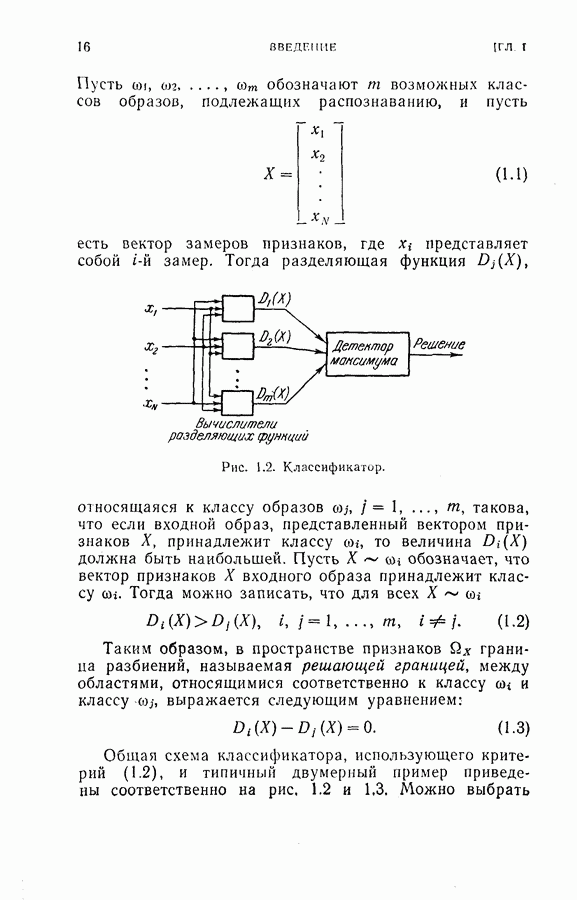
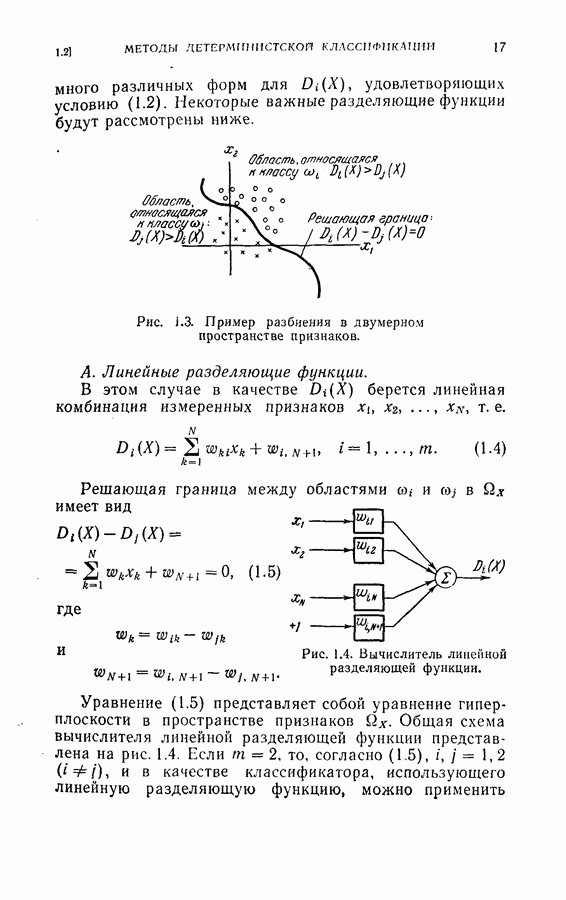
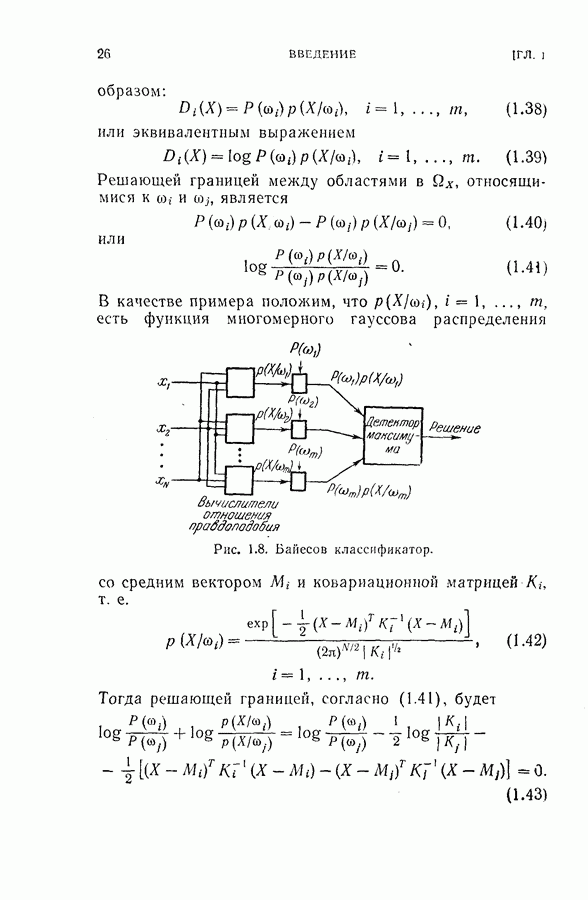
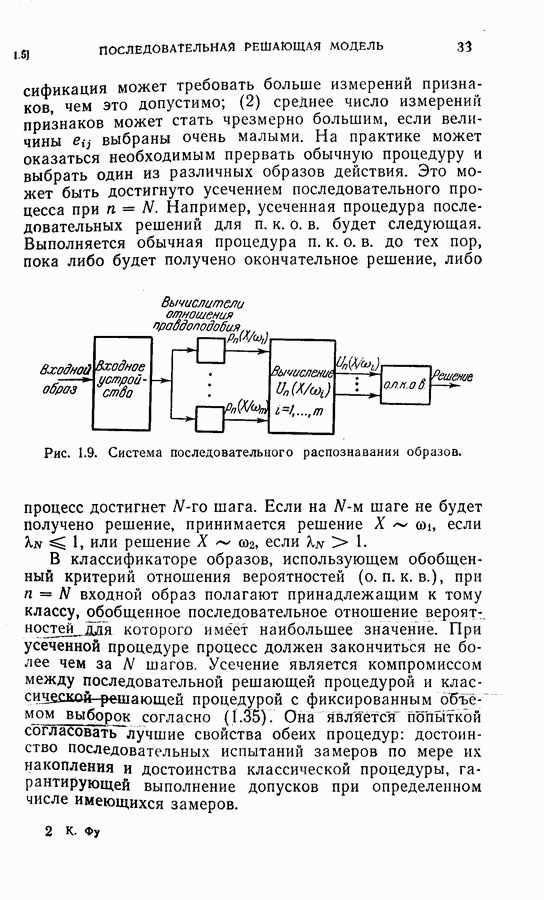
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
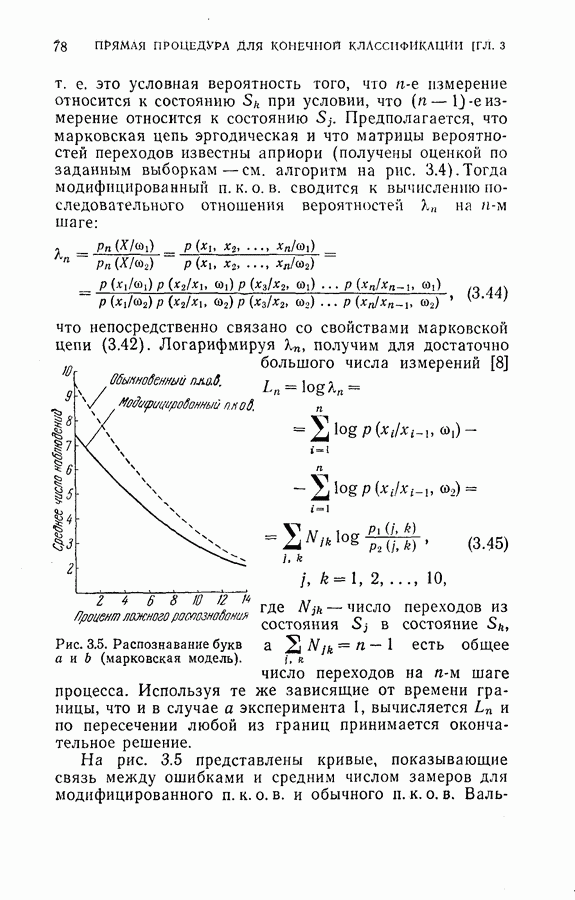
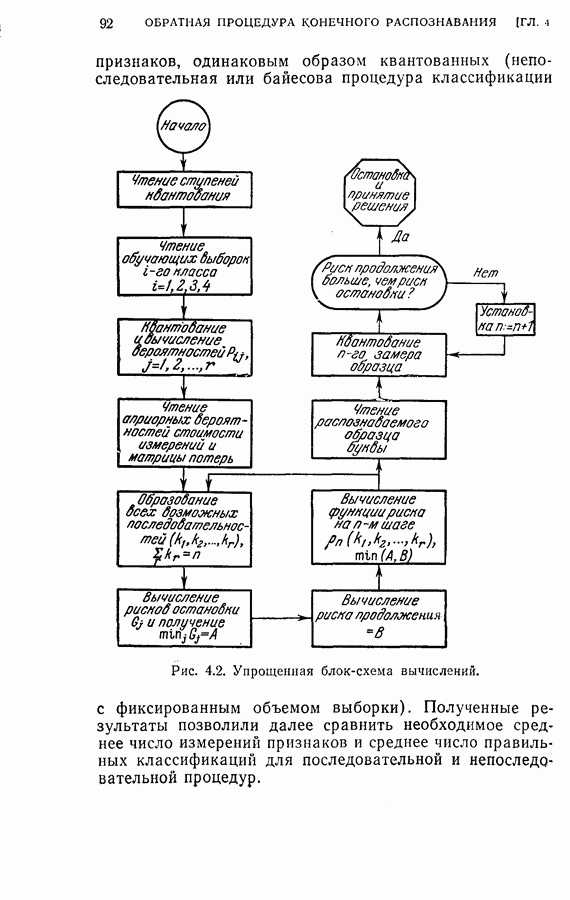
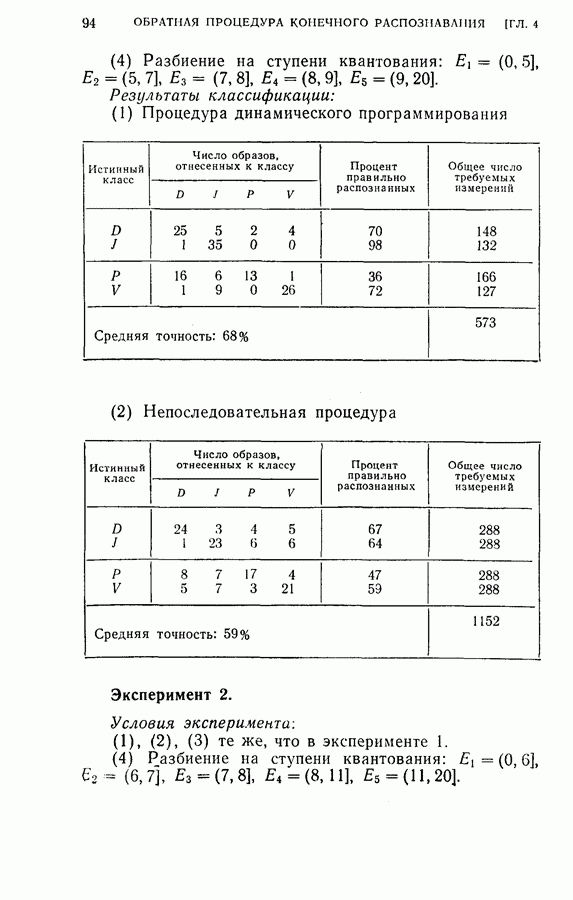
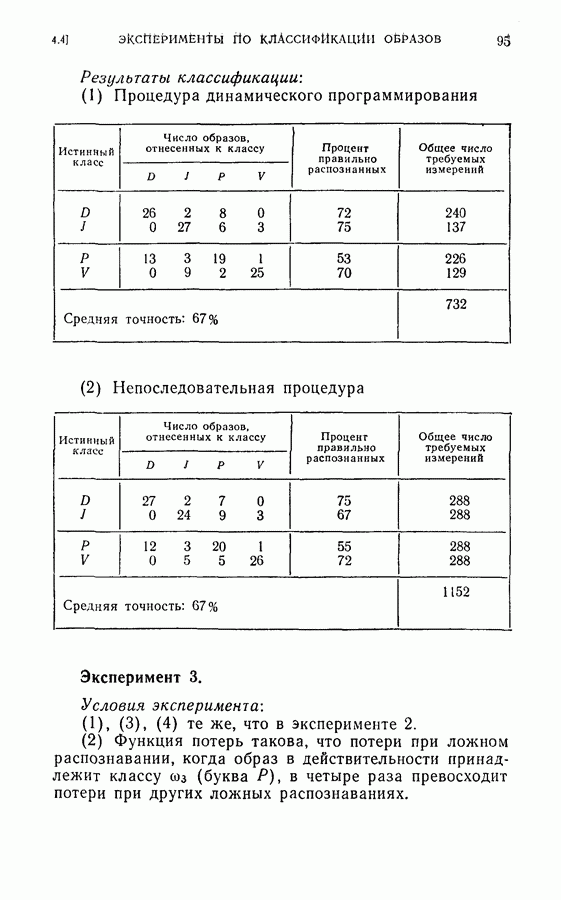
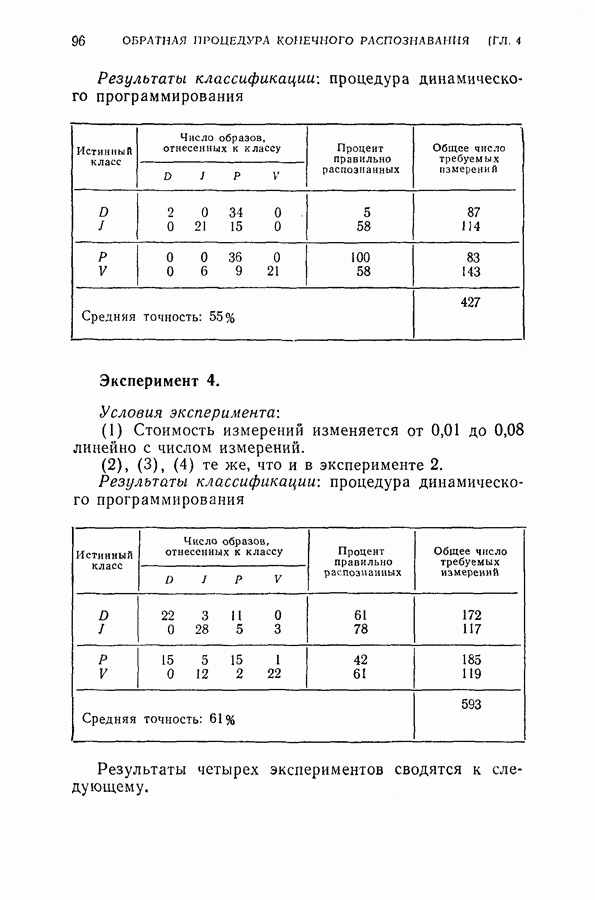
4.7. Применение динамического программирования для отбора подмножества признаковПредложенная для упорядочения признаков и классификации образов процедура динамического программирования может быть модифицирована для отбора оптимального подмножества из данного множества признаков. В этом параграфе рассматриваются два частных случая. Когда для классификации образов применена усеченная последовательная решающая процедура, важно выбирать из данного множества признаков лучшее подмножество, объем которого равен усеченной длине. Процедура динамического программирования позволяет решить и этот тип задачи выбора признаков. Положим, например, что надо распознать три буквы
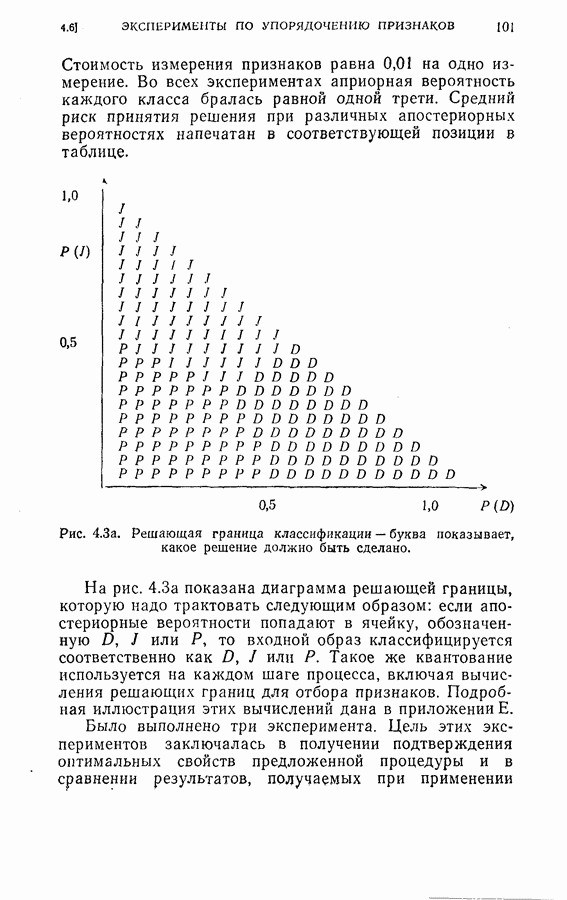
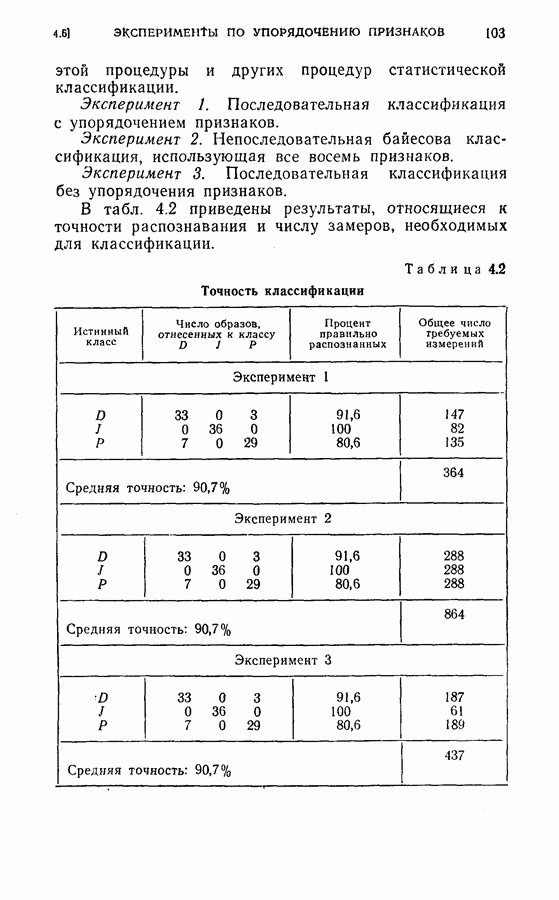
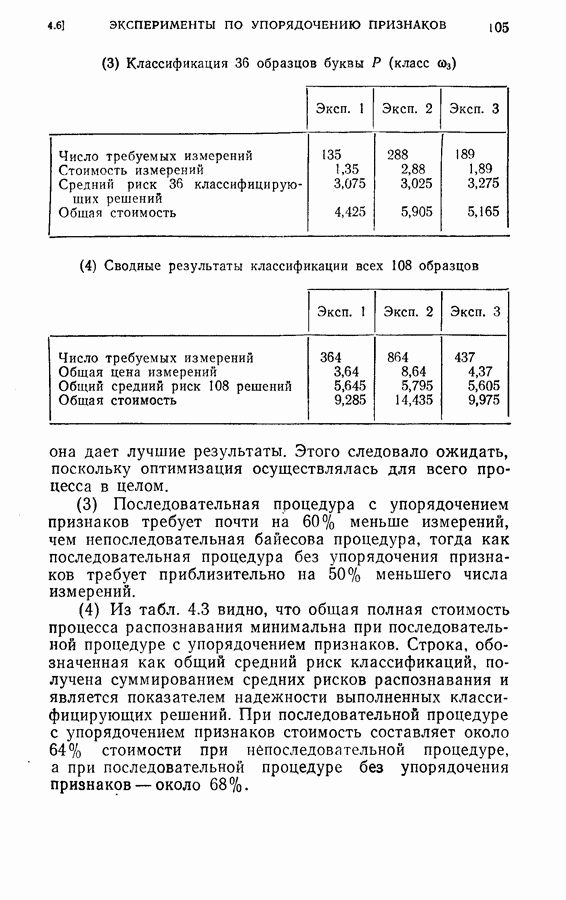
дают одинаковый минимальный средний риск для процесса. Любое из трех упорядоченных подмножеств признаков является оптимальным подмножеством с пятью признаками. Если для классификации образов используется непоследовательная решающая байесова процедура или процедура максимального правдоподобия, то процедура динамического программирования также может быть применена для определения лучшего подмножества из данного множества признаков. Единственное отличие данного случая от только что рассмотренного заключается в том, что стоимость выполнения измерений равна нулю. Моделирование на ЭЦМ было осуществлено для примера, рассмотренного в § 4.6. Априорные вероятности трех классов предполагались одинаковыми и, следовательно, равными одной трети. Потери ложного распознавания во всех случаях были равны единице. С помощью процедуры динамического программирования вычислялся средний риск для каждого подмножества из восьми признаков.
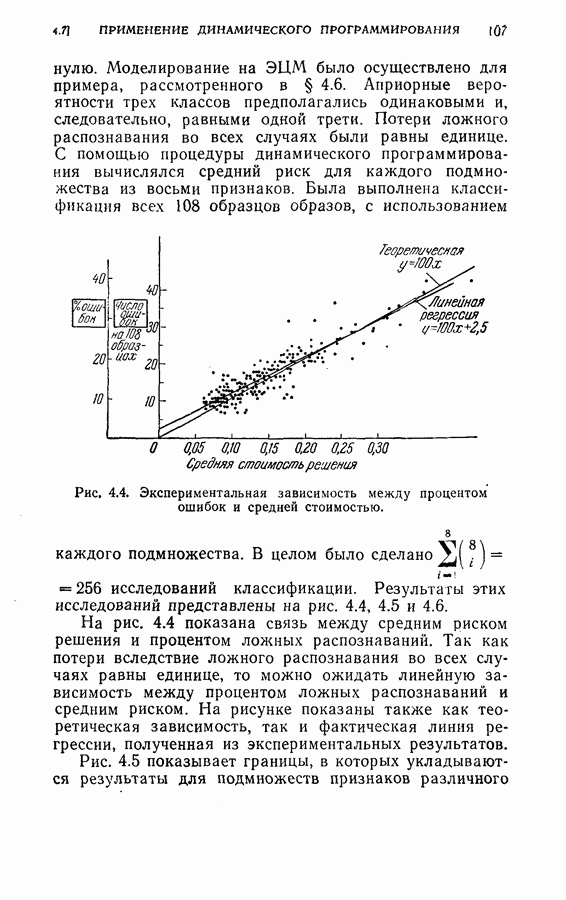
Рис. 4.4. Экспериментальная зависимость между процентом ошибок и средней стоимостью. Была выполнена классификация всех 108 образцов образов, с использованиемкаждого подмножества. В целом было сделано На рис. 4.4 показана связь между средним риском решения и процентом ложных распознаваний. Так как потери вследствие ложного распознавания во всех случаях равны единице, то можно ожидать линейную зависимость между процентом ложных распознаваний и средним риском. На рисунке показаны также как теоретическая зависимость, так и фактическая линия регрессии, полученная из экспериментальных результатов. Рис. 4.5 показывает границы, в которых укладываются результаты для подмножеств признаков различного объема. Из этих результатов ясно видно, что средний риск является хорошим показателем точности классификации.
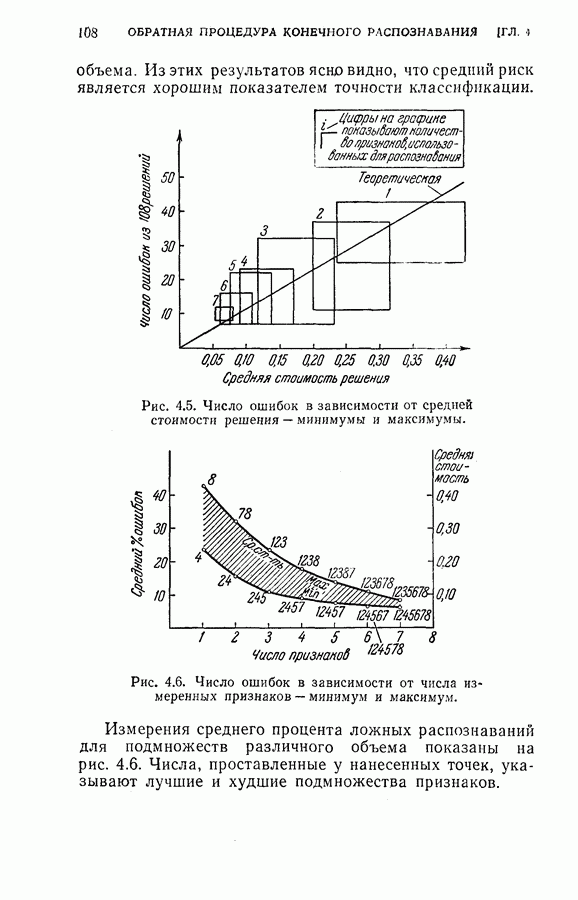
Рис. 4.5. Число ошибок в зависимости от средней стоимости решения — минимумы и максимумы.
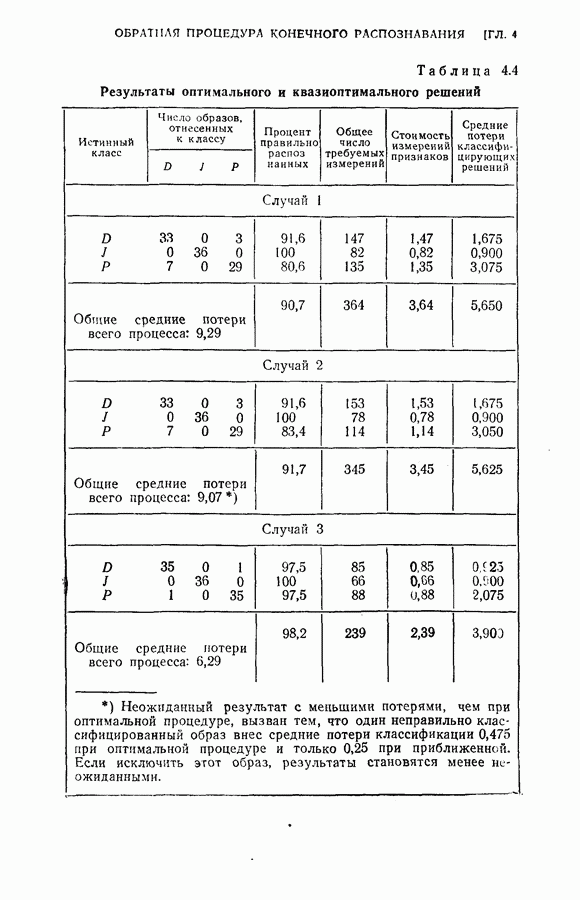
Рис. 4.6. Число ошибок в зависимости от числа измеренных признаков — минимум и максимум. Измерения среднего процента ложных распознаваний для подмножеств различного объема показаны на рис. 4.6. Числа, проставленные у нанесенных точек, указывают лучшие и худшие подмножества признаков.
|
 |
Оглавление
|









































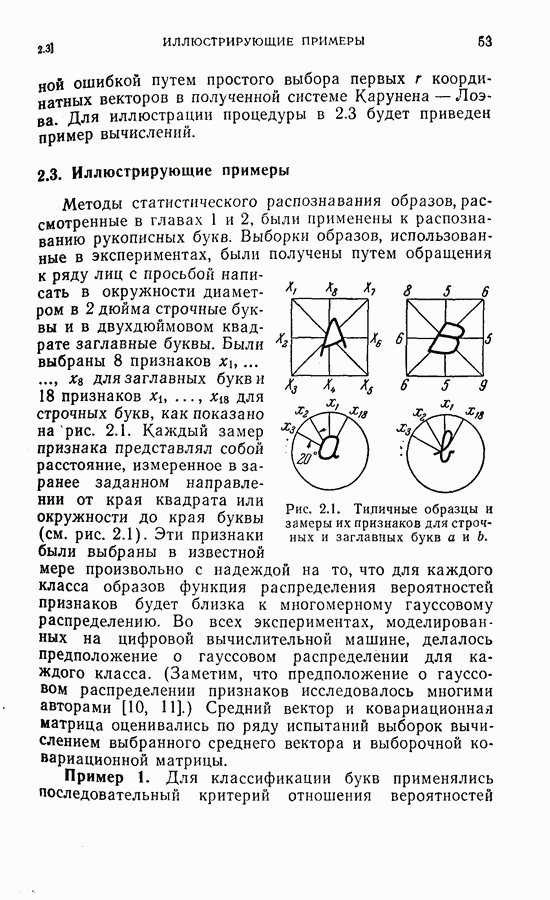

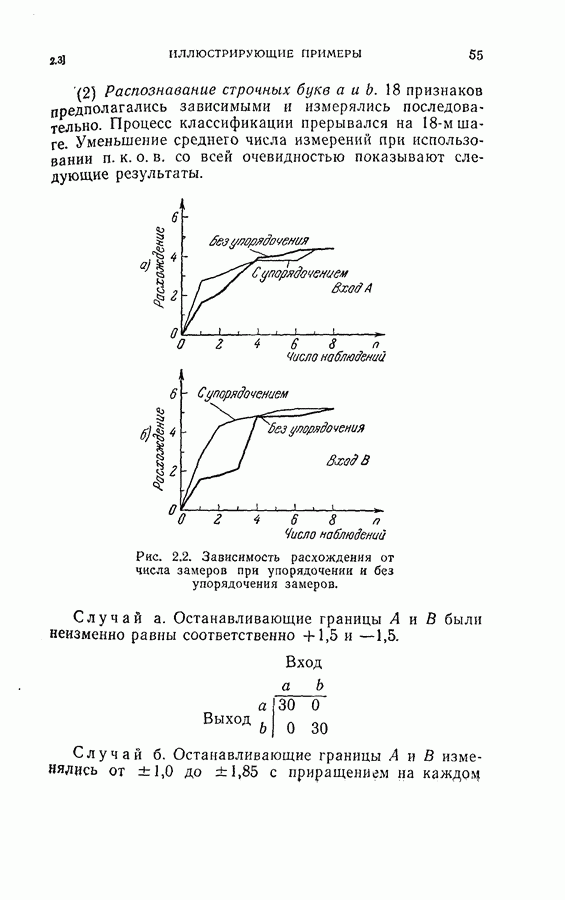


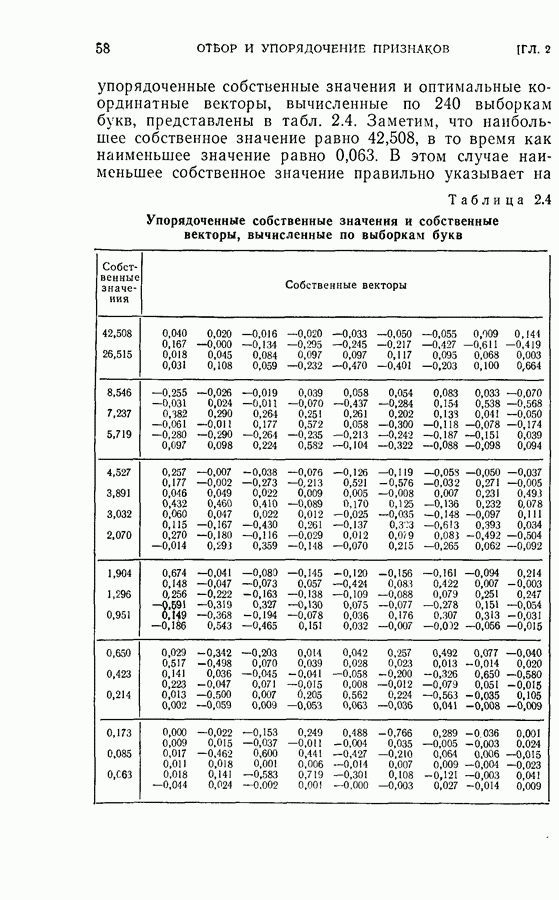
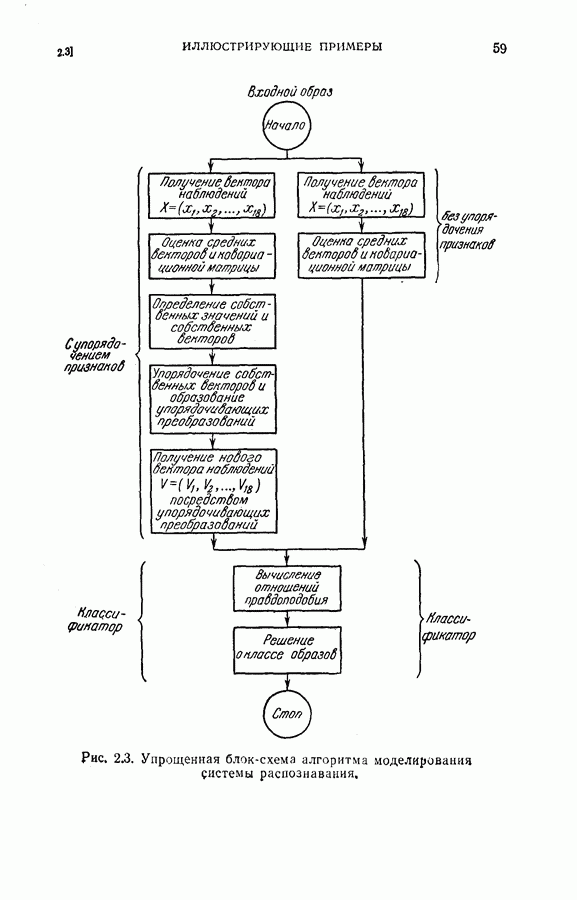













































































































































































 применив прямую последовательную решающую процедуру с числом независимых, но не одинаково распределенных признаков не большим пяти. Задача заключается в выборе лучшего подмножества объемом пять из восьми данных признаков. Предположим, что априорные вероятности для каждого класса заданы. Задача отбора подмножества признаков может быть решена путем поиска в памяти решающих границ, обеспечивающих минимум среднего риска среди всех границ, содержащих пять признаков. Если положить в примере, приведенном в § 4.6,
применив прямую последовательную решающую процедуру с числом независимых, но не одинаково распределенных признаков не большим пяти. Задача заключается в выборе лучшего подмножества объемом пять из восьми данных признаков. Предположим, что априорные вероятности для каждого класса заданы. Задача отбора подмножества признаков может быть решена путем поиска в памяти решающих границ, обеспечивающих минимум среднего риска среди всех границ, содержащих пять признаков. Если положить в примере, приведенном в § 4.6,  и
и  , то все три подмножества
, то все три подмножества


 исследований классификации. Результаты этих исследований представлены на рис. 4.4, 4.5 и 4.6.
исследований классификации. Результаты этих исследований представлены на рис. 4.4, 4.5 и 4.6.

