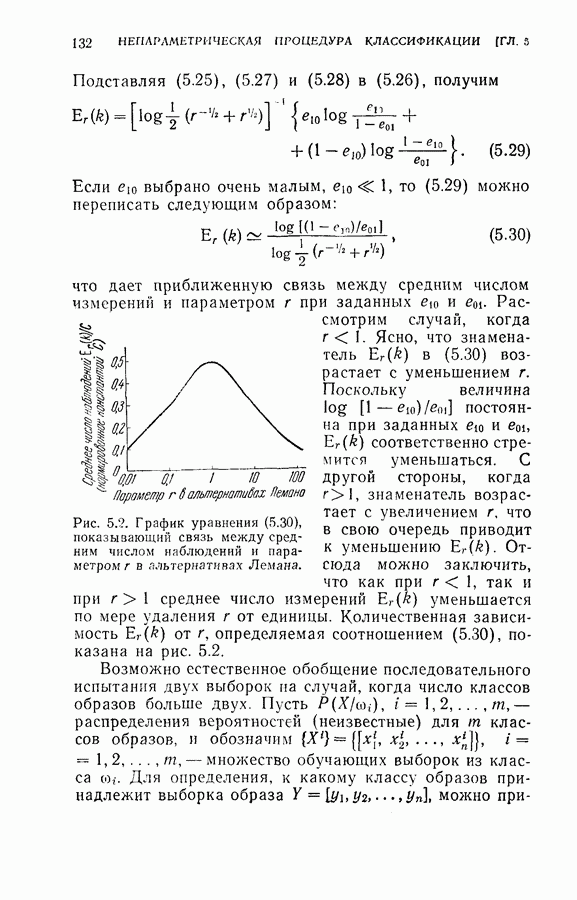
сохраняет свой знак. Математически алгоритм может быть записан в форме процедуры Дворецкого



 является постоянной, пока
является постоянной, пока  имеют один и тот же знак. Алгоритм
имеют один и тот же знак. Алгоритм  сходится с вероятностью единица. Фабиан предложил следующие ускоренные алгоритмы [17]:
сходится с вероятностью единица. Фабиан предложил следующие ускоренные алгоритмы [17]:



 и
и  сходятся к искомым величинам только в сравнительно узком классе задач, в которых функция распределения случайной величины у симметрична относительно 0. Другая схема ускоренной сходимости, предложенная Фабианом, использует аналог метода наискорейшего спуска. Эта схема сводится к следующему. Для данных
сходятся к искомым величинам только в сравнительно узком классе задач, в которых функция распределения случайной величины у симметрична относительно 0. Другая схема ускоренной сходимости, предложенная Фабианом, использует аналог метода наискорейшего спуска. Эта схема сводится к следующему. Для данных  и
и  берется ряд наблюдений (с помехой)
берется ряд наблюдений (с помехой)  величины
величины  Допустим, что величины
Допустим, что величины  независимы от
независимы от  Выберем
Выберем  если в случае процедуры Роббинса — Монро
если в случае процедуры Роббинса — Монро


 предложенный процесс сходится с вероятностью единица.
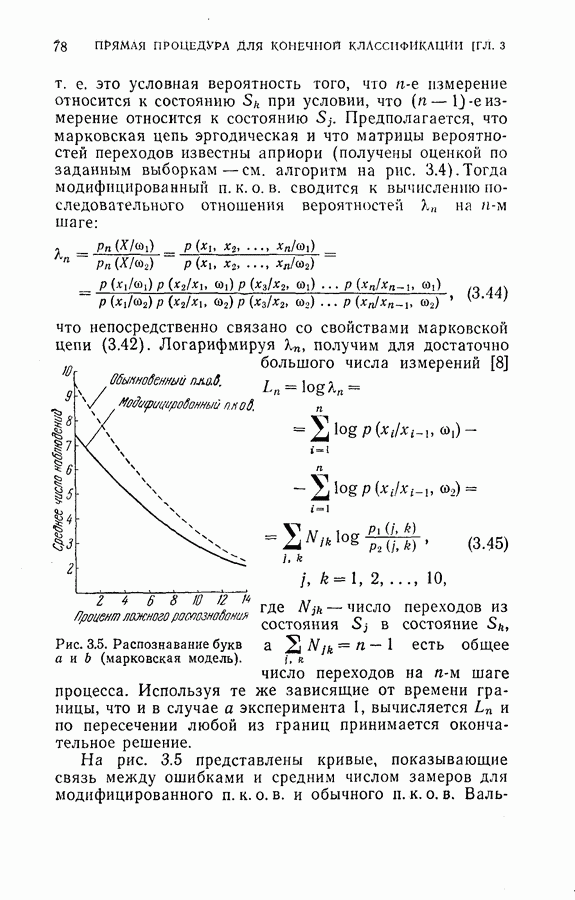
предложенный процесс сходится с вероятностью единица.

 и
и  независимые случайные величины, условные распределения которых при заданных
независимые случайные величины, условные распределения которых при заданных  тождественны распределениям
тождественны распределениям  представляют две последовательности положительных чисел.
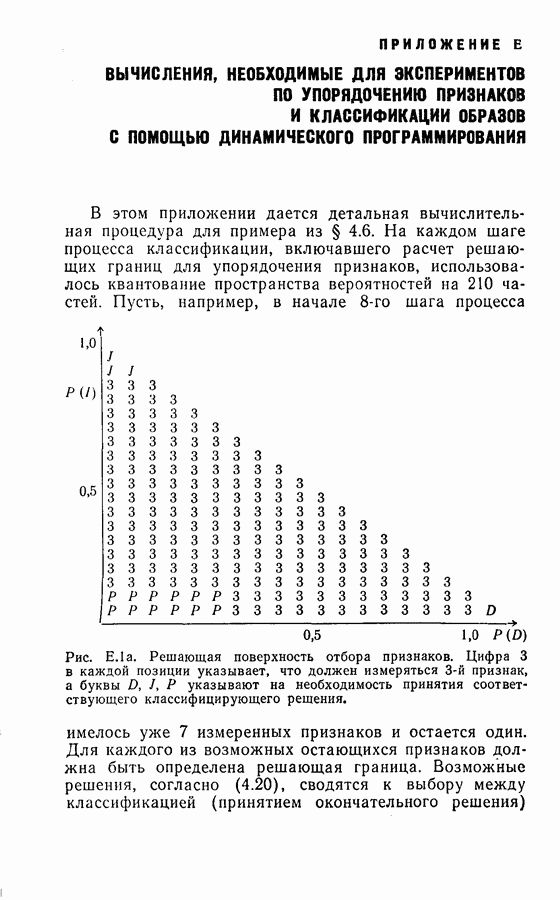
представляют две последовательности положительных чисел.  оценка крутизны а, которая определяется следующим образом: положим, что
оценка крутизны а, которая определяется следующим образом: положим, что  где
где  известны. Пусть
известны. Пусть


 сходится с вероятностью единица. Если, кроме того,
сходится с вероятностью единица. Если, кроме того,  то он сходится в среднеквадратичном. Эта же идея может быть применена к процедуре Кифера — Вольфовица. В этом случае на каждом шаге итераций делаются три наблюдения и соответствующие разности второго порядка (вторые разности замеров) используются для оценки производной второго порядка функции регрессии вблизи максимума (или минимума), та информация далее используется для определения следующей оценки
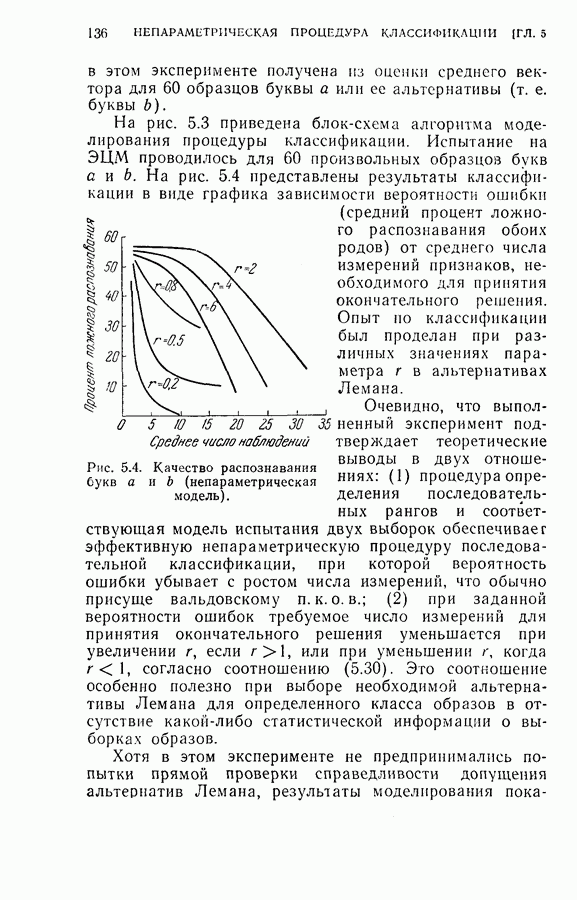
то он сходится в среднеквадратичном. Эта же идея может быть применена к процедуре Кифера — Вольфовица. В этом случае на каждом шаге итераций делаются три наблюдения и соответствующие разности второго порядка (вторые разности замеров) используются для оценки производной второго порядка функции регрессии вблизи максимума (или минимума), та информация далее используется для определения следующей оценки  максимума (или минимума). С помощью аналогичной идеи, предложенной Фабианом. можно так модифицировать процедуру Кифера — Вольфовица, что скорость ее сходимости становится почти такой же, как у процедуры Роббинса — Монро. Эта модификация заключается в том, что увеличивается число наблюдений на каждом шаге итераций и эта информация используется для исключения (отфильтровывания) влияния всех производных высокого порядка функции регрессии.
максимума (или минимума). С помощью аналогичной идеи, предложенной Фабианом. можно так модифицировать процедуру Кифера — Вольфовица, что скорость ее сходимости становится почти такой же, как у процедуры Роббинса — Монро. Эта модификация заключается в том, что увеличивается число наблюдений на каждом шаге итераций и эта информация используется для исключения (отфильтровывания) влияния всех производных высокого порядка функции регрессии.