Пред.
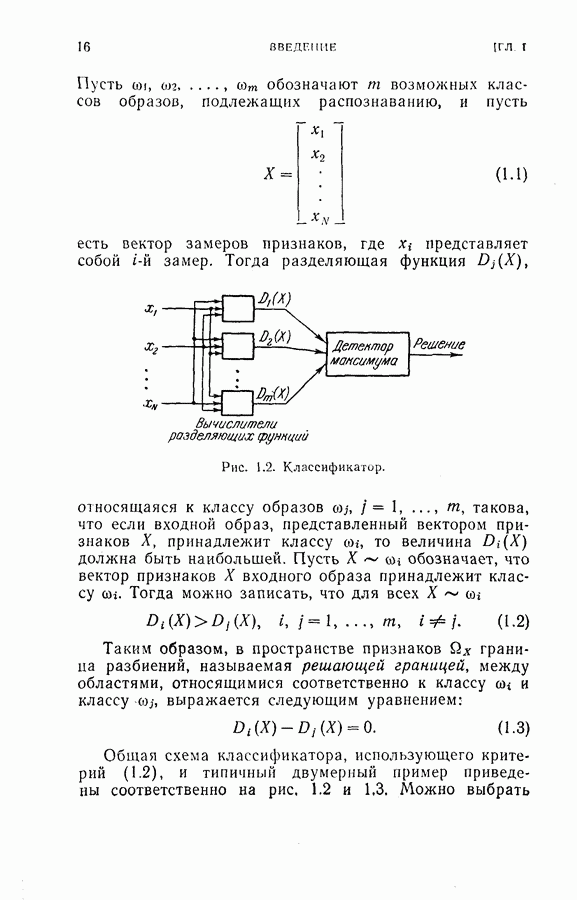
След.
Макеты страниц
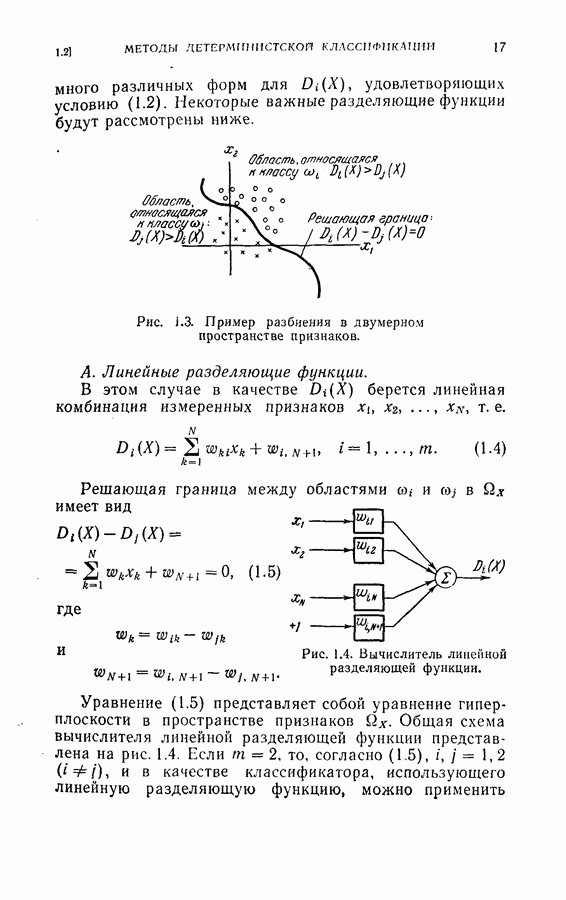
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
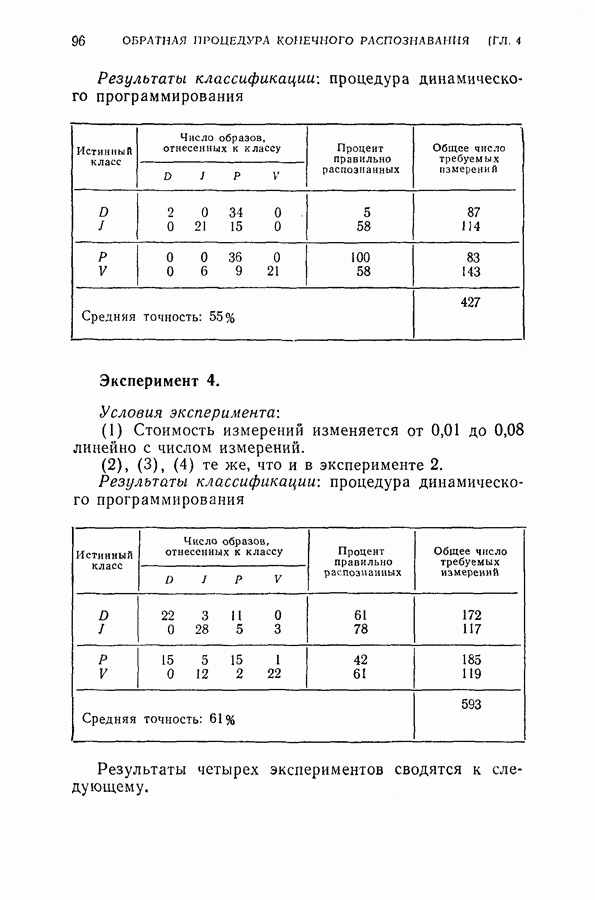
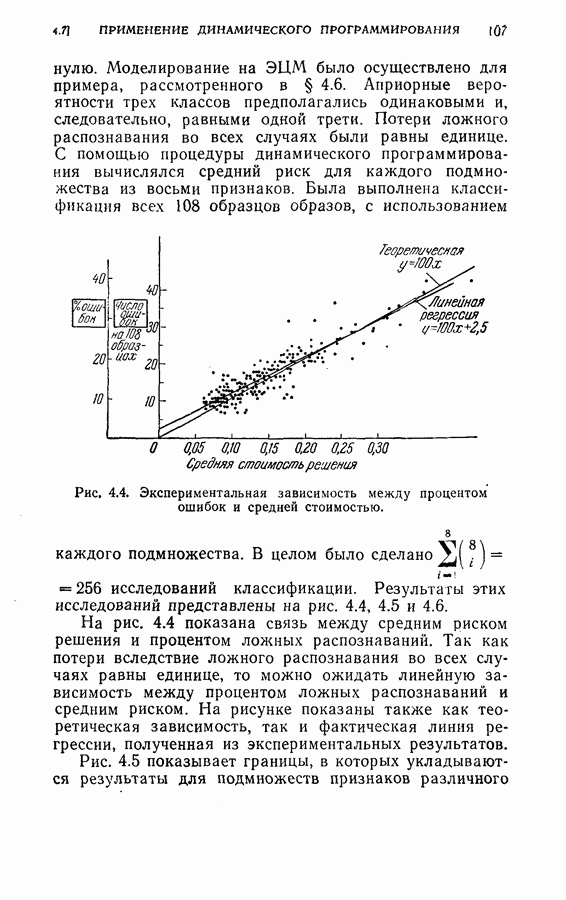
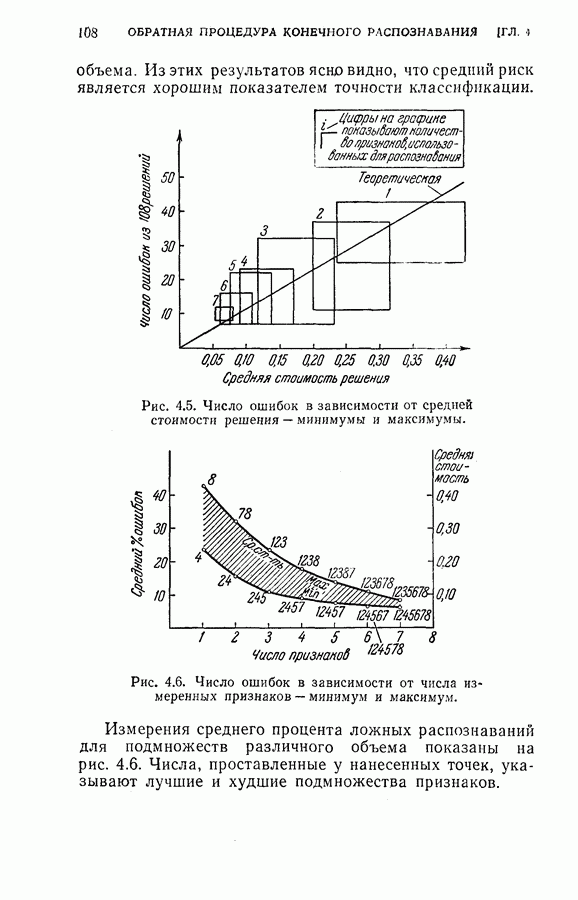
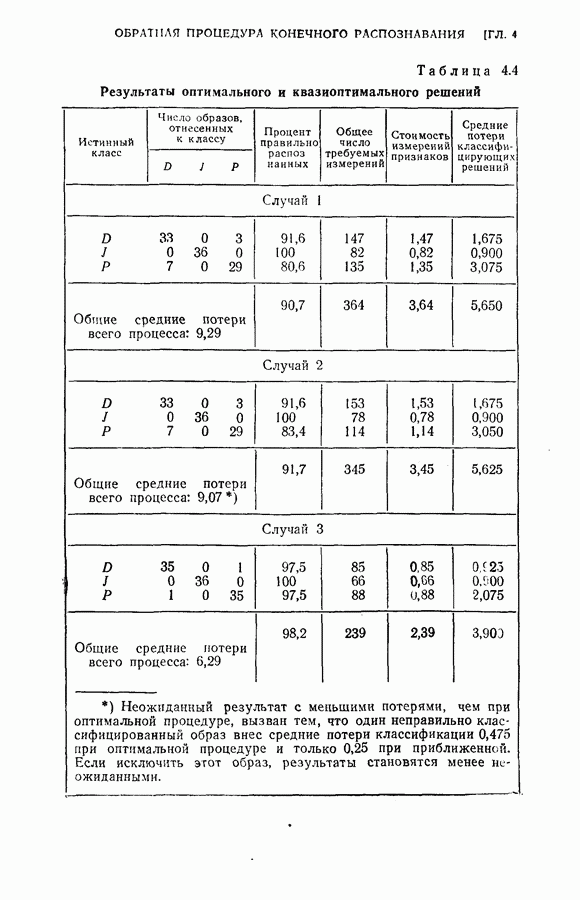
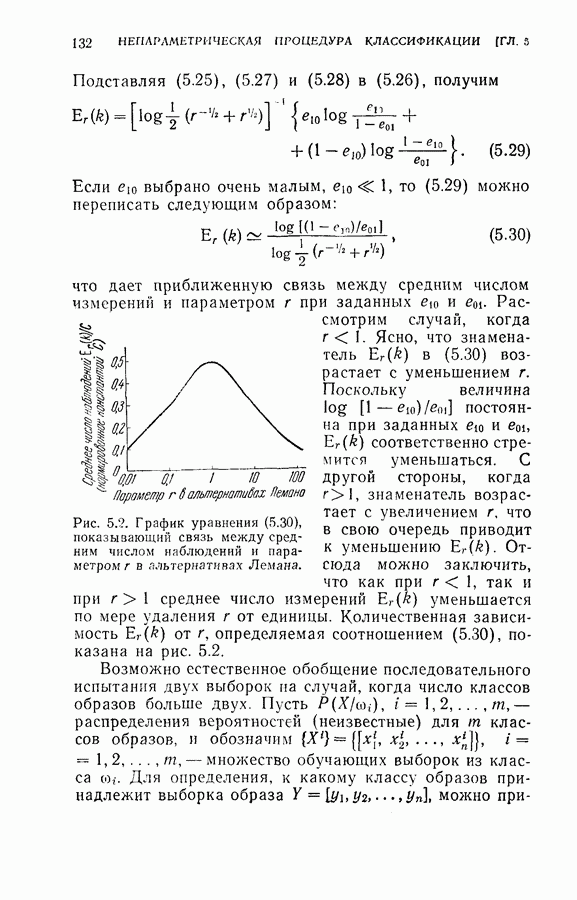
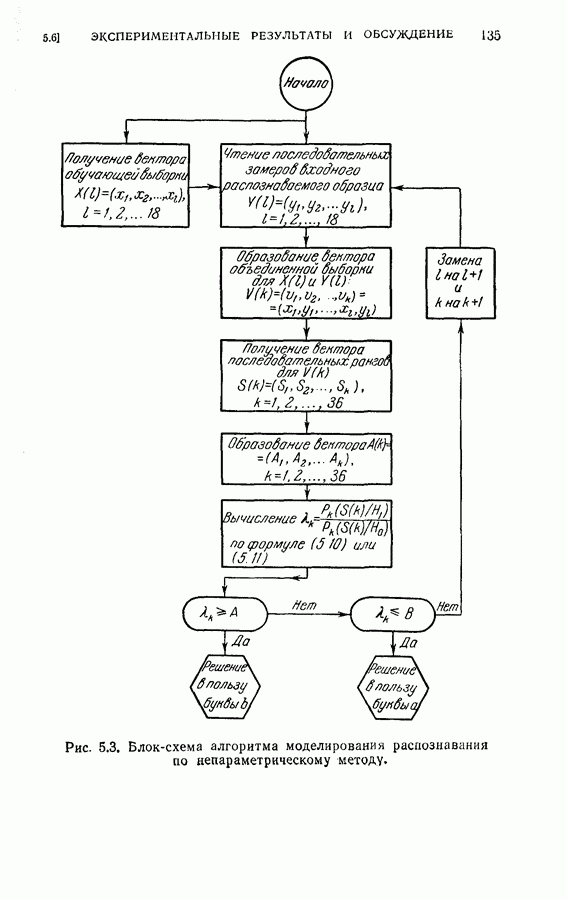
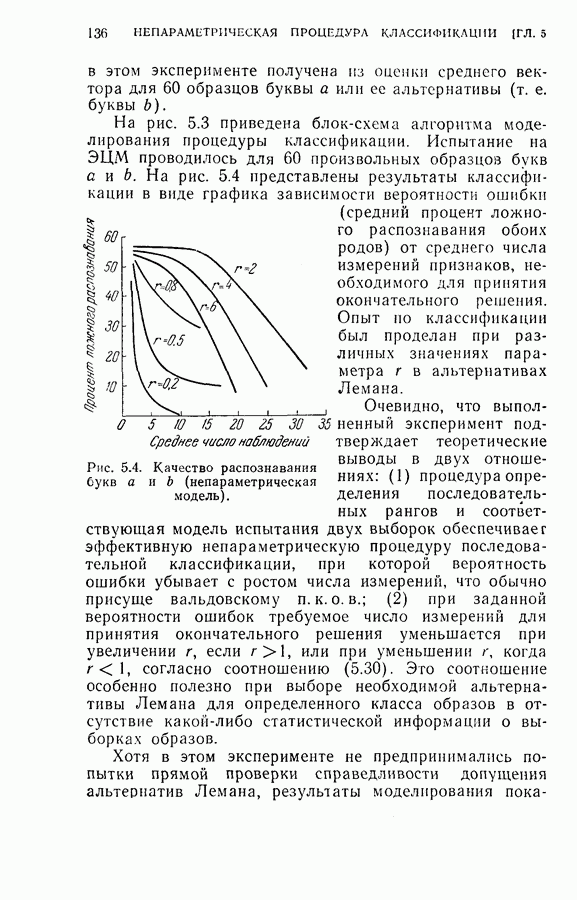
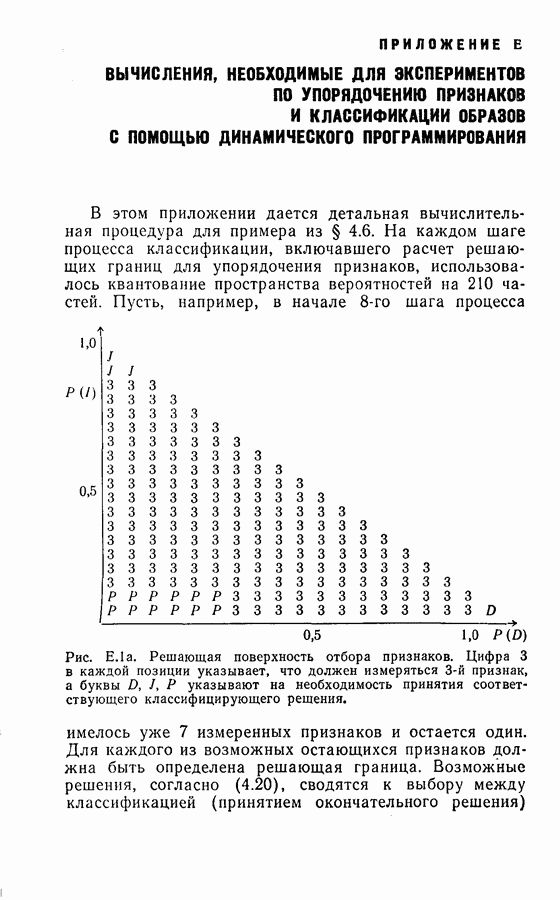
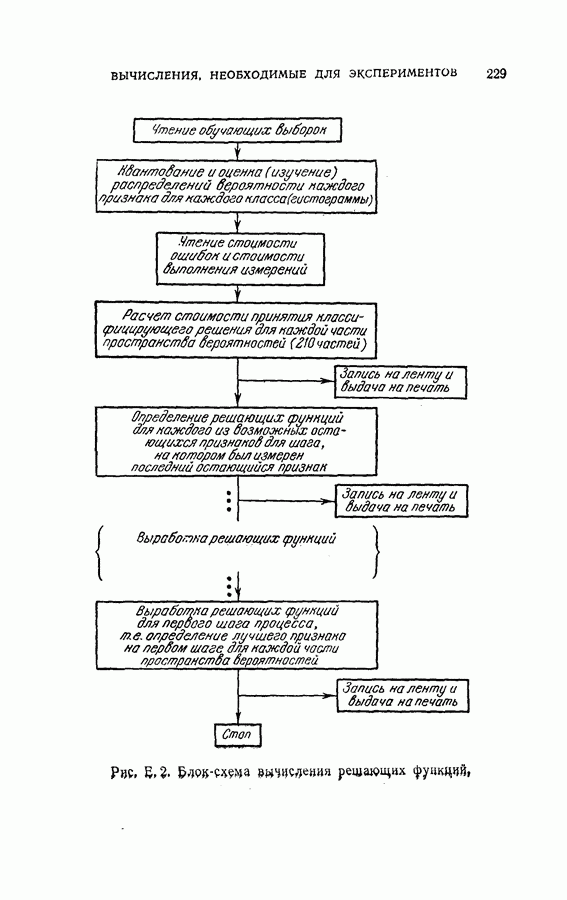
4.8. Квазиоптимальное последовательное распознавание образовВ § 4.5 была развита обратная процедура для построения оптимального режима упорядочения признаков и классификации образов. В общем случае для вычисления по формуле (4.20) требуется знание функций плотности совместных вероятностей всех признаков и априорных вероятностей для каждого класса. При осуществлении этой процедуры часто оказывается трудным избежать большого объема вычислений. Если в практических задачах распознавания приемлемы некоторые допущения (например, о независимости замеров), то оптимальная процедура может быть осуществлена так, как это было изложено в § 4.6. Однако все же желательно получить приближение к оптимальной процедуре, которое позволило бы существенно упростить вычисления. В настоящем параграфе рассматривается способ приближения, который приводит к квазиоптимальному решению, и проводится сравнение с оптимальной процедурой, чтобы показать соотношение между оптимальностью и вычислительными трудностями. Аппроксимация, приводящая к квазиоптимальному решению, заключается в том, что на каждом шаге классификатор рассматривает следующий шаг как завершающий, т. е. работает так, как будто на следующем шаге должно быть принято классифицирующее решение. Для иллюстрации эффективности квазиоптимального решения было выбрано три различных случая: Случай 1. Оптимальное решение при независимости замеров для каждого класса. Случай 2. Квазиоптимальное решение (усечение на следующем шаге) при независимости замеров для каждого класса. Случай 3. Квазиоптимальное решение при замерах каждого класса, подчиняющихся марковской зависимости первого порядка. Сравнение случаев 1 и 2 показывает влияние приближения, обусловленного усечением. С другой стороны, сравнение случаев 1 и 3 позволяет определить относительный выигрыш, который ценой усложнения вычислений достигается либо 1) более полным учетом информации о статистической зависимости между вероятностями признаков, но при усеченной обратной процедуре, либо 2) выполнением в целом всей программы обратных вычислений при упрощающих предположениях о вероятностях. Случай 1. В этом случае
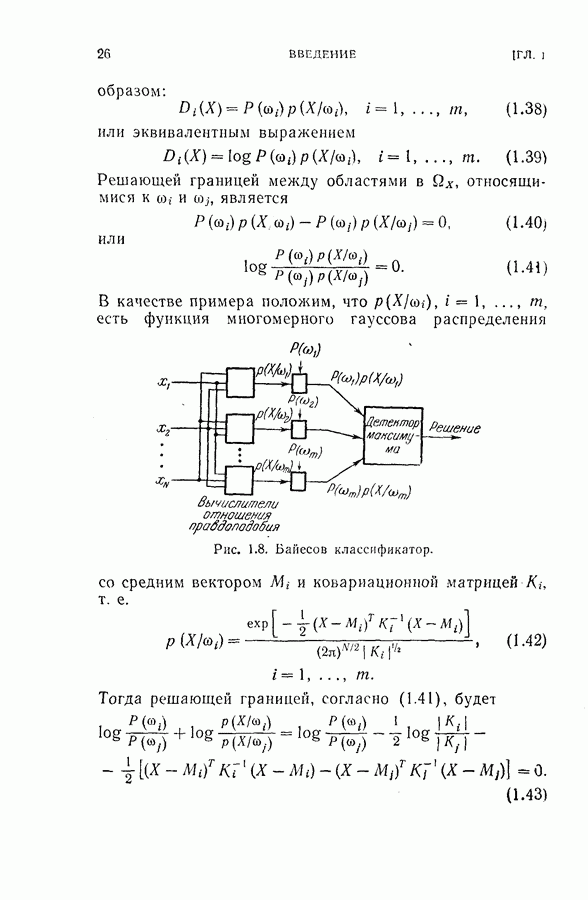
Уравнение (4.23) можно использовать для вычисления на каждом шаге апостериорных вероятностей каждого класса. Пусть
Тогда основное рекуррентное уравнение (4.20), использующее
Случай 2. Уравнение (4.26) в этом случае принимает
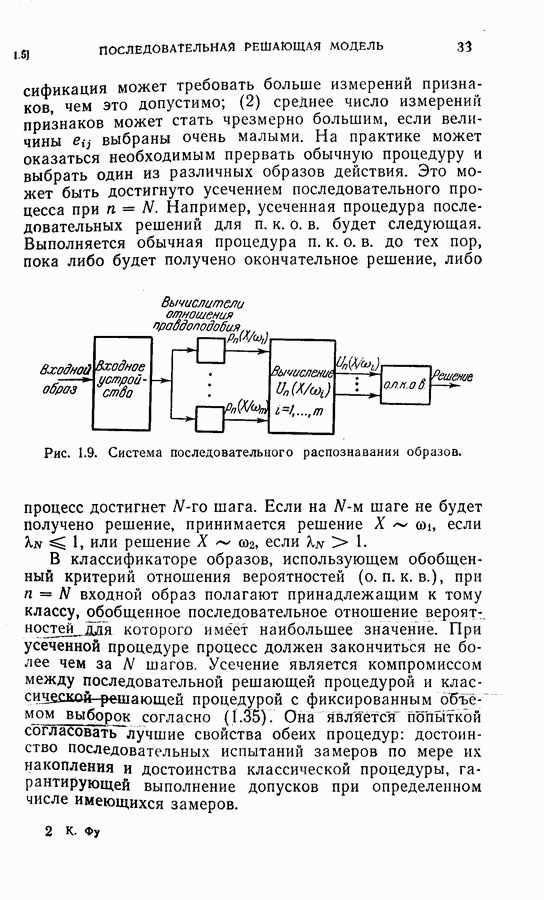
Следует отметить, что процесс усреднения в формуле (4.27) всегда производится по стоимости завершающих шагов и легко выполняется, когда процесс последовательного распознавания продолжается. Таким образом, требование, предъявляемое к объему памяти (т. е. память для значений стоимости на каждом шаге), резко сокращается и необходимые вычисления упрощаются. Случай 3. Здесь
и апостериорные вероятности вычисляются следующим образом:
Тогда достаточной статистикой является
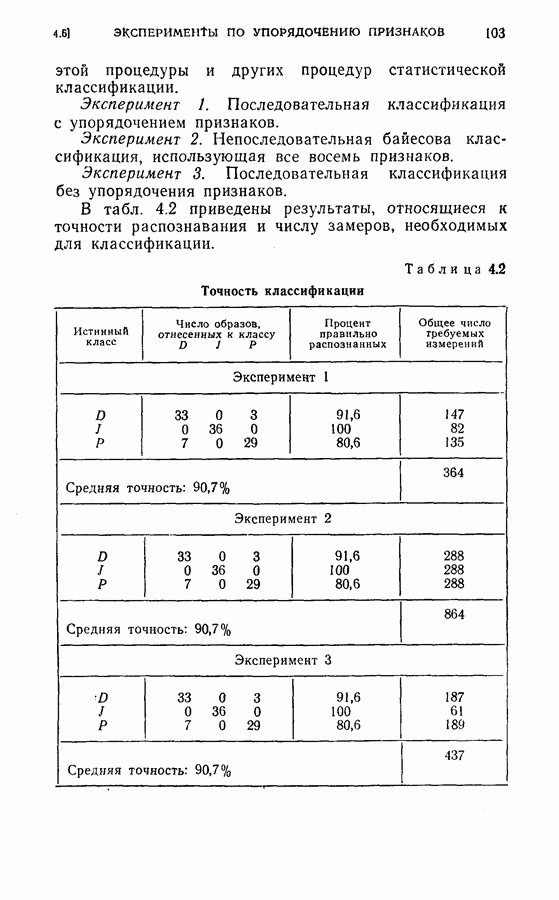
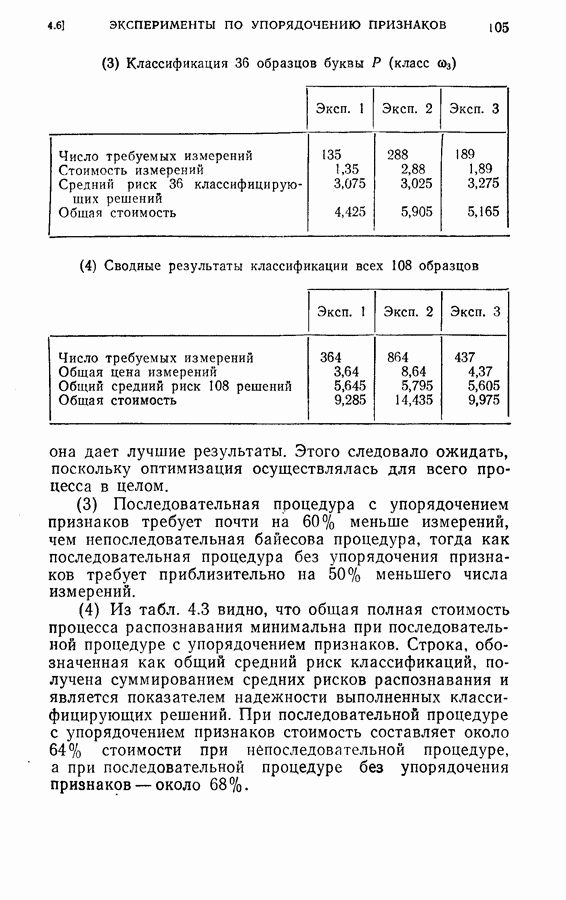
Легко видеть, что вся информация, полученная из предыдущей истории выбора признаков и замеров, включая В случае 3 требуется дополнительная память для хранения последнего замера. Более серьезные требования к памяти определяются необходимостью хранить матрицы переходов и иметь дополнительный объем для учета меняющейся функции стоимости на каждом шаге. Конечно, главное достоинство вычислений остается в том, что усреднение выражения (4.30) производится только завершающим шагом и легко может быть вычислено на каждом шаге процесса. (см. скан) Для проверки постановки задачи в случаях 1, 2 и 3 в качестве примера вновь было использовано распознавание букв Из результатов, приведенных в табл. 4.4 для данного примера, следует, что, используя марковские статистики и приближения с усечением на один шаг вперед, мы могли бы учесть корреляцию между замерами и все же сохранить возможность осуществления последовательного процесса распознавания, близкого к оптимальному. Конечно, когда замеры в действительности независимы, марковское предположение не дает улучшения по сравнению с предположением о независимости.
|
 |
Оглавление
|


























































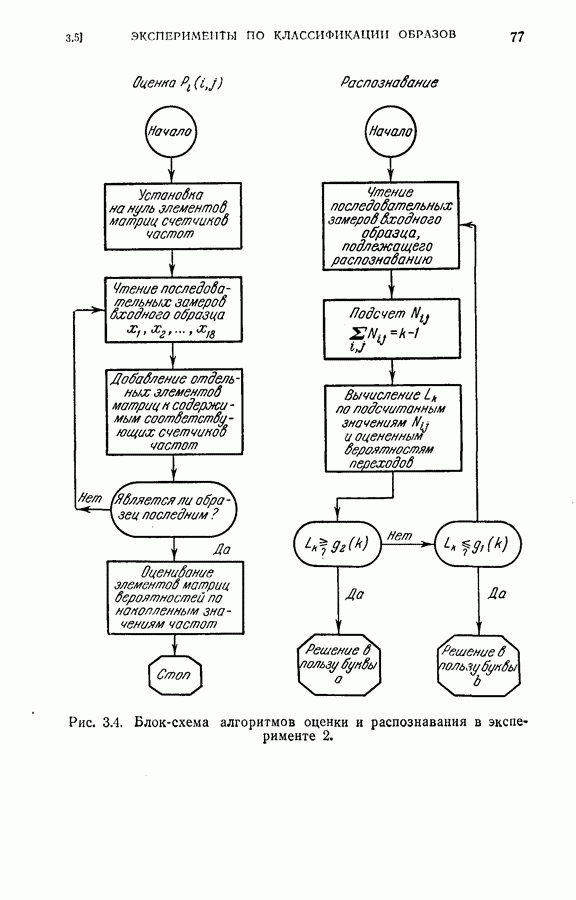


















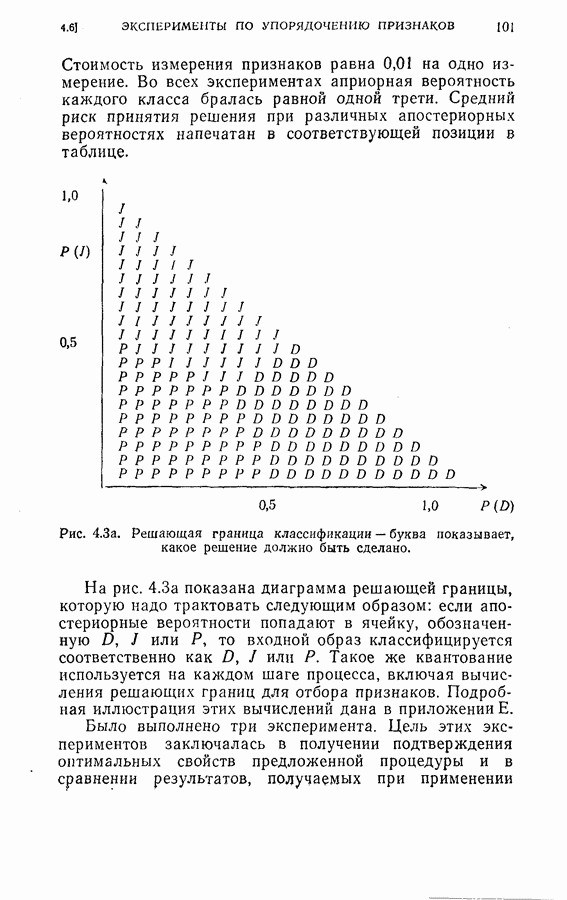














































































































































 множество апостериорных вероятностей появления каждого класса, вычисленное по формуле (4.23), т. е.
множество апостериорных вероятностей появления каждого класса, вычисленное по формуле (4.23), т. е.

 как достаточную статистику, приводится к следующему:
как достаточную статистику, приводится к следующему:




 и формула (4.20) принимает вид
и формула (4.20) принимает вид

 шаг, содержится в вычисленной апостериорной вероятности. Остается только следить за тем, какие признаки измеряются и какие условные вероятности вычисляются. Таким образом, фактические значения полученных замеров и порядок измеренных признаков можно исключить из рассмотрения, тем самым сократить объем вычислений и необходимую память.
шаг, содержится в вычисленной апостериорной вероятности. Остается только следить за тем, какие признаки измеряются и какие условные вероятности вычисляются. Таким образом, фактические значения полученных замеров и порядок измеренных признаков можно исключить из рассмотрения, тем самым сократить объем вычислений и необходимую память.
 Были использованы те же обучающие образцы, что и в § 4.6 для установления необходимых функций плотности вероятностей и вероятностей перехода. В табл. 4.4 приведены результаты, полученные при стоимости измерений каждого признака на любом шаге, равной 0,01, и при потерях, вызванных любой ошибкой классификации, равных 1,0.
Были использованы те же обучающие образцы, что и в § 4.6 для установления необходимых функций плотности вероятностей и вероятностей перехода. В табл. 4.4 приведены результаты, полученные при стоимости измерений каждого признака на любом шаге, равной 0,01, и при потерях, вызванных любой ошибкой классификации, равных 1,0.