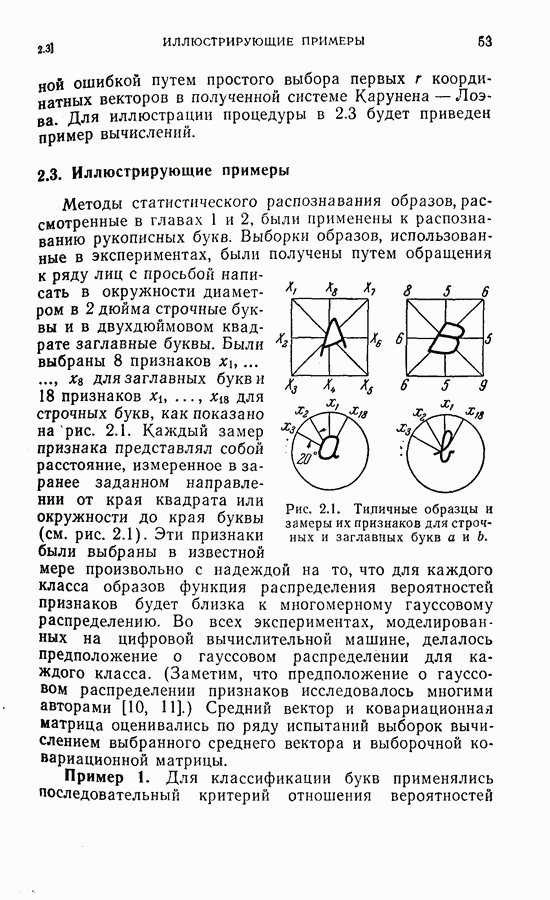
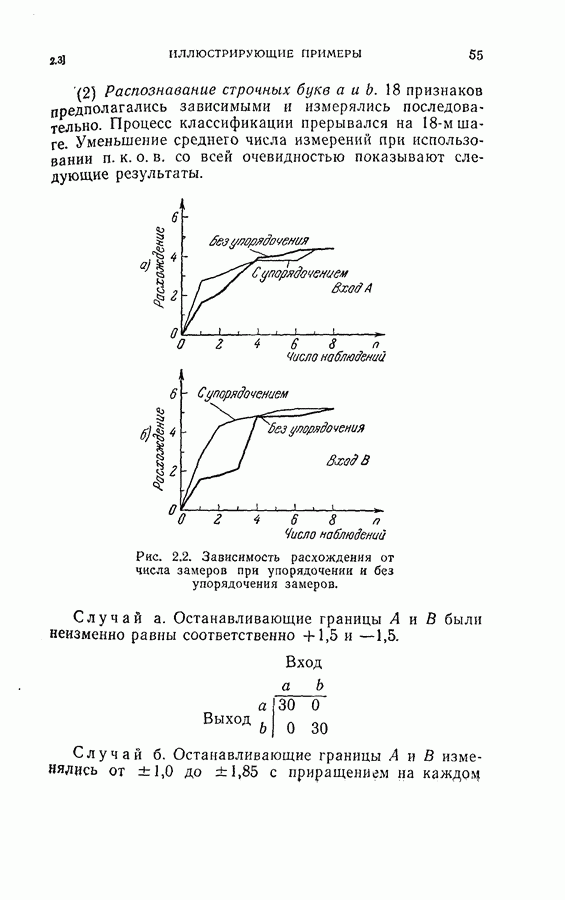
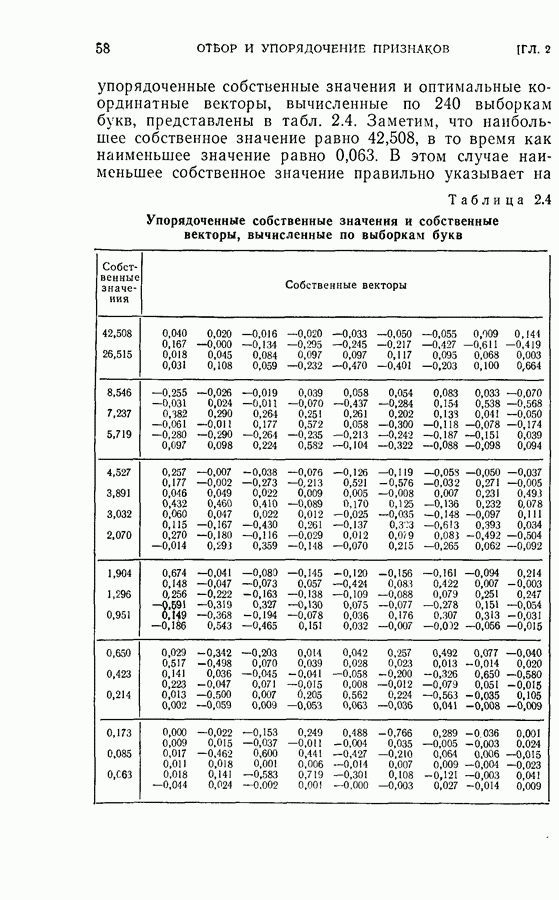
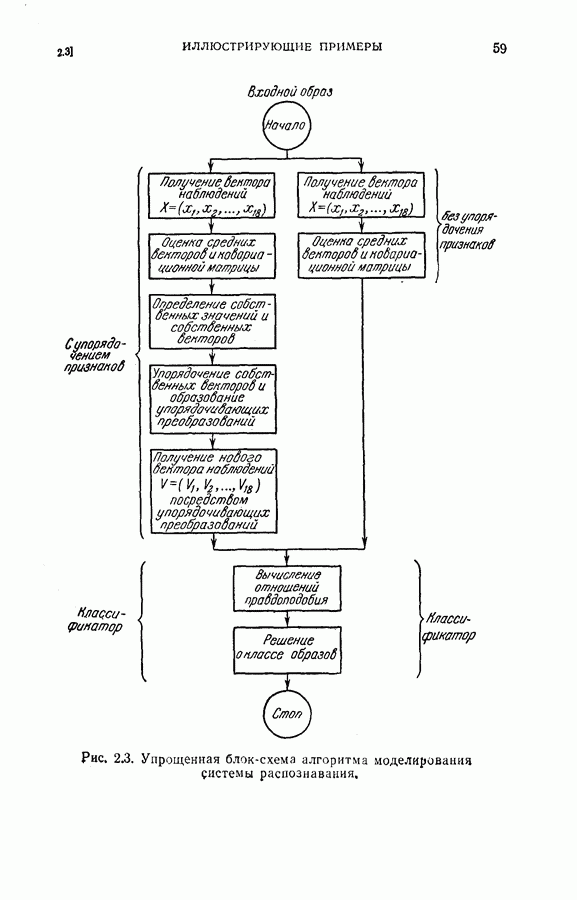
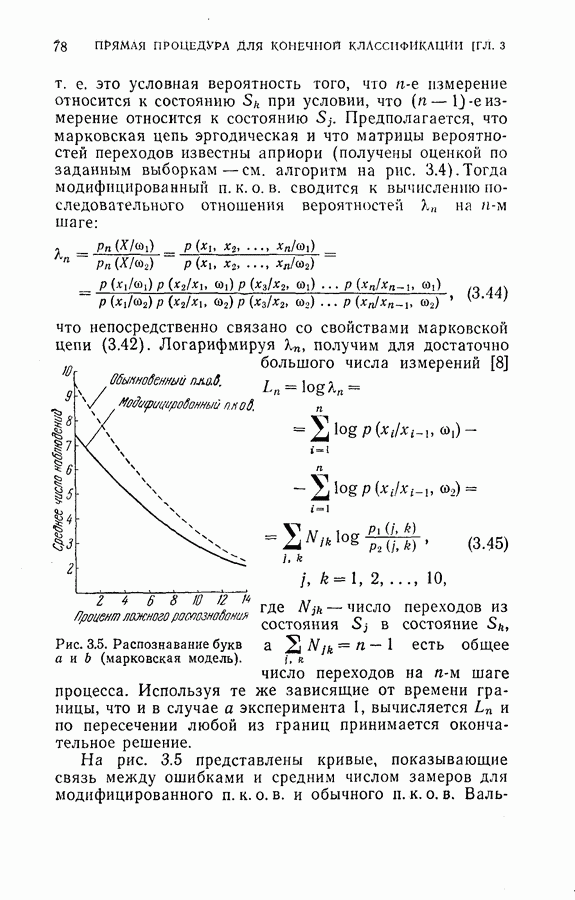
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
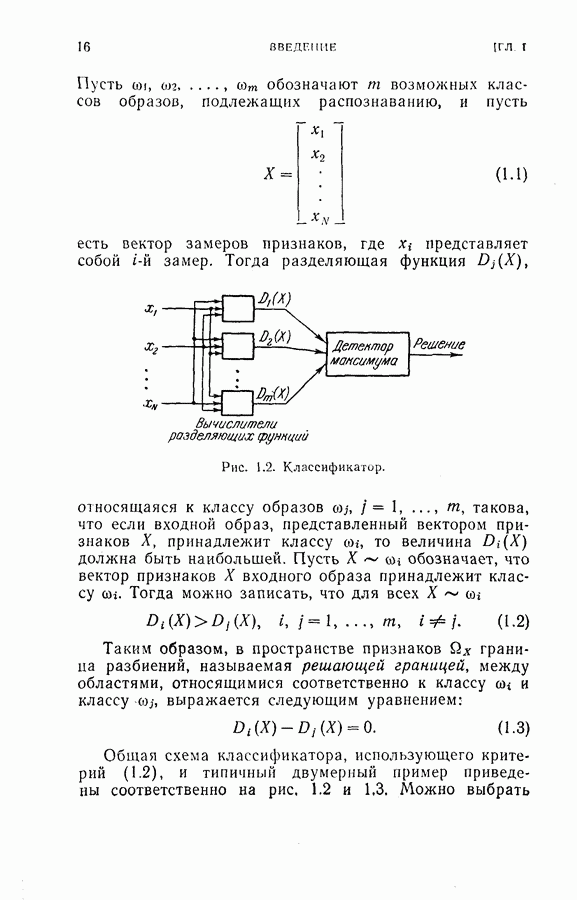
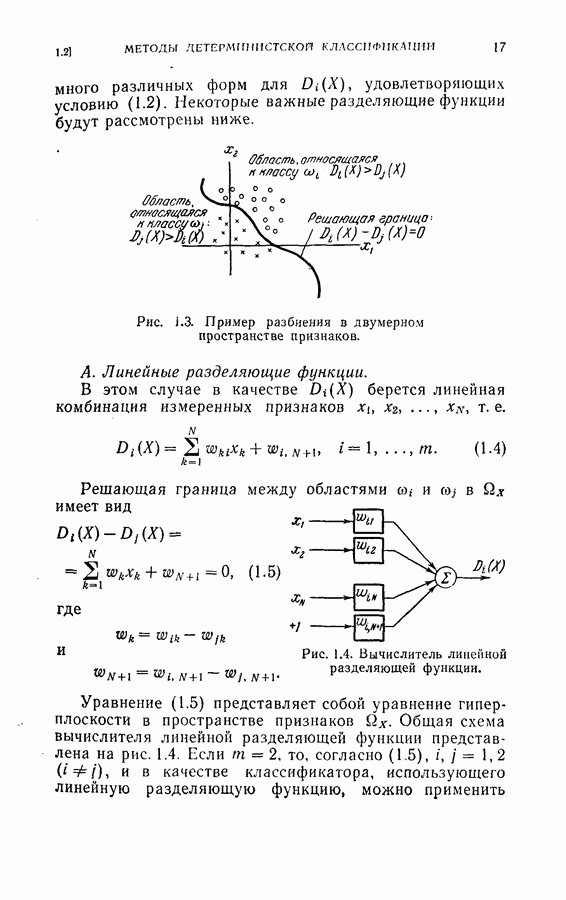
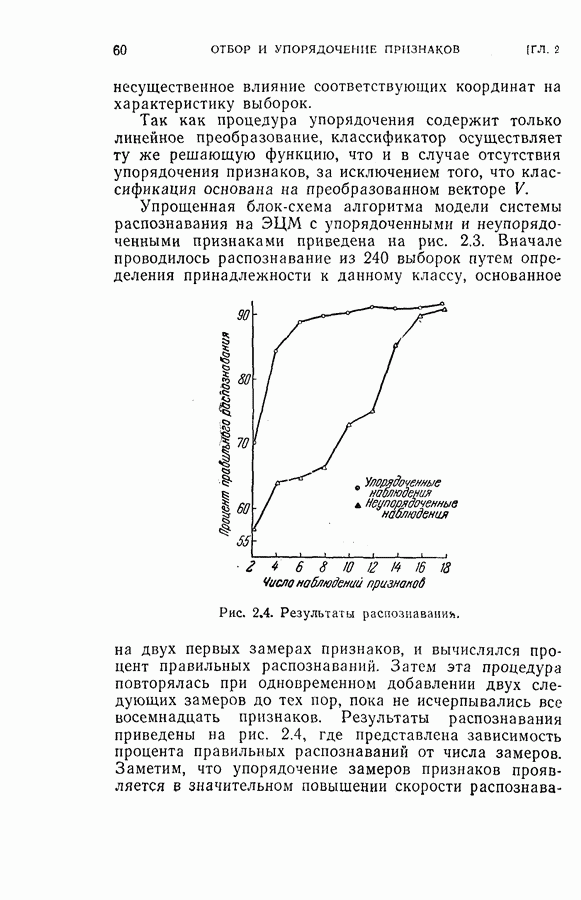
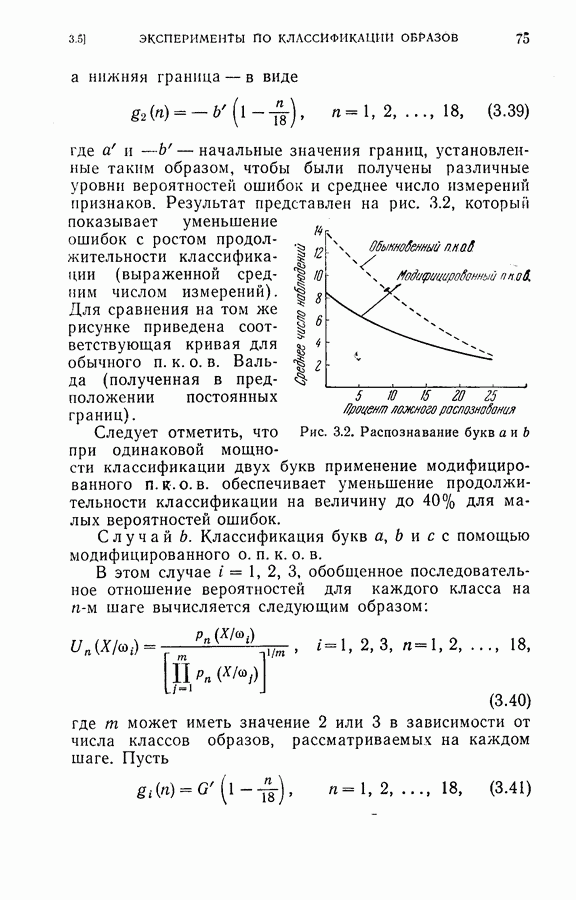
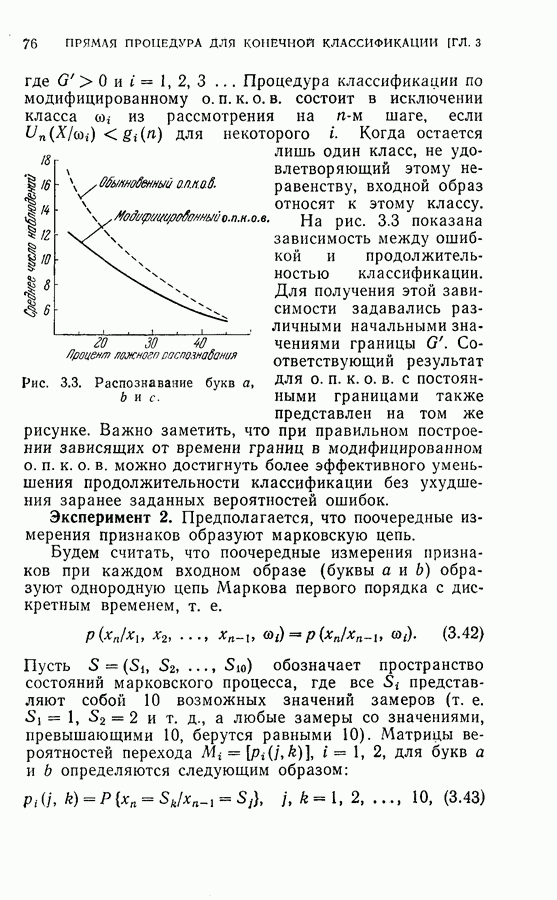
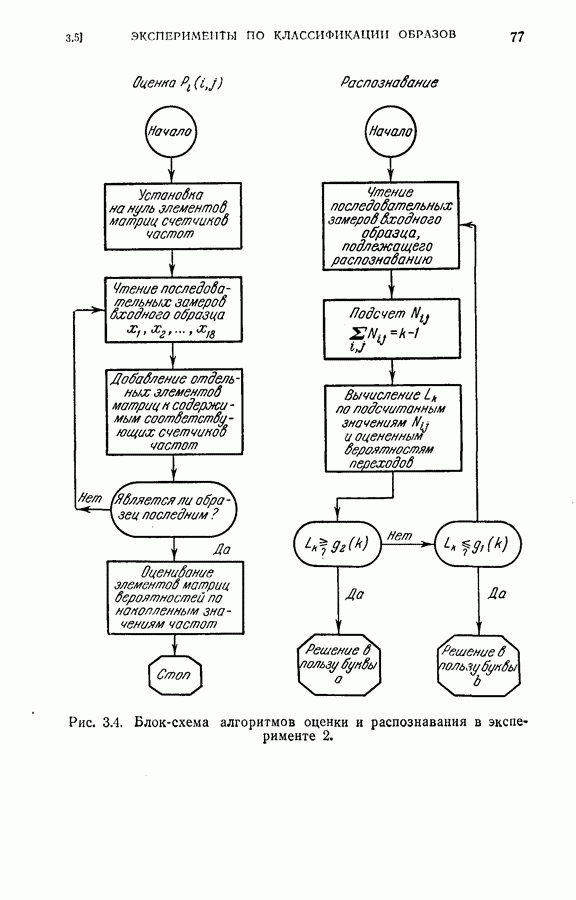
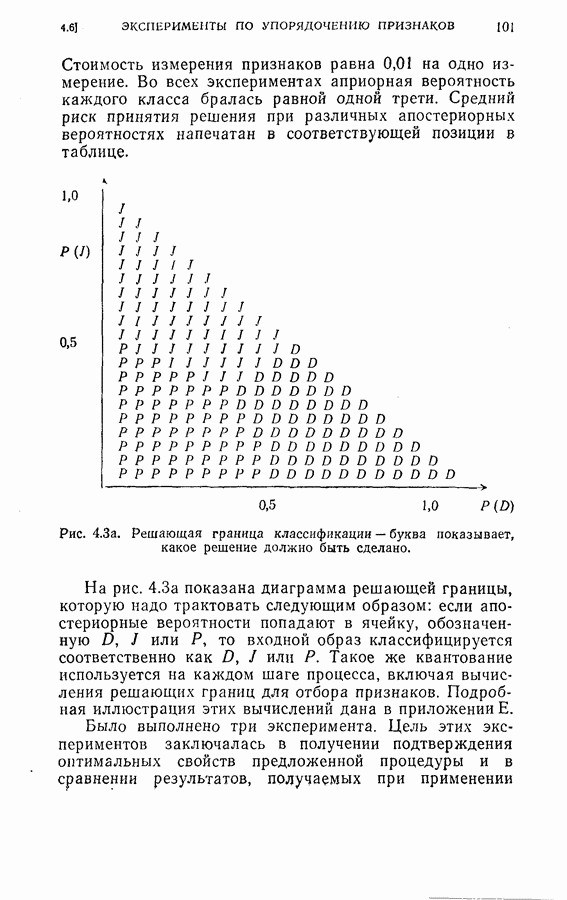
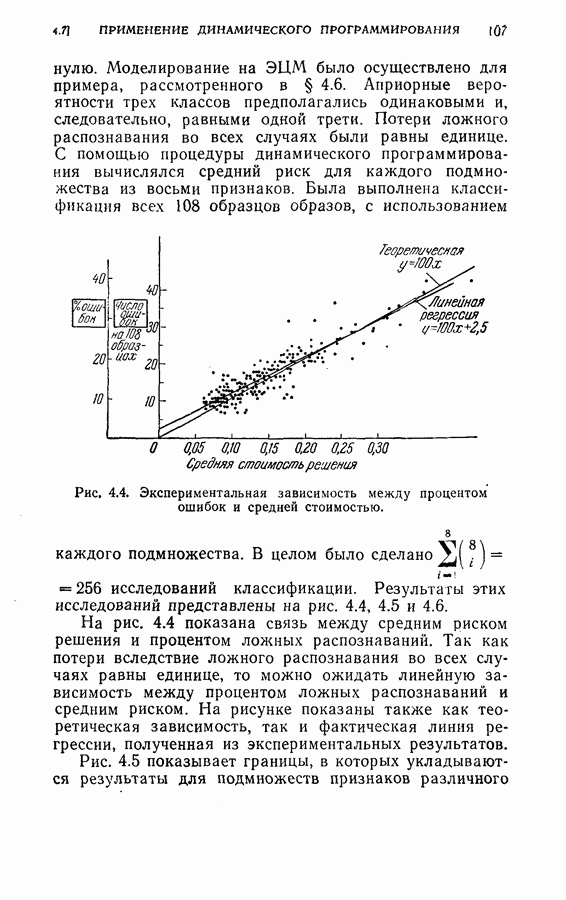
4.4. Эксперименты по классификации образовДля проверки постановки задачи и процедуры, описанных в §§ 4.2 и 4.3, была взята частная задача классификации образов. В качестве классов образов рассматривались буквы обработаны 36 образцов каждой буквы. Как показано на рис. 4.1, в качестве последовательных замеров были взяты восемь радиальных отрезков
Рис. 4.1. Типичные образцы букв Далее каждый замер квантовался на пять уровней
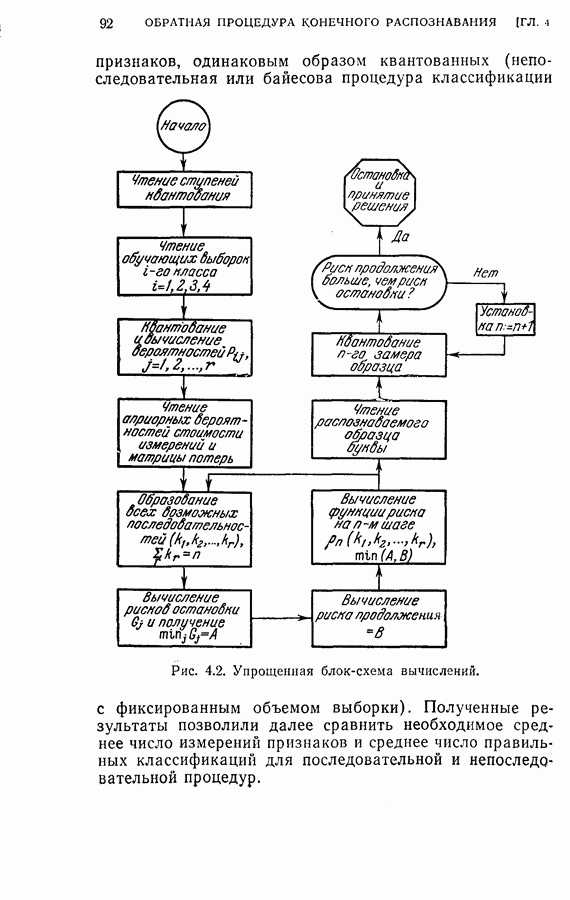
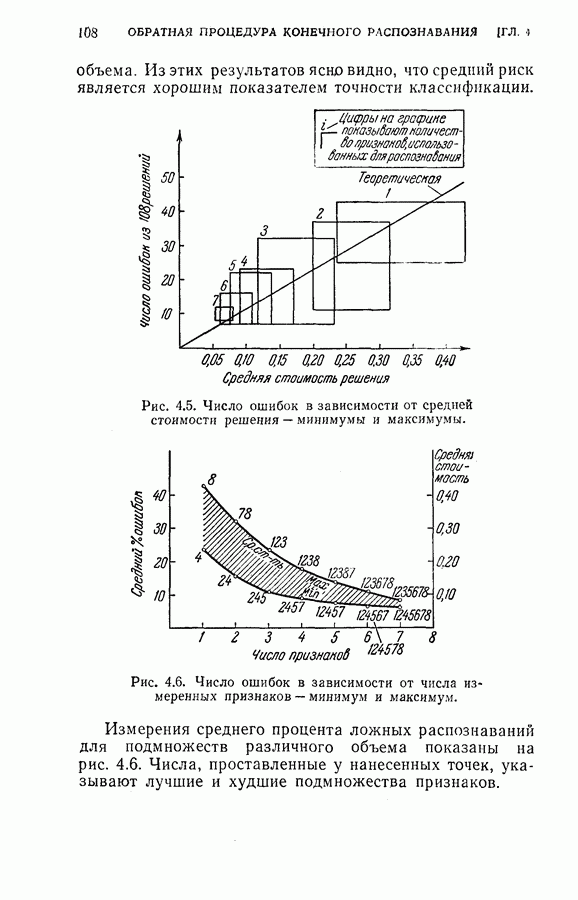
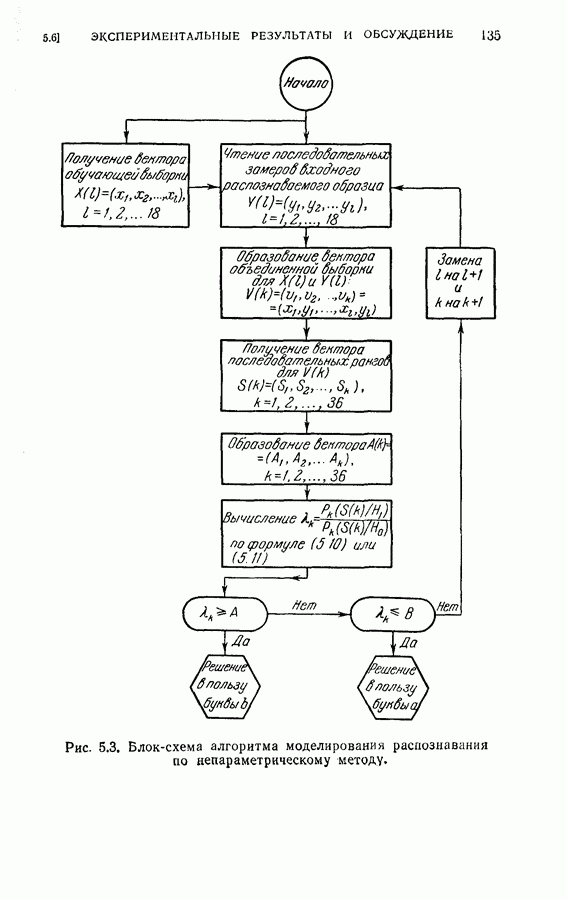
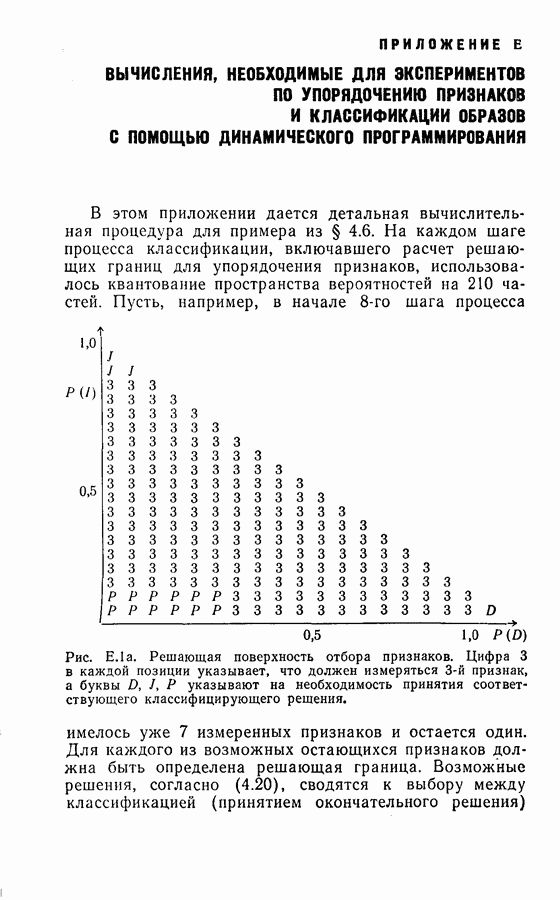
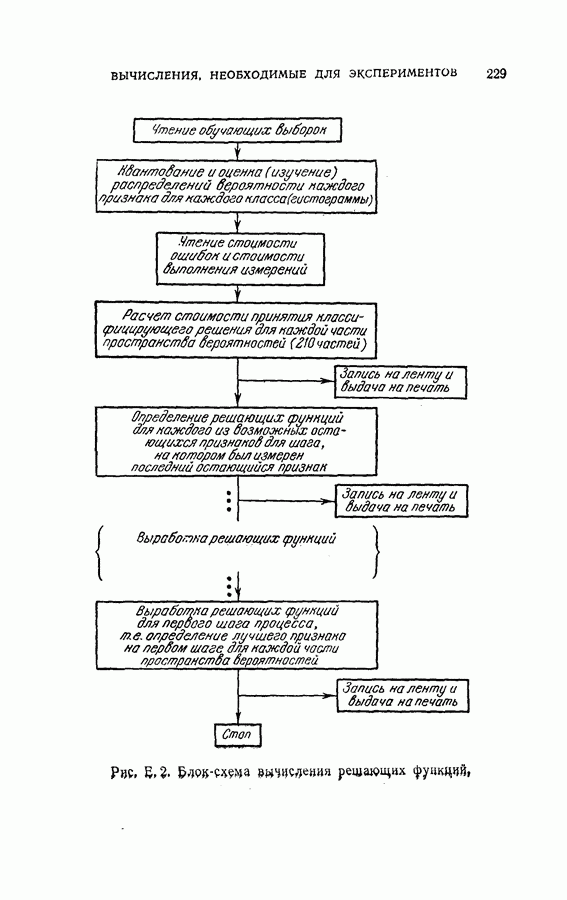
На рис. 4.2 приведена упрощенная схема вычислений, которая показывает как программу вычислений, так и хранение различных величин, требуемых для процедуры классификации, а также программу самой процедуры классификации. Ниже приводятся результаты, полученные с помощью этой программы при различных условиях эксперимента. Кроме процедуры динамического программирования эксперименты проводились также для определения погрешностей, получаемых при использовании всех восьми признаков, одинаковым образом квантованных (непоследовательная или байесова процедура классификациис фиксированным объемом выборки). Рис. 4.2. (см. скан) Упрощенная блок-схема вычислений. Полученные результаты позволили далее сравнить необходимое среднее число измерений признаков и среднее число правильных классификаций для последовательной и непоследовательной процедур. Таблица 4.1 (см. скан) Распределения замеров признаков для букв Эксперимент 1. Условия эксперимента: (1) Стоимость всех измерений одинаковая (2) Функция потерь
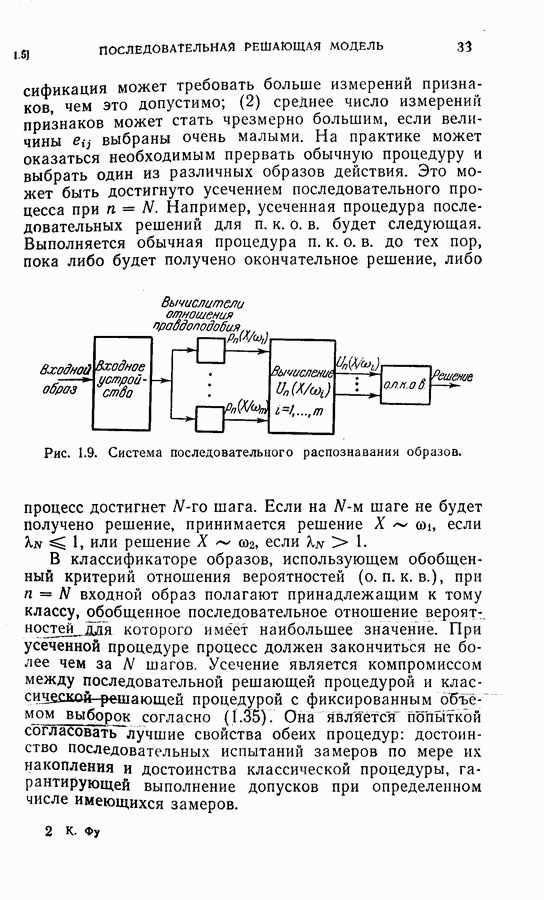
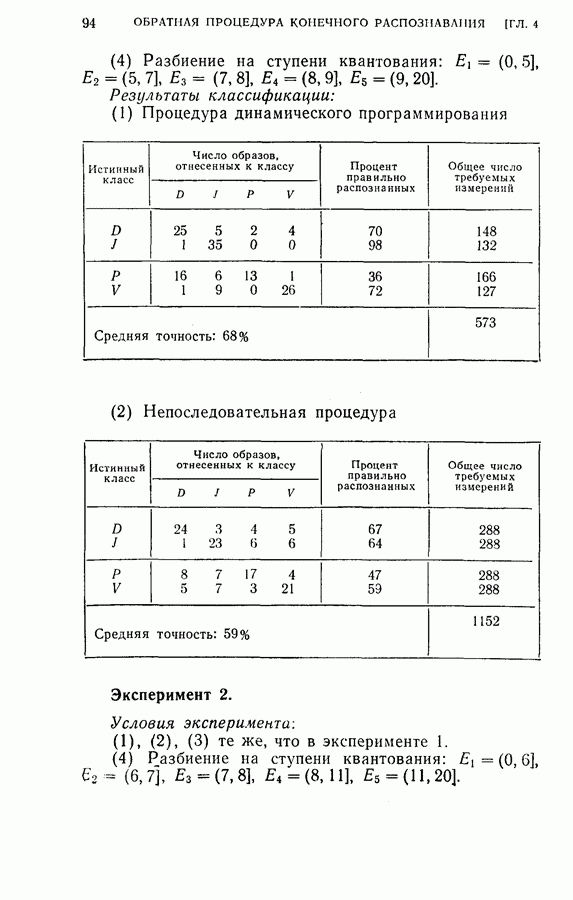
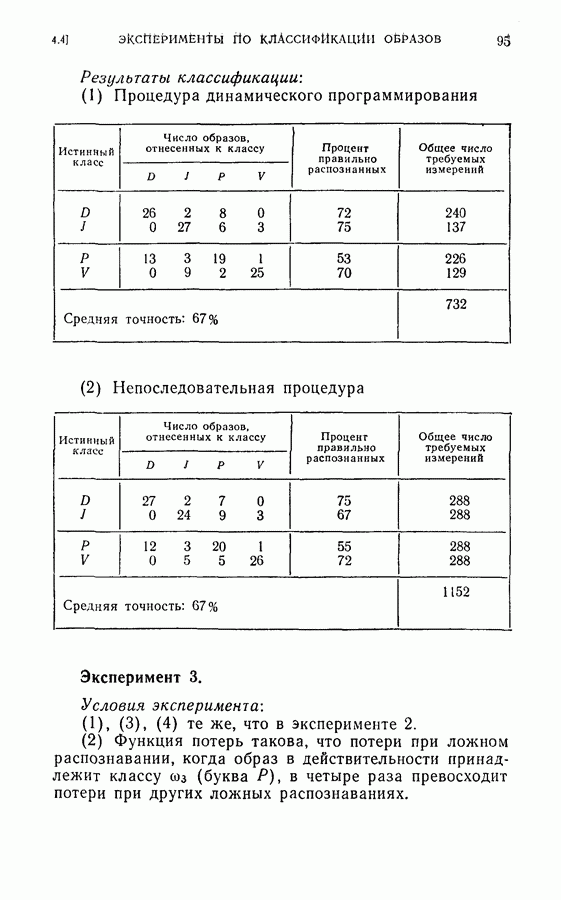
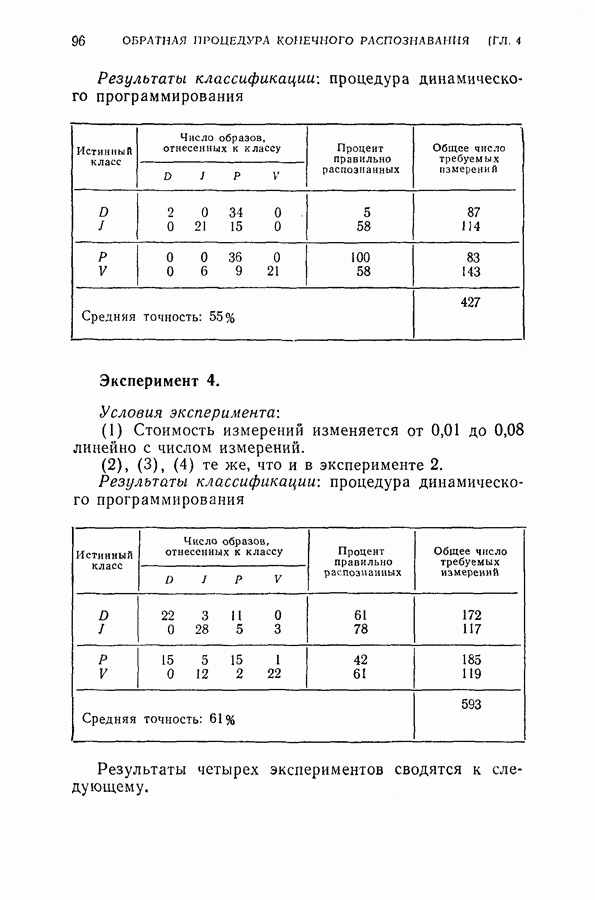
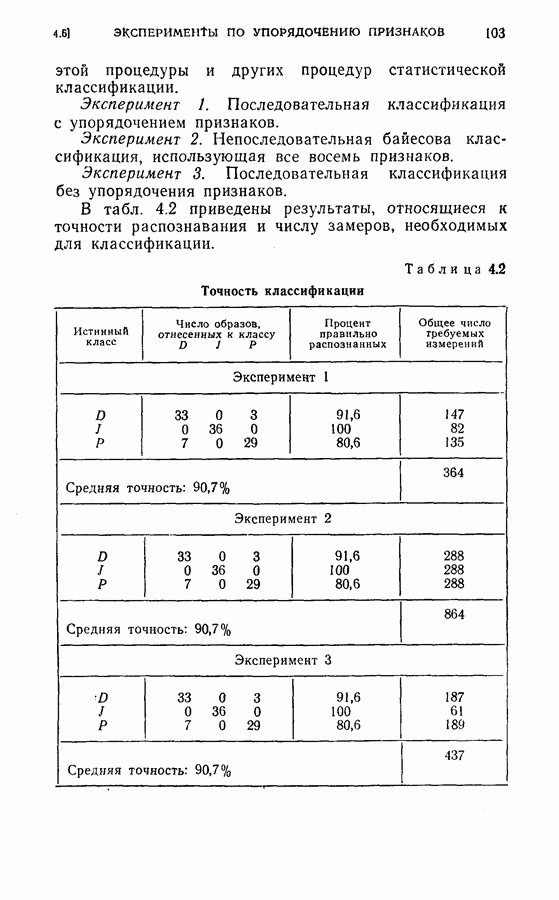
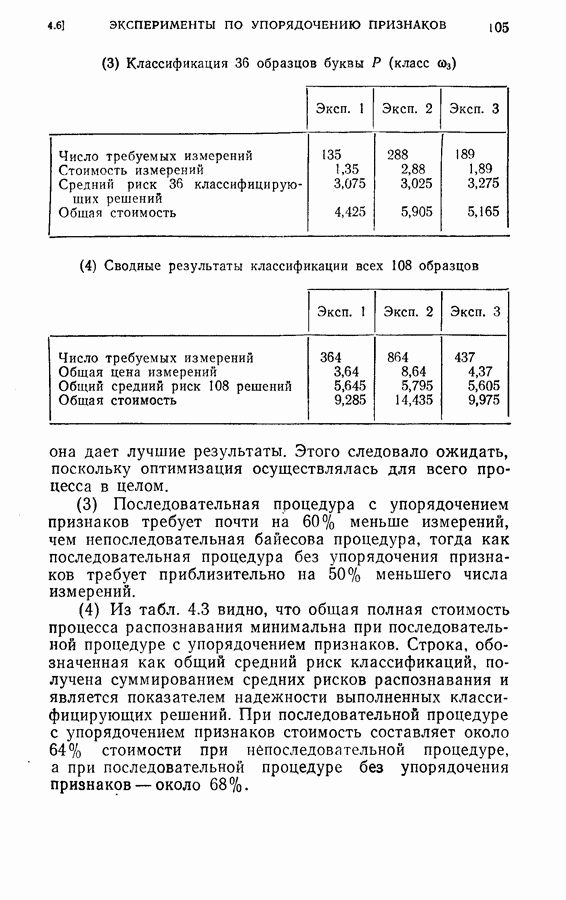
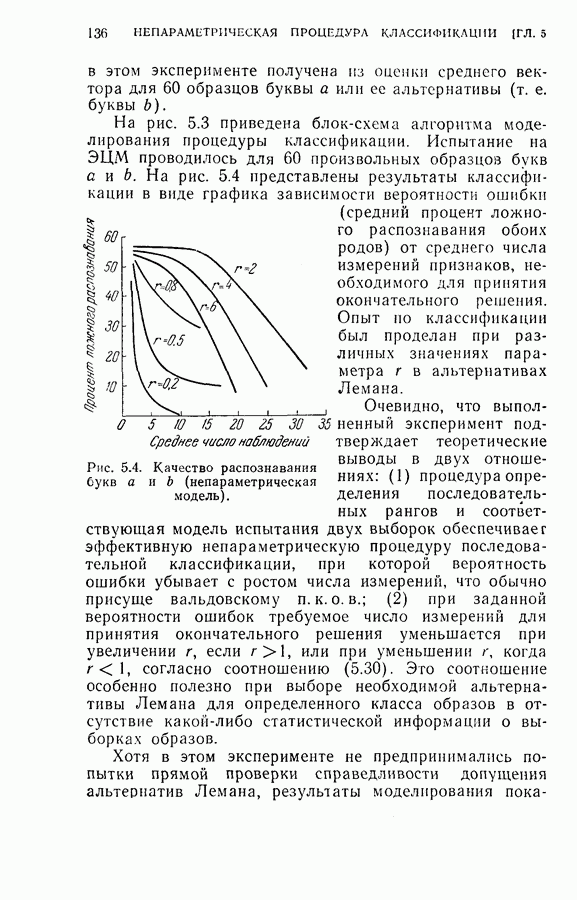
(4) Разбиение на ступени квантования: Результаты классификации: (1) Процедура динамического программирования (см. скан) (2) Непоследовательная процедура (см. скан) Эксперимент 2. Условия эксперимента: (1), (2), (3) те же, что в эксперименте 1. (4) Разбиение на ступени квантования: Результаты классификации. (1) Процедура динамического программирования (см. скан) (2) Непоследовательная процедура (см. скан) Эксперимент 3. Условия эксперимента: (1), (3), (4) те же, что в эксперименте 2. (2) Функция потерь такова, что потери при ложном распознавании, когда образ в действительности принадлежит классу Результаты классификации, процедура динамического программирования (см. скан) Эксперимент 4. Условия эксперимента. (1) Стоимость измерений изменяется от 0,01 до 0,08 линейно с числом измерений. (2), (3), (4) те же, что и в эксперименте 2. Результаты классификации: процедура динамического программирования (см. скан) Результаты четырех экспериментов сводятся к следующему. (1) Эксперименты 1 и 2 позволяют сравнить результаты классификации с помощью процедуры динамического программирования и процедуры непоследовательной классификации для двух различных квантований пространства признаков. Как и следовало ожидать, применение процедуры динамического программирования требует для каждого эксперимента значительно меньшего числа измерений, чем непоследовательная процедура, без существенного снижения процента правильных классификаций. (2) Эксперимент 3 показывает влияние применения несимметричной функции потерь. Придавая классу из значительно больший вес, можно получить для этого класса правильную классификацию в 100% случаев. Хотя этот результат достигается ценою увеличения ошибок при классификации образов других классов, тем не менее такое изменение функции потерь делает процедуру классификации более гибкой и удобной для различения всяких ошибок. (3) Эксперимент 4 показывает влияние изменения стоимости выполнения измерений (использовалась линейная функция стоимости). Следует отметить, что большая стоимость более поздних измерений приводит к тому, что процесс классификации завершается значительно раньше, однако за счет снижения точности классификации.
|
 |
Оглавление
|

























































































































































































































 (обозначенные соответственно как классы
(обозначенные соответственно как классы  Для оценки различных требуемых статистик каждого класса были
Для оценки различных требуемых статистик каждого класса были
 значениями от 1 до 20), такие же, как в § 2.3 для букв
значениями от 1 до 20), такие же, как в § 2.3 для букв  Для уменьшения объема вычислений был применен метод, описанный в разделе 4.3.1 в предположении, что замеры статистически независимы.
Для уменьшения объема вычислений был применен метод, описанный в разделе 4.3.1 в предположении, что замеры статистически независимы.

 и измерение их признаков.
и измерение их признаков.
 и в качестве событий рассматривались попадания значений замеров на ту или иную ступень квантования. Значения параметров
и в качестве событий рассматривались попадания значений замеров на ту или иную ступень квантования. Значения параметров  характеризующих мультиномиальное распределение класса Юг, оценивались путем построения гистограммы и вычисления отношений частот появления этих событий. Приближенная функция кумулятивного распределения замеров, полученная таким способом, приведена в табл.
характеризующих мультиномиальное распределение класса Юг, оценивались путем построения гистограммы и вычисления отношений частот появления этих событий. Приближенная функция кумулятивного распределения замеров, полученная таким способом, приведена в табл.  представляет число замеров из класса
представляет число замеров из класса  меньших целого числа
меньших целого числа  где
где  Например, если 3-я ступень квантования будет заключена в пределах (6, 10), то для класса
Например, если 3-я ступень квантования будет заключена в пределах (6, 10), то для класса 


 на одно измерение.
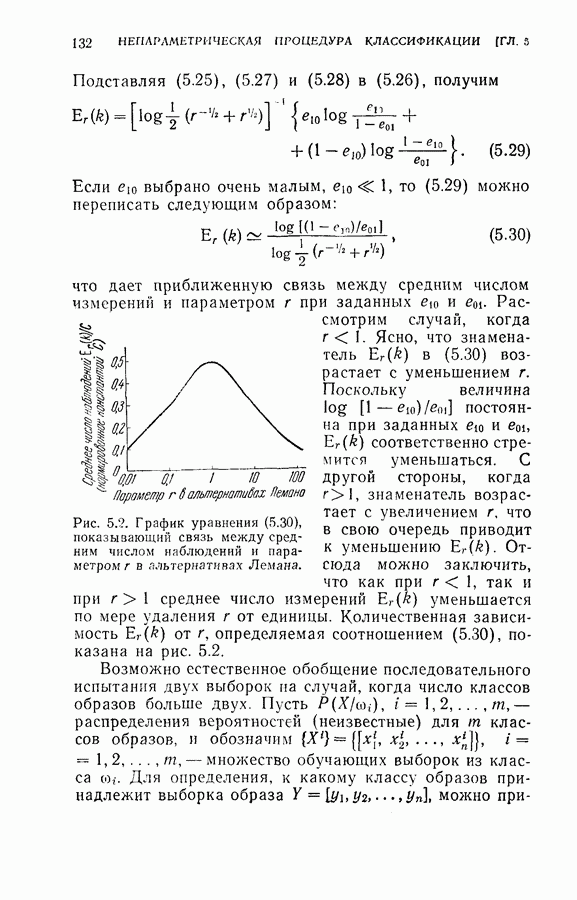
на одно измерение.


 ].
].
 (буква
(буква  в четыре раза превосходит потери при других ложных распознаваниях.
в четыре раза превосходит потери при других ложных распознаваниях.